@gaoxiaoyunwei2017
2019-04-18T07:01:16.000000Z
字数 3871
阅读 1486
阿里巴巴智能数据中心AIOps演进之路
北哥
讲师简介
向飞
- 阿里巴巴基础设施事业部高级技术专家

做数据中心是很小众化的,从某种程度上来说,国内除了阿里巴巴和另外几家云厂商就没有了。本文将根据以下几点来分享阿里巴巴智能数据中心:
- 云市场现状。个人觉得任何问题一定要放在大背景的前提下来看,在这个大背景下,我们处在哪个位置?在这个情况下应该往哪个方向走。
- 在这个情况下我们处于什么阶段?每个阶段所采用的方法不一样,我们应该怎么做,遇到哪些挑战。
- 阿里巴巴智能数据中心AIOps演进。
- 最后是展望。展望更多的是心里怎么想,会引领我们在实际工作中如何做。
1. 云市场现状
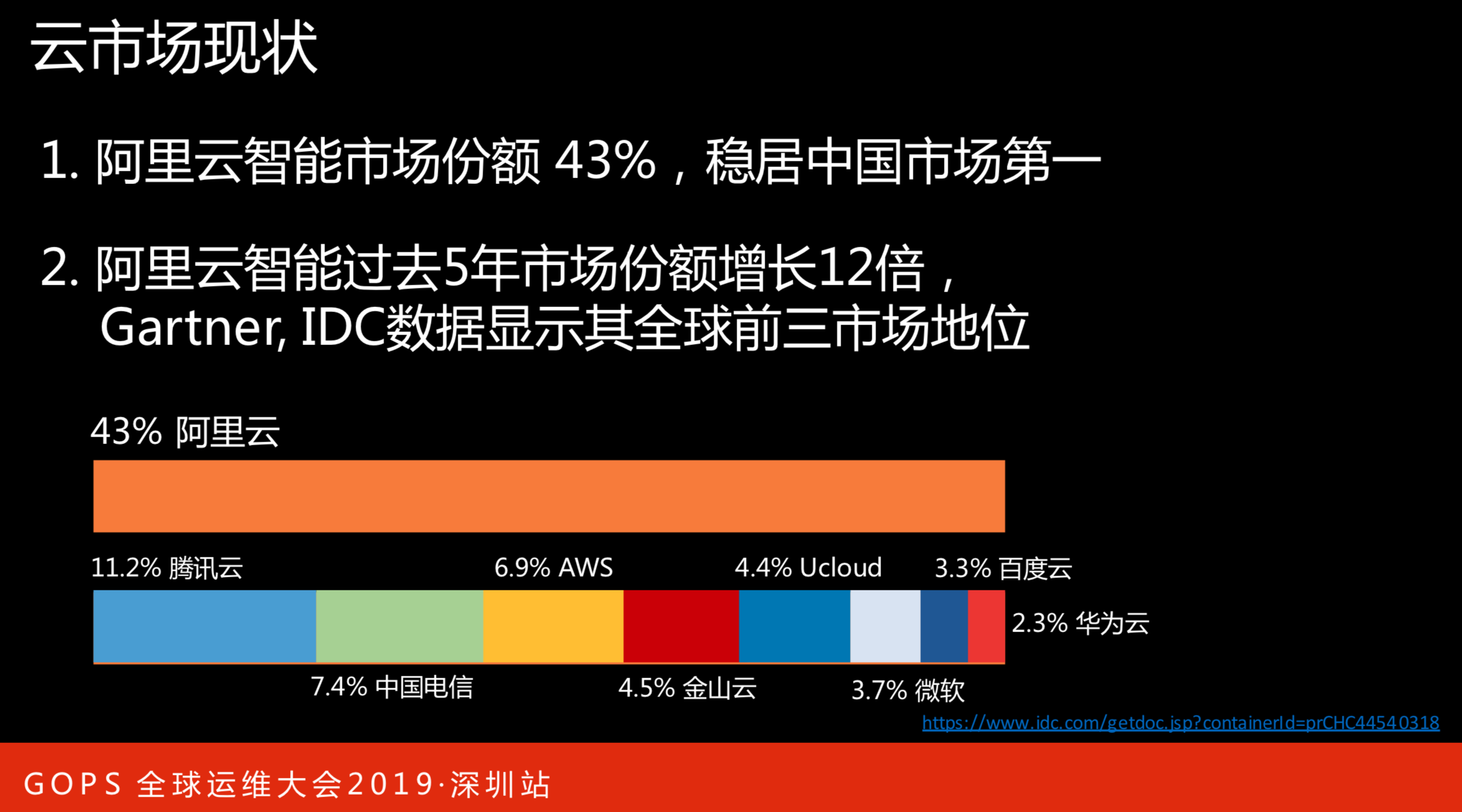
上面是截止到2018年6月份国内云市场份额占比的情况。阿里占据市场份额的43%,最下面的一列是第二到第八名的市场份额。在国内市场份额,阿里巴巴稳居第一位,第二位和第八位加起来比阿里巴巴还要少一点。
还有一个数据,虽然阿里云已经十年了,但是前几年是以市场培育和内部技术沉淀为主,过去5年是商业化阶段,有一些突飞猛进的表现。据统计,在过去的5年阿里云市场份额增长12倍,Gartner、IDC数据显示阿里云全球市场第三。
可得出,这是一个快速的市场,我们在国内或者国际市场处于猛烈增长,同时我们也将面临各种各样的问题和挑战。
2. 阿里巴巴智能数据中心业务及挑战
数据中心分布
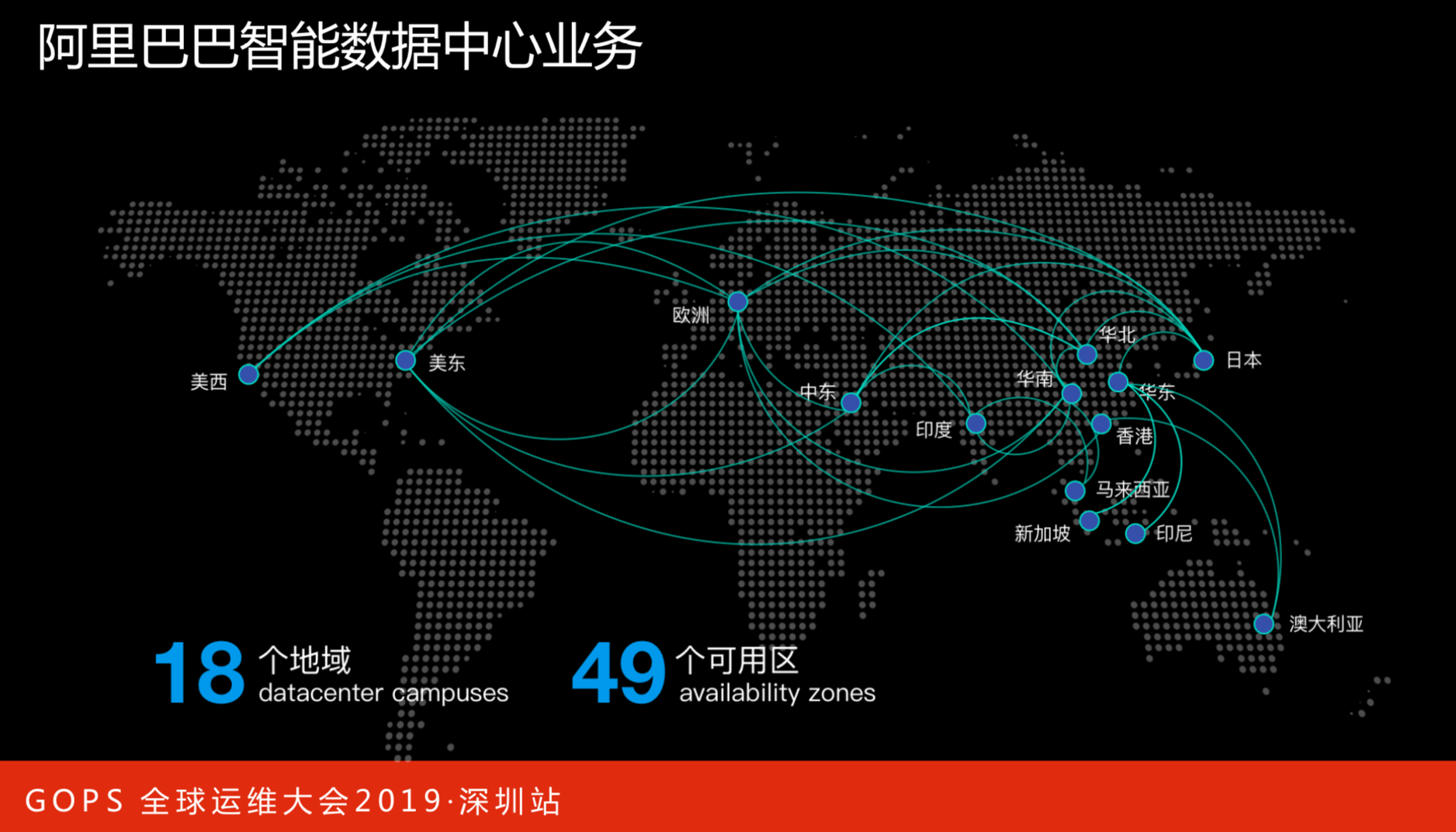
此图是阿里巴巴智能数据中心全球覆盖情况。
目前阿里云智能数据中心核心是在亚太区,从图上就可以看到。除了非洲之外,各大洲都有数据中心的分布。特别是美东、美西和澳大利亚,美东和美西是针对美洲的市场。
数据中心业务的分布可以很好的支持国内企业走向国际市场,也可以更好地服务国际上的客户,包括一些国际上的大客户进入国内的市场。
目前数据中心分布18个地域,具有49个可用区。
数据中心挑战

从整个行业发展和阿里云自身的快速发展情况来说,阿里云智能虽然过去5年跻身于全球第三,而且还是在不断的增长壮大。
根据Uptime的数据报告,所有DC中断中70%由人为事故造成。
云市场的规模越来越大,每年还在翻倍的增长。在这种叠加的情况下,大家面临的挑战必然是越来越多。我们面临的问题就是上面这句话:保障规模化的数据中心下高效和稳定运行。
数据中心机会
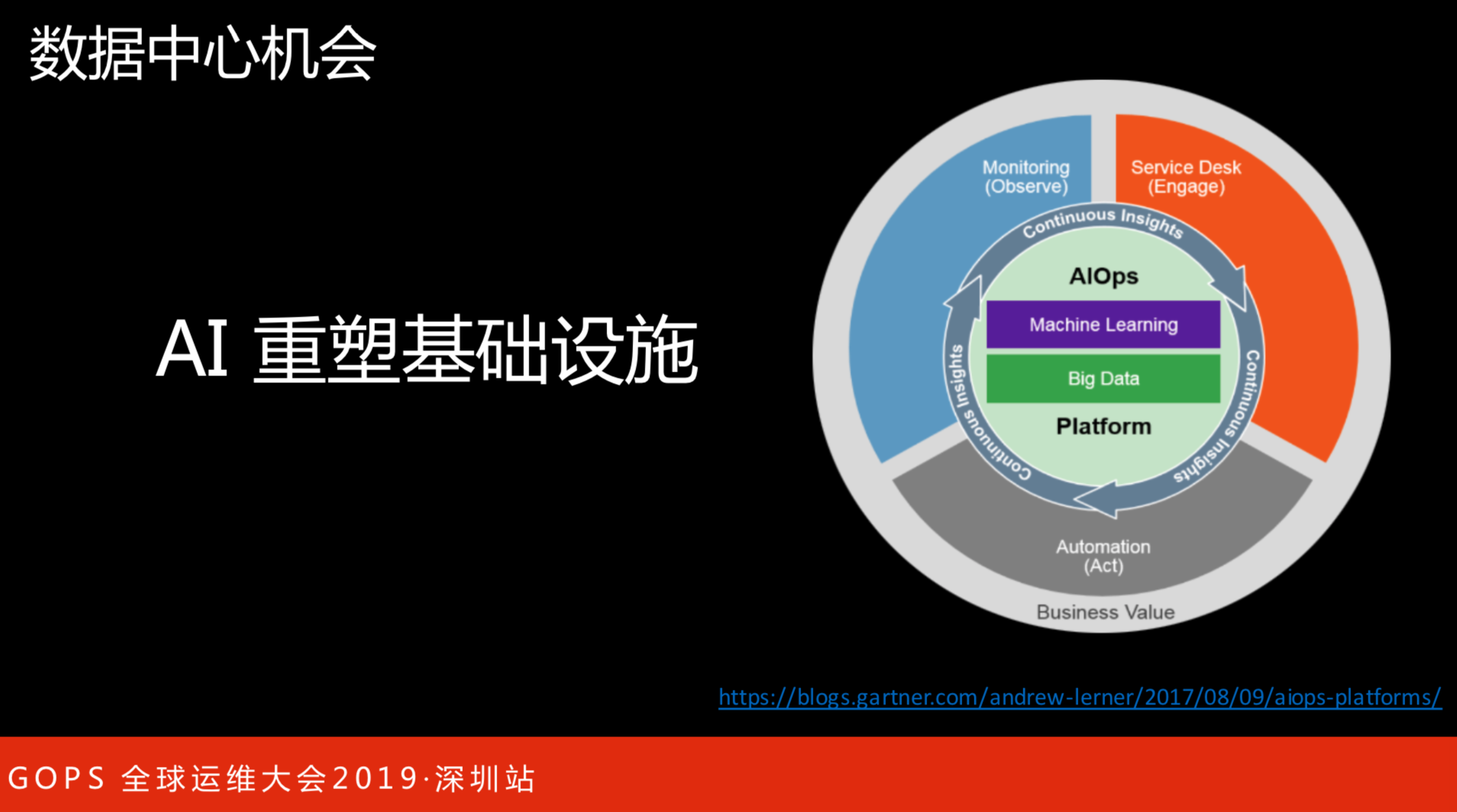
有问题、有挑战、有市场,给大家带来的就是有机会。
阿里巴巴提出智能化是2016年,2016年也是云市场进入了快速发展期,服务器超过百万规模。很多时候量级超过了边界点,带来的挑战完全不一样。从那时候我们就提出来,用AI重塑基础设施。右边的图,是2017年提出了AIOps的概念,在这个概念里,核心有两部分,除了平台之外,还有引入算法,任何算法都是基于大数据,只要有数据才有算法,才能发挥作用。
3. 阿里巴巴智能数据中心AIOps演进
AIOps落地阿里
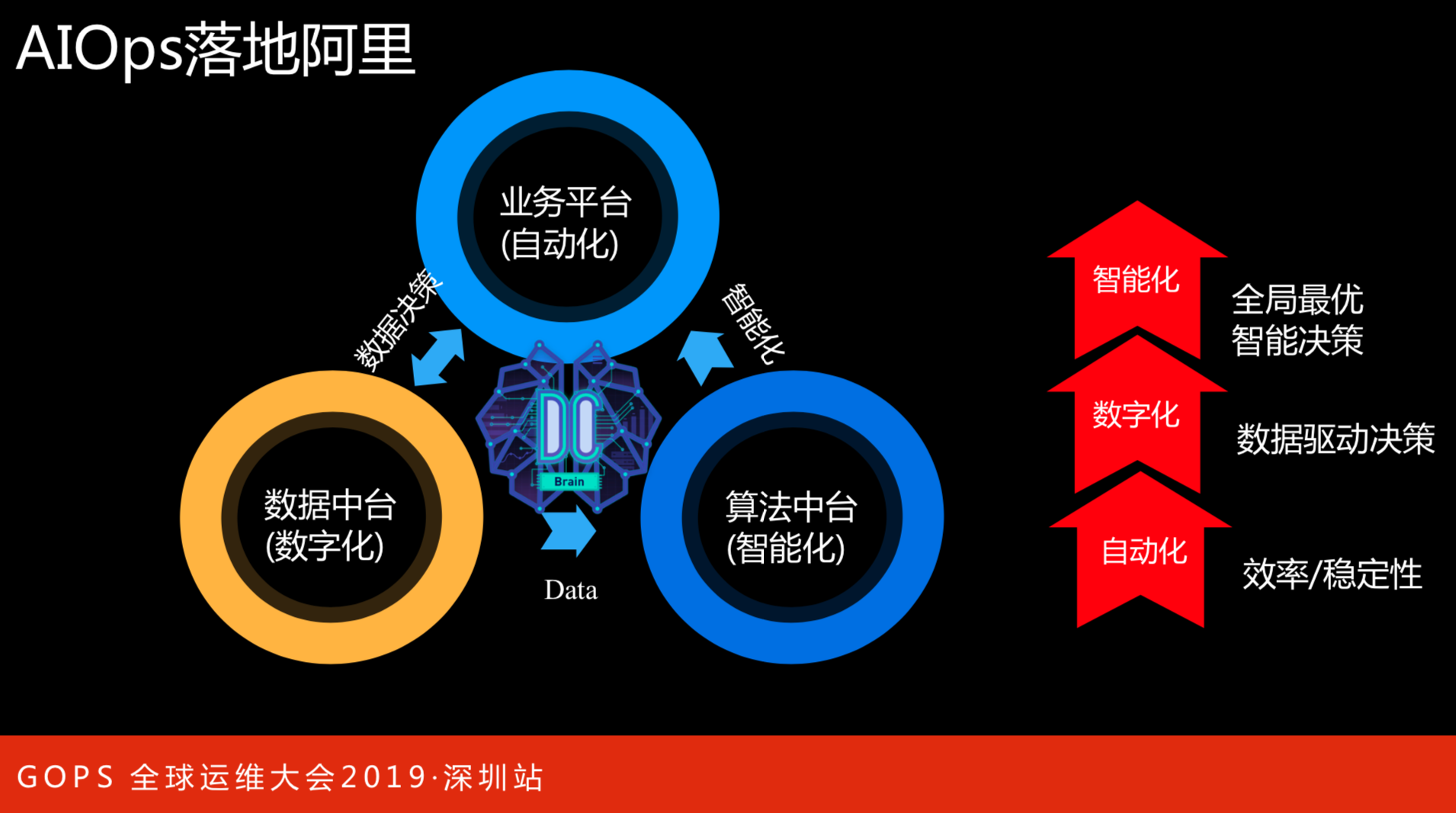
这个是阿里巴巴智能数据中心AIOps总揽,分为三部分:业务平台、数据中台和算法中台。左边图是这三部分的逻辑关系。
任何公司和任何业务的发展一开始都是通过小应用和小工具完成的,随着业务的不断迭代,可能慢慢增长为业务平台,平台都会有各种连接,就会思考平台之间的自动化,以此来提升效率。有了平台和自动化,才能沉淀出来各方面、全维度、全场景的数据。在有数据的情况下,我们才会建整体的数据中台,把整体的数据化标准出来。我们的想法是怎样更好的利用数据中台产生的数据,来结合业务平台思考。
自动化是在追求效率和稳定性,用平台化和自动化解决70%人为故障的问题。用数字化描述业务,以数据来驱动对业务的决策,从业务来说只看到一个点一个点,从数据化才能看到全局。智能化是另外一个层面,人的判断永远都是局部的,虽然有数据化,还需要对全局上做一些最优智能的决策。
以上是我们建AIOps平台的想法,有了这个想法和关联关系,才决定了我们的方向。
基础设施智能运维平台
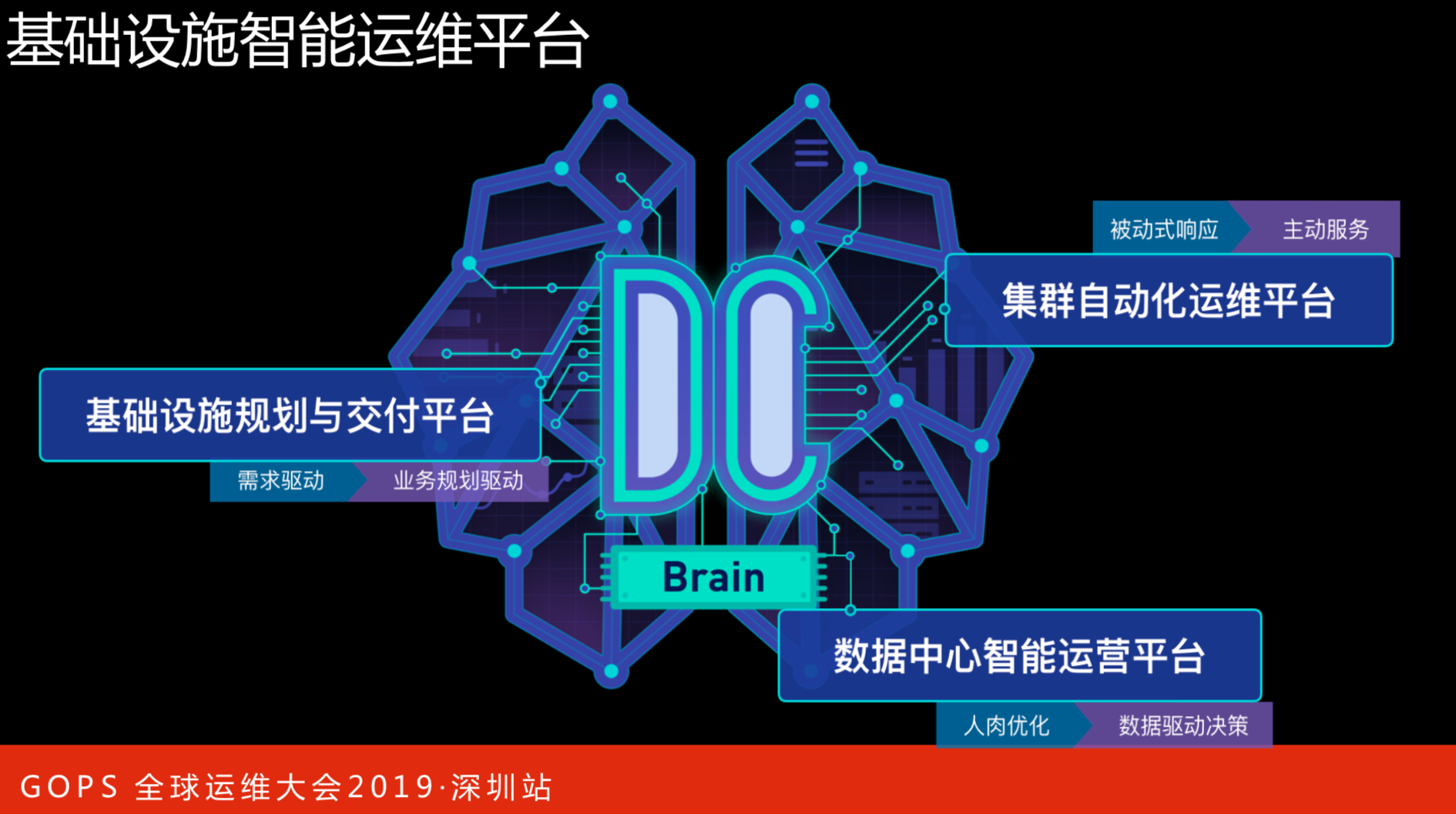
我们每年承载是接近上百万的服务器交互。基础设施智能运维平台分为三层:
- 第一层是基础设施规划与交付平台,保证数据中心不间断;
- 第二层数据中心智能运营平台;
- 第三层集群自动化运维平台。
我们想做的是语言需求怎么规划驱动业务,在数据中心智能运维,靠人为的优化变成驱动的区划。数据中心里面有很大部分是风和水电,大家都会调整,就是PUE,人的调整永远都是根据个人的经验来调的,比如说某些东西调到某些级别。前面说到了数据的收集,算法应该调到哪个值更合适,会考虑得更多。这是三大平台的总体建设思路。
基础设施规划与交付平台
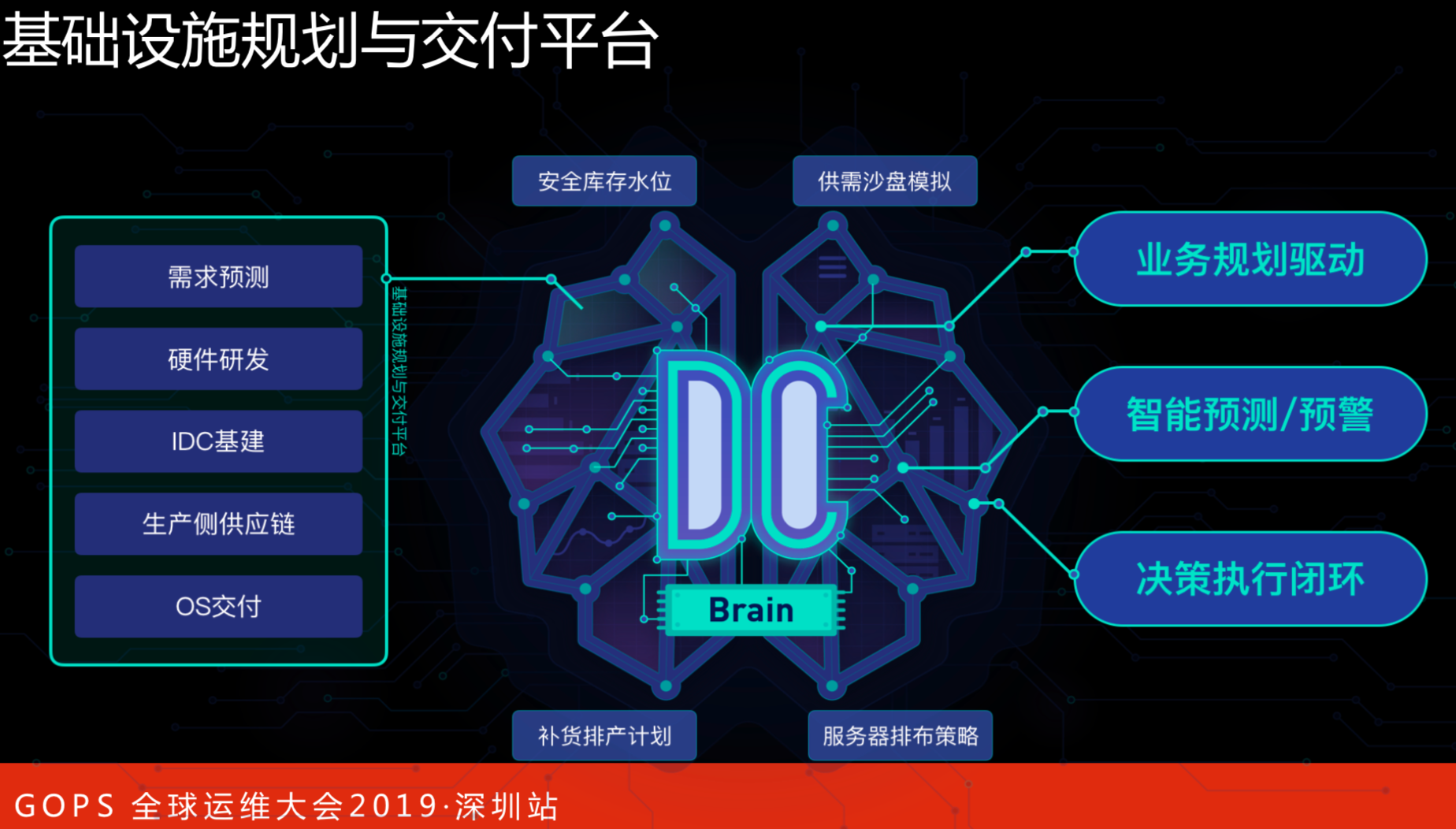
这个是基础设施规划与交付平台。这里生产侧供应链是解决基础设施供应链的问题。首先要解决的是业务需求规划,进一步成数据中心的规划,建多大的数据中心。随着硬件的发展,我们网络带宽已经到400G,这会直接决定了供应链能不能产生对应的货。还有IDC的基建是自动化的交付,保证硬件进入数据中心到上线可以使用,更加的高效。比如OS交付,到了一定量之后,10台机器放10天没有关系,但是,十几二十万台就是很大的成本。
必须保证供给的效率,就是不断的供给,从业务规划来说,这是不容易解决的问题,缺少十几二十台从哪都可以挪过来,但是,缺少十万台机器的时候,就是行业的问题了,这需要通过整体的业务规划来解决。
智能预测和预警,是通过大家在云产品上下单获得数据分析的。另外,我们还会参考基础设施有多少库存,结合各方面的数据来评估,在接下去一个月或者是一年内,在某个区域建多少,这是整体的智能化预测的事情。有了这些数据之后,通过数据中台,不管是从老板视角还是执行人员视角,都能看到执行情况,有利于老板做各种方面的决策,这就形成了决策执行的闭环。
需求预测
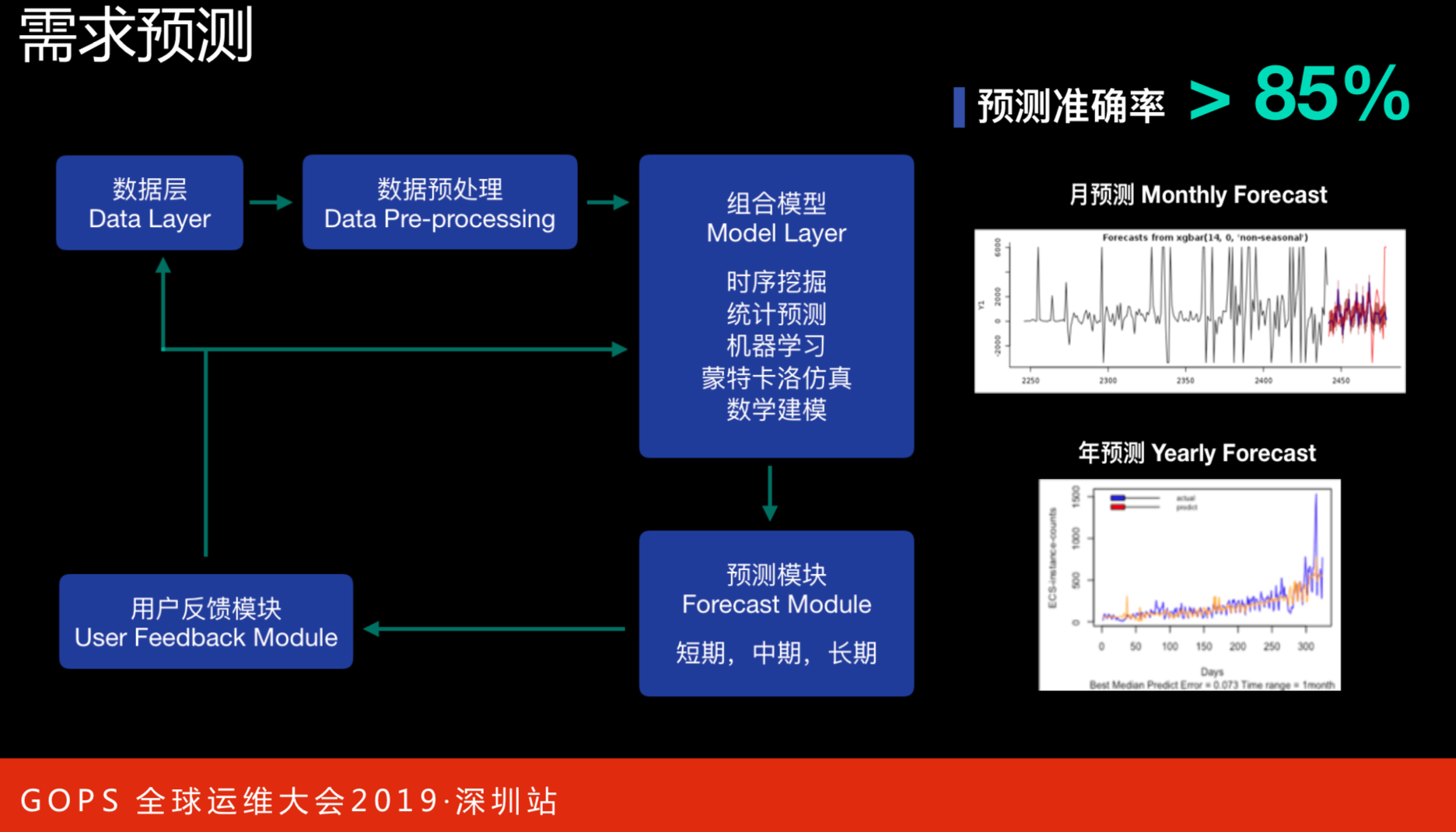
本图是通过一个供应链具体的配置来剖析需求预测。右侧是供应链月度预测和年预测的统计图,目前整体预测准确率大于85%。从算法上来说,在5月会告诉你有多少数是卖掉了,月度可以在90%以上,年度会低一点,但是平均起来会超过85%。
这为供应的效率和供应的成本提供了很大帮助,在规模的情况下,准确率提升一个点,带来的成本节约可能就是几百万,因为会有规模效应。
数据中心智能运营平台
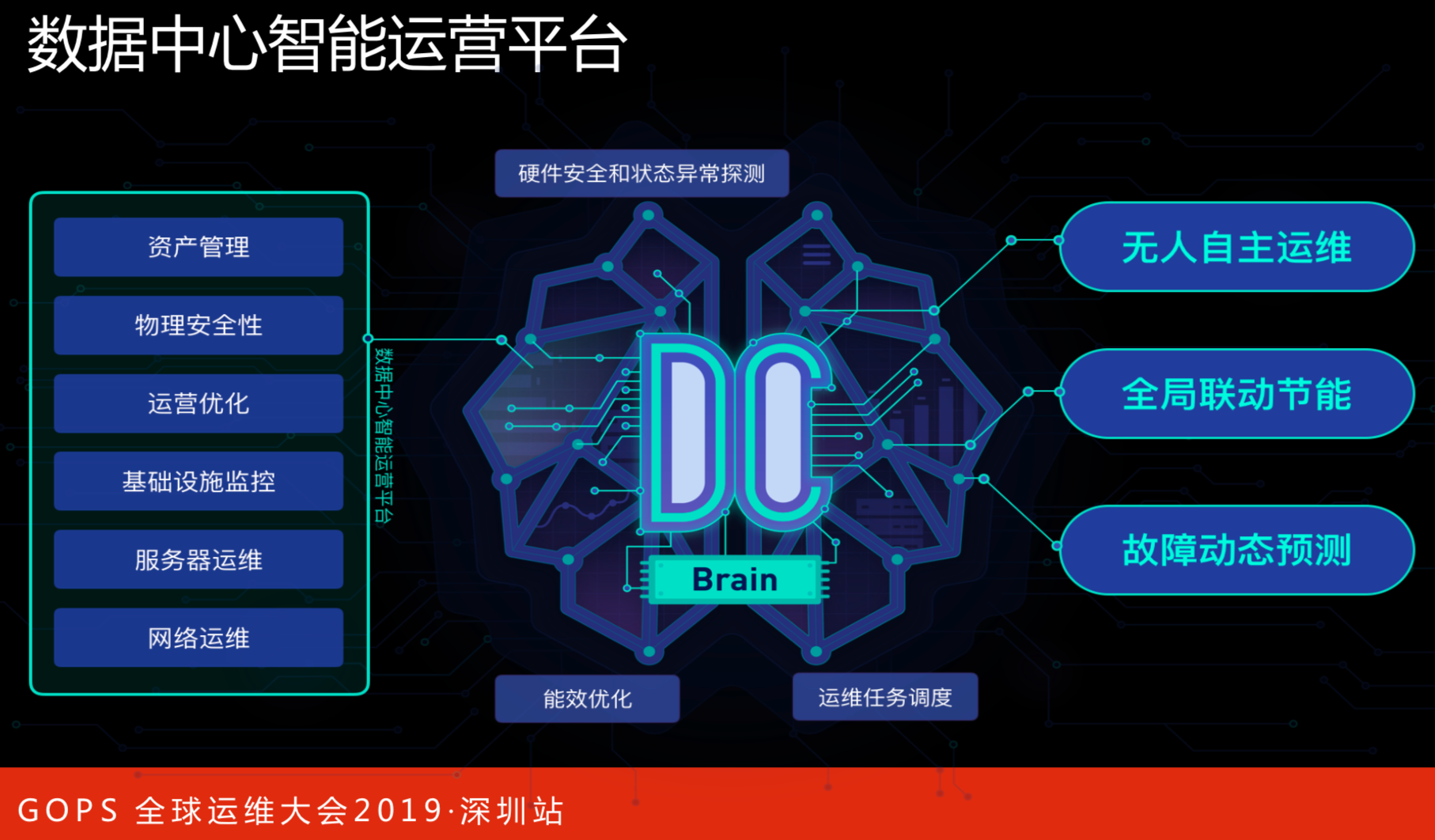
任何服务器和网络设备交付到数据中心以及OS上架之后,要进入到运营阶段,这是由数据中心智能平台承载的。在百万级服务器规模下,整体的运营优化会变得很严肃,服务器的增长和人员规模的增长,需要从全局上进行判断。还有服务器运维和网络运维,需要通过业务平台自动化解决,以平台固化下的整体流程,减少人为的操作,以此降低所有数据中心70%由人为造成的故障。
所要达成的目标:
- 无人自主运维的数据中心。无人自主不是不需要人,而是亚增长或不增长。如在大数据中心使用机器人来处理重复性的问题。
- 全局联动节能。在百万级服务器情况下,怎么让每台服务器消耗的能耗更少。还有风火水电,这是智能化的调,而不是人为的调。
- 故障动态预测。假设只有几万台服务器,换一块硬盘肯定是能修得过来的,等到了几百万台服务器的时候,哪里换了都不知道。怎么规划,怎样跟上层联动,下层的故障和上层的故障怎么隔离开来。
故障预测
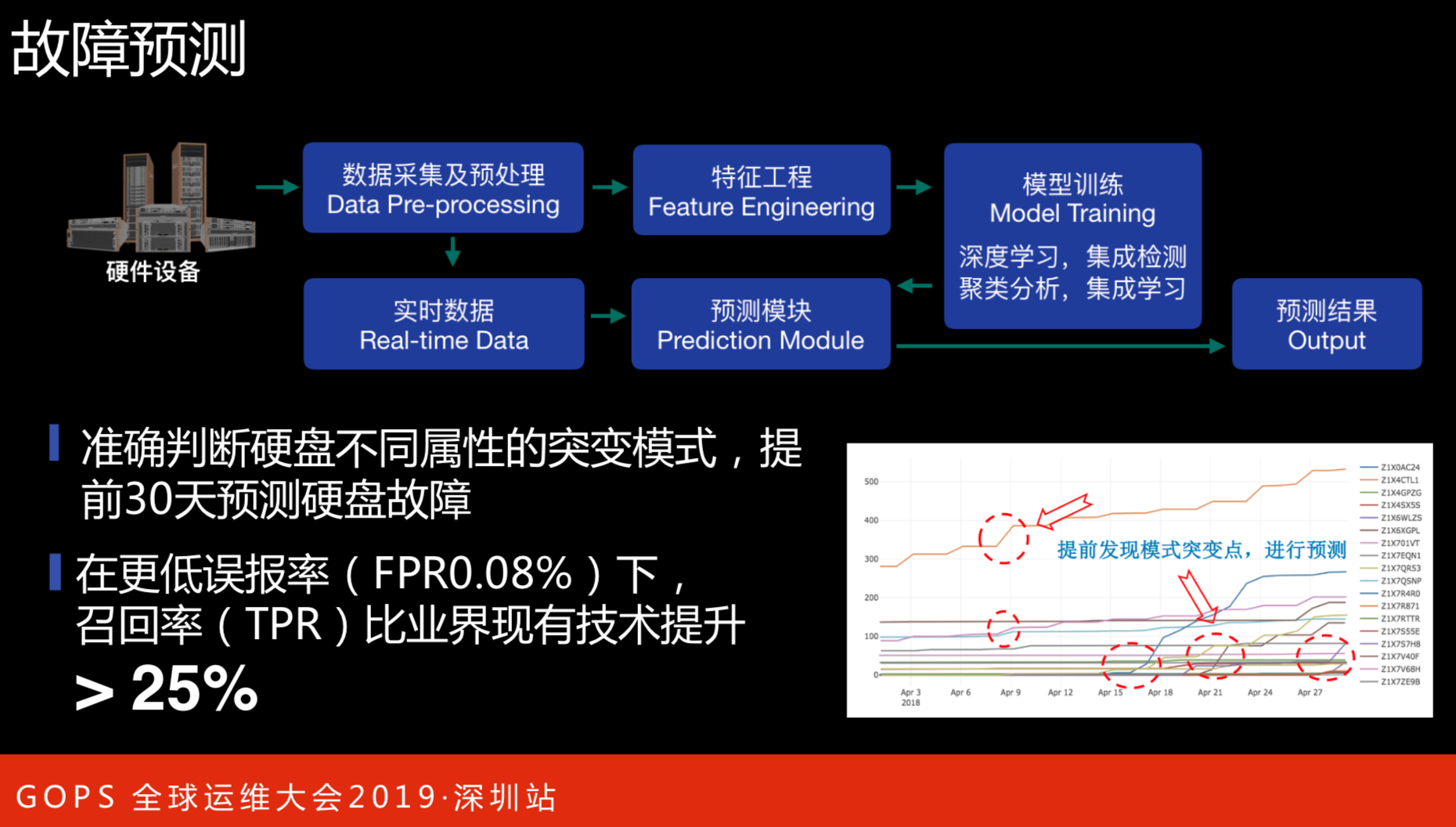
右下图是实际的情况。这里是通过引入了各种机器学习算法和采集机器上各维度的数据以及机器物理数据、各种应用数据和指标,大概在什么时候、什么时间点出现了拐点。会提前把这些机器清走,批量维修,避免出现问题后再做处理。
目前是提前30天预测硬盘故障,拿到的数据比业界现有技术提升达25%以上。
集群自动化运维平台
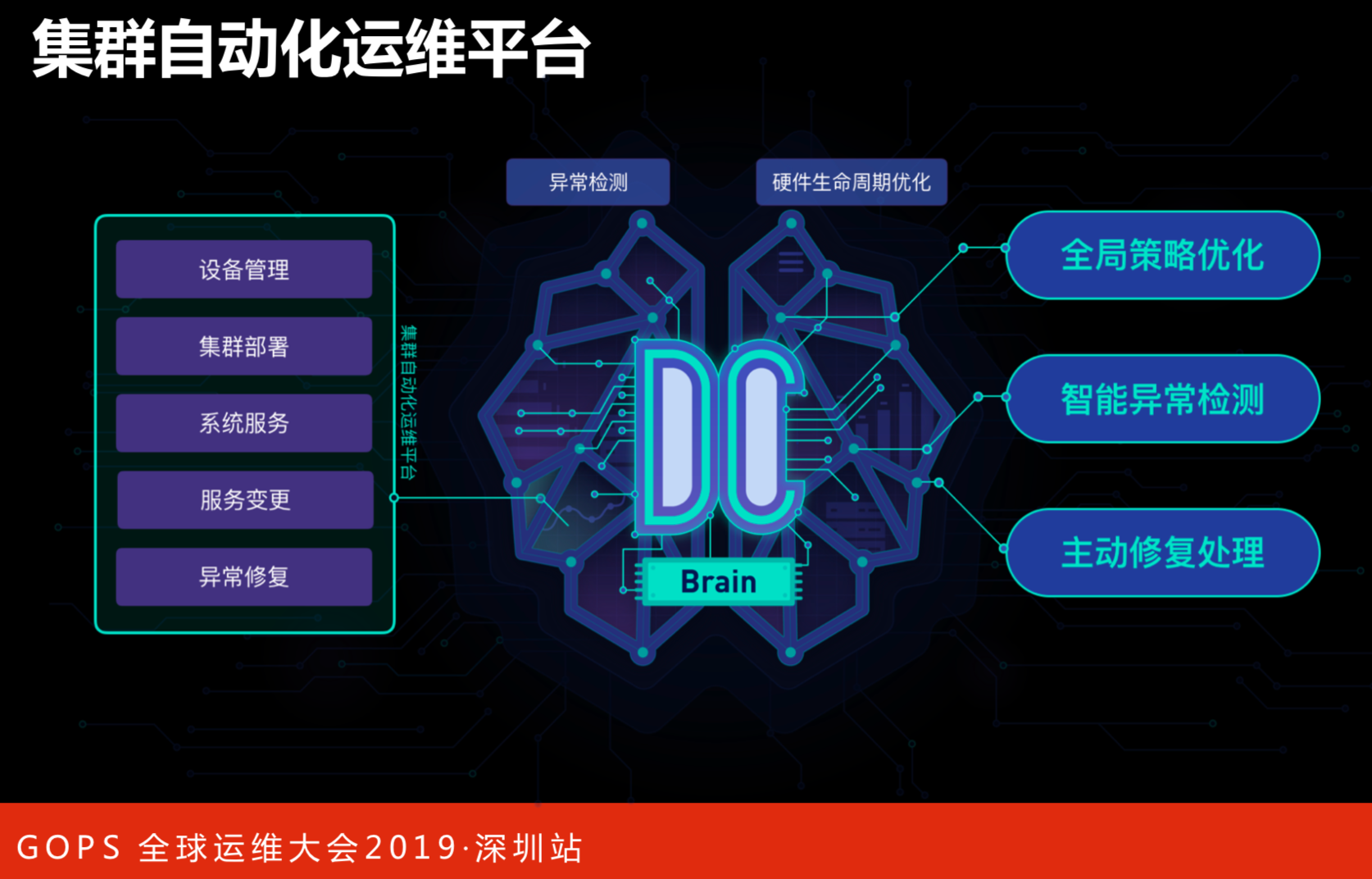
上面内容谈到任何业务都是分层来做的,数据中心面对更多的是对风和水电及人的层面提出效应。对于集群平台来说,先要把上层云产品和用户进行分层管理的能力做好。物理设备达到一定规模下,不发生故障是万万不可能的,但会不会影响用户?这是产品用户的能力。在发生故障之后,让用户无感知,是需要联动解决的,如集群部署、服务变更和异常修复,会承担这方面的职责。
右边是要达到的目标:
- 全局策略的优化;
- 智能异常检测,怎么发现集群本身的服务器出了哪些问题?是硬件问题,还是软件本身的问题?
- 主动修复处理。在发现问题的情况下,怎么降低对用户更低的影响,是主动修复还是被动处理?
智能修复
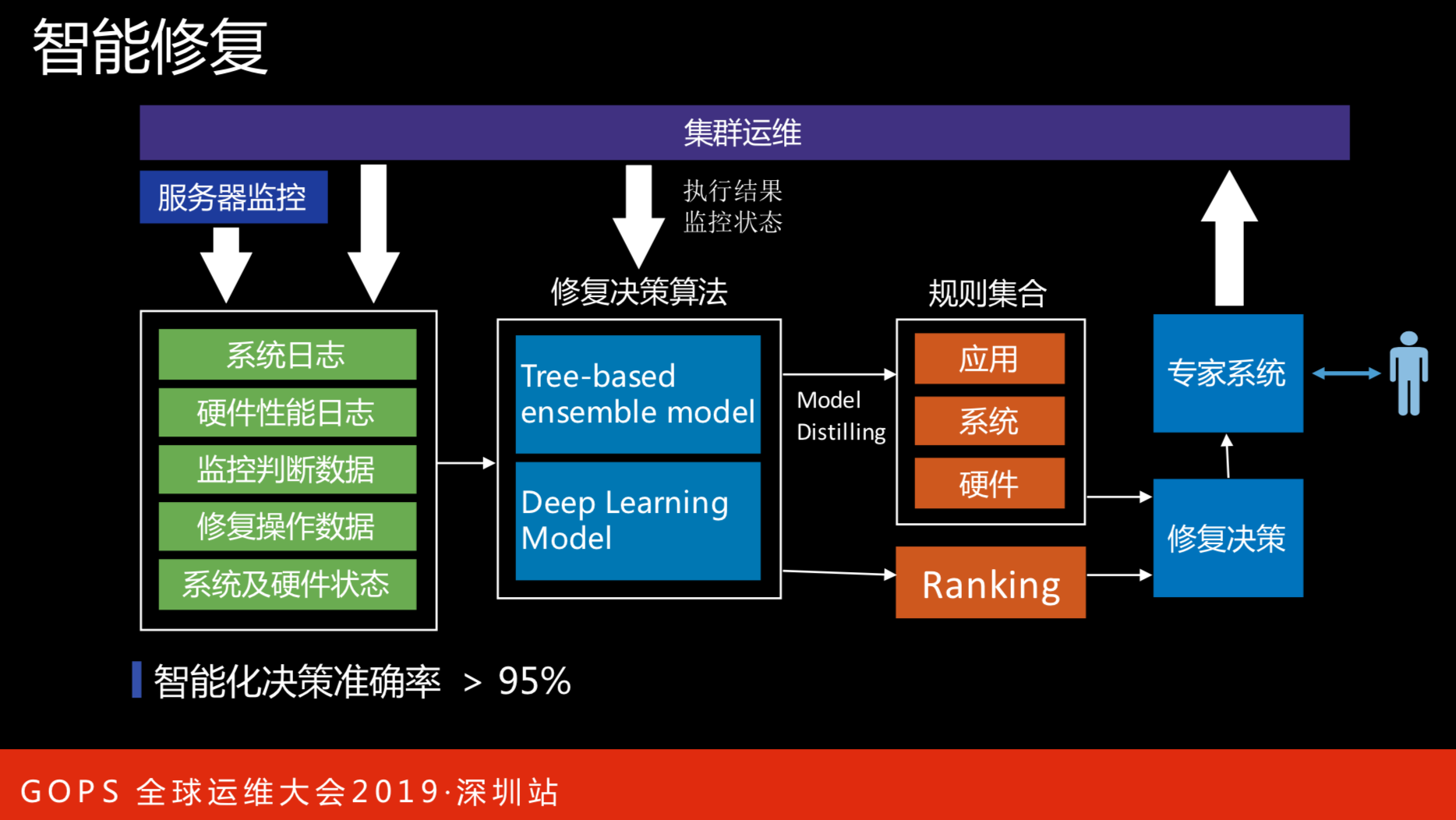
上图是智能修复的思路,有软硬件一体化的思想在里面,包括区块硬件数据,收集各个方面数据,通过机器学习算法来判断发生了什么情况。另一个是发生了故障之后,到底应该怎么解决,解决的方式是什么,用哪种方式是对用户影响更小又是能修复的。0-60分是人可以做的,但是60-80分是要智能化解决的,智能化所依赖的数据更全面,能得到全面的解决。还有修复策略,人会参与到验证的过程,包括整合到专家系统,更好的解决算法层面上的问题。
目前智能化决策准确率可达95%以上,这是经过实际案例验证过的,而且比人更合理。
4. 展望

哪些地方还可以用更加智能化来做一些提升呢?有下面三点展望:
- 智能供应链。上面提到智能预测需求做到了85%。补货策略是什么?不是这个月预测下个月拿多少货这么简单,每个地区供求是有差异性的。还有SLA预警。
- 智能数据中心运营。全局能耗优化,这是我们正在运行的项目,从单台到集群的调度。从全局上来看,我们是能算出这台机器有没有跑满,明天会跑到什么程度。如果机柜跑满之后,应该调哪个机柜,这是要从全面考虑的。还有全局工单调度,这是规模化带来的问题,几百万的服务器这么多的问题需要解决的情况下,谁解决了什么问题,就变得至关紧要了。如果这方面不合理的话,很多时候会导致问题成倍增长,让不合适的人处理不合适的事情,稳定性和效率就更差了。
- 智能集群运维。解决集群容量和灰度发布策略,任何功能上线是灰度发布的。
以上是数据中心基础设施平台总的目标,也是指引我们近几年发展方向。
