@gaoxiaoyunwei2017
2019-07-15T07:25:24.000000Z
字数 7235
阅读 1518
科学的故障管理
北哥
讲师简介
赵成
- 蘑菇街
本文主题是故障管理:鼓励改进而不是处罚错误。主要介绍蘑菇街在故障管理的经验,如何建立SLO体系和科学管理故障,怎么定性、定级和定责,以及蘑菇街与各大云厂商之间的稳定性体系建设实践。

科学的故障管理,鼓励改进还是处罚错误。这个议题是偏软性的话题,之所以设置这样的话题,是希望从另外一个维度看高稳定性和可用性上还能做什么。技术是我们的右腿往前走,还是需要有左腿辅助,两条腿走路才能更远。

首先做一个自我介绍,我叫赵成,来自蘑菇街,从我的工作经历来看比较简单分成两段。2015年之前是在华为,2015年到现在是在蘑菇街,负责蘑菇街平台技术团队。这十多年的工作经历绝大部分是做运维相关的事情,早期在华为是负责运营商的客户服务和运维,之后做互联网运维,再到后来跟团队实践。去年蘑菇街业务整体搬迁上云之后,现在很大的精力是在云计算,怎么在云上提升效率。


这是本文分享的议题部分:
- 第一部分要讲为什么做科学故障管理,既然要科学的管理,应该从哪个维度看,为什么做这个事情。
- 第二部分是来自我们的实践,既然讲科学就要有合理、规范的东西,确保这个机制落地,不仅仅是让大家知道怎么回事,而不知道怎么做。还有故障管理SLO,衡量稳定性要定SLO的标准。
- 第三部分会讲SLO跟故障管理怎么结合,希望定量的看故障,而不是靠感性和拍脑袋看故障应该怎么管理。

蘑菇街每日的日活和订单百万级别,80%的流量来自手机移动端。主要技术栈是java,线上应用过千。采用混合云的模式。


为什么要做“科学”故障管理?故障管理我平会交流得多一点,接触外部的行业多一些,如传统的运营商、金融、证券、制造业、互联网公司,大家普遍的痛点或者是感觉压力很大的事情就是故障管理。有两个点:
1.出现故障的时候,我们要承担着很大的压力,要尽快的恢复。
2.在故障处理过程当中或者是在复盘的时候,我们要承担很大的痛苦过程,我们会遇到很多推诿扯皮和相互甩锅的情况。甚至是我们在故障处理过程当中,处理得慢一点,有很多人指责你说为什么不处理得快一点,为什么不能赶紧恢复等等。
这种情况下,我们会发现这种故障管理的模式是没有很好的标准执行,大家都是靠感情和情绪的发泄来推动一些事情。


要很好的做这个事情,真正要体现无职责的文化,我们要怎么落地呢?之所以落不了地,是因为有很多的标准和机制不够细致的。在故障管理或者故障复盘的时候,经常纠结的问题、发生冲突、争执矛盾比较大的问题无非这三个:
1.问题到底严不严重。这个时候大家就会起争执,特别是技术部门和业务部门,大家认为损失2万块钱不是很大的金额,对于业务部门来说,损失2000块钱就是很大的事情。
2.责任到底由谁承担。我们换一个词来说,就是这个锅到底谁来背,我们会关注这个点。如果这个事情没有标准,绝大部分情况下,到最后定型故障是某个有话语权和决策权的人。之所以经常会说这个锅我背了,这里面很关键的点是没有标准,这个锅和这个责任承担的是心不服口也不服认为是被冤枉的。反过来看,还是缺少规范性的东西。
3.造成恶劣的影响是罚还是不罚。这是跟大家的切身利益相关的,动不动被交罚款、绩效完了、年度晋升没有了。往往这些问题处理不好,团队氛围就会非常的差,大家人浮于事,多做不如少做,尽量不做,一出问题大家就相互指责、相互推诿。
我们看国外比较好的案例,这是很现实的,2017年的时候,Gitlab磁盘故障,导致全球服务部可用。Gitlab公司在全国各地的,出了问题电话会议拉起来就处理。在UTB开了全球直播故障处理过程。之所以敢做这个事情,背后是有规范的或者是既定的事情,可以遵循着做的。我们总结的是“无职责”,我们也经常讲对事不对人。但是,现实情况下真正再去管理故障和故障复盘的时候,大家还是会偏情绪化些,特别是产生一些争执的时候。

故障复盘黄金三问:
- 我们应该怎么做,才能更快的恢复业务?
- 我们应该怎么做,才能避免再次出现类似问题?
- 我们有哪些好的经验可以总结提炼并固化?
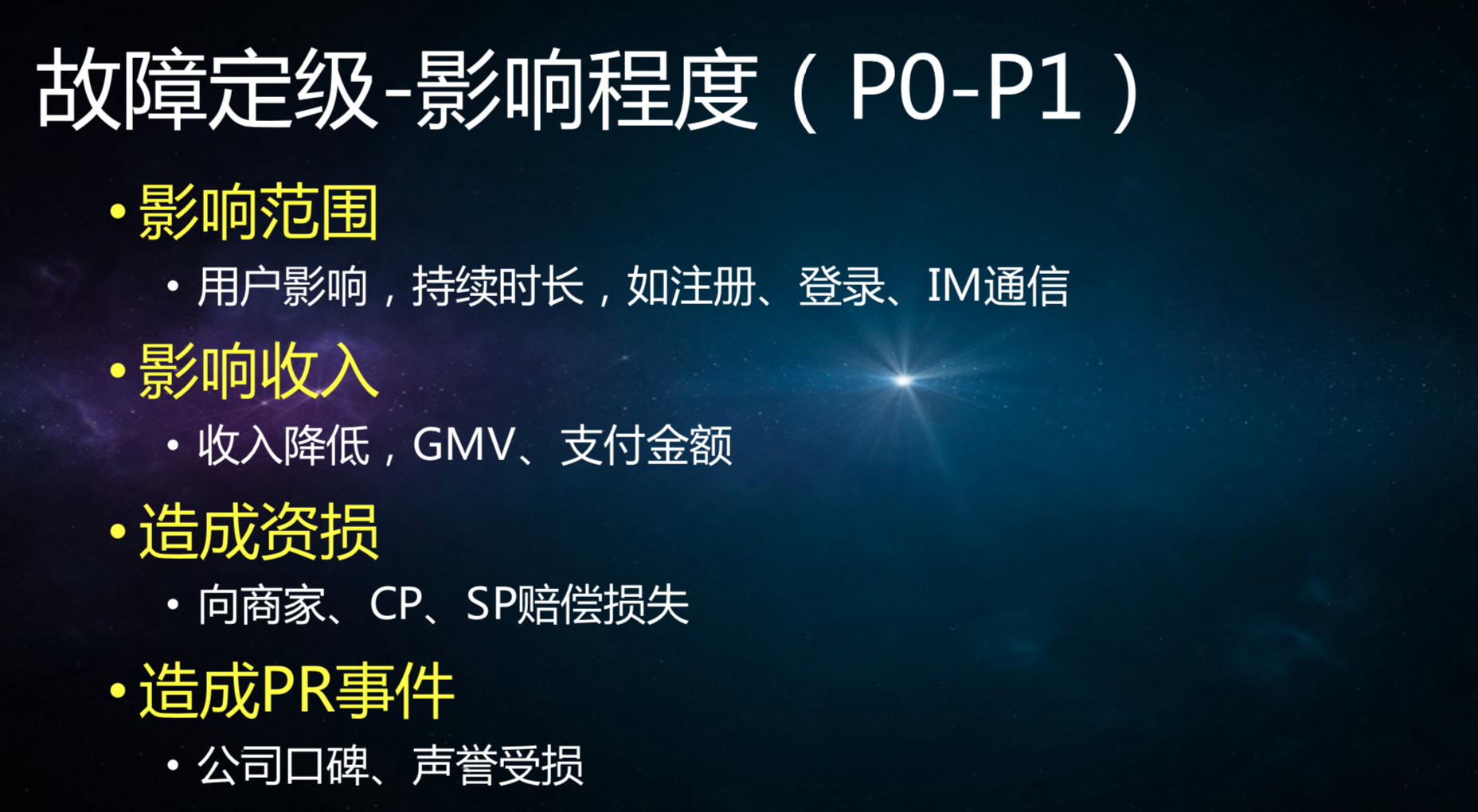
针对这样的问题我们应该怎么做,问题到底严不严重?严不严重要有定级的标准,每个团队都有一个标准,哪怕标准不是书面的,也会让你知道。定级P0-P4,我会分几个维度,以蘑菇街作为电商为例,可能会影响多少范围、多少用户等等。每个公司和团队来说,根据业务特点来看,游戏有游戏的维度、社交有社交的维度、外卖有外卖的维度、搜索有搜索的维护,大家对自己的业务来定维度。
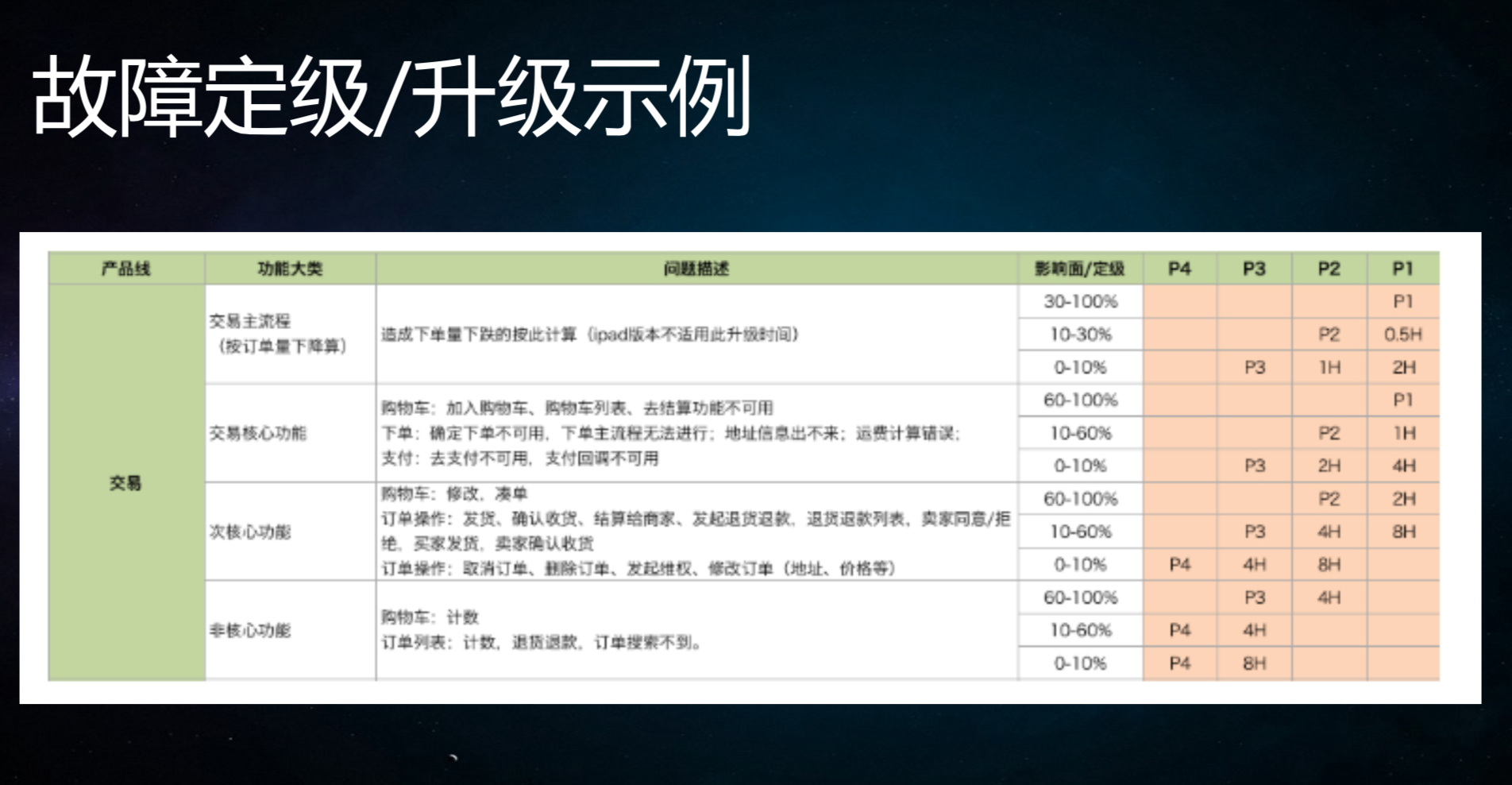
故障定级后要细化。举个例子,这个是定的交易线的标准,如果我们定级的话,经常会出现的问题是,把这几个维度定出来了,但是,每个维度定得不够细,在执行的时候还是落不了地,没有办法对照下去。用户影响多少是严重,多少是不严重,这个要有非常严格的定义。以我们的交易为例,假设用户影响超过10%,这个故障定义为P3,如果是超过20%,定义为P2,超过30%就是P1了。还有故障时长,如果影响10%的用户,超过3分钟之内,这个故障是P3,超过3分钟就是P2,这是比较细的定义。这里还要区分,我的交易会有很多的情况,对于电商来说,交易有很多的渠道,可能从购物车订购、分享订购、外部渠道订购,每个渠道订购的比例和订购的权重是不太一样的,这种情况下,要根据业务来一步步梳理出来,再定义不同权重的渠道以及影响的程度。
深入到业务把细节定下来。在定级别的时候,才会有统一的标准。我定的这个指标是跟业务相关的,如果是技术团队单方面定是没有意义的,可能业务是不认的。如果是定技术类的指标,是运维团队单方面定,可能开发团队是不认的。在定指标的时候,一定要多团队一起来制定标准,一起制定的标准才能遵守,单方面制定可能不会遵守的。

故障的定性,我把故障分类,上面列了很多还没有列完。分类的目的是为了做长周期的总结和提炼。上季度刚刚分析完故障情况,会发现代码BUG和代码逻辑导致的问题非常多,我们就要看为什么这么多,是因为新员工太多了技能没有达到就多了,还是说项目管理的周期是有问题的,单元测试和各种测试的手段是没有保障好,还是什么样的原因,还是有关键的员工调岗、离职,导致了什么样的问题。这样的问题是要通过长周期的故障分析来总结出来的,我们需要有一个分类来总结。同时也可以倒逼管理,比如技能不行就要增加培训提升技能,如果是因为测试有问题或者是代码质量有问题,就要关注软件工程的过程。

要解决责任到底谁来承担的问题。如果没有标准和原则,就是每个人拍拍脑袋定,说这个责任是你的那个责任是他的。我们一定要定义原则,它没有严格的标准,大家认可的就行,根据自己的业务特点来定。我们故障定责判定原则有:
- 高压线原则。每个公司都有高压线的条文,比如我在华为运营商的时候就有非常明显的高压线政策。白天业务忙时,坚决不允许动线上的网络设备,插网线、配网络策略是绝对不能干的,你只要干了,一定是罚得很狠的。还有做数据库管理和维护的时候,在白天绝对不允许对大表做一些建索引等的事情。这个原则很简单,只要谁碰了高压线就谁承担责任。
- 上下游原则。A接口变更了,有可能后面有B、C、D、E,它们是依赖于我的,这个时候A变更没有通知到其他的各个方面,就会出现扯皮说你没有跟我说或者是我说了你没有按照我的方案调整。我们定上下游,A是上游的变更方,后续有很多的依赖方的话,A作为主导方是有责任把B、C、D、E拉到一起变更,要配合我做什么,共同保证业务的稳定性。如果上游把这个事情做到位了,再出事情的话,是B就是B,是C就是C,上游是没有责任的。如果上游没有平衡清楚,上游是要承担责任的,这是上下游的关系。
- 健壮性的原则。举个最典型的例子,很多团队经常一台物理服务器挂了,这台物理服务器上部署比较核心的业务,比如数据库、缓存、核心的应用,服务器挂了,服务就挂了,业务就挂了。很多团队定责的时候就定给运维了,因为服务器没有维护好。这是很大的不合理性的,服务器两个点:一是服务器是不可控的,挂不挂不可控。二是能预见有一定的概率是会挂的。这种情况下,我们一定会要求在软件架构的时候,软件是能保证高可用,一定要面向失败的设计。如果再出现服务器挂了就业务挂了,责任一定不在运维。谁的服务没有挺住,就是谁承担责任。
- 分段判定原则。一个故障出现之后会出现衍生的故障,这种故障也会扯,说前面的故障不会,我后面的故障也不出,我就不承担。对于主故障来说,故障虽然出了,但是,很快就恢复了。但你的业务没有挺住,长时间是宕机的。我们就要分段来看,两个问题造成的影响是不一样的,前面归前面,后面归后面,分开定责,大家就不用相互扯了。
- Case By Case原则。不可能覆盖所有的问题,就有自由裁量的方式。
以上是我们经常定的原则,大家可以按照这种方式,根据自己的业务情况来定互相认可就行。

要不要处罚是大家比较关心和关注的问题。

看看图中的逻辑关系。前面我们定责,只是定责给了某个团队和某个人,定责的目的是为了让他重视这个事情,后续的改进措施是能够落地的。定责不意味着一定要处罚,处罚也不一定跟他的利益挂钩,利益就是钱。我们太多的团队对这个逻辑关系搞不清楚,一出故障就罚钱、晋升挂钩。我要表达的是定则不一定要处罚,不一定要罚钱,要放在长周期来看。
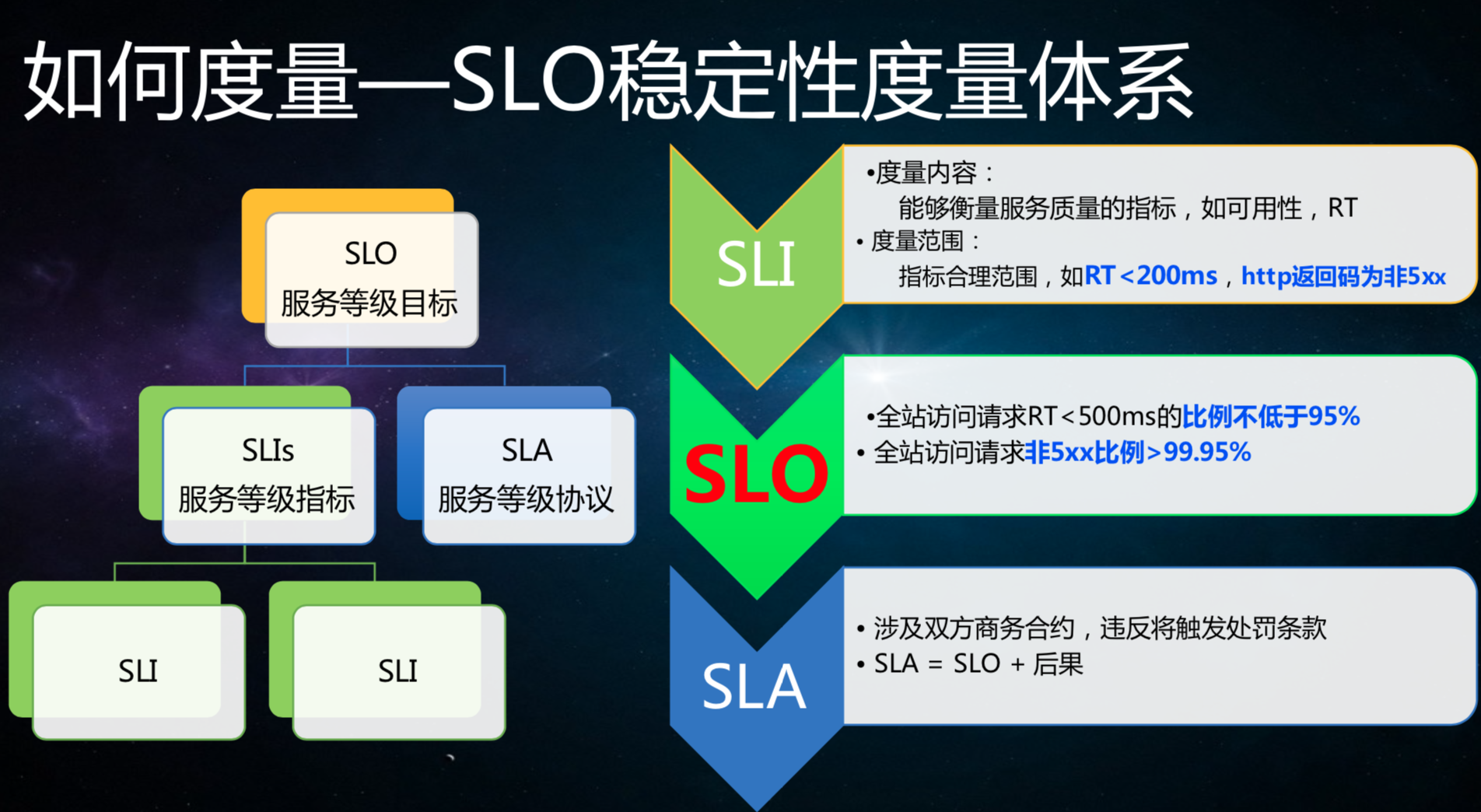
讲SLO的时候,首先是找SLI,就是找跟稳定性相关的指标。比如ATP请求,反馈码是200,就是成功的,是5××的就是失败的,失败的一定会影响稳定性的,这种指标会定义成SLI。还有超时太长,要找对稳定性有要求的指标。对稳定性没有这么大影响的指标,我们不会把它定义为SLI。SLO是什么呢?要更全局的看指标,一定的周期内,成功率是如何的,跟我们经常说到的三个9、四个9、五个9大致类似。

我们经常听到SLA的概念,从稳定性的角度来说用得不多,SLA常见的场景是用在商务条码上,定义方式跟SLO差不多,也要定义可用性的范围。如果大家对SLA不是那么清晰,可以看一下公有云的服务,每一个公有云服务都要求你同意它的SLA,如果不同意就不能用。公有云出故障之后,很多人要求赔偿,赔偿的标准是什么?就是按照SLA不会是SLO,SLA的定义稳定性区间比SLO宽泛。如果太严格的话,厂商一定是赔死的。有兴趣的同学可以去看一下各大公有云的SLA是怎么定的。

SLI的选择依据也是有套路可以遵循的叫VALET法则。
- Volume-容量。跟容量相关的指标,如系统容量、单机容量
- Availablity-可用性。服务是否正常?(2xx的返回码的请求比例)
- Latency-时延。响应是否足够快?(rt是否在规定范围内?任务执行时长是否合理?)
- Errors-错误。错误率有多少?(5xx占比)
- Tickets-人工介入。人工介入在大数据场景使用的多一些
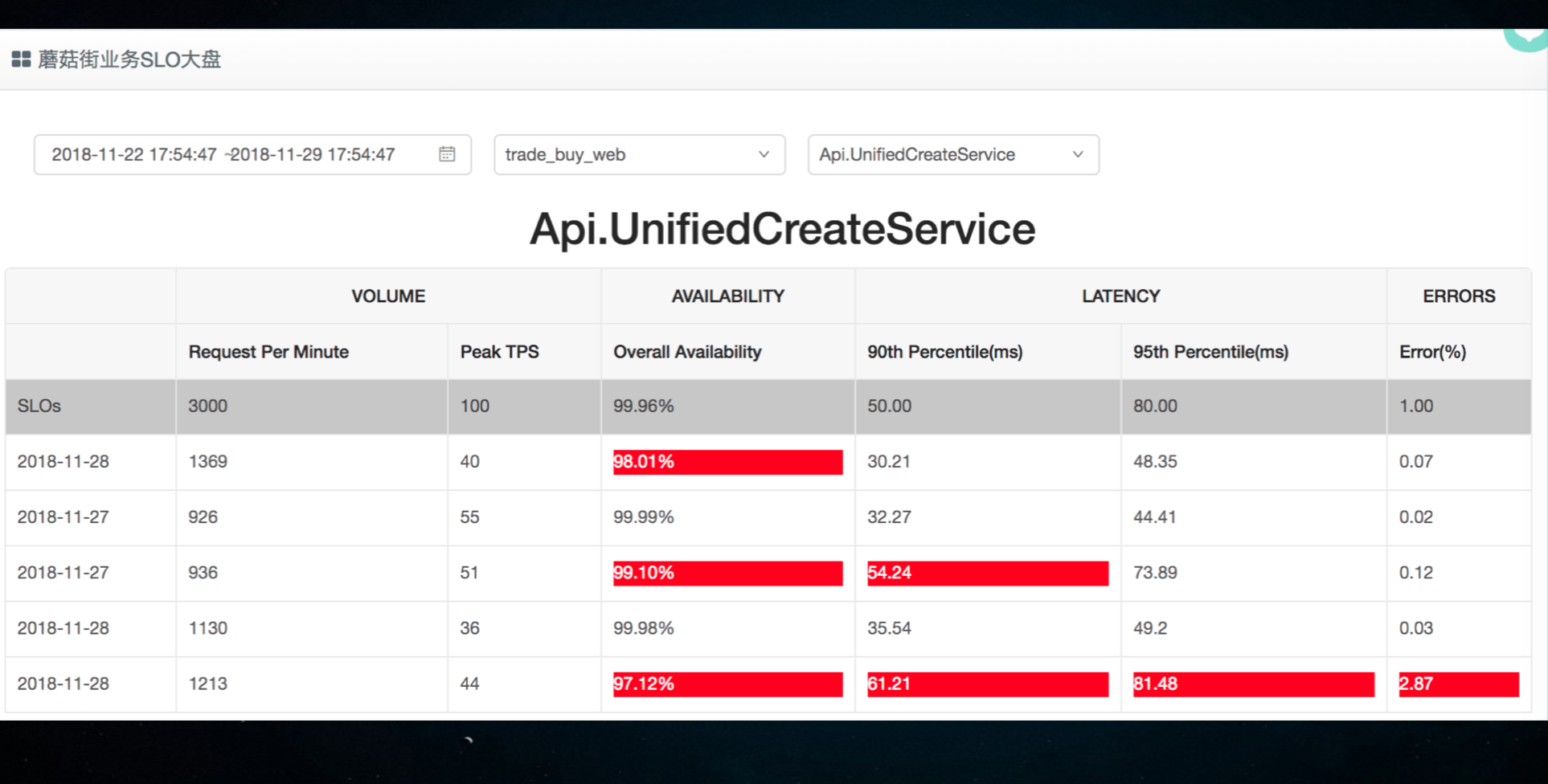
这是我们内部根据VALET法则定的“红绿大盘”,标识定义出哪些服务会达不到SLO的承诺。图中的指标在我们的监控系统里一般都会有的,但是,大多数是没有从SLO的角度思考。这种角度指标看着就很明显和明确我的系统有没有问题。SLO是可以拉长一个周期看的,这一次故障要不要处理呢?就要看SLO。在SLO周期没有影响SLO的承诺,就没有必要跟绩效挂钩。要是影响到了就跟绩效挂钩,之后再考虑其他的事情。
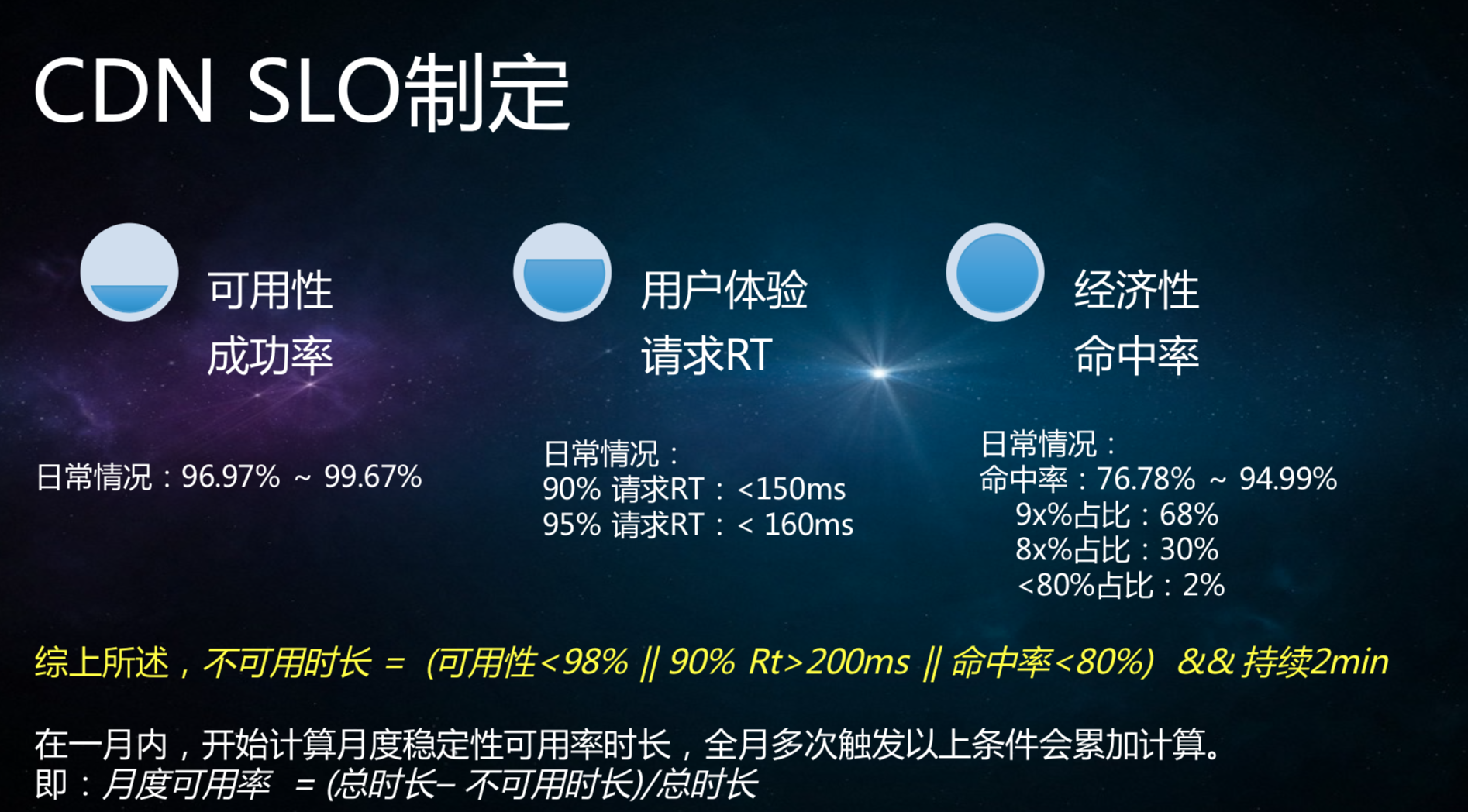
这个是我们想做但是没有推起来的,要跟很多外部厂商协作。我们跟第三方的CDN SLO,套路和上面的差不多。前一段时间遇到了一个问题,为什么定我跟云之间的SLO?前不久腾讯云上海光缆被挖断的故障,我们机房没有受到影响,但是视频业务受到了影响,基本上70%-80%的视频是无法观看的,包括主播和用户进不了房间,这个影响对于我们非常严重。我们就反馈了这个问题,从云厂商的监控来看,他们认为我的影响是在2-3%间,我要等着线路能够尽快恢复就不做切换动作。但是,从80的角度来说问题很严重了,希望尽快做切换的动作尽快恢复业务。当时大家在等和纠结,这里面很关键的点就是大家的标准是不一致的。从公有云的角度来说,检测只有5%,而我们这里是80%?因为公有云的检测是全国性的可能只有2-5%。但是,我们的用户绝大部分是聚集在江浙沪地区的,在上海出了问题之后,很多江浙沪的用户没有办法进去。对于用户来说,我的稳定性标准完全个性化,如果遵从云的稳定性标准,我们会发现这个东西就匹配不起来,很多动作就做不了了。我们要约束的话,还是希望能跟云厂商和第三方服务协商约定业务层面的SLO统一标准。
这个事情有一些难点,SLO是客户的标准,没有统一的标准,很容易造成的问题是假设我定了SLO,其他客户也要定SLO,我定的SLO可能是非常严格的,如果不小心把SLO公布到网上了,引起很多用户要按照这个标准提要求,这对于云厂商的压力是非常大的,这是一个阻力。另外,如果我们要做这个事情需要配备大量服务人员以此保障稳定性。通常情况下是保证全局的稳定性,没有必要保障每个人的稳定性。但是,定了SLO之后,就需要投入非常大的人力精力做维护,这对于云厂商的标准来说非常高,可能不太乐意做这个事情。从服务的角度能帮客户达成SLO可以收服务费和技术运营的服务费,个人觉得还是有合作的空间。目前来说还是因为标准不统一,而且实施起来的难度太大,没有办法很好的推下去。谷歌叫这种角色是CRE(用户稳定性工程师对用户的SLO负责)和SRE(服务稳定性工程师)。

SLO体系延伸:
- Error Buget-错误预算。每次故障之后是不是影响了错误预算。
- Policy-预算策略。错误预算多少、错误预算还剩多少,如果全部用完了,你的承诺和绩效就不达标。如果没有被消耗掉,就不用跟你的绩效挂钩。
- 宽松和收紧SLO。
- 基于SLO的告警。

要不要处罚呢?
我们内部观点是慎用处罚。一旦罚了之后,这是跟员工利益相关的,是属于人性,不是说人大度不大度,某个人缴几百上千的罚款一定有抵触程序,下次定责的时候一定是反抗的,赶紧把责任撇得清清楚楚,甚至会指责别人。另外有一些事情不能一刀切的,比如现在有一个紧急项目和产品上线,这个时候是需要开发同学的速度快,在做决策的时候,他应该是要意识到快质量一定会有问题的,可能会有一定的故障。不能说这个同学保证了产品上线,因为速度太快而产生故障把他处罚了,这样的话,他肯定是消极的不干事了。一定要看实际的场景和情况,再去看要不要罚。
处罚要有标准有理有据,要按照制定的机制和规则判定。
罚有几种情况,比如高压线、重复错误、低级错误,这些要罚。高压线是一定要罚;还有重复错误,第一次犯了无所谓,但一而再再而三就要跟绩效挂钩了;低级失误,把交换机的地址配错了,跟技术和管理没有关系,就警告一下,这种情况要罚的。大家要记住罚不一定是跟钱挂钩的,口头警示也是可以的。我们希望长周期、全局审视这个事情,不要出一次事情就打趴下了,这对于团队的伤害是非常大的。
有时候是要罚就罚管理者,管理者要承担更大的责任。阿里云和腾讯云出故障,公开出来的故障报告,其实被罚最狠的都是管理者。阿里P10往上是管理者,腾讯内部都是副总裁级别的人,真的出现大的问题的时候,管理者要承担最大的责任才对。说得直白一点,对员工还是要柔性一点,不能一刀切,要罚款、扣工资对于个人和团队的伤害是非常大的,要特别慎重,否则副作用比较大。
长周期、全局审视怎么做呢?我们是跟SLO挂钩的机制。

定了这么多的规则,谁来主持公道呢?我们专门设定了“法官”的角色,法官在我们内部是“技术支持”。这个经验是跟阿里学的,阿里之前有一个部门是全球技术运营中心,专门做科学管理的判定。法官就做三个事情:
1.要定级、定性、定责的条文定下来,来牵头开发、运维和测试,来把这些东西梳理和定下来,大家都认可就按照这个执行。
2.真出现问题之后要介入,要根据定级、定性、定责的规章,判断这个故障应该定给谁、是什么级别。
3.如何跟进。

法官角色的权限比较大的,它有几个特点:
- 中立,跟任何团队没有关系。
- 权威,是不容置疑的。在我们内部定下来,他判定这个故障是什么级别,责任定给谁,你是没有办法直接反驳或者是挑战的。如果有意见,跟你的主管反馈,主管认为有意见就跟总监反馈,总监认为这个东西还不合理就找CTO反馈。CTO认为这个事情是不合理的,可以再拿回来重新看。但是,不允许任何人找法官来改掉,这个是没有用的。从机制上,我们就保证这个角色一定是中立、有权威的,他定下来的事情是要执行的,因此这个角色是非常关键的。
- 普法宣传,要做一些案例的宣传。
- 规则制定
- 自由裁量
- 主持公道

如何辩证的看待故障?这个是公开的言论。
- 理解一个系统应该如何工作并不能使人成为专家,只能靠调查系统为何不能正常工作才行。
- 系统故障是常态,系统正常是特例。大家每天要面对不同的问题,换一个角度来说,对故障的包容度和态度更好,不要奢望于消除故障,这个不现实,但是有了故障之后要尽快的恢复,达到正常运营。
- 故障永远的表象,背后技术和管理问题才是本质。做故障管理,很大的诉求是为了改进,不是为了做处罚和把责任丢给谁,要找到背后的管理问题。
- 从技术角度考虑解决方案,尽量避免流程和制度约束。我们经常遇到的场景,因为代码的原因出了问题,在下次发布的时候让主管批,下次再出问题就让主管的主管批,加重流程。加重流程是解决不了问题的,有这样的经历会有这样的感同身受,只是增加流程并没有从根本上解决这个问题,一定要通过技术手段解决,要避免增加流程和制度来做事。
- 管理者应该多反思,这是我比较推崇的观念,管理者一定要多反思,不要只管处罚、处分和定责而不考虑自身的问题,这是非常大的问题,真的出现大故障,罚应该是罚最大的。

故障定级
P0-P4,影响范围、影响收入、资损、PR事件
故障定性
代码质量、变更操作、第三方、网络等
故障定责
高压线原则、上下游原则、健壮性原则、分段原则

总结一下,科学做故障管理的最大诉求和愿望是能够鼓励改进,而不是处罚错误,处罚一定会让大家畏首畏尾不敢做事情。一定要从故障找到完善的点,鼓励大家不断的改进和创新,而不是把焦点聚焦在处罚和背锅上。
