@gaoxiaoyunwei2017
2017-12-29T05:09:07.000000Z
字数 10401
阅读 1397
运行无间
阿里巴巴运维保障体系的一种最佳实践 --吴昌龙
黄晓轩
讲师 | 吴昌龙
编辑 | 黄晓轩
讲师简介
吴昌龙
阿里巴巴全球运行指挥中心,GOC (Global Operations Center)是保障阿里经济体的线上业务稳定运行的核心团队。
2014年硕士毕业,专注于云计算。
先后就职于微电影,Melotic(比特币),Rakuten(日本第一大电商)。2016年回国加入了阿里巴巴GOC,到现在一直专注于运维保障。
前言
阿里巴巴全球运行指挥中心,GOC (Global Operations Center)保障阿里经济体的业务稳定运行的核心团队。我们负责了整个阿里巴巴全局生产系统的稳定性。就像业界经常提到谷歌的SRE,我们相当于阿里巴巴的SRE。
今天我的分享分为四个部分:
- 稳定性现状及挑战
- 运维保障体系介绍
- 运行无间最佳实践
- 未来的发展及方向
一 稳定性现状及挑战
提到阿里巴巴,不得不说刚刚过去的双十一。在刚刚过去的双十一,每秒订单创建的峰值达到32.5万笔,每秒支付峰值达到25.6万笔。相比2016年的17.5万笔和12.5万笔提升近80%。相比去年的紧张状态,我们今年收到的普遍反馈是比较平稳。同时,做为阿里巴巴双十一备战的一员,双十一当天切身感受到,喝着茶就把今年的双十一给过了的感觉。并且业务上也再创新高,达到了1682亿,这是一个非常不容易的技术新高度。
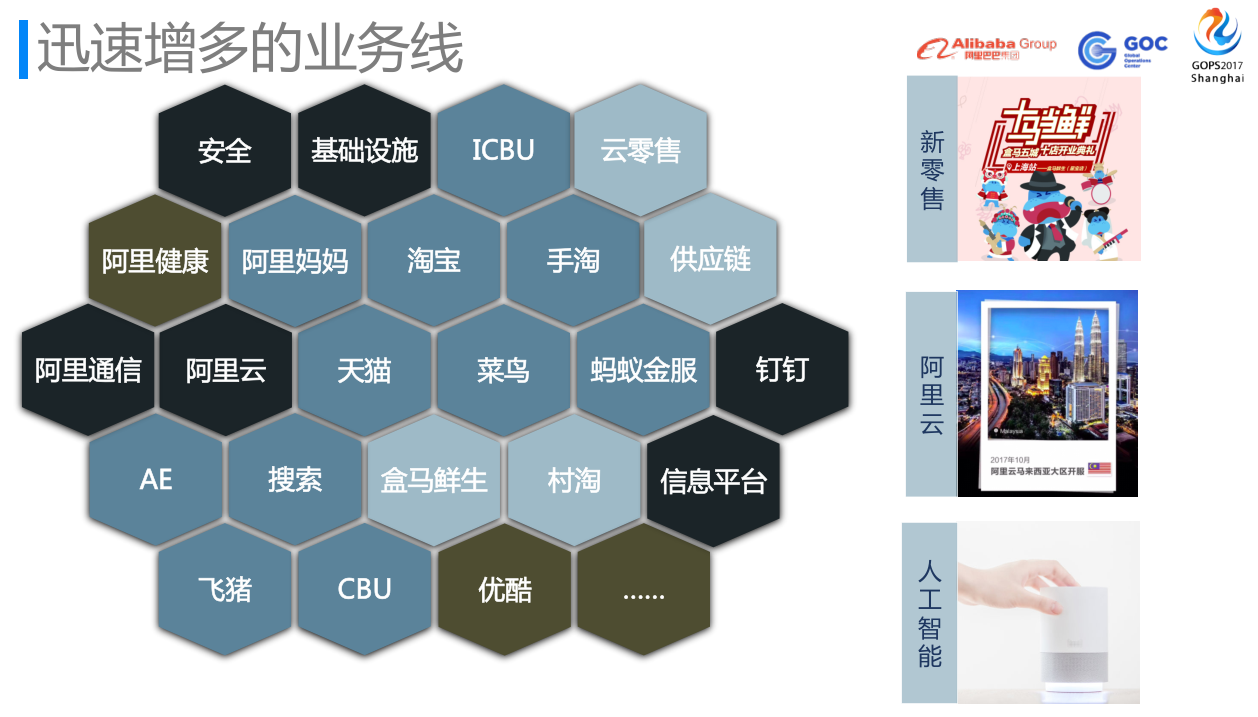
如上图所示,阿里巴巴业务迅速扩展,对于稳定性保障来说非常有挑战性。从基础架构层面来看:我们需要保障IDC,网络基础设施,安全,阿里云、阿里通信和钉钉;从业务层面来看,我们需要保障天猫、淘宝、手淘、蚂蚁金服、AE、飞猪、阿里妈妈、搜索;以及近期迅猛发展的新零售、大文娱业务,如盒马鲜生,村淘、云零售、优酷、阿里影业、阿里健康等。
今年9月28日,新零售盒马鲜生做了五城十店同开活动,一般来说开一家超市成本很高,而互联网的速度却是,可以一下子开起来,当然盒马鲜生不是就满足于一天可以开10个店的速度,未来是百家店、千家的店的速度。
10月份,阿里云马来西亚区开服。用不到1年时间,完成数据中心的新建。并且马来西亚数据中心,也刚好是马老师E-WTP(Electronic World Trade Platform,电子世界贸易平台)真实的落地,速度确实非常快。
11月份,在双十一活动上,有超过100万台天猫精灵智能音箱的售卖。人工智能业务的发展尚是如此迅猛,而我们也紧跟着业务在思考,人工智能算法的稳定性应该如何去衡量。
从各个维度看,阿里当前的业务面很广、层次很深,因此很难做统一的一致的运维保障方案。所以,问题就在于,在这样的情况下作为一个目标是要对接整个阿里经济体线上业务稳定性的一个团队来说,GOC应该如何去做。
昨天,魔泊云的副总裁Christ Chen在分享中提到,他在2001年经历了一个非常大的故障,原因是一个运维误操作把一个DB搞挂了,而整个Cisco线上会议的服务也就挂了。当时间滑到16年后,2017年2月28日B厂也因为30分钟无法通过WAP访问的故障导致被约谈;此外,AWS因一位工程师误操作,导致整个美东一大片区域AWS不可访问。
随着时间,业务复杂度一直在增加,但导致线上故障发生的原因往往没怎么变。因此,需要我们在万变之中找不变,找到运维保障的钥匙。
随着越来越多的新技术,新业务不断涌现,我想这会是一个新的阶段,这个阶段是一个非常不容易达到的技术广度,而在该技术广度上,无论是人工智能算法、还是大规模基础设施,稳定性运维保障都已经成为一个很难的课题。
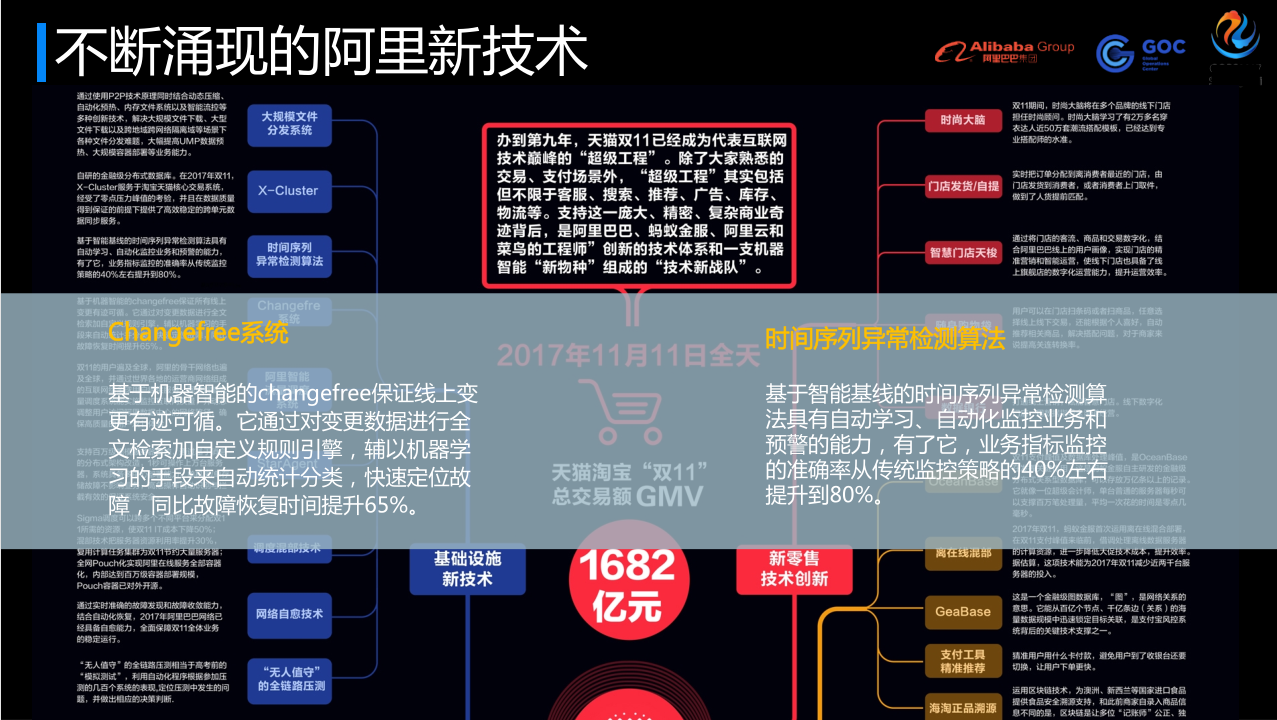
当双11办到了第9年的今天,天猫双十一已经成为了互联网的一个超级工程,“超级工程”是一个新的概念。除了大家熟悉的下单、支付这样的一些场景外,这个超级工程里面还包含了很多新技术,包括客服、搜索,推荐,广告,库存,物流等等。而这些是所有阿里工程师每天不断创新突破的力量,这是非常不容易的技术速度。
这里面为大家介绍2个点,正好是我们团队做的。一个是Changefree系统,基于机器智能的changefree保证线上变更有迹可循。它通过对变更数据进行全文检索加自定义规则引擎,辅以机器学习的手段来自动统计分类,快速定位故障。这些是官方的表述,但是同比故障的恢复时间我们能够检验得出来,可以提升65%,这是个非常难得的事情。另一个是时间序列的异常检测算法,基于智能基线的时间序列异常检测算法具有自动学习、自动化监控业务和预警的能力,有了它,业务指标监控的准确率从传统监控策略的40%左右提升到80%。这2个光荣的上了我们新技术的榜,却是是很难的点。
讲完了现状和挑战之后,我想带大家一起回过头思考一下。当我们站在这样的一个技术高度、广度以及速度的时候,线上业务的稳定性、连续性以及运维保障方案有没有不同。当出现故障的时候,或者频繁出现故障的时候,如何保障用户的使用不受影响或者受影响的程度可以降到最低。
二 运维保障体系介绍
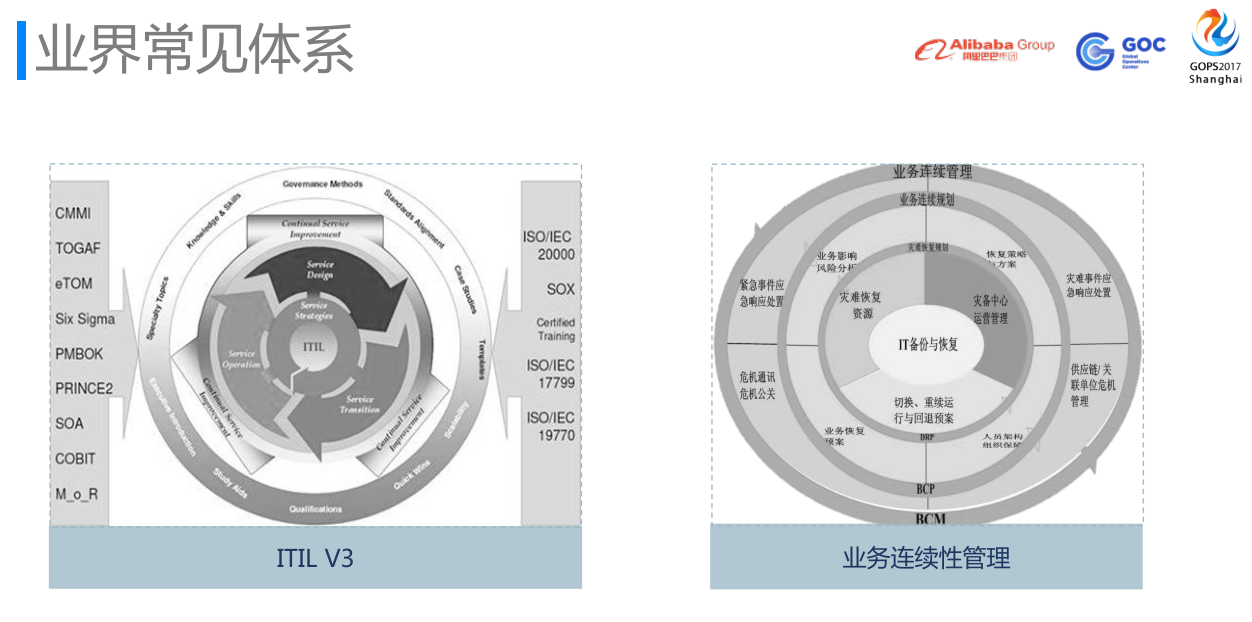
我们阿里巴巴的运维保障体系也不是凭空起高楼,也是慢慢迭代出来的,主要学习这两个体系:一个是ITIL ,一个是业务连续性管理,也就是BCM,ISO 22301。我们的运维保障体系,也是脱胎于此。
ITIL侧重于流程和服务,能很好地建立服务目录,但在深度使用过程发现略冗长,不太适合互联网的精益迭代。GOC最初刚成立的时候,主要是用ITIL,但是随着业务稳定性诉求的不断的更新以及优化和不断增长的时候,需要自建的诉求就自然而然来了。总的来说,我们希望流程可以再轻便、高效一点,服务之间不再是孤岛,希望服务之间是为了同一个目标,比如:故障快速恢复。通过这样一个简单的目标,我们能够去把服务/产品打通,打透。
业务连续性管理,提到业务连续性管理,往往会同灾难恢复一起讲,英文称为BC&DR(Business Continuity and Disaster Recovery)。一般提到BCM,经常会举2013年东南亚海啸的案例,海啸发生后,某某银行受到了严重影响,从结果看,一周内能否恢复营业,若恢复,说明基本不受影响;但如果1个月才能恢复营业,说明他很有可能需要长达3-5个月的时间来停业整顿;如果2个月还不能恢复,那这个银行距离倒闭的时间就不远了。传统行业对于业务连续性的诉求,在互联网行业,往往更苛刻,可能10到15分钟,这个业务就很难了。BCM有一个特征,其实它原先画了很多,我们理解BCM是设计一套针对不频发,但确是大灾难的场景下,如何保证业务的连续性。其实对于互联网行业来说,需求多,变更快,故障是非常频繁的事情,影响面对于业务来说也很大,所以我们希望在BCM里面,加入一些持续优化的因素,而这个ITIL里面是有的。我们把这两个东西结合一起。
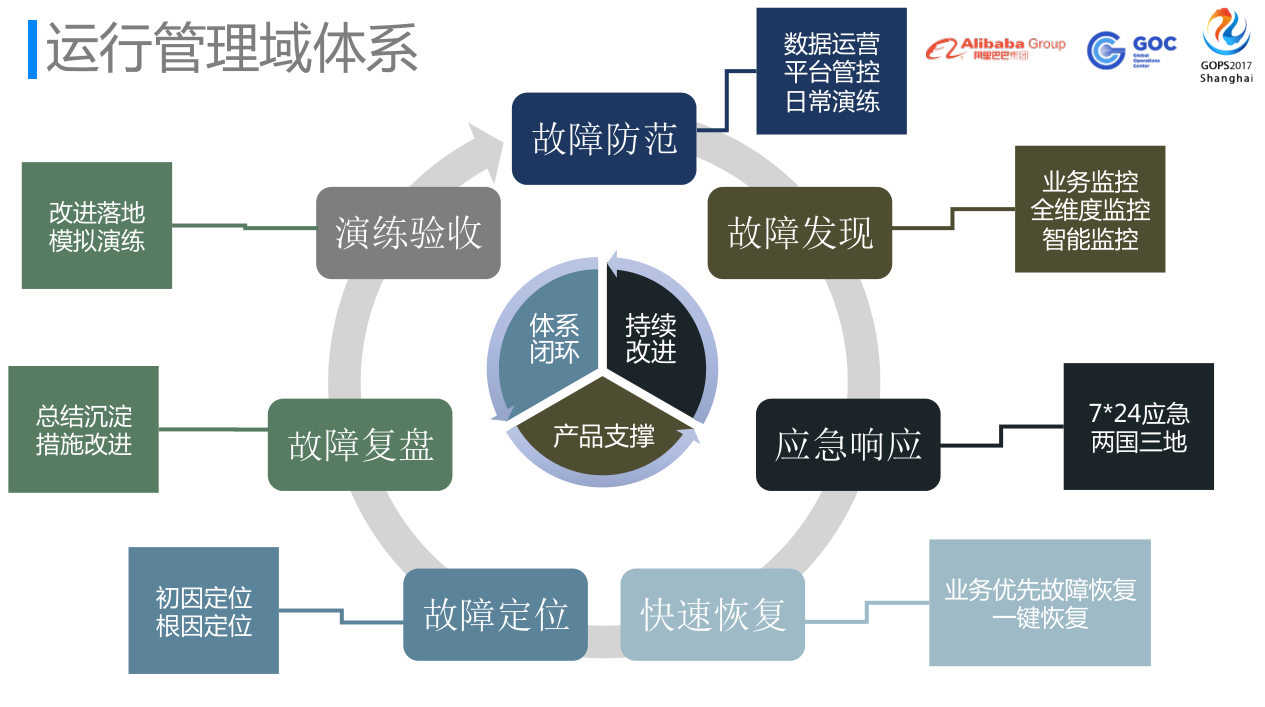
阿里巴巴的运维保障体系,说白了很简单。这是精减版的草图,简单来说就是全生命周期围绕故障,形成体系闭环,持续改进以及快速的产品支撑落地。
- 故障防范。
当公司没开的时候,比如我们明天准备开淘宝了,这时我们可以很轻松地坐在一起,把规范定出来,故障防范的约束定出来。但是很多时候业务起来了,我们还没有及时介入,所以说故障的闭环很可能是业务的已经在做或者稳定性做的不太好的时候,GOC再切入进去。
在故障防范的阶段,GOC重点关注3个点:一个是数据运营;一个是平台管控;一个是日常演练。
首先,看看数据运营。在阿里经济体所有业务中,无论是相似业务还是完全不同业务的稳定性情况,可以简单比较下各个BU稳定性的情况,可以给出一份稳定性建议报告。当具体到某个BU、某条业务线的时候,我们可以具体分析他们的稳定性情况:与去年同比故障数有无增减;故障中多少比例是监控发现的,还是等用户打爆投诉电话后,才慢慢上来处理的;有多少比例的故障是人为失误、变更等形式导致的。
此外,是平台管控。核心产品是ChangeFree,他是阿里巴巴做变更管控非常好的平台,基于数据运营。现在很多故障刚刚发生的时候,变更人还不知道什么情况的时候,几分钟时间就已经发生过一个故障,但通过快速回滚恢复掉了。这中间有两个点,第一个点,看变更能否发到线上,期间会有一系列的管控,通过很严格的变更红线来衡量线上变更。第二个点,看变更到线上后是否符合预期,这是非常关键的点。符合预期不是说是否符合变更人的预期,而是指他是否符合不影响线上业务的预期,这是客户最在乎的,也是我们GOC最关注的。比如某团队做了一个非核心的边缘变更,但这个变更通过几层链路的传导,可能会传到电商交易的核心链路,那么整个交易就会被阻塞掉,阿里发生过这样的案例。当出现这种情况,你会发现,没有很好的平台支撑,你是很难找到引发这个故障的具体变更。因为从出问题的点往上回溯的时候往往是最难的,GOC通过大量实际案例,以及算法同学们的努力,我们现在能够解决一些这样的问题。
日常演练我们提日常,经常会有一个反问句,这个也是我在SRE读到的,你到底是愿意圣诞节晚上和老婆、孩子看电视享受节日的时候,突然故障发生了,还是愿意在演练的时候,所有人都在一起,大家来模拟故障,故障一发生大家快速处理,我会选后者。演练很重要,而且需要频繁做,要把他当作日常的事情来做。阿里巴巴这边我们演练就是老板非常看中这个事情。
我们2015年发生过一个527事件,影响特别不好,我们后来通过技术来避免这个问题,叫异地多活和一键切换。但是这个工具是否每时每刻都是有效的,毕竟它的依赖很多,而且它所依赖的东西会因为一些需求的变化而更新。后来,大老板给我们出了一个难题,让准备一个核按钮,随时都可以按,按一下一个机房就挂了,这是人为造成的而且事先不告诉你,这把我们GOC训练地很警惕。我们有值班体系,7*24小时值班,这样大老板早上一时兴起就按一下,一个机房挂了,GOC赶紧一键切换掉,然后业务恢复。期间也就1分钟、2分钟。若是交易挂了的话,1分钟是几百万的损失,其实影响面是很大的,但是我们觉得在业务低峰期搞搞演练,让大家一直保持对生产环境的警惕,是很有必要的。这个项目的代号叫虎虎虎。
- 故障发现
这个部分我也提3点:一个是业务监控。我相信不同团队、不同公司会有不同的理解。甚至东西方也有很大的区别,在国外主要用service level agreement,在阿里巴巴主要从用户视角来看业务,比如业务是否不可用,用户体验是否变差。如果有,那我们就划出4级来,然后告诉你这是风险非常高的级别,那么你必须要做好限流,必须做好降级,必须做好容灾。这样做,逼着你时刻在关键的功能点或接口上做好日志记录或者做好链路信息上报,从而形成业务日志监控。业务监控是监控的一种,但核心跟用户体验息息相关的故障等级定义相关联。这在阿里巴巴特别有用。例如交易下跌10%,这是2010年定的,已经七年了,一旦发生交易下跌10%,系统稳定性偏低的团队会比较紧张,怕是自己导致的,尽快响应并恢复,否则时间久了,就会发酵成更大的问题。大家都认同业务监控的重要性,也是我们能够集中力量去恢复很多复杂故障的一个很好的点。
全维度监控,就是说从各个维度上,比如IDC、网络、应用、系统和业务层面。业务层面我们也分,不是所有的接口都是很致命的接口,有时候我们也会降级。比如双十一时,会把购物车里面否已收货的状态接口降级掉,你就暂时看不了,但是不会影响你下单和支付。
最后智能监控,核心是为了解决报警不准的问题,一般来说,新上的业务,该业务点很关键,但是量不大且经常抖动,这时候,设置告警阈值会很痛苦。GOC主要通过智能监控来解决这个问题,通过算法计算基线,然后自动预测异常,而报警可以只设一个相对于预测基线的水位有没有下跌即可,非常方便,而且准确。这可以帮我们省掉很多问题,因为业务根据其特性在某些情况下往往会有较大的波动,比如10点钟聚划算有活动,肯定会往上涨,中午大家都在吃饭的时候,支付宝肯定会涨,淘宝会跌,周末的量比周一到周五的量大。这种东西你配一个死的阈值很难搞定,智能监控是比较好的,我们这边使用范围很广。
3. 应急响应
为什么会有这个智能,GOC做了非常有挑战的事情,做7*24小时应急。一个互联网公司不该设这样一个传统的职位。大家小区里面门卫是7*24小时的,我们就相当于是阿里巴巴这些生产系统门卫。真的是7*24小时去支持我们线上的故障。当然解决这个问题,我们也想了一个办法,其实这个也是我们从一些前辈的公司学到的,谷歌公司他们也是这么做的。他们分公司特别多,总是可以找人换过来,google的SRE是可以实现日出而作,日落而息,总是有另外一个时区的同事能够接替上。我们现在还不够,大概做到了3个地方,硅谷、北京和杭州。未来我们也希望能够在中东或者欧洲建立起来这样一个团队。能够真正让GOC也实现日出而作、日落而息的7*24小时。
4. 快速恢复
快速恢复是最重要的事情。我们前面做的不管是故障发现还是应急响应,最终的目标是快速恢复。快速恢复有一个误区,不是说故障恢复了你就恢复了,你故障可以不恢复,你业务先恢复就好了。这里面有一个思路,就是隔离。隔掉就好了,我不受影响,我的冗余能撑住现在的量,让用户不再受影响。那个故障,该哪个团队去查原因去搞就行了。还有一个是一键恢复。例如异地多活,因为平时又不能切,切一下那十几秒中还是会有交易影响的,必须等到真的发现单机房出现问题的时候,大量报警涌出来时,你果断切掉就好了。所以这个点,我们现在也不能做到完全的智能或者故障自愈的方式,还是通过一键的方式来搞定的,当然非常方便,点一下就好了。
5. 故障定位
这里面有两个点,一个是初因定位,一个是根因定位,这两个一直在打架。
初因定位对于我们来讲,最浅层的话故障就两种可能,要么是容量不够,要么就是有变更。这里面的变更是指非常广义的变更,我们对于变更的定义也是集团通行的,叫做生产环境上的一切操作都属于变更。包括你从跳板机登陆生产机的操作,也属于变更。这是很严格的,很多开发不理解,有的开发会说,发布才算变更,像配置,打一个日志,杀个进程那就是个日常操作为什么是变更,会有这样的争论。我们这边要求一定是这子的,我们发生过这样的案例。以前比较早的时期,我们很厉害的一个B大师,有一次有一个很复杂的故障,影响面还挺大的,他就在那查了好久,最后才发现是有一个同学在线上改了一台机器GVM的参数,直接是在上面改的,那个参数有了问题后,就会连锁反应,会影响到上下游的很多东西,用户会一直交易上会有问题。这东西根本没办法查,你查的时候总是会去从可能性方面去查,从网络、上下游、链路、哪有发布。查了好几个小时发现是这个东西的时候,这种事情找到它是很高兴的,但找到之后我们的反思总结出来东西,其实可能就是红线的事情。生产环境要敬畏生产,严格把控。最近也有人在犯,发生变更的时候,他违规操作出了故障。他说要凌晨1点半变更,然后夜深人静时候,他就1点20选择了变更,提前了10分钟。这里面也有一个点,就是我们能不能更智能判断他到底是在故障应急,还是违反了他自己声称的时间窗口的方式去做,但是他做了,最后我们给他的结果也是不太好,因为确实违反了红线。这里核心的道理就是生产环境你要敬畏,你说了什么时候做就什么时候做,毕竟我们不是消费者,我们是拿着工资的开发或运维同学,我们要对公司生产经营活动负责。
根因就是指上下游链路。
6. 故障复盘
故障复盘也有是两个,总结沉淀和措施改进。这个ITIL里面也有,我们这里面其实基本上是一样的,组织一个故障约会,我们去把导致这个故障的前因后果按照时间序列列出来,再有就是列好所有故障改进的Action。故障改进,也是我们很看重的事情。我们会看故障改进的及时完成率,而不是看他的完成率。因为当我们发生了一个故障,出现了改进措施的时候,这个改进措施会影响故障的再次发生,如果你及时的把他改掉了,那么这个故障再发生的概率就会降低很多。如果你不改掉,第二天很有可能还会再发生这个故障。这个风险我们觉得是非常严格的事,所以我们对于每一个同学的改进措施,也是非常严格非常高要求的去运营这个事情。我们也欣喜的可以看到,阿里云有很多团队,每次故障之后他们能够及时核对和检查改进措施是否已完成。我们尽可能把线上的风险发现了,就把它消灭掉。把真正的潜在的风险留出足够的buffer。
7. 演练验收
演练验收有一个悖论,有时会问开发,优化措施完成没,每次都说落地了没问题了,然后故障又以同样的原因再次发生了,然后解释说当时搞改进的时候没有考虑到有这个case,这是意外情况,但是之前故障的那个场景考虑到了,不会再发生了。出现这样的情况,就应该尝试去推动演练验收,跟进具体改进措施的结果是不是能达到我们描述的预期。阿里巴巴演练做了很多,比如说我们做发布的时候会有灰度,演练的时候在线上隔离环境中造出来一套和线上类似环境,但其实走的是演练的量而不是正常用户的量,然后灰度时候我们一部分会引入一些特定用户量进来。这里核心的点是,要具备隔离环境的能力,要具备演练的机制,真真切切的把线上的Action能够尽快落地到演练里面,然后把他日常化起来。我们只有日常演练,反复演练,才能故障发生时心里有底。其实演练做法很简单,比如接口有做限流,那我给接口再多打一点量;比如说的接口健壮性没有问题,那我就给你摘掉一个或者摘掉下游的一个DB什么的。通过阿里巴巴的演练系统,可以很快地落地,并且形成闭环,对于业务团队是非常宝贵的经验。
三 运行无间最佳实践
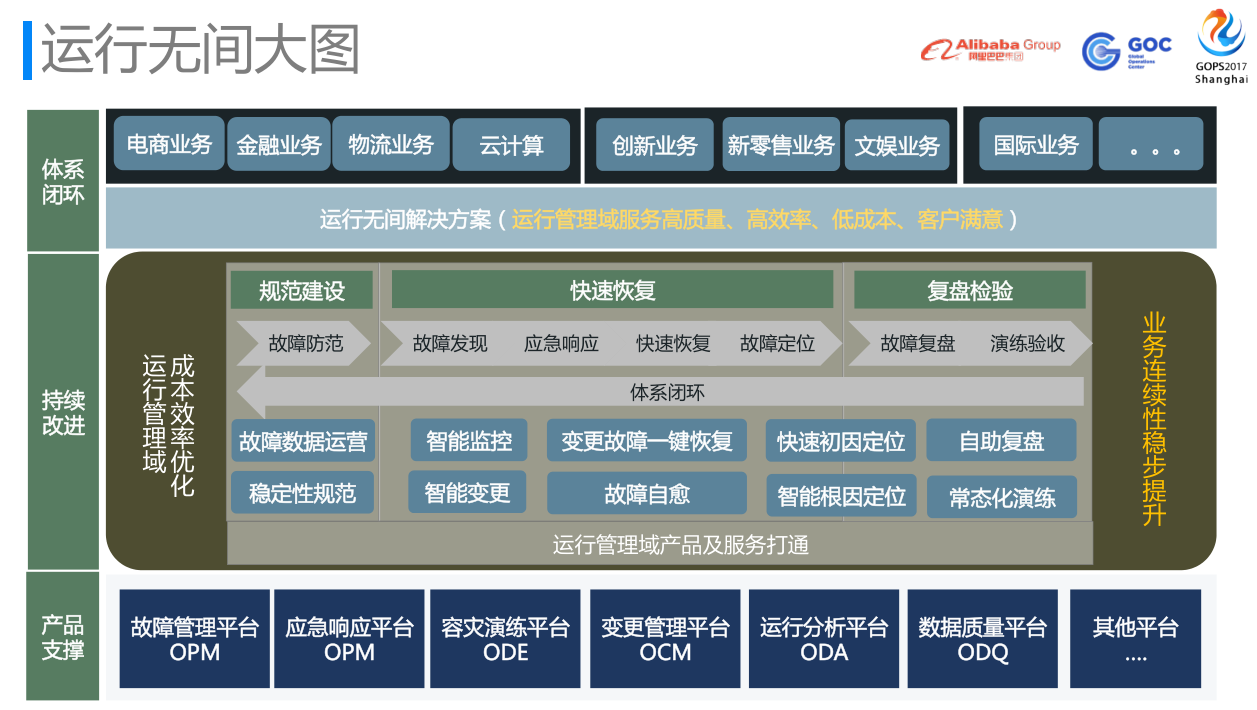
基于运维保障体系,我们摸索除了一个最佳实践。这个图还是比较复杂,我简单的讲一下,它是分三层。但其中最核心的,最重要的是产品支撑。不管我们用任何体系也好,用BCM,还是用ITIL,其核心点在于我们要有一套趁手的能够管理好生产环境的平台。我们的平台主要有,故障管理平台(OPM),应急响应平台(OPM),容灾演练平台(ODE),变更管理平台(OCM),运行分析平台(ODA),数据质量平台(ODQ)等。
第二个持续改进,就是运行管理域体系的那7个流程,防范、发现、响应、恢复、定位、复盘和验收。这里面,我又简单的分了三类,第一个防范层面做好规范建设。静态去看每个公司都会认为自己做的是最好的,我们也认为做的最好。但在真正跑的过程中出了故障,发现规范里面有漏洞,那就要回来形成一个故障的闭环。在规范建设里面,我们没有做多深的理论,但一定要保证够快够权威。当业务发展上到新台阶时,或者出现新的问题时,你一定要把他尽快地放到规范里面去。比如说某一天突然间我们发现盒马鲜生有个交易故障,当然那个故障处理的很快,15分钟就恢复了。但我们以前没有想到的问题是,业务不答应,门店员工不答应,而且情绪激动,拍图发过来说,你看这十几分钟时间,多少手推车被扔这了,这里面还有活蹦乱跳的鱼和生鲜,我现在要怎么把这些全都收回去,因为交易有问题,顾客等不了就不买了。这其实讲一个研发的体感,研发有很多确实没有体验过线下业务,淘宝、手淘与盒马鲜生在支付场景最大的区别是,盒马鲜生线下的用户更易怒。手淘支付失败了十几分钟,大不了手机切到微信、微博吐吐槽,过十几分钟切回来再买也可以接收,对于交易故障的容忍度还是比较宽容,但是在盒马鲜生门店,你拎着几条鱼或者大龙虾,在那排队等了十分钟,基本就不会再等了,直接把东西扔在那里走人,换做是我也会是这样,因为消费场景不一样。这里面背后工程师对于稳定性、以及交易的体感上确实理解不深,后来盒马稳定性小组就定了一个很简单的规范,盒马门店是早9点到晚10营业,营业期间一切变更停掉,晚10点后到第二天早上9点前合规的变更是可以做的,一条朴素的规范,解掉了很大的问题。
其实这个里面的三块部分我们还是讲一下运行无间这个词。运行无间是指把运行管理域体系里面的产品和服务做一个打通,不要拘泥于这个是变更管理服务,这个是故障管理服务,其实我们希望是打通的,当故障发现的时候,你是先去恢复他,还是说如果你可以更趁手的找出来这里正在有一个变更发布,你回滚那个变更。实践证明,当监控报警出来的时候,同时把变更信息推出来的时候,把变更回滚掉对更快的挽回业务有非常大时间的缩短。 故障发生,然后我们通过监控发现这个故障,然后迅速的把这个故障的业务指标所对应的接口,那个接口所对应的后面的应用,上下游画个圈,所有相关联的变更在最近15分钟内的故障全都列出来(15分钟是一个黄金的线,我们统计过90%的变更导致故障,15分钟内一定会导致这个故障,只有10%的变更要一两天或者两三天通过一些特定的条件触发之后导致故障),然后发给相关变更的同学,很有可能变更的同学第一时间是不知道有故障了,由于高强度的工作,不一定每个群都看,不一定每个信息都读,我们是直接电话打到他,说亲请立即回滚。让他回滚掉,然后业务恢复。这个恢复速度,是比要去查出来原因等应急队长再调度一下组织救火要快很多。这里面很典型的,故障监控以及变更的信息联动的操作,然后这个东西其实进一步做,故障变更发现了之后,我们还是让开发自己做的回滚。进一步去想故障能不能自愈,这类故障我们自己去操作回滚,而且回滚是安全的话。我们还有一个前置条件,任何变更如果你的回滚预案是不安全的,是不能回滚的变更,是不可能被审核通过的,任何回滚事件,是建立在100%能够回滚回去的,这时候我们就可以通过故障自愈的方式,很简单的把他恢复掉。
快速的初因定位和智能根因定位。智能根因定位,是做智能基线算法的同一个团队的同学做的。智能根因定位难点在于那个链条,我们有两种,一种基于应用的链路,一种基于业务指标的链路,这两种分别有不同的优化的效果。
然后还有就是复盘,我们这边人手不够,可能你在做故障复盘的同时,又发生了一个故障让,故障恢复后,你是先把这个复盘做完,还是接着做下一个呢,这样的话人肯定是吃不消。我们提倡的是信息的自动采集,自助式的复盘。只要质量达标,里面关键链路的信息从SRE的角度或GOC的角度来看,质量是没有问题,里面不会存在这种坑蒙拐骗的行为就可以过的。自助式复盘,是比较好的能够减轻业务大发展时对稳定性诉求越来越高的点。
常态化演练,通过这个东西把一些我们常见的ITIL服务的相互之间的打通,我们的确可以看到运行管理域的成本效率是有优化的,这个东西的优化可以带来我们业务连续稳定性的提升。
后最后一个是体系闭环,就是说我们做一个体系也好,不管是好体系还是坏体系,我们做的最佳实践,最终还是要业务方买单的。而业务方还是一群易怒,不关心稳定性这样一群开发,你跟他谈稳定性时,过后很快就忘了。核心点是闭环一定闭到他们那边,让他感受到我们是一起战斗的。在去年元旦节,大家都放假在家,凌晨两三点时,发生了一个故障,我们GOC很快就响应了,最后发现业务方起来4个非常高级别的专家,一线值班同学们都基本上没看到,在放假凌晨的时候,大家是很难处理故障的。这里面希望跟大家将,稳定性是要形成协同作战、共担共建的体系闭环,只有这样才可以真正保障线上业务,一个故障恢复,肯定不是某一个团队能够做的好的,那个团队做的再好,他周边的不给力,一样会受非常大的牵连。而且这个体系闭环里面会面临一个发展,他不是一个静态的闭环,不是说你搞定了淘宝就搞定了一切,你会发现淘宝孵化出天猫,天猫孵化出天猫社区小店,孵化出新零售的各个新兴业态。最后一点是想说的是国际业务,无论是印度、东南亚公司的跨国团队,对我们带来更大的挑战,沟通上、文化上、业务上,都需要深入合作、共担共建,从而实现体系闭环。
案例
盒马鲜生从2016年开始摸索到2017年7月正式对外发布说阿里巴巴全资的盒马鲜生是阿里巴巴旗下新零售的代表。从那个点开始迎来了很多关注,并且业务爆发式增长。那时候盒马鲜生门店天天爆满,各种业务诉求和稳定性的问题逐步突出。GOC对接盒马鲜生也差不多从那时开始,大约1个月跟盒马同学完成了一个初步稳定性提升方案的落地,有了明确的稳定性目标、稳定性组织,还有很多稳定性专项。现在再看928五城十店同开,双十一活动,稳定性问题得到很好地管理和改善,而且交易也再创新高。通过运行无间能够在一个月左右的时间,快速能够摸清业务现状,明确稳定性目标,最终确实提高稳定性,减少故障,缩短故障处理时长,为业务大发展创造条件。同时,我们进一步探索新零售的运维保障体系该怎样去建,因为当天猫社区小店做规模化的时候,当银泰、大润发需要稳定性的时候,GOC可以更快介入进去,从而形成体系闭环。
四 发展及方向

GOC的愿景是线上业务能在无人值守中稳定运行。而线上业务可能处在不同的发展时期:一个大体量的稳定发展期,可能处在中型体量的飞速发展期,也可能处在各种需求迭代持续在变更的小体量创新探索期。
无论业务如何变,GOC始终坚守3个朴素的观点:
1. 防止能预见的问题。线上业务的稳定性应该以预防为主,比如消防,不是为了灭火,而是为了防火,让火烧不起来,这才是消防最大的好处。
2. 快速恢复不能预防的问题
3. 不再重复已发生的问题
GOC后面的发展方向主要有四个方面:
1. 自动化:会持续做下去因为还有很多点没有做到自动化,或者场景变化的太快,还来不及自动化,场景就没有。
2. 智能化,我们在监控的领域做到了智能监控,我们在变更领域做到智能变更,但我们依然相信还有很多领域需要智能的,像天猫精灵一样,希望后面也能出来对着GOC智能值班工具说:Hi,GOC,帮我把出故障的机房断掉。
3. 国际化,今年双十一,我个人备战的时候,有个非常大的印象,虽然我们是喝着茶过0点的,但是好累。因为国际化,活动时区不仅仅是东八区,国内双十一忙完后,发现巴西的双十一还没结束,一直搞到12号的下午4点多才结束。
4. 无人值守。通过标准化SOP操作,做一些常规的业务巡检,来代替高成本的人力,减少日常工作,同时用机器人来代替,也可以降低很多误操作。
