@gaoxiaoyunwei2017
2017-11-06T11:21:20.000000Z
字数 25747
阅读 1415
阅后即焚,Python运维开发速成99% 20171025-晓光
刘策
作者简介:
史 影: 应用运维负责人。擅长应用运维、运维开发、故障排错、系统调优。
韩晓光: EXIN DevOps Master授权讲师、信息系统项目管理师。GOPS金牌讲师、金牌作者。著有《系统运维全面解析:技术、管理与实践》、《运维的一天:架构设计、故障处理…》。
导读
首先请读者原谅这个文章标题有些唬人了。借用Bruce Eckel大师的话“Life is short. You need Python”,其实你会发现万物相通,道法归一。当前社会节奏飞快,我们需要快速学习很多新东西,学以致用,但没必要纠结是否要精通。因为很多东西上升不到道法体系的层次,大多数只是纯技术、纯应用,只需做到用完即走,阅后即焚,清理累赘,落得个白茫茫大地真干净。
在我们有限的精力里,总期望学的更多,干的更好,活的更精彩。然而现实中我发现很多运维、开发人员工作不会使用python。难道python很难么?是的,学精难,但辅助工作还是可以分秒速成的。就以我们团队为例,都是干运维的,因工作需要去做运维自动化平台,接触python程序从0到1,当天即写程序,项目一期很快就完成了。不得不承认我们只是在应用python,我们不是理论大师,我们只是搬运工。作为技术应用人员,我们目标就是运用python工具支撑我们的业务发展,这就足以。
人生苦短,我用python,为了精彩人生,请让我们开启python速成模式。本文以实际工作案例出发,提炼出极简约的python教程,不啰嗦笔墨,节省读者时间,旨在给大家梳理思路,快速上手。跟我来,别掉队,没有什么学不会。
本文目录内容如下,不妥之处,恳请广大读者批评指正,真诚期待交流互动。

前言
运维干的活很杂,很琐碎;即高端,也很基础;要细致敏捷,也要搬得动服务器。
运维有很多痛苦和尴尬。任何行业工作都有其委屈尴尬的一面,背黑锅是运维人员成熟历练的必经之路。

运维工作的特点决定运维需要掌握很多知识技能,需要知识面宽广,也要有所精专,更需要架构体系能力。那么如何解决IT运维之痛呢?其实推行运维自动化很好的切入点。
通过实施运维自动化,能够很好贯穿人、事、物、流程标准,从而有效地贯彻质量、成本、效率和安全体系。运维体系的好坏影响运维自动化的实施执行,反过来,运维自动化也会推动运维体系的建设。当云计算时代到来的时候,面对成百上千、上万台机器,人工手工运维显然是不现实的,这个时候就凸显自动化运维的优势了。自动化运维分担了我们很多的工作压力,将重复、乏味的工作交给程序去做,推动运维工作更稳定,更高效、更智能。
那么我们的运维自动化平台架构是这样设计的:
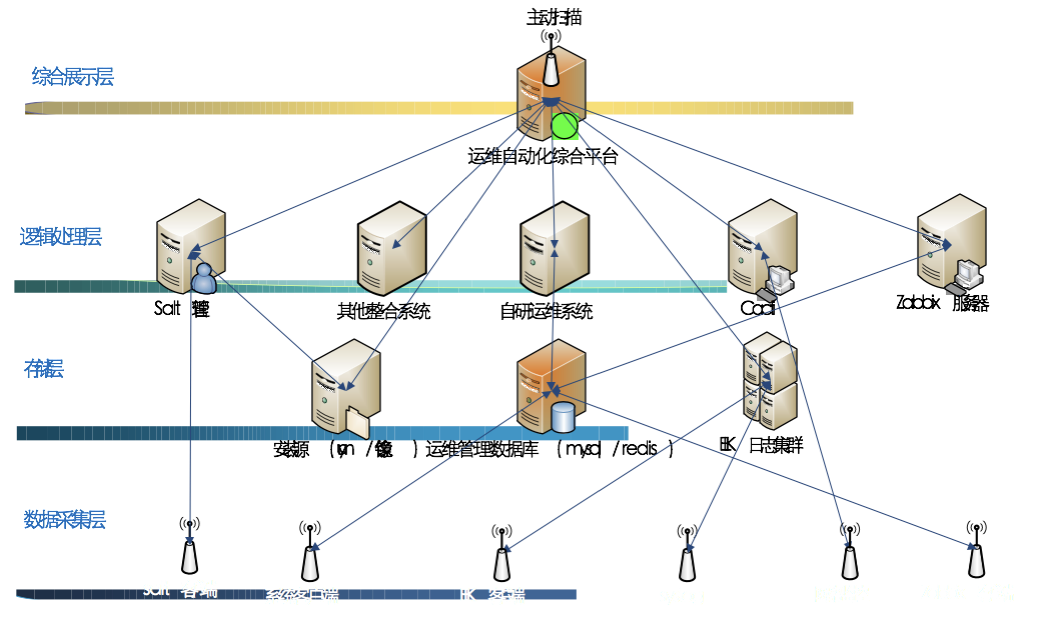
我们运维平台使用的开发语言及工具:
后端开发主要通过Python程序实现。
信息采集写入ELK、Redis、MySQL数据库。
前端WEB展示以及与后台数据层、应用层的交互通过Django框架实现。
界面修饰使用Bootstrap、Echarts等框架工具。
当时我们运维平台一期实现的功能如下:
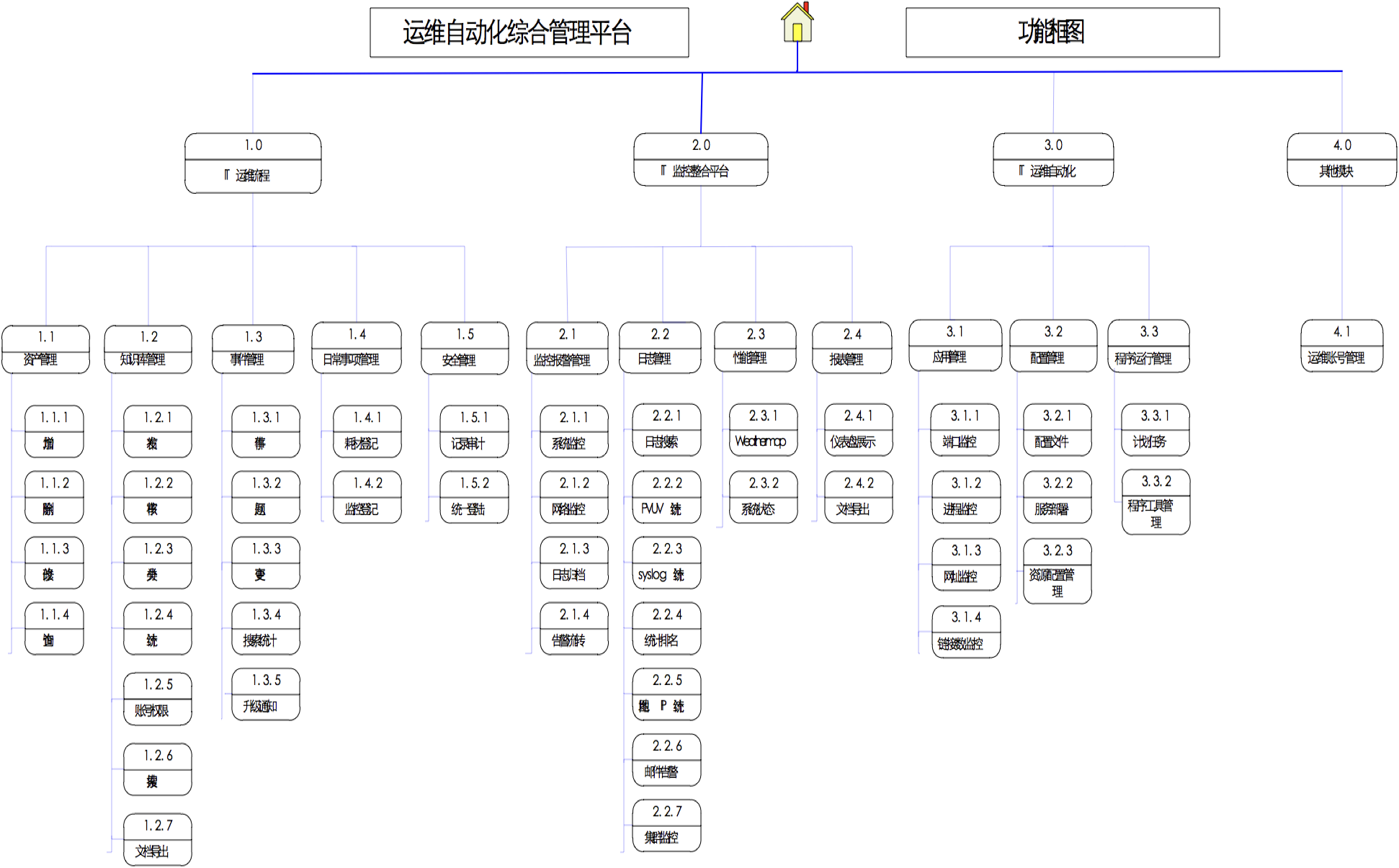
目前Python已在各领域应用广泛,同样对于运维人员,python是一门很适合运维工作的语言工具。如下来自网友对python的形容:语法简约,容易上手,适用广泛,从抓宠物,到打外星人,啥都做…..python在linux系统里通常是默认安装、跨平台、可读性好且开发效率高、有丰富的第三方库(开发框架、各类API、科学计算、GUI等)、社区活跃,拥有众多开发者。

好了,至此让各位读者瞻仰完我们开发的拙劣的运维系统,现在让我们开始python学习速成之旅,本文所讲授的python知识经验都已在我们的运维系统中应用实践。
1、Python速成宝典
Python是什么?
Python是一种面向对象解释型计算机程序设计语言,由Guido van Rossum(吉多·范罗苏姆)发明,Python语言是一种既简单又功能强大的编程语言,语法简洁而清晰,具有丰富和强大的类库,可以帮我们解决很多事情,比如做WEB开发、图形图像处理、科学计算、应用系统、运维管理、网络程序等等。
Python简单易学,拥有极其简单的语法,是一种代表简单主义思想的语言,正所谓:“人生苦短,我用Python”。
Linux系统默认会自动安装Python程序包。在Windows系统下安装需要手动安装Python程序。对于初学者,建议可以在自己的Windows系统上安装一个Python开放集成环境,例如notepad++,Pycharm等。对于熟悉.NET开发者,也可以使用Visual Studio集成环境。本文主要以Linux示例为主。
通常Python的解释器被安装在目标机器的 /usr/local/bin/python 目录下。在命令行的Shell提示符下键入Python,启动解释器,>>>是Python语句的提示符。例如:

按Ctrl-d退出提示符。如果是在Windows命令行中,则按Ctrl-z再按Enter。
Python的IDE(集成开发环境)很多,比如vim、Pycharm、Visual Studio 2010、PyDev等。
Python至少应当有第一行那样的特殊形式的注释,它被称作组织行,源文件的头两个字符是#!,后面跟着一个程序。这行告诉你的Linux/UNIX系统当你执行程序的时候,它应该运行哪个解释器。

执行Python脚本语法如下:
python + [python脚本名称]例如:#python helloworld.py或者 #./helloworld.py
注意:上述都是在当前相对路径下执行Python脚本。当然你也可以写绝对路径。
1.1、基本概念
1.1.1、变量
同其他语言的变量概念基本一样,变量只是你的计算机中存储信息的一部分内存。
变量可以处理不同类型的值,称为数据类型。基本的类型是数和字符串。
1.1.2、数值
在Python中有4种类型的数——整数、长整型、浮点数和复数。
整数是正或负整数,不带小数点。例如1、2、-3都是整数的例子。
长整型不过是大一些的整数。整数最后是一个大写或小写的L。例如2344352454665L。
浮点型(floating point real values)由整数部分与小数部分组成。例如1.23、-1.23。对于很大或很小的浮点数,就用科学计数法表示,例如,0.00123可以用12.3E-4表示。E标记表示10的幂。那么12.3E+4是多少呢?
复数(complex numbers)的虚部以字母J 或 j结尾。(1+2j)和(2.3-4.6j)是复数的例子。
以下实例在变量赋值时数字对象将被创建:

可以使用del语句删除一些数字对象引用。del语句的语法是:
del var1[,var2[,var3[....,varN]]]]
可以通过使用del语句删除单个或多个对象,例如:
del var1del var2, var3
1.1.3、字符串
字符串是字符的序列。字符串基本上就是一组单词。
使用单引号('):你可以用单引号指示字符串,就如同‘hello world'这样。所有的空白,即空格和制表符都照原样保留。
使用双引号("):在双引号中的字符串与单引号中的字符串的使用完全相同,例如"What's your name?"。
使用三引号('''或"""):利用三引号,你可以指示一个多行的字符串。你可以在三引号中自由地使用单引号和双引号。例如:

创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!'var2 = " What's your name?"
注意:
字符串是不可变的。这意味着一旦你创造了一个字符串,你就不能再改变它了。
“\”按字面意义级连字符串。如果你把两个字符串按字面意义相邻放着,它们会被Python自动级连。例如,'What\'s''your name?'会被自动转为"What's your name?"。
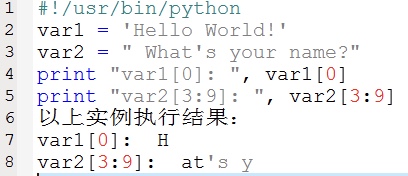
1.1.4、Python访问字符串中的值
Python不支持单字符类型,单字符在Python中也是作为一个字符串使用。Python访问子字符串,可以使用方括号来截取字符串,如下实例:
1.1.5、Python字符串更新
你可以对已存在的字符串进行修改,并赋值给另一个变量,如下实例:

1.1.6、转义符
假设你想要在一个字符串中包含一个单引号('),例如,这个字符串是What's your name?。这不能直接用'What's your name?'来指示它,因为Python会弄不明白这个字符串从何处开始,何处结束。可以通过转义符(反斜杠)来完成转义。
例如这里使用反斜杠\'来指示单引号即可。例如你可以把字符串表示为'What\'s your name?'。
另一个表示这个特别的字符串的方法是"What's your name?",即用双引号。类似地,要在双引号字符串中使用双引号本身的时候,也可以借助于转义符。此外,你可以用转义符\来指示反斜杠本身。
注意:
在一个字符串中,行末的单独一个反斜杠表示字符串在下一行继续,而不是开始一个新的行。例如:
"This is the first line.\
This is the second line."
等价于"This is the first line. This is the second line."
1.1.7、自然字符串
如果你想要指示某些不需要如转义符那样的特别处理的字符串,那么你需要指定一个自然字符串。自然字符串通过给字符串加上前缀r或R来指定。例如:
如下示例使用r指定一个自然字符串

1.1.8、字符编码
ASCII(American Standard Code for Information Interchange)
是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号。
Unicode字符串
编码有多种,例如ASCII、GB2312, BIG5等等,后来有了一种统一编码规范,让所有语言的字符都用同一种字符集来表示,这就是Unicode。最初的Unicode标准UCS-2使用两个字节表示一个字符,所以通常Unicode使用两个字节表示一个字符的。当然后来还有UCS-4标准,它使用4个字节表示一个字符。
Unicode编码长度是固定的,无论是数字、英文还是其他文字,所以Unicode编码有点浪费空间。于是后来又有了UTF8,它对字符的长度是动态的,可变长的,这就解决了unicode的空间浪费的问题, UTF8通常使用一至四个字节为每个字符编码。
占1个字节:一个数字、英文字母
占2个字节:拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文等。
占3个字节:基本等同于GBK,通常就是一个汉字的长度
占4个字节:中日韩超大字符集里面的汉字
Python允许你处理Unicode文本——你只需要在字符串前加上前缀u或U,例如u"This is a Unicode string."。
在你处理文本文件的时候使用Unicode字符串,特别是当你知道这个文件含有用非英语的语言写的文本时。
1.1.9、逻辑行与物理行
此概念同Shell基本一致。默认地,Python希望每行都只使用一个语句,这样使得代码更加易读。如果你想要在一个物理行中使用多于一个逻辑行,那么你需要使用分号(;)来特别地标明这种用法。分号表示一个逻辑行/语句的结束。例如:

1.1.10、缩进
空白在Python中是重要的代表这缩进、层次、模块。行首的空白称为缩进。在逻辑行首的空白(空格和制表符)用来决定逻辑行的缩进层次,从而用来决定语句的分组。这意味着同一层次的语句必须有相同的缩进。每一组这样的语句称为一个块。错误的缩进会引发错误。
建议你在每个缩进层次使用单个制表符或两个或四个空格,但不要混合使用制表符和空格来缩进,因为这在跨越不同的平台的时候,可能法正常工作。
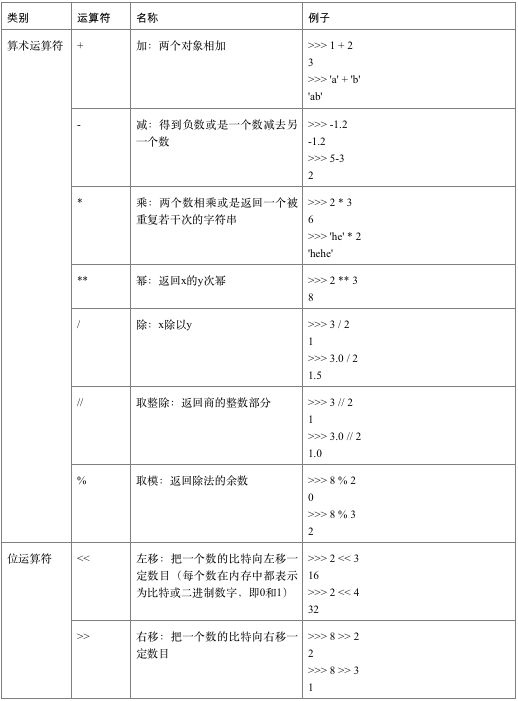
1.2、运算符与表达式
Python运算符常用语法如表所示。
表:运算符
续表
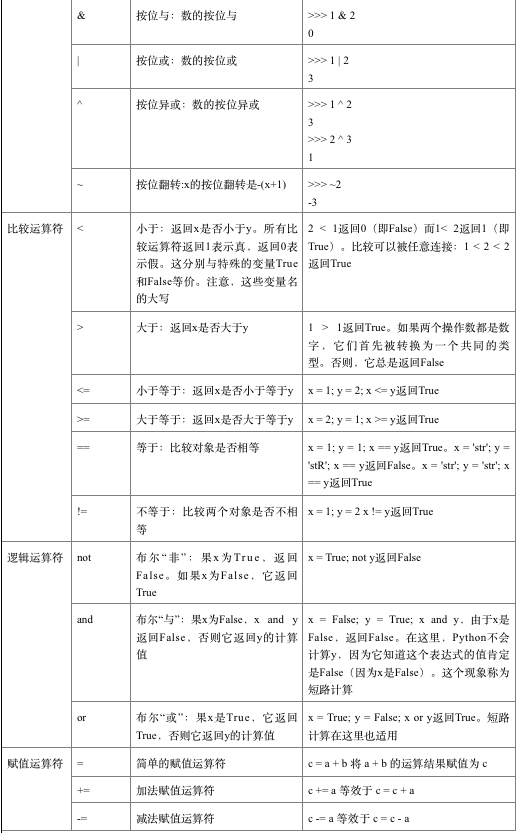
续表
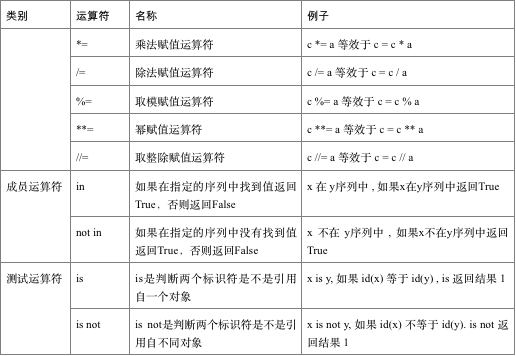
下表给出了Python的运算符优先级,从最高的优先级(最紧密地结合)到最低的优先级(最松散地结合)。
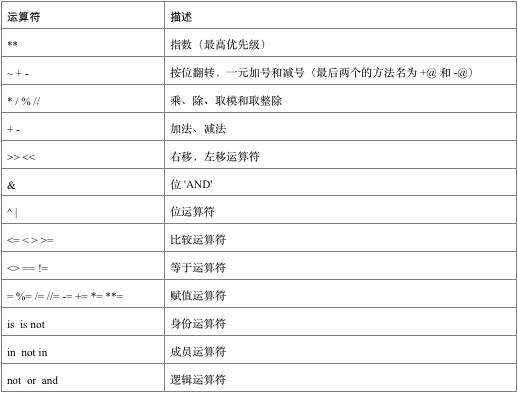
表:运算优先级
1.3、数据结构
数据结构是计算机存储、组织数据的方式。数据结构是通过某种方式组织在一起的数据元素的集合,这些数据元素可以是数字或者字符,甚至可以是其他数据结构。
序列是Python中最基本的数据结构。Python有6个序列的内置类型,即列表、元组、字符串、Unicode字符串、buffer对象和xrange对象。最常见的是列表和元组。
序列都可以进行的操作包括索引、切片、加、乘、检查成员。序列中的每个元素都分配一个数字,即元素位置(索引),第一个索引是0,第二个索引是1,依此类推。
1.3.1 列表
1. 列表(Lists)
列表是最常用的Python数据类型之一,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型。创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['beijing', 'nanjing'];list2 = [1, 2, 3, 4, 5 ];list3 = ["a", "b", "c", "d"];
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。
2. 访问列表中的值
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:

3. 更新列表
可以对列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项,如下所示:
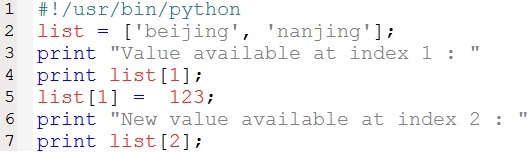
以上实例输出结果:

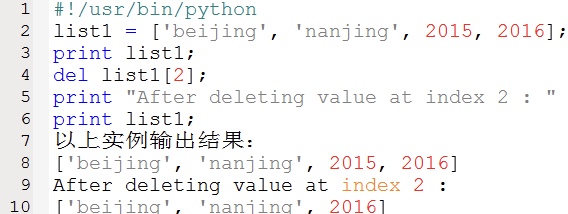
4. 删除列表元素
可以使用del语句来删除列表的元素,如下示例:
1.3.2 元组
5. 元组
元组和列表十分类似,只不过元组和字符串一样是不可变的,即你不能修改元组。元组使用圆括号,元素之间用逗号分割。如下示例:

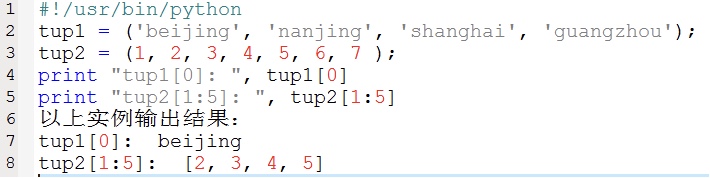
6. 访问元组
元组与字符串类似,下标索引从0开始,可以进行截取、组合等,可以使用下标索引来访问元组中的值,如下示例:
7. 修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下示例:

8. 删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下示例:

1.3.3 字典
9. 字典
字典以关键字为索引,字典也被称作关联数组或哈希表。字典可以理解为一组键值对(key:value pairs)的集合。
关键字可以是任意不可变类型,通常用字符串或数值或元组,但不能使用列表作为字典的键。关键字必须是互不相同的(在同一个字典之内)。
一对大括号可以创建一个空的字典:{}。初始化链表时,在大括号内放置一组逗号分隔的关键字:值对,这也是字典输出的方式。字典的主要操作是依据关键字来存储和析取值。
每一对键与值用冒号(:)隔开,每一组键值之间用逗号(“,”)分割,整体放在花括号({})中。键必须独一无二,但值则不必唯一。例如:
dict1 = { 'abc': 123 };dict2 = { 'abc': 123, 45.6: 78 };
10. 访问字典里的值
把相应的键放入方括弧内,如下示例:

11. 修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对。如下示例:

以上实例输出结果:
dict['Age']: 8dict['School']: Enlish School
12. 删除字典元素
能删单一的元素也能清空字典。显式删除一个字典用del命令,如下示例:

1.4、控制结构
if语句用来检验一个条件,如果条件为真,我们运行一块语句(称为if-块),否则我们处理另外一块语句(称为else-块)。else从句是可选的。语法格式如下:
if expression: #冒号不能少statementstatement #注意:相同的语句块缩进要相同elif expression:statementstatementelif expression:statementstatement...else:statementstatementother statement
while语句只要在一个条件为真的情况下,while语句允许你重复执行一块语句。while语句是所谓循环语句的一个例子。while语句有一个可选的else从句。while语句语法格式如下:
while expression:statementstatement...statementelse:statementother statement
for循环用于遍历元素或者对象的属性。for语句语法格式如下:
for var in ...statementstatementelse:statement使用for语句示例:#!/usr/bin/python# Filename: for.pyfor i in range(1, 5):print ielse:print 'The for loop is over'注意,这里range函数其实有3个参数,第一个参数是起点(包含),第二个参数是终点(不含),第三个参数是步长,默认为1。因此这里:for i in range(1,5)等价于for i in [1, 2, 3, 4]
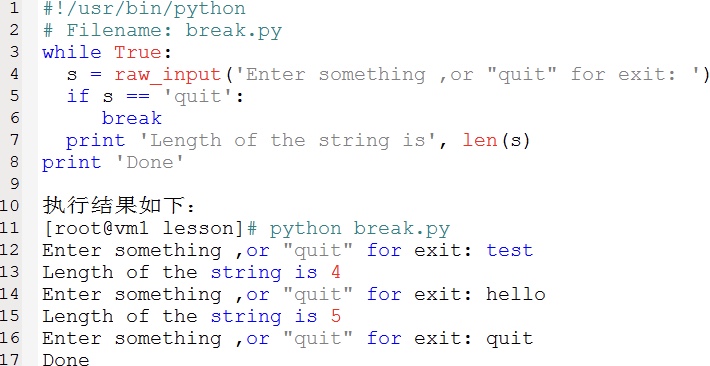
break语句是用来终止循环语句的,哪怕循环条件不是False或序列还没有被完全递归,也停止执行循环语句。
注意:如果break跳出for或者while循环之后,将不再执行任何与while或者for配套的else语句。
break语法示例如下:
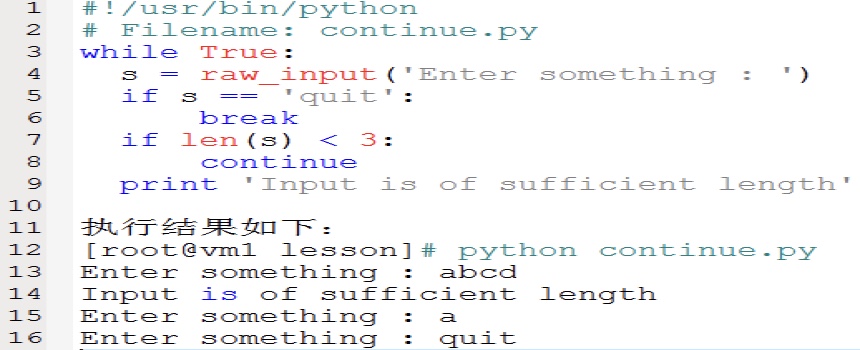
continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。使用continue语法示例如下:
pass 语句表示什么也不做。它用于那些语法上必须要有什么语句,但程序上什么也不要做的场合,通常用于保持格式(或语义)的完整。例如:
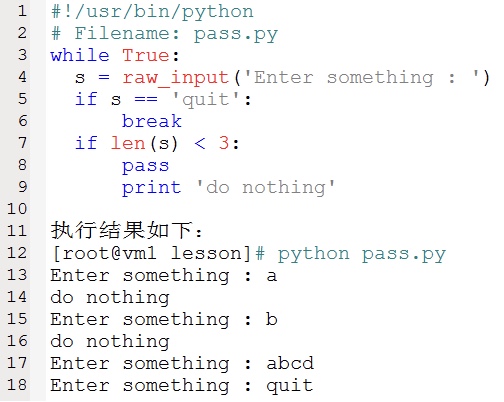
1.5、函数
给定一个数集A,对A施加对应法则fun,记作fun(A),得到另一数集B,也就是B=fun(A)。那么这个关系式就叫函数关系式,简称函数。你可以定义一个有自己想要的功能的函数,以下是一些语法规则:
函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串——用于存放函数说明。
函数内容以冒号起始,并且缩进。
Return[expression]结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
1.5.1、函数语法
def functionname( parameters ):"函数_文档字符串"function_suitereturn [expression]
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
定义函数与调用方法如下:
#!/usr/bin/python# Filename: function1.pydef sayHello(): #函数名print 'Hello World!' # 函数体returnsayHello() # 调用函数
1.5.2、函数参数
函数参数类型有如下。
默认参数:默认参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样,必须传入一个参数,不然会出现语法错误。
命名参数:你的某个函数有许多参数,而你只想指定其中的一部分,那么你可以通过命名来为这些参数赋值
默认参数:默认参数的值如果没有传入,则被认为是默认值。
不定长参数(可变参数):你可能需要一个函数能处理比当初声明时更多的参数。
函数参数示例如下:
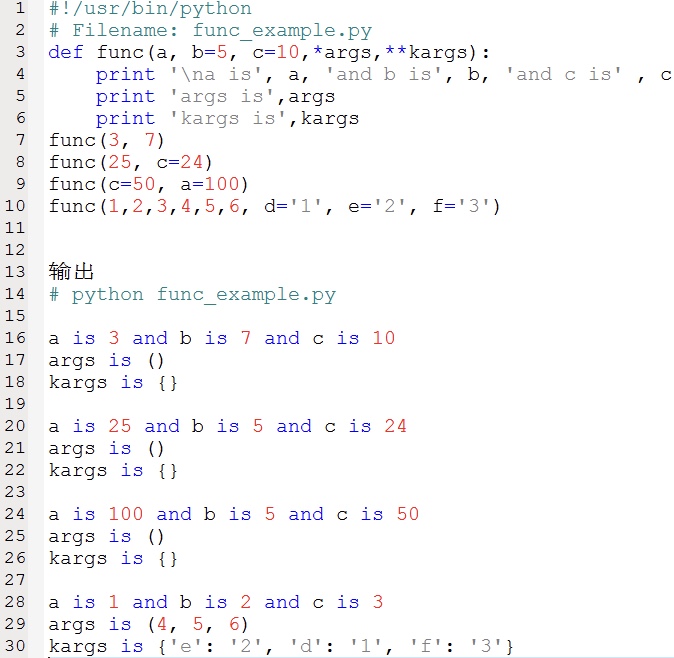
func(3, 7)的时候,参数a得到值3,参数b得到值7,而参数c使用默认值10。
func(25, c=24)的时候,根据实参的位置变量a得到值25。根据命名,即命名参数,参数c得到值24。变量b根据默认值,为5。
注意:参数*args,**kargs这两个是python中的可变参数。*args表示任何多个无名参数,它是一个tuple元组;**kwargs表示关键字参数,它是一个 dict字典。另外,在同时使用*args和**kwargs时,参数*args需要放在在参数**kwargs前面。
1.5.3、按值传递参数和按引用传递参数
传递参数的时候,python不允许程序员选择采用传值还是传引用。Python既不是值传递也不是引用传递,这种参数传递方式可理解为对象传递。Python中的object(对象)分为两大类。一类是mutable object(可变对象),一类是immutable object(不可变对象)。
可变对象:如列表,字典,类的实例等。
不可变对象:数字、字符或者元组。
可变对象作为参数传递时,某些操作可类似于引用传递。
不可变对象作为参数传递时,类似于值传递。
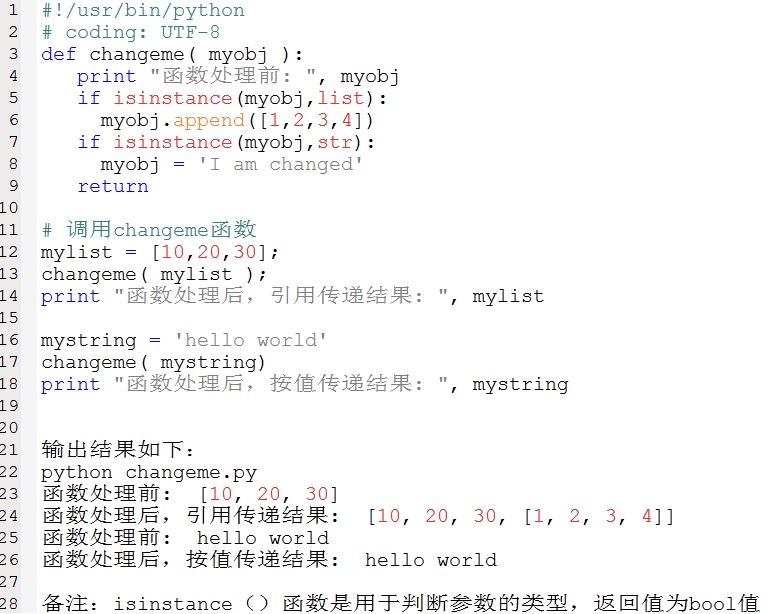
1.5.4、变量作用域
一个程序的所有变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下。
全局变量:定义在函数内部的变量拥有一个局部作用域。
局部变量:定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。必须使用global语句声明全局变量,否则是不可能为定义在函数外的变量赋值的。如下示例:
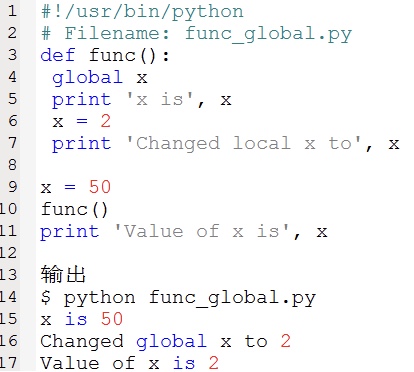
1.6、模块
模块让你能够有逻辑地组织你的Python代码段,把相关的代码分配到一个模块里,能让你的代码更好用,更易懂。模块也是Python对象,具有随机的名字属性用来绑定或引用。
简单地说,模块就是一个保存了Python代码的文件,即包括Python定义和声明的文件。文件名就是模块名加上.py后缀。模块能定义函数、类和变量。模块里也能包含可执行的代码。
包是一个有层次的文件目录结构,由模块和子包组成。包通常是使用用“圆点模块名”的结构化模块命名空间。例如,名为A.B的模块表示了名为“A”的包中名为“B”的子模块。
1.6.1、import 语句
想使用Python源文件,只需在另一个源文件里执行import语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到import语句,模块在当前的搜索路径就会被导入。 搜索路径是一个解释器会先进行搜索的所有目录的列表。习惯上所有的import语句都放在模块(或脚本)的开头,但这并不是必须的。被导入的模块名入在本模块的全局语义表中。如下示例:
#!/usr/bin/python# 导入模块import support# 现在可以调用模块里包含的函数了support.print_func("Jack")以上实例输出结果:Hello : Jack
1.6.2、From…import 语句
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明建议不要过多地使用。
导入可使用\进行换行,
from module import name1,name2,\name3,name4....
可使用as更换模块(方法)名称:
from module import name1 as namefirt
1.6.3、定位 模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
当前目录。
如果不在当前目录,Python则搜索在Shell变量PYTHONPATH下的每个目录。
如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/pythonX/。
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
>>> import sys>>> sys.path['', '/usr/local/python27/lib/python27.zip', '/usr/local/python27/lib/python2.7', '/usr/local/python27/lib/python2.7/plat-linux2', '/usr/local/python27/lib/python2.7/lib-tk', '/usr/local/python27/lib/python2.7/lib-old', '/usr/local/python27/lib/python2.7/lib-dynload', '/usr/local/python27/lib/python2.7/site-packages']
1.6.4、模块的name
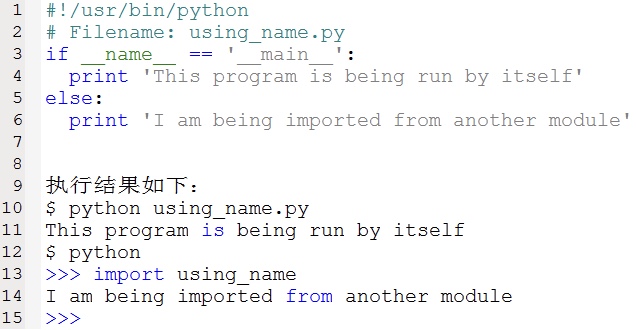
每个模块都有一个名称,在模块中可以通过语句来找出模块的名称。
如果模块是被导入,name的值为模块名字
如果模块是被直接执行,name的值为’main’
这在一个场合特别有用:例如我们只想在程序本身被使用的时候运行主块,而在它被别的模块输入的时候不运行主块,这时可以通过模块的name属性完成。如下示例:
1.7、面向对象
如果你以前没有接触过面向对象的编程语言,那你可能需要先了解一些面向对象语言的一些基础知识,这样有助于你更容易地学习Python的面向对象编程。
1.7.1、面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
方法:类中定义的函数。
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是 模拟"是一个(is-a)"关系(Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python的类提供了面向对象程序设计语言所有的标准特性。例如:类继承机制允许有多个基类,一个派生类可以覆盖基类中的任何方法,一个方法可以使用相同的名字调用 基类中的方法。
1.7.2、创建类
使用class语句来创建一个新类,class之后为类的名称并以冒号结尾,最简单的类定义形式如下:
class ClassName:<statement-1>...<statement-N>
在类体中往往由类成员、方法、数据属性组成。
1.7.3、类继承
你可以继承多个类,方式如下:
class A: # define your class A.....class B: # define your calss B.....class C(A, B): # subclass of A and B.....
1.7.4、 类实例
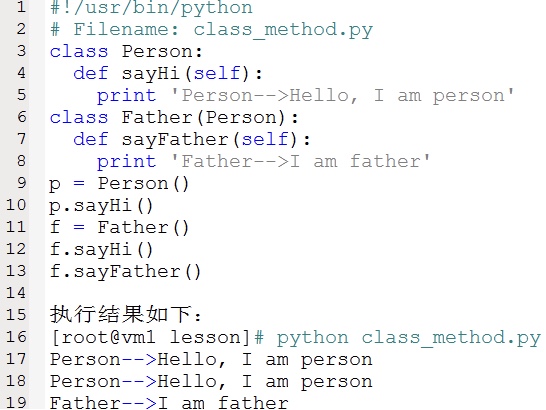
类的定义要经过类实例化并执行才能生效。以下是一个简单的Python类实例化及类继承的示例:
1.7.5、self参数
注意到上面类定义中的方法都有一个self参数。类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称,但是在调用这个方法的时候你不需要为这个参数赋值,Python会提供这个值。这个特别的变量指对象本身,按照惯例它的名称是self。
Python中的self类似于C++中的self指针和Java、C#中的this参考。
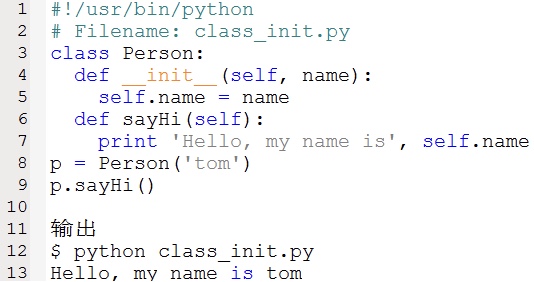
1.7.6. init方法
init方法在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象做一些你希望的初始化。注意,init字母前后各有两个下画线。如下是使用init方法示例:
1.7.7、类继承
你可以继承多个类,方式如下:
class A: # define your class A.....class B: # define your calss B.....class C(A, B): # subclass of A and B.....
1.7.8、issubclass()与isinstance()方法:
issubclass():布尔函数判断一个类是另一个类的子类或者子孙类,语法为issubclass(sub,sup)。
isinstance(obj, Class):布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
1.8、异常
异常即一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。一般情况下,在Python无法正常处理程序时就会发生一个异常。 异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
捕捉异常可以使用try/except语句。try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。如果你不想在异常发生时结束你的程序,只需在try里捕获它。
通过异常,我可以处理如下几个场景:
错误处理,当python检查以程序运行时的错误就引发异常,你可以在程序里捕捉和处理这些错误,或者忽略它们。
事件通知,异常也可以作为某种条件触发的信号、标记。
特殊情形处理,有时有些情况是很少发生的,把相应的处理代码改为异常处理会更好一些。
控制流,异常可作为特殊的"goto"流程。
python的try语句有两种风格---一种是处理异常(try/except/else),一种是无论是否发生异常都将执行最后的代码(try/finally)。
1.8.1、try/except/else风格
以下为简单的try....except...else的语法:
try:<语句> #运行别的代码except <名字>:<语句> #如果在try部份引发了'name'异常except <名字>,<数据>:<语句> #如果引发了'name'异常,获得附加的数据else:<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,Python就在当前程序的上下文中做标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当try后的语句执行时发生异常,Python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
如果在try子句执行时没有发生异常,Python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
1.8.2、try/except/finally风格
try:<语句>except: #捕获所有异常<语句>except <名字>: #只捕获特定的‘name’异常<语句>except <名字>,<数据>: #捕获特定’name’异常和它的附加数据<语句>except (name1,name2) #只捕获这里列出的异常<语句>finally: #退出try时总会执行<语句>
执行try下的语句,如果引发异常,则执行过程会跳到第一个except语句。
如果第一个except中定义的异常与引发的异常匹配,则执行该except中的语句。
如果引发的异常不匹配第一个except,则会搜索第二个except,允许编写的except数量没有限制。
如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。
python总会执行finally子句,无论try子句执行时是否发一异常。如果没有发生异常,python运行try子句,然后是finally子句,然后继续。
如果在try子句发生了异常,python就会回来执行finally子句,然后把异常递交给上层try,控制流不会通过整个try语句。
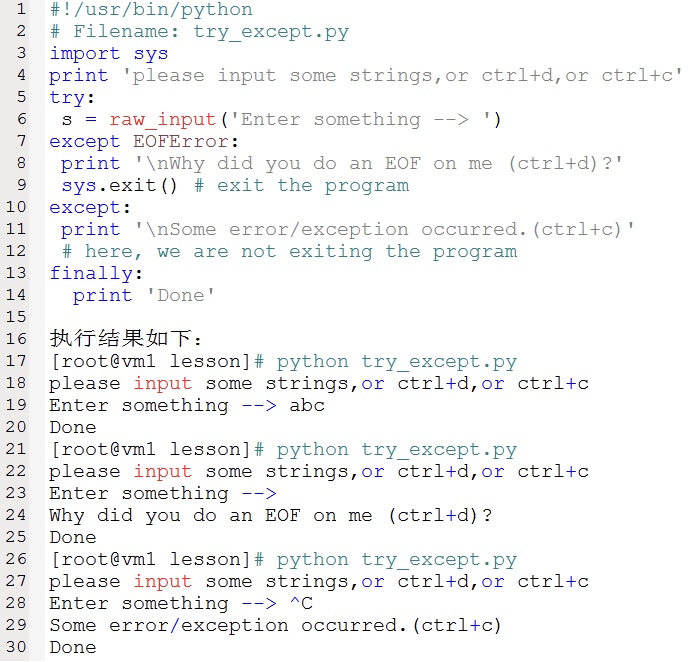
如下是一个处理异常的例子。
1.9、pdb调试
Debug 对于任何开发人员都是一项非常重要的技能,它能够帮助我们准确的定位错误,发现程序中的 bug。
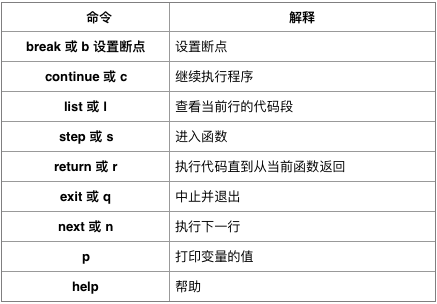
pdb 是 python 自带的一个包,为 python 程序提供了一种交互的源代码调试功能,主要特性包括设置断点、单步调试、进入函数调试、查看当前代码、查看栈片段、动态改变变量的值等。pdb 提供了一些常用的调试命令,如下表所示。
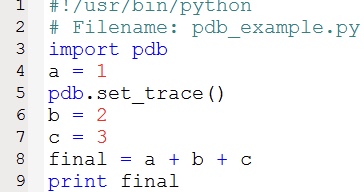
你可以很方便的通过pdb模块在你的脚本中设置断点。正如下面这个例子:
import pdbpdb.set_trace()
你可以在脚本的任何地方加入pdb.set_trace(),该函数会在那个位置设置一个断点。示例如下:
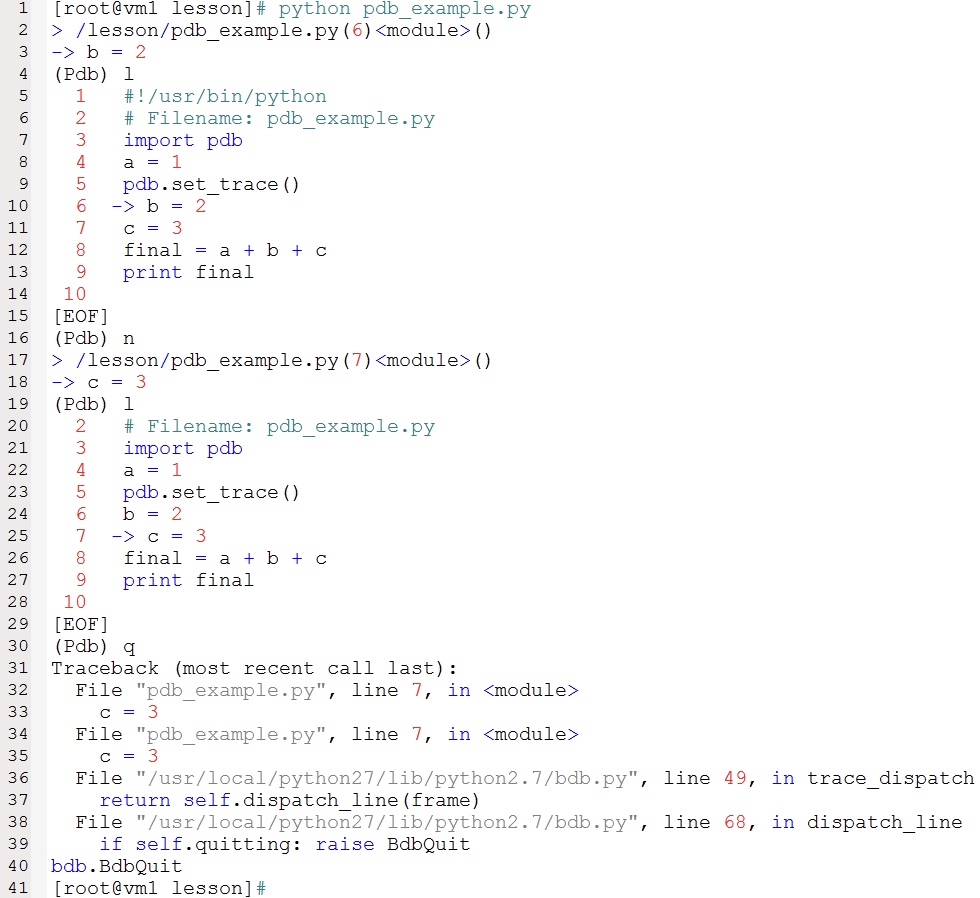
开始调试:直接运行脚本,会停留在 pdb.set_trace() 处,选择 n+enter 可以执行当前的 statement。在第一次按下了 n+enter 之后可以直接按 enter 表示重复执行上一条 debug 命令。
执行结果示例
2、Python 程序案例
上一章节主要介绍了python基本语法概念,让读者朋友对python开发有一个整体基础了解。本章内容则以实际案例出发,分享作者在实际运维工作中的开发经验。
为方便读者理解开发思路,下文案例将增加很多注解,正所谓炮制虽繁必不敢省人工。
2.1、密码探测
遍历给定IP列表,程序根据预定密码库以多线程方式探测系统密码。
#!/usr/bin/env python# -*- coding:utf-8-*-"""check specified port status from item_list:down or updesign by hxg2014/12/31################################################################# passwd_tryssh.py####根据预设的IP列表,密码列表,以ssh方式多线程循环尝试验证正确的密码#############"""# python的SSHv2 protocol协议实现,用于python调用各种ssh功能import paramiko# python内置的多线程模块import threading# python调试器(Python Debugger)#import pdbiplist = []passwd = ['123', '12346', '12345678']# 打开欲检测的ip列表文件f = open("./item_list.txt", "r")# 遍历行,去除换行符,将ip附加到列表iplistfor line in f:line = line.strip('\n')iplist.append(line)print iplistprint len(iplist)# 关闭文件f.close()# 定义函数,传入欲测试的ip,密码列表,要执行的命令def ssh(ip, passwd, cmd):# 建立SSHClient对象ssh = paramiko.SSHClient()# 设置自动接收公钥ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())print "------thread going to try:--------", ip, "------------"# 遍历密码列表for pwd_try in passwd:# 使用给定参数尝试连接服务器并执行命令try:ssh.connect(ip, 22, 'root', pwd_try, timeout=4, allow_agent=False, look_for_keys=False)stdin, stdout, stderr = ssh.exec_command(cmd)print "\n"print stdout.readlines()print "IP is: ", ip, " passwd is:", pwd_try + " trying right"print "\n"break# 若失败则报错并继续下一个except:print ip, " ", pwd_try + ' trying wrong'continuessh.close()if __name__ == '__main__':cmd = 'hostname'threads = [len(iplist)]print '**** threading start ****'# 遍历ip列表,多个ip同时探测for ip in iplist:# 定义多线程对象thread = threading.Thread(target=ssh, args=(ip, passwd, cmd))# 启动对应线程thread.start()
2.2、密码探测--改进版
生产系统通常不能root直接登录,需要其他账号su切换,上述代码就无法适应了这种情况,因此需要改进为如下程序,应对切换账号,系统交互的场景。
#!/usr/bin/env python# -*- coding:utf-8-*-# author:hxg# des:ssh登录系统,如果是非root账号(普通账号)登录服务器,则su切换到root。最后以root执行命令。# date:20140814# python的SSHv2 protocol协议实现,用于python调用各种ssh功能。import paramiko# python内置时间模块。import time# 根据用户名密码从普通用户提权到root用户执行给定命令def ssh_su_root(ip, username, password, root_pwd, cmd):# 建立SSHClient对象myssh = paramiko.SSHClient()# 设置自动接收公钥myssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())try:# 使用给定用户名密码尝试连接服务器myssh.connect(ip, 22, username=username, password=password, timeout=4)except Exception, ex:print str(ex)return# 如果默认root不允许远程登录,提供的是普通用户账号+root账号,则调用invoke_shell,使用交互式shell方式切换到root账号,并执行命令。if username != 'root':print 'I am NOT root'ssh = myssh.invoke_shell()time.sleep(0.2)ssh.send('su - \n')buff = ''# 循环检测密码输入提示,出现后发送root口令。while not (buff.endswith('Password: ') or buff.endswith('密码:')):#从接收缓存中读入最多9999bytes数据。resp = ssh.recv(9999)buff += respssh.send(root_pwd)ssh.send('\n')buff = ''# 循环检测#提示符,出现后执行传入的命令。while not buff.endswith('# '):resp = ssh.recv(9999)buff += respssh.send(cmd)ssh.send('\n')buff = ''# 循环检测#提示符,意味着命令执行完成,出现后关闭ssh连接并输出结果。while not buff.endswith('# '):resp = ssh.recv(9999)buff += respmyssh.close()result = buffprint "su root result-->", resultmyssh.close()else:# 如果提供的是root账号,则直接调用paramiko exec_command方法,执行命令。print "I am root"stdin, stdout, stderr = myssh.exec_command(cmd)stdin.write("Y")print "stdout.readlines()-->", stdout.readlines()myssh.close()if __name__ == "__main__":cmd = 'date'ip = '192.168.198.128'username = 'user_test'password = '12345678'ssh_su_root(ip, username, password, '12345678', cmd)username = 'root'ssh_su_root(ip, username, password, '12345678', cmd)
2.3、统计IP UV值
根据IP地址列表,统计每个IP及其网段出现的次数,并进行排序。这里借用字典进行计数统计。本程序没有使用list列表的count()函数进行计数,因为性能无法适应大量统计的场景。
#!/usr/bin/env python# -*- coding:utf-8-*-# author:hxg# date:20150305"""根据IP地址列表,统计每个IP及其网段出现的次数,并进行排序。这里借用字典进行计数统计"""# python内置的可移植操作系统依赖功能。import os# python内置的参数和功能模块import sys# python内置的时间日期模块import datetime# 用于统计时间开销print datetime.datetime.now() list_ip4 = []list_ip3 = []list_ip2 = []dict_ip4 = {}dict_ip3 = {}dict_ip2 = {}file_name = "./ip_for_count"print "starting count:", file_name# 较为优雅的文件打开方式,允许文件使用结束后自动关闭with open(file_name, 'r') as f:# 遍历ip行for ip in f:# 去掉换行符ip = ip.strip("\n")# 对ip变量的字符串根据”.”字符拆分成列表ip_split,形如['xxx','xxx','xxx','xxx']ip_split = ip.split('.')# 如果ip列表长度不等于4则跳出当前循环,视为ip不符合规则(此处仅是简单测试)if len(ip_split) != 4:continue# 将ip附加到4段的ip列表,形如xxx.xxx.xxx.xxx的字符串list_ip4.append(ip)# 取出形如xxx.xxx.xxx的字符串ip3 = ip[0] + "." + ip[1] + "." + ip[2]# 取出形如xxx.xxx的字符串ip2 = ip[0] + "." + ip[1]# 加入list_ip3list_ip3.append(ip3)# 加入list_ip2list_ip2.append(ip2)# 遍历list_ip4,判断item在字典dict_ip4中是否存在,不存在则创建并计数为1,存在则+1,下同for item in list_ip4:if not dict_ip4.has_key(item):dict_ip4[item] = 1else:dict_ip4[item] = dict_ip4[item] + 1print "clean list_ip4"list_ip4 = []for item in list_ip3:if not dict_ip3.has_key(item):dict_ip3[item] = 1else:dict_ip3[item] += 1print "clean list_ip3"list_ip3 = []for item in list_ip2:if not dict_ip2.has_key(item):dict_ip2[item] = 1else:dict_ip2[item] += 1print "clean list_ip2"list_ip2 = []# 对字典内ip逆序排序list_dict_ip4 = sorted(dict_ip4.iteritems(), key=lambda d: d[1], reverse=True) if os.path.exists(file_name + "_ip4"): # 创建完整ip的记录文件os.remove(file_name + "_ip4")f = open(file_name + "_ip4", 'a+')# 遍历字典并写入文件,下同for item in list_dict_ip4:res = item[0] + "-->" + str(item[1]) + "\n"f.write(res)f.close()print "clean list_dict_ip4"list_dict_ip4 = {}# 创建C类网段ip的记录文件list_dict_ip3 = sorted(dict_ip3.iteritems(), key=lambda d: d[1], reverse=True)if os.path.exists(file_name + "_ip3"):os.remove(file_name + "_ip3")f = open(file_name + "_ip3", 'a+')for item in list_dict_ip3:res = item[0] + "-->" + str(item[1]) + "\n"f.write(res)f.close()print "clean list_dict_ip3"list_dict_ip3 = {}list_dict_ip2 = sorted(dict_ip2.iteritems(), key=lambda d: d[1], reverse=True)# 创建B类网段ip的记录文件if os.path.exists(file_name + "_ip2"):os.remove(file_name + "_ip2")f = open(file_name + "_ip2", 'a+')for item in list_dict_ip2:res = item[0] + "-->" + str(item[1]) + "\n"f.write(res)f.close()# 用于统计时间开销print datetime.datetime.now()
2.4、统计IP UV值--改进版
上例程序代码逻辑清楚,但不够精简,也增加了CPU时间。本例引入正则匹配IP字段,通过lambda表达式简约代码。
# !/usr/bin/env python# -*- coding:utf-8-*-# author:hxg# date:20150305''根据IP地址列表,统计每个IP及其网段出现的次数,并进行排序。这里使用正则匹配进行计数统计''# datatime模块为python内置的时间日期模块。import datetime# re模块为python内置正则表达式模块。import re# 定义全局变量字典dict4存储完整ip,dict3存储C类网段,dict2存储B类网段。dict4 = {}dict3 = {}dict2 = {}def main():# 用于统计时间开销print datetime.datetime.now()# 只读打开ip列表文件。ifp = open("ip_for_count", 'r')# 读文件所有行至内存,注意文件不可过大。iplist = ifp.readlines()# 遍历ip列表iplistfor ip in iplist:# 对字符串进行规整ip = ip.strip()# if re.match(r"\d+\.\d+\.",i).group():# 正则模块match函数针对ip字符串变量i,匹配ip格式(仅基本检测),若存在则调用check函数。if re.match(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", ip):#根据传入的ip字符串变量i和对应ip类型数字size,去对应完整ip字典中检索是否存在,存在则+1,不存在则置为1,下同check(ip, 4)check(str(re.match("\d+\.\d+\.\d+", ip).group()), 3) #check(str(re.match(r"\d+\.\d+", ip).group()), 2)# 根据网段类型字典的值进行倒排序,下同c4 = sorted(dict4.items(), key=lambda key: key[1], reverse=1)c3 = sorted(dict3.items(), key=lambda key: key[1], reverse=1)c2 = sorted(dict2.items(), key=lambda key: key[1], reverse=1)# 写如对应文件,下同。writeFile("c4_result", c4)writeFile("c3_result", c3)writeFile("c2_result", c2)def check(ip, size):"""根据传入的ip和对应size数字,去对应字典中检索是否存在,存在则+1,不存在则置为1:param ip: 传入单个ip字符串:param size: 传入数字,即A、B、C类网段:return: 无"""if size == 4:dict4[ip] = dict4.get(ip, 0) + 1elif size == 3:dict3[ip] = dict3.get(ip, 0) + 1elif size == 2:dict2[ip] = dict2.get(ip, 0) + 1else:passdef writeFile(filename, context):""":param filename: 写入的文件路径:param context: 要写入的内容:return:"""ofp = open(filename, 'w') # 只写入方式打开文件for k, v in context: # 遍历context内容,拼接字符串写入文件mix = k + ' ' + str(v) + "\n"ofp.write(mix)ofp.close() # 关闭文件if __name__ == "__main__":main()# 用于统计时间开销print datetime.datetime.now()
2.5、批量ping探测IP连通情况
遍历给的IP列表文件,多线程批量判断IP地址连通情况。
#!/usr/bin/env python# -*- coding:utf-8-*-# file:ping_all.py# python内置平台识别模块import platform# python内置子进程管理器,用于执行本地命令import subprocess# python内置多线程模块import threadingiplist = []# 只读模式打开ip列表文件file = open("./iplist", "r")# 遍历行for line in file:# 去除换行符,空格等line = line.strip('\n').strip()# 将ip行存入ip列表iplistiplist.append(line)print iplistprint len(iplist)# 关闭文件file.close()class PingIplist(object):"""定义PingIplist类,通过ping命令批量探测IP地址联通性。"""def __init__(self):"""此属性checkres,作为类共享属性变量,用于收集合并(来自各线程)探测结果,是结果的合集"""self.checkres = []def ping_iplist(self, iplist):"""本函数用于批量处理IP地址连通性:param iplist: ip地址列表:return:"""threads = []# 遍历ip列表,使用ping_ip函数为每个ip创建一个探测线程。for ip in iplist:thread = threading.Thread(target=self.ping_ip, args=(ip,))# 启动线程thread.start()#将线程放入列表threads.append(thread)#如果线程列表中有线程在运行,则遍历线程等待结束。if len(threads) > 0:count = 0count_time = 5for th in threads:# 统计线程数count += 1# 如果线程数量大于阀值5,则重新设定减少join等待时间,防止每个都等待很长时间。if count > 5:count_time = 3# print "count_time",count_timeth.join(timeout=count_time)return self.checkresdef ping_ip(self, ip):"""本函数用于根据不同平台使用不同方式,检测某一个IP地址连通性:param ip: 某一个IP地址,字符串类型:return:"""if platform.system() == "Linux":cmd = "ping -c 1 %s" % ipoutfile = "/dev/null"elif platform.system() == "Windows":cmd = "ping -n 1 %s" % ipoutfile = "ping.log"try:# 本地执行ping命令并返回结果。ret = subprocess.call(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)except:pass# 有返回内容,打印并记录if ret == 0:# print "%s: is alive\n" % ipalive_str = "%s is alive\n" % ipself.checkres.append(alive_str)return "%s is alive\n" % ip# 无返回内容,打印并记录else:# print "%s is down\n" % ipdown_str = "%s is down\n" % ipself.checkres.append(down_str)return "%s is down\n" % ip#a = PingIplist()res = a.ping_iplist(iplist)print "res-->", res##res2 = a.ping_ip("192.168.198.128")print "res2-->", res2
2.6、批量ping探测IP连通情况--改进版
假入你对ip输入想更灵活一些,你想支持如下几种IP输入方式:支持逗号,分号;例如192.168.10.10;192.168.10.100,102,104;192.168.1.100-105,那么上述程序可能就需要改进,首先要处理下不同输入格式的IP地址,本例代码示例如何格式化输入的IP地址内容。
import redef ip_split(string):"""查询ip拆分函数# testString = '192.168.1.10;192.168.65.20,24,26;192.168.75.100-200'返回完整ip列表:param string::return:"""step1 = string.split(';')all_ip = list()def ip_type1(strings):"""# 正则匹配形如192.168.1.100 得到['192.168.1.100']:param strings:"""# 正则匹配ip格式(简单匹配)type1 = re.match(r"^(\d{1,3}\.){3}\d{1,3}$", strings)if type1:return [type1.group()]else:return []def ip_type2(strings):"""# 正则匹配形如192.168.1.100,102,104 得到['192.168.1.100','192.168.1.102','192.168.1.104']:param strings:"""type2 = re.match(r"^((\d{1,3}\.){3})(\d{1,3}(,\d{1,3})+)$", strings)if type2:net = type2.group(1)sub = type2.group(3)fullIp = list()ips = sub.split(',')for i in ips:fullIp.append(net + i)return fullIpelse:return []def ip_type3(strings):"""# 正则匹配形如192.168.1.100-105 得到['192.168.1.100','192.168.1.101','192.168.1.102','192.168.1.103','192.168.1.104','192.168.1.105']:param strings:"""type3 = re.match(r"^((\d{1,3}\.){3})(\d{1,3}-\d{1,3})$", strings)if type3:net = type3.group(1)sub = type3.group(3)fullIp = list()ips = sub.split('-')start = int(ips[0])end = int(ips[1]) + 1for i in range(start, end, 1):fullIp.append(net + str(i))return fullIpelse:return []# 合并三种类型过滤的ip为一个listfor index, ips in enumerate(step1):all_ip = set(list(set(ip_type1(ips)).union(set(ip_type2(ips))).union(set(ip_type3(ips))))).union(set(all_ip))# 如果ip查询条件格式不正确返回空if all_ip is None:return Nonereturn list(all_ip)
2.7、括号匹配
学开发,需要了解数据结构,需要有编程思想。本例使用列表,用栈来实现括号的匹配检测。
#!/usr/bin/env python# -*- coding:utf-8-*-# author:hxg# fun_des: 检查匹配字符串中的括号,如果都是成对出现,则验证为正确。否则错误。这里使用了列表栈进行检查匹配。# 用于存储左(大、中、小)括号dict_left = {'(', '[', '{'}def match_check(strlist):try:stack_list = []strlist = list(strlist)while (strlist):# 从输入列表中取出第一个元素l_item = strlist.pop(0)# 如果该元素属于左(大、中、小)括号,则压入栈if l_item in dict_left:stack_list.append(l_item)# 否则从列表栈中取出最后一个元素,与上述列表元素进行括号匹配检查else:s_item = stack_list.pop()if (l_item == ')' and s_item == '(') or (l_item == ']' and s_item == '[') or (l_item == '}' and s_item == '{'):passelse:return "not match"# 在列表元素都取空了,而且列表栈中的元素也取空的情况下,则视为匹配,否则匹配失败if not (stack_list):return "match success"else:return "not match"except:# 由于输入错误,等因素导致程序异常return "match error,please check valid input"if __name__ == "__main__":str1 = '(()())'str2 = '(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))'str3 = '(()()]{}'str4 = '(()'str5 = '[]]]'res1 = match_check(str1)res2 = match_check(str2)res3 = match_check(str3)res4 = match_check(str4)res5 = match_check(str5)print "res1: %s \nres2: %s \nres3: %s \nres4: %s \nres5: %s" % (res1, res2, res3, res4, res5)
2.8、括号匹配--改进版
上例程序代码逻辑清楚,但CPU耗时不够优化,本例通过计数方式减少程序复杂度,比栈实现更快,减少CPU计算资源消耗。
#!/usr/bin/env python# -*- coding:utf-8-*-# author:hxg# fun_des: 检查匹配字符串中的括号,如果都是成对出现,则验证为匹配成功。否则验证为不匹配# design idea:''设置三个计数器初值设为零,分别记录小括号、中括号、大括号。从左向右依次循环扫描每个列表字符遇到左括号计数器加一,遇到右括号计数器减一,出现计数器小于零时,返回检查结果。''def match_check(strlist):try:##初始化参数little = 0middle = 0big = 0count = 0len_list = len(strlist)strlist = list(strlist)##循环检查括号匹配while (count < len_list):if strlist[count] == '(':little += 1count += 1continueif strlist[count] == '[':middle += 1count += 1continueif strlist[count] == '{':big += 1count += 1continueif strlist[count] == ')':if little > 0:little -= 1count += 1continueelse:return "not match"if strlist[count] == ']':if middle > 0:middle -= 1count += 1continueelse:return "not match"if strlist[count] == '}':if big > 0:big -= 1count += 1continueelse:return "not match"if ((little > 0) or (middle > 0) or (big > 0)):return "not match"return "match success"except:# 由于输入错误,等因素导致程序异常return "match error,please check valid input"if __name__ == "__main__":str1 = '(()())'str2 = '(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))(([]{}))'str3 = '(()()]{}'str4 = '(()'str5 = '[]]]'res1 = match_check(str1)res2 = match_check(str2)res3 = match_check(str3)res4 = match_check(str4)res5 = match_check(str5)print "res1: %s \nres2: %s \nres3: %s \nres4: %s \nres5: %s" % (res1, res2, res3, res4, res5)
结束语
至此,本文python运维开发速成暂告一段落,不知你速成了多少,相信各位读者应该至少都理解了99%了(不是么,告诉我你哪个字不认识?),其实只差那最后一点灵犀(一份实践,一下顿悟,一种编程思想),知易行难,实践出真知,未经思考的干货不是自己的知识,未经验证的经历不是自己的人生。
如果谁有100%的速成法宝,请告诉作者,我也想速成☺,作者微信:

