@gaoxiaoyunwei2017
2017-12-26T02:07:31.000000Z
字数 3077
阅读 1256
影响DevOps成功实践的15个指标
持续对特定指标的关注是衡量DevOps实践是否成功的关键。通过本文,我们看一下你确实需要关注的十五个指标。
你所在的组织里DevOps是如何践行的?如果你需要一些帮助来了解这个过程进行的怎么样,我们已经准备了一个关键的DevOps指标清单用来追踪。这些指标可以帮助你了解,在随着时间的推移你的团队是如何做的。
定义Devops对你们组织的意义
DevOps这个词对于不同的人有不同的含义。有人认为它是一种文化,这个行业中的每个厂商都声称他们的工具是有益于DevOps的。依据你对DevOps的定义不同,这些指标可能对你的或者你的团队的意义或大或小。
我认为DevOps包括了你的应用程序的在部署和监控中的所有过程。从很多方面来说,这都是现场可靠性工程的问题。
在Stackify,我们甚至都没有运维团队来操作。我们的开发人员会直接部署到云服务器,并且更像是“没有运维”的方式。
查看我的博客,可以找到更多我对于DevOps是什么的观点。
识别DevOps实践中将会面临的挑战
在你弄明白有哪些DevOps指标需要追踪之前,你需要识别出来你所在的组织中有哪些挑战,有哪些问题是你们正在解决的。
在Stackify,我们最大的问题是部署频率低,并且降低了缺陷逃逸速度。我们的执行团队正在把重点放在2018年的具体指标上。
Devops的指标类型
DevOps是为了尽可能快的持续交付并运输代码。你希望能尽快交付而不因此导致问题发生。
通过追踪这些DevOps指标,可以评估出你们持续交付的速度有多块,而不会导致有问题。
- 开发频率
- 体积变化
- 开发时间
- 投产周期
- 客户支持率
- 自动化测试通过率
- 缺陷逃逸率
- 可用性
- 服务等级协议
- 部署失败
- 错误率
- 应用程序的使用和流量
- 应用程序性能
- 平均检测时间(MTTD)
- 平均恢复时间(MTTR)
DevOps的目标:快速、质量、性能
DevOps的主要目标是快速,质量和性能。
你希望尽可能经常、快速地交付代码。可以做到多块,很大程度上取决于你的产品类型、团队以及风险承受能力。
你可以不跟踪DevOps中速度的指标,但至少应该关于质量问题。你可能已经试着根据自己的能力来做这些,但并没有真正地关心到底能有多块。
然而,你总是在关注质量。你最不希望的就是总是在救产品的“火“。
第三部分是性能。你可能对速度和质量的权衡有质疑。性能也和质量有关,只是有点区别。
部署规模
跟踪有多少故事、特性需求以及修复的bug正在被部署是DevOps的另外一个好的指标。你的项目的大小会影响部署规模的。你还可以追踪有多少故事点或者开发任务量。
部署频率
跟踪部署频率是另外一个不错的DevOps指标。最终的目标是,降低部署规模并加快部署频率。降低部署规模使得更加容易测试和发布。
我建议单独统计生产和非生产的部署频率。你多久部署一次QA或者预生产环境同样是重要的。为了确保测试的时间,你需要尽早尽快地部署到QA环境中。
在QA环境中查找bug,可以有效地保持较低的缺陷逃逸率。
部署时间
这一点看起来有些奇怪,但跟踪部署一次所需要花的时间同样是一个好的指标。如果在Stackify中,你的一个程序需要花费一个小时才能部署到Azure上时。这将会是个噩梦。
跟踪这些事情可以帮助你识别潜在的问题。如果部署的很快,也更加容易增加部署频率。
投产周期
如果目标是快速交付代码的话,这也确实是一个关键的DevOps指标。我对投产周期的定义是,从开始工作到部署之间所需要的时间。
这可以帮你了解,如果今天开始一项新的工作时,多久将能够投产。这也是有助于BizDevOps的一个好的指标。
客户支持率
应用程序问题的最好和最坏的表现是客户支持和反馈。你最不希望看到的就是你的用户发现bug或者软件的问题。因此,这也就成为了程序质量和性能问题的指示器。
自动化测试通过率
为了加快速度,强烈建议你的团队广泛使用单元测试和功能测试。由于DevOps严重依赖自动化,跟踪你的自动化测试工作质量是一个好的DevOps指标。
知道代码的变更多久会导致你的测试会失败是件好事情。
缺陷逃逸率
你知道有多少软件的缺陷在声称和QA中被发现?如果想要快速交付代码,你需要有信心能上在生产之前发现软件的缺陷。
你的缺陷逃逸率是非常大的一个指标,用来跟踪这些缺陷在生产中经常发生的情况。
可用性
你最不想要的就是程序停止。根据你的程序类型以及部署方式,可能会需要在维护计划中让程序下线。我建议跟踪这一点,以及所有计划外的停机。
服务等级协议
大多数有一些服务等级协议(SLA)。跟踪你的SLA是否合规同样重要。即使没有正式的SLA,也可能需要有对程序的期望。
部署失败
我们都不希望发生,但是对于你们的用户部署过程多久会发生一次中断或者较大的问题?挽救一次失败的部署是我们都不想要做的事情,但总是应该对此有应对措施。如果你们的部署过程有缺陷,一定要对这个指标做追踪。这也应当在平均错误时间(MTTF)中被看到。
错误率
跟踪程序的错误率是特别重要的。它不仅仅是质量问题的指示器,也与持续的性能和时间相关的问题有关联。对于好的软件来说良好的异常处理机制是很重要的。
- Bugs – 识别代码部署后产生的新异常。
- 线上问题 – 捕获数据库连接问题,查询超时,以及其他相关问题。
对于大多数程序来说,错误总是存在的。在Stackify,我们在几百台服务器和上千个SQL数据库中处理百万条消息。这里有些错误只是繁忙系统的意外。
重要的是你要把错误率保持在一个频率并且查找一个峰值。

应用程序的使用和流量
部署之后,你想要看到会话的数量或者用户访问系统是否正常。如果突然没有了流量或者出现峰值,就可能是出问题了。
你最不希望看到的就是没有任何流量。当你采用服务时,也可能看到有流量的峰值,而一个程序突然有了大量的流量。
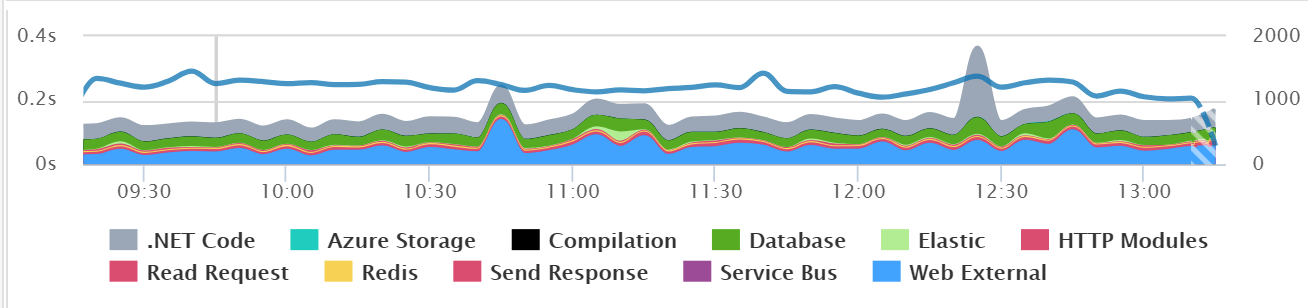
应用程序性能
在你部署之前,应该使用类似Retrace这样的工具查找性能问题、隐藏的问题或者其他问题。在部署期间和之后,你也应该查找是否有性能上的变化。
在部署之后,可以看到特定的SQL查询、web服务调用和其他程序依赖的主要变化。像Retrace这样的工具可以提供下面可视化的价值评估,以帮助你发现问题。
平均检测时间(MTTD)
当问题发生后,重要的是能够快速识别出来。你最不想看到是主要功能或者大部分系统宕机并不知道原因。健壮的应用程序监控并且能覆盖到位将有助于你快速定位问题。一旦你定位了问题,就必须快速地修复!
平均恢复时间(MTTR)
这个指标帮你记录从失败到恢复需要花费多长时间。一个关键的商业指标就是保持错误最小化并能够快速地恢复。通常按小时来计算,但对应的是商业上的小时而不是时钟小时数。
拥有一个健壮的应用程序监控工具从而快速识别问题并修复和部署对于减少你的平均恢复时间(MTTR)是很重要的。
应用程序指标
除了上面列出来的DevOps指标外,你还可以记录很多其他指标,这些指标都是针对特定程序的。它们中的大多数都在DevOps部署你的应用程序时不是必需的。然而,它们对于应用程序在生产中的使用和性能的监控是非常重要的。
例如,在Stackify中,我们利用自定义指标来跟踪每分钟通过API收到的日志消息数量。这是一个重要的指标,它可以帮助我们了解通过我们系统的数据量。根据你的应用程序实际情况,你可以定义类似对于你们来说非常重要的指标。
当部署以后,你就想要关注所有重要的程序指标,以确保是没问题的。
总结
如果你想要把DevOps实践到更高层次,我相信上面列出的DevOps指标将会有助于你追踪和改进。DevOps的目标是共同协作并让更多的开发者参与到部署和应用程序监控中来。
