@gaoxiaoyunwei2017
2018-12-18T04:08:01.000000Z
字数 6051
阅读 1403
智能运维:从0搭建AIOps系统
白凡
讲师介绍:主持人身份切换到演讲嘉宾。这是我们刚刚出版一本书的名字,智能运维从零搭建AIOps系统。刚才听了阿里和很多企业做了开源非常庞大系统,对于一些中小企业来讲要实施AIOps非常有门槛,我们要做到BAT这样级别非常困难,所以我们这本书帮助大家,尤其是中小企业,给大家一些建议,基于我们在微博的经验。
我现在微博广告团队,是一名奶爸,关注大数据。


1. 概述:我们离AIOps理想王国还有多远
刚才那本书,我们下午2点45分有签售,大家可以关注一下。今天分享分四个模块,首先我们了解和一起探讨一下,大家都在提AIOps,我们AIOps理想王国到底离咱们现在还有多远,我们一起探讨一下。

我们探讨这个问题时候考虑梦想或者理想是什么:
- 第一个,我们不背锅,我相信在座做运维的同学肯定有背锅的经历,如果我们AIOps不用再背锅了,这是第一个理想。
- 第二个理想,不用在企业,这个事情经常会发生的问题。我的团队,包括我自己,也会由于线上问题半夜起来操作线上服务,我们希望有了AIOps之后要实现的第二个理想
- 。第三个理想,我们不用去7×24小时值班,尤其国庆、双十一、双十二、618,各种节日非常多,这种情况下要班,希望有了这套机制不需要再做排班、值班,完全机器自动执行人工要干的事情,这是我们三好大理想。

刚才知道我们理想,怎么去实现呢?我们通过这样分析方法,5W-1H分析方法,在公司经营管理方面用得非常多,做任何事情要问5个W,1个H。第一个W,我们做什么。第二个,在哪个地方做。第三个,什么时候开始做。第四个,谁去做,大家问完这些问题心里已经有答案,谁去做,运维去做AIOps。我们怎么去做和为什么是我们做,而不是别人去做呢?接下来我们探讨这个问题。
我们理想到底怎么去实现呢,我觉得答案是这样的。coding,之前做运维同学写脚本或者做机器运维,现在我们做AIOps或者DevOps,我们进入了开发领域,所以我们不停写代码去实现自己的理想。

有的理想之后,我们又有了方法,我们到底还要多久实现理想呢,我们可以借助于康波周期,在座有同学知道什么是康波周期吗,这是一个俄罗斯非常出名经济学泰斗人物提出的周期概念,是指我们人类经济发展有周期性波动。
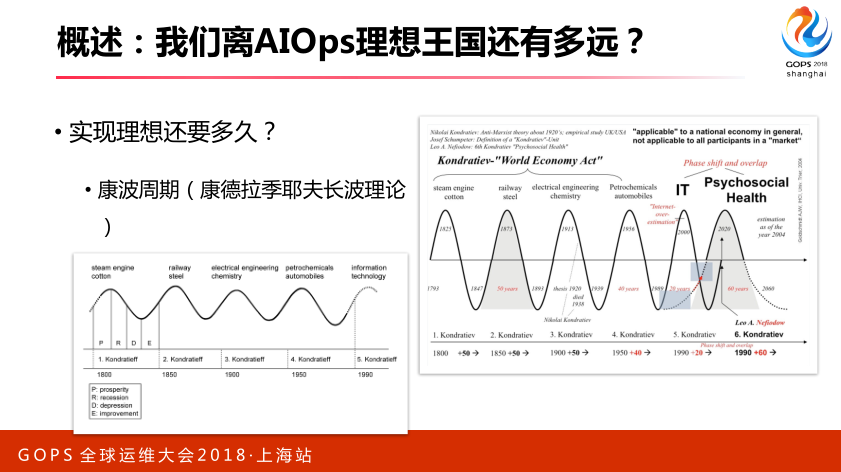
比如说我们经历了波谷到波峰过程,每次衰退到兴盛需要科技革命,比如蒸汽机、铁路,还有一些电气工业,到我们现在IT,到我们现在AI,这是推动我们建立这样一个周期的技术支撑,有这个理论,一个周期大概要50年,所以AI,我们现在刚开始,所以我们正处于这个时代最开始,所以大家非常有机会。

2. 准备:以终为始,看准目标
刚才提到我们运维从开始不用写代码,到我们写脚本,到我们可以做SRE工作,再做开发DevOps,再做AI,我们运维角色发生变化。最开始的运维到运维工程师,再到开发工程师,再到大数据工程师,再到最后变成算法工程师,所以就是这样一个角色的变化过程,我们处于这个AI时代,我觉得非常好的。
刚才我们谈了理想,有了理想之后,我们设定实施目标,所以现在我们探讨一下怎么去实施目标,要先了解一下我们行业的现状,具体的目标是什么,我们实施AIOps三驾马车是什么。

我们看一下行业现状,第一梯队,看国内第一梯队,BAT大家都认可的。当然还有BATXJ,还有ATM,还有XXX,还有很多企业,还有脸书等企业。我们跟第一梯队稍微困难一点,他们特点是人多、兵强马壮,钱多、体量大、起步早,别人比我们聪明,起步还比我们早,我们达到他们这样阶段,比如刚才阿里和百度同学分享的技术,我们达到他们境界可能还早着呢。对于第一梯队来讲,我们可能追赶他们稍微困难一点。

咱们看第二梯队,第二梯队我们认为市值100亿到500亿之间的企业,比如微博、搜狐、网易,这些企业更注重于业务,工程架构从零开始。要跟他们同台竞技,咱们企业AIOps实施建议,包括出了智能运维这本书,从这些材料里面和高效运维公众号里面学到很多东西,从零搭建自己的AIOps系统。

区别就是这样,对于第一梯队来讲,BAT航空母舰,造各种轮船大炮,所有零部件自己去搞。对于我们第二梯队来讲,我们做了什么事情呢?我们用了很多开源的东西,对于微博来讲用了非常多开源,我们国内用得最大,我们用了很多开源。

我们发现第一梯队和第二梯队区别,设定我们自己目标,明确运维目标到底是什么,这个很重要。我们列了几点,一般大家觉得我们稳定性、可靠性,性能是我们做运维的目标,实际上我们要考虑一点,对于稳定性来讲,有时候不能干预。

比如稳定性是一个系统稳定性或者服务稳定性,可能跟开发有关系,他写一个代码有BUG,稳定性不高会出错。我们运维去提高可用性,我们最重要关注的指标是系统的可用性。
可用性的定义是这样,它有两个因素影响可用性,我们故障出现的间隔时间,间隔时间如果越长,我们可用性越高。第二,我们故障的修复时间,修复越快,我们可用性越高。我们运维要做的实行,要去拉长我们故障出现的时间。第二,一旦出故障的时候,我们快速去修复,这两点通过自动化方式和智能化方式能够解决的问题。

我们刚才提到目标是要提高可用性,我们实现AIOps有三驾马车要去做。第一,感知层,监控平台,我相信所有做运维平台都知道监控平台是什么样子,需要有一个报警平台,需要有一个CI/CD平台,自动化平台。CI/CD平台负责最终执行,有了策略之后,把这个策略实施到线上,需要这三驾马车,只有这三驾马车非常充分情况下,并驾齐驱,三驾马车开足马力情况下才能实施AIOps计划。

3. 启程:从0开始!构建AIOps大舞台

3.1 拥有数据
前面讲了这么多,看一下怎么实施三驾马车,从零到一怎么搭建这个平台。我们看一下现状,我们所有的企业或者中小企业,我们要对照的看,我们企业到底大数据公司,你的数据量大数据,还是有数据。人工智能,还是智能人工。前段时间有一个段子说现在很多人工智能客户,后面雇了一帮人做人工客服的,人工智能客服实际上是智能客服,后面有一堆客服充当机器,所以我们要看清楚到底是否需要AI,有可能我们需要一些规则就搞定,报警聚合或者根因分析有规则就搞定,不需要太高深算法,我们要认清自己问题。

其次非常重视数据,在我们这本书非常详细探讨数据重要性,要以数据为王。如果没有数据,后面所有分析计算、模型、算法,我们无从谈起,数据最开始一定要把关好,从数据采集存储到计算,再到分析,一定以数据为王。
3.2 采集数据
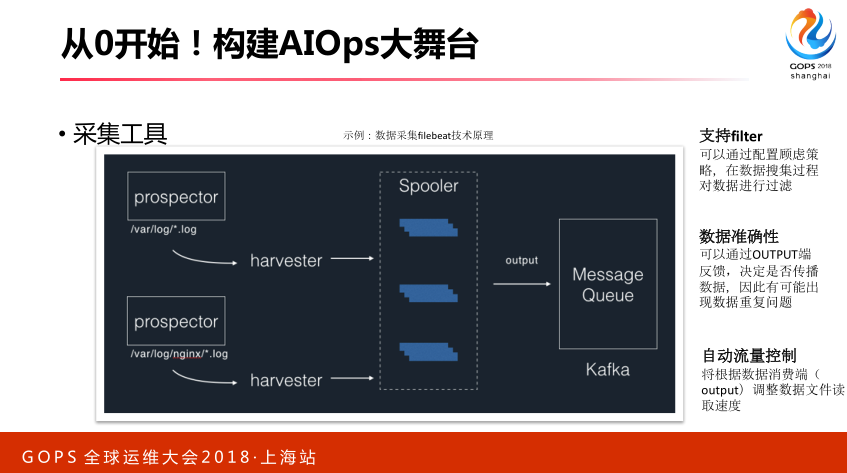
从采集这端,我们可以用开源工具非常多。在微博最开始是这个,随着性能增长它有很多问题,我们逐渐迁移,现在用我们自研一个版本。

自研版本支持自动流量控制,我们保证数据不丢失,能够支持各种适配,然后保证我们数据根据自己规则去进行一些简单的清洗。
我们对于自己采集端的性能测试。
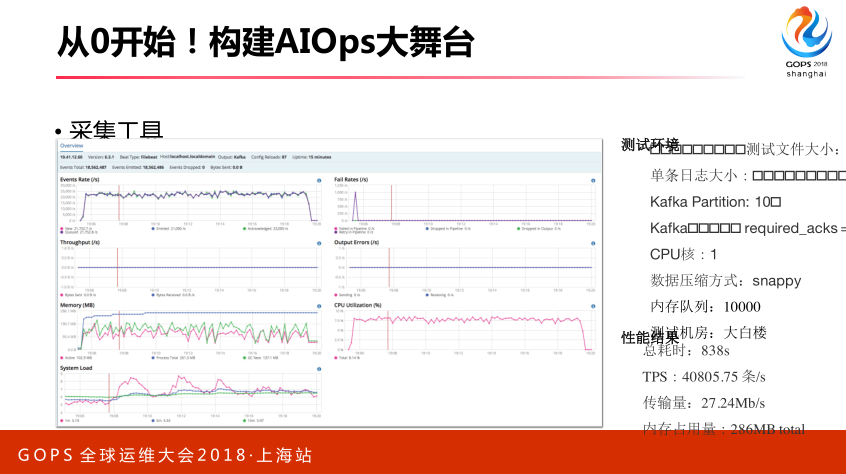
刚才提到所有数据采集端,数据采集在实施时候,尤其从零到一需要注意的地方。第一,采集做数据预处理,一定做数据处理,否则所有数据放到存储里面去,后面分析计算带来很大问题,最开始时候对数据进行非常严格的处理。同时我们去推动日志的标准化,如果开始架构不合理,最终改造成本非常高。
上次跟滴滴公司的同事交流,他们做一个系统花两年时间,线上的一个系统,打通所有业务系统之间的桥梁,要建立这个。你开始没有考虑这些,你可能需要花很长时间构建这样一套系统。我们最开始数据源头要注意这点,怎么保留数据能够正确和快速采集到。同时我们要让运维能够影响开发和产品,这点有必要强调一下,非常重要的。最开始运维常在技术方面或者常在开发后面,开发常在产品方面,产品常在业务后面,我们离业务非常远,没有办法影响业务,开发或者产品说上线找运维,立马让你上线或者做变更,我们比较被动的。我现在所在的团队,我们希望运维把我们影响要前置,把我们数据前置,在产品设计规划阶段,要告诉他们日志应该怎么做,系统应该怎么设计,我们需要建立这样一个机制,让运维工作能够顺利展开。
3.3 存储数据
存储,我这块不用太多讲了,如果对大数据比较了解应该非常清楚,比如存储有很多的方法,对于热数据怎么存储,对于持续数据怎么存储。

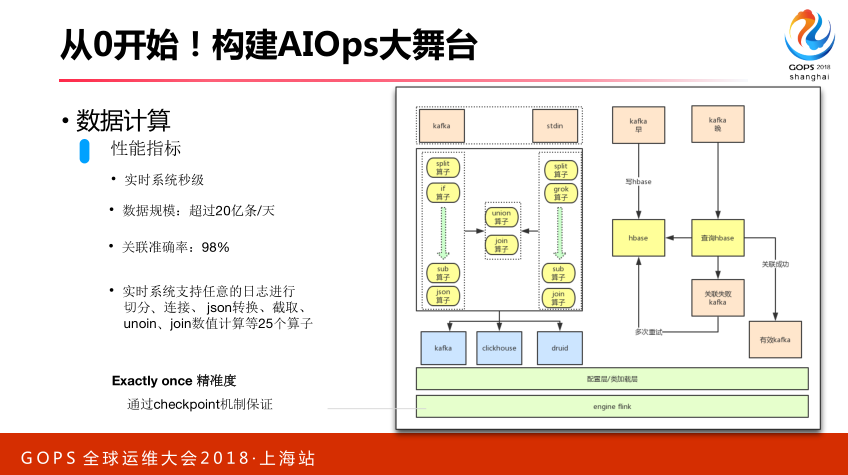
对于数据的计算,我们这里面考虑几个非常关键的问题,刚才说我们数据采集完了之后怎么去做数据的计算,这里面要注意好几个问题,比如我们实时计算系统怎么去支持多种维度的聚合或者关联,这个是非常困难的。因为对于实时系统来讲,我们关注两个点。第一,时效性,怎么快速去完成。第二,关注我们数据的准确性,实时流数据很难验证准确性,不像离线数据,按天重跑这个,实时数据很难验证,我们必须通过机制或者架构层面去保证。我们有一个算值,通过不同算值完成不同维度数据关联和聚合,通过配置方式可以实现线上的变更,比如新增一个数据指标关联,你只需要改下配置搞定,不需要再上弦发布。
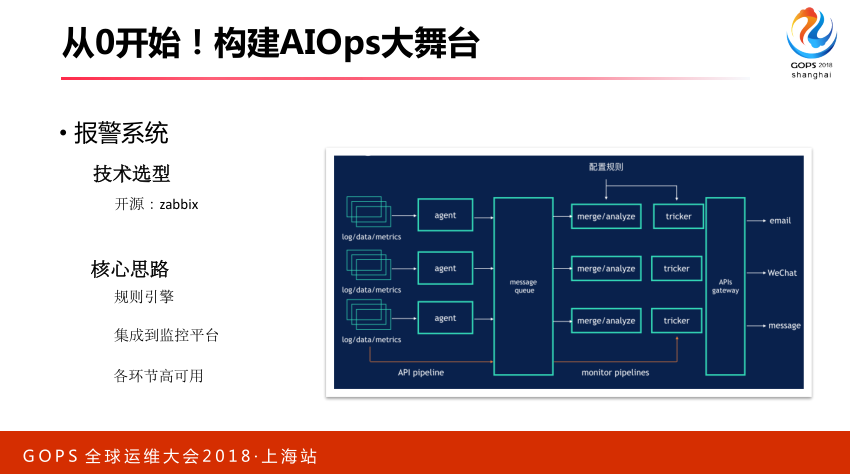
3.4 报警系统
对于第二驾马车,报警系统,我们觉得最关键一点,这里面有开源的这个可以用。我们核心思想把报警集成监控平台里面去,通过监控页面可是化和报警规则,这两个要打通,开发同学配了一个监控图,他希望根据这个趋势设定他自己的报警阈值或者是配置,这两个需要能够做到关联。
3.5 CI/CD系统
第三驾马车,CI/CD系统,这个系统很关键一点,它要能去集成我们QA的自动化测试功能,否则我们在所有的线上变更时候都会去做自动化测试,如果你没有自动化的测试环节,你很难保证我们线上的发布质量。刚才王艺提到我们线上有40%多的问题,因为线上变更导致,现实中可能更当,百分之八九十都是线上变更导致。因此我们必须有一套机制去保证所有的变更是安全,是没有问题的。从刚才数据的采集到我们数据的存储,再到数据的计算,再到其他报警和监控,整个系统如果合在一起,大概这样一个架构,这是我们可以实施架构,不是BAT很难很很高深架构,很多模块可以投入开源框架去完成。
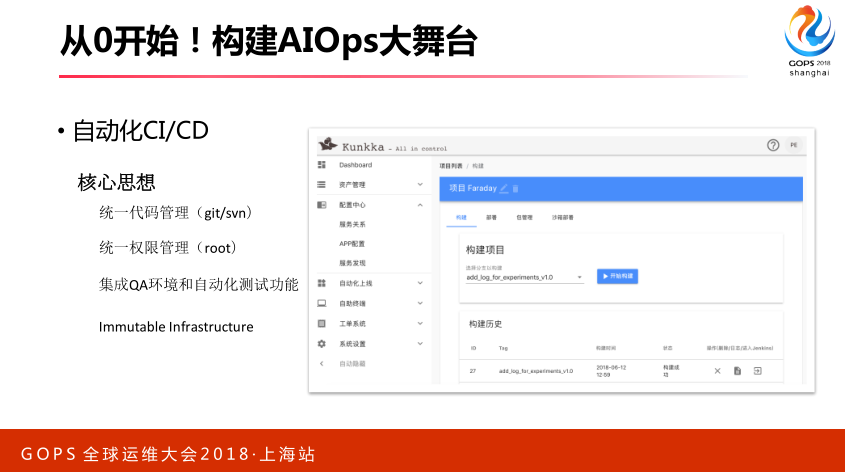
3.6 线上系统
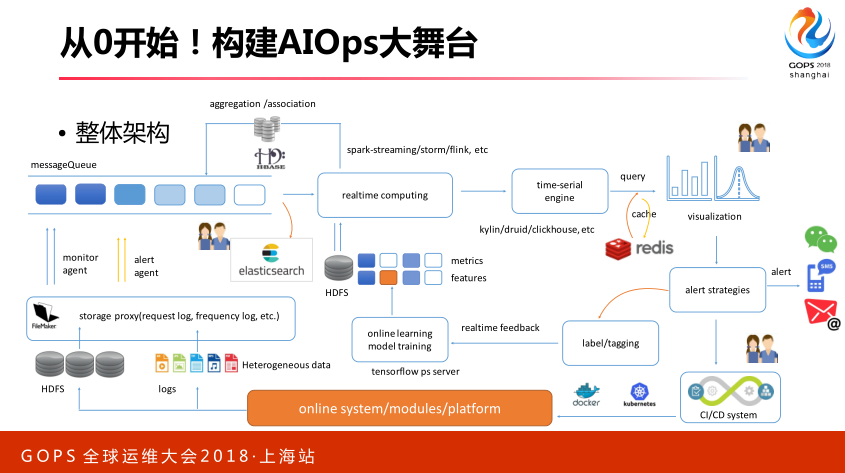
最下面是我们线上的系统,线上系统产生很多数据,这个数据通过一些存储介质,我们客户端收集,收集以后进入实时队列,再由实时系统进行消费,期间可能进行数据的关联和聚合,实时数据进入持续数据的存储引擎,比如这里面的这些,很多。再通过查询引擎,可能需要建立一套缓存机制,最终进行可视化,这个监控系统就出来了。监控系统出来之后,我们去配合我们的报警,我们需要有报警的策略,这个策略直接触发我们线上变更,微博里面有个名人出轨了,我们对系统进行降级或者扩容,这个操作要通过策略直接去影响到线上变更系统,CI/CD变更系统,最终影响我们线上。同时这里面有一条逻辑,我们还需要一个标注系统,对于实际报警规则有误报情况,对于这些信息进入标注系统,最终去反馈我们线上的特征里面去,这是一个整体的架构情况。
4. 爆发:智能决策,决胜千里

4.1 模型算法
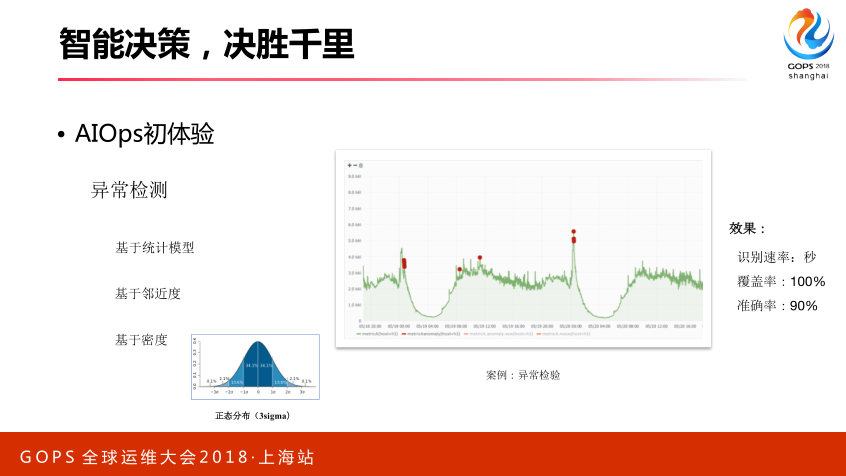
前面很多老师讲了智能运维根因分析和异常检测,其实简单来讲,你不拿算法来讲,对于异常检测,其实很简单。比如基于统计的模型,基于统计模型一定分析数据统计的规律,或者它的概率分布,这是必须要有,不一定是所有的数据都可以拿这个统计模型来去做。比如它是适合,你去分析发现这个数据属于正态分布,你可以用这个方法做检测。如果没有分布、没有规律,你可能只能按照其他方法,基于临近度或者密度的方法。临近度很简单,可以理解异常数据和正常数据,它是一个分的问题,正常数据在一堆,异常数据在一堆,异常数据距离比较短,这里面可以用分类算法,基于这个做。基于密度也是一样,物以类聚,聚在一起密度更高一些,它和异常点密度会更小一些,通过这两种方式都可以做。基于临近度和密度方法做,我们选K值可能困难一些,计算复杂非常高。
右边我们通过基于独立森林的算法做检测效果,我们发现这个算法能够带来的效果,我们准确率可以达到90%以上,这里一定要提到一点,我们异常检测不能完全替代,我们希望通过算法提高运维的效率。
4.2 报警聚合
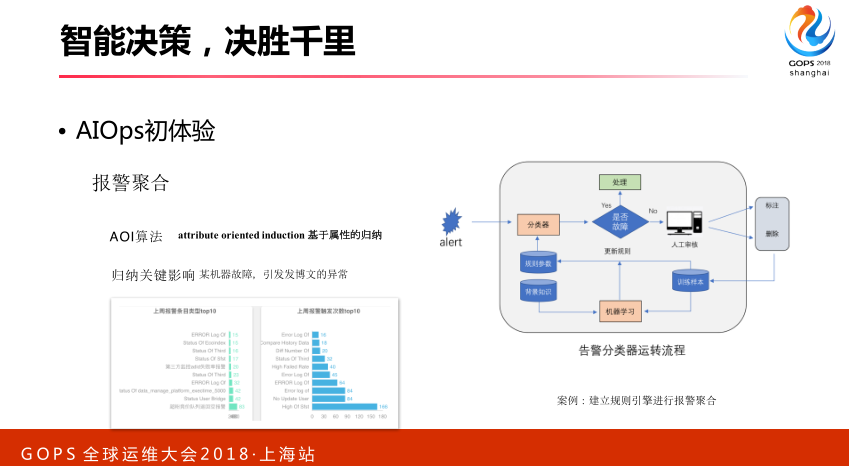
对于报警的聚合,这里面报警聚合,我们希望报出来的警,刚才提到有个明人出轨了,可能导致一堆系统都出了问题,这一堆系统可能成千上百台机器发报警信息,不知道该怎么处理了,对于这样的情况,我们需要用报警聚合的方法。比如我们用的AI方法,基于属性归纳,比如某台机器出了问题,这台机器存储服务,它导致存储服务部可用,存储服务上层业务支撑发博文,会导致发博文会受到影响。归纳起来,这个机器报警,存储出了问题,发博文受到影响,我们归纳起来只需要发一条报警的短信过来就行了,我们现在发博文是异常的,需要谁去处理,这样就可以极大的降低我们的报警条数。
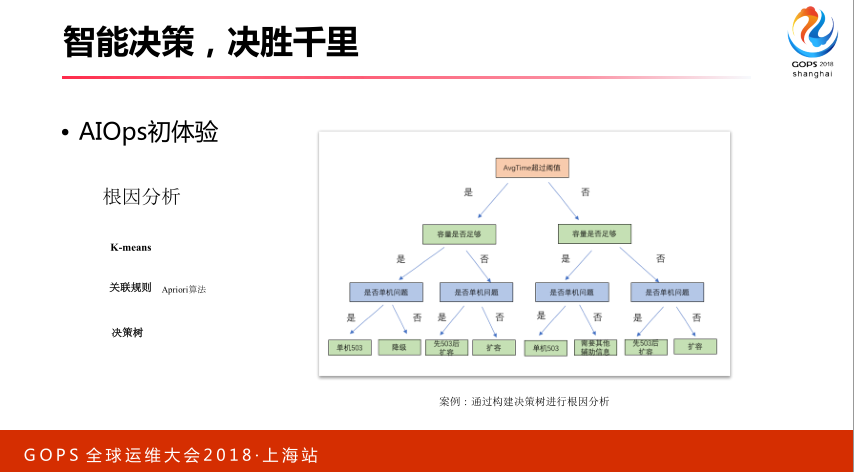
4.3 根因分析
对于根因分析,正好和报警聚合是一个反的方向,刚才是自己,上去做归纳,根因分析自上而下做分析和判断,最常见的方法决策树,也是最简单的办法。
发博文出了问题,它可能存储导致,存储运行哪些机器上,哪些机器出了问题,自上而下判断具体的原因。
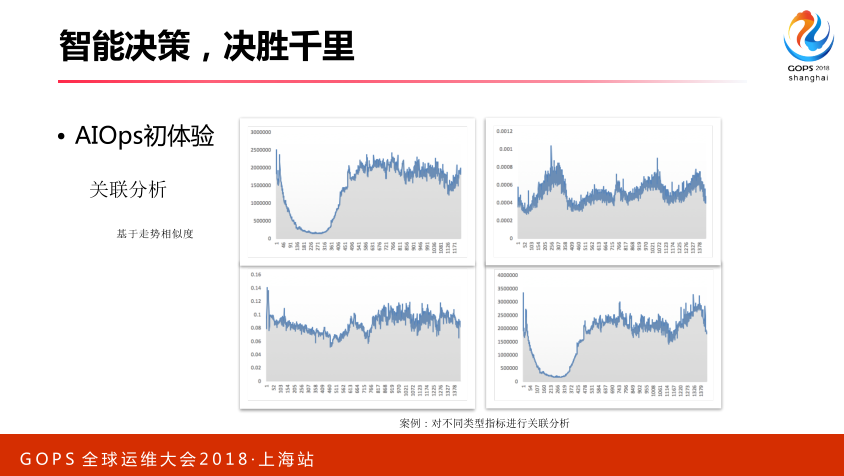
还有一些关联分析,这里面不太讲了。
4.4 预测
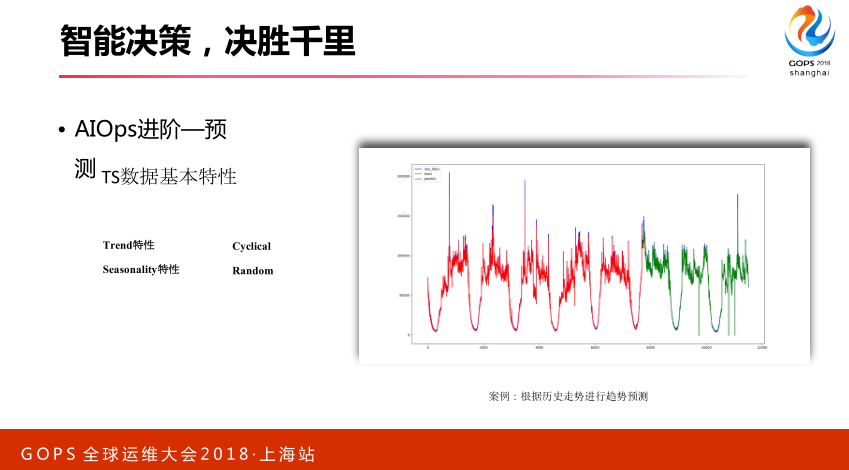
OK,我觉得AIOps的紧接,应该是预测,很少有人重点讲,我要重点去讲这一块,我们把祖师也搬出来,诸葛亮他在三国时期很好运用到了我们预测这种技术,比如我们的赤壁之战、草船借箭和借东风的故事,他通过预测的方法,他预测到11月份冬至时候有大风。根据什么来的?根据历史数据统计情况得来。我们持续数据可以运用现实运维,我们持续数据看历史情况来预测微量。我们看持续数据基本特点,它一般会有这样几个特点。第一个,我们可能有些趋势性,向上或者向下。右边的图周期的变化,它可能还有一些季节性的原因,可能复杂一点随机的看不到规律,它大概有这些特点。

对于持续数据的预测,其实我们有很多种方法。第一种方法非常简单,我拿历史的N个点来去做平均,比如广告的收入。我今天收入,我们找前七天加出来出一个七,就可以得到我明天大概收入情况。离你最近的数据可能对你影响更大,我们可以加全,我们把离最近时间点权重加大,加权平均。我只能选择N个点,非常难以选择,所以我们就有指数的平滑分法,我把历史N个点都选出来,并且也是离当前时间越近,我的权重越大,我们第三种方法。
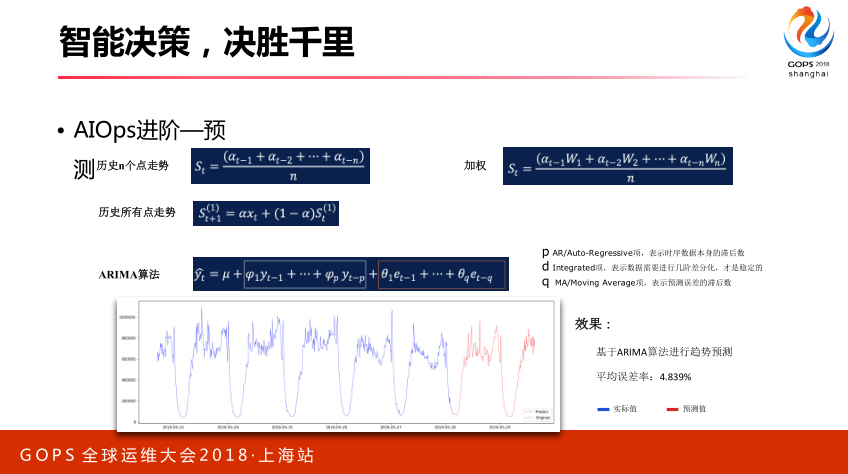
还有其他一些ARIMA算法,这些算法很大问题都有比较难以设定的参数,比如ARIMA里面设定PDQ,这个通常非常困难,也有一些自动化办法,它不一定适合所有场景,这个地方我们用了ARIMA做了对于广告的曝光量做了趋势预测,效果平均误差在4.8左右量。
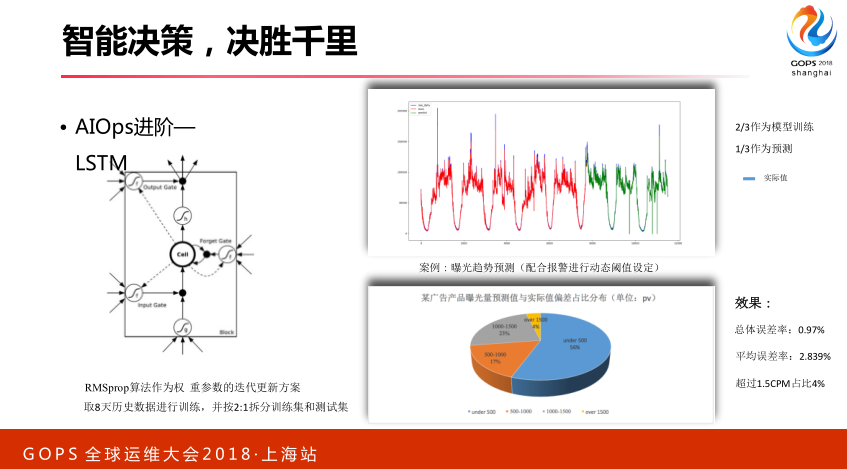
还有一种办法,LSTM,我们请出最高大上的算法出来,我们搞深度学习,搞机器学习,刚才提到的那些传统办法,决策树什么的。我们预测可以用到一些高深的算法,LSTM,它非常适合于做趋势预测,它可以把历史的数据信息,或者一些特征捕获进来,并且通过遗忘门,它有遗忘门机制,可以把历史数据特征有选择性的携带进来。通过这个,我们也做了效果,我们也是拿了广告每天的请求数据做了分析,发现了我们总的误差率在0.97,平均误差在2.839,比刚才的单纯用那个算法效果好很多。
还有很多相关的资源,大家可以关注一下,比如脸书、推特、谷歌有开源算法,大家都可以去了解一下。

