@gaoxiaoyunwei2017
2018-04-20T07:52:41.000000Z
字数 7919
阅读 1016
基因行业高性能计算系统全球化建设与运维实践
白凡
分享:刘曜玮-华大生命科学研究院
编辑:白凡
今天分享的是“基因行业高性能计算系统全球化建设与运维实践”。
1. 全球布局概览和因高性能计算系统部署区域
先讲一下华大基因在全球的布局,华大基因在全国有非常多的片区,深圳、香港、武汉、天津、南京包括河南,大部分省份都有自己的点,但不是所有的点都有高性能计算系统。海外主要在美国、丹麦、澳大利亚,包括东南亚,泰国可能今年会有一些。
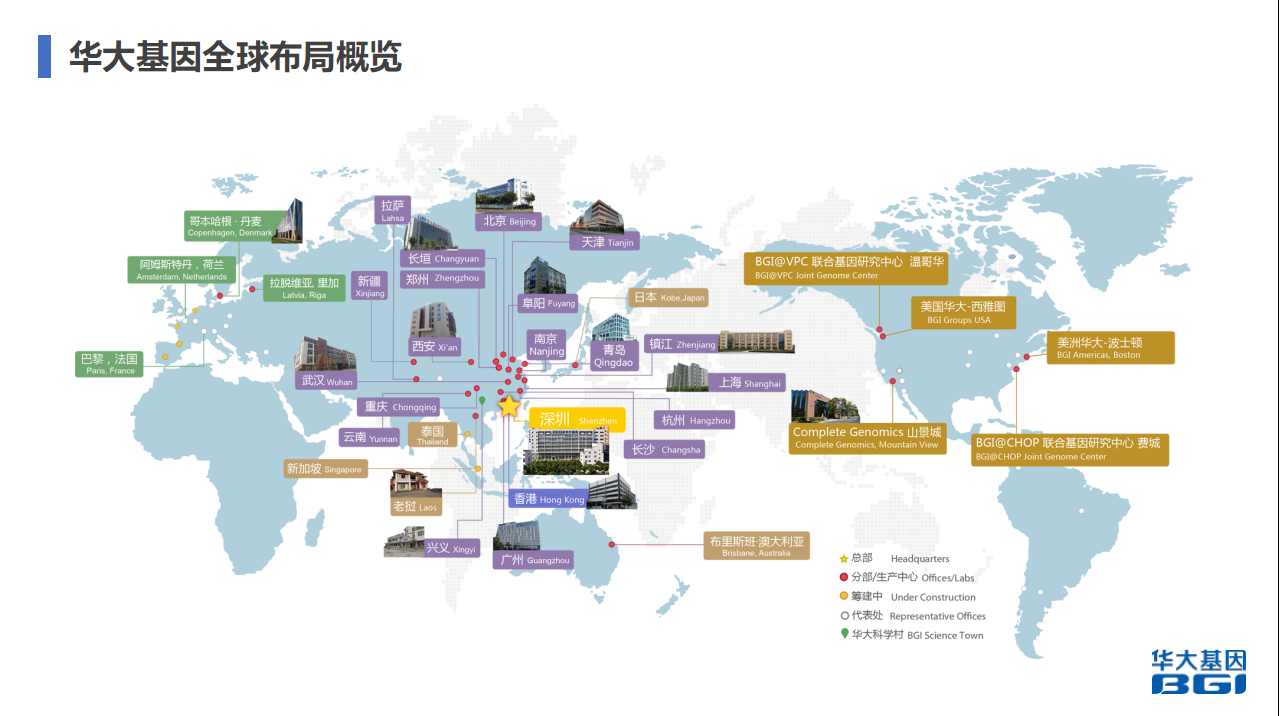
基因行业的生产系统与互联网的可能有非常大的差别。基因行业的生产系统就目前而言,借助云资源是很难实现高效生产,因为它有很多限制,包括数据量。我们在扩展每一个区域时,通常都会自己选择建自己的数据中心或者租用别人的数据中心来做。目前国内已经建好的,一个是深圳盐田,就是华大总部。国家基因库是前年和去年建的,还有武汉、香港、天津、青岛基因库,都是我们比较大的生产中心,还有北京、河南长垣、重庆、昆明,海外的有费城、萨克拉门托,还有丹麦哥本哈根,澳大利亚布里斯班。海外基本上是我弄的,国内是我们团队一起去弄的。

2. 高性能计算系统介绍
简单介绍一下高性能计算系统,基因行业的高性能计算系统和大家所知道的超级计算非常像。比如天河一号、天河二号超级计算机,我们应用基本一致,通过一套网格计算系统,调度非常大量的数据分析做法。Master Node 和Compute Node,实现不同的任务到不同计算节点,综合起来进行数据分析最后得出结果。包括气象、石油也是类似的结构。还有一个比较大的点是分布式存储。行业内主要是用的一些接口存储,我们用了大量的Lustre(编者按:一种平行分布式文件系统,通常用于大型计算机集群和超级电脑),还有一些商业的。主要是用来实现高速的补写,因为网格计算系统有大量job在同时运行,对数据的独与写有非常高的要求,包括吞吐量。尤其是生物的数据分析,生物数据分析的特征非常多,每年可能成千上万种不同的应用出来,它对分布式的要求非常高,需要满足很多场景。还有生物信息应用与数据库。我们整套系统,上面有基因组数据库,包括人的、动物的、植物的,我们测试出的一些基因组数据,典型的应用对比特征,然后组合出人的基因组数据,再从数据中挖掘特征,包括寻找变异点包括可能发生的一些变化。

2.1 快速建设与低成本运营
因为老板要求必须低成本但又能满足业务。我们通常在加强中抓住四个点,系统一定要产品化、标准化、模块化、规范化。
- 标准化是对每一个环节都进行了定义,包括刚刚说的计算、存储、监控、分析系统。都定义了非常严格的标准。
- 规范化,华大基因经过多次架构调整也经过很多版本的迭代,根据实际运营过程中的经验,在设计过程中定义在建设和运维中应该遵循的规范。
- 模块化,是整套系统的关键,包括网格计算、分布式存储模块、生物信息应用与数据库模块、监控模块、日志模块、配置管理模块等,我们有一套系统,可以快速布置和部署。
现在基因行业发展非常迅猛,这种建设的需求对我们而言是非常非常多的,可能今年就有十个或者十多个点需要去建设,但为了保证低成本,必须把整套建设流程和东西产品化,产品化之后能更快速、高效以及低成本建设,包括后期的运维,成本也会降低很多。

我们整套系统是以开源产品为主,商业产品为辅。网格计算主要采用分布式版,根据开源产品,在实际过程中定制调度策略。首先网格计算系统中任务调度的方式和特征分析。分布式存储,主要是使用Lustre。我们使用过非常非常多分布式存储,包括商业存储,但Lustre性能确实是最好的。因为它读写性能非常好,但相比而言稳定性会比商业产品要差一点。它相对于商业存储,它的成本低很多,对存储数据量的需求也很大,当时选择架构时几年前就定了,以Lustre为主,因为必须要降低成本。最开始时,主要还是选用商业存储做主存储,但发现商业存储对我们而言确实成本太高,当时高性能计算行业内Lustre算是用得比较多的产品,所以当时花了大量力气在上面研究。但Lustre研究过程中,确实有很多波折,因为开源产品的稳定性确实有待提高。经过这么多年的积累,因为它有很多东西,不仅仅是出现文化之后版本的升级,有很多参数、很多东西要去调整,调整之后才能配合自己的系统去达到一个很稳定的状态。Lustre现在的稳定性已经比较接近于商业存储,但它还是有一些风险在里面。我们在有些部分关键性存储还是选用这样的产品,没有完全用Lustre。

生物信息的应用数据库。常用的有数百种生物信息的软件、模块和数据库,但实际上基因行业的发展,现在非常非常快。每天可能都有几百种软件和流程出来,对我们而言,系统上也是压力非常大。因为在整个系统建设的过程中,不仅仅是建设整套系统,还要做它的软件和数据库,都要匹配进来,才能让做数据分析的同事最快最高效的使用。
3. 高性能计算系统建设
3.1 根据业务决定系统发展

建设过程中,可能很多企业都有这个需求,不仅仅是局限一个区域,国内甚至国外很多区域都要发展一些自己的业务。我们建设时主要是业务导向的,在实际运维过程中,会发现如果仅仅关注与自己运维方面的东西,包括IT方面、计算机方面的东西,是远远不够的,必须了解业务,至少对基因行业是这样的。IT人员包括运维人员对业务必须非常熟悉,因为它的变化太快,是一个信息化的行业,没有办法从其他公司借鉴到很好的经验,这种情况下只有深入了解业务,理解业务,在建设和运维时才能做得好,做得高效,成本也低。
建设时还有一个业务一致性,在建设过程中,可能老板说美国要建一个实验室。美国主要是一些医院和学校合作的实验室,需要出一个方案,这个数据中心大概设备要多少,预算要多少。这时候就很头痛,因为你不知道业务是什么情况,老板跟你说大概业务是多少,其实它也只是一个估算。但实际上可能并不像老板预测的业务发展那么快,这时候就要自己去评估业务量、数据产量、计算需求量,然后控制成本。这时候你要考虑前期时需要建多大,但又不能建太大,建太大对成本是非常大的浪费,不能建太大又如何快速扩展。这是你需要考虑的东西。有时候业务真的发展得很好很快,包括你支撑的一些服务器、存储满足不了时,是否能在半个星期或者一个月内把它搞定,通过采购迅速把它部署。我们在交互系统时要注意一些东西,如何快速交互。
业务扩展性,必须保证能够非常高效,扩展成本可控。成本可控,不仅仅是刚才说的为什么要采用商业产品。采用商业产品在扩展时也有一定的问题,包括成本和效率。因为在商业产品在采购和部署时,尤其是在海外,可能会遇到一些问题,包括不能按时做到。但如果使用自己的开源产品,可以再去扩展、建设、购买时,周期会比较短。
3.2 评估与建设落地
在建设过程中,主要几个步骤,确定业务需求,评估基础设施。不知道大家有没有做过基础设施建设。我们在做高性能计算系统时,必须要做基础设施建设。要么是我自己去建一套数据中心。因为很多地方确实是自己建的,美国、丹麦、澳大利亚都是。国内有些区域是使用的,因为有些区域是和医院合作,当时医院提供了这个场所,你去购买设备就可以。但一些大型生产中心还是自建。
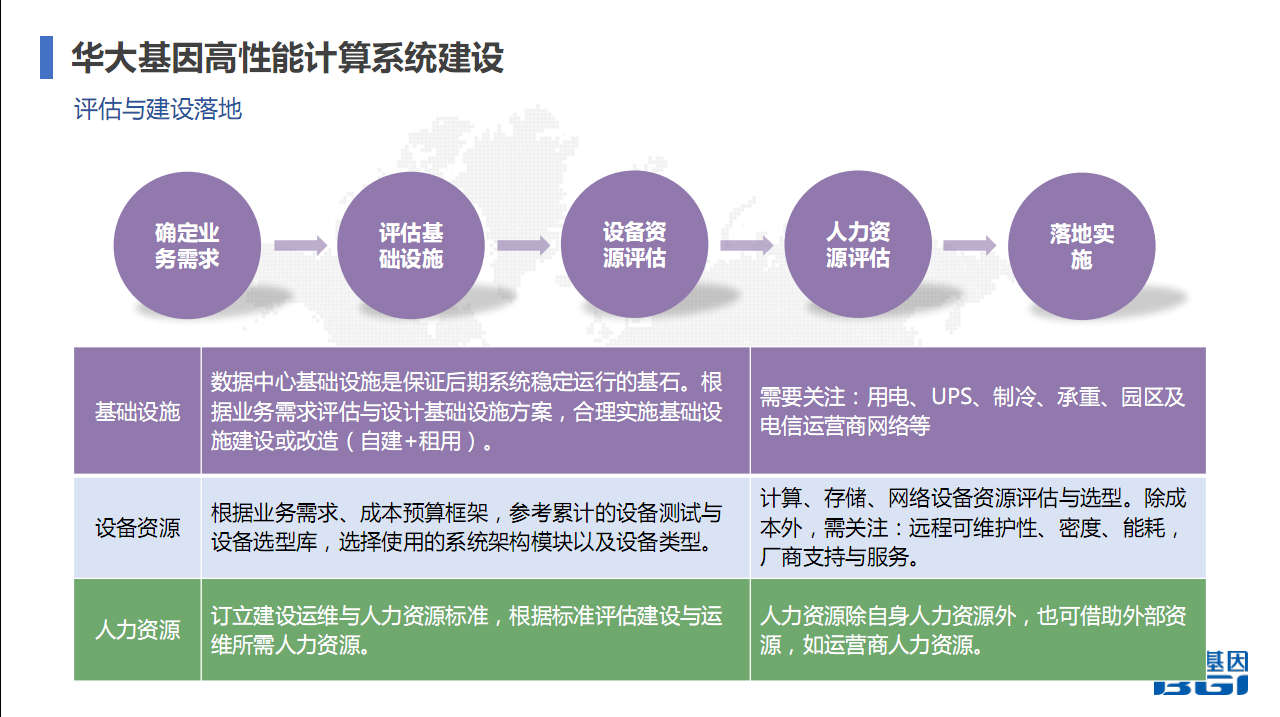
自建时,基础设施的评估非常重要,因为基础设施决定了上层的硬件、服务器、存储,再上层就决定了应用的稳定性。一般在基础建设时,一些标准化的东西,要关注用电,评估你的设备,在未来三年或者五年时间,大概有多少设备,大概需要多少用电,然后就可以估算出一个用电的需求量,提交给建设方。UPS是你根据自己的业务特征。比如我对用电的业务连续性有多高的要求,在停电情况下,需要保障多久。停电,在发达国家美国、丹麦,五六年了还没有停过电,但国内确实有这个可能,在建设过程中电力中断时有发生。UPS有必要,但要根据自己业务的连续性要求去做,因为建设又不能太大,根据合理要求建设。包括智能,你要估算设备有多少电量和热量产生,需要综合它的热量。承重也是我们这边要考虑的问题,包括在建设数据中心时,我们因为和别人合作,可能是使用别人的楼宇,不同的楼宇对承重有不同的标准,尤其是一些商务楼,承重没有那么多时需要做承重加固等等。
第一步是基础设施,第二步才是设备资源评估,根据业务需求、成本预算框架,我们参考之前的一些设备、测试和选型库,选择一个系统的架构模块以及选择合适的设备类型,包括在选择服务器时选择什么样的,选择存储选择什么样的,选择什么样的分布式存储,都要根据自己的业务需求去确定。
人力资源,除自身人力资源外,也可借助外部资源,如运营商人力资源。在发达国家招人做,成本非常高,我们通常海外是采用一些远程,当地的同事做。后来就采用另外一个方式,运营商在不同的国家会有非常多的资源,包括他们有自己的IT支撑人员和技术支持人员。通常会和运营商合作做这个事情,购买运营商的服务。包括中国电信、华为,在海外也有很多。我们会和他们签定协议,我们需要你们支持,因为你们当地有人力,我们付一部分费用。这个对我们来讲成本降低很多,高效很多。现在海外的点是运营商人力资源做。
4. 全球化运维
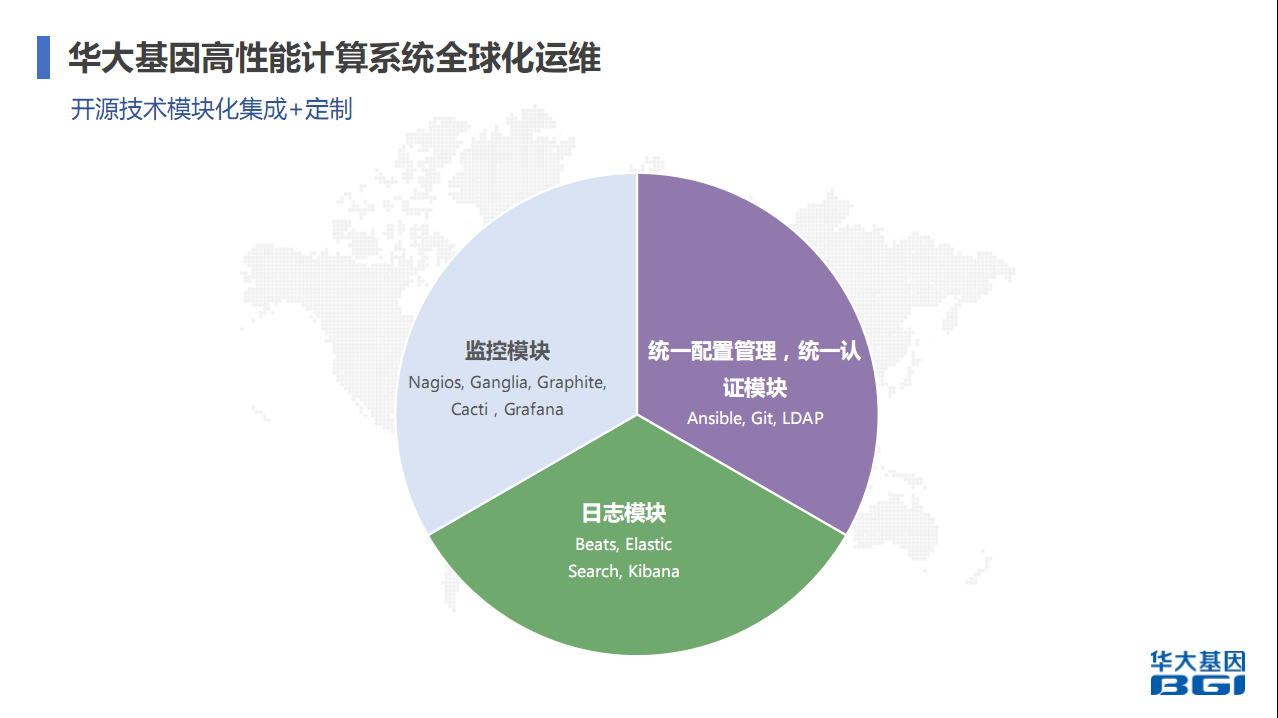
很多企业都是采用开源技术模块化继承,在上面修改、定制,做自己需要的功能或者东西。
4.1 监控模块
监控模块,用的比较通用的东西,包括Nagios是比较成熟的很多年的监控产品。Nagios主要用来监控和存储。我们存储非常大,设备种类也非常多。监控用Nagios主要是实现设备健康监控和报警。Ganglia是做计算服务器资源上的监控。Grafana做数据收集和展示,Cacti是做数据管理。统一配置管理和统一认证模块,我们有多个系统,整个系统需要做统一认证肯定需要一套认证体系。统一配置管理用Ansible和Git,等下会讲为什么选Ansible,为什么会结合Git,Git有分布式管理和版本管理,对配置管理会有非常大的帮助,因为多区域时,包括多个数据中心时,它非常有效。日志模块用得多的是Beats、Elastic、Search、Kibana,主要是用来收集系统各个模块的日志,然后分析,包括后期要做的一些AI也是基于日志和监控数据做AI。
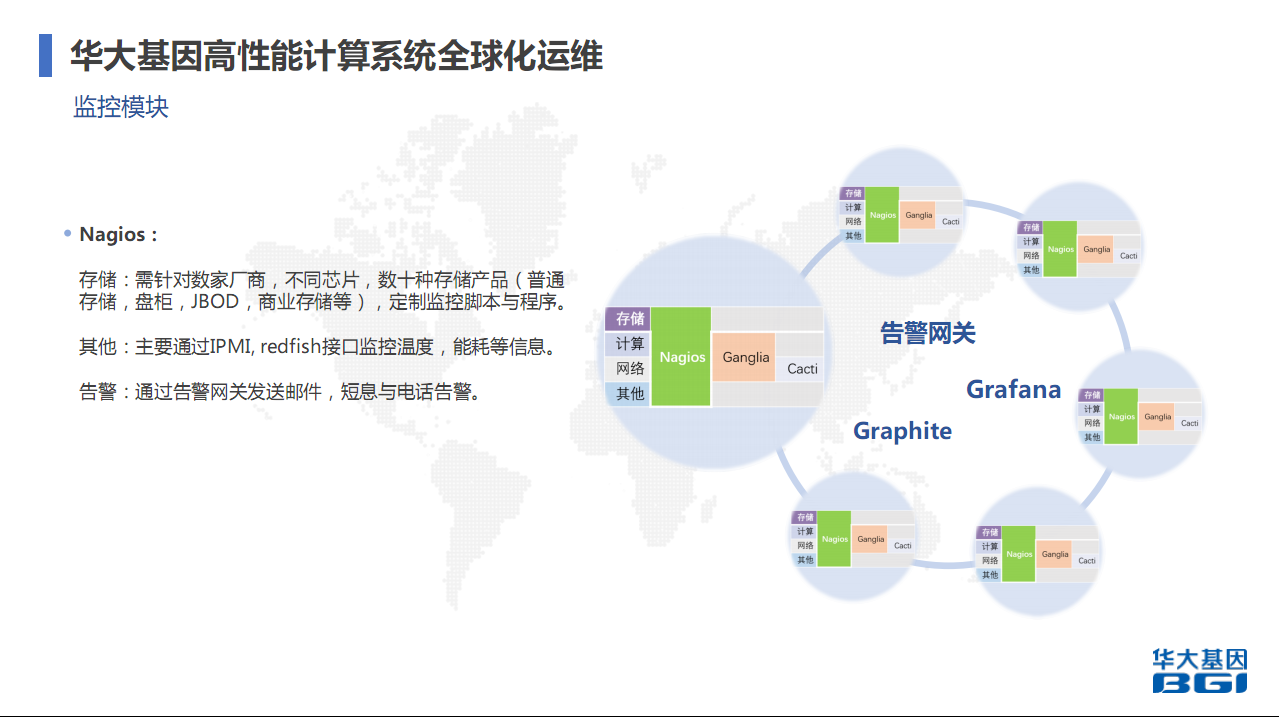
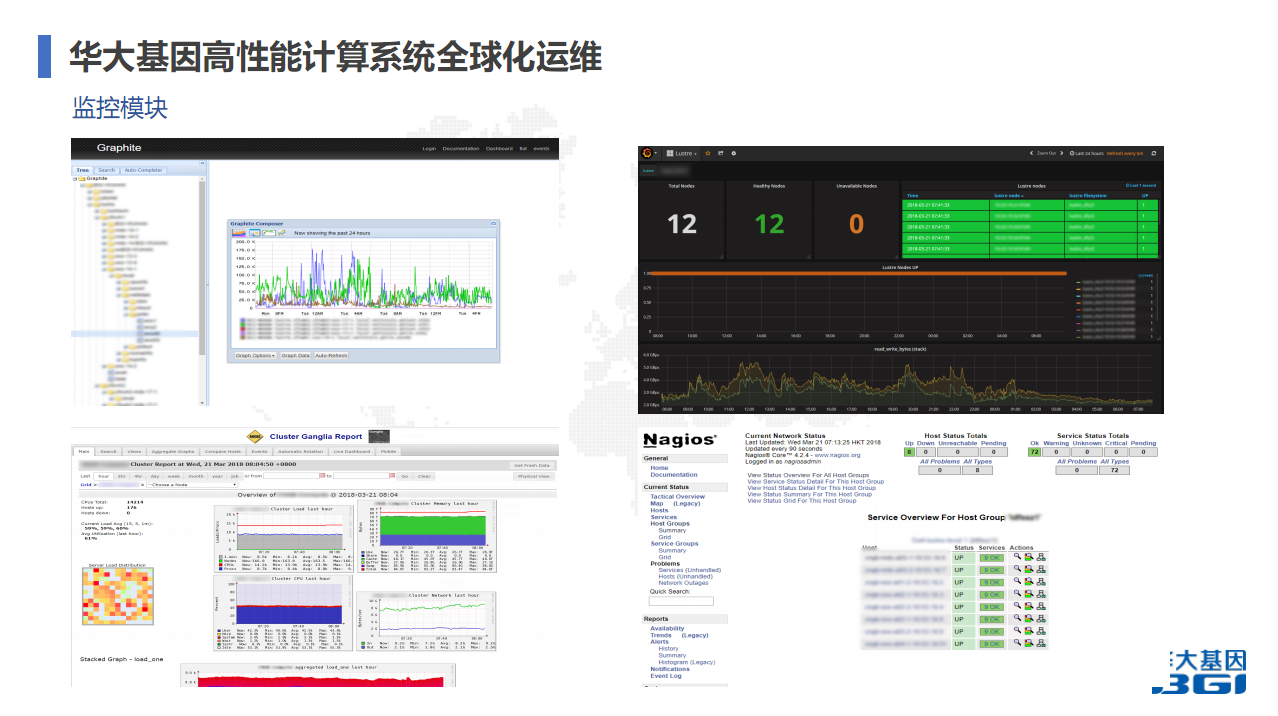
监控模块,存储需要用到Nagios。主要是Nagios能够定制很多脚本,因为存储服务非常多,包括普通存储、盘柜、JBOD等等,有不同芯片,程序也不太一样。现在也有很多公司在做这些产品,也可以去采用他们的,但我们从一开始就是自己做,针对各种产品和芯片做自己的监控脚本与程序。IPMI是监控温度、能耗等信息。告警网关当时选择了很多家,后来还是自己做了,主要是实现邮件、短信和电话告警。Nagios监控了存储,但部分计算和网络也监控。每一个区域每一个点都会部署这些系统,每一个系统都会有Nagios、Ganglia、Cacti进行监控,通过告警,最后所有告警数据都通过Grafana收集,收集其他通过Grafana展示出来,然后再汇集到一个点,对所有区域都能掌控它的监控信息。
监控模块,这是几个截图(见下图),有些信息安全的需求,把一些东西模糊掉了。Cacti可以监控很多数据,Grafana主要是用来展示的,Ganglia主要是用来监控计算服务器在运行程序时所具有的一些特征。这不仅仅是监控,因为可以分析到CPU使用率、网络使用率、内存使用率。这些都是都是后期采购服务器或者设计系统时需要参考的数据。尤其是你在采购时要决定服务器应该使用什么规格的,内存和核心数大概是什么配比的,都是通过历史数据来获取的。Nagios网络设备存储告警。
4.2 日志模块
主要是采用开源Elastic Stack。Beats主要是通过日志采集,通过它获取设备上各种信息,基本上所有信息都能抓到,然后采集过来。通过Elastic Search 主要是用来搜索,分析与存储也是基于它。 Kibana是数据可视化,能够非常直观的看到一些东西。这是一套现在用得比较多的日志系统。

重点关注的是调度系统日志,上面的任务有哪些特征,对整套系统的稳定性有哪些影响。这些都没有得到一个很好的数据,所以我们想通过现在在做的事情,去分析它,最后想实现的是调度策略的智能化。现在的网格计算系统调度策略主要是自己根据自己的经验去定义,包括你的job应该在那个上面,哪一个队列的效率会更高。但这种人为的干预,对人的要求比较高,压力比较大,效率也会比较低。现在主要要做的,就是调度策略的智能化,包括一些混合调度,将所有的平台集合起来调度。这是我们现在正在做的事情。分布式存储的日志,用来后期存储智能HSM。HSM是存储的分级管理。数据有冷有热,现在主要定义的是一级、二级和三级。但一级、二级、三级包括我们自己还有一些商业的产品,他们都能定义你的数据流动,比如数据冷热时从一级流到二级或者从二级流到三级。但我们觉得这个策略对我们而言,可能还不够那么精细,所以后期可能会做一个存储智能HSM。
4.3 统一配置管理
我们在多个区域时,有区域一、区域二、区域三、区域四,就代表很多不同的区域,包括美国、丹麦、中国香港、武汉、天津、深圳。在交互系统时,DevOps能够保证快速交互。当时我们选用的在建设系统时一键能完成部署并交互出去。但有一个问题,现在多区域时,配置管理怎么做。我们借助GitLab,为什么要用Git的版本协同管理,因为可以实现多用户的贡献以及版本管理。一个团队内可能有不同的人负责不同区域,不同区域在做时,需要保证每一个人对它的修改都能可追溯,可以有效控制。
我们当时选了Git,它可以多个用户提交。比如这个配置更改之后,只要提交审核,审核之后才能变更。这是一套流程,每一个区域有统一配置,不同区域又有不同配置。可能区域一就是一个Branch1,区域二就是Branch2。比如管理用户要改一个配置,早期可能没有这个管理时,就人员上去改了之后就下发出去了。很多年之后我们发现这种不行,配置后来很乱,因为不知道谁改的,也不知道怎么追溯,出现问题也不知道怎么回溯。建了这套系统之后,现在如果要更改一套配置,用户必须在Git上提交,提交之后要经过审核。因为每一个Branch都有自己的审核人,审核之后点击确认修改没有问题,再通过webhooks,就要一个合并的过程,把你所提交的配置信息合并,合并之后就自动推送到各个系统。如果修改的是区域一的,可能就推送到区域一的系统,修改区域二就推到区域二。它是用来保障整体区域系统的有效性和一致性,也保证它的灵活性,因为每一个区域都有自己不一样的东西。

统一认证还是用的OpenLDAP,但我们对OpenLDAP定制了,定制的东西是Schema。Schema也是针对多区域的,最开始一套系统不会有问题,但有非常多系统而且分布在全国各地时,就会出现很多问题。包括用户能不能登录到这个区域,这是原始没有的,但我们修改Schema定制自己的策略。
4.4 AI + BI
基因行业有两个AI方向,主要的方向是业务层面,医疗影像数据。医疗影像数据是非常火热的AI方向,医疗影像数据进行深度学习,进行智能判别。以前一个医生只能看十张片,但通过AI一套系统可能10分钟就能出来。但我们做的主要是运维层面,并不是业务层面。运维层面主要是信息调度系统。我们有非常多基因组数据的分析日志,包括特征和对整套系统的影响,包括资源的耗用情况。我们主要学习它,刚刚提到的智能运维、智能调度。在座不管是其他超级计算系统都会有遇到一个资源利用率的问题,我们希望通过AI去提高资源利用率,保证job最有效最快速的运行。
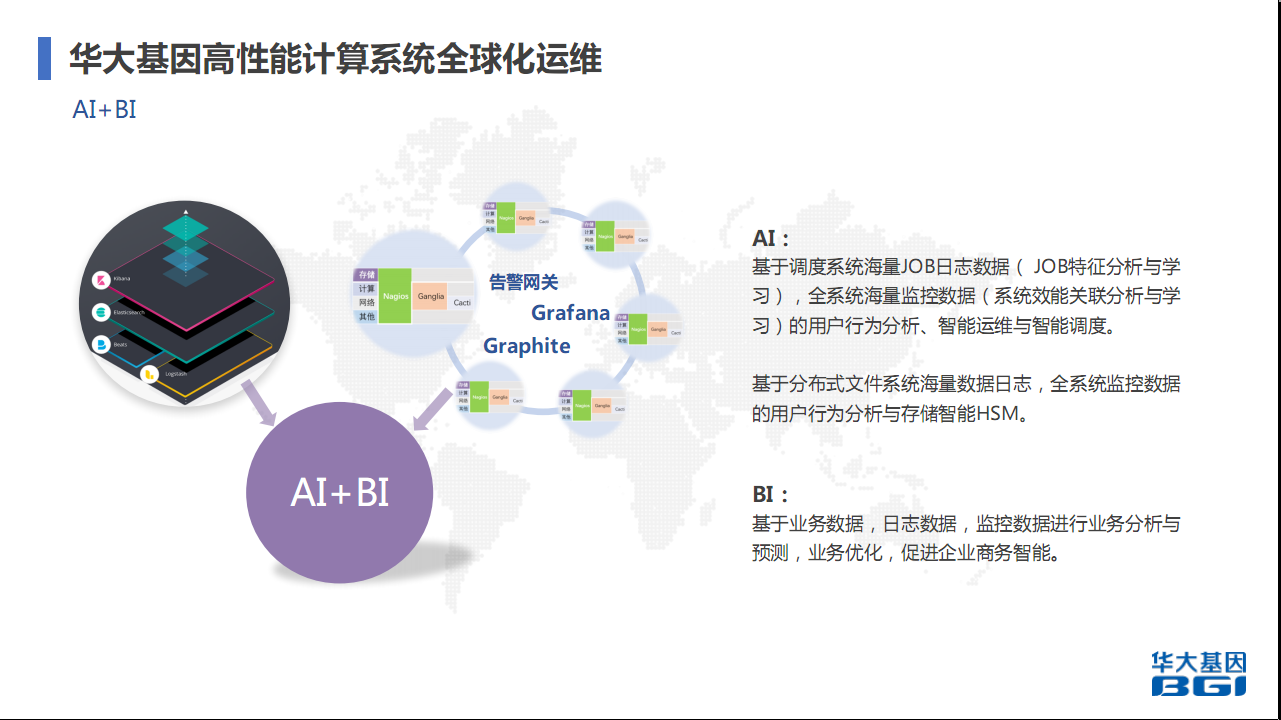
BI主要是基于业务数据,包括综合自己的日志数据、监控数据再加上业务数据。你的业务线业务成本是多少,最后的产出是多少。通过它对资源的耗用还有耗时,进行业务分析和预测,再业务优化。主要是给到老板一些数据,这个业务线大概多少成本,对比其他业务线是否有优化空间,然后老板再决定今年会在哪一个业务线上做调整,或者这个业务利润更高,可能会做一些更侧重于它的工作。
5. 目前面临的更多挑战
现在我们面临着很多挑战,这是基因行业的特征,数据量很大。举例,一个人的基因组是3个GB。为了保证数据的准确性,通常会测30倍,一个人的基因组大概就是100GB,有特殊要求时会测100倍,大概是300GB的数据。在基因测序过程中,除了基因数据还有质量数据,加起来之后会乘以3。一个人就会有300G的数据产出,还只是人的基因组数据产出,后续的分析数据不算。现在基因行业发展得非常快,越来越多人参与测序,很多样本都过来,数据量非常大。我们的存储年增量100PB左右,还没有算上后续的,后续业务层面影像数据等可能这个数据量还不止。我们需要对成本进行控制,包括海量数据如何管理,这是我们现在面临的挑战,也在和其他一些基因行业研究院做这个事情。
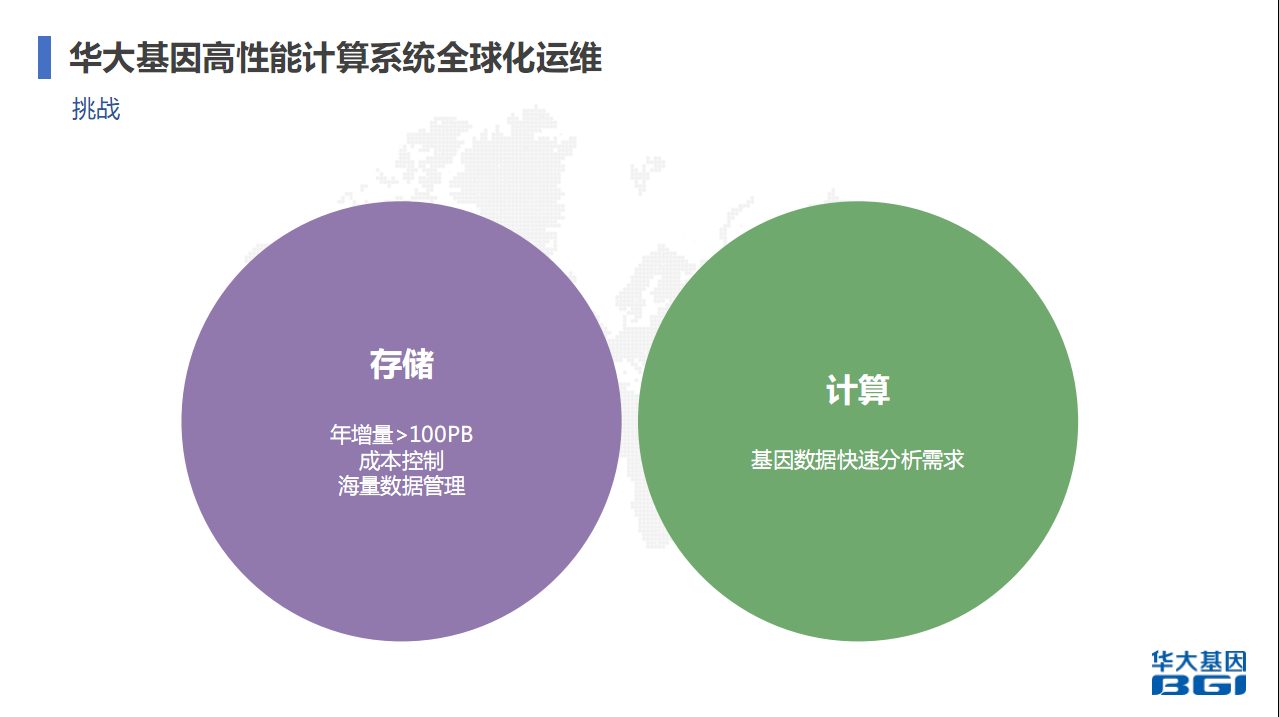
计算方面面临的挑战是基因数据快速分析需求。早年你分析一个人,可能一个人的全基因组数据需要几天时间,几天时间得到变异信息,主要看差异和缺失,诊断情况,包括疾病的关联程度。但这个时期在某些场景下是不会接受的,尤其是疾病场景下需要迅速得出结果。现在整个行业都在做的事情是加速分析这个过程。目前全基因组有不同的方案,普通方案CPU方案是一天到一天半左右得出,通过软件优化可以到半天。还有FGPA方案,就是一套全基因组测序下来得出变异结果就30分钟。
存储,Lustre可以降低成本,还有自己的特性。Quip,因为我们做数据时会进行压缩,早前我们使用Gzip(音)。Gzip压缩有非常大的限制,因为它的算法决定了在解压时没有办法并行做这个事情,它的压缩率也有待提升。后来这个行业有人做了Quip的压缩软件。主要针对一些基因组数据特征。基因组数据就是ABCD然后一个排列,有很多特征可以直接压缩。当时有人做了这个,我们也采用了这个,Lustre HSM+Quip。 我们在做一级到二级到三级存储流动时会自动做Quip的压缩,对用户是透明的。这样成本可以控制。比Gzip压缩提升70%左右。尤其是数据量达到百PB级增量时,非常明显。
现在和别人合作的是FPGA的压缩,它压缩时会非常快,但解压时提升没有那么明显。因为FPGA的算法现在做压缩基本是基于Gzip来的。QAT是英特尔的,处理器上带的,它也提到压缩和解压,我们也在做测试,包括看能不能应用到生产系统里。还会用到一些开源并行的压缩算法。存储主要是刚刚说到的,为什么要做压缩就是为了降低成本,因为成本非常高。数据管理问题,之前有做iRODS的数据管理系统,形成一些知识图谱。
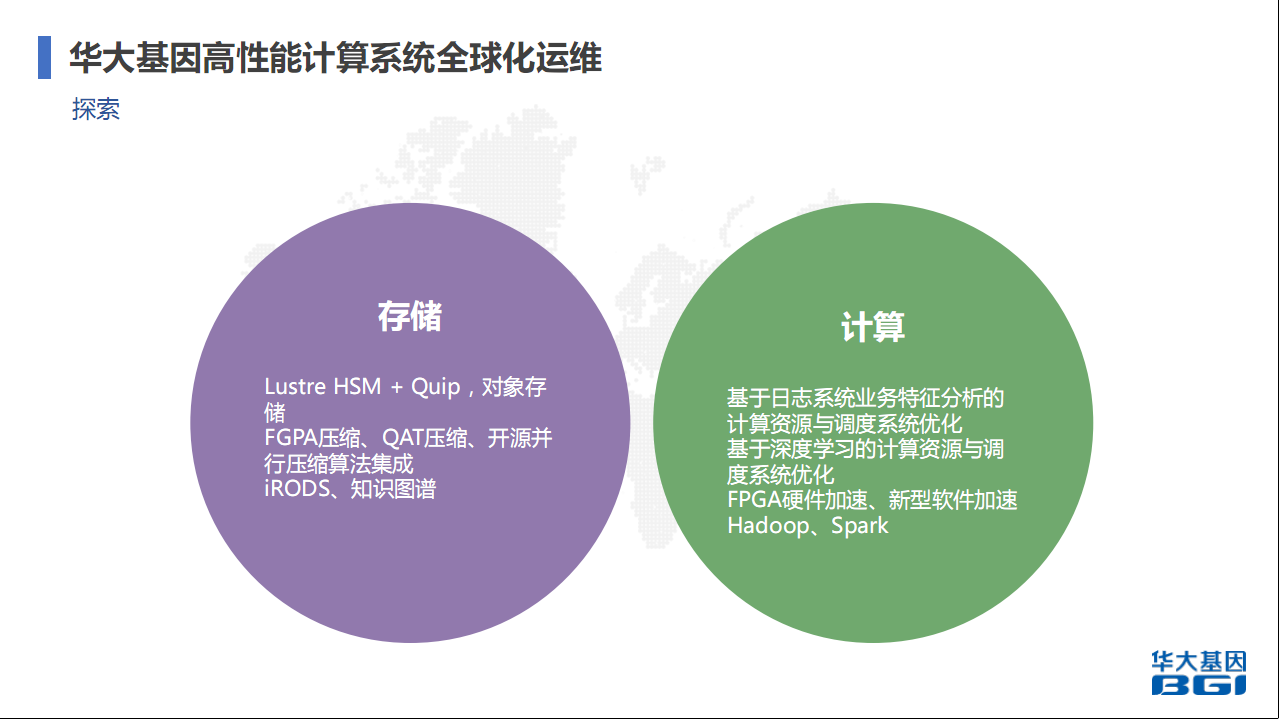
计算,现在主要做日志系统业务特征分析的计算资源与调度系统优化,基于深度学习的计算资源与调度系统优化。现在在收集日志,优化日志的搜集还有集成工作上。FPGA硬件加速,FPGA是基因行业非常大的行业。可能我用普通的CPU算要用一两天,但用FPGA很快。美国很多人在做,已经有厂家出了这些产品,能30分钟出来人基因组变异结果,这对以后的诊断和医疗有非常大的帮助,因为它能很快的得出结果。尤其是病人需要快速得到结果快速设计疗法时。不知道大家知不知道现在关于疾病诊断治疗的东西,基因有非常大的突破,包括癌症等等,很有可能是几年之后能被解决的。身边一些例子可以看到他们之前有一些传统的疗法包括化疗药物都不行,后来用新的疗法,能控制得很好。但这些很多都是基于基因数据。包括人的基因数据测序、快速分析,得到基因的变异包括一些特征,最后针对这个设计你的基因疗法。我们对未来也有非常大的挑战,包括未来如何快速加速,给到病人一些指导结果。刚刚提到FPGA、对象存储、网格调度系统,包括Hadoop、Spark我们也有用到,深度学习和知识图谱是我们正在研究的方向,谢谢大家!

