@gaoxiaoyunwei2017
2018-05-11T08:23:03.000000Z
字数 8100
阅读 1531
社交业务运维基础技术选型与演进
luna
作者:孙亮
作者介绍:孙亮,来自于腾讯社交网络运营部,在公司人称三叔,是一个十年运维的老同事,腾讯学院讲师。

前言
我索性用我当时想到的四个目录作为今天的内容:第一,软件包管理,这是整个运维体系的核心基础;第二,路由管理,围绕着我们08年游戏分布式的建设来给大家阐述;第三,技术管理的角度在成本节约方面起到的作用;第四,智能监控,织云AI运维。今天分享的点都在我们织云里面真实的落实。

1. 高效率发布,织云包管理
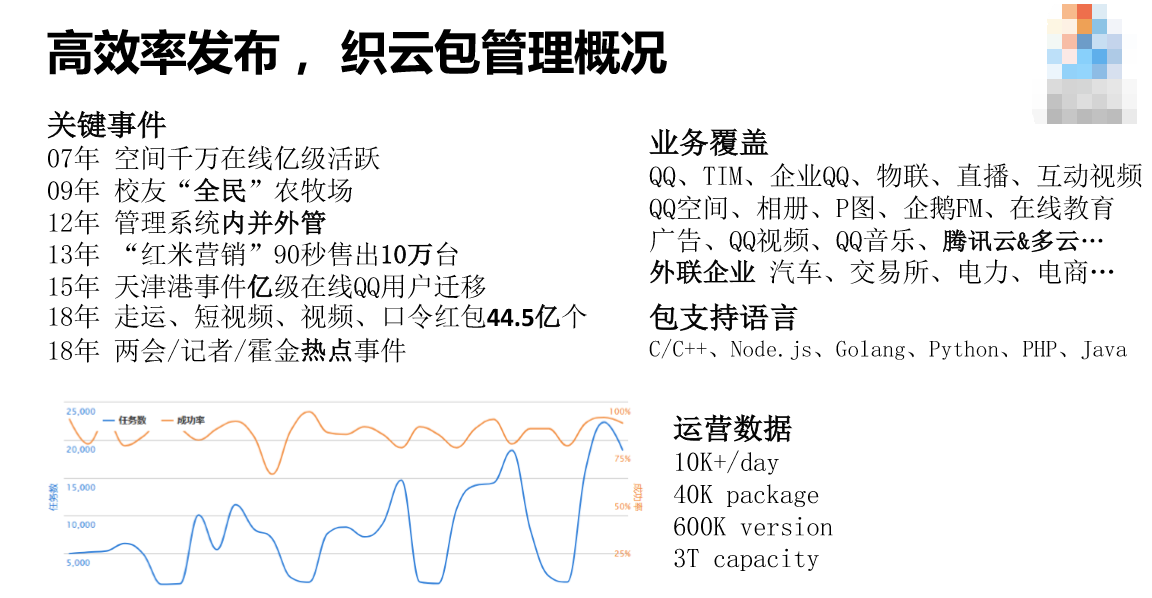
软件包管理的概况。首先是关键事件,我们最早通过高效的分布、敏捷的迭代,帮助空间业务在发布两年之后就做到千万在线亿级活跃。这个产品风风火火两年之后,由于运维和开发人员一起的高效迭代能力,我们把一个非常小的游戏上的产品做到全中国第一款全民级的产品。2012年公司内部有一些衍变,管理系统在公司内部有延伸出去的产品,也有并进来的产品。2015年发生了一件非常重要的事情,8月12日发生天津港化学爆炸,这个过程中间,决定离我们爆炸点非常近的QQ用户到底迁移还是不迁移,这是我们运维做出来的。我们考虑的主要点是异地容量够不够、爆炸的力度要不要迁移,从来没有怀疑过软件包对运营情况的监控是不是有差池,帮助我们决定的是在容量上面,而不是软件到底运营正常不正常。2018年有一些热点事件,帮助我们扩容。
业务覆盖方面,我们覆盖QQ和QQ空间,两大社交都有运营。我们的软件包支持一些多云的管理,包括腾讯自有的产品,还有亚马逊的一些产品,帮助我们的产品能够出海,通过软件包的发布遍布到全球。还有一些外延的企业花真金白银购买我们的产品,像汽车更看好我们的标准化,电力行业也很看好我们。下面这些数据大家自己可以看一下。
运维是服务研发的,研发是服务业务的。我们的软件包服务于什么业务呢?“你是夜空中最亮的星,指引我走出迷茫和黑暗。”这是07年的产品,这个口号非常有范儿,还在意识形态上影响了当时非常多的年轻人。暗黑系、非主流,嘟嘴卖萌,这都是当年的产品。这样的产品当年也不是一帆风顺,因为我们有竞争的业务,是把互联网当作国家战略的Server,有竞品就有竞争,有竞争就有“敏捷”模式,每个运维人手上都通过脚本登录到机器上操作发布,往往给自己的队伍埋下很多坑。
业务的发展,通常来说是开发人员先上,测试人员补充,运维人员最后。业务发展很快的时候,运维人员是最后补上的,那时候是人人都做发布。风口的业务会快速聚集大量人才,这些人会带来各种各样的软件包和开发模式,那怎么才支持我们的业务,跟我们这么强的竞争对手竞争呢?我们建立一个轻量级的发布,找出每次的差异化,并且跟研发和测试沟通好,要求他们交付给我。今天我们也经常提及“交付”,要把软件和软件相关的书信交付给我,包括它的名字。还希望做到线上和线下的映射,我看到线上是什么线下就是什么。

我们版本的差异软件主要有三大产品,前面是Windows的东西我们没有选择,后面对社区运营管理不是太好,所以我们选择了SU(音)这样的管理软件。
这是一个图(见PPT),大家在这里通过软件包接口上传去,然后反馈给用户,用户在界面完成。发布更新的时候,通过软件包的接口拉取我们需要的软件,更新或者存量的,下发到服务器上面,并且到数据库里去交付数据。运维同学在发布的时候就已经解决了这个问题,不需要再跑到机器上做这个事情。
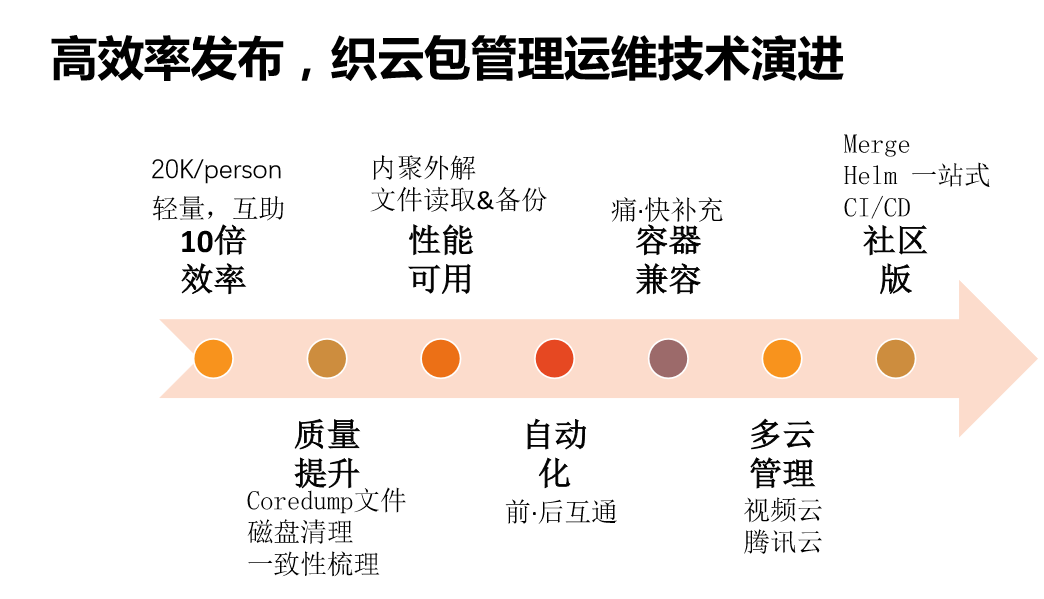
我们看一下是怎么解决后来遇到的问题的。我们现在一个人可以运维2万台服务器,今年春节的时候,有一个叫戴维的同学运维28000台的服务器。我们有了交付,所有的发布大多数都是开发自营的发布,我们不发了,因为领导觉得业务先行,我们把发布交给开发,我们把人力投入到建设上面,包括质量提升、性能提升、自动化,这是非常正向的发展方向。
从质量上来讲,我们怎么管理软件包的质量?大家都知道,这是一个dump文件,这是难以避免的文件,因为开发的质量参差不齐,这是操作系统应急保护机制,当我们的程序被访问中的时候会有这样的文件产生。最重要的是我们做成插件化,跟软件包框架合在一起,要提交给我们的开发,让开发尽快的把它拿到手,修改它的大小和路径,判断产生的原因是什么。
一致性梳理的时候插件为什么会产生?线上的环境不尽如我们预料,会产生不一样的情况。这么多年来有两次演进,原来我们主要的数据是通过每个人扫描自己的状态上报给我们的DB。我们发现这种架构不太适合统一的配置,我们把它改成了Server的架构,又Proutable(音)上包给server架构。原来我们的上报主要是定制扫描去上报自己的情况,但是遇到了一个问题,伴随着虚拟化越来越多,非常非常多的虚拟化之后,母机跟子机的比值越来越小,母机越来越少,子机越来越多,如果我们用Proutable的形式就有问题,需要我们优化。
我们把包管理统一到我们接口来,外检是把放在这里管理的接口梳理成统一的模块,通过消息队列的形式实现下发。把成功与否写入我们的数据库,这个数据库是外部界面里面可以看到的数据库。
因为代码是一个公司最核心的资产,除了这里面不可重建之外,还有一个重要原因就是,一旦泄露,安全就像脱了底裤一样。我们有一个自己的RS,也有其他公司的RS,我们自己的RS主要是推,其他的RS主要是拉,因为自己的RS好控制返回,时效也高,其他公司的RS我们会牺牲掉一些返回,因为网络质量比较差,会慢慢的返回,我们定时会去检查。
我们自动化是两面,向前和向后的。向前的自动化是从产品开发到测试,测试完再到自动化打包,然后再到线上,再到部署全面。向后的自动化主要是指故障恢复等等,所以我们还做了自动化接口的支撑。
从我的角度来讲最难的是容器兼容这一块。跟容器怎么结合?也就是Docker。为什么我又写成“容器”呢?因为这里面有“痛”和“快”。Docker有一个核心是它是虚拟机,我们使用虚拟机一直不是太顺利,因为我们不知道虚拟化给技术带来什么好处,但是给业务发展带来什么好处是需要思考的,我们原来使用的虚拟化是伴随着社区的支持,我们适用之后逐渐切入到容器上面去,但是事与愿违,我们并没有从这个虚拟化上得到好处,反而给运营带来很多负担,比如说失控。运行着很好的时候,它出现问题,只能释放之后让它重启。我们所有的高效率发布,当前比较稳妥的是把所有的发布放到我们的虚拟机里面,从我的角度我认为是差不多的,因为所有KVM(音)跑起来之后,CPU也是共享的,并没有在成本上有太多差距。明白了这一点之后,我们将要实现的方式是用KVM作为RS供应的载体,把Docker只认为是一个发布方式。我们为什么要这么做呢?我们的核心优势是有轻量和可以交付,但是Docker的交付是囫囵吞枣,交上去所有的东西并不知道里面运行的可能是一些什么东西,因为对它丢失了管控,Docker可能会是一个整体的开发环境,不知道里面会是什么,所以我们需要有一个互补的补充功能在里面,我通过软件包管理的一些规则声称我们的Docker,生成的Docker满足一个轻量和互助的功能。
怎么做呢?我们来模拟一下(见PPT),每次发布要解决一个产品,发出去的Docker不是销毁然后再更新,而是比较两次发布的内容不同,将差异化的东西发布,然后再看软件的执行、操作这些东西,我们将容器里面新的软件重启,这样就满足软件包的轻量和互助的思路。Docker对我们包管理另外一个是更加接近社区的发展,比如说兼容。除了做Docker差异化发布的内容之外,我们还有Helm的包管理方式。我这里只是讲,我们未来会将包管理做成一站式的组合管理,把若干相关功能的包加上一些监控统一打包,一起发布出去,大家拿到的包就是可以直接提供服务的。
2. 高可用容错,织云路由
包管理讲完了,接下来讲一下织云的路由。
右边的这张图(见PPT)是带有网络设备图标的流程图,我们看一下这个流程图主要包含了哪些内容。上面一块有线的细的路由和下面粗的路由。普通用户访问我们的路由器,返回的接入网关在这里,然后通过转发到接入应用型服务器。通过转发,在这里修改原地址,在这里加入序列号,以至于我们拿到这个请求看到的时候就是来自用户端,在逻辑服务这个上面优化,然后再进行返回。
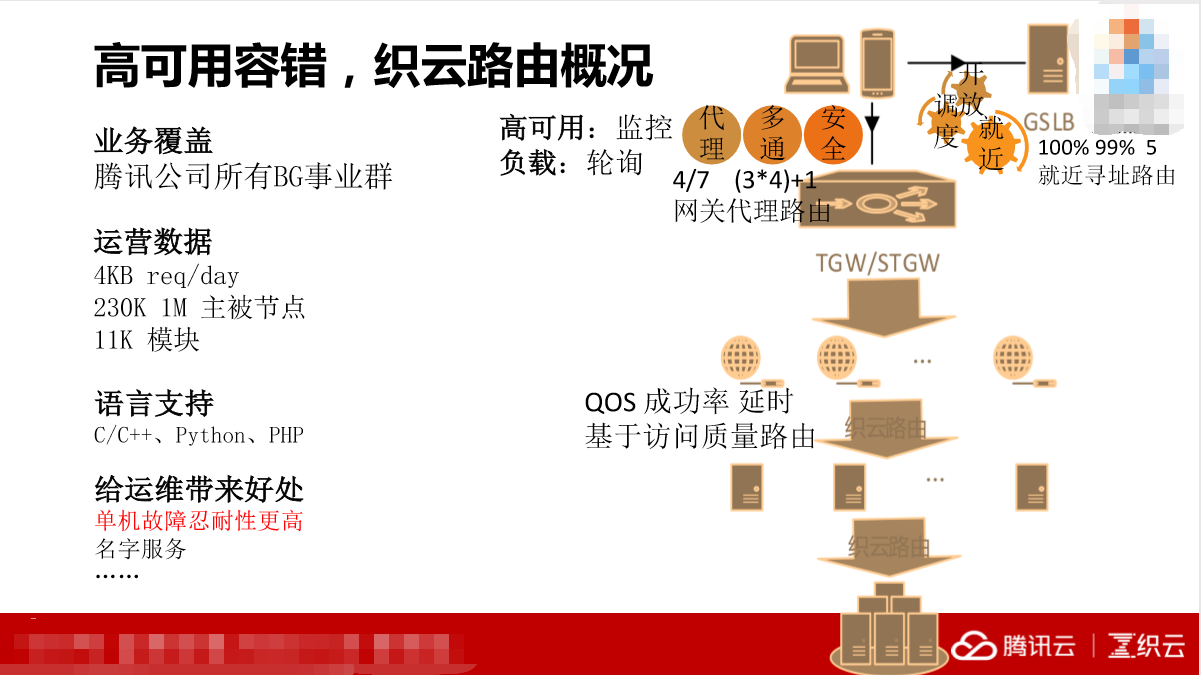
这里面有两类,在我们服务之外的路由和内部的路由。这两种路由大家非常熟悉,一个是基于BS,一个是基于LVS。主要实现的目的是就近调度以及开放。就近调度跟国家一些网络上的数据做结合,能够快速锁定我们用户的具体位置和IP地址,最快的接入给他。运营商在机房定时监控接入层和网关的代理情况,当发生质量波动的时候,它会把服务从我们的一个区域调往另外一个区域。另外,开放当中遇到一些问题,比如说运营不够用了,以及一些其他的问题,我们系统做了两套分割,压缩这个算法。
讲一下网关代理。在没有代理的时候,一个服务如果想把我们的服务提供给互联网的用户来用,必须就要有外网,但是外网是非常稀缺的资源,所以我们做了网关代理。它有一个好处,隔绝掉外网对我们的访问,让我们更好的服务,效率非常高。它还有三通、多通的作用,我们部署的业务通常只有一套。众所周知,在中国的网络环境里面,由于结算问题、由于网络质量问题,很少有人愿意跨网络。我们在一个城市、一个区域里面会部署一套服务,但是会部署移动、联通、电信以及小运营商。我们有一个“(3×4)+1”,“3”是指上海、天津、深圳,“4”是移动、电信、联通和小运营商,还有一个“1”是香港。这里接入的时候可能会做一个转换,因为有一些上传的服务不能直接留存,要找相同的服务器,比如说下载。
讲完了外部的,再讲一讲内部路由。在我们服务之上本质不同的一点是内部路由的设计理念,这里面有非常多的冀中的解决,所以我们一定要关注这个请求链路上每一个请求的成功率和延时,来决定我们的路由应该去怎么设计。
路由设计完了之后给我们带来什么样的好处?运维的同学有了这个路由之后,就从温饱变小康了。为什么呢?因为如果发生了单机故障,你再也不用刚躺下就起床了。坦白说,如果一个运维人员出了其他故障可以找开发和测试一起来背锅,但是如果一个服务器坏了你不去修,这个锅你是逃不掉的。私底下说,我觉得这个对运维人员最大的好处。
从社交网络这个事业群推广到全公司去用,这个运营数据是每天有4万亿次请求,不是指QQ请求的数量,而是指路由被请求的数量,我觉得这个数据还是蛮大的。
这里提一个问题,有没有同学知道图片上的是什么?这个是QQ农场业务,农场业务大家都用过,最早是一家叫5分钟的公司开发的,几分钟之内就可以完成这样的游戏,全民偷菜的游戏。行业内看到这个游戏之后,所以产生了“熟人社交”这样一个垂直领域的发展,所以那时候除了偷菜,还有好友买卖,把你的老板卖了,还有抢车位等等。这个游戏是5分钟这个公司开发出来的,所以架构上更多是单体式的,名字比较怪,LANP的模式,它会很快的搭建前后台的服务,而且还免费。主打社交的腾讯空间产品和子类产品以及校友网,准备开始做这样的业务,五分钟这个公司要不然卖给我们,要不然我们就仿制,理论上这个公司肯定会选择前者,卖给这些公司,这些公司就如火如荼的去改造,争取能够在熟人社交这个领域博得一杯羹。从一个小的应用要变成一个海量级社交的应用需要很大的改造。怎么改造?就像刚才那个流程图,里面最耗时的是在数据库这里,那时候没有SSD的硬盘,带有索引的查询就很麻烦,其他地方的访问都很快,电级别和机械级别差的很大。我们很快从数据库这里面拆出来,性能得到很大提升,若干模块去获取数据,这是第二个好处。第三个好处,我们做了更多的优化,把更热点的数据放到我们的缓存服务器,并且做了分层。这个分割是什么意思呢?一般大型网站会把所有模块做若干切割,比如说登录、个人属性,比如说栽花种草的成熟时间,这样做的好处是方便对外扩展,方便做容量维护,各司其职。我们整个架构里面增加了很多权限服务器,比如说你要购买花果,这些涉及核心的数据和经济的产品都会增加权限的服务器放在前面,会增加很多代理服务器接入。还会增加消息队列,因为这样可以帮助我们。做完这些就是从单体服务器变成分布式架构的过程。在这个分布式的架构中间一定需要名字,所以一定需要路由,这就是我们的路由产生的背景。这个路由要包含寻址、容错、负载均衡、过载保护的功能,对运维来说有容错功能是最好的。

这张图分左右两边,左边是介绍路由分布的大概流程(见PPT)。
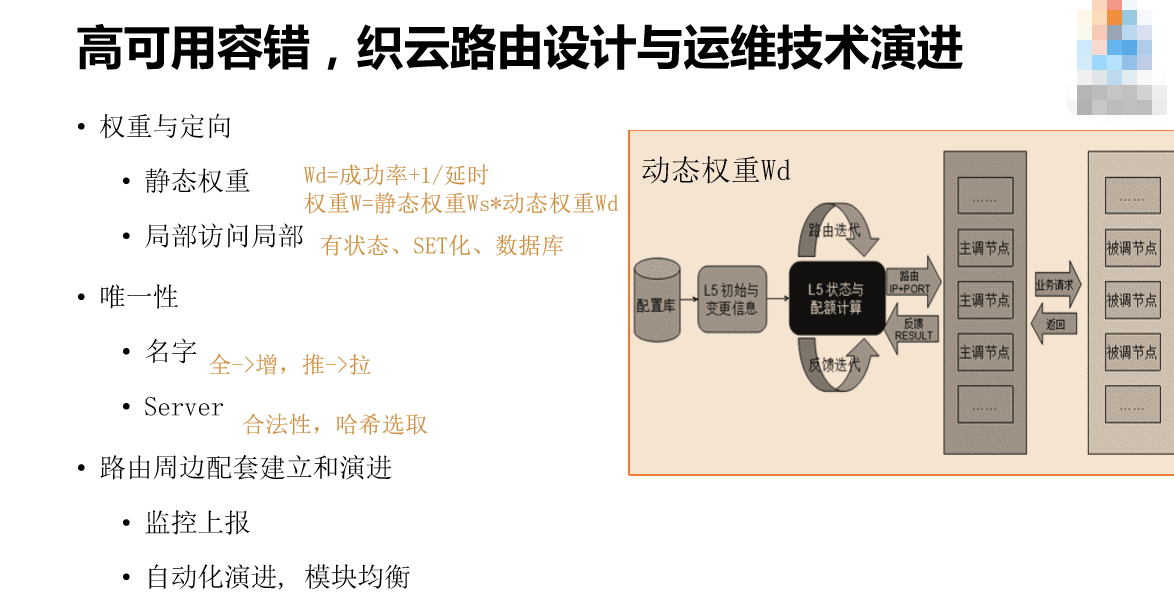
这是第一个发起请求的服务器,在第一次发起请求的时候,所有的服务器都是均分的请求。然后返回主要请求之外,还返回两个核心的数据,一个是这些请求的延时,还有这些请求的成功率。往一个方向去看的话,延时越高、成功率越高,下一个时间片里面的请求就给的越多,所以这就是一个动态权重。跟前面两种路由一样,它都有动态加权的过程。这里面总的权重还有一个静态的权重,这个静态的权重是动态权重的有利补充,因为它是线性的,所以可以直接设置成0,这样成功率更大。为什么?这是运维技术的领域,开发角度我们希望有最优秀的做法,但是实际上做不出来,所以我们就设计了静态运维。第一次请求加权重访问,用动态+静态的权重。
这里面谈一下运维的要求,状态是指通过不同的QQ号码路由到不同服务器上面去,因为在这里如果不控制,每一个主要节点都会被调,这是一个乱序的,就一定要通过相应的规则,在这个指标节点去调,因为它还做了赛格化(音),我们上海有两个机房,我们希望优先调这两个机房。这个算法里面的K相对稳定,我们尽量少搬迁,所以路由支持了哈希。
请问一下,“种子的数量”和“种子数量”是不是一个名字?(现场嘉宾:不是)。对,当时我们设计这个名字的时候犯下了很大的错误,因为口头化的传输,微小的差异,会带来很多很多名字的冗余。制造种子数量服务器的人申请的名字可能叫“种子数量”,来调查的人不知道,跑来又申请了一个“种子的数量”,所以我们的系统里就会出现非常非常多的冗余的、但其实是相同服务的名字,所以这时候要注意,最好的办法是全部改成英文,这样相对好辨认一些。
这里我们做了优化,每次下发是全量下发,然后变成增量。我们很土,运维模式固定,我们下发配置,但是下发并不是好的选择,所以我们变成推拉,需要什么名字就到配置库里面去拉。这个配置库前面有一个Server,在2011年8月份的夏天出现了一个非常特别的事件,当时社交网络运营部所有的数据都不能用了,出现有些时候能用、有些时候不能用的情况,我一看一定是运维干的事,果不其然就是运维干的事。我们比对的时候,我们运维直接把这个Server配置到这里,所有的数据变成推拉下去、下发下去。怎么改?第一步是合法性,所有的Server启动之后,要由原来的老Server发一个消息说,你不要连它,因为它不合法,但是这样的设计不合理。为什么要接?肯定是老的Server不行,老的Server不行怎么再给新的Server发消息呢,所以不合理。后来我们改进了,这个数据库前面连了一些Server,这些Server共享这些数据,就像前面讲的分层一样。前面放着一台Server,所有的主要结点想获取路由,就通过哈希选取到里面。
下面讲一下自动化的演进。有了这么好的路由产品,在自动化上面有哪些好处呢?我们看一张图,这是一张二维的图(见PPT),下面是时间维度,上面是所有设备的负载维度。密密麻麻每条图都是一条痕迹,按照时间负载的,主要是CPU负载的痕迹。为什么这些服务器会比那些服务器低呢?因为性能不好吗?恰恰相反,它的性能很好。在我们的权重里面,动态权重只有在出现错误比较高的时候才会做延时,但是请求如果没有达到错误的阈值,延时超过这个阈值的时候,它就会均分所有的请求,因为所有的服务器延时的错误率是一样的,整体的请求数没有超过阈值就没有区分,好的服务器负载就会低一些,但是这个不均衡、不合理,当请求超过所有服务器的阈值的时候,这些负载差的服务器会去试错,因为请求太多了,所以它要微调和试错,所以我们不容许任何一个请求在这里出现任何错误,所以要设置一个静态权重,给予好多服务器更多的请求,这也是静态权重所用的一个场景。怎么去自动化呢?我们每天动态的比较前两天服务器的负载,看服务器的负载和型号,动态的调整第二天的静态权重,让负载更加均匀。
3. 成本节约,织云成本管理方案
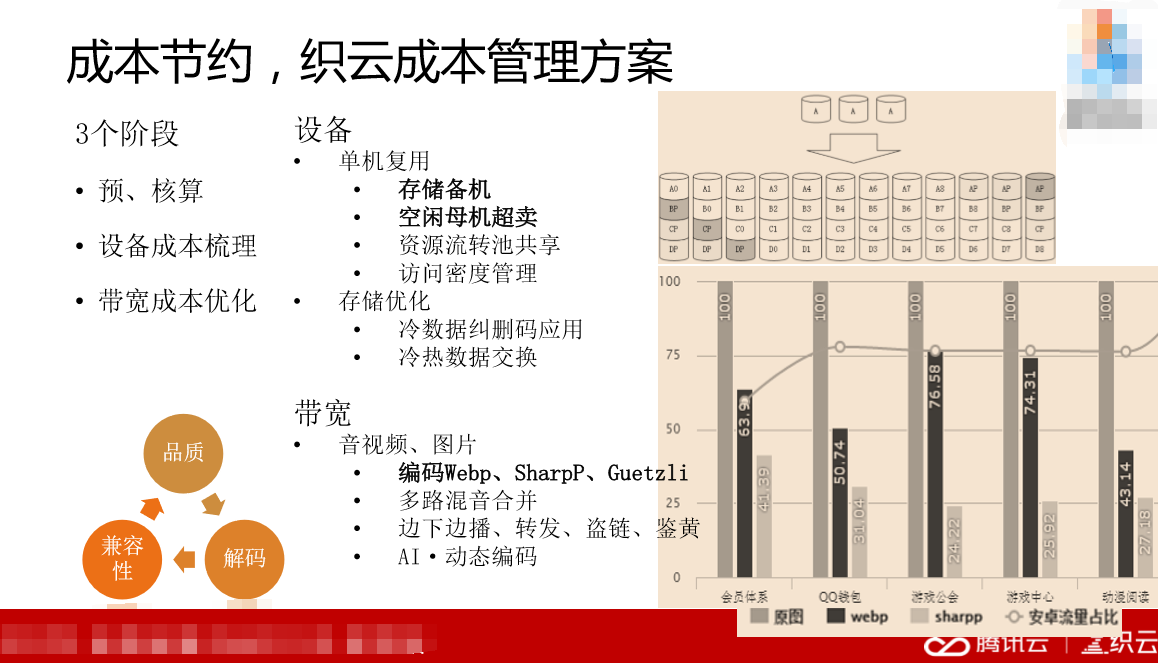
在2014年-2018年,腾讯公司启动了成本优化战略。当时我觉得这个成本优化战略并没有太大的作用,但是现在回头做总结的时候,我发现通过成本带来了很多运维技术的提升。这里的运维技术的提升,我觉得比开发技术的能力提升多一些,比如说,成本空间里面的设备,我们把刚才谈到的缓存化服务机的备机拿出来,比如有空闲的母机,这些母机上的子机容量不够多,我们把母机拿出来超卖。这两个都需要自动化操作,它们都需要知道母机跟备份的缓存化服务器上的多了以后,立刻变成超卖的,这就是运维的人可以做的事情,不需要开发的人做,这是我们做的重要的事情。
我们分析了长期存储的文件,包括很多大文件,这些文件很多存放着不用,所以我们要把存储做分层。这里存在着分布式存储的数据基础里面去,这就是谷歌的一个基本算法,读写数据的同时再写一些符号位,以保证这些数据在网络上可以遍布到各种地方去。
带宽的主要优化有哪些呢?有一个很核心的优化,Webp的支持。Webp是2010年谷歌的图片压缩算法,它的好处是可以压缩相应的图片变得更小,但是肉眼识别不出来。有这么好的事情,我们做的时候就一定要用它,所以相册业务就很快支持了这套算法,当时运维也起了很大作用,经过多次的测试我们发现,Webp做品质压缩的时候存在两方面的输出,一个是压缩之后能不能对肉眼有影响,二是压缩之后文件有没有真的变小。当品质比小于40%,大家可能有一点疑惑,这个品质到底是什么?我们做photoshop的时候,他问你要不要保存质量比较高的图片,就是这个值。小于40%的时候基本上看不清,超过90%的时候肉眼分辨出来那个文件反而大了,所以我们发现70%的时候比较合适。第二点,需要解码。如果文件比较大,下面解码的时候客户端就会慢。运维人员去调研,看不一样的这些数据,发现都拆解成100毫秒的时候耗时比较合理。第三点,金融性。我们需要判断是不是用谷歌的浏览器访问图片,如果是就下载。腾讯的SNG网络事业群把图片设计成SharpP模式,原来原图100%,SharpP40%,所以压缩的更高,通过浏览器里面的标准图和报上来的浏览器类型来判断。其他的多路混音、边下边播这些内容。
4. 智能监控,织云AI运维
智能监控,监控帮助我们中午十二点测一下大家的访问到底是多少,可以调整我们运营体系中的量、访问的测试、灰度,到晚上的时候,基本上可以满足把在信息化、移动化、大数据时代、AI的时代产生的巨大的信息聚合起来。我们可以设计开发和测试版本,还可以帮助我们管理部署和运维。
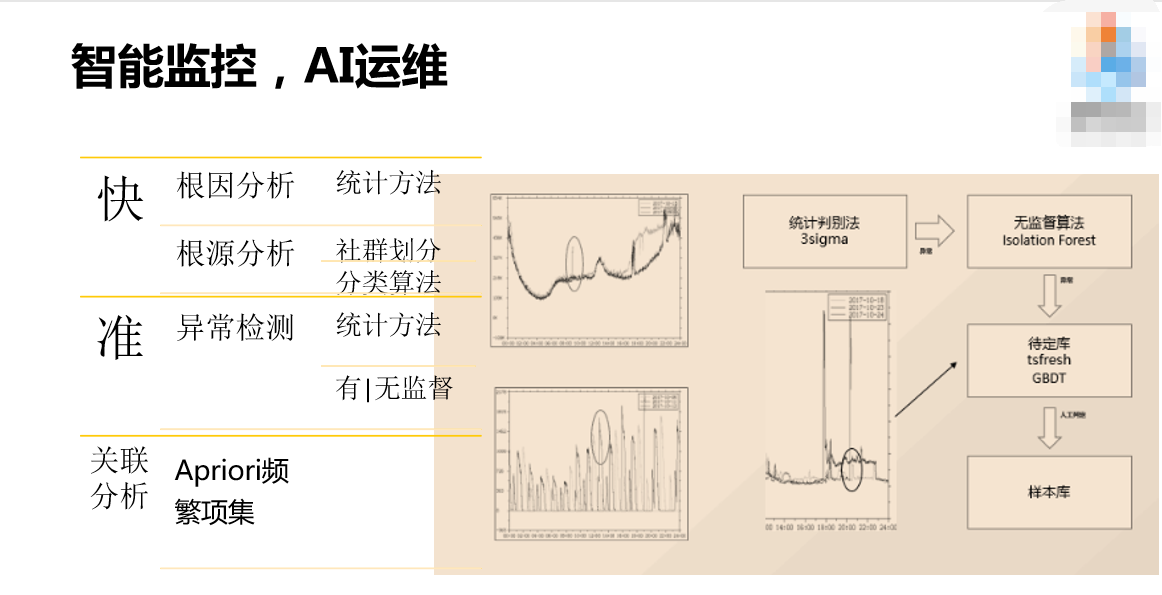
对于运维人员来说,挑战在哪里呢?每天有无数的报警,怎么办?我曾经跟一个空间的总监去聊,他说你们监控蛮有效的,他说我不知道准不准,但是通过你们的数据我大致可以判断出来我们的业务怎么检查。这其实有一点滑稽,但是对我们有一点刺激。我们原来通过设计一个阈值,判断报上来的数据有没有超过我们的能力,后来我们又做了一些优化,看当前报上来的数据是不是符合若干天时间整体的正态分布,来判断它有没有超过我们的阈值,然后产生报警。其实这两个现在都不行,因为现在整体的信息量比原来增加了很多很多,用户访问的行为也变了很多很多,热点事件如火柴一般容易点燃,也如火柴一般容易熄灭。我们把所有数据经过清洗、筛选、采集上来,通过无监督和统计判别法来进行统计。
最后是我的一点心得,我很欣赏凯文凯利说过的一句话,“对于事物的占有,远远没有对于事物的应用更加重要。”还有一句话是这两年比较火的一本书《人类简史》中的一句话,“人类之所以在十万亿年前从智人和猿人分开,因为智人想象到了一些原来不存在的东西。”运维人员一定要有老板提出的要求十倍效率、百倍效率的想法,才能够有一些很好的决策,长生不老。

