@gaoxiaoyunwei2017
2020-10-22T06:58:00.000000Z
字数 5972
阅读 1583
快速扩容百万核心:腾讯会议如何在云上高速增长-周小军
彭小阳
作者简介:周小军,2012年加入腾讯社交网络运营中心,现云与智慧产业事业群资深运维专家。加入腾讯以来先后负责腾讯社交事业群数据存储运维、接入架构运维、社交业务运维、腾讯自研业务上云等工作。拥有十几年互联网IT运维经验,精通互联网海量业务规模技术架构、云计算基础架构、自动化运营系统和监控系统等领域。项目历史包括所用户3亿的社交业务运维,亚洲最大的二万多台数据库集群运维,亿级流量的春节 QQ 红包,几百万核心的腾讯自研业务上云等项目。腾讯学院讲师,腾讯云布道师,GOPS 全球运维大会金牌讲师。

今天所分享的提纲有几点:第一,怎么在8天内快速扩100万核心服务器资源;第二,如何快速满足海外用户的接入,我们做了什么部署?第三,业务怎么在短短半个月时间内在云上快速生长?第四,对本次分享进行回顾。
一、8天扩容100万核心
大家都知道2020年最大的一件事情,就是新冠疫情。从1月份新冠疫情爆发之后,对我们的生活、工作都发生了很大的影响。新冠改变了人类社会运营的模式之下,线上的交易和线上的会议在疫情情势之下是联系办公和教育非常好的工具。

腾讯会议在疫情之前,它是一个新产品,在去年的12月上线,还是一个婴儿。我记得在1月份的时候,1月15号腾讯会议的在线用户才几千人,而且大部分是腾讯的员工使用。新冠疫情爆发之后,我们预感到腾讯会议会迎来非常大面积的爆发。
我们在春节之后,就开始动员大家从各地飞回深圳总部应对这场业务爆发的时间点。所幸的是,我们这些团队能够在非常短的时间之内,支撑住了业务爆发性的增长。在初八开工那天,很多产品都崩了,比如说钉钉,腾讯会议也崩了一回,为了满足业务爆发性的增长,我们在8天内就扩了100万核心的服务器资源。
这是我们公司内当时做的海报,大家当时还戴着口罩,我们的员工之中没有人有新冠,如果有新冠的话,整栋大楼就危险了,我们还有同事从武汉飞回来的,真的是幸运。

我们做腾讯会议爆发性增长支持的时候,因为我们有海量的经验,快、稳、好支撑了腾讯会议的发展。
快速扩容、快速部署,当时用户数最高峰达到几百万在线,有几千万的活跃,现在已经有上亿的注册。
稳是会议没有崩,从初八到现在为止没有出现过大的问题。
好是质量好,我参加会议的时候,我不能掉线、卡顿,会议对快、稳、好的要求是非常高的。
我们主要做了这些事情,有6个支持工作:

第一,云原生。腾讯会议是在云上开发、部署扩容的业务。
第二,SET化。我们在全国部署了4个区域,在华北、华南、华东、西南4个地方部署了业务,满足了全国各地的需求。
第三,基于K8做容器化的服务。
第四,敏捷发布,用DevOps支持每天的发展。
第五,容量和压测。
第六,运维保障。
我会针对以上6类做逐一的分析,希望给大家一些借鉴。
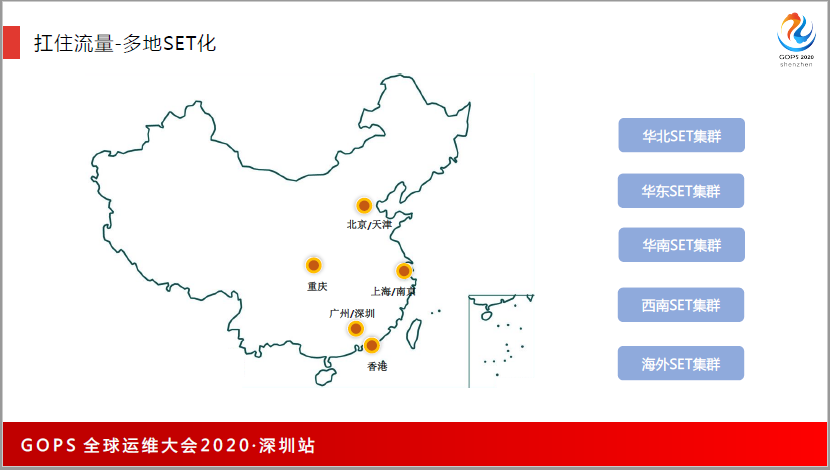
这是SET化的部署,我们当时在全国4地云数据中心部署了SET集群,SET能够快速部署和快速切换,我们当时还没有做海外部署的准备设施。
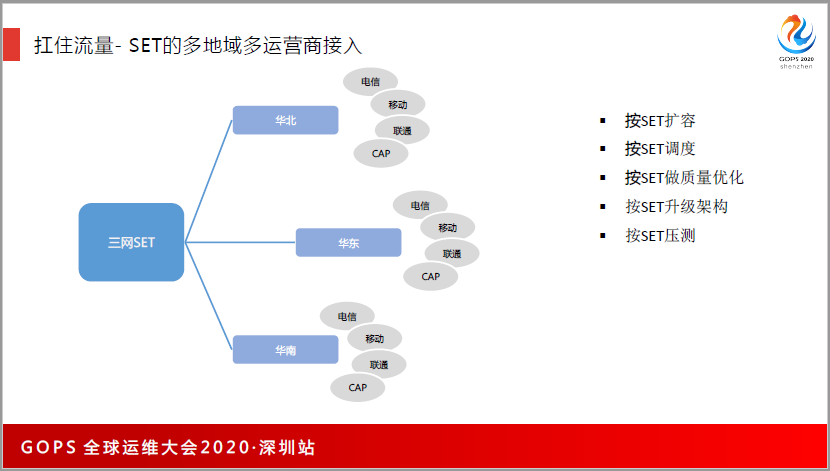
每一个SET,我们用了多运营商的接入,我们按照SET去做调控、调度和质量的优化。腾讯SET的理念是非常成熟的,所以很多业务都是按照SET化去做,比如华北挂了,业务可以把用户流量切到华东或者是华南。
因为资源的交付分两块,一个是在腾讯云交付IaaS计算资源,一个是容器化的交付和部署。在IaaS层的话,我们为了不增加成本,是用了碎片,比如说会收割在公有云上剩余的核心,比如在华东找二三十万核心,在河北又收刮核心来进行部署。要有非常大的交付能力,才能够支持业务部署的需求。

在IaaS层,我们用了VStation,它作为云计算操作系统,承担了资源调度、请求排队的工作。当时一天最多是扩了1万多台服务器,从下午6点钟开始,用VStation去便利计算资源,到了9点多开始创建虚拟机。扩容化,一直扩到凌晨三四点,第二天的八点是业务高峰,我们能够用VStation快速扩资源。
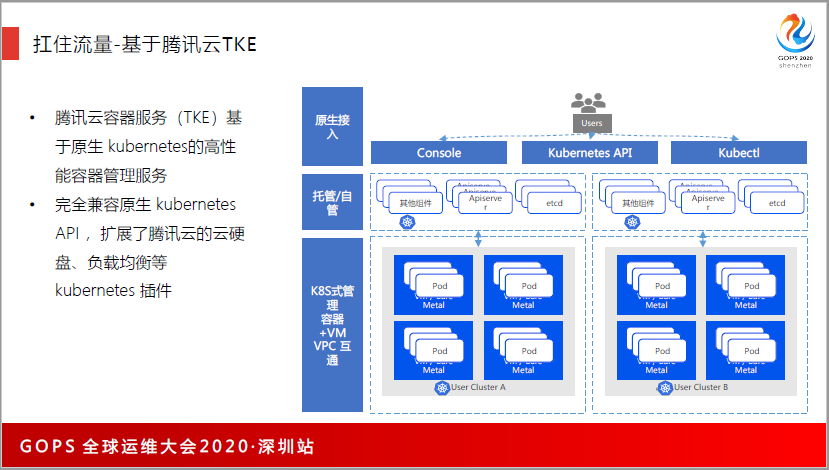
在VStation之上,我们用kubemetes来做业务的交付,8天扩了100万的服务器资源。当时有几个运维,运维8天8夜不免不休,白天要去跟踪用户的流量,去支持业务的快速增长,晚上6点多流量下来的时候就做扩容,开发也是一样,上午坚守现场做保障,中午开会讨论上午的业务流量有没有问题,做复盘和总结。
下午两点钟又开始做现场的值守,下午6点是一天业务的小结,晚上开发才有空去开发和迭代新的功能和新的版本,晚上10点钟之后开始做版本的发布,发布到凌晨12点钟就开始做压测,我们准备了几千台服务器做压测,压测了凌晨2点,发现了问题,又开始对版本去做迭代和更新。
到了凌晨4点,第二轮的发布完成,开发就睡2小时,6点钟其实就值守,那时候就像战场一样的气氛。

腾讯会议是音视频产品,它的视频、音频、共享桌面,对流量和质量的要求非常高,在容器的多人支持之上,我们也对POD提出了很多的要求。比如说容器要能共享内存,因为会议要在容器里面去有一片内存做音视频的优化。所以每一个业务逻辑都要开2G的个人内存来做音视频的(英文),所以说必须要支持共享内存,还有固定IP的特性。
因为腾讯会议是全球部署,要支持上万POD的秒级扩容能力,因为发展得很快,晚上10点以后要同时发全球的数据中心模块,所以必须要支持秒级扩容,分钟就要把这些扩完,并且要支持全链路的业务发布,支持全球的灰度发布和统一的发布。

当时TKE也做了很多的适配和开发工作,我分了8类,容器要支持CMDB,网络要支持弹性网卡,腾讯内部有路由服务,我们不可能用IP来去做寻址,所以容器要支持CLB服务,同时还要分批发布,要支持原地重启,如果把服务器重启,用户会断线,会议房间被退出,所以不能让用户受损,所以我们支持原地重启。
服务发布完新版本之后,重启服务的时候,用户是不掉线的,所以要支持共享内存,服务器重启,业务是100感知的。同时,服务之间要权限控制,以及镜像仓库,还有网络存储,以及远程日志。
大家在开发的时候,如何在开发之上做插件去支持业务的特殊要求,特别是金融、保险行业为业务的特性要求更高。
压缩是很重要的,因为压缩的时候会发现很多的问题,比如说业务的缺陷,我们用了几千台物理机每年晚上12点钟就准时对线上业务去做压测,发现了很多的问题。

我们会测哪些呢?我们会去看模块的并发能力能不能满足预期,我们也会测性能能不能达到要求,同时要测网络专线,会议平均一个用户的流量是几百K,包括音频、视频、位置共享、直播等,对流量的要求比较高,所以压测评估是非常有必要,这也能帮助我们去扛住千万级用的能力。
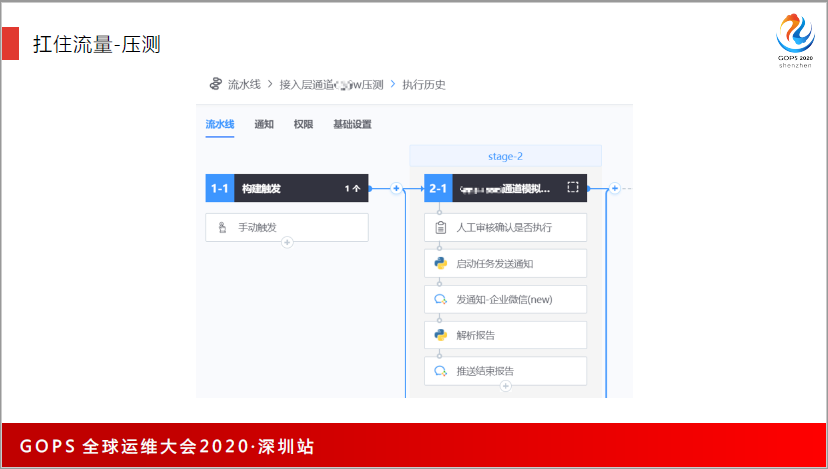
压测上我们用流水线的作业,用图形的方式去做压测,流水线可以灵活配置,从测试到发送通知,再到报告的解析,以及推送报告都是自动化实现,实现了无人值守,对测试人员的工作量也不大。
二、海外用户就近接入
腾讯会议支持了“一带一路”、中欧会议等等,当时腾讯会议也要支持很多跨国企业在海外开会的场景,基于用户的诉求,我们用了云的资源,快速完成了在云上的海外部署。
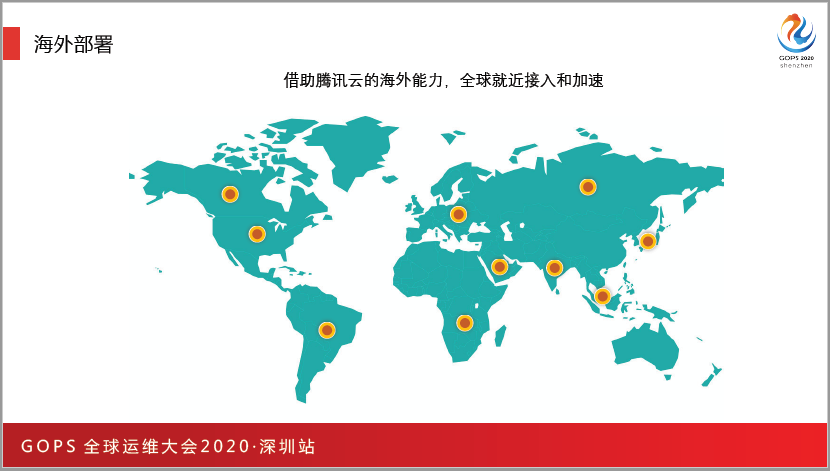
这是我们当时的布点,我们在东南亚快速部署了七八个国家和地区,比如日本、东京、首尔、中国台湾、新加坡、泰国等都做了大量的部署,因为那边的华人多,比如莫斯科、英国,还有北美,因为有腾讯会议的资源,我们部署很快,一周内就完成了部署。
我们需要在日本要有多少万的用户,希望腾讯会议能够准备这么多的资源和开发集群,所以海外的部署非常快。快的同时,还要好,怎么做得好呢?
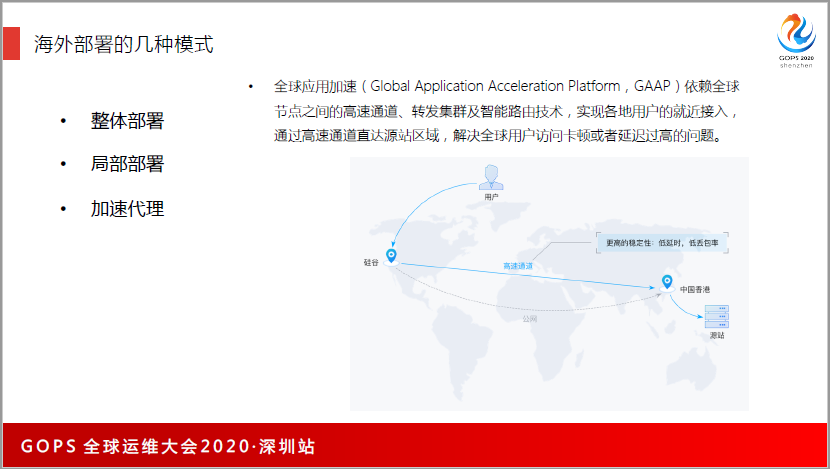
我们用了全球应用加速的能力,从欧洲到中国、美国,开会的时候,延迟可能都要两三百毫秒,我们当时测过,南非用户投诉南非到国内开会丢包非常大、卡顿非常高,我们发现从南非到中国香港的延迟有300多毫秒,我们用GAAP的方式加速,通过这些技术解决了各个国家地区同时在一个地方开会的质量要求。
同时,我们把用户的访问数据做了精细化的分析。从运营商、地区、版本等几个特征去做分类和汇聚,这样来分析哪些国家和地区什么城市用户的访问质量非常糟糕,针对这些差的数据来做解决。
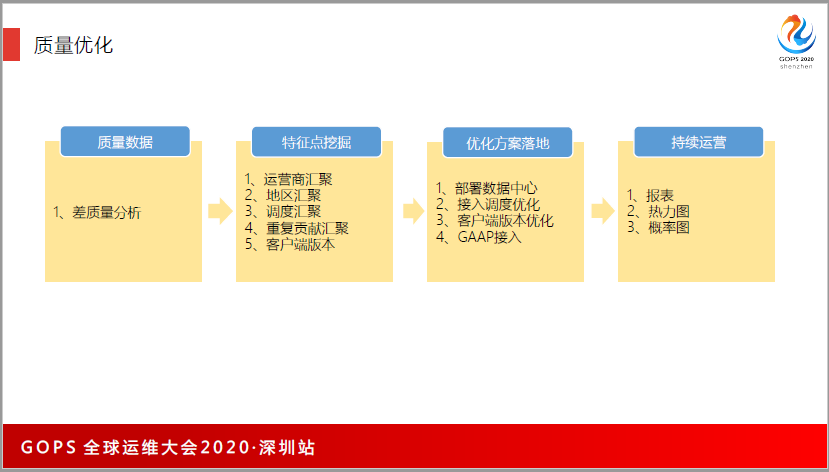
我们有几个方面:
第一,在当地部署数据中心;
第二,通过调度的方式把用户调到离他最优的国家;之前我们发现尼泊尔、西亚的一些国家,我们认为他接到孟买的数据中心会很好,但是我们分析数据之后发现,尼泊尔联到孟买的数据中心很差,我们对印度进行质量分析,印度国内的质量也是非常糟糕的,可能从新德里到孟买的延迟甚至比国家到国家之间的延迟还要差。
通过数据可以发现很多的问题,后来我们把尼泊尔的用户调度到新加坡,用户的数据改行从善,差质量的用户从12%降低到3%。通过大数据的能力和数据的能力,就能够对全球的用户做精细化的定位跟分析。
我们做的时候,我们也参考了王者荣耀和微信海外的部署质量数据,腾讯会议更特殊,我们是针对腾讯会议业务产品还做了很多个性化的优化。通过质量数据的分析和调度,我们就能够做到海外用户在3%差质量的占比。
三、云上生长
腾讯会议作为云上的发展业务,有什么特点?运维已经大大被释放,计算资源、网络资源、中间件(卡博卡、存储、加速),完全都是用腾讯云平台去支撑。意味着会议的运维不需要再关注这些平台的支持。

真正支持腾讯会议的运维只有几个人,只做全球化的保障、部署、自动化流水线,比如数据库、中间件、K8集群全部是给腾讯云后面的团队进行。
我认为这是未来的革新,大家业务上云之后,下面这些团队会越来越少,这也解放了运维线,运维可以专注到业务本身的架构和用户数据的优化。
那我们做时间呢?我们就关注于这4方面的内容:

第一,业务管理。我们要做好压测、容量模型、演习和预案,还有故障管理。
第二,资源管理。通过业务的分布去拿各种资源,做弹性和规划。
第三,高可用的管理。包括SET化,把这么多的模块按SET去做部署,跟业务一起做架构优化,通过监控的手段,保证业务的可观测性,保证整个业务的链条,从客户端到接入、逻辑、后端的存储等都是可视化的。
因为会议发展得太快,开发还来不及做全链路的监控,所以这是我们比较遗憾的,没有全链路的工具去对业务做可观测性啊。新业务上线的时候,一定要做好团队监控的接入,帮助你知道业务链条当中的很多问题。
第四,质量管理,通过数据的运营能力,去帮助业务的访问质量做优化。
这是我们在云时代,运维所要聚焦的4点。
我们利用了云的资源,云的监控能力是非常弱的,我们用了十几个云的产品,在上面看监控不直观,我们后来还是用(英文)做大屏的监控。我们找了会议室,用投屏的方式,实时展示业务的质量数据、在线用户、各种大盘动态。
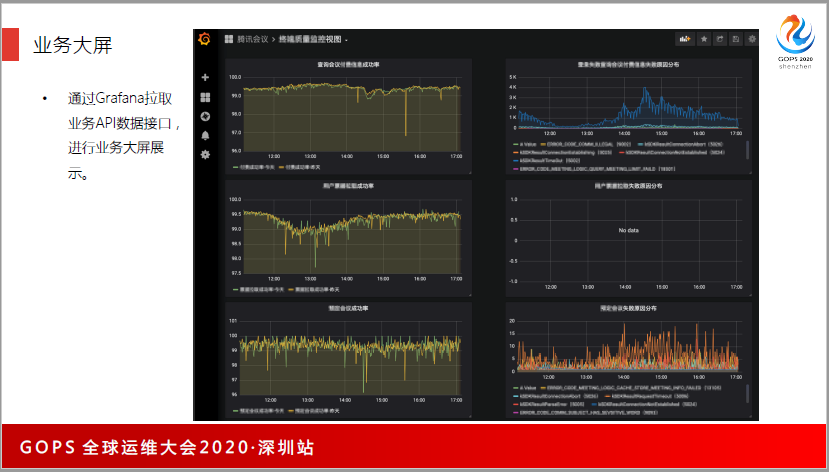
去做大屏的展示,大屏在会议室里面,我们有一个作战会议室,那个会议室通宵都有人在,大屏上显示各种数据的分布。Grafana是一个非常好的工具,可以通过Grafana实时拉取机器负载,按模块汇总、按业务服务汇总,并展示平均负载。
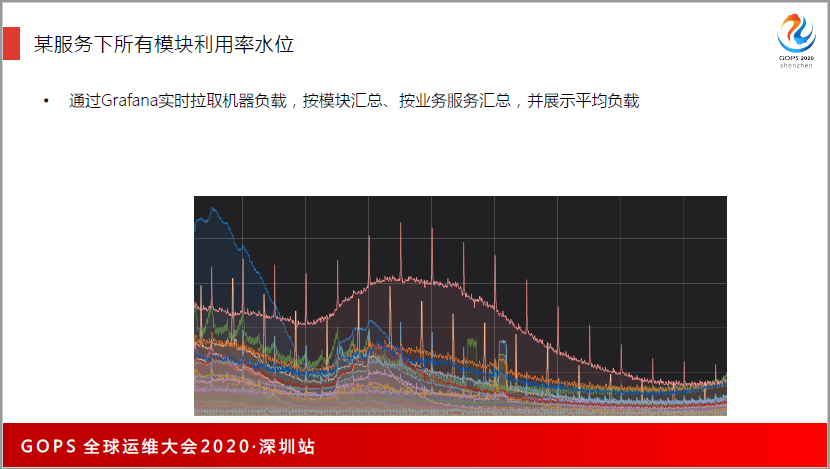
我们也大量用了监控系统保障业务的观测性。如果没有监控,对业务数据、系统健康状态是不了解的。从全球各个国家和地区去拨测,看能不能符合预期,同时通过单位指标和多维指标及日志去做监控,服务方面,是通过模块调用、全链路等,依托腾讯云PaaS监控产品,在IaaS层是用了IaaS的能力去做。
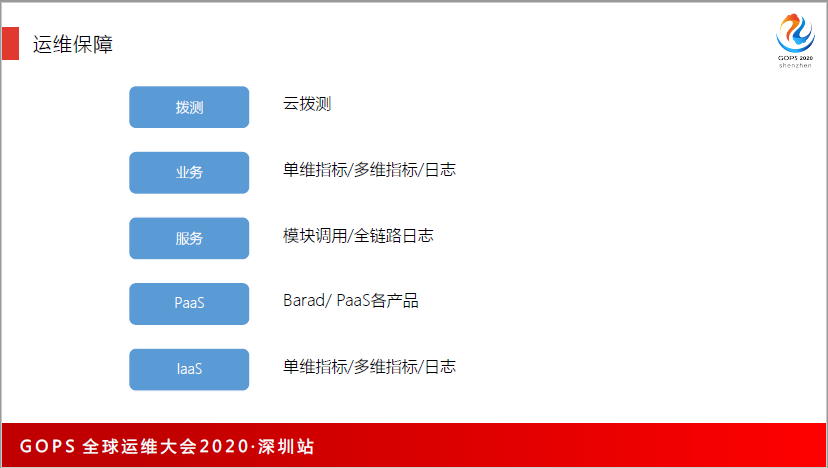
同时更多的是通过拨测、业务和服务,这是业务运维所做的事情。
我们也用了智能AI方式去做,IEG的李世岗也讲了,在蓝鲸平台上去做智能监控和智能运维的探索。在腾讯会议上也赋予了智能业务的能力,对业务去做智能业务云。

这是智能监测的位置,监控的业务数据是通过SDK相关的方式上报到代理和队列,然后通过(英文)实时流处理的方式对数据进行实时加工,然后数据会拓到智能监测平台,由这个智能监测平台去给它做异常监测、根源分析。
我会介绍怎么来做检测跟分析,智能检测出来以后,这个数据送到告警平台去做告警。比如我发现这个模块的CPU告警了,我们会回调一个开发的插件,让它能够自动对(英文)进行扩容。
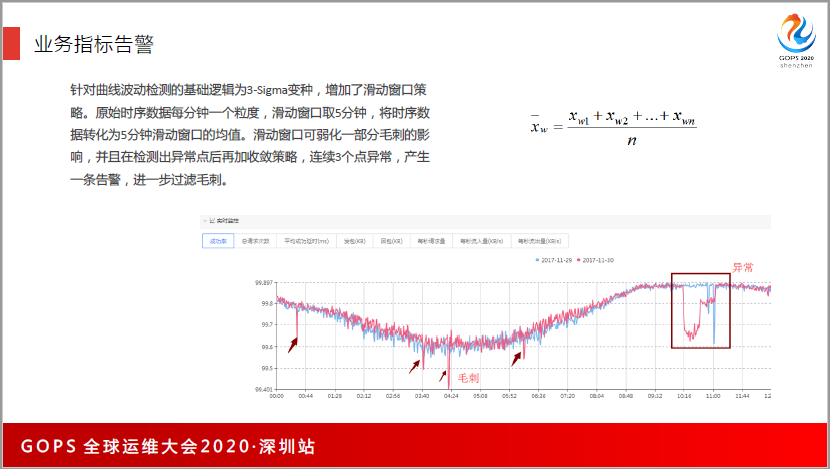
这是一个例子,我们用了3—Sigma的方式去做异常检测。我们是分两种场景,一种是有率的告警,一种是有量的告警。业务优先成功率就是有率的告警,比如说98%,或者是99%,它是有率的报警,率的话,直接用3—Sigma来做检测是最好的,因为它符合动态分布。
同时,为了保证没有毛刺,按5分钟的时间窗做平滑,会把5分钟的数据先平均完,再去做均值检测,这样保证了对毛刺不会有影响。
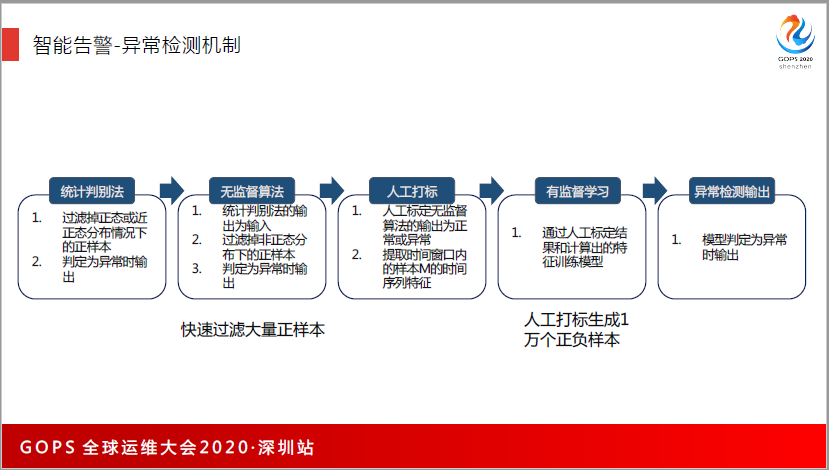
用户量的告警,比如说用户量,或者是请求量,它不是率,我们用了融合的方式来做,这里是分5个步骤,首先用统计判别法的方式,统计学的方法把正样本给过滤掉,做异常分类的时候,正样本最好是1:1的比例。
第二轮再通过无监督算法方式,过滤掉之前没有过滤的,通过这种方式,送入了50多万的正负样本,最终只有1万多个样本送到人工打标环节,然后通过运维人工去打标,在1万多个样本里面,找出将近2千个异常样本,再把正负样本送到人工打标环节。
客户端是非常多的,有APP的版本,有业务的特性,还有在哪一ITC等等。这么多的特征,我们靠人去定位到是什么国家地区的客户端有问题,我们是非常烦琐。
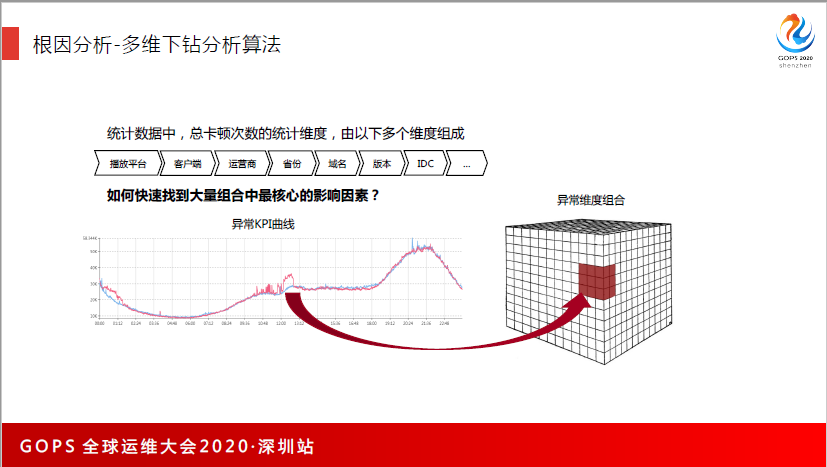
所以我们也做了分析,它能够自动化地去辨识很多的组合,找到是哪一个特征出现问题,然后做把这个特征发送给运维去做告警,把运维之前花半小时定位到一个地方异常的时间缩短到3分钟。

同时,我们也用了云上非常好的工具,腾讯云有一个智能转化的平台,它能够自动判断哪些数据库的使用率是异常的,然后帮助你分析,可以通过优化慢查询的方式,或者是去做扩容的方式,帮助你解决数据库卡、慢的问题。这是一个例子,数据库的连接数、内存等,都能够自动检测你的数据是健康的还是不健康的,我们不需要关心数据库的状态。
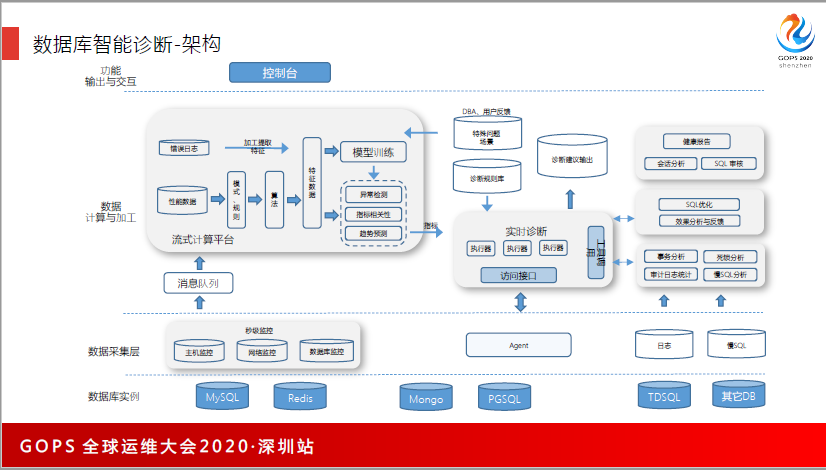
这是我从数据库拿出来的架构,主要有3块方面来做智能诊断。B是经过这层,他们用了这个帮助你去判断数据库的CPU过窄,或者是容量什么时候达到一个点,然后帮助你去做扩容的支持。
日志,李世岗也说过,可以把日志变成向量,通过算向量之间的距离判断哪些日志是距离比较近、比较类似的。他们也用了日志向量化的方式去判断哪些语句有异常,通过慢查询分析去提出建议,帮助业务去改善慢查询的SQL然后提升性能。
四、回顾总结
讲了这么多,我回顾一下。

腾讯会议在云上8天破了100万核心,腾讯会议为什么能支持这么海量的用户?
第一,它是云生的方法,在云上用云的资源和云的网络、云部署去快速发现。
第二,通过SET化的方式,能够保证用户的质量做得非常好。
第三,容器化的方式,支持业务的隔夜发布,CICD都能够完成闭环,可以支持开发每天都能够发现版本。
第四,敏捷发布,用的是腾讯云内部的能力,能够高频发布。
第五,业务运维聚焦带容量、压测,能够保证会议和高可用性做得非常好。
谢谢大家!
