@gaoxiaoyunwei2017
2018-04-18T02:09:02.000000Z
字数 5924
阅读 1440
全站跨平台系统补丁自动化部署实践
啊哈
作者:梅岑恺
- 作者介绍:梅岑恺,eBay运维经理,主要是负责eBay全站云平台、应用平台、网络流量的维护。
本文和大家分享的是关于全站跨平台系统补丁自动化部署的实践。
1. 背景介绍
从加入eBay到现在有将近11年,主要是负责eBay全站云平台、应用平台、网络流量的维护。eBay成立至今已经有20年了,在中国互联网里面有20年的公司并不多,我在eBay有11年。最开始eBay是全windows服务器做前端,静态内容是ISS。eBay上曾经卖过最贵的一个产品是1.68亿美金的游艇。2016年eBay的业务成交量是850亿美金。我们内部的要求的ATB是99.947%,不像很多公司要求的要99.99%,我们只要三个9加一个4就可以了,我们会做每周一次的数据库的升级和迁移,这些凡是对用户有影响的我们都算进去,不管是我们的原因还是外部的原因。我们作为电子商务平台,我们做的跟支付有关系,如果Paypal不能来收钱了,它的影响对我来讲是我的用户到我的平台上买东西不能产生交易,平台挂了算我的,我的ATB受影响。对用户来讲是这样,对我们来讲看起来就有点不公平,你的下游产品发生了问题,你不能成交,这个ATB的影响要我们来背,平时不可见的因素非常多,导致我们平时要非常小心。但是我们又是做互联网的,比如说1.68亿的成交金额,你不想你的服务器因为漏洞被人黑了,这笔钱转到其他人的账户上,或者说有一天你的公司被黑客攻击了,由于你的系统没打补丁,你受到了什么影响,可能对大多数人来讲,包括我们自己也是一样,对自己的安全保护我们还是比较在意的。这是一些内部情况的介绍。

外部形势从去年以来就比较严酷,包括去年出现的勒索病毒,整个安全形势是非常严峻的,反映到我们每个工程师来讲,我们的压力就很大了,每次有漏洞出来都得补,eBay对于用户的承诺是什么呢?我们要求我们的补丁周期,从发布到完全部署完要45天做完。

eBay的业务是24小时不能停,经过20年的发展,我们有windows和linux,系统是几十万台,应用数量是数千个,全球加起来运维人员只有12个,12个人要维护windows加上Linux系统,我们的windows系统是2万台,Linux是十万台,然后分属到几十个库里,我们的PD不需要关心系统级别的漏洞,它跑的OS上面有漏洞,这个补丁我们来打。同时我们还要管理其它的事情,打补丁只是其中的一部分。
2. 问题分析

那时候是2万台windows系统,当时领导告诉我,下个星期开始补丁你来打,我当时不知道是怎么办的,你又没有人,你的业务还要继续跑,不会给你加机器,不会给你加人。
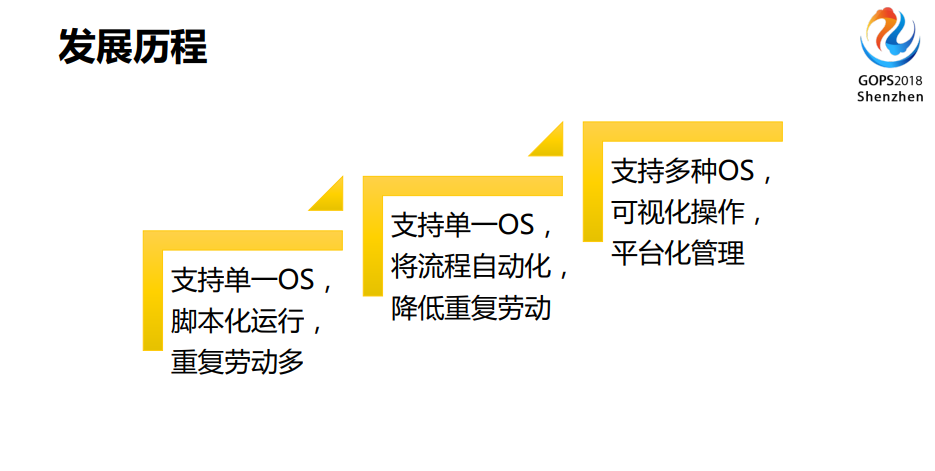
我们后来经历了大概几个历程。简单来说是三个历程:
- 支持单一OS,脚本化运行,重复劳动多
- 支持单一OS,将流程自动化,降低重复劳动
- 支持多种OS,可视化操作,平台化管理
可能在很多情况下,跟很多互联网企业很类似,可能一开始只有windows系统,当时OS是单一的,用了windows活动目录,没钱买它更好的服务,windows有一个免费产品,可以选择跟它对接实施下来,把补丁做下来,它可以选择策略,要么是只下载,另外是下载了定时安装,还有一个是下载了自动安装。如果下载了自动安装,它需要重启,这就会出现一个问题,两万台机器在那时候下了补丁自己装,装了之后重启了,那时候监控中心的人就慌了,因为没有人发一个工单,在我们那里任何机器重启都要发工单,但是发现全站2万台机器全部重启了,没有人发工单,这时候我们内部就要开始把所有的跟运维相关的人叫起来,问他是为什么,我们说在打补丁,他说下次不要这样干,因为你这样干了,首先我不知道你什么时候打的,另外重启是不可控的,有些服务是不能随便重启的,它有特定的维护时间。
所以怎么办呢?我们选择用一个脚本让那台机器把每个月的脚本下下来,然后我们再把它测好,我们要做的第一个是兼容性测试,很多时候我们不希望说打一个补丁之后windows挂了,蓝屏重装,当时我们有一些黑科技,重装一台windows也只有15分钟,但是这个量太大,恢复起来很难,所以我们就把机器所有的补丁下载下来,选择用脚本,我每次都选一个机器列表,然后发个工单让SEC的人把它重启。在那时候机器的变化还是会有的,你不断会有新机器加入到线上,不断有旧机器下来,你不管做什么,因为有这个脚本,有机器列表,脚本是死的,机器列表是变的,你每个月还得把那个机器列表维护一遍,这也是挺麻烦的一件事情。后面讲到怎么解决这个问题,我们把往来放在这里,引发大家思考。
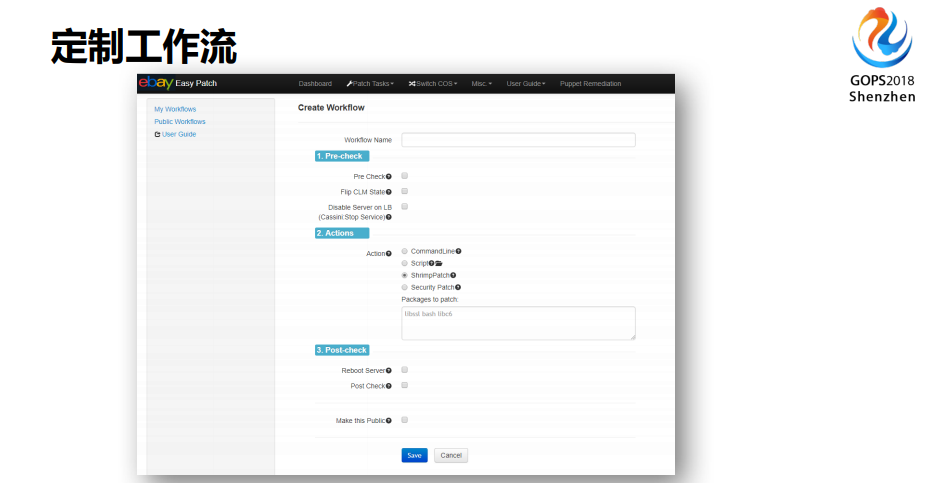
我们从单一OS变成了自动化的流程,我就就实现了灰度发布。到最后我们希望变成一个可视化的、平台化的操作,并且我让做Hadoop运维的同学负责Hadoop的事情,并且我开放一个接口让你把你的逻辑放进来。你需要测试我帮你测试,但是你的业务逻辑在你那边,我把这个业务逻辑放给你做。

打补丁有几个问题,第一,你怎么知道漏洞在哪里,第二,你怎么发现这个漏洞,这个漏洞对于部署有什么影响。当我有一个漏洞发现的时候,我怎么从应用的角度来看影响是什么。然后补丁怎么部署,我们要实现跨平台,还有一个问题是打补丁怎么才能保证安全。
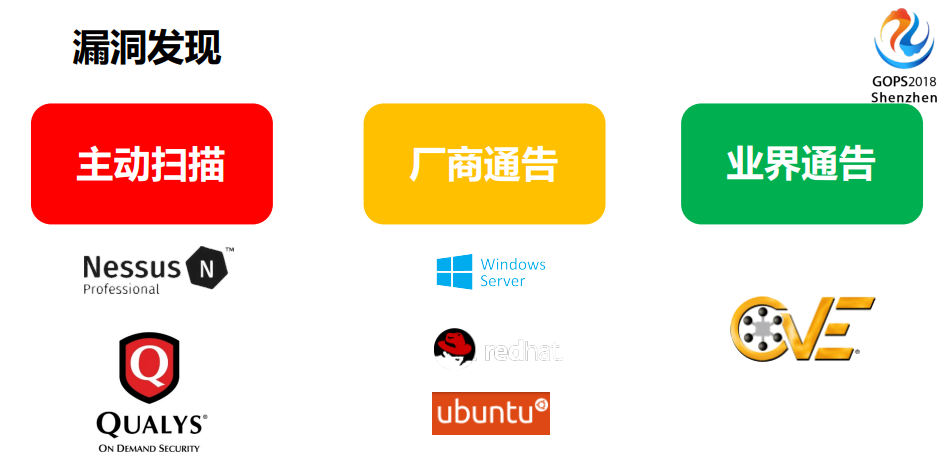
大多数同学可能是通过看官方公告或者微软的公告等等,发现漏洞,再去给系统打补丁的,其实还是有其他的可能性的。
首先一个是主动扫描,每次定期对你做健康检查,就像我们自己做体检一样,商业产品或者是开源的产品,我们觉得相对来讲还不错的,一个是Qualys,它会提供主动的基于漏洞库的扫描,帮你发现从应用角度和主机端的角度来看一些漏洞是什么,并且它还有一个好处是帮你做漏洞的分级。可以借用一些现有的漏洞,有些时候你出过漏洞,你不知道那个漏洞的危险程度是高还是低,就像前面说英特尔CPU有一个漏洞,我听到这个事一脸懵逼,可能有很多人也是这样,它的含义是什么我们并不知道,它有可能告诉你是什么原因,我们会借用别人的一些知识来补全我们自己。
然后是有厂商通告,包括有windows等等的官方通道。
除此之外还有一个,就是业界通告。
在美国有一个比较流行的叫CVE的,当我们发现任何漏洞扫描出来之后,它会附上两个信息,一个是官方有没有补丁,第二个是CVE,CVE会告诉你你的漏洞可能的评级是多少分,它已经做了评级,也把相应的可能的危险程度以及补丁的方式告诉你了。在国内很多模式可能已经被关掉了,比如说乌云就是借用它的模式,用户往上传,会记录在它这里面,然后通告出来。其实是业界在根据CVE的发现再去找。既然CVE和商业扫描的软件有很大的共同点,为什么你有了开源的还不用公共安全信息,还用商业的呢?其实有一点就是从效率考虑,以及从专业知识考虑,有时候给了CVE,它的量太大,你没办法一个个比较。如果20万的机器分布到7个类型里面,还有不同的版本,哪怕是软件包都不一样,在平常我们做运维的人发现这是很正常的现象,这叫软件包的漂移,我们在补丁过程中也要尽量避免这种软件包的漂移。
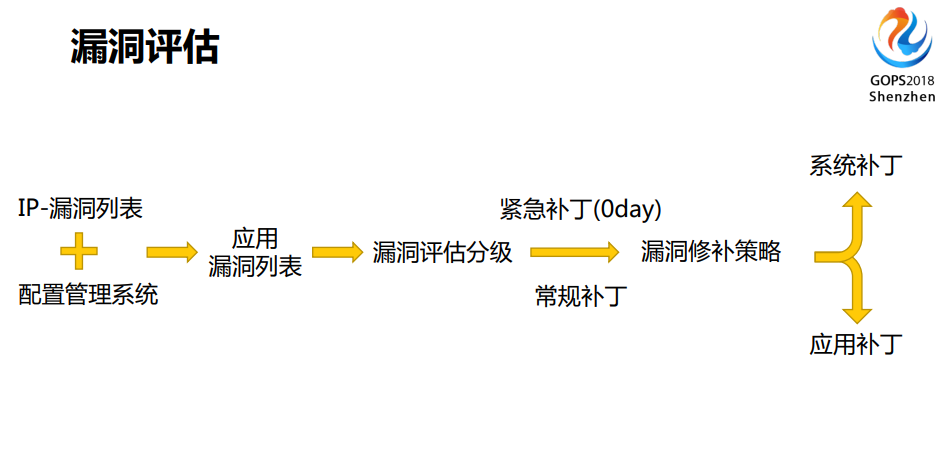
在eBay内部做的事情是这样的,我们用扫描软件把所有基于IP网段的扫一遍,保证是全覆盖,然后加上CMS的系统,这是一套配置管理系统,它很多时候在内部叫CMDB,基于这两部分再看这样的漏洞会映射到哪些应用程序上有问题,方便我们接下来做一个评估和分级。
不是所有的漏洞都要打补丁,有些漏洞可能你会放一放,或者说你采用其它的方式把它直接停掉,评级完了之后你会发现如果是0day的你就只有打了,对于常规补丁还有喘口气的机会,如果是0day我就需要找美国的同事一起,加班加点把它解决。这时候就决定了你的漏洞修补策略,到底是你要把漏洞干掉,或者是有漏洞的包的服务停掉还是怎么样。
策略定好之后,如果是系统级别的,运维团队全权负责,但如果说很多跟应用紧密相关的,你得通知相应的开发团队,跟他说你的应用需要打补丁,做你的应用补丁的时候,全部把它修理掉,或者把它放到应用程序的部署里面去处理掉,这是我们对漏洞评估的一个过程。
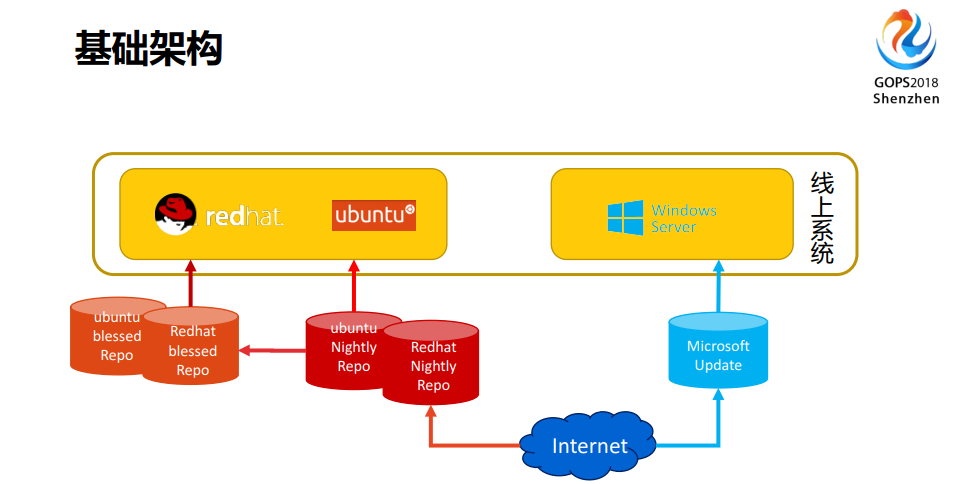
让跨平台可以在一个系统下面完成我们的补丁任务,其实有两个点:首先在线上系统上面有Redhat、ubuntu,还有windows。
windows还有好多个版本的,好在它是给你同一个包,它这个包也是一个月更新一次。所以大家会注意到有一个差别,Linux有两个更新包,windows只有一个,相对来说比较稳定,Linux随时会更新。我需要定期从外部把所有的软件包拉进来,我们在ubuntu上面,不是所有的机器都能访问到互联网的,我们做反向代理,流量可以从互联网进入到eBay内部,然后到负载均衡,负载均衡到后面的Server,然后再出去还给用户,所以它是一个反向代理的模式。ubuntu不用跟互联网接触,这样也可以降低我们被攻击的可能性。所以在这里面我们需要设置两类Repo,包括线上的机器能得到最新的软件包。每日更新的软件包会时刻不断地跟外部保持同步,之后会自动触发在内部的CICD的过程,然后做部署、做测试。现在在软件包开始的时候有这些部署,有这些部署之后我就可以把生产上现在已经有的包拉出来去测,测完之后没有问题,再发布出来。还有一点,你打了线上的补丁,你的Repo没更新,出来的东西还是有漏洞的,所以它一起把Repo更新掉,保证新生产出来的机器已经具有了这个漏洞,从技术架构上我们就是这样做的。
有了上面的准备工作,后面将会更进一步谈到的是补丁部署的时候怎么保证安全,有了技术架构,我也可以让它出补丁了,我也可以做我的测试了,我们的开发团队也可以知道这些补丁什么时候部署了。
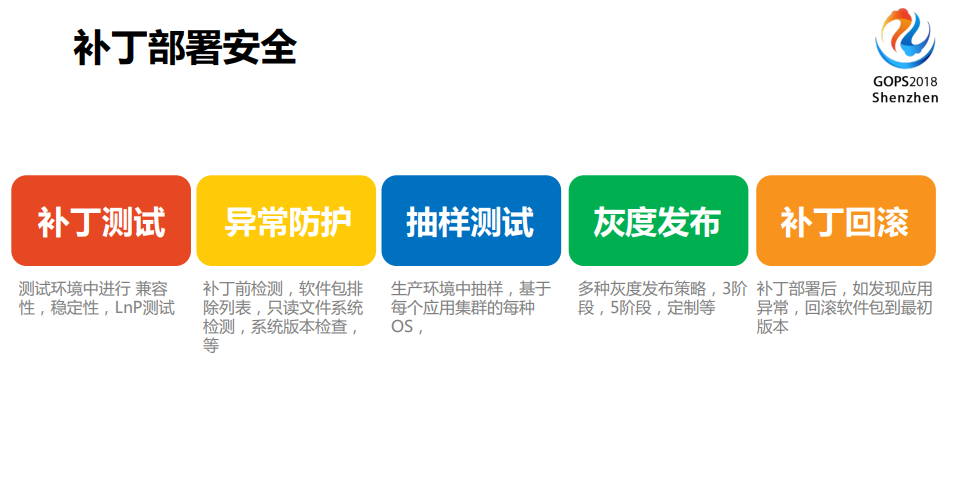
在补丁部署上呢,我们的运维团队是直接部署的,首先是做补丁测试,还有异常防护,很多时候其实对于运维和开发最大的差别是说,运维要担负的责任是要预防那些还没有预见到或者说已经可能预见到,但是还不知道什么时候发生的问题,所以我们会做异常防护,补丁之前我们会排查软件包的列表。我们会基于某些应用有一个黑名单,它的应用列表是不打的,或者我们会看对于像PHP这种可能会影响到应用的,我们把它加到黑名单里面,系统补丁、安全补丁不打。接下来就是重要的抽样测试,在灰度测试里面会谈到金丝雀测试,就是抽样测试,我们把它放到生产环境里面,每个案例库找一台去跑,并且找同样的OS,然后再做灰度发布,灰度发布可以分为三阶段、五阶段,或者说你可以随便定义。如果实在你的运气不好,你还有机会回滚,而不至于让你的业务受到很大的影响。
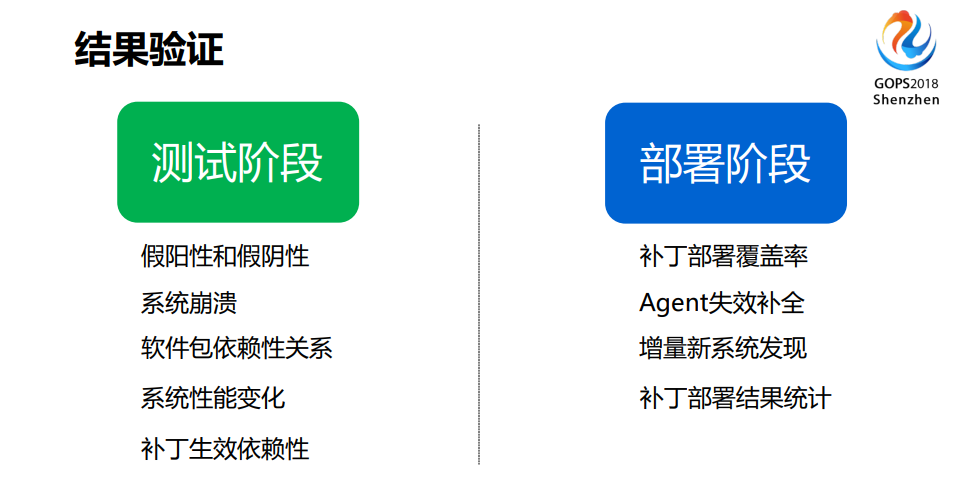
接下来我们看看在结果测试里面会碰到的问题。
比如说假阳性和假阴性。
什么叫假阳性?
外部扫描软件扫出来说你这里有个漏洞,结果你再一看,这是一台Linux设备,在你的配置数据库里面有双数据存在,这个世界对我们来讲并不是那么美好的,我们要对这个世界有了解,这个世界不美好,我要知道它哪里不美好,这可能是会存在的问题,这是假阳性。
假阴性就是,明明你打过补丁了,你看到没问题了,你看到的版本号跟你这个是一样的,只不过你是看错了,扫描的时候会告诉你,你说的阴性还是有漏洞的,这是在我们现在测试阶段会碰到的问题,就是说你如何去验证你在打完一个补丁的时候真的是已经补丁完成了,然后会测试系统会不会崩溃,软件包依赖的关系、性能的变化,还有生效的依赖性关系。
还有就是部署阶段我们怎么验证。
其实部署阶段的坑更多,一个是补丁部署的覆盖率,我们经常说我们打完补丁之后,window系统是你把包下在那里通知它去装,这靠的是agent,但是它可能会失效,你怎么发现它失效。还有就是当你的包下下来之后,它其实并没有准备好,它那个时候还有大批量的机器会被退出来,这是我们完全不知道的,所以你要看在这段时间到底有多少机器被退出来。还有增量新系统的发现,最后还要看这次结果里面有多少补丁要打,你的工作量是多少,这一点要跟你的老板去讲,这是我的工作量,我这个月做了多少事情,虽然我只有12个人,但是我做了这么多事情,要让他知道结果是什么。同时你的老板还要向你的老板的老板去解释。

在结果测试除了以上两个问题外还会其他的问题,比如说打补丁的时候其实会涉及到重启,会涉及到OS宕掉。我们要有一个锁机制,当我去部署这个补丁的时候,与此同时你不要再减少它的容量,代码部署可能会影响到它。另外是监控,如果机器下线了,重启了,监控的人要知道为什么,他甚至想说,你打补丁是正常的变更,你不要让我看到这么乱。还有是它的权限管理,我可以把压力传导到其它的部门,我们基于AD的管理或者LDAP的管理,你有你的权限,应该是我提供工具给你用,出了问题是你的问题。
三. 系统架构
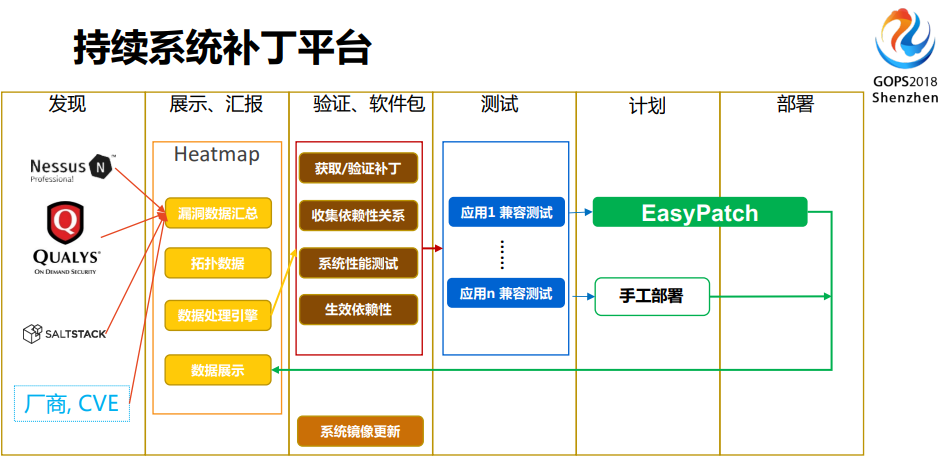
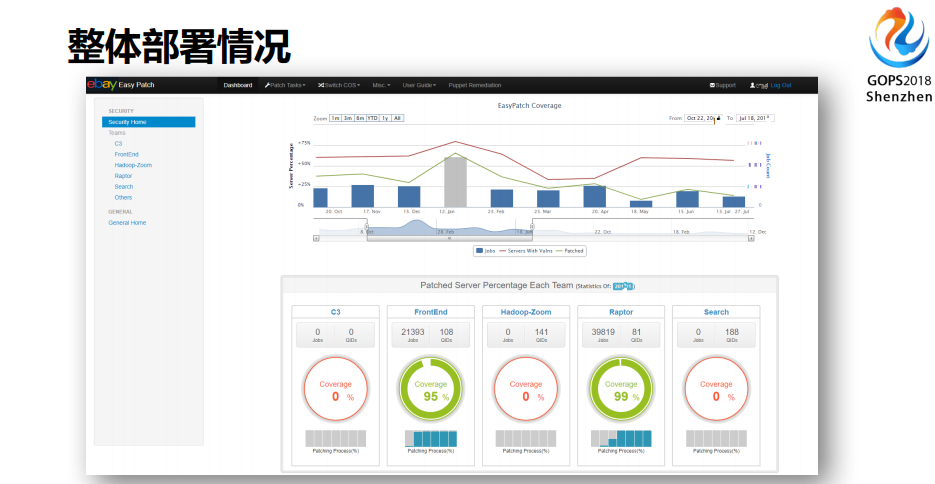
接下来我们可以看整体系统架构,大概就是这样一张图,从发现到展示,你怎么展示你的图,漏洞的数据,验证你的软件包,然后测试、计划、部署,可能还有一部分,你不能被纳入到自动化,它是特殊应用,它不能被纳入到自动化部署。比如说数据库,我不敢纳入进来,打挂了我负不了这个责任。因为总共就两台DB,我为什么要部署它?整个流程走完之后,你会看到这边有一个数据展示,把你的结果告诉给老板,通常最后关心的不是运维关心的数据,最后你的老板可能会关心,他要对外部的公开媒介公布自己的健康状况到底是怎样的。
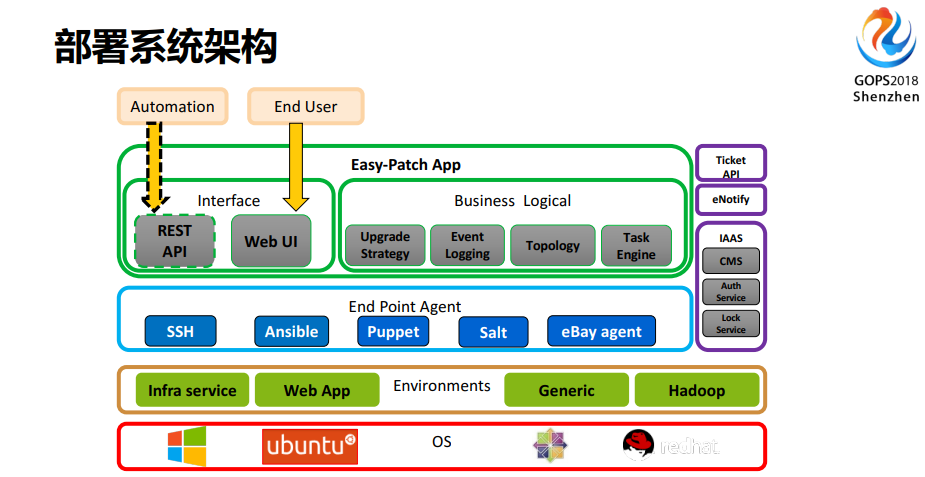
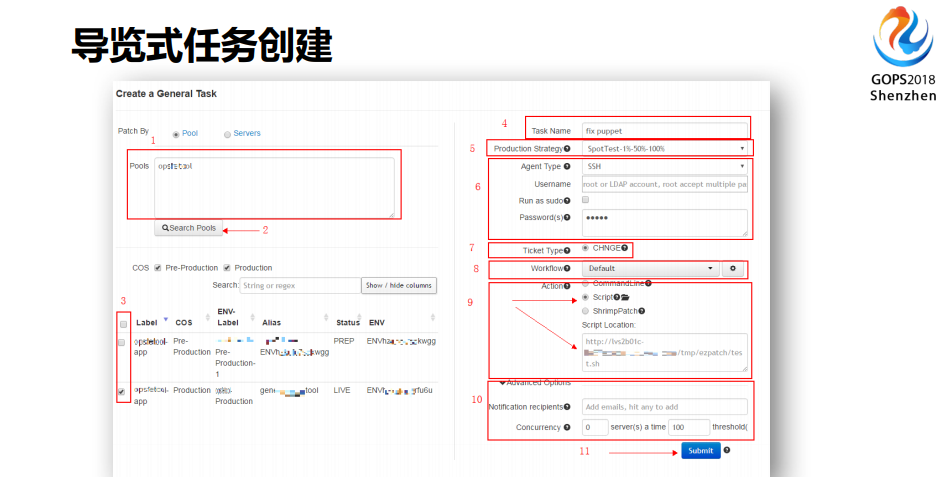
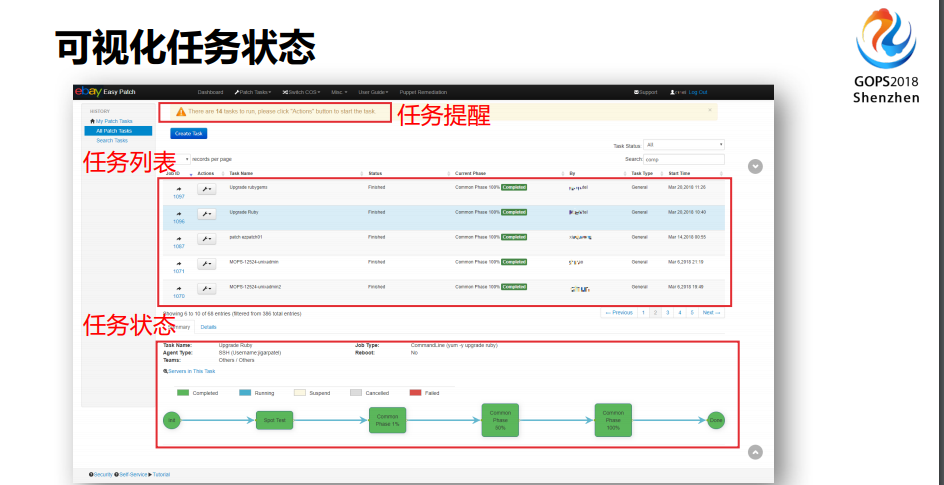
在eBay内部前端运维是管理整个WEB服务器的,然后还有其他的团队负责其它的事情,我们根据LDAP或者AD让他们管理好自己的部分。然后你是怎么部署的,你怎么连接,你的工单是什么,需不需要发变更,你要发命令或者发脚本下去,或者有防护的脚本,你的脚本在哪里,要告诉他,随着你要把消息推送给谁,当你打完这个工单之后,你很清晰的就知道你完成了多少,并且我告诉你当前还有多少任务没完成。
最后有一个图表显示,我的工作是这些部分。
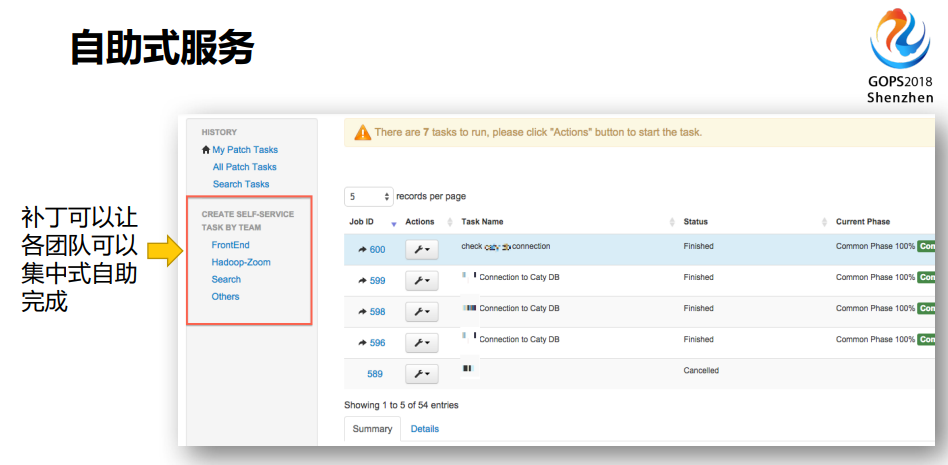
还有一些是其它部门的同事要做的,这个是要由他们来做的。
四. 未来展望

介绍完了现在的状况,展望未来,还有很多可以想像的空间,一个是我们要做内核热补丁。我们前面讲的都是系统级的,内核的补丁怎么打?另外一个是我们希望借用以后的科技,融合或重装不需要带补丁。
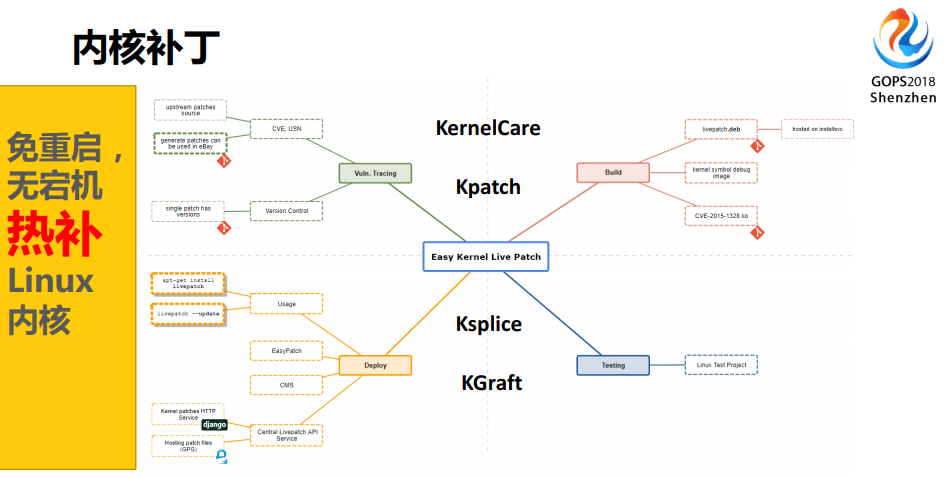
这个内核补丁我们讲了几种技术,我们选择的是Kpatch,还有其它的几种技术可以选用。
所有的机器就像一艘船一样,操作系统只是一个载体,只是提供你的运算资源,如果你所有的代码、所有的依赖性关系都在容器里面的话,其实我只需要替换一个容器就行了,或者你上面是容器,下面的船给你修好,把容器拿掉,放到另外一个船上也可以,相对来讲你会快很多,而且你也会轻松很多,而且你会把应用上的漏洞一起解决,我们以前讲应用的漏洞我们让开发人员自己改,放在部署里面,这样做会更快。

我们希望以后让打补丁变得就这么溜,轻轻松松搞定,不用再痛苦或者迷盲。我的分享就到这里,谢谢大家。



