@gaoxiaoyunwei2017
2019-04-29T06:52:43.000000Z
字数 8168
阅读 1355
多云环境下的自动化运维实践
白凡
分享:赵班长
编辑:白凡
讲师介绍:作为第一个演讲者,我演讲的主题是混合云环境下的自动化运维实践。可能有不太熟悉的,我叫赵班长,之前在武警部队做运维工作,最早做电台台长,后来做运维,2008年退役之后一直做运维。从工程师到运维总监,我现在应该算是在创业阶段、打工阶段、打杂阶段。

我也写了运维知识体系和缓存知识体系,大家可以直接百度,有一天睡不着,我想了一下运维有哪些知识。很多人问我怎么做一个CTO,以前的年代研发很容易成长为CTO,在现在的年代,运维很容易成长为CTO。为什么?运维不专业写代码之外,其实剩下所有的技术,你都应该掌握。之前有一个猎头,我问他说,现在你们招一个CTO需要哪些条件?他说现在要CTO,班长,你告诉身边的CTO千万不要离职,因为他们离职可能找不到工作。
为什么?因为现在的猎头找CTO,你要懂架构、运维、测试、大数据、云计算、AI,当时我都蒙了。他说对,我说这么厉害,能拿多少钱,他说这边的职位都是年薪百万的,都是这么要求的。还有一个潜规则,要求MBA,招聘要求不会写,但是潜规则。现在CTO好难,原来CTO怎么当上的?研发经理、研发总监、CTO。以前很难从运维成长为CTO,现在越来越多了。

我们的话题围绕资源管理、应用管理,最后用一点时间简单介绍一下混沌工程。之前有人问我说,班长,我如何评测企业自动化建设的成熟度,大家都在做,我们搞了好多年,不知道自己是否做得好。我说做得是否不好不要看安排什么工具,现在工具好多,看什么呢?我问你一个问题,如果你能答出来就说明你们的自动化水平比较高。问题是什么?如果将生产中一太Web服务虚拟机直接删除掉,是否可以使用自动化手段恢复?第一,如果有人把虚拟机干掉,你第一部分要干什么?先说一个例外的话题,一个虚拟机被干掉了,不应该对你的生产造成任何的影响。你的第一个反应是干掉了,干掉就干掉了,如果你没有这种回答说明你当前的架构存在以下的问题。干掉就干掉了,不会对业务产生任何的影响。这是正确的。在此基础上再往下走:
第一,你是否能自动化创建一台新的虚拟机?不管用公有云、私有云。
第二,是否能够把自动化配置应用运行环境?当然有人说,我把虚拟机镜像直接做好,这也是一种方式,都可以。
第三,你是否能够自动化部署应用的当前版本?这个业务在跑,现在被干掉了,你肯定要把最新的版本部署上去,有人说把代码打包在里面,那代码就废掉了。
第四,这个机器代码部署完以后是否能自动添加监控。监控包括机器的监控、中间件的监控、应用的监控。
第五,你是否能够完成日志的自动采集。注意,是自动化的。
第六,是否能够自动化执行冒烟测试?新部署了机器,肯定要测试一下才能上线,不能部署完就往上,一旦有问题肯定不行。我们之前这么干的,没有冒烟测试,自动化觉得做得很牛,上了之后两天才发现有问题,为什么呢?因为这台机器上不了网,所有API的回调都调不来。因为一个集群有好几个节点,这台机器很小,所以大家监控没有考虑,大家看到500没有注意,后来发现有一个节点上不了网,没有做到冒烟测试。
第七,是否能够自动化添加新节点到集群中?不管你用的什么,是否能添加到集群?可能只有命令,公有云不一定非要写API,也有命令行。
第八,以上所有步骤是否涉及到CMDB的资产添加和状态变更。应该有一个状态记录资产添加,新增一个资产,资产的状态是什么?未安装、安装完毕、测试完毕、已上线。
如果你把这八个问题,你说这八个问题在我们公司全是自动化的,恭喜你,你的自动化程度做得还不错。因为自动化有点像项目的特性,项目的特性叫见即明细,做着发现这么多要做。没有一个边界说我们公司的自动化做完了,没有其他可以做的,没有这个边界,只能说不断去完善,不断去完善。

这是我之前分享的基于全开源的自动化运维的工具体系,自动化的安装-配置管理-监控-日志采集等等。很多企业,我分享完之后,之前有企业叫我过去,班长,你帮我们看一下企业的自动化做得怎么样。班长把图打出来,不屑一顾,这些我全有,我说那你有什么痛点?还是有痛点,这些东西全有,但是自动化还是做得不够好。我说你回答一个问题,他发现连不起来,整个工具链串联不起来,都是独立的。刚才那个问题,很多人心里有疑问,班长,你这八个问题如果用K8S的话,K8S会创建一个系统出来,K8S可以给Port设置健康检查,包括存活的健康检查和就绪的检查。添加新起一个PUT,K8S有一个控制器更更新,这样就更新Svrs,如果你用K8S好像八个问题有六七个都解决了。很多人问我说想做K8S,我说应该先懂现在的运维是怎么样的?
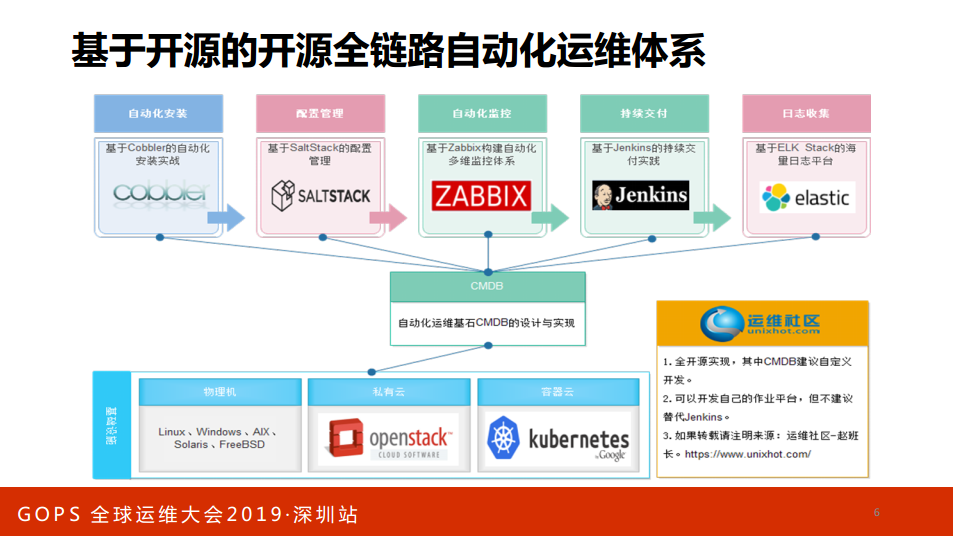
这是调研报告,看到有60%的企业都使用Docker,60%的企业都使用K8S。
这个话题为什么是多云,这是第三方的调查报告?调查100多个企业用户,84%的用户有多云的企业,18%是混合云,17%是私有云,58%是多有云。
有一个好的方式是做公有云的运维,比如说你再考一个证书再快转型。公有云给大家带来一个什么好处?学习,你想我们学习看文章、看书,其实刚入门运维的,我说你什么都不要看,你看公有云产品文档,你可以把概念的全新技术全部学会。
有些人刚入行不知道怎么学CDN,我说你去看CDN的产品白皮书。之前只要有新产品发布,我组织团队里面学习,看一下,因为很多公有云的产品是他们内部多年的经验产品化之后的分享。这些东西都可以学习,如果没有看过我的运维知识体系,下来可以百度搜索一下。
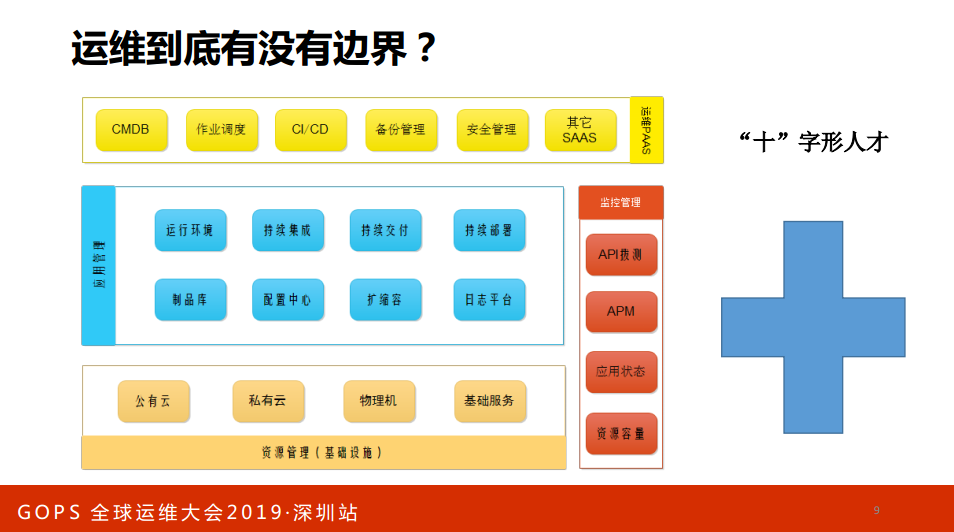
这就衍生出来一个问题,运维到底有没有边界?你发现现在什么技术都能和运维挂钩,大家有没有发现?其实在这些年运维场景化越来越严重了,很多公司招聘运维很明显说我要基础设施的运维。我要做平台开发的运维平台开发工程师,我要专门做监控系统的监控运维工程师,我要做应用管理的应用管理工程师,现在还有一个更火的职位:大数据运维,因为缺人。咱们这边有找大数据运维工程师的可以找我,我这边有几个腾讯的职位,他们很缺,又懂大数据又做运维的。现在运维场景华越来越细分了,这个细分有没有什么不好的影响,有的。在我面试的新入门的运维,他们对运维的掌握只会垂直化,我只会这一块,其他的不会。不像在座的老运维都能会,没办法,你就只能做领导。

大家之前讲过“T”字型人才,我个人比较崇尚十字型人才,做技术一定要带有深度,尤其是运维工程师。我面试只有一句话,不要讲你会什么,你最精通哪一门技术?很多运维不会讲,NS熟吗?还行,私有云也玩儿过,K8S也玩儿过,你到底哪个精通?都还行,在团队里面,肯定想要一部分人对某一门技术精通?这样团队才有综合性,不能说什么都行,那你干我的职位。运维要有深度。
第二,光度不能少。你说我只会这一个行不行,也行?你说我只会Redios,运维很难深度某一个领域。大数据运维行不行?也行,但是你想做CTO很难,也行,你到大数据公司做CTO。还有一个往上的,有人说是高度,有人说做技术和运维带有高度,首先我是认同高度,以前我参加大会,主会场我肯定不去,分会场感兴趣就过去了。主会场觉得是听领导吹,这真的是误解,高度不够,现在参加大会都去主会场,你要掌握技术的方向,如果不掌握方向只做手里的技术对你未来的发展是有影响的。如果大家参加大会先去主会场,主会场先听。因为你回去给领导报告,领导说你学了什么?你给他讲技术,你给他讲整个运维行业的发展,他觉得钱花得值。这可以理解成高度,除了技术有高度之外,还可以理解为什么?细分了,比如说管理,比如说业务,其实都可以。比如说第一个管理,大家要掌握一些,至少在中国的形势下不可能一直做工程师,现在好多公司招聘工程师30岁以上不要,有的放宽到35岁,可能得做管理了,其实还有一个就是业务。很多做应用运维跑偏了,我面试应用运维工程师只会讲你们公司怎么赚钱的,如果这个人讲不明白就不合格,应用运维就是服务于业务的,你都不知道怎么赚钱的,你运维做得太没有高度。
大家自嘲码农,我不知道怎么写,领导叫我这么些就这么些。做运维也是一样,你都不知道怎么赚钱的,我只知道这个不能挂,你就是一个搬砖的。如果你未来要做管理一定要懂业务,其实懂业务的运维挺可怕的,我之前做广告业务,我们老板怕我出去单干,因为业务体系我很熟,除了销售以外,其实我自己另起一摊就可以单干的,因为你懂业务。希望大家朝着“T”字环境发展。
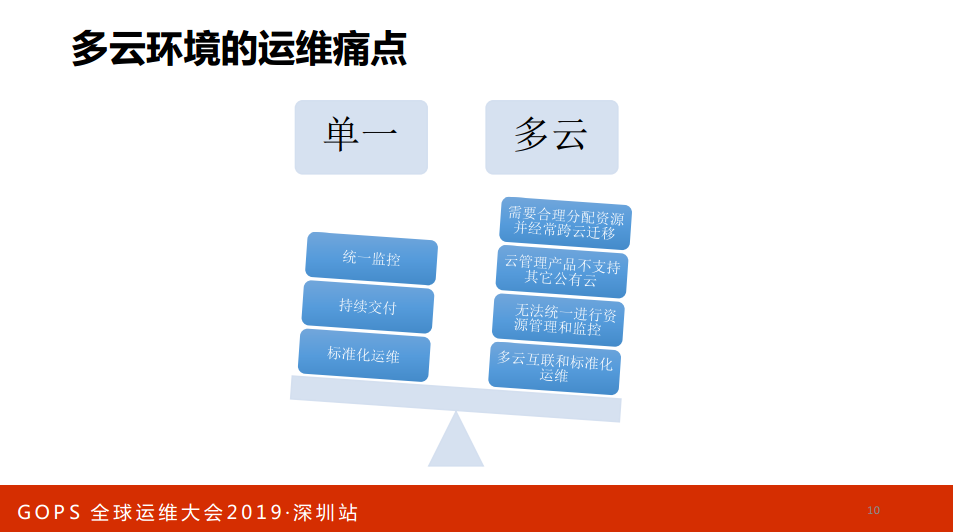
在多云环境下,你在多云环境下有很多公有云,你用一个云产品的管理,发现它不支持多个公有云,管理起来不方便,资源和监控无法统一,标准化无法统一,我们之前有一个坑,什么坑呢?我们都知道阿里云的云主机对DNS的解析配置了参数,两个DNS是负载均衡的模式。我们的工程师所有线下的模式都是按照阿里云的配置,他觉得阿里云配置不会错,结合全部参考阿里云的配置,因为我们是轮循,有的通有的不通,导致有的业务一会儿好一会儿不好,当时很郁闷,怎么回出现这样的问题?检查发现是这样的问题。某一些是全部标准化,某一些是单个标准化。
如果提到资源管理,我们大家都会讲CMDB,这是一个古老的话题。CMDB是哪里提出来的?在资产配置和管理的时候提出来的,提出来资源配置管理,大家发现这两年火了。因为大家开始说以前叫做传统的CMDB,服务于Ito这个流程,现在服务于应用,通过应用的反层设计和应用数来管理资产。还有做场景管理的,以前对场景的服务并没有那么高,现在做持续交付和自动化就可以把很多服务存储在数据。自动化运维其实想打通所有的链条只能依靠一个组件,那就是CMDB。这不算是业界提出来的,我个人有一个想法,未来的CMDB一定要往多云管理的方向去发展,支持混合云。现在行业的CMDB有支持混合云的吗?很少,老牌的都不支持。
第一个,CMDB未来要把堡垒机融合在一块儿。在座有生产堡垒机的举手,堡垒机是不是有资产管理,堡垒机是不是有权限管理。这些里面都有CMDB,其实你在权限里面加入CMDB的功能就很容易实现。未来堡垒机是很激励的产品,可以与CMDB放在一起人,你把证书放在里面,我可以帮你做录型,现在可以做很多实现。
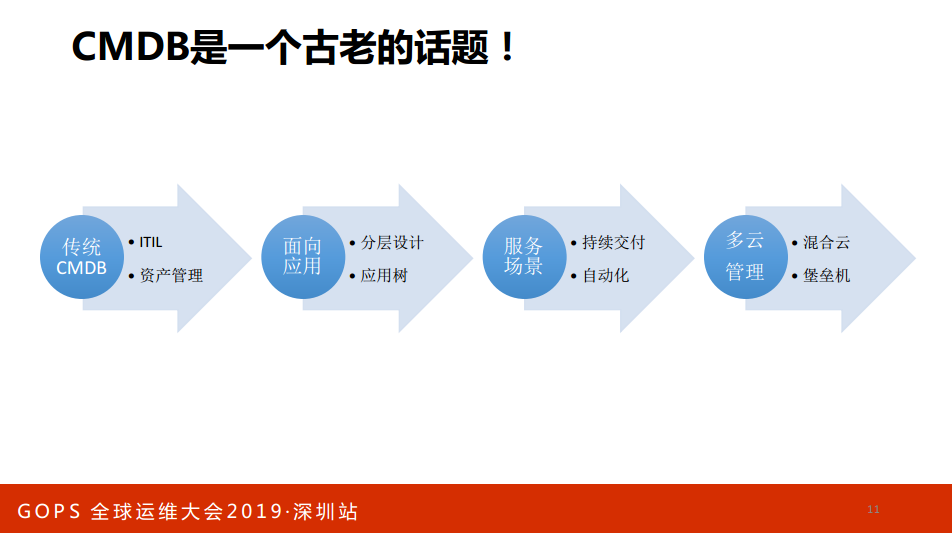
做CMDB建设,我们之前总结了一个叫三步工作法或者3C工作法。什么叫做3C工作法?我们觉得做CMDB应该有三个步骤:
第一,建立核心。你要把CMDB建成个自动化运维的核心,或者我们称之为弱化CMDB,不要让运维人感觉到CMDB,上面是数据库。
第二,连接。链接就意味着你的CMDB和其他的运维系统连接起来,如果链接不起来就是失败的。
第三,做系统的闭环,和各个环节连接起来以后,系统要做闭环,要把数据修复掉保证资产和线上是100%一致的,可以存在某一段时间的不一致,但是要保证某一段时间的不一致。
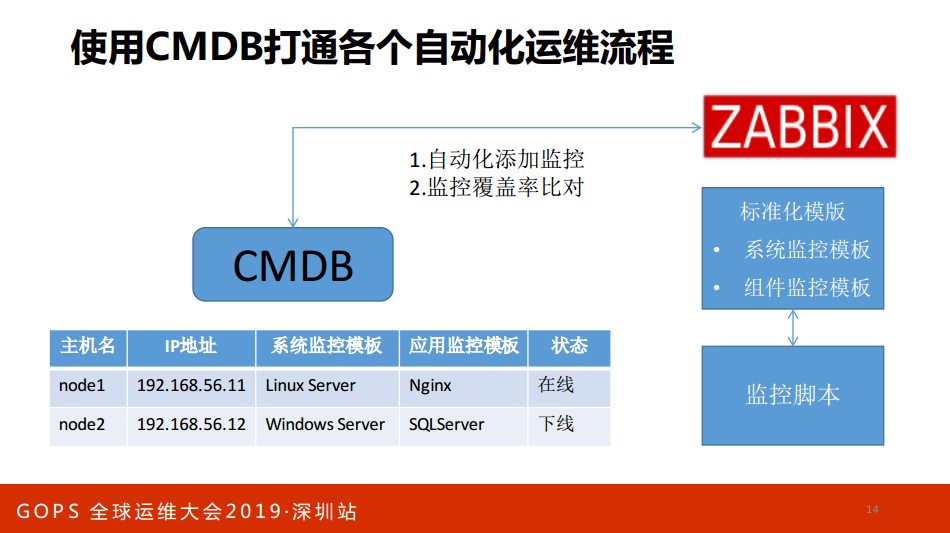
以CMDB为核心,意味着你要把自动化运维所有的东西都存在CMDB中。比如说监控,像我们之前是不允许做操作和添加机器,因为我们把CMDB和资产关联好了,你只需要在CMDB添加资产,选择资产的操作系统和监控,自动添加监控,所以不允许工程师自动添加操作。以前这么做,昨天挂一台机器,就那台机器忘记加监控,它就挂掉了。咱们在座的领导问你说咱们公司的监控覆盖率能到100%,如果你没有把CMDB和管控连接起来绝对没有,如果你的手下告诉你有,那就是骗你的。包括CMDB,包括应该把API覆盖进去。你要把CMDB打通整个自动化的流程,我们之前监控是用ZABBIX,我们对ZABBIX会做标准化,标准化的系统监控,所有的组件像ES、Kafka等等会一个一个去组件化,组件化一是包括模块;

二是脚本。把这些东西方在一个地方,我们CMDB做什么?有一个新的资产添加的状态,我后端的脚本会调用ZABBIX做自动化的监控添加,如果这台机器没有添加就加上。我们之前用ZABBIX的发现,因为ZABBIX的网络发现问题很多,比如说我们用的机器很老,一个机器上面七八个地址,或者有的地址服务很多,那就各种不好用,除非你做了标准化,所以我们废弃了主动去做。
不做CMDB建设可以简单给大家一个模型或者参考。我们之前做底层用MongoDB,做了数据模型接口层,做公有云API、模型管理、仓库关系,上面做Restapi,最外面做外部应用和Dashboard。比如说内部堡垒机通过WebSSH支持、VNC支持、Windows,多租户管理:租户直接相关,不规则租户,混合云管理,AWS:EC2、SG、RDS、SLB,标准RestAPI。所有的CMDB一定是有框的CMDB,域名不通就搜一下,看一下对应的IP是什么,内网是什么,外网是什么,研发做的CMDB不知道运维有这样的需求,很多时候做出来就是外国版的Excel,不能怼得太厉害,待会儿CMDB的厂商要进来砍人了。
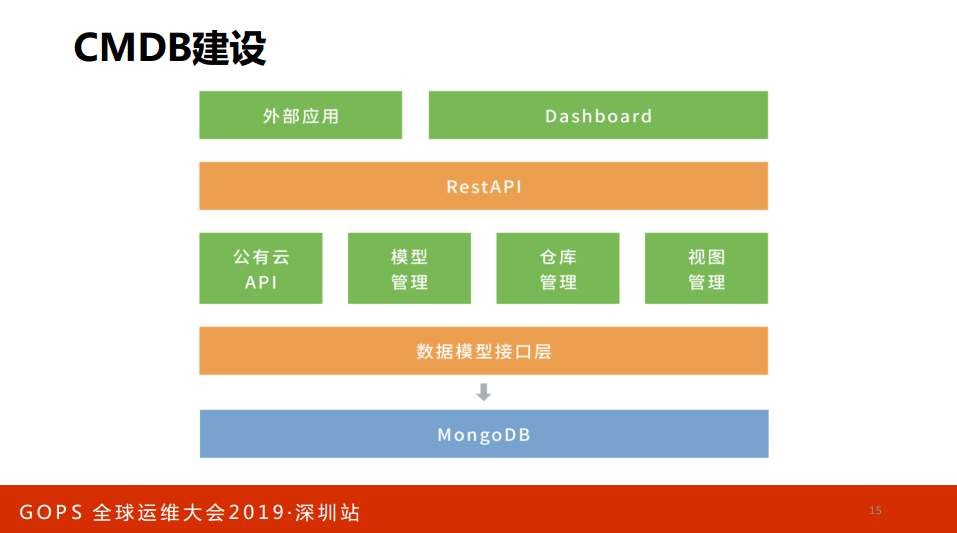
如果你选购一个CMDB,这个CMDB的产品人是什么出身,如果不是运维出身就不要考虑。我说做了十几年运维的人和没有做运维的人做出来的产品完全不一样,完全不符合运维的场景,完全玩应用,炫技术,有十几种关系,蕴含在,包含在,链接,每次讲关系都要拿出文档,这样的CMDB给我们运维能明白吗?
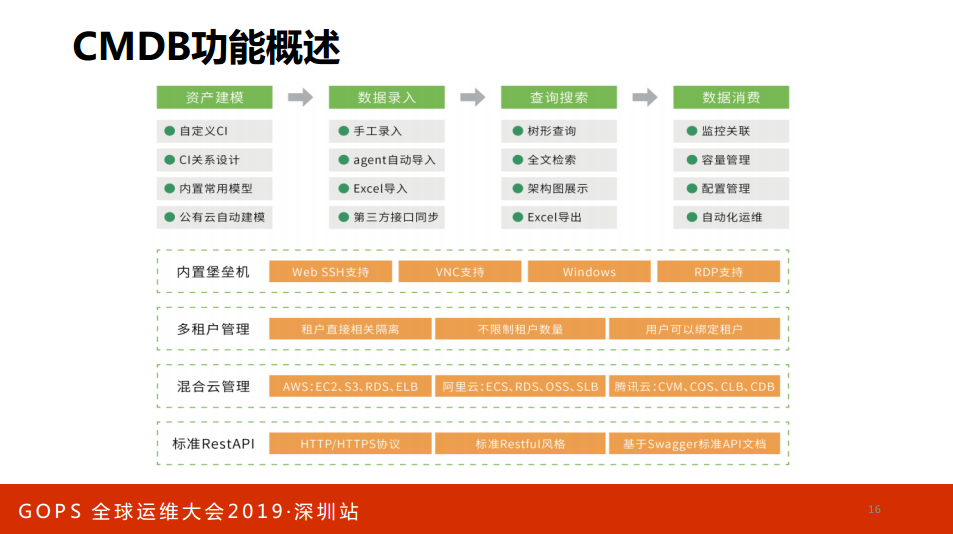
2. 多云环境下的应用管理
非容器应用环境配置管理。目前主流就是比如说开源的像SaltStack、Ansible,SaltStack有Agnet、Salt-SSH、SaltCleud,除了BAT不要自研Agent,因为我身边有人自研的,超级不稳定。我在座培训的,以后讲培训不要教写Agent,很多人觉得搞一个模块把客户端一连就把Agent,不要误人子弟,稳定性真的不好。包括资源的使用率。

做运维配置很多人跑偏了,运维的世界有两种管理模式:一种是声明式管理;二种是命令式。很多人用Ansible都用错了,命令编排,其实都是生命周期管理,我声明一个管理,执行得多了,什么标准化一致性都没有了。这是我要强调的一点,非应用环境的,那么我个人更倾向于做声明式的管理,不要做命令式的管理,中国依然很多人运维做命令式的管理。没办法,错的人对了就认为是对的。
容器其实就是Dockerfile,可以做级联的、分层的,下面是操作系统、运营环境、上面是应用,可以做镜像的预热。我们之前做镜像就是在全网铺一下,标准化的镜像,操作系统层和运行环境层未来部署应用只需要拉不同的层就可以了。当然,可以基于开源去封装,有人说我想自己写怎么办?
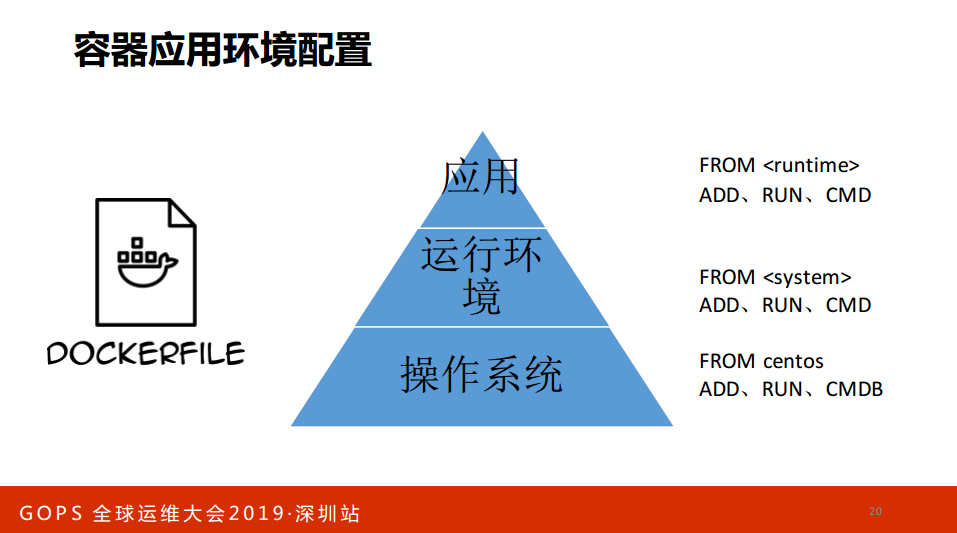
不写Agent,你基于开源做一个封装,比如说你装Saltminion-ZABBIX-AgentFilebeat,封装起来Supervisor有一个集成的感受,这样是你工程师走了还找到其他的东西,你工程师走了到其他的公司发现没有这个东西。原生API调用还可以紧跟开源社区,很多公司做二次开发就回不到炉子了。
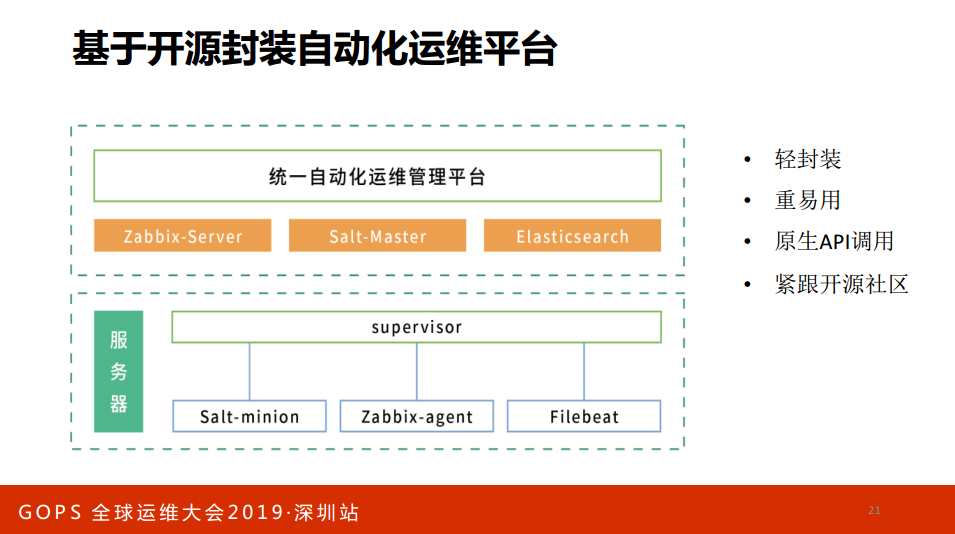
很多理念是腾讯蓝鲸的理念,这不一样,他们是PaaS平台。

讲完了应用配置、应用资产管理,下一步做CI/CD,比如说用Jenkins做编排,用K8S做应用管理,这种实践听了很多。
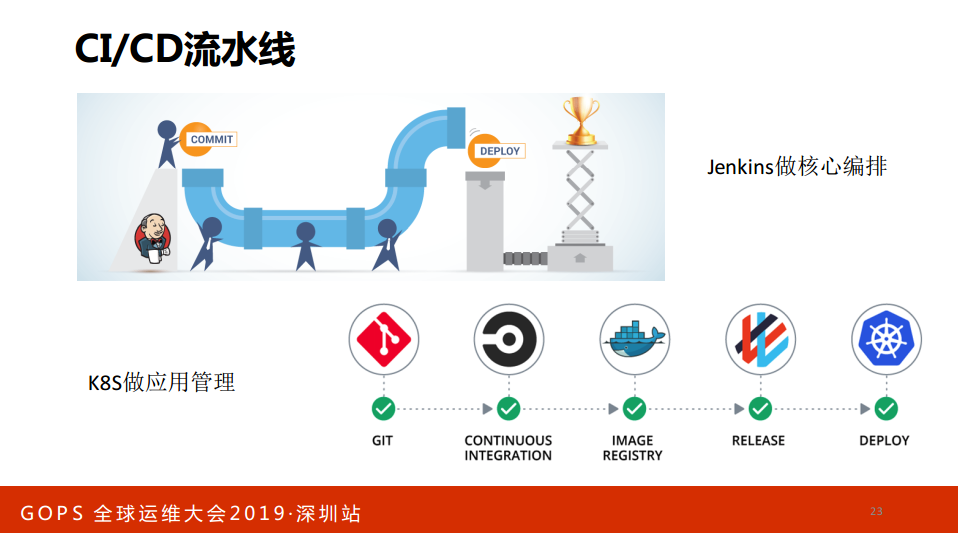
如何区分一个讲师是干过还是没干过?现实中的Pipeline不是改数据就行了,涉及到数据库,有人给你讲数据库涉及到Pipeline,不是的,一般领导介绍怎么干的。你说干过的,我们三个DB一个做管理,一个做线上业务,一个天天执行sql,别人还看看执行计划、调调优,我没有时间看。
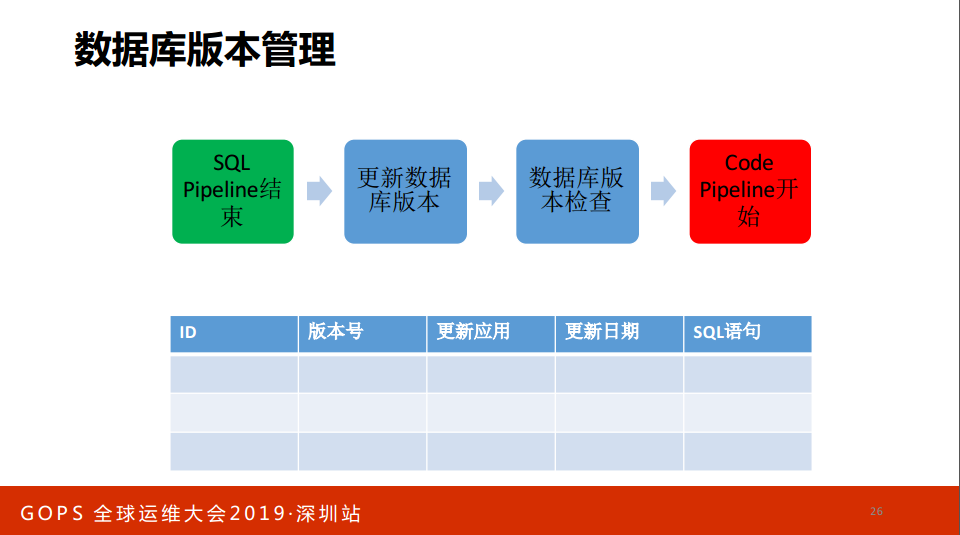
这时候怎么看,做一个设计库存变革的平台,基础设施的Pipeline,可以通过发布就完了。比如说SQL提交,SQL工单,继续变本号,自动审核,SQL语法审核、SQL规范审核,自动备份,根据表大小。同时还要做数据库的版本管理,在DevOps有一个理念,把数据库的版本和应用的版本写成一样的,不一样有一个对应的关系,每一次更新都有一张表记录数据库当前的版本。
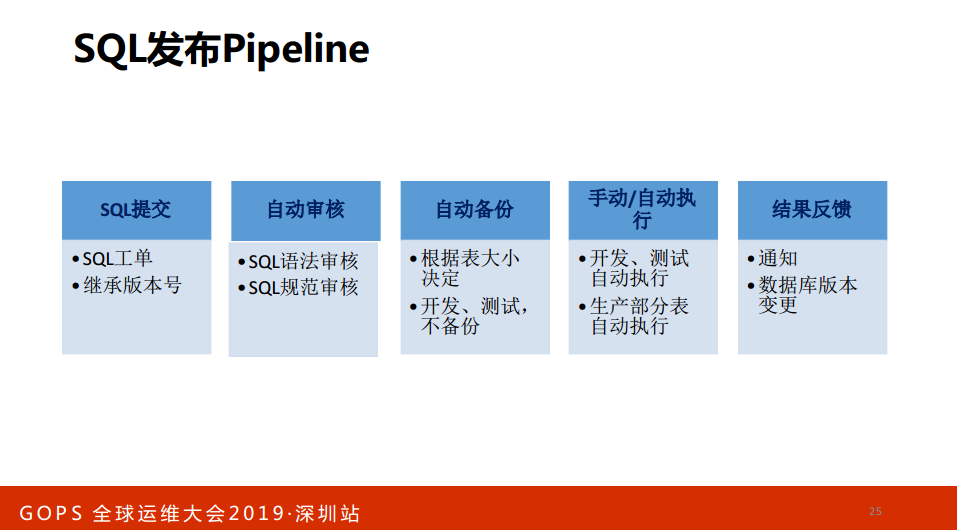
当前的版本是什么?哪个应用更新的,更新的版本号是什么,sql是什么,可以记录每一次数据库的变更。每一次做代码部署的时候要做数据库的版本检查,如果版本不对说明什么?数据库还没有执行,先不要执行。原来我们发文件说执行一下SQL,4点发的,6点怎么都DB布完了,这边就开始布了,后端没有说报错了,我们排除故障排除了30分钟,DB也很后悔,不好意思。
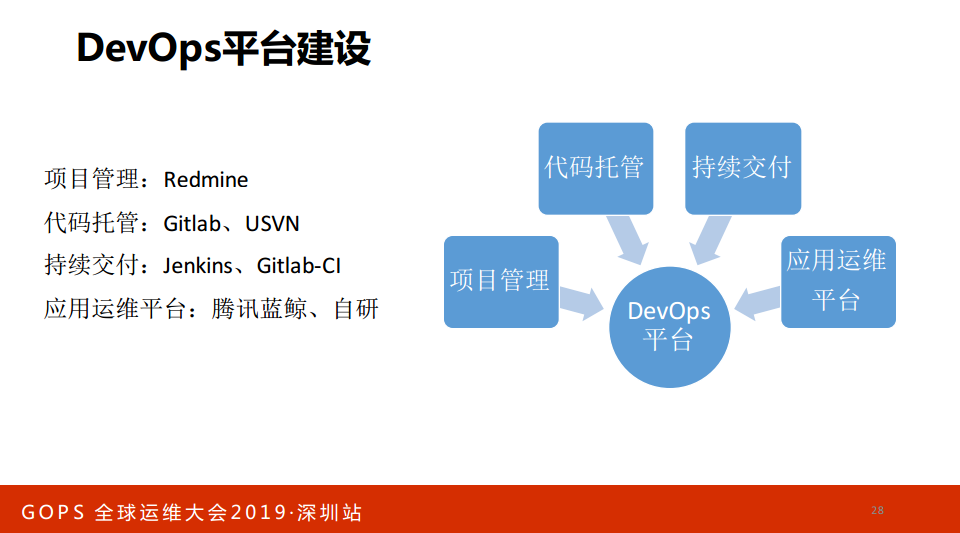
开源数据库版本控制也有,比如说Flyway和Liquivs,前者封装少,后者封装多。我们看DevOps平台建设,DevOps有四大模块:项目管理、代码托管、持续交付、应用运维平台。

项目管理有Redmine。如果你想自建怎么办?学别人怎么办。这样就没有自主产权了,不是的,做工程师首先要干什么?首先要承认自己很平凡,我承认自己是一个平凡的人,有很多优秀的,我向他学习。
别老认为自己是正确的,包括看一下百度效率云,这是阿里的云效,包括腾讯的,腾讯云现在好像在推Codin,推Codin的解决方案。

应用运营时配置,DevOps中的一些原则,一是代码和配置的分离,制品只构建一次,一个脚本部署多套环境。
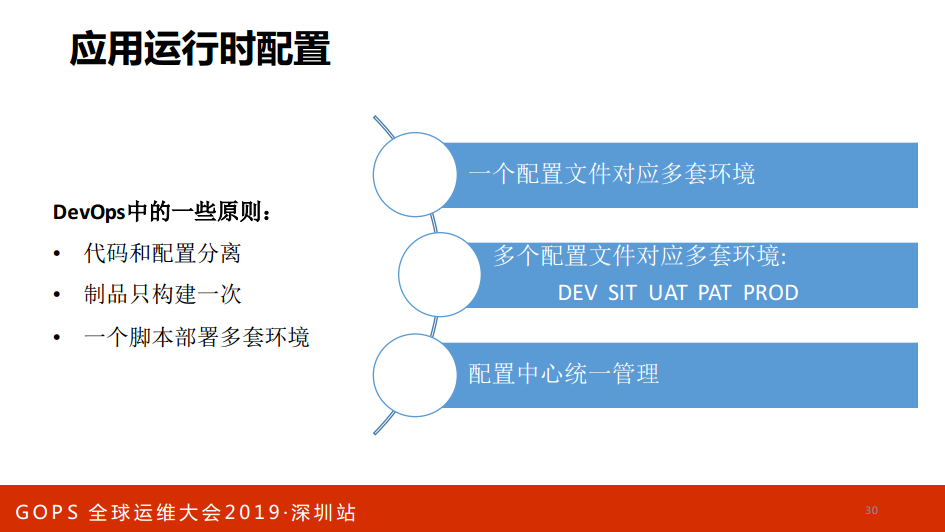
这时候面临配置文件,一个配置文件对应多套环境,每一个配置文件对应多套环境,配置中心统一管理。
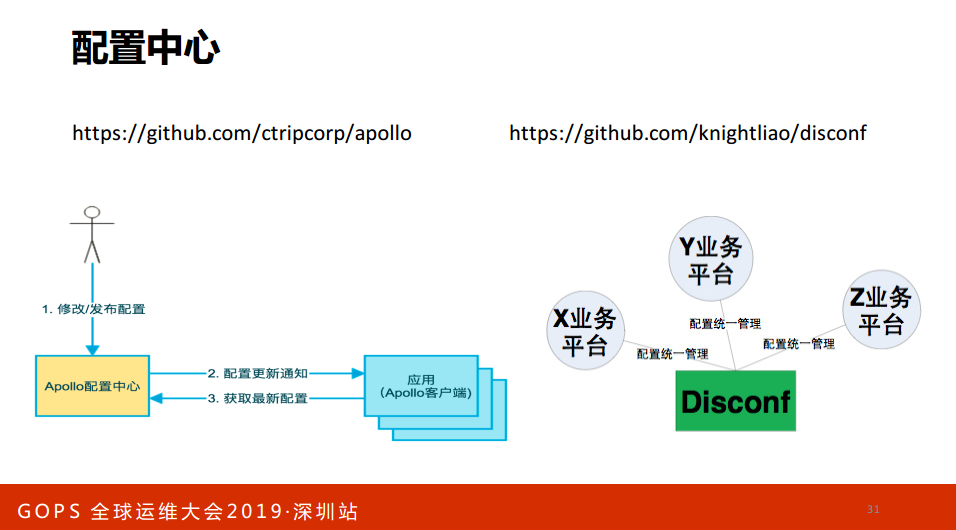
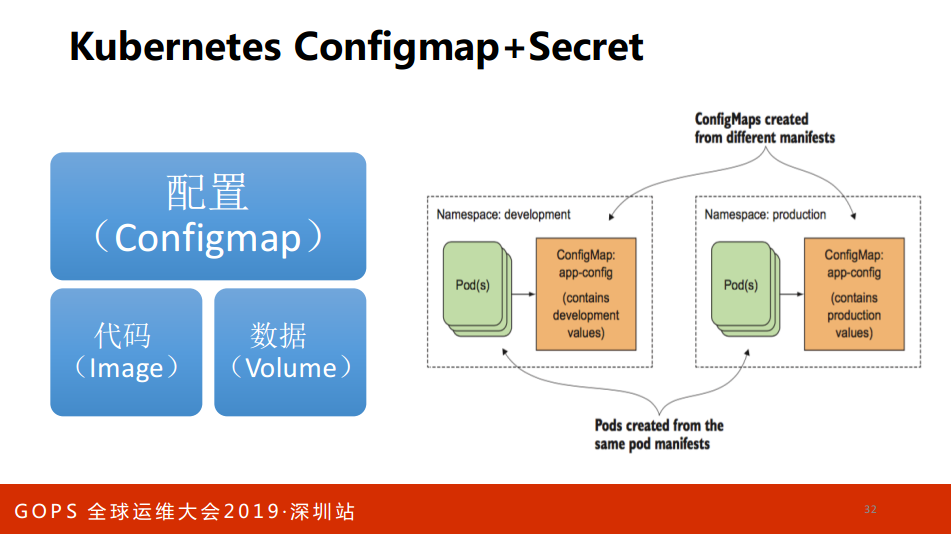
如果你用K8S怎么玩儿?那就是Configmap,K8S代码是Image,数据Volume,数据通过PVC的方式来做存储。
3. 多云环境下的混沌工程探索
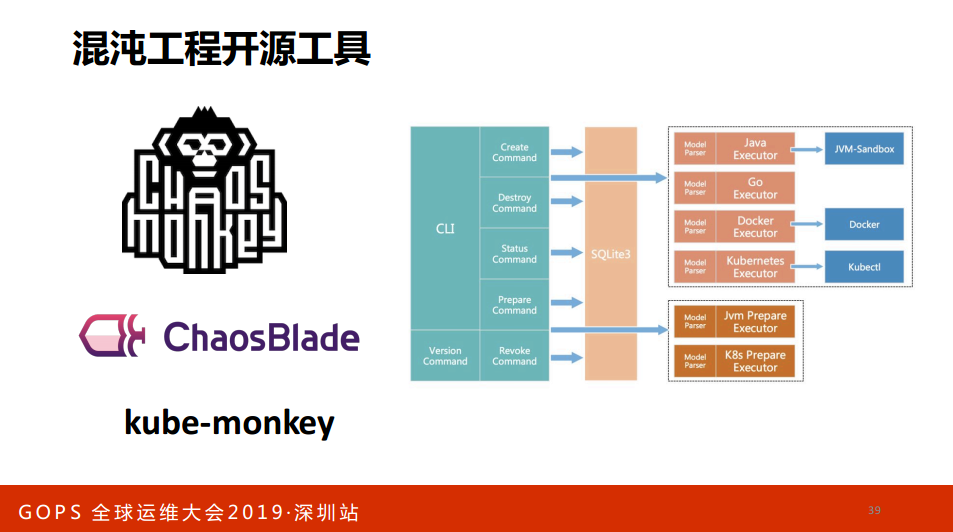
最后有两分钟再介绍一下,因为我发现大会没有讲混沌工程的。我最近在研究,我利用两分钟给大家讲一下,如果有兴趣可以去研究。什么指混沌工程,混沌工程是在分布式系统上进行实验的学科,在生产环境中进行由经验指导和受控实验,目的是建立对系统抵御生产环境中失控条件的能力以及信心。

这是最早NETFLIX在2010年提出来做了一个Monkeys,只有把云主机干掉,看一下怎么恢复。从2010年到现在的演变,,到2017年有一个商业的产品,混沌工程其实已经开始做商业化了,从最早提出做了这只猴子到做猿猴军团,到最后开源,提出了FAT的概念,叫做故障注入测试,到最后的商业。

大家可以了解一下,大家有一个疑问,混沌工程与测试有什么区别?混沌工程是一种实验,针对于未知的环境,我不知道如果这台机器发生什么情况,它会导致什么现象,所以混沌工程是一种未知的探索。但是测试是已知的,比如说高可用测试,我把这台机器搞看看是否能自动华迁移。他们两者有很多一样的地方,也有很多不一样的地方,混沌工程提出很多原则,这个行业还处于没有标准的东西,各大公司都在探索,这时候混沌工程提出一个原则,你要符合我的原则就是很好做混沌工程的事情。

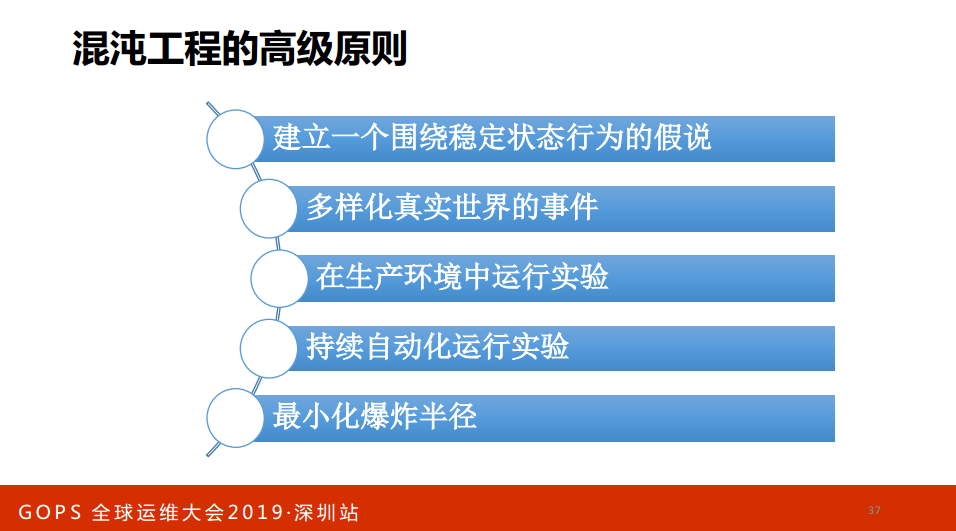
第一,建立一个围绕稳定状态行为的假说。你先说我的状态通过哪些指标证明现在的正常的;
第二,多样化真实世界的事件。你要不统计出来在身世世界中有那些事件有可能发生,比如说有人把Kafka的队列干掉了,类似于这种真实世界发生的事件统计出来做成一个固像画像。
第三,在生产环境中运营实验,最好在生产环境,而不是测试。
第四,持续自动化运行实验,你的自动化应该靠工具,比如说模拟CQ负载100%。
第五,最小化爆炸半径。你要把可控放到最小,混沌实验直接把一排机器全部关机试一试,那不叫混沌工程,那就是作,要把实验影响的范围缩小,范围缩小就会更聚焦某一个领域的问题,在不同领域去做这样的实验。
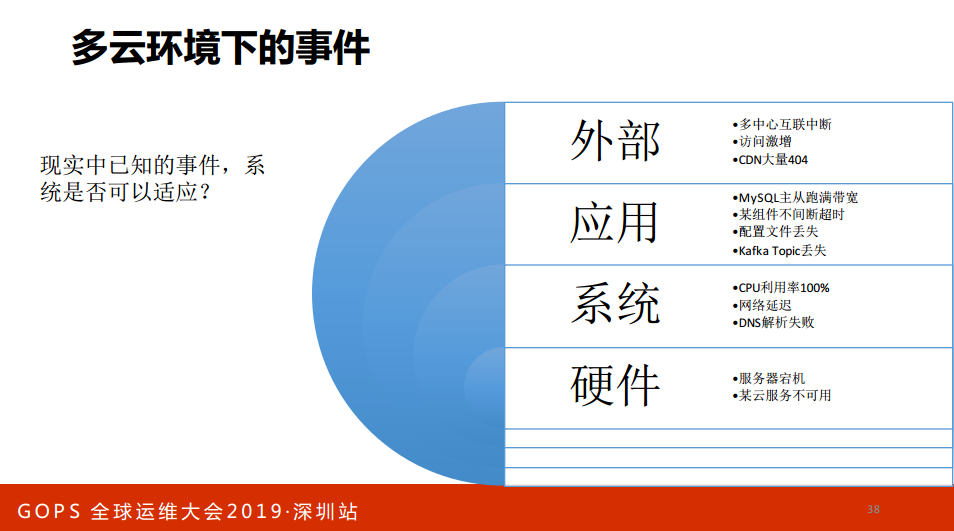
当然,做混沌工程要闻第一个问题,现实中已知的事件系统能否适应。什么意思呢?用户挂了能不能反应过来,不能说否得挂了解决不了,还得找一个实验。如果这个问题回答不了,先做对高可用的设计,混沌工程现有的架构已经是高可用,但是自动化运维做得很好,是不是没事干?闲的,这时候研究怎么去提高系统的抗击打能力。
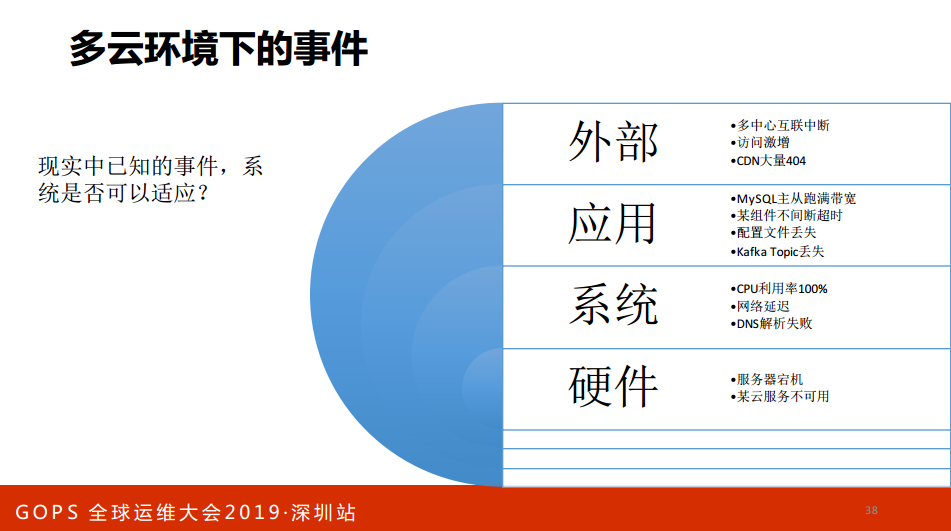
这时候你可能要做一个故障画像,我就做一个非常简单的几个例举,分层做一个故障画像,每一个层面会出现什么问题?比如说DNS,因为大家知道DNS一直备两个,主的宕的配备的,配置是5S吗?但是您要知道超时时间是5S,很多应用就直接爆掉了。
现在有哪些开源工具,除了“猴子”以外还有阿里开源的,还有基于K8S做的。我目前主要的学习途径,我在看阿里的,阿里云线上也有一个类似这样的一个产品出来。
我不知道腾讯有没有,反正我最早看到阿里上面有,所以这个可以介绍一下,如果大家有兴趣可以去看一看。我们就不设提问时间了,等一下可以加微信。下面有请杨文兵,杨文兵是腾讯的高级工程师,他分享的主体,腾讯怎么做自动化运维平台的设计,我多次听过杨文兵的讲课,非常精彩,希望大家有所收获。