@gaoxiaoyunwei2017
2021-06-01T09:04:23.000000Z
字数 3847
阅读 1534
保卫波特姆行动:稳定性工程能力实践之路
未分类
说明:本文根据王帅老师在 GOPS 全球运维大会 2021 · 深圳站的分享整理而成。
作者简介
王帅,资深稳定性工程专家。从事证券行业系统运维10+年,熟悉证券行业业务规则及系统运行特点,拥有丰富的交易业务系统运维、测试经验,目前专注系统稳定性运行研究、平台建设及产品设计领域,负责稳定性工程平台的产品研究和运营。
大家上午好!刚才大家看了“稳定性工程”视频不知道有什么感想和期待?下面我们一起看下今天的分享主题“保卫波特姆行动:稳定性工程能力实践之路”。我叫王帅,来自华泰证券,在华泰证券从事系统运维工作10+年,近几年专注稳定性工程能力建设与实践,后续可以进行技术交流和沟通。
今天分享的主题分为四部分,分别是业务稳定性分析、稳定性平台能力建设、稳定性工程能力实践,最后是我们对未来稳定性平台建设和实践的展望。
一、业务稳定性分析
首先我们来分析一下业务稳定性,各行各业对业务稳定性有不同的理解,在证券行业如何理解业务稳定性?这里从两个视角,首先站在客户视角,客户希望行情更新快、交易快、业务办理顺畅、不卡顿。
第二站在业务视角,业务人员希望业务功能和流程符合预期,大行情下,系统能够按照预期运行不崩溃,系统运行满足SLA,稳定运行无监控告警。我们期望的业务保障场景主要有四类,分别是新功能上线、业务关键时刻、行情火爆及外部环境变化。
为保障新功能首日顺利投产,我们会通过监控关注首单的时间及系统就绪状态,实时关注订单的趋势,首单及系统交易状态没有问题后,接下来我们就要重点保障业务的关键时刻了。如9:15、9:25、9:30、13:00、14:57、15:00,这几个时间点是我们的业务高峰期,需要重点保障。在这几个时间点后我们要关注系统能否经得住火爆行情的挑战?我们通过实时监控渠道、集中交易后台业务水位来观测性能容量是否超限。这些都没有问题后,是否代表系统可以稳定运行了?做运维的都知道,经常是人在家中坐,锅从天上来,例如外部线路、基础环境、外部业务节点等发生变化后,都会对生产系统运行构成风险。
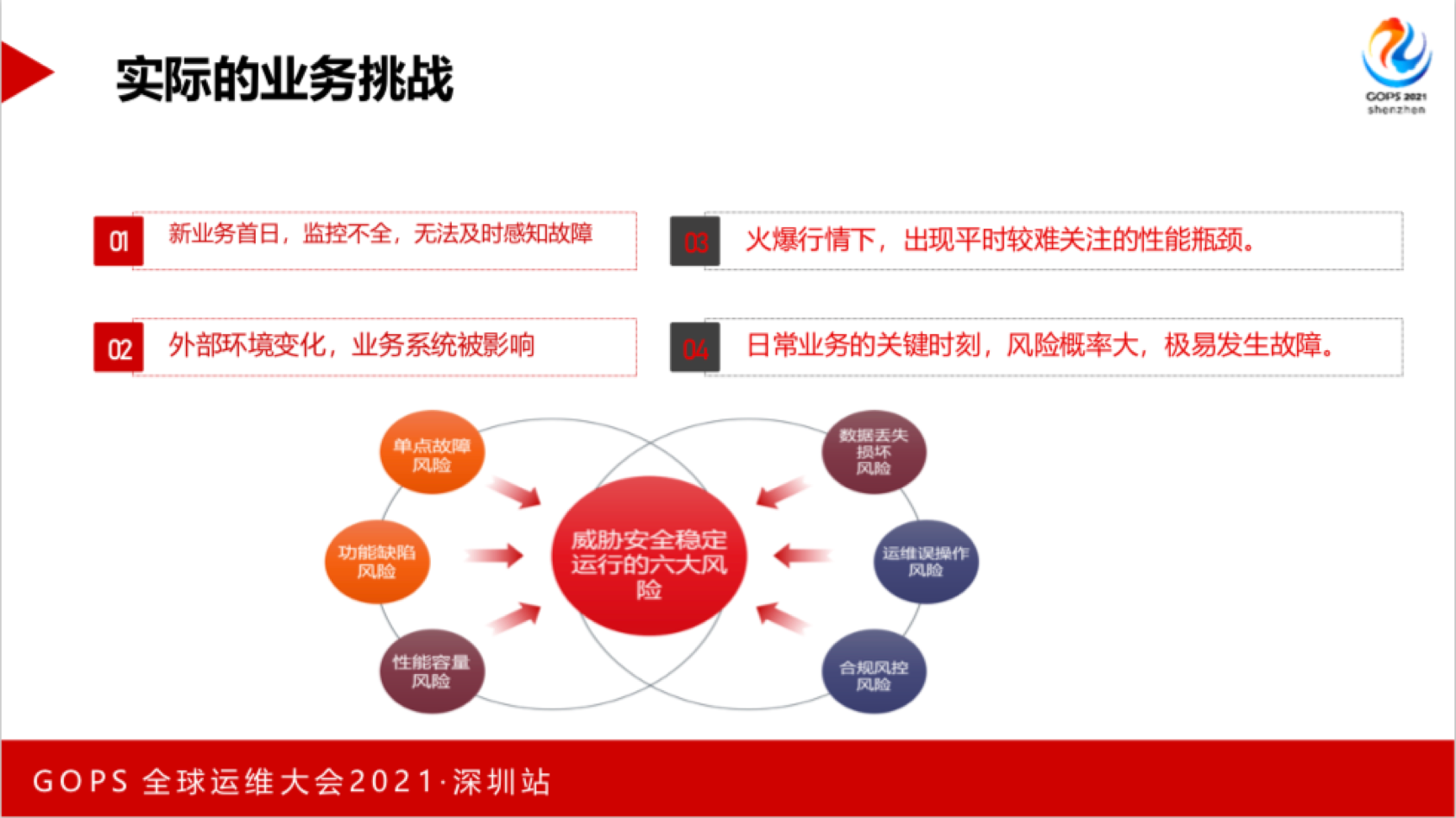
实际上面临的业务挑战是什么呢?新业务首日因为监控不全面,无法及时感知故障。日常业务的关键时刻,风险概率大,极易发生故障。对运维人员的应急处置能力是极大的挑战。火爆行情下,通过性能压测、扩容等做了很多工作,还是遇到了平时较难关注的性能瓶颈。外部环境变化,影响了业务系统。这时候可能锅就来了,外部环境的变化可能会对系统造成一定的影响。我们根据生产运维经验,总结出威胁安全稳定运行的六大风险,分别是单点故障风险、功能缺陷风险、性能容量风险、数据丢失损坏风险、运维误操作风险以及合规风控风险。
为应对生产运维中的六大风险,我们通常的做法是系统测试全覆盖,确保测试的全面性,全面识别变更风险。通过日常应急演练,提前发现系统风险,提升应急处置能力。

我们在以上日常保障的基础上做了拓展,引入了混沌工程。关于“混沌工程”的概念就不展开说了。引入混沌工程以后,我们通过以战养战,开展常态化故障演练,找出系统潜在技术风险和解决方案。
二、稳定性平台能力建设
面向六大类风险,我们建立了场景化、全流程、开放式的稳定性工程平台,提升了故障发现能力、故障定位能力及故障处置能力。平台基于阿里商业 AHAS Chaos 实现故障注入,面向证券行业特点,建设了华泰“稳定性工程平台”,打通了监控、变更、测试、应急等生产运维场景。
阿里 AHAS Chaos 具有标准化、开放式的能力,经过多年集团内部实践沉淀,同时应用于公共云和混合云。支持丰富的故障场景,并且在电商、物流、云计算、新零售、新金融等行业都有广泛的应用。
华泰稳定性工程平台,最底层汇聚了华泰内部的 Agent 监控、一体化监控、统一监控、应用CMDB、自动化服务等基础能力。中间层是演练管理、故障演练、演练自动化及演练评价,演练完会形成演练知识库,对用户进行演练推荐,并且对第三方系统开放API接口,自动生成演练报告,对系统进行稳定性评价。最上层是用户视图和演练空间,通过开放第三方API接口,进行内部约十六个系统的数据流转。
在故障类型及故障构建能力规划方面能力如下:首先是基础设施故障,支持CPU、内存等基础故障注入。再上一层是单点不可用等容器服务故障,第三层是应用服务故障,包括进程、JVM、服务调用等。第四层是云资源故障,主要为宕机与重启。第五层是数据损坏,如误删、丢失等故障。最上层是业务卡吊死,应急预案采用了公式型、可量化度量覆盖率的应急预案模式。早期采用抽样式演练,中期采用地毯式演练,后期采用双随机演练模式。
我们将稳定性工程融入运维一体化体系,首先打通了应用CMDB,将系统模块及节点信息汇聚到稳定性工程平台。同时对接统一监控平台,来观察演练系统和演练节点是否发生了监控告警,是否符合预期。接下来运维人员通过统一操作台的限流、降级或熔断来进行应急处置。引入了统一测试服务台,在演练的同时注入业务背景压力,进行生产的业务压测。整个演练结束后,将演练结果同步至运行质量管理平台,对演练全流程进行评价。检验是否做到了四个第一,即第一时间发现问题,第一时间定位问题,第一时间处置问题,第一时间报告问题,演练结束后将演练报告推送给应急管理平台。
为降低演练门槛以及系统运维人员的学习成本,我们会提前预置演练场景库,实现系统、模块及节点的关联。支持根据模块、机房、所有机房及随机等个性化方式选择演练对象,通过打通 CMDB,一键批量生成演练任务,覆盖所有系统模块与节点。
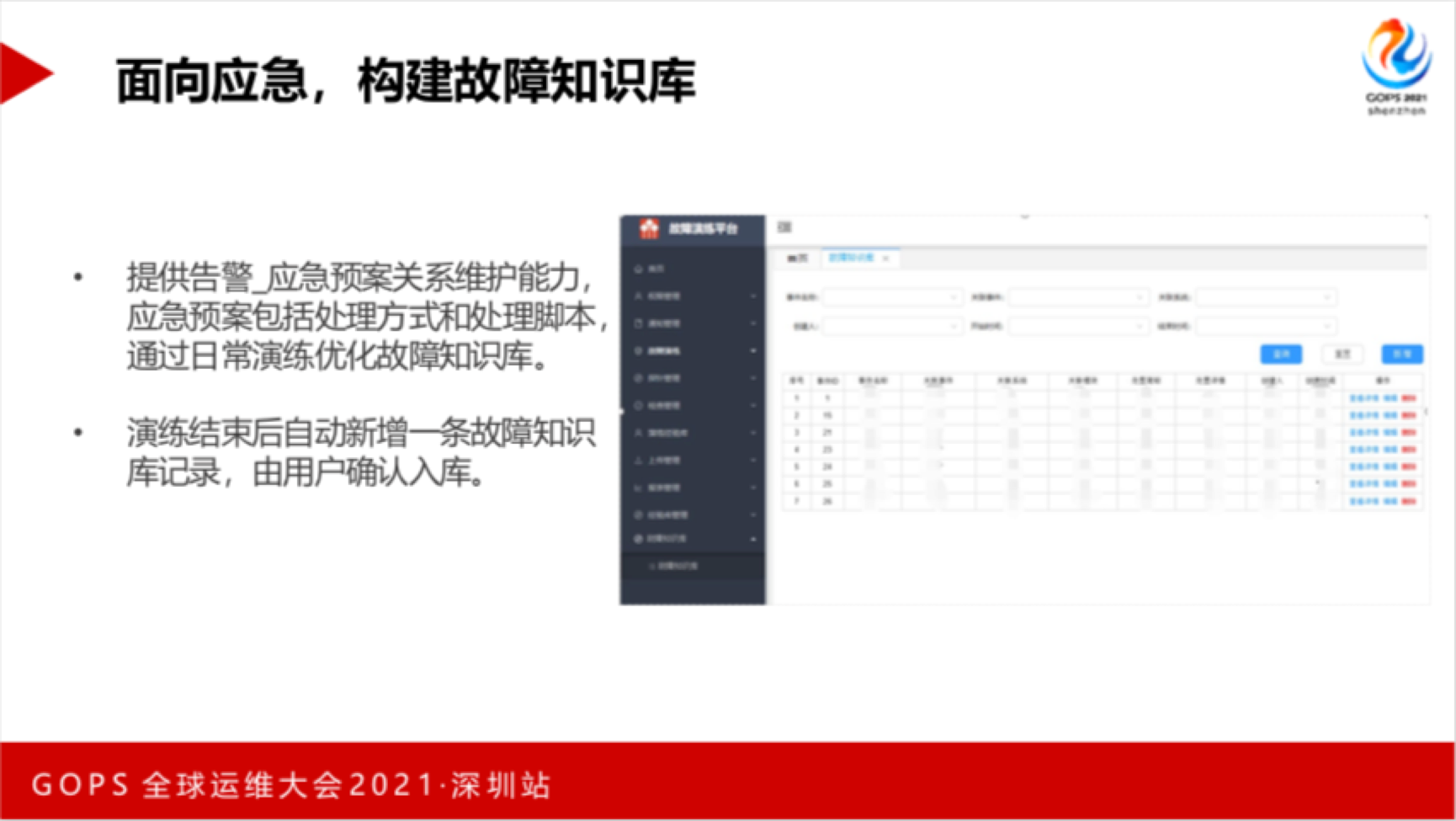
面向应急处置,构建了故障知识库,维护监控告警、应急预案及应急处置三者的关系,演练结束会自动生成一条故障知识库记录,关联应急处置预案与应急处置人员。

演练的最终目的是面向改进,管理学大师德鲁克曾经说过,如果你无法度量它,就无法管理它,进而无法改进。从故障注入、监控告警发现到应急处置的整个过程,我们完成了系统稳定性能力评价、监控告警的覆盖度以及应急预案的覆盖度与有效性评价。
为提高演练的易用性,我们完成了爆炸半径的可视化。首先建立了客户端的一体化监控,如行情、交易、账号及清算的一体化监控,同时建立了后端服务接口的一体化监控,最终实现了从客户端到服务端的全链路监控的一体化,可实时观测到接口级故障影响范围。
三、稳定性工程能力实践

基于稳定性平台能力,我们开展了保卫波特姆行动,有童鞋想问波特姆是什么?所谓波特姆就是Bottom,底线的意思,通过该行动,我们不断探测系统运行底线,发现技术风险,从而牢牢守住系统稳定运行底线。我们通过建立稳定性工程模型,分析了典型业务故障场景,进行了地毯式演练覆盖。首次通过建立故障演练模型,构建了故障场景矩阵,建立了一二线运维联动机制,实现了历史生产故障回放机制。
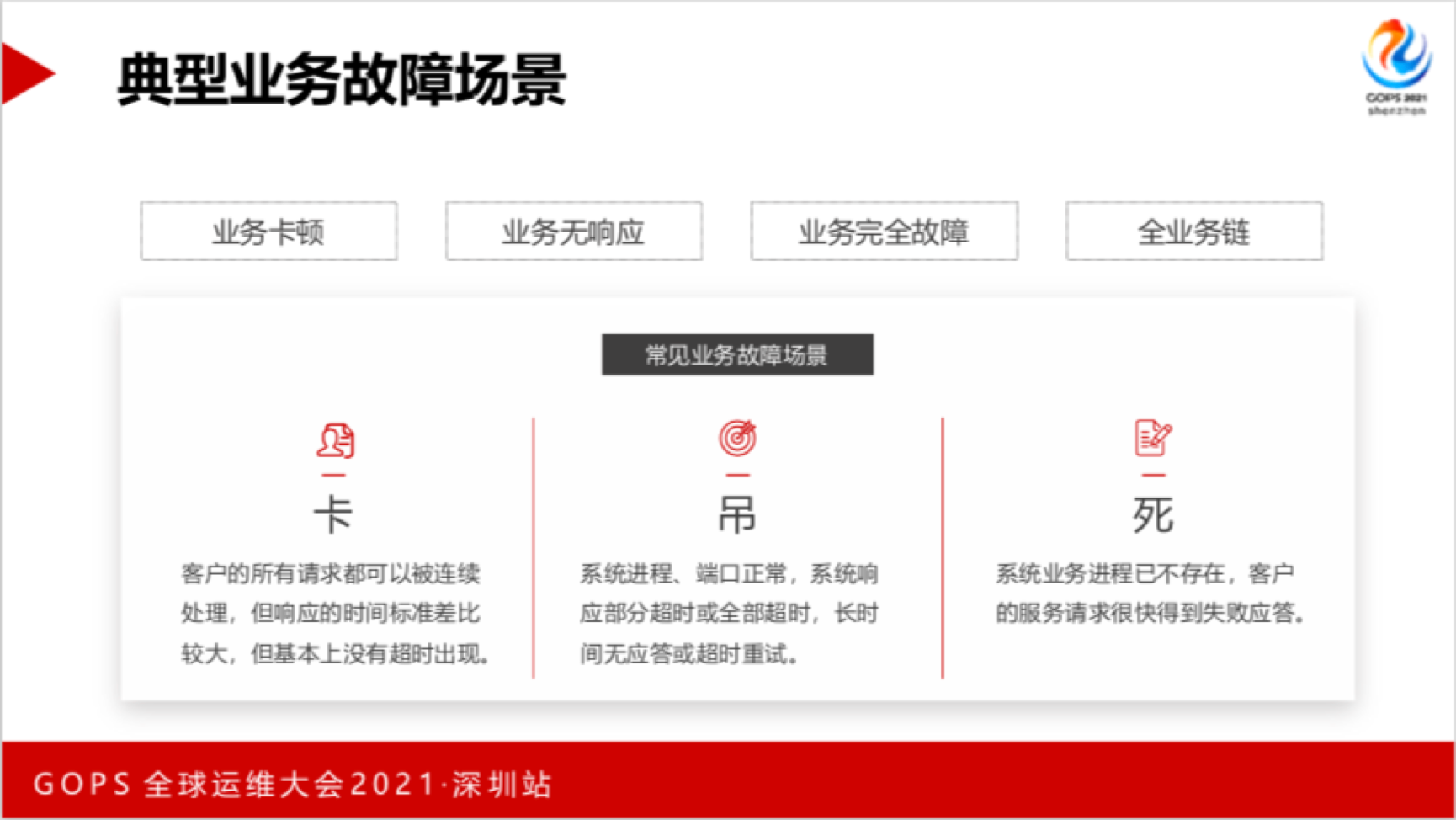
根据生产运维经验,我们总结了三类典型业务故障场景,简称为“卡、吊、死”。
“卡”指业务卡顿,客户所有的请求都可以被连续处理,但响应时间标准差比较大,基本上没有超时发生。“吊”指系统进程、端口正常,系统响应部分超时或全部超时,长时间无应答或超时重试。“死”指系统业务进程已不存在,客户的服务请求很快得到失败的应答。

根据保卫波特姆行动的初心,我们开展了地毯式演练,系统梳理与覆盖了应用资源层、通讯链路层、数据库层、负载均衡及域名层资源。在此基础上分析历史生产事件,进行故障回放与演练,验证系统优化及应急处置的有效性。
为掌握实时演练情况,我们建设了稳定性工程活动看板,可实时观测到当前正在注入的故障场景,已经完成的故障场景,以及未来将要开展的应急演练模块与故障场景。看板同时展示了演练过程中发现的问题,包括业务线问题、平台问题以及演练需求。为防止演练中的故障注入未及时恢复,看板中间是故障未恢复的场景列表,右侧是未来的演练趋势。
在保卫波特姆行动中,我们建立了稳定性工程文化。通过演练启动会,明确了演练计划与范围。演练结束后系统自动生成每日演练报告,通过对演练数据运营与分析,持续优化故障演练方案。通过部门安全生产专项行动,将稳定性工程平台能力推广至所有AB级核心业务系统,为系统稳定性保障赋能。同时我们每季度对生产事件做分析,评估哪些系统哪些模块容易发生故障,通过故障类型来丰富我们的实际故障演练场景,不断完善故障构建能力,最后通过评选季度“保卫波特姆大使”,鼓励在演练过程中表现突出的同志,建立正向红榜文化。
在半年多的保卫波特姆行动中取得了一定的成果,整个行动覆盖交易、行情、账户、理财等4大核心业务线及其他业务线,涵盖了27种典型故障场景,完成了750次平台化演练,合计3331个故障场景,发现了23类技术风险。对技术风险进行分析后,落实了272个改进项。如果没有该行动,这些技术风险可能会引发生产事件。通过稳定性工程平台能力建设与保卫波特姆行动,提前发现了系统潜在的技术风险,为系统稳定运行保驾护航。
四、展望
基于当前稳定性工程平台能力和实践,未来我们将在以下领域做深度探索和研究。第一是双随机演练,所谓双随机演练就是随机场景、随机时间进行故障演练。第二是红蓝对抗,从防守与攻击角度进行红蓝演练。第三是系统稳定性能力的可视化,在故障注入到恢复的全程,我们都可以看到系统的稳定性情况与表现。第四是架构风险自动感知,通过对系统架构分析,能够自动感知到系统的潜在技术风险,给出演练路径与故障场景的建议。最后是结合AIOPS,通过学习故障场景与知识库,形成演练场景智能化推荐能力。 以上就是我今天分享的主题,谢谢!
