@gaoxiaoyunwei2017
2017-09-27T04:10:42.000000Z
字数 8047
阅读 1885
手机QQ 移动网络接入优化之路 --- 郭智文
北哥
个人介绍
郭智文 腾讯 – SNG – 社交网络运营部 – 高级运维工程师
主要负责:手机QQ, QQ音视频,视频云直播 业务运维
腾讯公司工作经历:
- 手机QQ 运维负责人 (2009 –至今)
- QQ音视频运维 (2015 – 至今)
- 视频云直播运维 (2016 – 至今)

分享的主题如下:
- 业务概况
- 移动网络用户接入故障按理
- 业务后台架构及部署优化
- 全局智能调度
- 移动端网络性能优化
- 总结
一. 业务概况
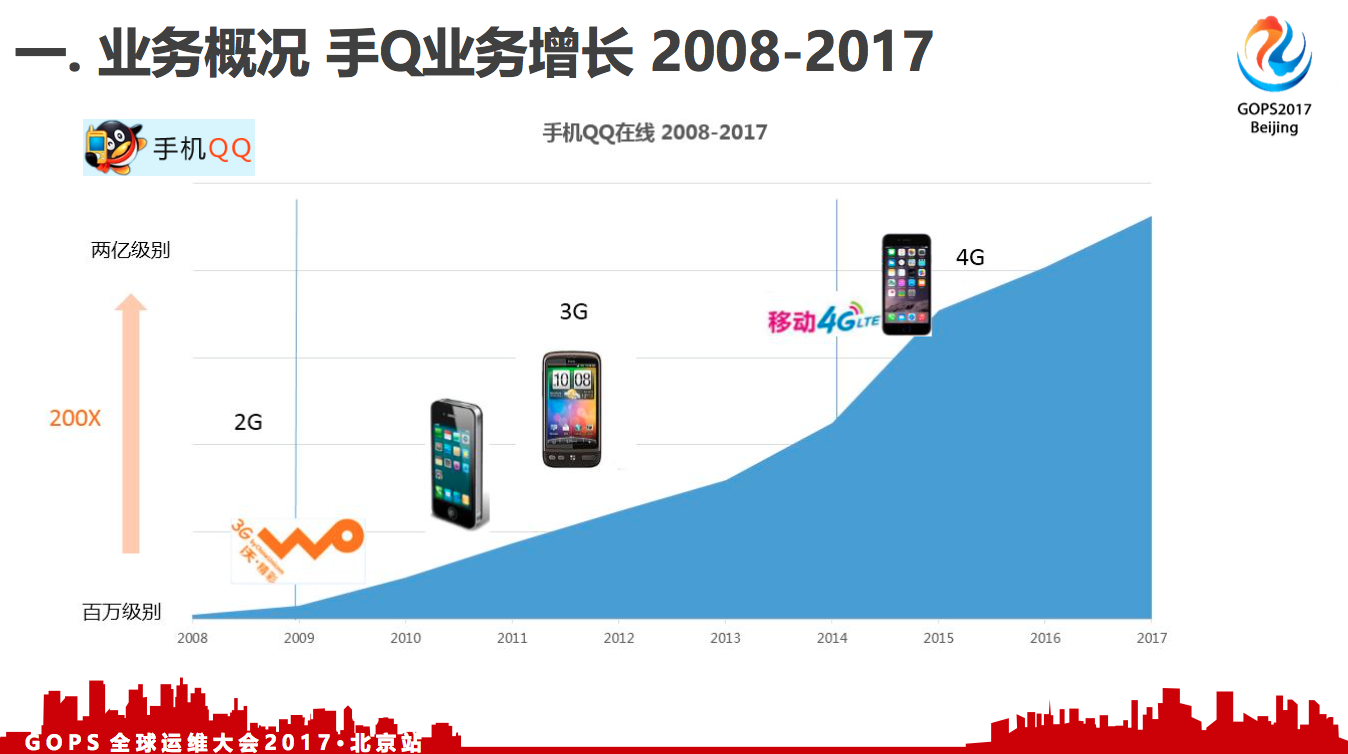
1.1 手Q业务增长 2008-2017
这是我们的业务发展历程。其实,手机QQ在2003年就已经开始做了,但是在那个时代主要还是PC互联网时代。
对手机终端来说,很多都是只有黑白屏如诺基亚,承载不了太好的用户体验。
同时,那时候的网络还是2G网络,网络速度非常慢。如果用这种版本的手机QQ,可能也只能做一些收发消息,文本这样的东西。
经过五年的发展,到2008年手机QQ大概达到了500万的在线级别。
我是2009年入职的。2009年是一个转折点,这一年中国网络进入3G互联网时代,在终端上面,像iPhone、Android也是方兴未艾。我们有非常好的网络,有非常好的硬件,然后在应用层就开始爆发了。
2008年是500万,到2009、2010年就已经突破千万级别了,到2013年就突破亿级级别了,短短这几年,就增长了200倍,这是一个非常快速的增长。
二.移动网络用户接入故障案例
2.1 重庆联通用户移动网络(2G/3G)故障
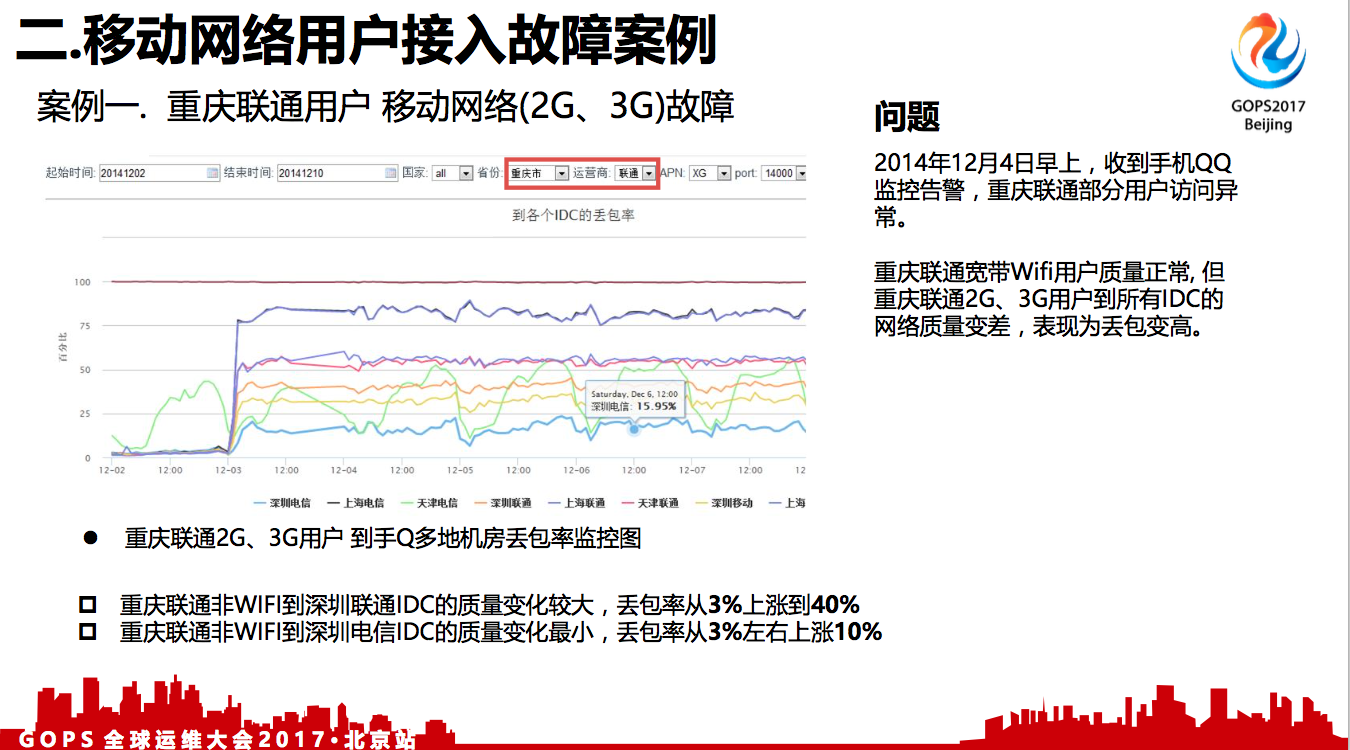
问题:
2014年12月4日早上,收到手机QQ监控告警,重庆联通部分用户访问异常。
重庆联通宽带Wifi用户质量正常,但重庆联通2G、3G用户到所有IDC的网络质量变差,表现为丢包变高。
上面是重庆联通移动网络到各个IDC机房的丢包率监控图,下面的不同曲线代表腾讯不同的机房。
在正常情况下面,丢包率基本上是1%,2%是我们认为可以接受的。但是,在12月4号凌晨,我们从客户端上万日志监控里面看,就发现重庆那个地方从3%涨到4%左右,其它的有些涨到10%。
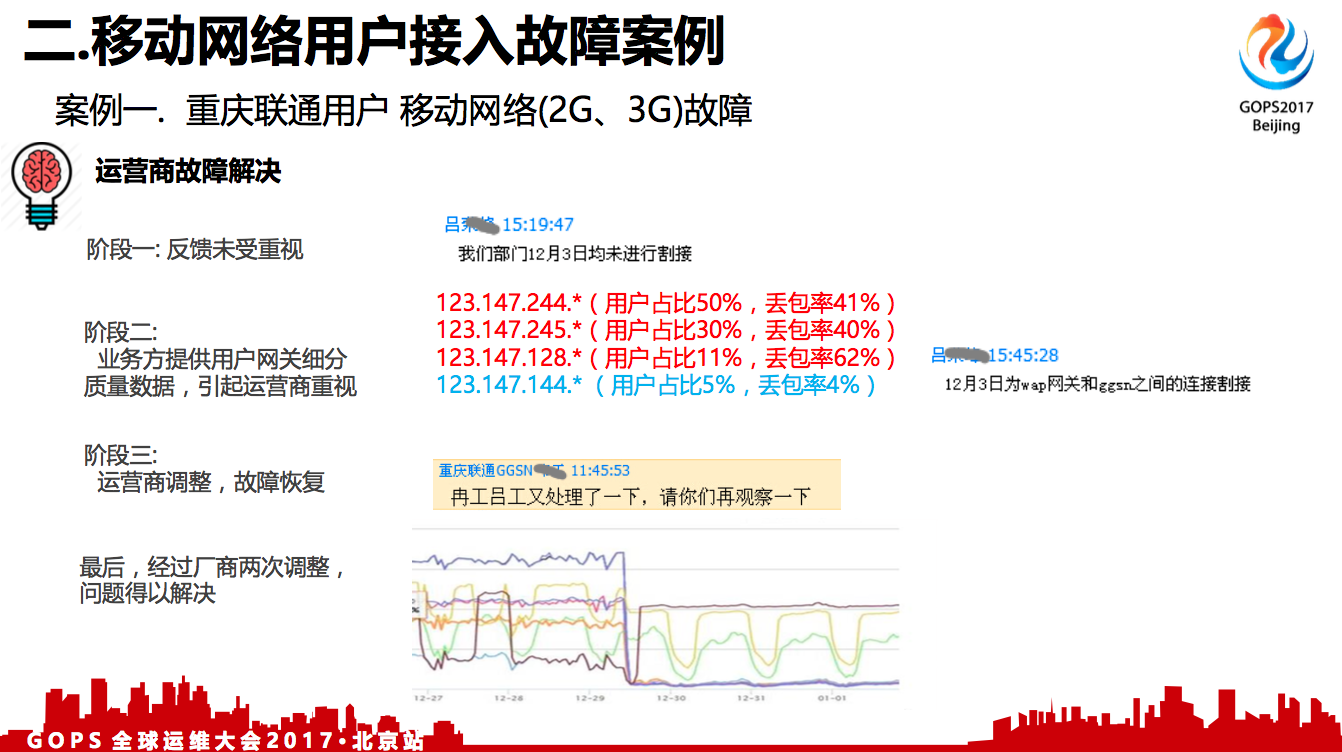
从右下图来看,我们的后台业务,在那个时段是没有调整的,用户故障也主要聚集在具有地域的收敛性。
我们通过网络中心联系到联通那边的同事,他们说跟他们没有关系,我们再挖掘,找出来了网关的某些IP有故障,然后我们再次提交给他们,他们内部沟通一轮之后,就确认确实是他们在那段时段在割接网络,他们也找厂商联调,经过两次调整最后故障才得以解决。
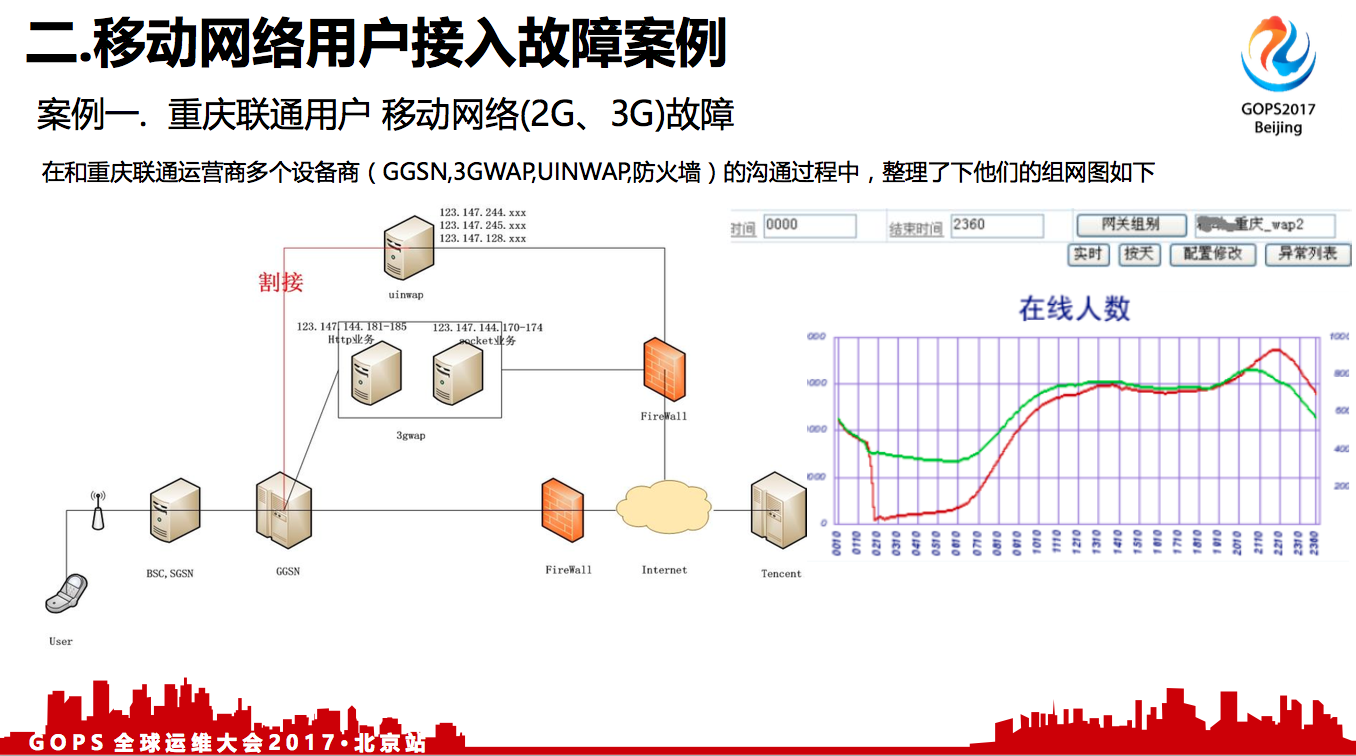
通过这个故障我们知道,用户手机从手机侧到附近基站,到移动的GGSN,再经过互联网,再到腾讯服务器,其实是一个比较漫长的路径。左图最上面两个,一个是UINWAP网关和3GWAP网关。
右边这张图,是我们内部对用户在线情况的监控,做的比较细的,不但有一个总在线的监控,也会到运营商的网关出口。针对这一组网关上面,如果有故障我们都可以发现,在几秒钟之内就能发现问题,然后及时联系对方去解决。
2.2 香港数码通与新世界电讯联网问题
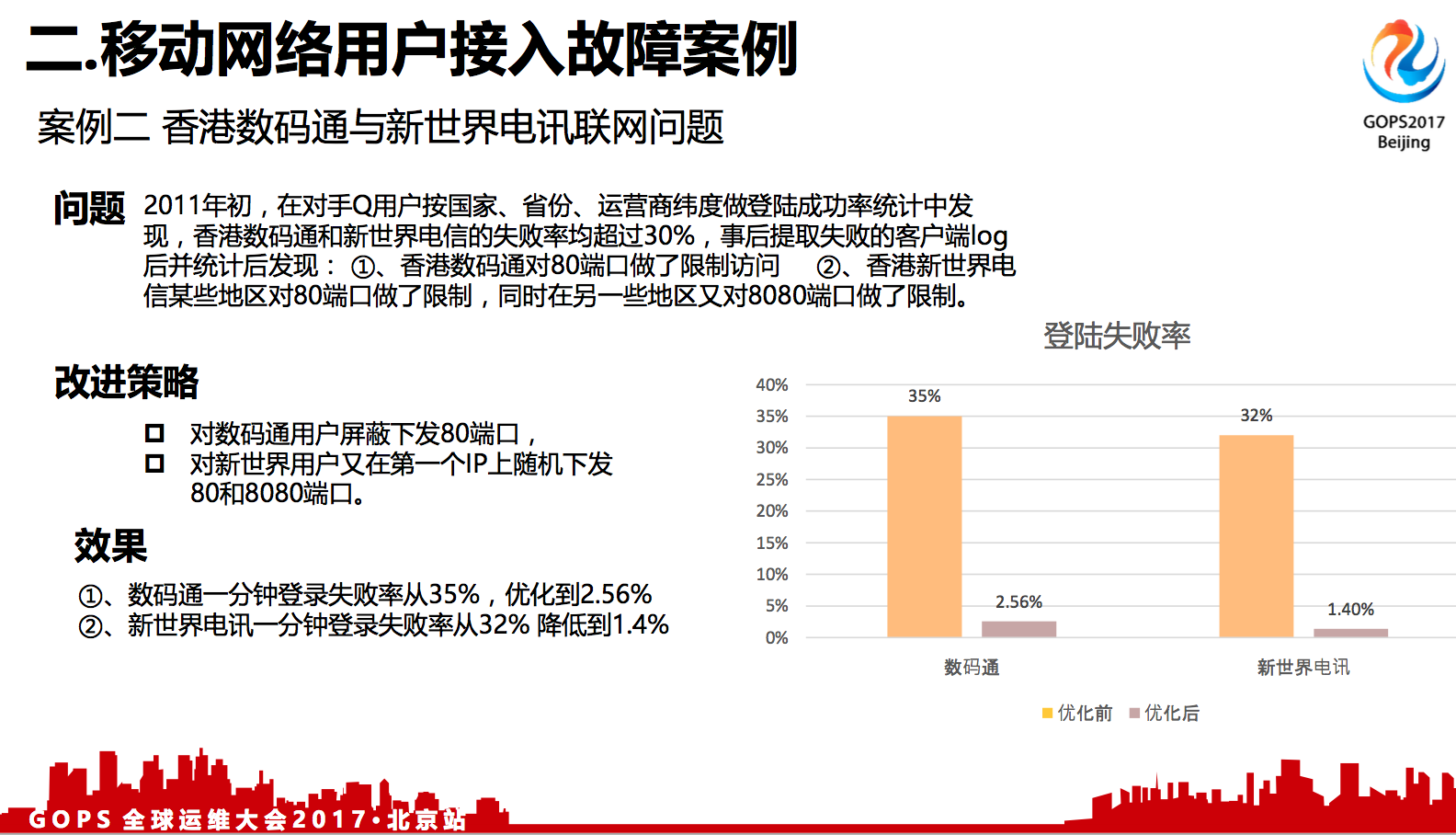
问题:
2011年初,在对手Q用户按国家、省份、运营商纬度做登陆成功率统计中发现,香港数码通和新世界电信的失败率均超过30%,事后提取失败的客户端log后并统计后发现:
1. 香港数码通对80端口做了限制访问。
2. 香港新世界电信某些地区对80端口做了限制,同时在另一些地区又对8080端口做了限制。
这个案例是海外用户所遇到的。QQ日活跃用户有6亿,这么多的用户数,除了在国内,在全球也有很多用户。这些全球的移动用户是接入到全球其他的移动网络运营商,这种广泛的运营商,他们对网络的管控也是有很多潜规则的,是我们无法预料到的。
上述案例是香港运营商一个数码通,一个新世界通讯。数码通是针对80端口不允许访问,新世界是针对80和8080端口不允许访问,另外一些基站又可以。
这个是通过收集客户日志来分析他落到哪个端口或者哪个地区,然后针对性的配置端口。后面可能讲到有一些全局调度的系统,能够自动的发现这些问题,自动的去规避。
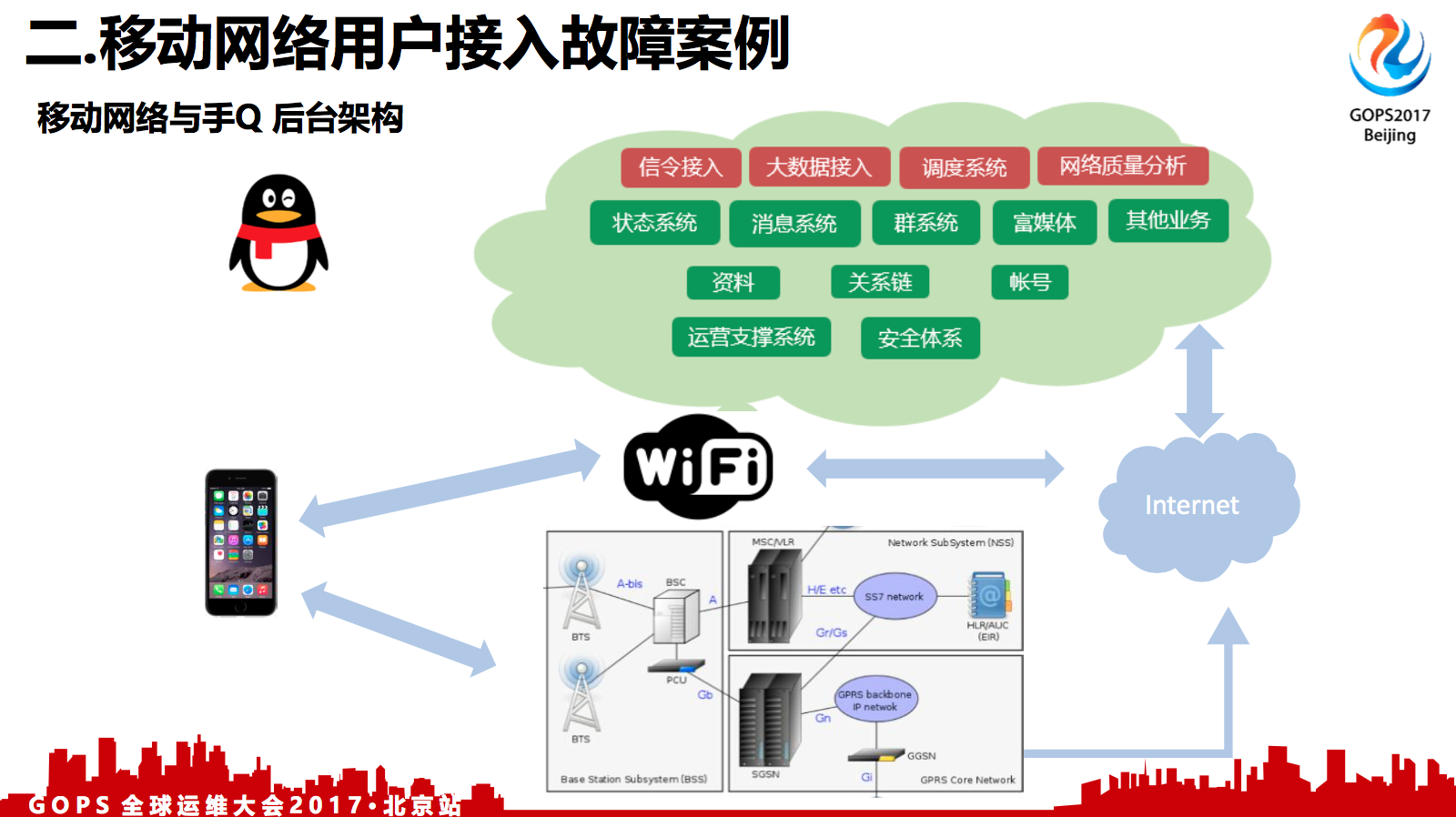
这个就是我们的一个从用户侧到无线网络,到互联网,再到后台服务器的架构。
其实最主要的就是由于WiFi与移动网络,不是物理连接的,是无线连接的,这会带来一些高丢包率,高延时的问题。
最上面是我们的后台服务层。然后,随着用户规模的增长,从百万级到千万级,然后到亿级,可用性要求更高了,逐步从一个中心演变成双中心,进而达到三中心。
三. 业务后台架构及部署优化
3.1 2G时代(2004 - 2010)
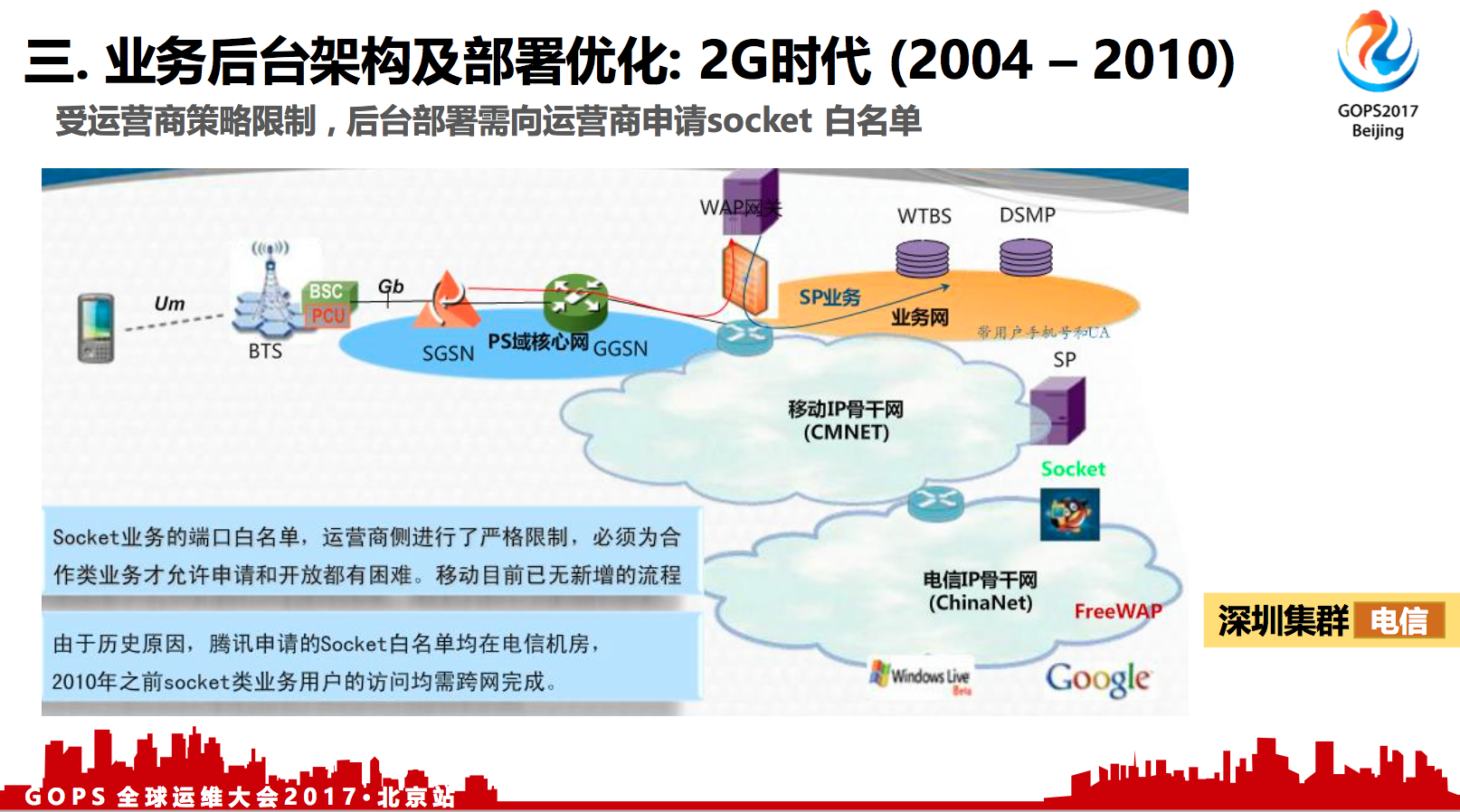
受运营商策略限制 , 后台部署需向运营商申请socket 白名单
在2G网络上,移动网络有CMNET和CMWAP两种网关。CMWAP就是给这些功能机通过Wap协议,再走wap代理,然后再抓取到服务器侧的Wap页面。
CMNET网关主要是给像PDA智能终端或者电脑这种业务场景的,允许使用socket协议。协议比较自由,访问路径上限制少,没有阻碍。
CMWAP网关就只能够通过Wap协议来访问。
对移动运营商来说,它是使用非白即黑的控制策略。如果 app的访问请求从CMWAP网关出来,但访问协议及服务器目标IP与端口,不在防火墙白名单策略里,请求就会被阻止掉的,用户的请求根本出不来。
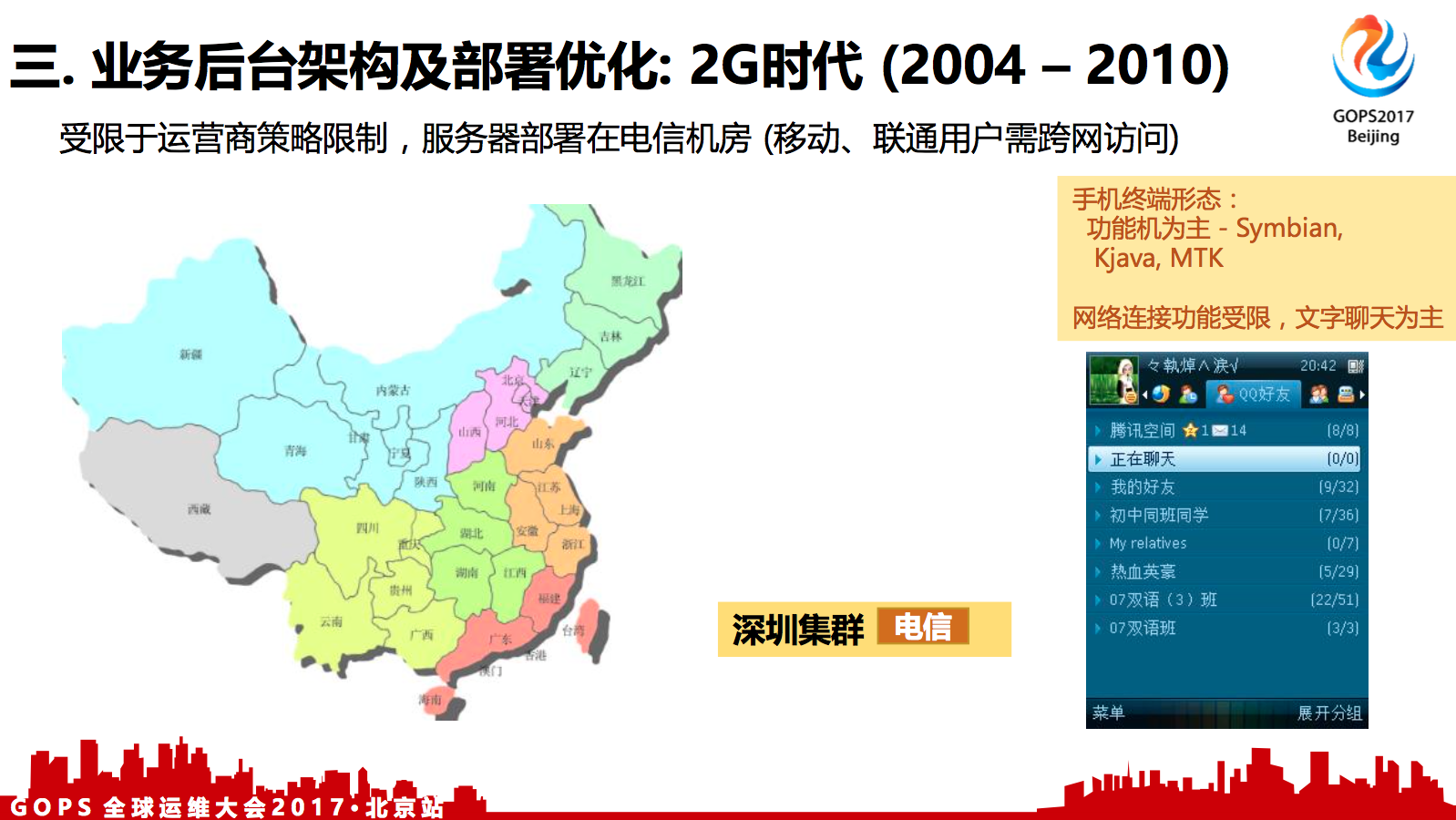
受限于运营商策略限制,服务器部署在电信机房 (移动、联通用户需跨网访问)
在2G时代,那时候规模还比较小,主要在深圳地区,移动也没有移动机房,一开始就都部署在电信的机房里面。同时,把电信机房的IP和端口到移动那里都申请了白名单,这些白名单要配到各地的运营商那里,这个工作量是非常大,申请也是非常麻烦,我们花那么多年,也只申请了几十个。因为白名单已经固定是绑定到电信机房的服务器上,所以移动用户,联通用户,都是要跨网访问到电信服务器。晚高峰时候移动用户跨网登录到电信服务器,登录耗时常常需5~7秒,这是非常慢的,对用户使用体验不太友好。
3.2 3G时代(2011 – 2013)

运营商socket限制逐步取消,业务增加移动、联通机房部署,实现同运营商非跨网接入。
2009年,电信、联通的3G网络发展起来了,WAP网关和NET网关也逐步融合了。同时,也是因为在2009年,2010年的时候,业务规模已经发展到千万级别了,千万级别的在线对移动来说也产生了很大的压力。因为2G的承载能力是比较差的,访问电信的时候丢包率比较高,也比较慢,"这些数据都要经过移动的基站和WAP网关",而且比如丢包之后就会重置,重置就会加重移动的网关的负担。
另外,从运营商的运营成本来看,也是有很大挑战的。按工信部的规定,跨网的策略,就是如果中国移动的用户访问电信的资源,或者说电信的用户访问中国移动的资源,这里产生的跨网费用都是要由中国移动去支付的。因为中国移动的用户也很多,千万级的在线,再乘以每个用户消耗的带宽,可能每个月就产生千万级的跨网费用,一年就几亿了。所以他们也有很大的推动力,一方面是让我们协助解决跨网的问题,消除它的费用。另一方面,也是通过解决丢包降低他们网关的负载。2013年中国移动还没有申请到4G牌照,那时候主要还是由2G网络来承载流量,无线网络信令的消耗压力非常大,移动集团也联合腾讯业务一起做大量移动网络优化的工作。

移动、联通机房起用效果: 丢包率,时延明显改善。
基于这三方面大家利益的共赢,移动提供了移动的机房以及白名单资源给我们,我们部署到深圳移动机房,最终优化解决了跨网访问的问题。联通跨网访问也是通过类似的方式解决了。
我们跟运营商的合作带来什么好处呢?解决了丢包的问题。从之前的跨运营商的丢包率20%到40%,一下子降到同网只会有1%的丢包率。另外,时延从100毫秒变成几十毫秒。同时,每年会给中国移动节省数亿元的跨网结算费用。
3.3 4G时代(2014 – 2017)
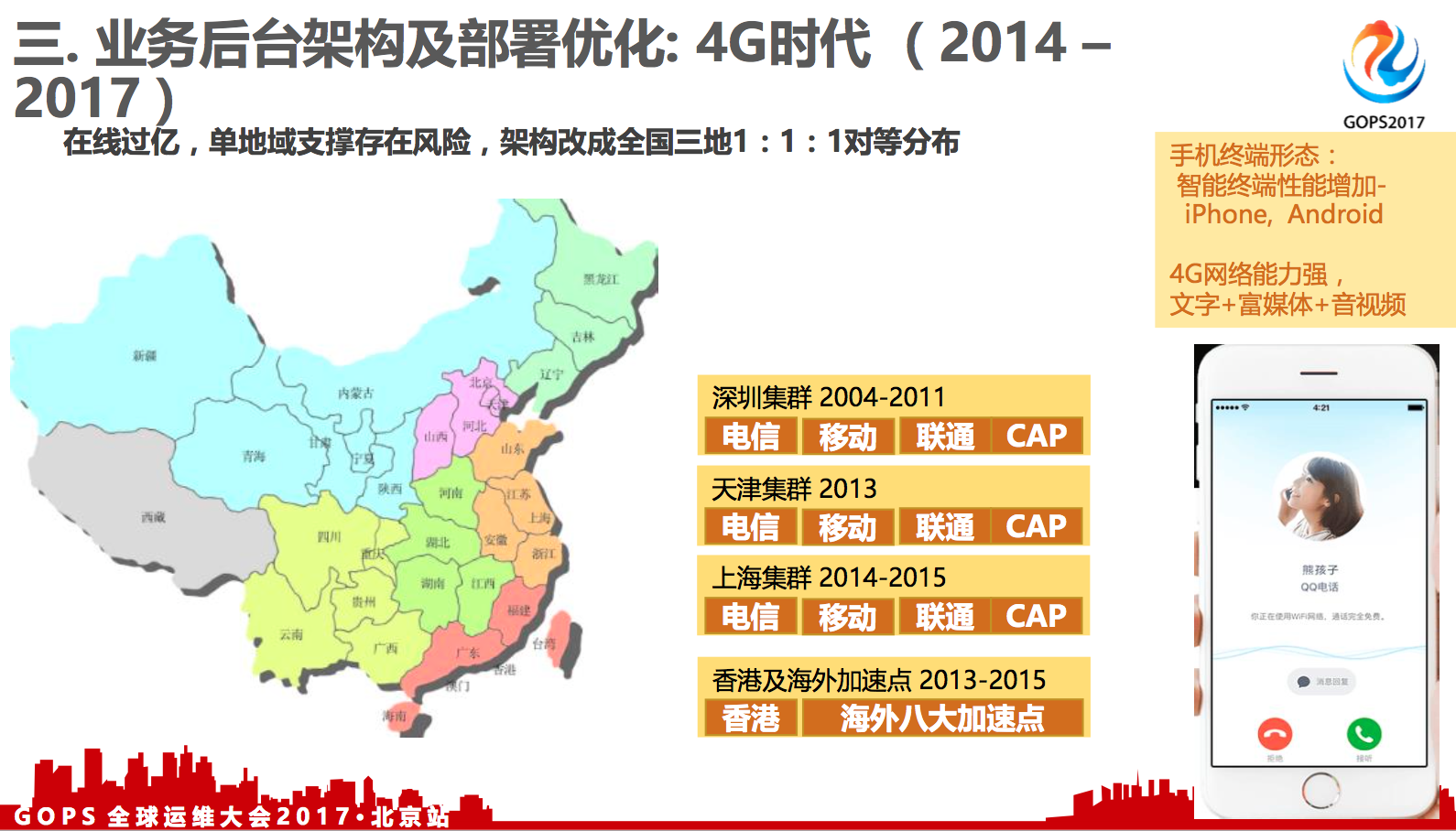
在线过亿,单地域支撑存在风险,架构改成全国三地1:1:1对等分布。
2013年已经超过一亿级在线了,从百万到千万,到亿级,这个对后台可用性的要求是不太一样的。
当我们到一亿用户的时候,那时候我们要考虑,深圳这个地方已经不那么保险了。
其实在2013年的时候,因为业务发展的非常快,整个深圳地区的机房、机位资源都已经很紧张了,假如我们一直待在深圳,会面临着没有机器可用的情况。
其他方案是:我们把一半的用户量迁移到天津,这样既能够减轻公司IDC基建的压力,同时也能够给我们业务带来多地容灾的好处。所以,我们在2011年在天津自建了一个机房,最大容量可以达到20万台。在2013年手机QQ实现了深圳+天津的双中心 分布。深圳与天津日均各承载了5000万~6000万在线用户。
到2015年,手机QQ同时在线用户数达到两亿了。中国的大多数互联网用户,聚集分布于华北,华东,华南三大地区,用户的分布比例接近1:1:1,最理想情况下,是让用户分别接入到北京,上海,深圳的IDC集群, 这样 用户到服务器的物理距离是最近的,访问时延最小。
另外,从双中心变成三中心会有其他收益及必要性。在双中心的情况下面,业务遇到极端场景进行容灾,例如天津机房全宕机了,我需要把海量用户都集中调度到深圳一地。深圳平时的容量就要能够承载全量的用户,它平时的利用率最高只能用到50%, 平时的冗余率是要翻倍的。
平时最高的利用率不能够超过50%,这方面平时会存在资源上面的闲置。真正发生调度压力也会很大,因为你把一个地区的百分之百请求压到另外一个地区,它的请求是翻倍增长的,这种急剧的增长可能会产生一些不可预测的事情,还有就是流量变的太大了,可能有风险。但是如果变成三中心,把一地迁到另外两地,另外两地每个增长50%,相对来说,平时的冗余不需要保留这么多了,对调度来说,风险也可以降低。
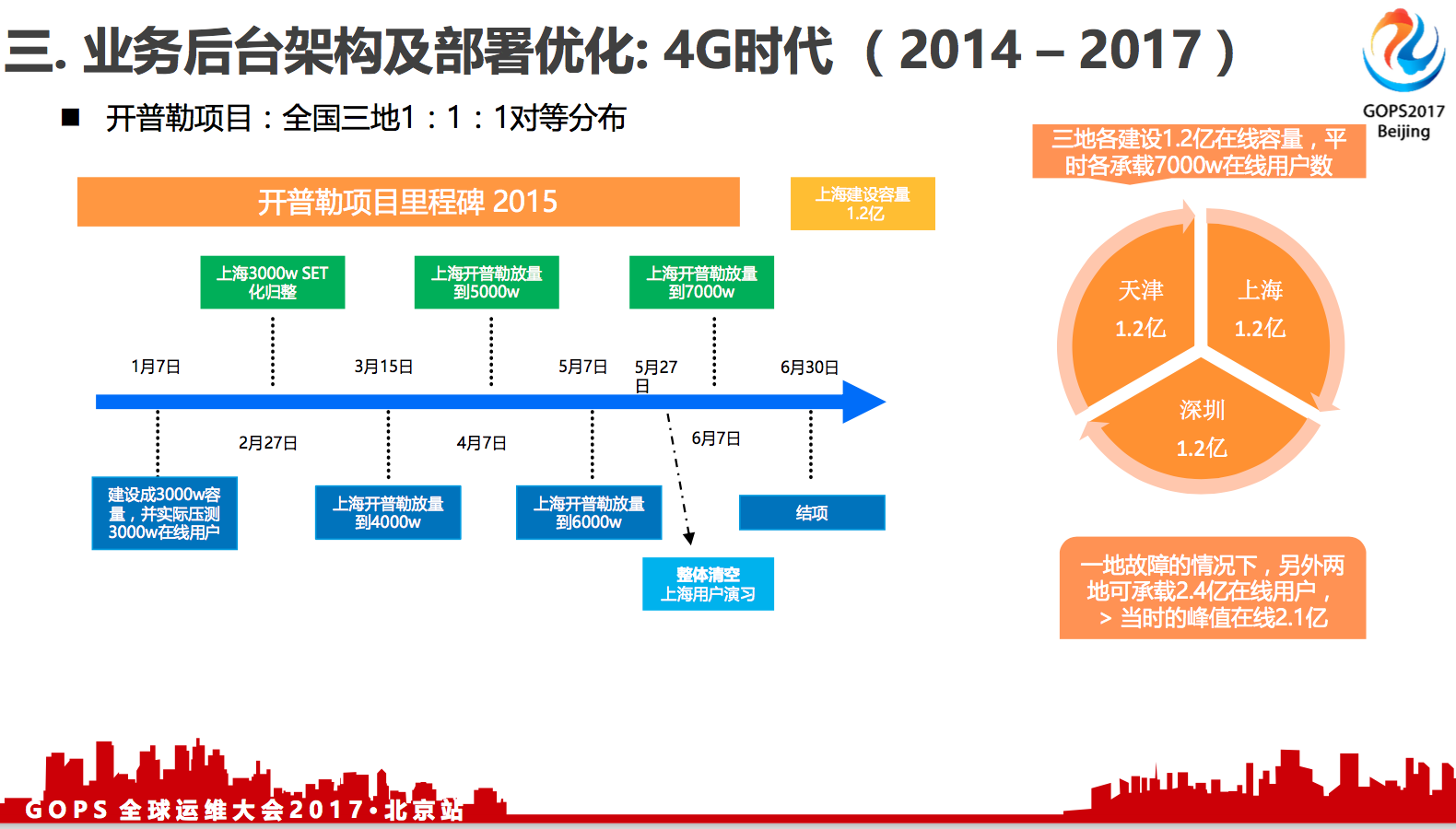
开普勒项目:全国三地1:1:1对等分布。
后台集群三中心分布的项目, 大概是2014年底就开始调研,2015年1月正式启动,2015年6月份完成结项,完成之后我们天津1.2亿,上海1.2亿,深圳1.2亿,当时我们还拿了一个总裁奖。

全国三地1:1:1对等分布,实战检验结果。
有一个定律,叫做墨菲法则。意思是说你越担心的风险,就越有可能会出现。
我们是2015年6月份完成的项目,2015年8月份,天津港就发生了爆炸事件,我们的天津机房离天津港最小物理距离只有几百米,当时我们机房的墙都已经被冲击波冲击倒了,也受到化学物品的污染,随时会发生停电的风险,但是还有七千万用户在那里。当时我们马上把天津七千万的在线用户迁移到上海和广州地区,大概花了一个小时,在用户几乎无感知的情况下面,平滑的把用户调度到另外两个中心。
四. 全局智能调度
4.1 全网网络状况统计分析
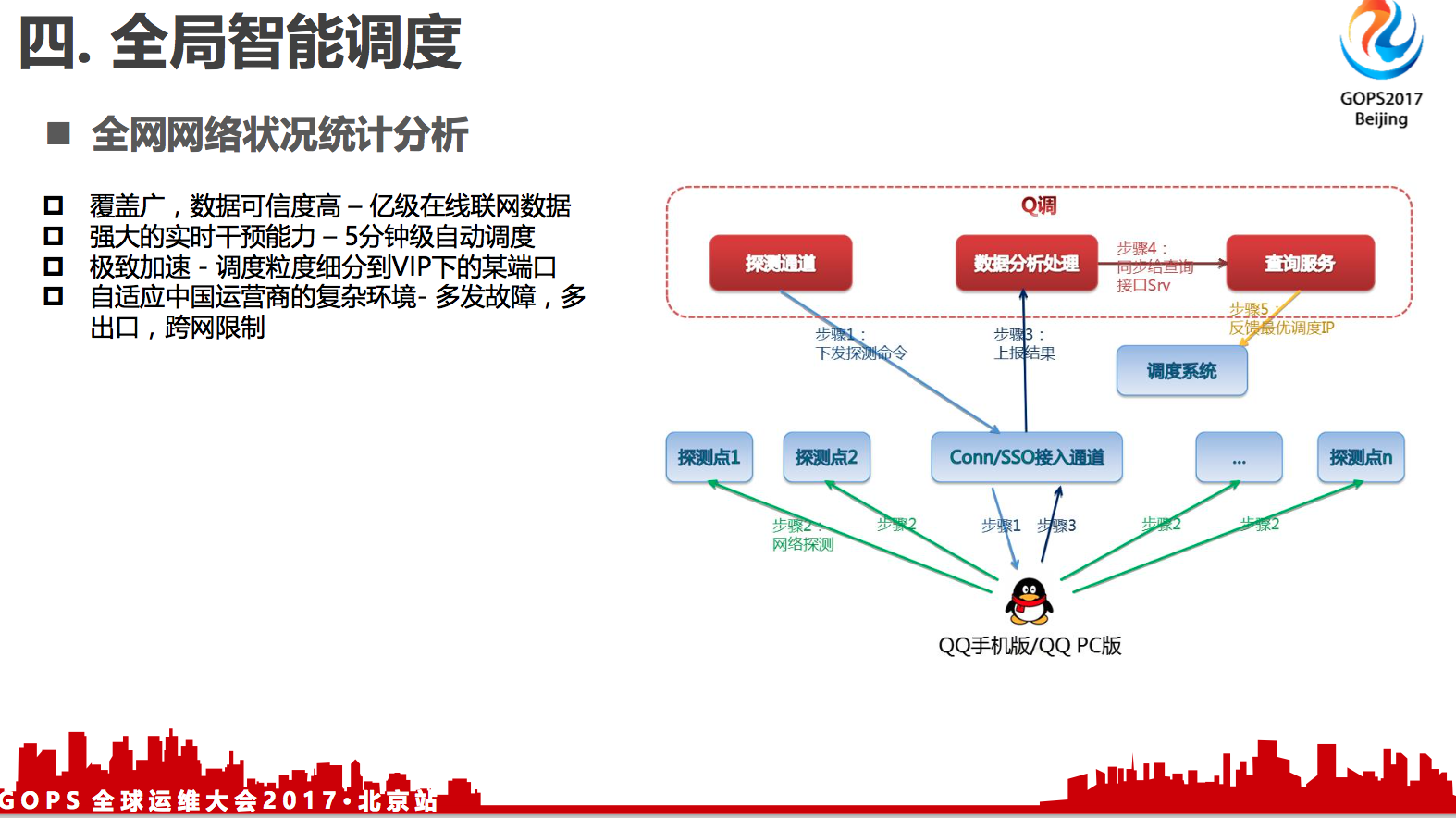
- 覆盖广,数据可信度高 –-- 亿级在线联网数据
- 强大的实时干预能力 --- 5分钟级自动调度
- 极致加速 --- 调度粒度细分到VIP下的某端口
- 自适应中国运营商的复杂环境 --- 多发故障,多出口,跨网限制
前面我们讲了,在后台架构上面,我们做了从一中心到两中心到三中心,这就足够了吗?未必。就像高速公路,也可能会发生交通事故,导致高速被堵了。这时如果你还是让用户按常规从高速入口进入,就可能一直堵在路上了。除了高速公路之外,还有很多国道、省道等等之类的,绕过拥堵路段。
我们有两亿多的在线用户,在这些高速公路上面的用户其实是非常多的,可能也会堵塞的。有没有办法帮助用户解决堵在路上的问题呢?有的,一个覆盖度非常广的用户接入的数据,用户联网之后,客户端定期或者储备到一定量的数据,会把它的关键事件的质量数据会回送到我们的后台,这些关键事件包括联网的数据,收发消息的成功率,还有收发图片的成功率。有了这些数据,我们能够及时的去感知用户侧的使用是否正常。
有了这些数据之后,我们可以做很多实时干预的能力。比如说,我们平时是将北京联通的用户调度到天津联通的机房,假如某一天运营商做了一些变动,或者干脆某个施工队把光纤挖断了,就能感知到这个出口的用户掉了,我们能够在5分钟之内由调度系统推荐到次优的最佳的那个接入点上面,这个是可以做到5分钟级别的。
还有调度粒度,我们可以细分到IP下面的某个端口。可能在一个目标IP地址上面,我们用A端口,或者B端口和C端口,不同的运营商可能限制不一样。我们通过收集是能够感知得到的,在这个运营商的网关上面,连接腾讯的哪些IP的端口是可达的,我们只发送可达的调度的IP端口给客户端。
同时,国内的三大运营商,还有中小运营商网络环境也非常复杂,出口的限制也比较多,基于这套系统,我们能够做到自适应。
4.2 智能调度系统后台架构
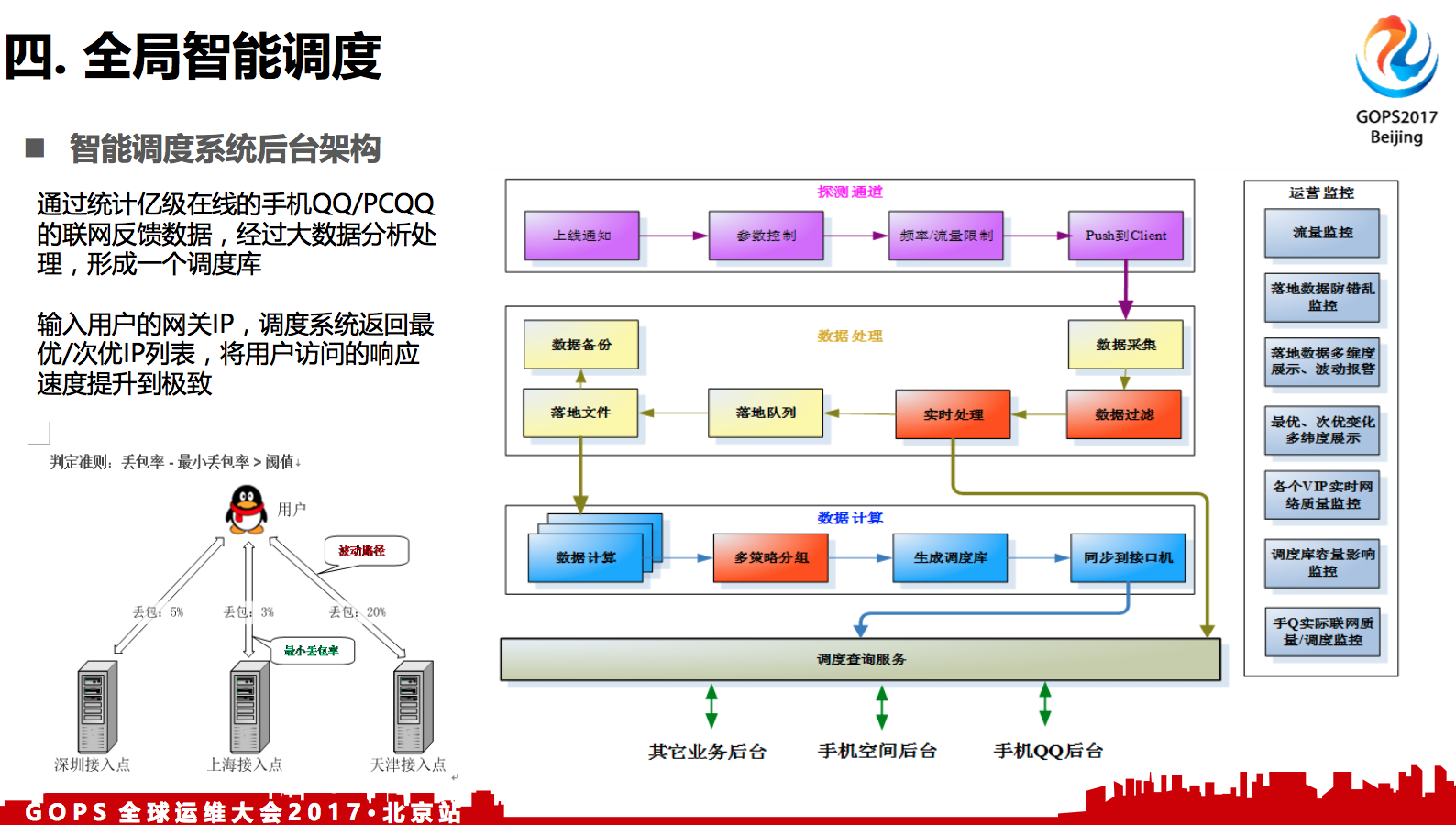
通过统计亿级在线的手机QQ/PCQQ的联网反馈数据,经过大数据分析处理,形成一个调度库。
输入用户的网关IP,调度系统返回最优/次优IP列表,将用户访问的响应速度提升到极致。
判定准则: 丢包率 - 最小丢包率 > 阀值
左下角的例子就是做调度触发的一个时机,比如这个用户连腾讯多组的集群,当某一组集群的丢包率超过预测的时候,比如丢包率20%,其他两组只有2%,20%减去2%就是18%,这个就超出阈值,我们就会调度到最左边的两个集群上去。
4.3 每天都在发生的实时丢包干预效果

这是每一天网络波动图。从这图来看,5个省份有丢包的问题,如果我们不去自动干预,比如海南,这部分有26%多的丢包率,但是在我们实时的干预调度到跨地域的集群,就能够降回到3%左右的丢包率,效果其实是非常好的。
4.4 平均登陆耗时对比
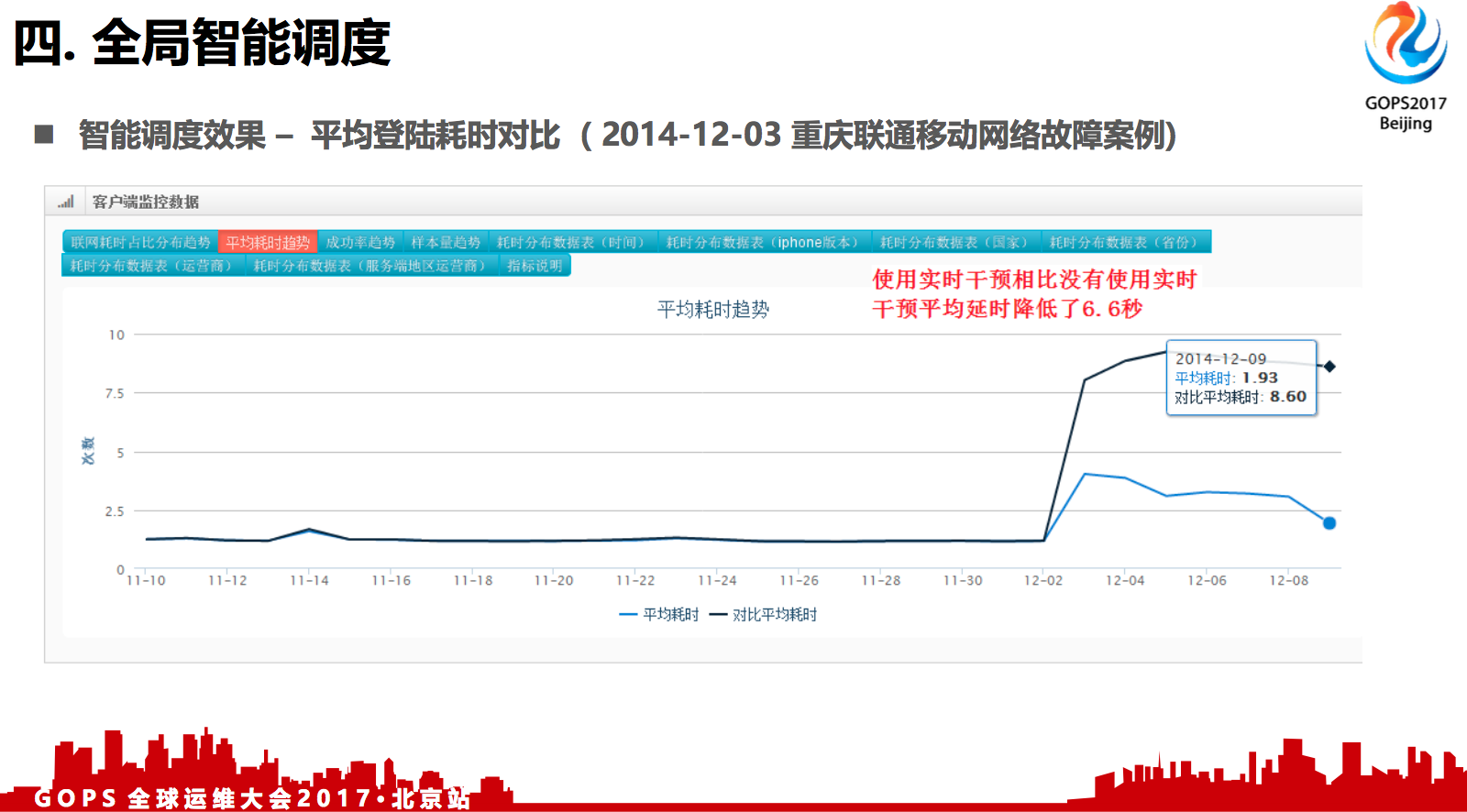
从耗时来看也是非常小的,当时我们的全局调度也是发挥作用的。
从我们的智能调度的抽样的案例来看,被智能调度干预的用户平均的登录耗时只有1.9秒,如果没有自动干预,用户需要8.6秒。
4.5 海外用户加速点
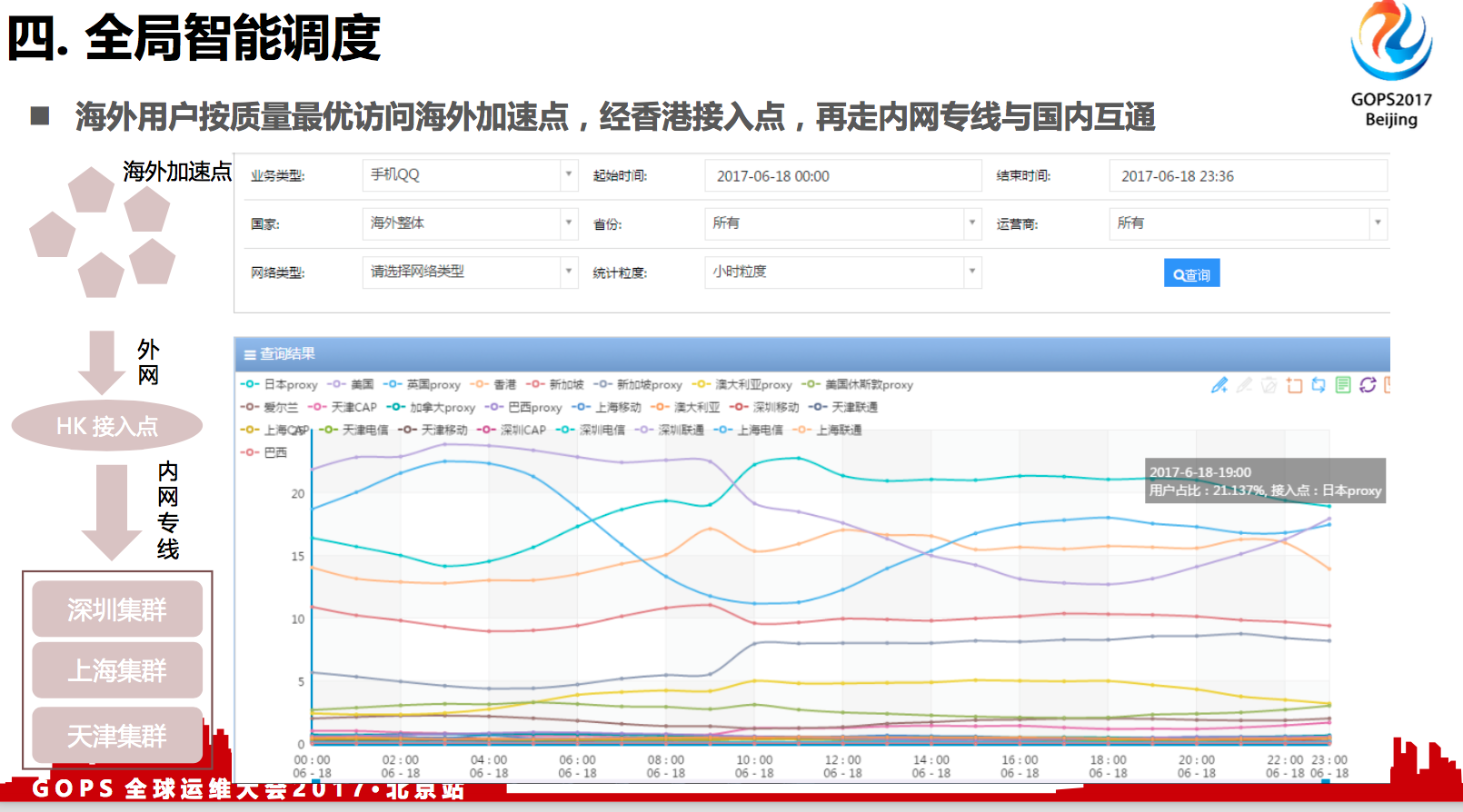
QQ海外用户数相对来说比例比较小,大概1%到2%左右。因为QQ的用户群主要是华人,主要在港澳台,还有东南亚,再加上北美这些地区。一开始我们只是用香港去覆盖的,可能对香港周边国家的覆盖是没什么问题,但是距离比较遥远的国家,还是会带来高时延,高丢包率的问题。
我们的解决方法是,比如说在用户就近的地区布一些网络加速点,在这些加速点连到香港服务器,然后香港服务器走腾讯跨境专线回到深圳的集群。通过这种方式来解决。
我们在北美有加拿大,美国加州集群,在欧洲有爱尔兰,英国集群,在东南亚有新加坡,日本集群,在南美有巴西集群,在大洋洲有澳大利亚集群。为什么建这些点?主要根据这些点的华人人群,使用QQ的相对比较多,然后就部署了。
在用户接入上面,也用了我们的智能调度系统。比如像右下图,我们其实也让用户去测了他连日本服务器,连新加坡服务器,哪个质量更好,如果日本的更好,会自动连到日本,如果新加坡会更好,会自动连到新加坡。这种网络的质量其实它不是固定的,都是实时在变化的,可能今天连日本会多一点,明天可能就是新加坡了,这也是智能调度的一个好处。
五. 移动端网络性能优化
5.1 通信信道预激活 --- signaling加速
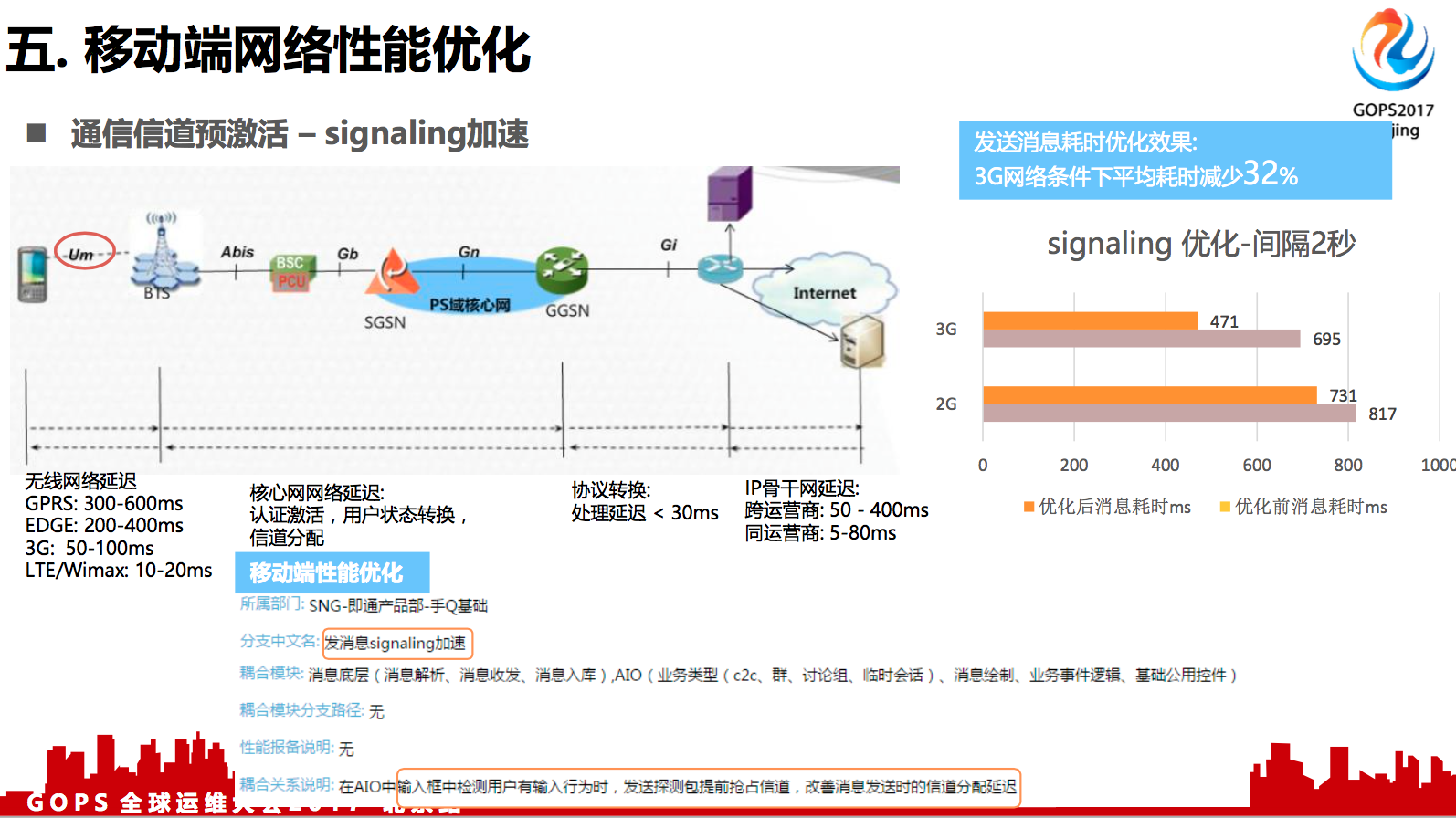
上图最左边,手机到基站那条线,我用圈圈起来了。为什么会圈起来?因为这条线来说,它是一个无线的,没有移动物理连接的,对它上面的那些信道来说,一个是信令信道,一个是数据信道,它们的资源是共享的。因此,你手机的数据请求在基站这里可能会产生排队现象。
这方面有没有办法优化呢?我认为对手机来说,发送消息,发送图片是一个最基础的体验,我们希望用户得到一个极致的体验,他一按下发送,消息就会瞬间达到我们的服务器上面。我们也调研了一些其他APP的做法,都是采用了下面的优化策略。
比如我检测到用户正在输入文字,或者正在输入框做操作的时候,我向后台发一些心跳包,这种数据的内容可能不太重要了。当有上行的时候,基站会提前分配处理了,就是进行一定的排队,可能就会分配到相应的信道。用户输入文字可能需要十几秒,在这个十几秒里,基本上信道都Ready了。
我们做这个优化,加了一些数据日志分析,对3G网络来说,这个优化是可以把用户感知这个体验从600多毫秒降到400多毫秒,平均耗时减少了32%左右。
5.2 IP直连
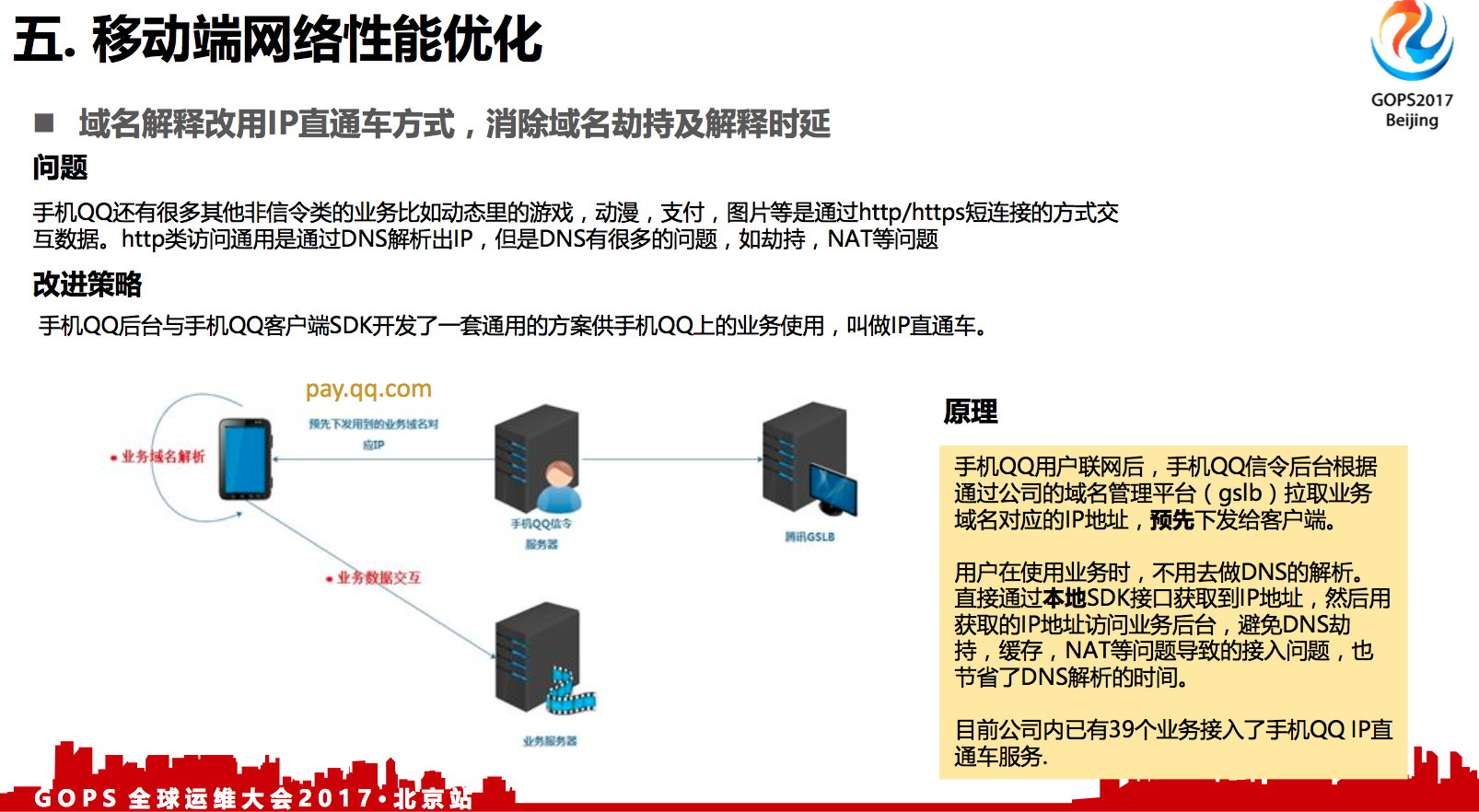
域名解释改用IP直通车方式,消除域名劫持及解释时延.
移动端上面,手机QQ主要是聊天的应用,使用的协议是私有协议。但是上面还有一些其他的流量入口,可能承载一些像游戏、动画、支付、图片这种业务,他们是使用了标准的http协议,通过域名访问。但是,域名不可避免的有两个问题:
- 第一域名总会有劫持
- 第二域名一般可能是绑定到某个地区,某个运营商的这个级别,就是你是不定时的。
对它的访问来说,是不是最优的,DNS解析是没有办法解决的。
我们是做了一种IP直通车的方案,手机终端可能一天24小时都跟手机QQ的服务器维持连接。我最直接的方式是通过一直连着的这个连接给用户做域名相关的解析就行了。同时还能根据用户的出口网关分析他连到哪个IP地址最快的就返回给他。这样既能够解决劫持问题,又能够解决访问速度最快的问题。目前已有30多个业务已经接入了手机QQ IP直通车服务了。
5.3 高时延下逻辑聚合
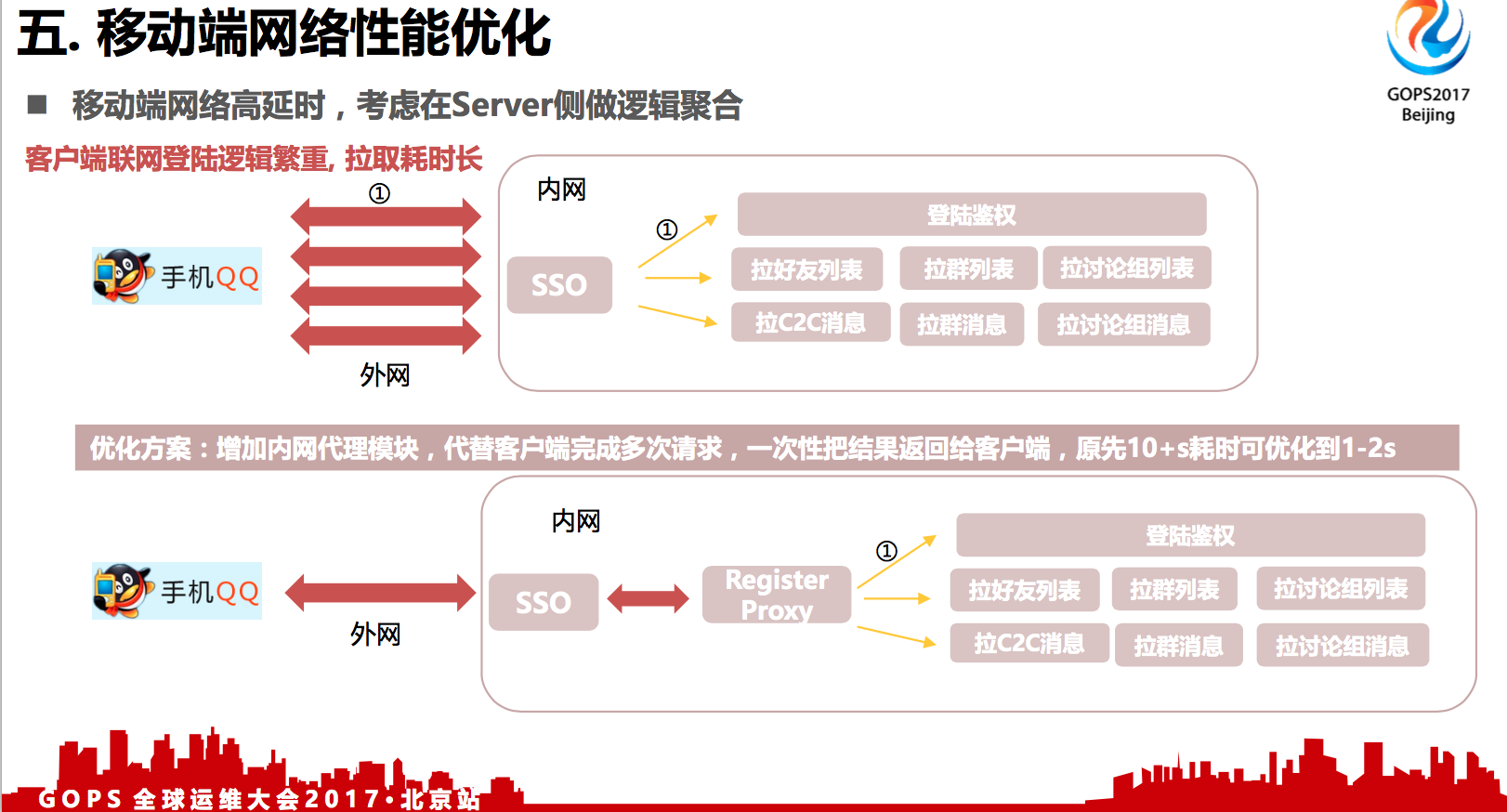
移动端网络高延时,考虑在Server侧做逻辑聚合。增加内网代理模块,代替客户端完成多次请求,一次性把结果返回给客户端,原先10+s耗时可优化到1-2s。
手机端还可以做的优化就是考虑把部分客户端的逻辑做到服务器逻辑里面去。
比如说像手机QQ是一个IM,就是即时通讯的工具,首次登录和联网过程的步骤比较多,首先要进行身份鉴权,要拉你的好友列表、群列表、讨论组列表,还有好友消息、群消息,请求消息。如果每个客户端都让客户通过官网拉,可能就需要八九秒了,用户等的太漫长了,可能也没有办法接受。
我们做了一个优化,把登录联网这个逻辑做到一个注册代理上,还有把客户端逻辑做到后台服务逻辑上。这其实还有一些其他间接的好处,比如说我们在春节零点抢红包的时候,很多用户会大量的联网,都是集中在那个时间点去连。如果是在客户端的情况下,可能我们没办法修改访问频次,做一些比例控制的。但是,如果是后台服务,我们是可以在注册代理做一些频率控制+队列来降低零点时刻爆发峰值对我们后台业务的冲击。
六. 总结

业务架构及部署优化
- 不同运营商间跨网访问对业务影响大,尽量消除这种情形
- 分运营商就近接入,消除跨网的高丢包率及高时延
- 多地域部署带来更快的物理访问速度,以及更高的容灾能力
全局智能调度
- 基于海量用户的接入质量数据,进行大数据分析,增强对运营商网络波动的实时干预调度能力
- 海外用户量较少 < 1%, 可通过增加加速点覆盖,曲线优化网络访问质量
移动端网络性能优化
- 发消息速度提升 --- 增加signaling机制,预激活信道分配,用户体验更快
- 域名解释改用IP直通车方式,消除域名劫持及解释时延,并实现最优质量调度
- 移动端网络高延时,为尽量减少交互次数,可考虑在Server侧做逻辑聚合
总结一下,在后台侧要解决跨运营商的问题,同时,根据你的业务的发展,架构上要从一中心演变成双中心以至于三中心。
- 第一,在调度侧,可以根据你已有的用户的连接信息,还有结合一定的拨测的信息,来决定你的用户调度到哪些服务器是最好的,访问质量上面,按最优的调度质量进行调度。对客户端侧,刚刚说的这三种的优化。
- 第二,收发消息的时候可以做一些信道的域名分配,避免域名劫持,加快访问质量。
- 第三,我觉得是有点创新的,就是把客户端的逻辑移到后台,通过后台来进行模拟。把客户端做的越来越轻,后台的变革来说是非常敏捷的,一些客户端逻辑改成在后台来实现,常常会带来惊喜的收获。
