@gaoxiaoyunwei2017
2018-04-20T07:51:42.000000Z
字数 6613
阅读 1507
智能运维和自动化测试工具&平台实践
白凡
分享:范超-京东运维总监
编辑:白凡
讲师介绍:现在负责的业务是京东前台业务的运维工作。京东从去年开始把研发团队做了前中后的划分,跟阿里一样。前台主要是负责面向用户的APP、PC、微信、手Q、小程序;中台是上游,提供的是我们赋予我们的一些基础;后台是财务系统、物流系统、仓储系统。
零售团队就是卖家平台,因为京东第三方卖家现在接近10万,每天活跃的商家也好几万。这些商家的管理平台,也是在我们这边负责。我是2014年加入京东,从2014年到现在,业务规模突飞猛进的4年。我刚刚接手京东业务,进来是负责APP,当时定单占比不到20%。我接手之后,服务器很清晰,整体就几百台,包括当时的前台、中台,还没有这么大的规模。这4年,随着业务的增长,后台系统增长得非常大。比如前台业务,现在有2000多个应用,它涉及到的点也扩展特别多,比如虚拟类的充值、各类票务都有,包括我们APP上一些黄金流程上的功能。在京东之前在腾讯负责过社交和电商业务。
今天的话题主要是围绕前台业务的监控建设和运维效率工具的建设。
大概有五六个主题,这五六个主题是围绕这个平台实践经验,就算是一些实践中的技巧或者有一些巧妙的方法,分享给大家。其中也不包括我们跟业务深度耦合的。大家可能来自各行各业,电商业务的一些实践经验,并不一定特别适用,就挑了一些跟业务耦合不是特别紧密的。大家通过听我的分享,能够了解到几点对于自己的工具或者建设有帮助的就可以了。
技术方向和背景
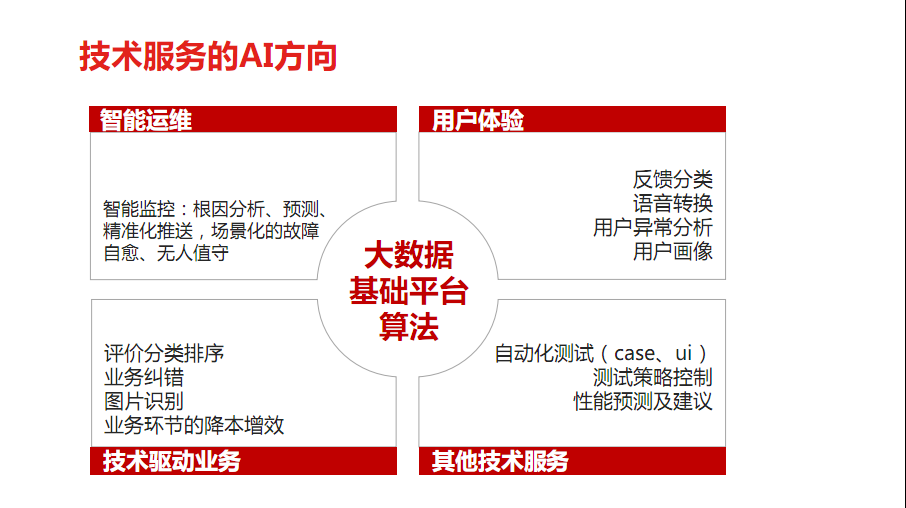
先说一下今年设定的,整个团队对于AI的方向。最近两年AI方面确实比较火,包括阿里、腾讯、百度,BAT公司内部团队也孵化了很多AI方向。京东今年也是设定了几个方向。这几个方向都是围绕大数据,在过去两三年里积累了很多数据,不管是监控数据还是客户端指标或者客户反馈问题的监控。
智能监控方面,腾讯也开始做一些智能告警,比如智能告警关联。基于这些告警关联,做了一些初步的根因分析、故障预测。严格讲,我们也没有特别运用好涉及到AI的技术框架风险,只是在这个层面上做了一些数据的深度加工分析。这也算是一个AI的方向,也算是门槛,入门级别。效果比较显著,只要有了充分的数据支持,针对数据做一些智能的运维工作,就看想法有多少,就能做出来多少。
用户体验方面,是重点跟进的一块。我们会汇总各个渠道用户反馈的问题,对它进行一个归类、分析,跟进处理。评论服务、京东网站上看到的图片、视频、直播,根据这类业务层面,业提供一些技术支持的方向,帮助业务提升这方面的治理。
另外一块是自动化测试,比如怎么改善自动化效率,日常的运维和测试工作效率。
1. 全网质量监控。
做运维的同学都知道,在中国的互联网环境下做全网质量监控,面临很多困境。比如现在32个省份,每一个省份还有三大运营商,除了三大运营商有可能还会有中小运营商,有的业务可能也会面临一些海外用户的反馈。当然,像京东这种,来自海外的定单也比较少,但访问量还是有一定的比例,尤其是一些高层,包括投资人。早期还有南北互通的问题,这些南北互通没有那么明显,但从南到北因为物理限制,还是不小的。比如广州到深圳到北京,公网延时,正常要50毫秒,最低也要45毫秒。比如像华北地区访问北京,华南这几个省份区域,就是10来毫秒。物理地域的限制还是对我们影响非常大。
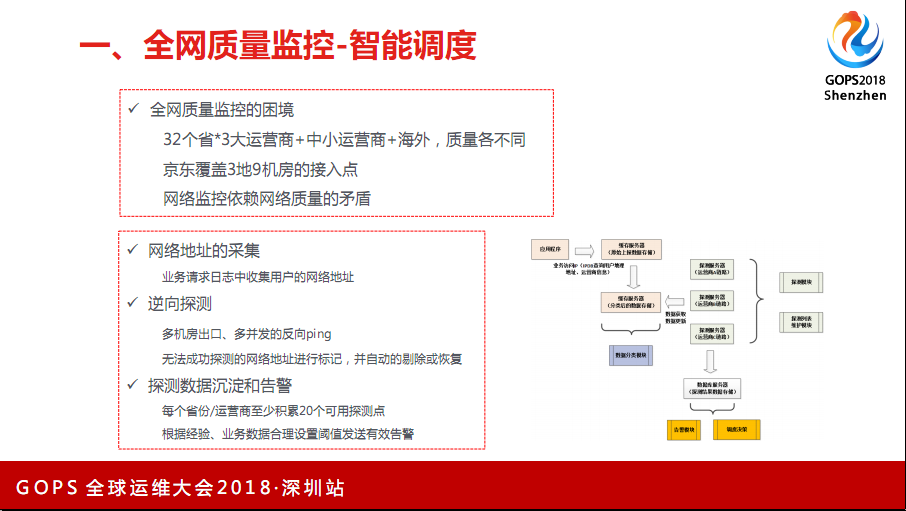
我们做网络监控时,面临一个悖论,不能太依赖网络去做网络的监控。大家应该有一些体验,好多APP里有网络诊断功能。当你发现APP体验不好时,在设置里可以找到网络诊断的功能,我们早期也上线过这个功能,但有一个最大的问题是网络质量的报告上传不上来。真正体验是有问题,我们也知道它有问题,但报告也生成了,除非用户给你截图发给你。但如果是一个很长的报告,我看有的APP里体验报告是通过邮件的形式,你点发送报告就打开了邮件终端。这种收到的可能性也比较小,后来就把这个功能下线了。确实对我们故障排查处理时没有多大帮助。
1.1 全网质量监控-智能调度
我们建立了全网质量监控的方法,这个方法是从客户端访问日志里,把客户IP统计汇总,从服务端反向拼回去。当然,拼回去的质量相当不好,99%以上的是拼不上的,但剩下的1%已经足够使用。系统每一个省每一个运营商会选20个探测点,真正的客户端IP。这些IP有可能是4GIP,有可能是家庭宽带IP,会实时更新和迭代。通过这个IP的整体质量反映这个地区这个运营商的网络质量。
实现的算法说起来简单,最后会发现选活性探测点包括淘汰机制,稍微要费点精力去做,最后提炼出来就一劳永逸。除了新疆这样的省份,其他省份基本都能有一个固定的点,选出来可以做一个探测。有可能你也能搜到这样一个探测点。这个方法的好处在于你不用依靠客户端给你反映质量,自己在服务端反映拼出来,经过实践还是非常行之有效的。几乎99%以上,在我看过来用户反馈的问题都能监控到。基于这个网络质量结合核心指标数据做关联,就能把这个地区的网络问题都反映出来。
比如一个地区网络质量延时或者丢包率高,我们关联核心数据,如果发现真的有问题,做一个告警,这个告警非常非常准确。前期基于这个告警做应急调度。后来发现这个可以沉淀下来,当这个地区到一个固定的机房,长期并且稳定延时,会把这个地区的运营商直接调度到这个省份去,这是自动化实现的。它也有它的备份,算一个选举机制。
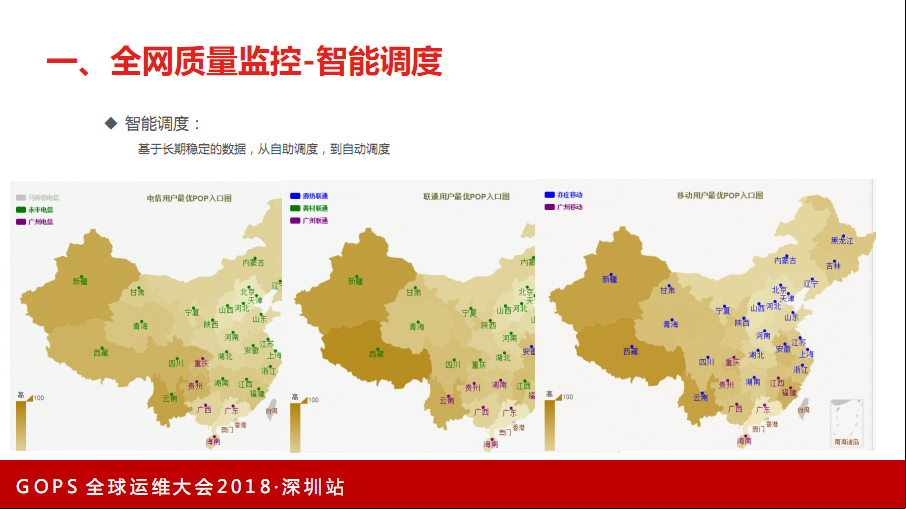
这是选举机制做出来的图(见上图),第一个图是网络机房覆盖在南方几个省市质量比较好。联通有三个机房。这样对于监控的同事一目了然。我们现在看调度包括看接入点,比如运维同志可能会记住几个电信IP、公共IP,现在是接机房,因为机房跟IP是绑定好的。运维同事和监控同事不用关注IP是多少,也不用在任何地方输入IP,有时候会输错或者记错IP,那就记住机房点,因为机房点是固定的。
1.2 全网质量监控-CDN质量
CDN监控,就记住一点,图片CDN。图片CDN在服务端做了很完善的,各个节点和源站做并发量、流量、异常量的监控。这些还不够,有些地区的问题还不能第一时间发现到。我记得非常清晰的一个案例,2016年双十一时,当时江西电信失联了,那时候我们没有实时跟踪到这个问题,是过后看到微博上有大量反馈,查江西电信这段时间的访问量,确实掉了不少。移动互联网时代跟PC时代不同的是某个运营商有问题或者核心指标下降,都会在另外两个运营商上有补偿,一般有两个运营商。你的手机可能是移动4G,但连的WIFI可能是电信。来回切换可以保障一定补偿,很少用户会彻底失联,多数还是有补偿的。
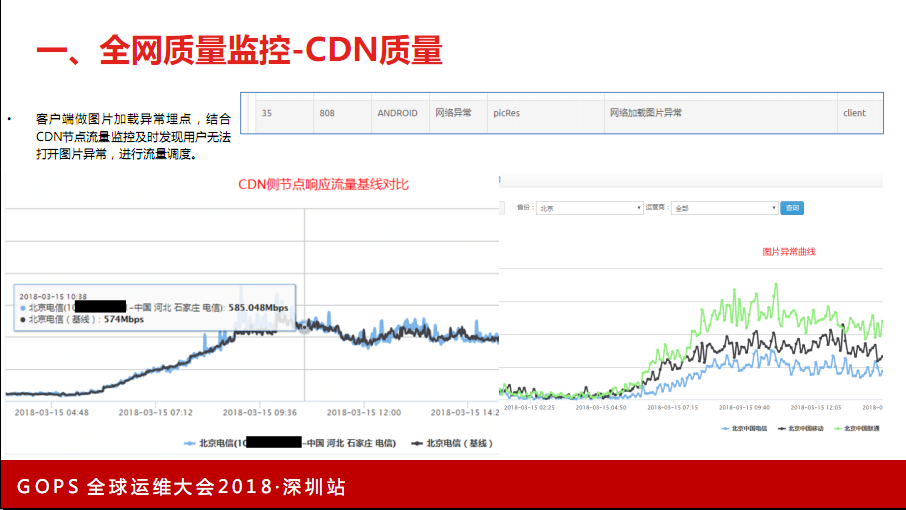
这是我们做的一个CND侧节点响应流量曲线(见上图),在客户端做了一个图片,也是为了减少客户端的开销,不会在客户端做很复杂的埋点。增加了用户客户端性能的开销,也增加了网络的开销。在做这个监控埋点时也非常谨慎,所以只做了一个808的ANDROID埋点,我们也不会区分图片加载失败、图片解析失败,就在客户端图片网络库加了一个图片加载异常上报。另外一个好处是CDN出问题时,上报机制并不是通过CDN分发网络,监控这块还比较准确。真正有问题时,这个数据报告是可以收到的。根据这个异常码做分析,我们发现一个问题,正常情况下也有一定的异常,而且这个异常是保持一定的值。通过分析有可能是用户本身自己网络没打开然后去打开APP,会有报错,或者有其他未知的情况。
三大运营商的异常曲线,这是很正常的一天,北京电信、北京移动、北京联通的数据。但真正异常时,比如北京电信出问题了,异常码会超过自己的占比,正常占比电信、联通、移动是433的比例。这个也没有区分4G还有WIFI。全网值是在这儿的,比如广东的电信,比例要偏高,可能要占到6。每一个省份把自己的占比做成一个固定的值,当你超出这个占比时,433变成333或者243都会做告警。非常准确的反映出CDN质量。这两块的数据一关联,比如电信的比例超过40%,再结合这个地区的节点告警,就能准确的定位,非常真实的反映出这个地区是有问题的。我们把这块跟前面说的全网质量监控一起做了,现在CDN也实现了智能选点、智能调度,不悦人工干预。
2. 用户反馈跟进
前段时间发生了一个“六六事件”,大概反馈一下京东怎么跟进用户的反馈问题。
东东客服和电话客服,这个量每天40万以上。一线客服人员大概能处理70%以上,在这几十万里,大概有百分之几十能第一时间给用户一个合理的完美的解释。当然,也有部分因为业务没有权限或者要核实。这些会流转到后台系统。
用户反馈的跟进,是跟进客服没有解决的用户的问题。另外一个渠道是PC、APP、微信、手Q,用户反馈的问题里有一个功能建议,这个功能建议最后,发现好多用户也没有在里面真正提建议,反馈的是问题。这大概每天有三四千条。
另外一个渠道,内部员工也有一个反馈渠道,比如各个事业群包括快递员,它也有一个渠道,把这些问题给我们反馈。
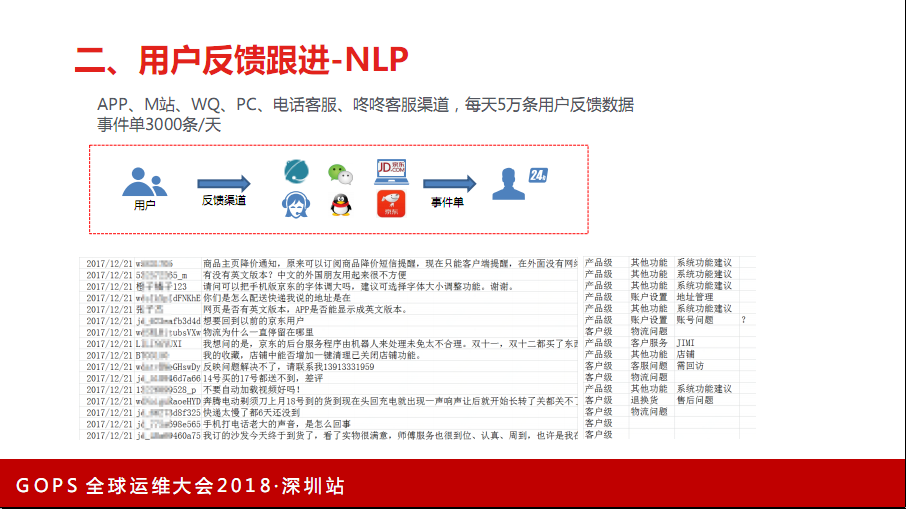
这三类问题,都会在后台进行汇总分析,转发到各个部门去处理。所有的问题都有一个实现要求,24小时内。后台导出来的一些数据,有些是建议,比如加一个英文版包括字体调大。还有一些解决不了的问题,让我们去联系。有些问题是无效的,最后这两条,“打电话声音很大”。其实这不是一个问题。几年前,我经常会收到日报和周报,用户体验反馈。他说清楚了昨天用户反馈的总量是多少,哪一类问题是多少,这个问题是突发的还是增加的问题。我问那个小姑娘怎么弄的,她说是人工筛选出来的,她从早上九点干到晚上六点能看两三千条。当然,这个流失率非常高,因为没有人愿意来到京东以后整天干这个事情。我们系统对于这类问题还是有很多办法来处理的。当时还没有智能语言和AI概念提出,当时提了说能不能用关键字提出反馈问题。整个后台系统数据里,像白条、物流这样的关键字,就认为是一个物流和白条的问题,做一个分类。这个分类可以把原来的问题分开,给这些分类做出关键字匹配,也会设置优先级。
整套做下来,确实有一定的改善。原来那个小姑娘不是看这个了,就是定义一些关键字导入到系统,系统会实时分类。这个系统上线之后大概70%,还有30%数据需要人工。从去年开始AI团队也帮我们做了这方面的分析,包括用户的正面情绪、负面情绪,评论问题的严重等级。现在准确率大概是95%以上,每天大概百十条的数据没有自动归类。这些就是自动归类出来的结果(见下图),无效问题是空白的,非常符合用户体验的需要。也是在“六六事件”之后,京东确实如老板头条上公布的信息所说,京东内部把跟用户体验相关的包括后台系统都整合到一个团队。

比如不能第一时间处理的还能自动派单,刚才提到反馈数量39条数据,每一个都是反馈条的ID号,会自动关联好同一类问题,派一个工单给一个部门。有些用户给截图了,可以附上这些图,还会做日报、周报、月报,还有各个版本的总结。这个情况会整体发给大老板看。
3. 数据曲线预测。
3.1 精准告警
针对曲线非常不稳定,波动性非常大的指标做合理的告警。比如每天整点时会有秒杀,这个秒杀会带来系统非常大的业务工作量。面对这些工作量,早期也费了很大的劲,怎么监控到这些突发情况。比如整点时没有突发,认为也是异常,有可能是配置的商品问题或者秒杀的系统出了问题。有时候毛刺可能是五倍、十倍的,怎么做精准分析。我们开始是在不同时间段设置不同的阈值,这样就不能准确预测到到底是不是有问题,有可能没有上来这个量。后来沉淀出一套算法,叫加权平均算法。过去两周在这一个时间点所有数据做一个加权评估,越靠近现在的时间权重越大,时间越久权重越小,根据这个做加权平均,做出一个预测曲线。这是我们业务标准的每天走势,根据加权平均算法把当天的预测出来。业务的实际走势,黑色线是当天的实际走势(见下图),根据这个加权平均算法做出的走势预测非常准确。根据这个趋势曲线,会把它做一个波动阈值,这个阈值根据不同的业务指标可以设置。定单大概是设10%的阈值,其他阈值设置稍微大一些,最高不超过30%。
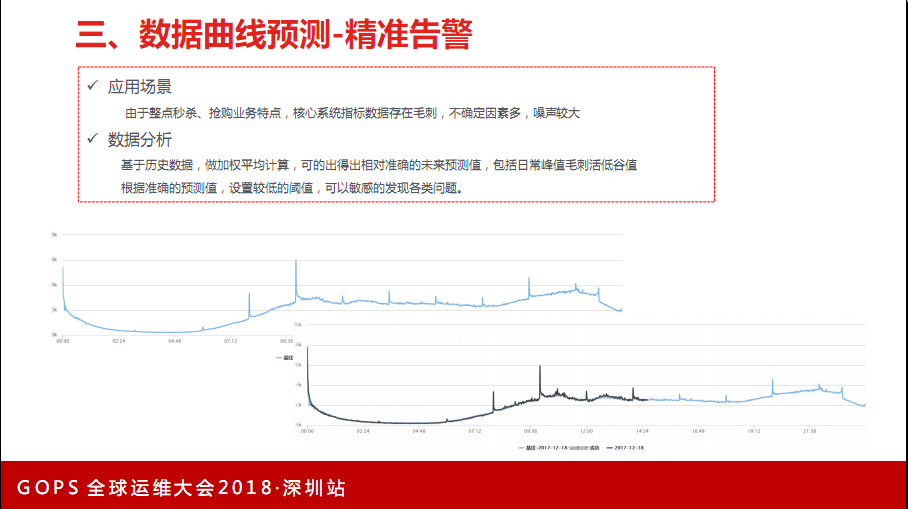
核心指标,包括带宽数据、访问量、定单量、支付总量都做了基线,根据基线准确反映告警。
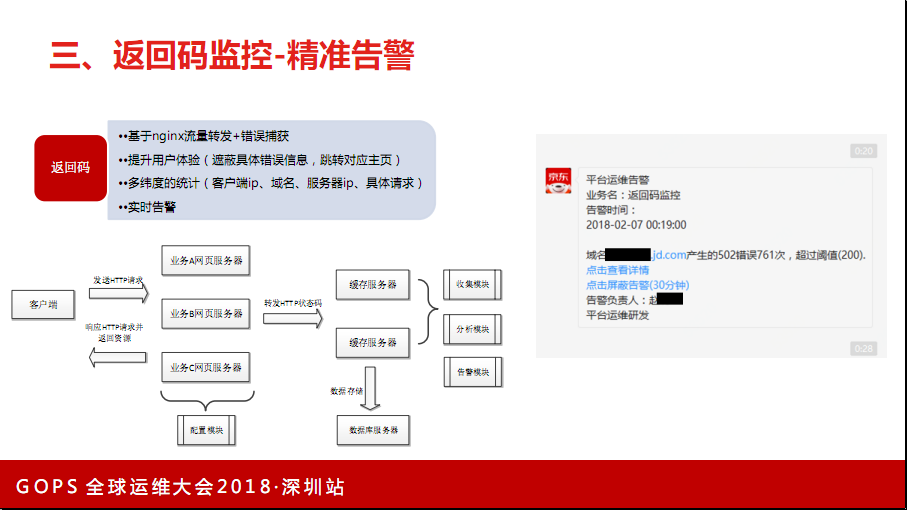
3.2 返回码监控
我们前端基本都是外部服务,把返回码做了完整监控,过滤大量日志,包括在服务端做一些埋点。开销非常大,别管过滤日志还是在服务端埋点,但也有配置可以实现定义好的错误,把错误流量导到后面。就实现了对于错误页做多维度的统计,在后面配置不同的错误页,不同的业务需要的是不同的错误页,这样更人性化。这是收到的告警,还有大概框架(见下图)。
4. 自动化测试实践
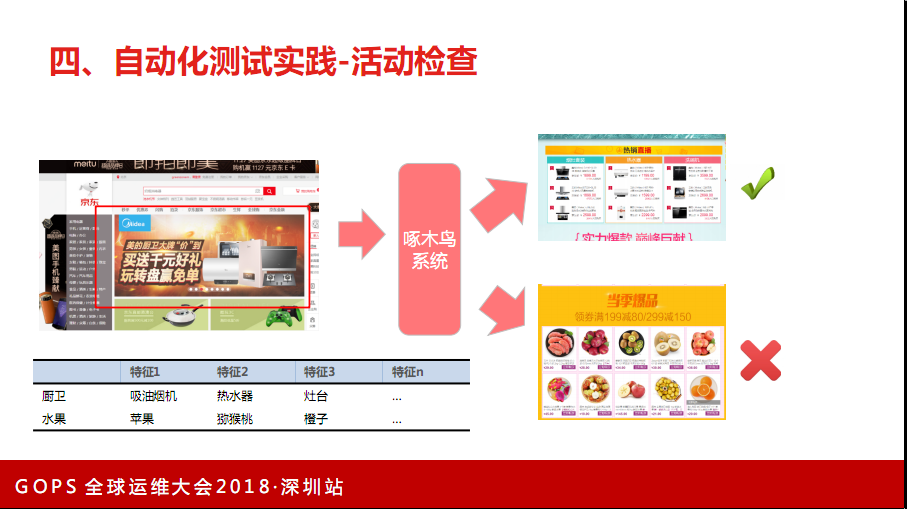
活动检查,京东除了黄金的购物流程,比如首页搜索,其他所有的页面看到的几乎都是活动页,活动页日常在线5000以上,包括品牌日、秒杀类的活动。针对这些活动,开始是测试人员跟进重点的测试工作,比如测试页面性能怎么样,页面里有没有错误或者其他的问题。问题点比较多,比如活动过期了。

这样的活动量规模人工覆盖几乎不可能,我们通过用一个浏览器内核把页面都抓取下来解析,解析之后根据设置好的去判断活动是不是有问题。活动是定时检查,也会做发布前的性能检查。发布前是性能,比如是不是会造成很大流量的开销或者里面有没有一些图片比较大。发布过时是在线时活动有没有国旗。

现在基本首页活动,5分钟一个周期的检查,二三级入口分不同时间,10分钟、1小时。解决活动运营效率还有人工成本这是投入产出比相当高的,投入两个人开发了这一套系统,解决了原来十几个人的测试团队工作。
现在我们对活动检查的平台也进行了升级,基于一些图片识别功能,比如你在首页看到的是一个厨卫活动,但有可能点进去发现厨卫活动里有一些生鲜楼层或者品类,这个也会做告警,有可能是运营配置错误或者后台任务生成时出现一些匹配问题。我们把活动入口图片解析出来,看它到底是哪个品类的,看活动页面里的内容是不是关联的,是相应的还是怎么样。
5. 持续集成
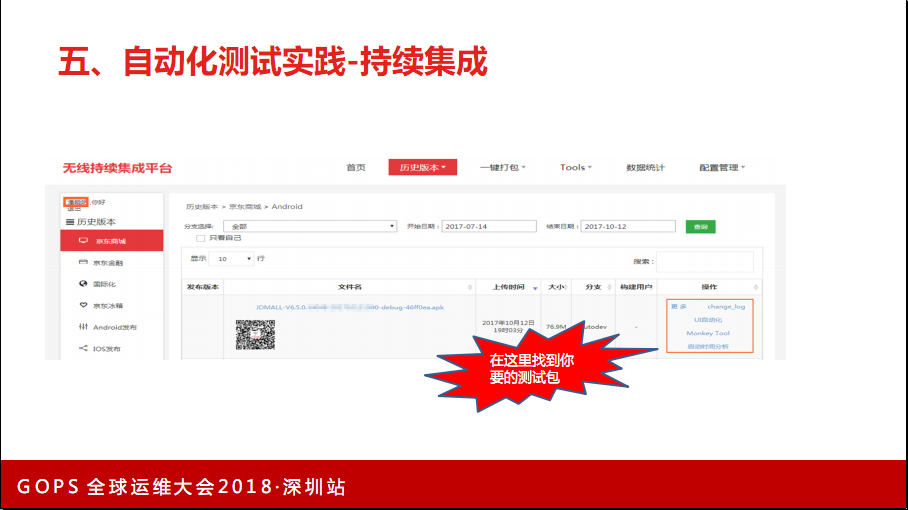
建这样一个平台前期投入开销非常大,但这是一个典型的通过一个工具能整个提升产品流程或者质量体验的一个项目。这个系统建设好之后,发现整个APP的发版流程都流畅了许多。也就是说现在实现的效果是随时随地都能生成,包括变成一个很小的功能都能生成一个包。这个开销比较大,在机房有安卓和IOS不同的打包服务器。我们回溯问题时也能非常快速的,哪一个问题是哪一个包带来的。
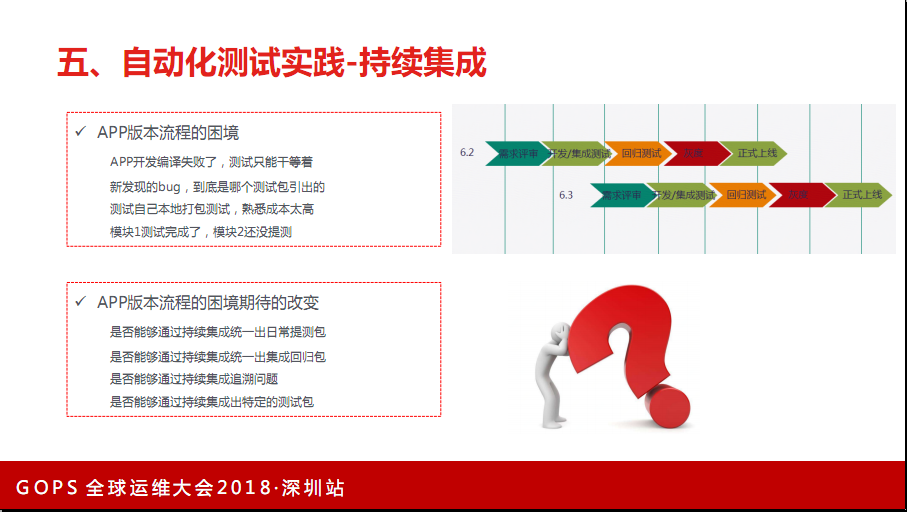
这里分享一点,有些公司可能也不适合去做这么一个大的大包平台,因为铺包的效率特别频繁,不是日版或者周版的节奏,就没有必要设置。
我们平台也会做功能扩展,比如代码扫描、安全扫描,苹果的审核也是一个很严重的问题。在前年时有一个包要提交给苹果,这样个把月就过去了,非常头疼。现在应对的策略是整理了非常详细的有可能被拒的问题,在这个打包平台里把问题扫描出来。不管人工审核还是机器审核,这些问题自己整理一遍。
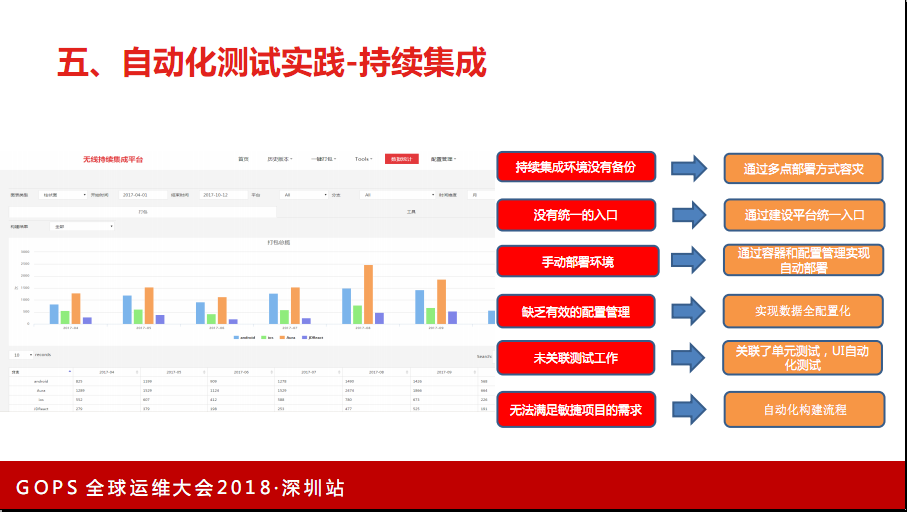
6. 移动端管理经验
刚才所说的整体和立体监控的项目,都是通过微信发送出来,微信是通过我们申请一个企业号。申请了这个服务和企业号之后有相应的接口可以调用。当然,这取决于你公司的规模,比如你公司500人的规模,可能每天发几千条没有问题。确实现在大家都不太看短信了,通过短信发,成本比较高,最便宜的也要三四分钱一条。现在通过微信,大家都在看,另外开发效率和成本比较小,调度接口还很简单,可用性也比较高。我们用到的,还没有出现微信接口超时或者有问题的,时效性都很高。

第一个图就是刚才讲的CDN监控。广东省电信占比大概是70%左右。印象中广东省的电信占比应该是60%左右,流量下降99%,肯定就是广东电信CDN质量的问题。我们也有一个非常简单的APP,运维和研发团队看的,包括注册量、登录量、首页访问量、搜索、商详、购物车等等,一点进来就可以看到实时曲线,为了解决值班运维还有开发人员看。当然,微信公众号也可以设置很严格的白名单,相对安全。微信企业号的劣势是实时曲线不能推送出来。这是我们服务器的告警(见上图),给这个企业号发一个曲线,再配一个IP号。弥补了微信企业号不能实时推送图片。DNS切换,这也是应急之需,基本上都实现了自动化的调度。当时,比如你做节点正常变更或者操作时,可以在这儿操作一下,把它调度走。
这是在移动端管理做的沉淀和积累,分享其中主要几个。大家如果做运维或者开发,都应该有这个痛点,大晚上可能爬起来,非常不方便。在保障安全的前提下,这是我们就在用的,也没有出现类似的安全。控制好的话,对人的休息时间确实可以解放出不少。
