@gaoxiaoyunwei2017
2018-04-19T03:50:49.000000Z
字数 7166
阅读 1375
蘑菇街DevOps实践和转型之路
luna
作者: 赵成
作者介绍: 我的题目是《蘑菇街DevOps实践和转型之路》。2015年前,我在华为公司,2015年后到了蘑菇街。我在华为是接触软件的运维和开发,也做互联网的项目,开发模式、运维模式是电信级的。到了蘑菇街后,到现在差不多3年,我基本上的经验是互联网的运维,我今天的分享是3年来实践的东西。
我个人是开发、测试、运维、架构设计,包括一线客户服务都做过,背景丰富一点。这是我个人公众号的二维码,感兴趣的可以扫一下。

今天分享的内容有三个方面:
- 第一,蘑菇街技术架构演进简介;
- 第二,DevOps和技术架构;
- 第三,持续交付实践。
现在为什么需要DevOps解决方案和方法论?这更多是谈一下我个人的理解。DevOps核心的部分就是持续交付内容。
第一部分是先讲一下蘑菇街的技术架构演进过程
蘑菇街的业务,它是专注女性时尚的电商平台。2017年,我们和美丽说合并,成立了美丽联合集团。合并后,技术体系和运维体系是以蘑菇街为主,我们进行了融合。
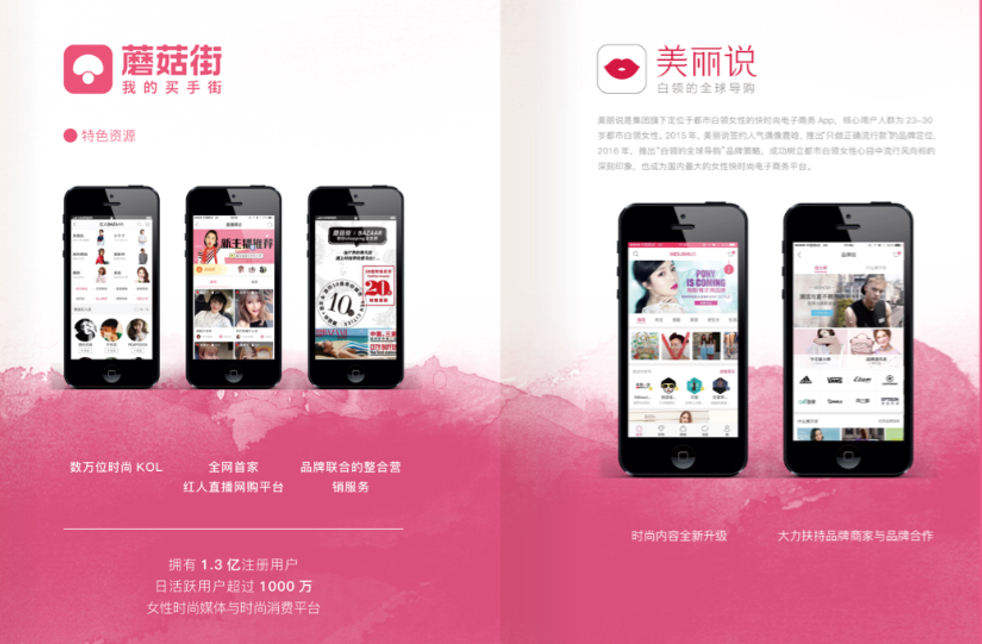
这是蘑菇街的基本数字。我们现在有1000万日活,80%移动流量是来自APP和小程序,每日百万级订单量,1000多线上应用,核心链路占70%,Java为主。我们机房是腾讯云的黑石机房,我们把蘑菇街的业务搬到腾讯云的黑石机房,结合腾讯云的弹性能力进行释放,这对成本的控制非常好。我们研发团队有700多人,运维团队有25人。

这是蘑菇街最早期的技术架构,2011年的业务是导购型的,那时候我们采取最简单的架构。这样的架构比较简单,实际上是没有架构的,我们就这样一直发展到2013年。

2014年后,这个工程越来越大,是臃肿的PHP单体工程,这样的变化有两个方面。第一,蘑菇街从最初只做导购的业务形态到后来做电商,这个体系是变得越来越大,有了电商要做用户、交易、商品、支付、广告等,业务的范围非常大。第二,蘑菇街研发团队的规模从最初二三十人到上百人,2014年后,差不多有300多人了,所以这个工程就是臃肿的PHP的工程。

工程大了后带来什么问题?软件上的耦合性太高了,改一个地方会影响很多地方,到底影响什么?这是理不清楚的,最初一开始到工程的开发人员是清楚的,但是人员不断有新的进来,他们不清楚,会导致代码的耦合性高,开发效率就降低,业务的迭代速度就下降了。这时候,业务跟开发的矛盾是比较严重的。
另外一点,到目前这个阶段,代码非常复杂,整个过程耦合性非常高,改动的成本非常高。但是,这个阶段的挑战主要是开发,运维是没有什么挑战性的。因为运维只面对一个功能,不管后面多少台机器都无所谓。对运维来说,并没有太大的挑战,但对开发来说,这个代码基本上是不可维护的。
这个过程比较大,中间还有一个中间层,从软件工程角度来说,我们从单体工程演进到分层架构的架构体系下,稍微有点意思。
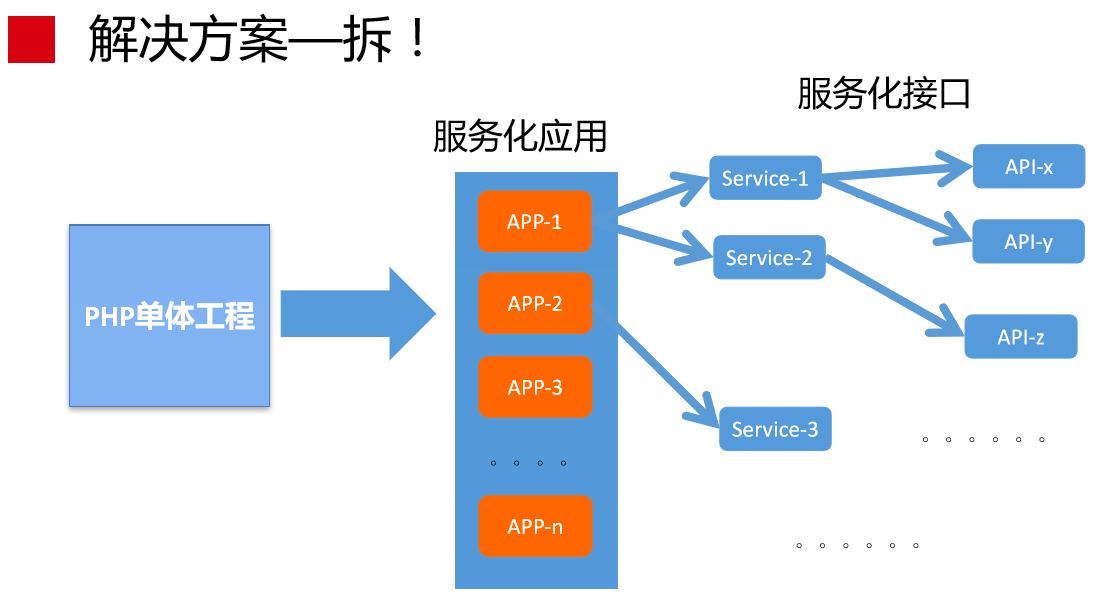
解决方案就是拆,把大工程拆成小工程,其实就是做服务化,就是微服务。通俗点讲就是把大工程拆成一个个APP,可以按照业务领域拆成商品应用、购物车的应用等等。这是整个过程。
如下是商品案例,里面有不同的服务,服务后面有不同的API,就是大致的拆分过程。但这里想表达的是,我们都在讲微服务、服务化,其实微服务也好,服务化也好,力度到什么程度?这还是非常考验业务架构师的水平能力,这要跟后面的运维成本进行权衡。举个例子,商品中间有不同的服务。如果微服务拆得更细一点,后面的API也可以当成独立的服务进行运行。这其实是有很高的代价的,我后面会讲到。
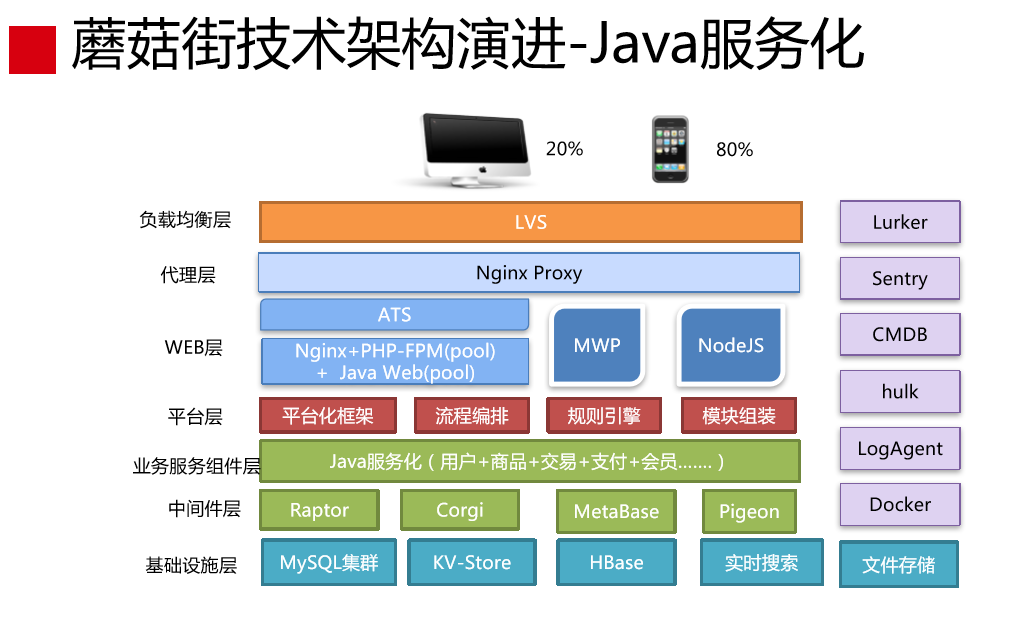
微服务做完后,整个架构形态就变成这样(见下图)。2015年年底到现在没有发生太大的变化,就是这样的架构形态。
第二部分DevOps和技术架构
回到我们的主题上来,我刚才讲了这么多关于技术架构的东西,我好像没有提运维。第一个问题,技术架构跟DevOps有什么关系?第二个问题,DevOps到底是做什么的?DevOps听得最多的是解决运维和开发之间的矛盾,DevOps到底是干什么的?第三个问题,为什么DevOps的需求会这么强烈?我谈一下我个人的想法和理解。
这是业界软件架构演进过程(见下图)。软件架构就是从单体结构到分层架构到微服务,单体架构不行,有连接层的架构需要带分层,再往后,逻辑的工程越来越大,这时候只能拆成服务化。资源粒度是从物理机到虚拟机再到容器。开发模式从瀑布模式到敏捷模式再到DevOps模式。发布部署是停机变更到热部署到现在的持续交付。
蓝色部分,我们可以想象这个规律,我们一提微服务就提容器,一提容器就提DevOps,提到DevOps就提到持续交付,就是这样的规律。这里面是有一些关系的,这些关系到底是什么呢?这就是我要讲的。
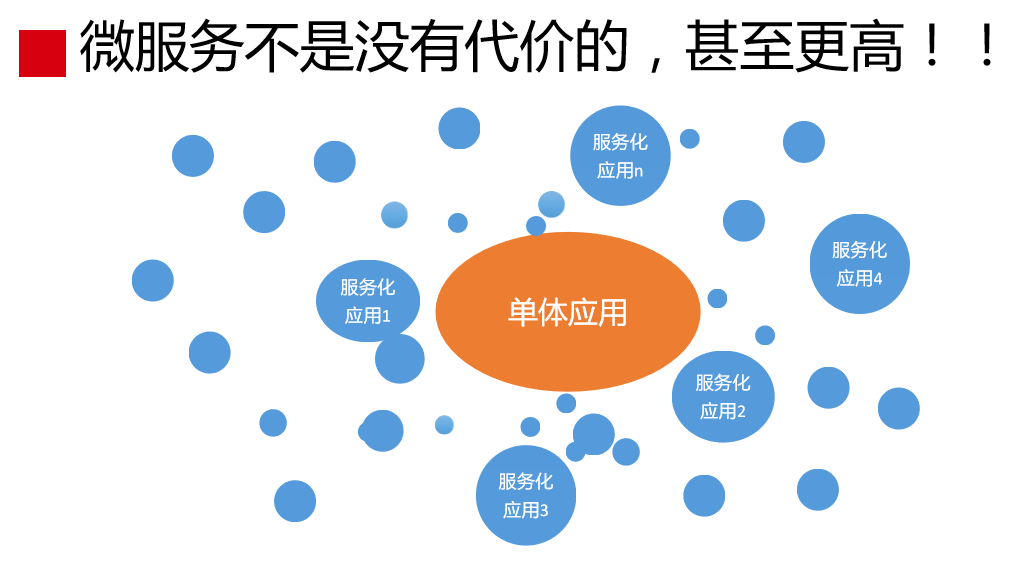
我们做微服务,微服务并不是没有代价的,代价是非常高的。我们从一个单体工程进行拆分,拆成几十个、几百个,甚至有上千个应用,我们面对的场景是一个单体工程会拆成很多应用。那时候的挑战是在开发,对运维来说没有什么压力和挑战的。当工程拆成这么多应用的时候,面对的应用工程不是一个了,是上千个了。像BAT那样的,规模会更大,工作量会翻倍,这就是代价。为什么说微服务拆的力度并不是越小越好,这是有成本代价的。
更复杂的一点是,把应用拆出来的之后,其中是有关联的有可能是服务之间的调用关系,也可能是API之间的调用关系。
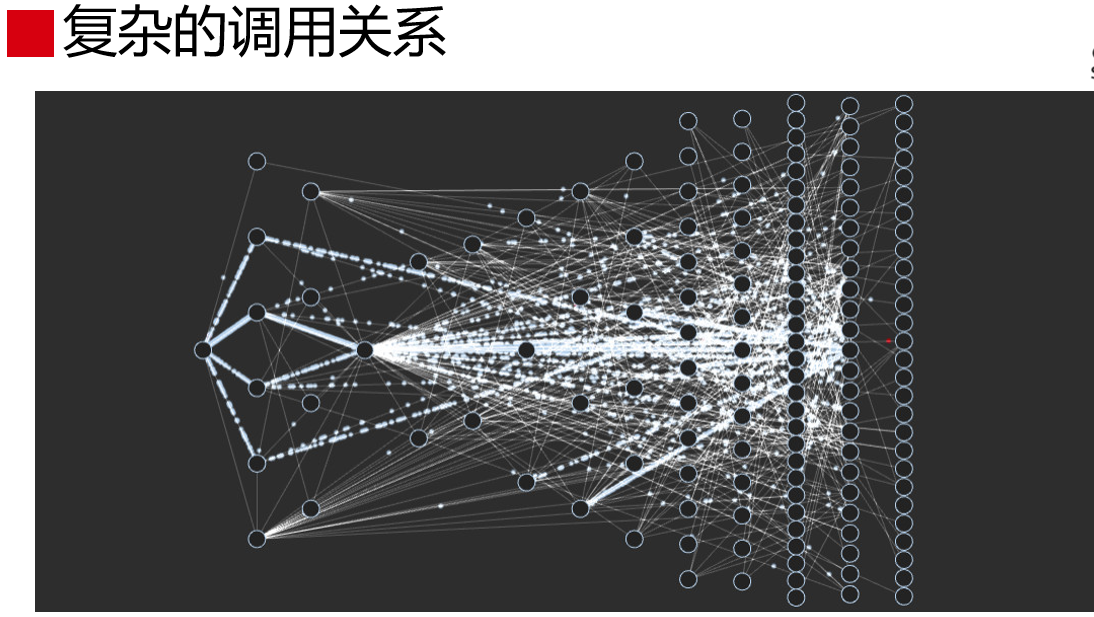
通过这两个图,大家能感受到什么?这时候引入微服务后,系统复杂度远远超出了人脑认知范围,超出人力掌控范畴了。做发布的时候,里面的众多应用靠人是搞不定的,讲持续交付的时候会讲到。这么复杂的关系,靠人脑是理不清楚的。理不清楚怎么办?这时候,就要靠技术的手段进行解决,就要有工具、平台、体系去建设这些东西。这些东西谁来建设?要建设的话,是离不开运维和开发的配合,同事因为Dev和Ops的工作特点,Dev和Ops必须合作共建。

举个例子,做交易的业务肯定不会去实现商品的代码、支付的代码,要做支付的人不会关注商品的代码怎么写,所以视角是局部的。只关注局部,全局怎么办?这里面还有两个角色要关注,一个是业务架构师,要关注全局,另外一个是运维。运维面对的是线上整体的效率提升,面对的是线上的全局。这样的分工特点决定了DevOps必须合作共建,要通过技术的手段解决这些问题,倒逼运维和开发必须合作。
DevOps本质上是技术复杂度上升到一定程度的必然产物。技术复杂度就是引入了微服务和分布式架构引入带来的。DevOps并不是单纯为了解决运维和开发之间矛盾才产生的。这种情况下,你要解决,运维和开发必需要合作,这是倒逼的关系。
有了这样的理解后,我们对DevOps要有重新的定义和理解。微服务和分布式架构下,运维是整个架构体系的一部分,是架构体系的延伸,并是不可分割的关键核心部分。运维能力是整个技术架构体系的能力表现,不再是单纯运维的运维能力体现。我们做的运维工作是基于架构去做的,没有哪一个运维体系直接放到某个应用上做。这种情况下,必须把视角从运维中跳出来,从全局的角度看事情。这是需要重新定义和理解的。
在座的有没有不是做运维的?有吗?这么多,是好事情,对运维重新的理解和定义,不仅仅是运维的人需要转变思路,是开发都需要改的,如果只把运维定义到搞搞网络和服务器,这样是做不好的,期望从架构设计开始,从最上层的开始有一个转变,这是非常关键的。在座的可能不是就运维团队里的,现在可能多多少少有一些这样的感受。
第三部分持续交付实践
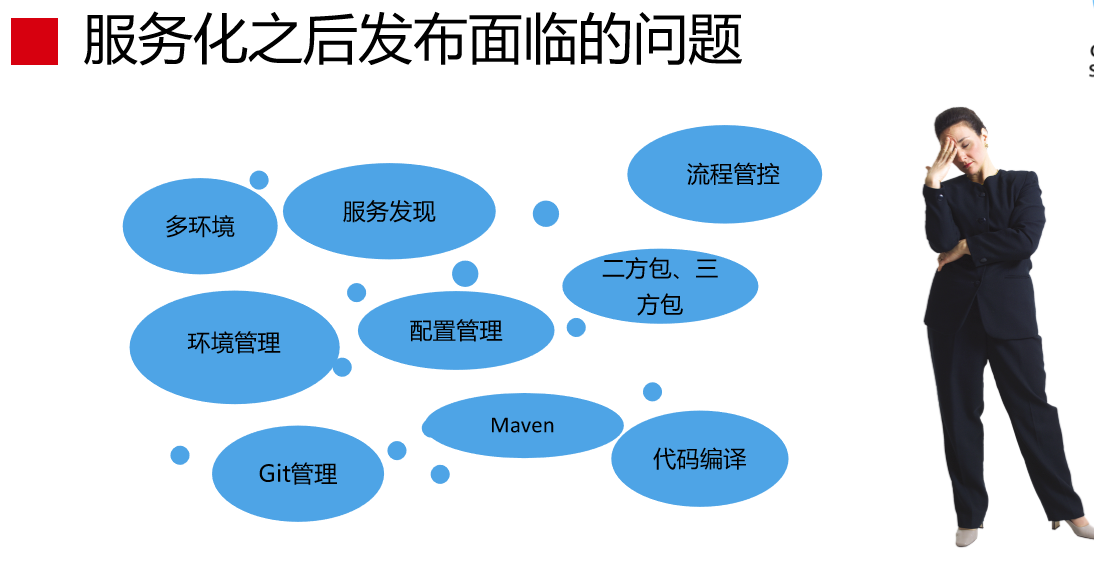
接下来讲持续交付实践。我主要讲一下持续交付遇到的问题如何做选择。这是服务化之后发布面临的问题(见下图),其中有两个改变,一个是单体工程拆成很多应用,管理复杂度上升了。另外就是技术从PHP迁到Java上,这时候面临什么问题呢?我举个例子,PHP做代码发布的时候怎么发布?PHP代码写完,文件一发就可以了。Java来说,完全不一样,写完代码后要编译、打包,不同的应用有不同的配置,这时候要考虑配置怎么打包进去。因为是在服务化的环境下,在这个环境里,发布一个应用影响的不仅仅是你自己,有可能影响其他的,要有线下的环境保证,整个过程比原来复杂很多。
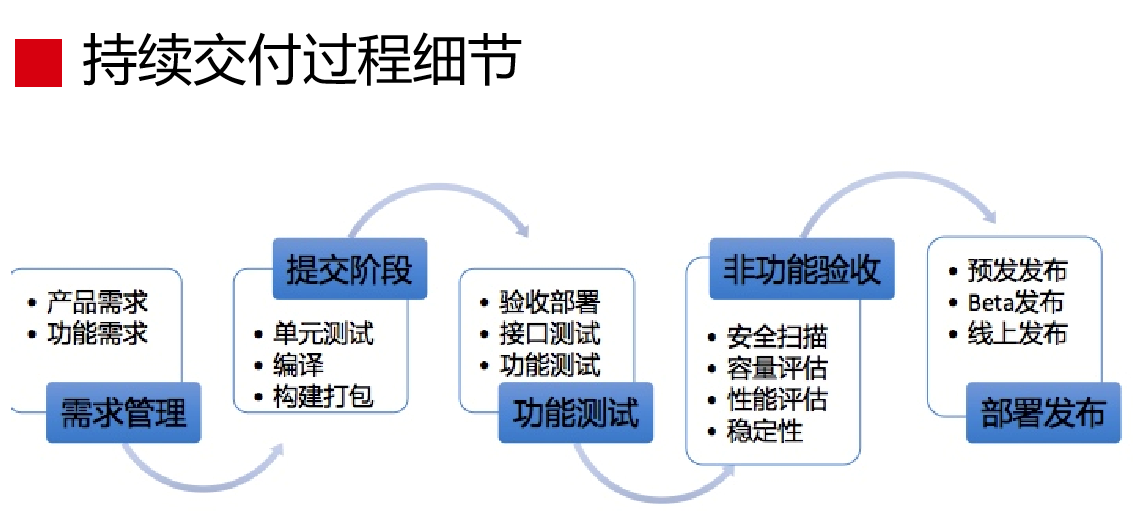
这是持续交付过程细节(见下图),需求管理到提交阶段、功能测试、非功能验收,再到部署发布,这个图是我总结出来的。我们做发布、交付的时候,我们也没有持续交付的理论指导我们怎么做。当时我们面临很现实的问题是做了服务化之后,2015年年底有很多团队的服务化改造完。我们2015年年中做改造,我要先把代码拖下来,不同的环境拖不同的配置,再把配置打包,再发布上线,这时候还需要发布前把应用拿下来,再进行变更,再从配置中心上挂上去。这个过程下来,运维人工做一个、两个去做还可以,七八个应用就搞不定了。这个需求是非常迫切的,我们当时只有一个念头,就是赶紧把发布的问题解决了。
我们发现,最迫切的问题解决后,我们还有很多可以完善的,所以我们不断完善,就把这个东西做成现在这个样子。
这是需求管理(见下图),我们做需求管理最初的目的是代码发布是想每一次变更都可追溯,一个应用变更有两种原因,一个是需求变更,一个是修改BUG。对需求来说,是非常复杂的,所以我们后来跟PMO部门合作,我们要求在项目立项时要把需求分解,分解后必须要有业务架构师承担需求的,要把需求拆借成一个个Feature,对应到应用然后进行发布。我们做了这个事情后,带来一个好处,我们原来没有考虑到的。一个需求拆借成这么多Feature后,这些Feature是有关联关系的,Feature1和Feature2是有关联的,这对开发人员是不知道的,他并不能清晰地看到关联关系。这种情况下,关联关系他就管理不起来。
我们做了这个事情后,我们要求架构师在需求发布的时候要以需求功能去发布,要协调好不同应用之间的发布数据,他必须要做这个事情。后来,我们看Google做发布的时候有一个角色,叫发布协调员,其中一个作用就是做这个事情,必须协调一个需求不同的应用之间的发布顺序,甚至是多个需求做一次发布,中间的过程是怎样的,他必须要把这个事情做好。
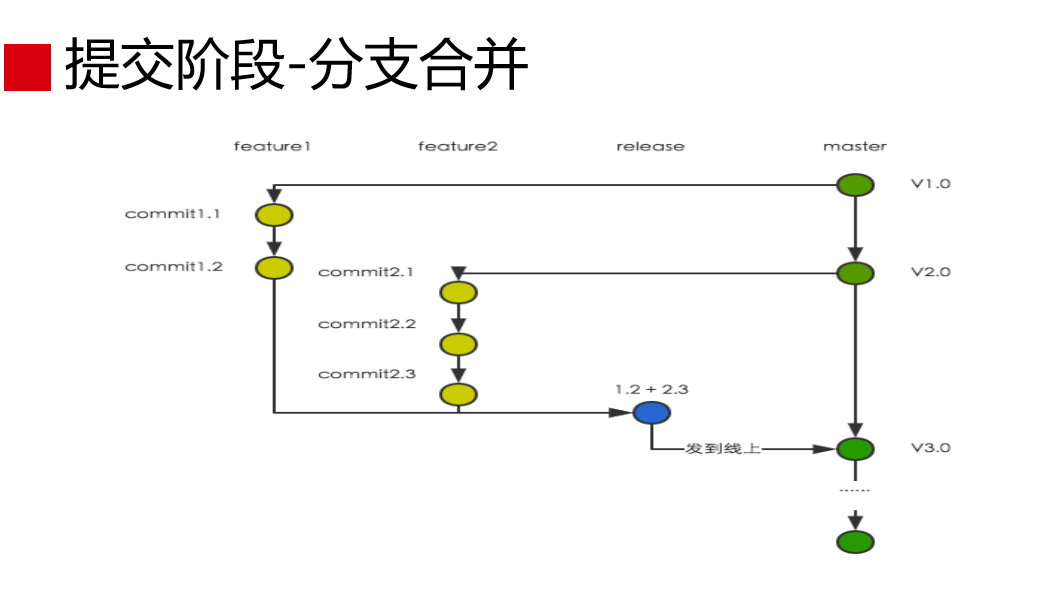
这是提交阶段。写完代码之后,我们面临代码怎么提交,提交里会涉及到怎么合并,选择什么样的分支模式?这涉及到分支模式的选择,这也涉及到开发团队如何协作的问题,我们归结到是开发模式选择的问题。业界主流的是三种,就是主干开发模式、Gitflow开发模式和分支开发模式。

主干开发模式就是从Master分支拉代码直接改,改完之后提交到Master分支,发布的时候发布Master分支。但是,这是有场景的,如果一个团队同时进行一个项目是可以的,这种情况下提交任何代码都有功能测试和非功能测试的环节保证,发布的时候代码是有保证的。但是,这是比较理想的,一个开发团队可以同时进行很多项目,一个项目里涉及很多应用。这个情况下,有可能两个项目同时在一个代码,Master同时在改、同时在提交。我在做项目A的发布时候,会把没有经过质量保证的代码也发布了。
干开发模式是一个项目团队同时只在进行一个项目是可以的,它解决不了并行的问题。
所以就有了Gitflow开发模式,它在Master分支上有一个Development分支,任何变更都要从Development分支上迁代码。这种模式可以比较好地解决项目并行的问题,但带来更大的问题,它分支太多了,是非常复杂的,分支管理成本会非常高。
分支开发模式是我们现在采用的模式,我简单说一下。我们从Master分支每次做变更的时候,一个需求拆分多个Feature,从Master分支迁出Feature分支,在Feature分支上做变更,在发布的时候以Master分支为基线,迁出一个release分支,Release发布后,合并为Master,这始终与线上的版本是同步的。这样的成本会小一点,还能解决项目并行的问题。我们在做这个的时候,我们调研过,阿里也是采用分支开发模式。
代码提交到分支上了,要做一些单元测试和接口测试。我们会用Junit和TestNG分别进行单元测试和接口测试。之后,我们用Maven插件,用来执行Junit或TestNG用例。用JaCoCo分析单元测试和接口测试后的代码覆盖率,之后用Jenkins,自动化测试任务执行,报表生产和输出,与Maven、Junit、Gitlab这些工具结合非常好。
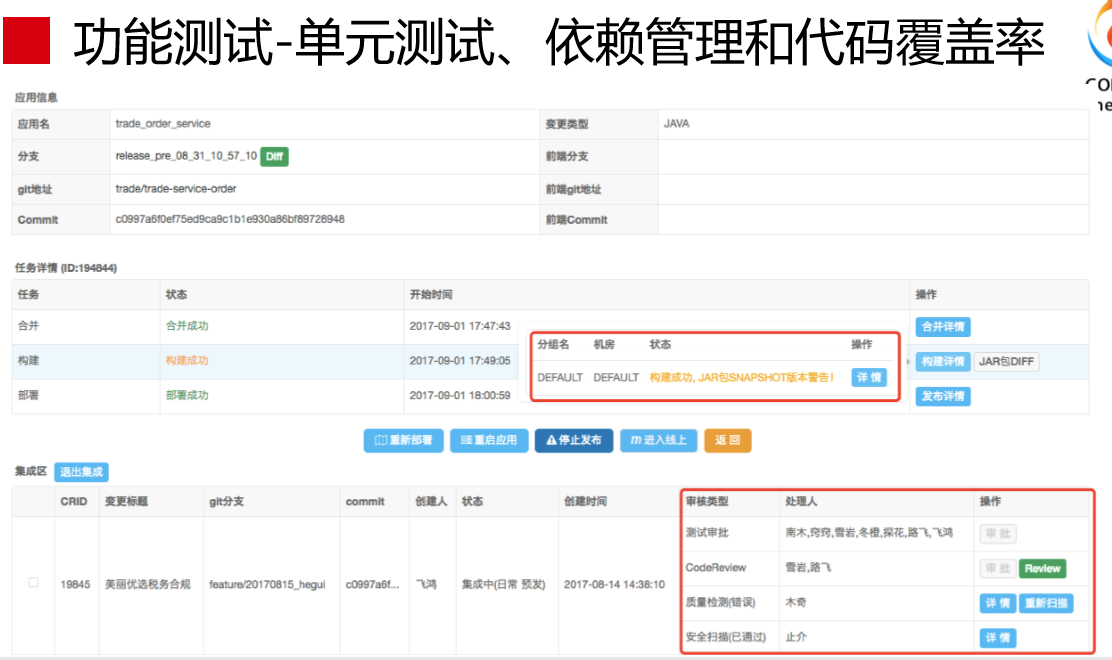
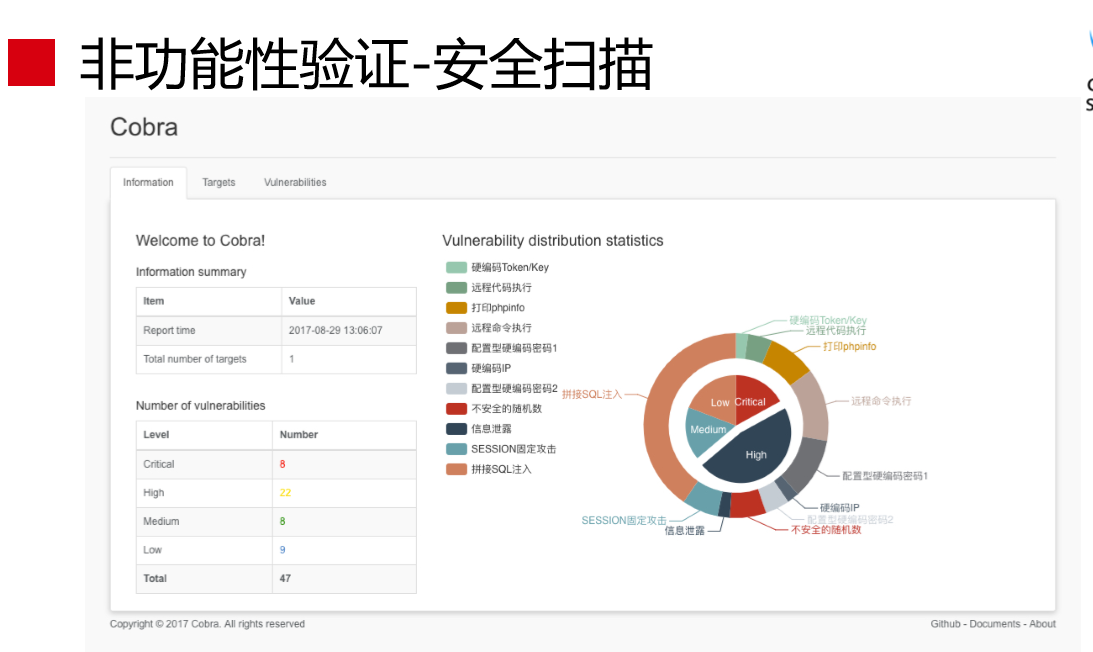
非功能性验证是穿插在整个过程中的,比如提交阶段会进行非功能性验证,就是安全扫描,要看看有没有漏洞在里面,检查的漏洞非常多,比如远程代码执行。这个工具叫Cobra,是我们团队开发的,现在很多公司也在用这个工具在做这个事情。我们做的时候,中间有一步是安全扫描,这个必须通过的,不通过是无法进行下一步。
我们提交完之后,代码也测试过了,下面就可以打包,这时候我们要做编译构建管理,我们用两个工具,一个是Maven,这是做依赖管理,还用它做打包和自动化的穿插执行。Maven对插件的功能非常好,能非常好地实现自动化。第二是Docker,这不是用于最终的发布,我们用Docker是用它提供非常干净的编译环境。编译的时候非常依赖环境,如果在固定的编译环境下,会导致很多编译冲突。但是,Docker会有很大的好处,它的隔离性非常好。通过Docker拉一个编译环境出来,是非常干净的环境,把代码放进去,把交付件拉出来就可以了,然后把环境销毁掉。Docker提供了并行的可能性,我可以在一个物理机上并行几个去跑,所以并行效率是有保障的。

这个方案我们从2014年用,我们发现Docker这个工具后,没有一下子做交付的工具,我们用来做编译是挺方便的。后来,跟其他公司聊,他们的发布编译也是用这个方式。
这个阶段的难点是什么?就是复杂的多环境和配置管理,这个大家应该有感受。我们做发布也好,做运维管理也好,最麻烦的就是配置管理。我们做一次发布会经历不同的环境,比如线下环境、预发环境、Beta环境、生产环境。配置复杂在什么地方?跟环境相关的配置,线下环境连的DB,跟线上环境连的DB是不一样的,你用的Token,Token也不一样。如果你依赖第三方支付的,你在线上的环境可以直接连正式的支付通道,但是在线下不能连,这跟环境相关。这种配置每次打包的时候,生成交付件的时候,要提前判断出来,这是跟环境相关的。
我们需要多少环境?这是我们实际用的环境(见下图),有开发环境、项目环境、集成环境、预发环境、Beta环境、小蘑菇环境。我以线下环境为例进行讲解。
一开始的时候,我们就一个线下环境、线上环境,中间会做网络隔离。实际情况是什么呢?对开发团队来说不是只有一个项目在并行,是多个项目的,这些项目都有质量保证的需求,这些需求都放在一个机房测试的话会有冲突的。我们会碰到测试的时候应用不行了,这会产生环境的冲突,这怎么解决呢?我们就建设项目环境,每个项目分不同的环境,这只允许核心的项目,一般的项目不会这么做,因为这是有代价的。
我们分了这么多环境,这些环境里只包括本次项目涉及到的变更应用,如果不涉及到变更应用就不会设置这个。我们做了一个改造,在分布式的服务化架构上,我们会优先支持本地调用。比如在项目1里有应用A、应用B、应用C,这些应用是本次项目需要变更的,这时候之间的相互调用都是在本环境内进行闭环的。但是如果是应用E、应用F、应用G,在本次项目中不包含的,这时候就依赖集成测试环境。这既保证了环境的隔离,又保证了环境的建设最小化原则。 这是线上环境,大家可以看一下,如果有问题的话我们线下进行交流。
多环境下的配置管理,有三种:多配置文件、PlaceHolder和AutoConfig方案。多配置文件就是一个环境建一个配置文件出来。最初的时候,我们是线下环境、预发环境和生产环境,有三个环境的时候,我们用这个方式,但是后来会有项目环境、开发环境,这种方式是搞不定的。AutoConfig方案有点复杂,但是有一些教程可以在网上找到。这个方案可以比较好地管理不同环境之间的配置,阿里在用这个方案,我们现在在调研这个方案。
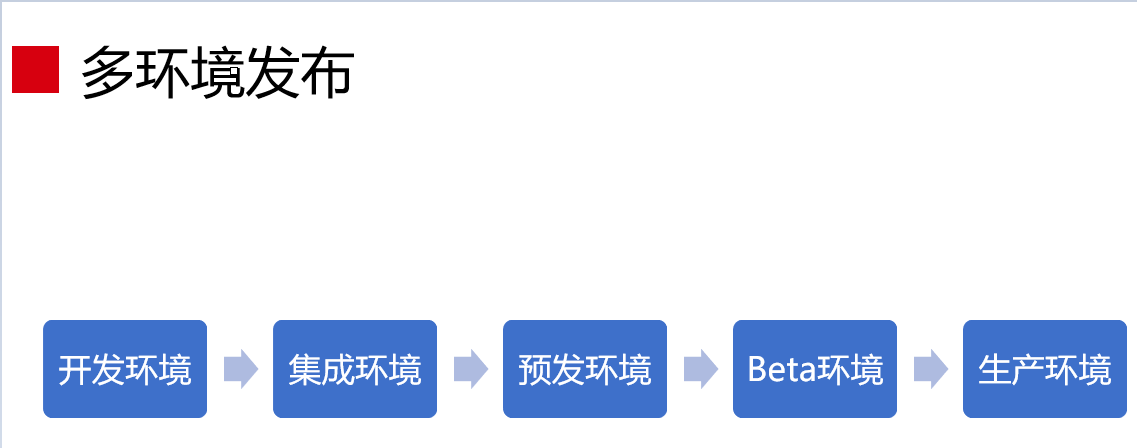
后面会涉及到多环境发布的问题,这几个环境是我们必须经历的环境,即开发环境、集成环境、预发环境、Beta环境、生产环境。
这是单提机器上线部署的场景分解(见下图),这个单机的。如果靠人工去做,做一两台是可以的,但是几百台是搞不定的,所以我们要把过程串联起来。我们会把单机的动作做成自动化的过程,之后我们把这个过程再应用到线上去。
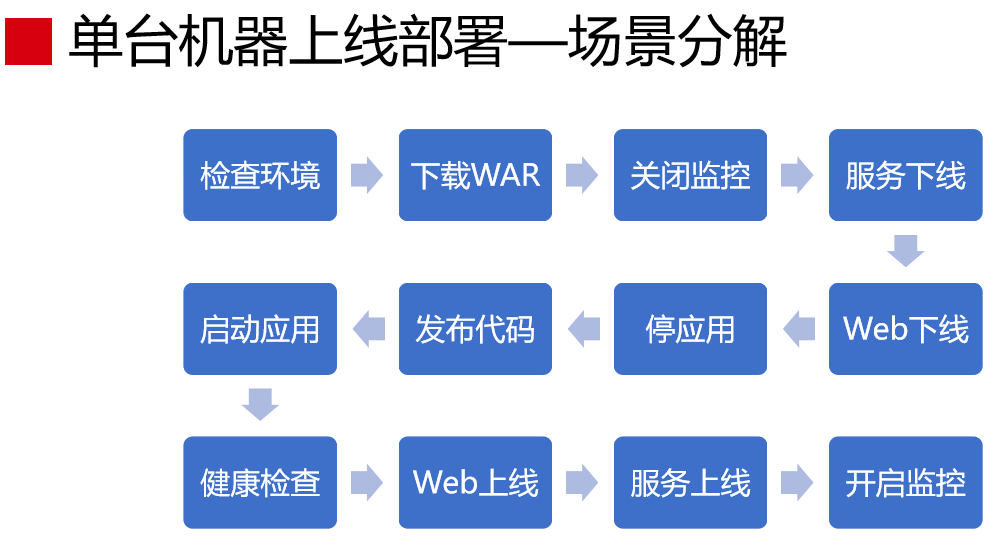
这是发布和部署模式(见下图)。主流发布模式有三种:蓝绿部署、金丝雀发布和滚动发布。蓝绿部署在线上有两个环境,发布的时候先发布到绿的环境上,验证没有问题的时候,再切换蓝环境,解释起来挺复杂的,从管理上来说也是挺复杂的,用的时候,我感觉没有这样的场景需要我们这样去做。

我们做的是金丝雀发布和滚动发布。金丝雀发布就是从线上的环境里挑从两三台机器,先把版本升级发布,这几台机器在线上承载线上真实流量,它有没有问题会暴露出来。Beta发布完了,版本没有问题,就大面积往线上发布,这时候需要考虑一个问题,不可能线下的机器都停掉,会分批去发布。
线上部署案例,我分了8批,每批有8台。我们采取的方式是金丝雀的灰度发布再加滚动发布的分批形式。发布完后,我们会做另外的非功能性验证,验证性能和容量的下降,要看QPS有没有降,或者有没有出现新的错码。
我们导流的方式有两种方式,一种是Nginx的方式改一下,另外一种就是改一下负载权重,这样可以看到单机极端的应用如何,可以看到发布前和发布后容量有没有变化。我们的效果是随时可以发布。
关于DevOps和运维,我们今天讲了效率的部分,我觉得整个运维是比较大的,包括稳定、体验、安全、成本,稳定性方面没有时间去讲了。
如果大家感兴趣的可以关注我的公众号。最后,感谢大家。

