@gaoxiaoyunwei2017
2019-04-29T06:30:31.000000Z
字数 7492
阅读 1267
恺英网络的多云实践之道
白凡
分享:徐巍
编辑:白凡
接下来轮到我们的主场了。刚刚几位演讲嘉宾,一个关注高可用;另外一个关注网络。我现在待的其实是一家相对不太大的一家公司,所以更关注我们公司云,整个90%的云跑在公有云,也有一些主机,所以我的题目是恺英网络的多云实践之道。

1. 自我介绍和现状
我做一下自我介绍和关于现状的介绍,我十多年一直从事运维相关的工作,之前在视频公司和一些在线交易系统,现在在一家游戏公司,做了很多年的IAAS和Paas的一些事情,我当前在PPTV的时候经历过主机从几百台到几千台的业务爆发增长。



2. 问题
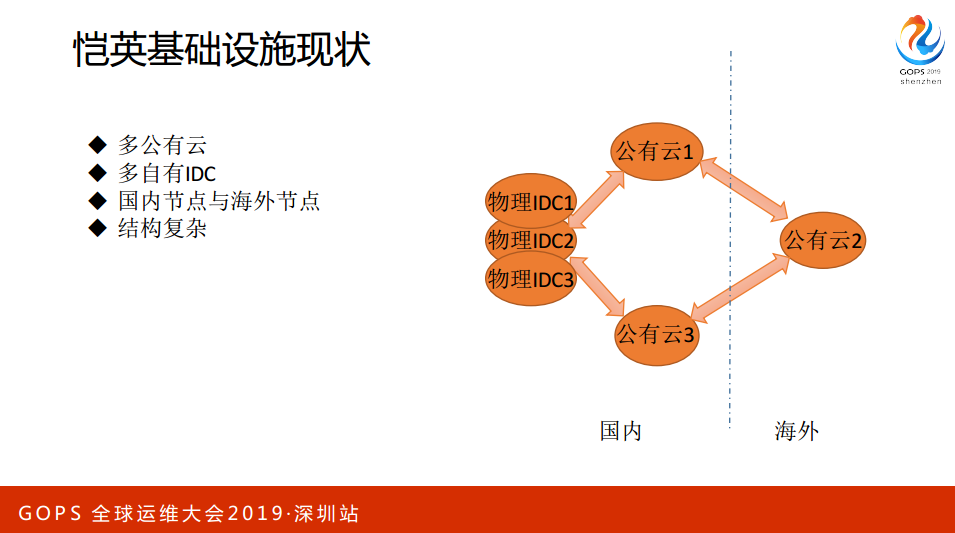
2015到2017年也经历过业务从5000单到1300万单,服务器规模从1000台到1200台的增长。这是我比较幸运的一点。之前也提到过一些历史包袱,恺英有5朵云,7家供应商。
接口非常混乱就带来一些问题:
第一,稳定性的问题。2015年还是2016年,有一个公司的年会发生故障,当时公司的兄弟坐在会场,我们的业务是中断的;
第二,2017年10月份发生过大规模的中断,我们的核心掉电了,导致业务中断8个小时。这是底层的问题,效率的问题,应用的发布、开发和资源的交付这里面的效率就很难得到保证。
第三,成本,做运维或者技术关注三个东西:稳定、效率、成本。成本这一块会存在很多的浪费和不可控。

稳定性问题怎么来体现呢?比如说我刚刚提了有“567”,6朵公有云:阿里云、Cloud、ABS、金山、腾讯云。每个人要上去创造一台VM,早先他们自己上去创建,每个人的创建习惯和操作不一样,这样会导致VM的型号或者配置都不太一样。
配置管理也是一个问题,有一个人离职了,权限怎么来管,记得来收回。操作的熟悉化等等。效率问题通过页面的操作和脚本的曾经一定没有未来,因为上万台机器,每天都有机器创建和销毁,你通过业务去操作完全不可行。

另外是成本问题,我去年在线上发现好多机器在那儿闲置着,其中有60多T的虚拟机,一个月的成本是6万块,应该闲置了有几年。这就是多少钱了?你就会发现、服务器、IP、硬盘、对象存储谁创建的?怎么创建的?资源怎么分摊?这些问题搞不清楚。

3. 多云之道
解决这些问题要有宏观的规则:
- Design for failure。其实刚才小米也提过,它整个都在云AWS上面,我经常跟云供应商来交谈。我跟他们一起开会,我说你们所有的运都不信任,一定会挂,我们一定要为失败而设计,我们人会犯错,公有云会挂,代码会出BUG,网络会出问题,这些所有的问题都会出问题,墨菲定律在那儿。
- 简单即好用。所有的东西越复杂越不可靠,一定要越简单越好。
- 目前恺英面临的问题,我们有很多的云和物理IDC,我们是否需要这么多的云和物理IDC,这些东西一定要做减法,不要做加法,举一个例子,有很多新的技术、产品和想法,我们要慎重地去评估和考量究竟要不要引入。我们有时候用好一个工具远远比用好一个工具重要。
- 只有标准化才有未来,标准化才有自动化,自动化才有平台,平台化才有数据。

我们的边界在哪里,恺英的业务分几类,有一类是游戏业务,在座不知道有没有游戏公司的,其实我之前没有游戏背景,我对游戏的理解不是很深刻。游戏里面存在着单驱单符的场景,一个VM里面有C++、PSC,全部的东西都在里面,这叫做边缘节点,因为这些东西需要供IP,它不存在很复杂的架构。
恺英还有一部分业务就是游戏平台,游戏平台其实与互联网应用没有太大的区别,本质上就是用户的登陆、交付、注册等等一系列的东西,所以说基于这些场景和大数据,基于这些场景,我想到了把它分为核心节点和边缘节点,同时通过标准化和流程把这些东西串联起来,形成自动化的平台,然后通过一种组织架构的一些建设。因为我后面会简单地讲到康威定律,我越来越深刻领悟到一切架构的设计与你组织的架构是有密切的关系。如果你组织架构上面的一些,屁股决定脑袋,只要你组织相对合理,架构就相对合理,如果你组织很混乱,架构不可能好得了。
归根结蒂还是在人方面,Chaos Menkeys,刚才小米的同学也讲到这一块。我们把云分为核心和关键节点,核心节点就是平台业务,通过点连通起来构建一个互联互通的网络。刚才有同学提问说关于网络这一块是否有做一些设计,我认为网络是有边缘的,三网分离:办公网、测试网、生产网,三网要做到物理隔离。
生产网,核心的生产网,所有的机器上没有公网IP,只有出口上有公网IP,整个公网内部是相对可信的。VPC呢?不是互联互通的,都是一个独立的整体,为什么每一个公有云都有一个VPC名?其实这个VPC名没有什么关系,便于与中心的控制节点做通信,从而管理整个公有云的一些网络和机器这些资源。
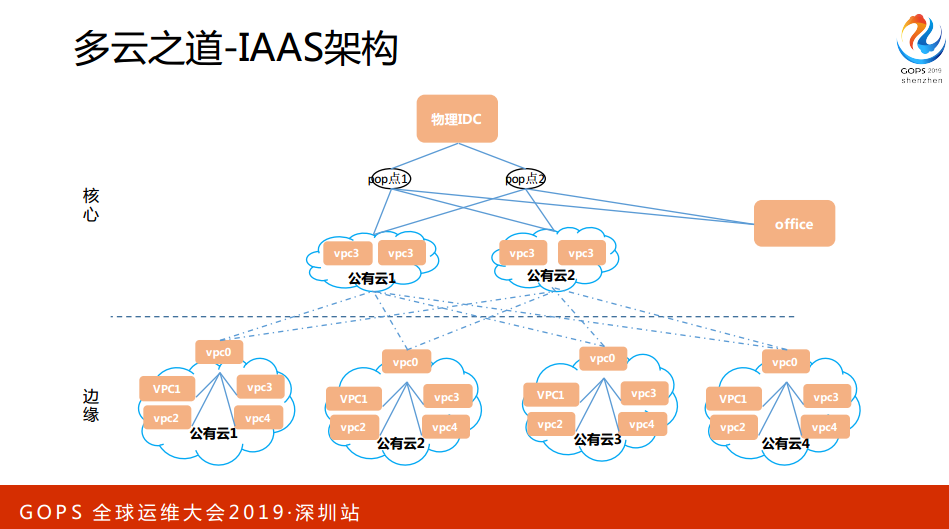
标准化怎么做?底层做起?从机房、网络、服务器资源。资源这一块称为映射表,标准化怎么做?底层做起?从机房、网络、服务器资源。
资源这一块称为映射表,在内部把恺英的服务器这一块做了一个标准,举一个例子,我服务器会有型号一、型号二、型号三,型号一就是四核8G,四核8G会同市映射到腾讯云、阿里云、Cloud等等,映射到各个云的配置,同时这个配置会形成一张表,表有一个叫Resource Gateway的资源,新增资源,对每一个资源做测试,确保性能和标准一致。
操作系统当然要一致,软件、应用。

在我的理解里面,做整个运维其实归根到底就是两件事情:
第一,资源的生命周期管理。一个资源从出生到故障、变更和回收消亡。整个过程的资源包含很多,IP是资源、网络是资源、存储是资源、域名是资源,每一个资源都需要从整体上收口。
第二,Workflow。Workflow,面向用户的编排的工具,它就是表单系统,表单系统就是计算资源、存储资源或者数据库资源等等的东西,你可以通过它来生成一个工单。

工单就是Resource Gateway,这些数据知道了Resource Gateway的一个API,收到这些信息,收信息之后去厂商创建资源,资源创建万以后就落到CMDB和服务数,保证所有的资源是收口的,并且是标准化的。
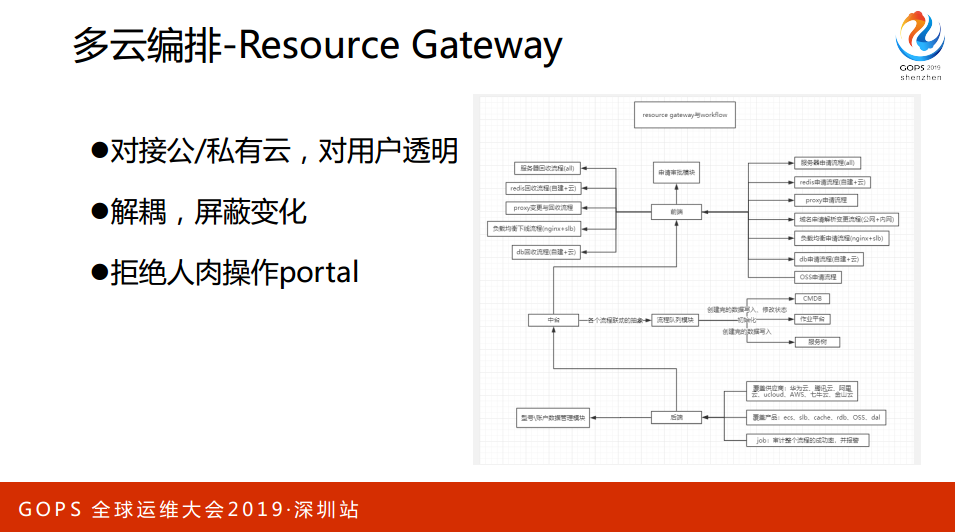
云创建之后有一个作业平台,或者说我们子一了虚拟化怎么样的,你创建一台主机完了之后会有一个叫Agent,其实Agent会通过一些plan Book创建资源的初始化。这时候会对你的系统做一些优化,包括一些检查和相关配置的一些下发等等,确保我这个机器经过做引擎之后交付过来一定是生产可用的资源。
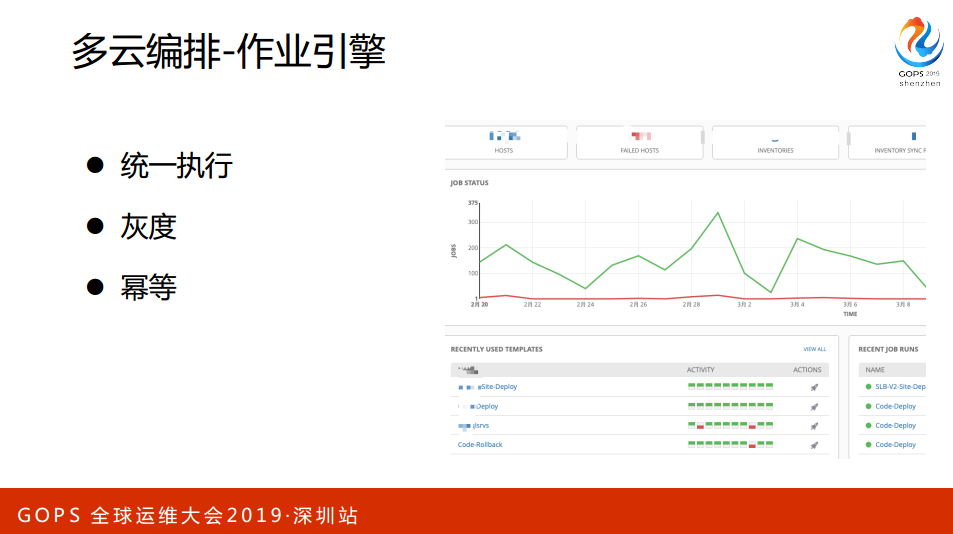
有这么多,那这个东西基本上就完了,我整个的资源,不管你是Cache、DB或者Services等等,到了这个阶段就是完全可交付的阶段。这就是工具管理里面有很多组件,这些组件主要是面向运维,还没有面向产业自助的过程。看一下,这个图看得不够细,里面主要会有一些比如说监控,像刚刚提的作业引擎,同时会把监控的Agent布上去,同时资源也会在CMDB和服务数里面注册,因为CMDM和服务数有属性,监控自动键控起来,包括上面会跑什么应用等等,整个过程不需要人来参与。
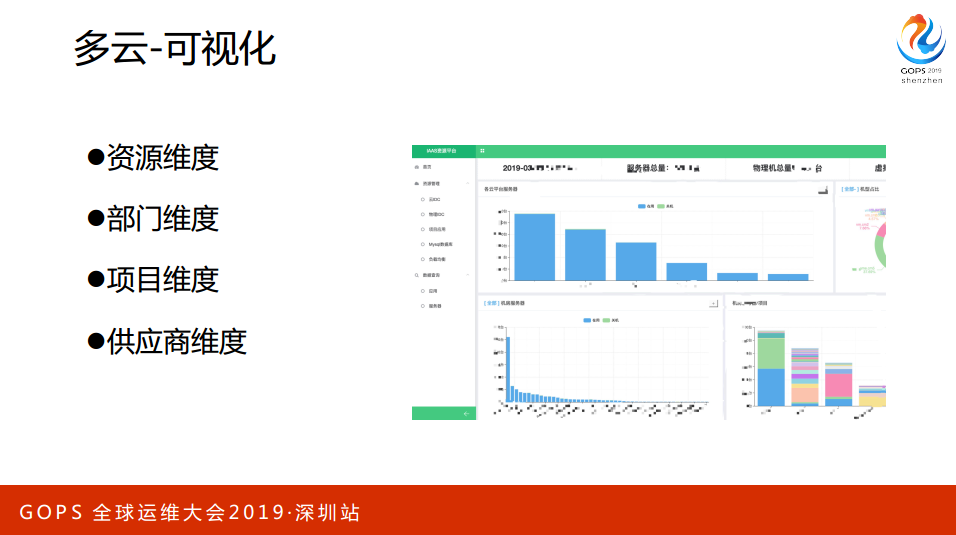
多云有很多资源:云主机、物理机、数据库、域名等等。从几个维度来看,从业务的维度看,我的业务有多少资源,从部门的维度,我部门有多少资源,从供应商,Cloud有多少资源,华为云、阿里云有多少资源。从不同的角度来看,大家会有不同的需求,同时包括成本等等的一些,都会与这个东西关联起来。
其实刚刚那些东西里面有很多的一些细节,涉及到一些特别重视的一个东西:数据。所以我专门建了一个邮件组里面每天做巡检的报表。报表做什么?对于线上的数据,CMDB、服务数、系统、监控等等去巡检一些情况,通过这些巡检,我们就能及时地发现一些代码的BUG或者之前没有考虑的问题,不断FIX它,让它逐步收敛到我们所期望的状态,一定是要先收口再来治理,同时就是一些细节,一点点去扣,一点点治理下去。

容量与成本这一块,我这边没有放图是因为正在做,还没有做成。成本这样的东西在一个公司高速增长的阶段是不漂亮的,我之前在饿了吗?两年花了10个亿,那时候是高速增长,公司发展到一定的阶段或者平稳期,公司一定会要求大家来挤水分,挤水分,花钱大家都很开心,省钱大家都很不开心。我给某个业务说扩张100台、1000台机器,如果你说减1000台,他说出了问题怎么办?你负责吗?这时候一定要通过一些数据,除了上帝,一切人都要通过数据说话。
关于利用率这一块有一些平时认知的错误,很多人认为CPU利用率到50%还不合格,到80%才行。整体而言,全球之前跟很多公司,包括与百度与腾讯的哥们儿了解过,像搜索引擎这一块平均的利用率达到40%,一般交易系统的利用率达到20%都谢天谢地了,也不是平均利用率,就是相对而言整体偏峰值,一般在10%以下,这里面有很大的水分和空间,到50%的时候也有很大的容量。随着Response Time是否有提升,通过全链路的压测等等手段来实现。
成本这一块,我把成本核算到每一个部门和应用,同时会算在那里花多少钱,每个月和每天花多少钱,我目前在恺英这边还没有实现,我之前在前面的公司其实已经实现了。我会每个月给管理层发一份报表,排在第一个,谁的利润率最低同时成本最高,团队老板收到这个信息肯定会有压力。同时,会把成本与数据关联起来做一个计算,给到用户,哪个用户会有缩容的空间,但是我会帮他缩容。因为我可能不太深刻理解应用,因为应用可能下个月有大促,我这个应用刚上线,接下来会有推广。宏观上给你一个数据,给你这边来做支撑,同时给整个红黑榜来给老板自上到下的压力,这让整个数据可行,同时,你这边推销了多少数据或者消耗了多少资源,我这边都有纪录。

应用这一块,我这边展开可能不是特别多,主要是关注在CACD通过整个的Jenkins或者自己包的一套垂直发布的系统来实现研发自发的发布。运维,包括携程很多公司都是研发自助式服务,运维不太会参与整个发布的过程。大的互联网公司每天目前几百几千次变更,很正常,我认为让运维来做早就过时了。关键是一键回轨,所有的发布灰度要做到一键回轨,除了问题两分钟回轨没有问题,通过人效团队可以基于这个质量判断一个团队的发布指数、回滚指数,回滚的比例相对偏高是有问题的,通过这样的方式。配置管理,配置管理其实是形成开源的一套管理,我们也在使用,基于这一点,因为恺英这一块目前还没有实现容器化,我做的阿波罗都是为容器化打基础。所以这一块可能处于初步的阶段。
4. 挑战与应对
刚刚提的是多云的一些东西。接下来会重点给大家谈一下做这些东西是不是就够了,其实还有问题。业务与技术这一块始终有很多的博弈,我长期是作后台技术的,我认为技术非常非常重要,但是最近这几年的经历,我发现其实老板更看重的是业务。如果你站在CEO的角度来看,包括我上次看到一个GE还是的公司开会,最终说你们公司的CIO到了吗?CIO需要来吗?其实大家站在业务的角度,技术只是一个支撑的作用,这个时候不会去在意技术不断重构的需求,或者不断有稳定性的需求,业务看的是我要上新的应用,我要变更,我要快速迭代,快速开发,稳定性的问题是你们要快速搞定的,但是实际是什么样的呢?
相当于一个车,我其实是想找一架飞机的,但是实在找不到,我找了一辆奔驰车。车在开要换轮子和发动机,跑得慢了还要被业务骂。CTO这个角色,很多公司的CTO其实挺惨,偏向于大中台,很多东西不碰业务,很多公司的CTO管运维、安全、大数据、架构、中间件的,管这一摊偏向于业务支撑的体系,不怎么碰业务了。在这个过程中,业务的整个需求与后端的需求其实是有些冲突的。在这个过程中就会碰到很多的挑战,包括业务一直在奔跑,故障随时会发生,在这个过程中会做很多的技术负债。

康威定律和技术站,康威定律,我刚才听小米同学的演讲,前天头条的朋友跟我聊,我有一个深刻的体会,一个产品或一个应用为什么能发生?归地到底与公司的组织架构有关系,公司的组织架构决定了技术体系的架构甚至于产品的架构,为什么有一些产品的诞生?因为有组织的诞生。组织一定是分层次和团队的,每个团队有自己的核心利益,每个团队相对而言就是局部作用,比如说负责运维的,运维按道理要做到最好是怎么样的,不准变更,一个月或者一个星期变更一次,不准扩容,或者上线什么业务要通知我,这样运维可以保证不出问题。但是业务就活不了,也许业务老板正在谈一轮融资,正在准备IPO上市,业务没有十倍和百倍的增长,公司就死掉了。所以一定要从全局来看,我们做技术有时候也要跳出技术的领域站在老板的角度或者更高的角度来看问题。为了全局,局部要做一些妥协。
边际成本和边际收益。做技术的人,很多人都是完美主义者,我要把技术做得很牛,我要把产品逐步迭代达到一个很理想的状态。其实学过经济学的人会发现一个问题,一个叫“边际”的概念。你考试的时候从30分到60分随便弄弄就可以了,从60分到90分要努力,再从90分到100分不容易,你的边际成本是递增了,边际收益就递减了,有一个“二八原则”,不一定解决100%的问题,要解决80%的。
前几年,我在公司有一点技术洁癖,我会跟老板吵架,要资源来做这件事情,其实技术债一定要有,技术债务有杠杆就能很好撬动业务。关键在于什么?代码的重复和架构的更新是不是要继续,说白了就是利息是否还得上,利息还得上,这个债就不会导致整个资金链的断裂,这其实没有问题。举一个例子,比如说我们的网站发生了什么很严重的故障,导致整个网站宕机。你作为CTO,你去跟老板谈,现在技术难度很大,可能三五个月把网站关掉,你看哪个老板会同意?如果你跟老板说,保障业务的同时,做重构和业务更新,老板说,你去弄吧。
阿里云前不久故障一次,腾讯云故障两次,今年以来,我们所依赖的云都故障很多次。所谓的依赖一定是不靠谱的,所以一定不能有单点,不能把自己的身家性命寄托在别人的手里。我随便搜了一些宕机的案例就出来了,宕机一定会发生的,所以要做一些事情。

防御性编程其实说白了有很多的东西,比如说我们的业务一定要有主路径,关键路径与非关键路径区分,主路径怎么理解?不可降级。比如说整个交易环节的下单、支付不可降级,但是有些环节可以降级,比如说风控,如果说风控出现问题,一定是配置中心下的一个Paas,把配置降级掉。
限流。一些活动的时候从入口到里面都需要都一些限流。
熔断,熔断与降级归根结底就是一千一后,降级就是大促有业务的时候先期把消耗路径的资源降掉。熔断无非就是在业务层有一些防御措施,比如说多层请求之后就不再请求。真正发生问题之后,在数据库层面有一些补偿和业务机制,特别是一些公司做了双活,会发生数据脏掉,这一定要有补偿机制。依赖和被依赖,依赖,我之前有很深刻的一个痛苦是什么呢?主路径做了很多的优化,最终没有问题,我被一个非主路径给拖死了。那时候是注册还是什么?其实有一个上传图片,上传到阿里云去,那天不知道是网络还是阿里云故障,导致存储故障了。相当于关键路径依赖了非关键路径导致整个服务的不可用。

监控和告警。这个东西说到底,旗帜我看这几天的会议专门把监控与告警拉出来,监控本身不难,不管是普罗米修斯等等技术已经很成熟了,关于在于告警。告警这一块还有很多路在走,现在很多人提AIOPS,AIOPS在运维领域有两个地方可以用:一是监控;二是海量成本和机型的分析这一块。因为阿里的服务器是百万级别,他们是有在用这样的事情。告警这一块其实也有很多公司在尝试,我们也还是在路上,只是做一些简单告警的一些收敛等等,还做不到告警的智能化判断。

Chaos monkey与SOP,我基本上每周每个月会做一些故障演练,比如说把某个业务,目前业务级别基本上是大类业务,一个业务有很多的应用,APID,你可以一组APP之间集成做一些跨机房的一些演练。一个业务一个业务的演练,演练完以后,有一天突然想到运维平台,整个演练涉及到很多运维工具的切换,包括DC切换和数据切换等等,这些东西都是基于运维平台的,那我的AIOPS本身工具平台是不是有演练。我本身做了很多的优廉,UPN-SSN的单点登陆到服务器管理,到CICD,甚至到切换的,这些东西都要做到长期的演练。做这种Monkey这种事情,关键问题在于什么?
通过做这件事情形成一个SOP。假设实现了什么操作,举一个例子,我把一堆机器给杀掉,这时候监控系统一定要有所体现。我监测监控系统的有效性问题,当监控系统收到什么信号以后应该执行什么操作,不要做现场的定位或者什么,一定是不经思考,就像我喜欢打乒乓球,打乒乓球要形成一个肌肉记忆,看到什么现象就实现什么样的效果。一定要形成一个可行的不经思考的基于某种现象或者执行某种结果的可执行的行动。这个东西才是真正的SOP。

那安全这一块为什么要提呢?我过年其实被上海市网信办的人叫过去喝茶了,为什么呢?他说每年都会有中国的整个管制,对于安全的需求越来越高,拥有大量数据的企业会对你做很多的安全测试、扫描等等的,甚至会有一些所谓的白帽子等等一些人来去探视你。所以这个时候一定要深刻理解安全。
因为现在新的《网络安全法》,不知道大家是否有接触。上次网信办的人给我普法,现在的法律要求如果真的出了要求,不是公司承担,相关人(法人、技术负责人)都要承担,他说你们再这么搞,赶紧跑到加拿大去。加拿大与中国没有引渡协议,说白了大家要在安全注意,安全就是边界和治理。

故障复盘和改进。故障发生之前要做的,聪明的人一定看别人跌倒了,自己不一跌倒;一般的人是自己跌倒,爬起来不再跌倒;愚蠢的人一二再再而三地跌倒。我们一定要查找根因是什么?是流程的问题,技术的问题还是什么问题。人肯定是会犯错,不能说出了问题,这个人操作不行,旁边找一个人看这或者找个人来签字。这种东西不靠谱,一定要通过技术手段或者流程来解决,相信人会犯错,但是每个人都不是主观犯错的。整体来说,一个技术团队的组建很重要就是积累,每一次的积累,文档或者工程师文化的培养,这是非常重要的,一定要培养工程师的问题。

5. 一点心得
Code,未来的云都是基础设施水电,有东西做IS或者Paas的人会越来越少。我认为未来也不会有什么OPS与DEV的差异。我一直是做技术的,做技术的人相对而言会重视数据,拿数据出来说话。比方说这个业务跑得有点不好,什么叫好,什么叫不好,一切东西都要可量化,不量化的东西都是耍流氓。Design for failure,康威定律,还是回到人的架构,组织架构要结构化,权责要明晰,边界要清晰,中间的边界要比较少,否则这个过程要不断抽象迭代,确实比较麻烦。

最后一句话送给大家“未长夜痛哭者,不足以语人生”。在你经历过痛彻心肺,旁边是华为的图,“所有光鲜亮丽的背后一定是苦难”。

