@gaoxiaoyunwei2017
2017-11-09T01:43:11.000000Z
字数 3952
阅读 1606
千万QPS分布式系统设计及高效运维之路
wt
简介
我一直从事后台的海量分布式的数据存储系统的设计、研发及运维。早期在微软,刚开始的时候在 SQL Server;后来转到OSD。OSD是搜索引擎和在线数字网络库,主要是支撑微软的整个数字广告系统。这个系统的要求很高;5毫秒响应响应时间,单机的QPS要达十万以上。后来就去了twitter。
形形色色的数据库
twitter整体存储架构有如下四套系统:
NoSql,主要包括用户信息、比较小的数字;当时大约有三万多节点。
大文件系统,主要是存储图片、video等大数据文件。与NoSql同样,也有三万多个节点。
Hadoop系统,主要用于后台数据处理、分析;最多的时候有九千个节点左右。
MySQL,简单、有利于查询。
各种数据库的CAP
说到数据库,不得不说的就是CAP。CAP是什么呢?C就是一致性。A是可用性。P就是分区容错性。Eric Brewer证明了在CAP三个诉求中,你只能满足两个;永远做不到三个。所以你做数据库设计的时候就要考虑应用场景是什么;牺牲那个特性来取得另一外两个特性。事实上所有的数据库,包括现在新兴的数据库都遵从这个CAP原则。它们针对某个应用场景做优化,没有一个大而统什么都能用的系统。
下面是不同类型数据库对CAP的抉择:

关系型数据库,主要应用于交易系统;例如银行系统。因此它是强一致性的;放弃了A。
NoSql的好处在于它的高并发,能够支撑很高的并发数;但是一致性稍差,是最终一致的。

NewSQL,号称能够同时满足CAP三个;但是每次只能做到两个,能够采取一些措施足够包容这个网络的问题。但是理论上还是 不能突破CAP。
特殊用途的数据库;例如时间序列型的OpenTSDB,文档型的mongoDB以及图数据库Neo4j等。
Manhattan的前世今生

Twitter最早用的是Cassandra。早期cassandra没有虚拟节点导致不能部分的扩容;现在的Cassandra已经可以了。第二个就是Cassandra用的是gossip协议。gossip协议不能够有效的让分布式系统保持一致性,存在一定程度不一致的问题。

在以上问题的驱动下,twitter研发了自己的NoSql也就是manhattan系统。manhattan设计实现主要关注的要素如下:
可靠性;
可用性;
可操作性;
低延时;
高效;
manhattan分布式实时海量数据库目前有三万多个节点,每个节点可以支撑上万QPS;P99延时为10毫秒。
Manhattan设计之存储引擎
首先,做一个One Size Fit All系统是肯定不可能的。所以我们当时特意做了模块化设计;后面的存储结点和存储引擎是可以接插的,可以根据不同的需求来定制数据系统。因此,我们的后台有下面三类常见数据引擎和一些专门用途的引擎。

常见数据引擎
SeaDB是只读优化。因为我们有很多用户;尤其是广告客户,他们是定期往上面更新数据的。这个时候很适合做批量更新,但是前端是只读的。
SSTable针对写优化的存储引擎。与google的bigtable机制是类似的,它对写是非常高效的。
RMDBS传统的关系数据库系统。有很多用户是同时读写的,同时对读是很在意的。此时RMDBS是可以进行index又可以实时的update。
专门用途的引擎主要是从以下三个方面进行优化的措施:
强一致性;
时间序列服务;
二级索引;
Manhattan设计之架构
Manhattan整体架构分为四部分;分别是调度、读、写以及一致性协调。
Cordinator调度模块,它的主要功能是对请求打包,然后根据不同key将其分散到不同的后台节点上;最终将节点的响应重新组装返回给请求方。MemTable是在内存中的,index的查询速度非常快;bloom filter提供一些辅助的效应。对于有很多用户请求进来时,这时可以限制它们。
读请求,对于SSTable这种架构的存储;读的代价时非常高的。因为它要读很多很多SSTable。当然我们有很多措施可以对其进行优化。第一就是定期将小的合并成大的SSTable。第二我们有两级索引;一级驻内存,另外一级在磁盘中,这样能保证我们的加速。
写过程实际上是直接写到内存里的,commitlog是非常快的;所以写的效率很高,基本上可以看作是写到内存里的。
Reconciliation就是最终把所有写入的数据复制;通过这种job对它进行传播保证它有同样的数据。同时,reconciliation有个定期的工作就是扫所有的文件;然后把文件的不一致进行整合达到最终一致性。
海量系统高效运维实战

Twitter数据量非常大;大家都知道这个请求是有叫做放大特性的。例如前端要调用一个,后端可能有几百个调用。我们最大的集群每秒有两三千万请求,线上有十几个这样的集群;所以运维这样的系统非常痛苦。曾经有个很极端的例子,有一个SRE经过一段时间煎熬,白天突然在办公室昏倒。后面我们在运维方面做了一些改进。分别从组织架构、流程、工具三个方面来提高系统运营的效率。
海量运维-组织架构

大家可能知道,常见的研发写了一些code;结果运维出问题了。代码也不知道干什么的,半夜三更被叫起来,气得要死;然后找研发。研发说你这个都不懂还来当运维。于是无法调和的矛盾就这样产生了。所以靠人是不行的;最有效的是组织架构,有了这个所有的问题引刃而解。为什么这么说?研发参与运维和运维全部打成一块。这时候你写个烂代码,你半夜三更被叫起来。或者你写了一个不必要的报警,你的同事被叫起来,第二天是要被臭骂一顿的。
服务上线交给运维之前,研发必须自己运维自己的功能模块一个月。通过一个月的产品磨合,最后再进行培训和交割。东西要交给大家做的时候,必须要有一个所谓的training。
海量运维-流程

所有人都需要上岗运维,但是需要一个很好的流程。首先培训,新人来了以后;老人开一到三次的讲座,介绍产品,介绍运维经验。然后就是所谓的Shadow Others,当资深运维在处理问题时你在他旁边看着。还有一个就是Shadow by Others,当你觉得你学会了就可以尝试来处理问题了。所有这些都通过了,你就可以独立上岗了。
在项目交付流程中,运维在项目早期一定要参与研发设计。如果运维要signoff;但是韵味不能signoff,研发不能算完成的。研发在设计之中有两个比较的重要的 work items 必须要有。第一个时运维指标,哪些运维指标要好是干什么的。第二个就是告警,这些都是 要通过大家讨论的。
还有的就是操作手册。一定要有服务或者功能模块很完整的操作手册。最后在上线之前有个预上线的会议,基本上研发线、运维线的各个部门包括安全都来对着文档看看。
海量运维-工具
运维人员除了日常的排班他们还干什么?开发一些有用的运维工具。我们有几个工具帮助我们极大的降低了运维的成本。

- Self Service,以前运维的服务80%是内部团队的;有很多内部服务我们花了很长时间在上面。所以我们设计了一个Self Service UI,极大的降低了沟通成本。只有10%很特殊的服务或者很重要的服务,我们会跟他们沟通处理。这里最重要的就是调试工具。因为大家服务上线了,有了调试工具的UI就非常方便了,写一个Key-Value非常方便。

- 部署,需要各种不同的环境,测试环境、生产环境等。对于数据服务来说,需要注意canary两个节点不能在一个replication set上。部署的回滚能力特别重要。凡是不涉及到任何数据格式变化的变动一般来说都没有什么大问题。但是,一旦涉及到数据尤其是数据的格式的改动就要非常小心;数据格式变动后就没有办法回滚了。所以部署一定是分两步的。第一步,先把新的代码部署上去,新的格式不要变;新的代码能够处理好新的数据格式。第二部,升级一下,新的数据格式就进来了,这样就不怕了。

- Topology Transition,当需要在线的扩容或这嫁接节点的时候;我们需要有个所谓的状态驱动来保证数据的一致性和统一性不受影响。当时老的方法痛苦在于开始以后在90%的时候停了,我都得重来。这个对于SRE来说是非常痛苦的。
运维的挑战与机遇
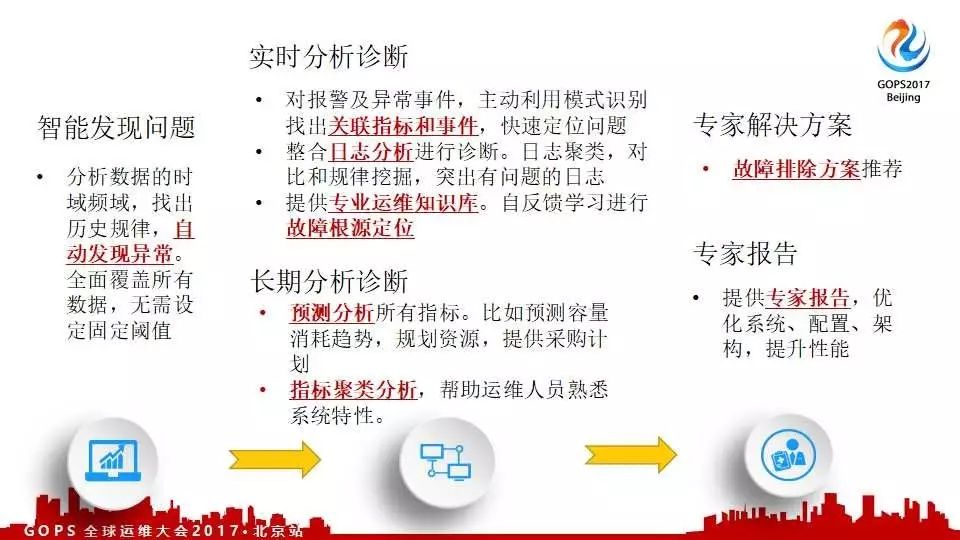
在twitter做了这么多,其实还是有很多问题的。例如,故障排除高度手工化。因为twitter所有的服务加起来总共超过10亿。一旦出问题,排查起来就是一件很痛苦的事情。对于这么多指标,哪些有问题、哪些没问题;人是很难判断的。但是机器可以通过对比历史数据并分析是可以做到异常自动发现的。
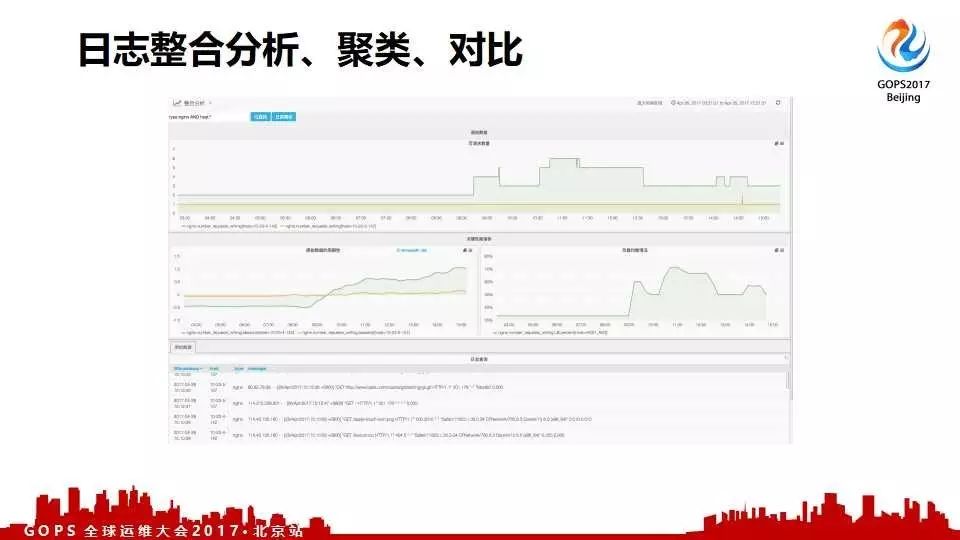
大家可能有经验,前端出问题往往是由于后端导致的。怎么将前后端关联起来,这个机器是完全可以做的;这样一来就可以节省很多人工的时间。很多时候知道到服务指标不正常可能还不够,这时需要查看日志。查看日志有很头大,要对比时间;为此我们做了日志分析和整合的系统。下图是日志的整合、聚类对比的结果。
智能运维案例分析
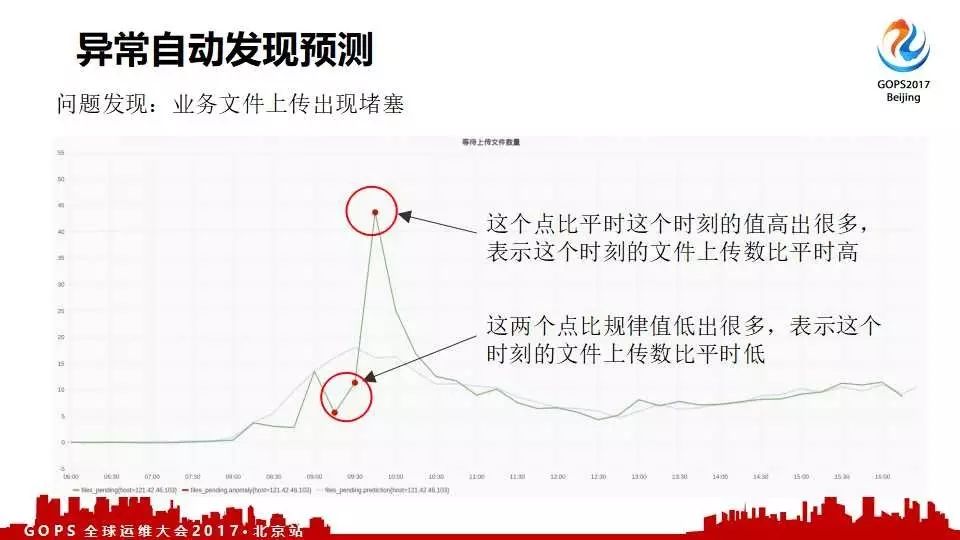
这是一个央企看客户,他们业务上传经常出现阻塞;这个点是机器自动标识出来的。通过机器标识可以建立很灵活的报警规则。
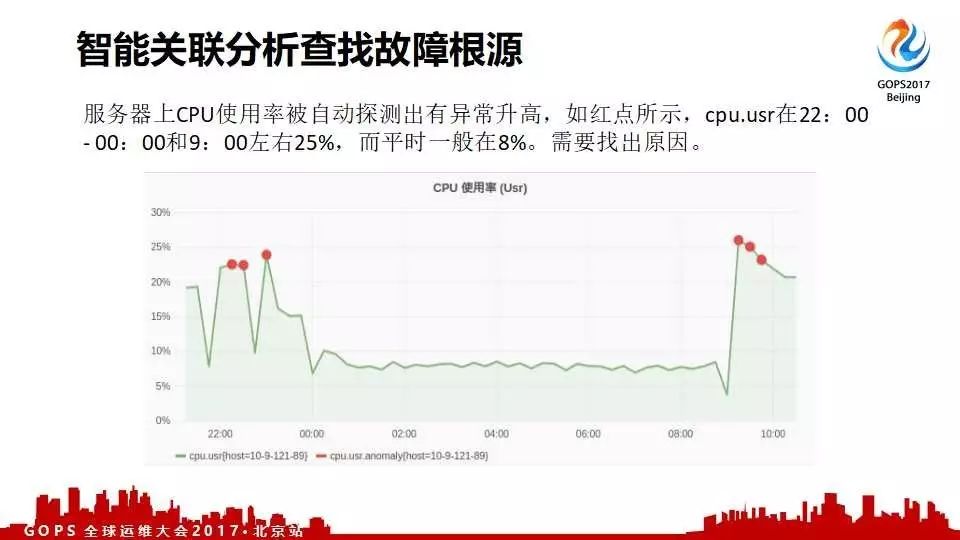
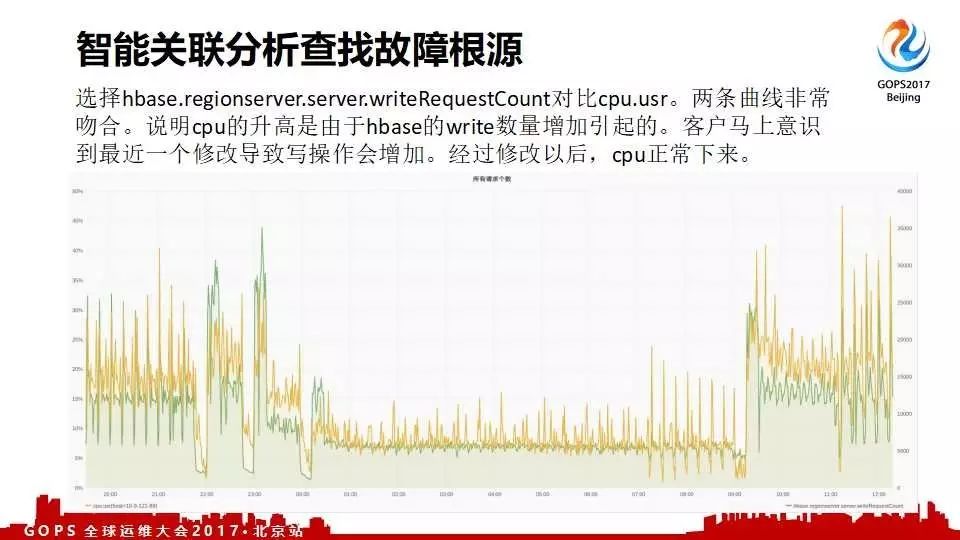
另外一个客户CDN突然飙高,不知道什么原因;通过智能关联排查故障根源工具发现这个是一个hbase写也增加了。经过这个推荐给客户,客户很快知道了是由于一个配置修改造成的问题。
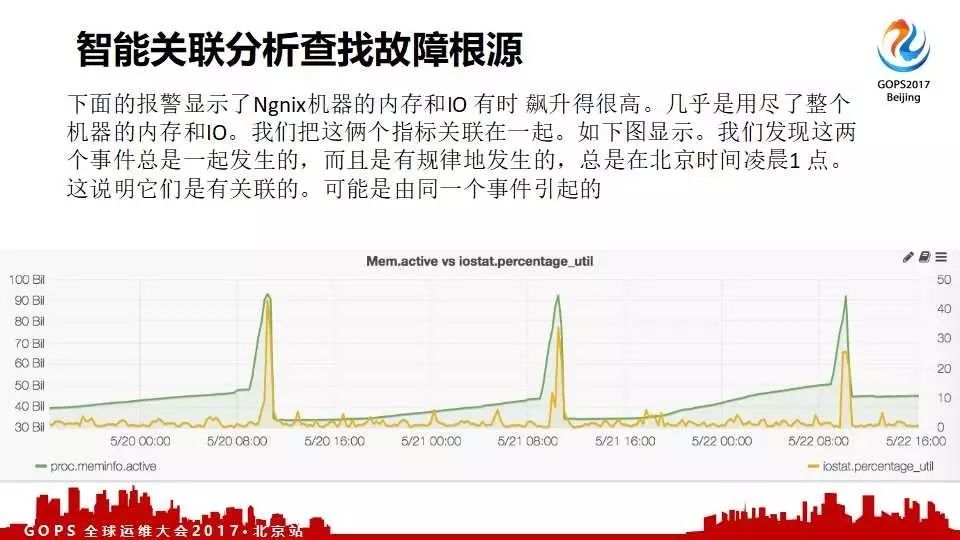
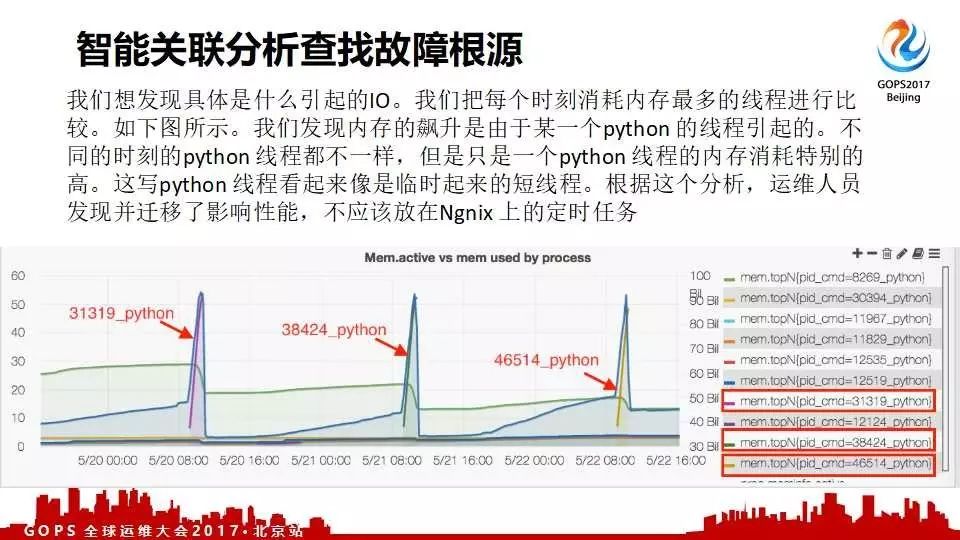
这是另外一个客户,非常重要的门户服务器经常出现飙高;但却一直不知道什么原因。后来通过我们的工具自动找出了问题;找出进程,包括甚至用什么语言写的。后来发现是他们的SRE写的一个脚本,扔在那儿忘了;但是每周、每天都在跑,导致他们服务受影响。

我们做这套东西非对故障诊断有非常大的帮助。这也是我们建立这个智能管理整个一站式解决方案的原因。最后一个智能知识库是把大家的运维知识不断积累放在里面;最后就是一个机器大脑,随时可以查询,相当于一个运维的知乎。
