@gaoxiaoyunwei2017
2018-02-11T02:54:39.000000Z
字数 7623
阅读 1298
虢国飞-饿了么异地双活数据库实战
刘策
我今天分享是饿了么在数据库和多活数据库这块的实战经历,供大家参考。
主要分享以下五点:
1、多活当中的难点
2、多活的架构
3、数据库改造
4、DBA 挑战
5、收益与展望
一、多活当中的难点
我们先来看一下多活的第一个难点:要考虑做多活到底是同城的多活还是异地的多活,跨地域网络延时是现阶段很难突破的点,因为饿了么面临的是异地的多活,所以我们需要基于延时这个前提来考虑方案。
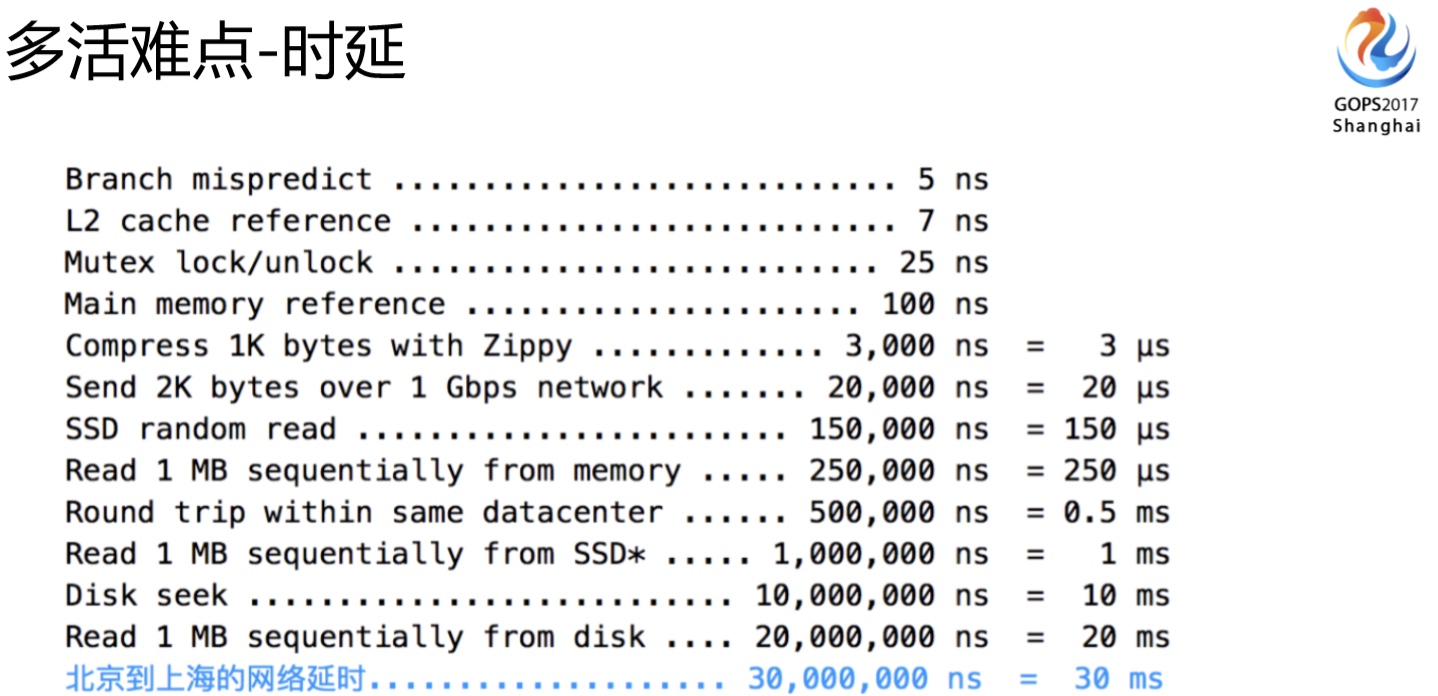
从北京到上海中间有30毫秒的延迟,这个会带来什么问题?我们接下来会讲。
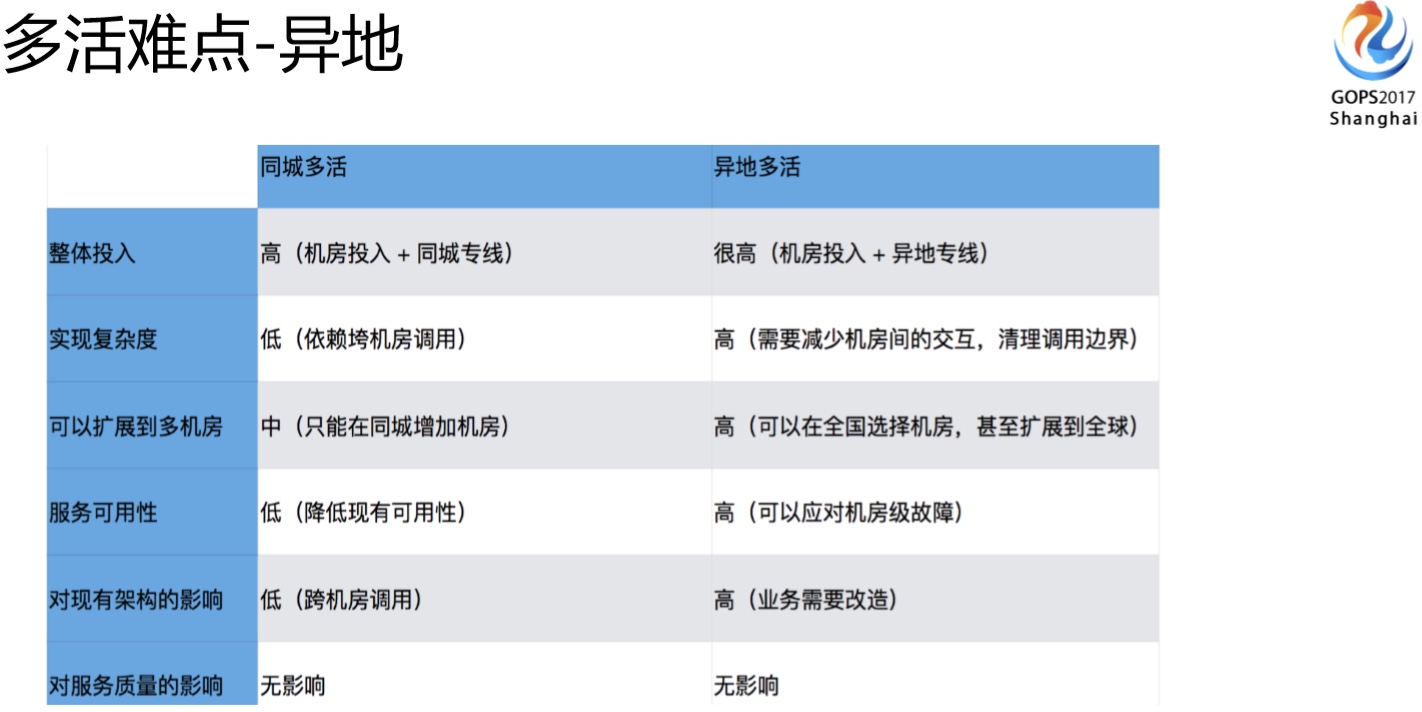
上图是同城和异地多活不同的点,复杂性和可拓展性对架构的影响方面会有很大的不同。
我们挑几个点讲一下:
1、如果只是做同城多活的话,像30毫秒的延时不需要考虑,因为同城的延时通常只有几毫秒,跟同机房差不大。
2、如果是异地30毫秒的延时就需要重点考虑了,因为如果是反复调用的应用,放大的时间就不只是30毫秒了,可能是300毫秒、500毫秒,对很多应用来说是不可接受的。
在可扩展性方面如果做的是异地多活的话,你的可扩展性理论上来说没有太多的边界。我们做同城多活只能在上海机房里面选,如果是异地多活,可能是全国甚至是全球都可以选。

还有一个比较难的问题,就是怎么保证数据的安全。多活数据可能面临多个写入点,可能会错乱、会冲突、循环复制、数据环路等问题,这种情况下怎么保障一致性。如果这些没有考虑好之前,你是不能上多活方案的,多点写入的风险对数据的考验是很大的。
综合考虑下来我们选择了异地多活,所以这些问题我们都需要克服,也意味着会面临很多的改造。

如何解决跨机房延时对业务的影响,包括各种抖动甚至是断网的问题。怎样有效区分我们访问的流量,最大限度地保障用户的访问落在正确的机房,这个都是需要解决的难点。
我们采取了一些措施:
1、尽量把业务做成类聚的,让一个用户的访问落在同一个地方。
2、不是所有的业务都有多活特性的,还可以有全局使用的业务(比方用户数据),所以需要做业务类型划分。

在服务划分这一层怎么定义业务调用的边界,还有我们基于什么对流量和用户做划分的呢,目前根据我们的业务特点使用的是地理围栏(POI),用户、商户、骑手当前所在的地理位置是我们入口流量划分的依据。
再看看路由控制这一块,除了入口流量这一层做了机房的划分,还在内部使用了虚拟的Shardingkey,ShardingKey会把全国流量分成多个部分,并且与POI标签绑定,这样就可以把逻辑ShardingKey和物理位置对应起来,切换的时候访问就可以随ShardingKey分流到不同的机房。APIRouter就是为了完成这个工作的,它会根据配置的规则把Shardingkey对应的流量分到对应的机房。
脏写预防方面,为防止数据冲突,我们也需要业务配合做一些多活规则的改造,这些规则对业务还是有一些侵入性的。另外SOA-Route就是内部跨业务调用的访问路由。还有一个DAL,就是数据库的代理层。业务访问在我们多层的路由控制下,理论上应该能正确路由到合适的机房,如果超越规则或者没有按规则改造的意外流量真正穿透到DAL这一层的时候我们是强制拒绝的,因为底层认为这个访问是属于异常的调用,流量走错了机房,这时候就会拒绝。所以我们宁愿让他失败也不能让控制之外的数据进来,这样才能保障规则和数据的可控性。
数据一致性方面我们有一个重要的DRC数据同步组件,数据库这块有一些自增的控制,DBA还研发了一个数据一致性校验的工具(后面会介绍)。
二、多活的架构
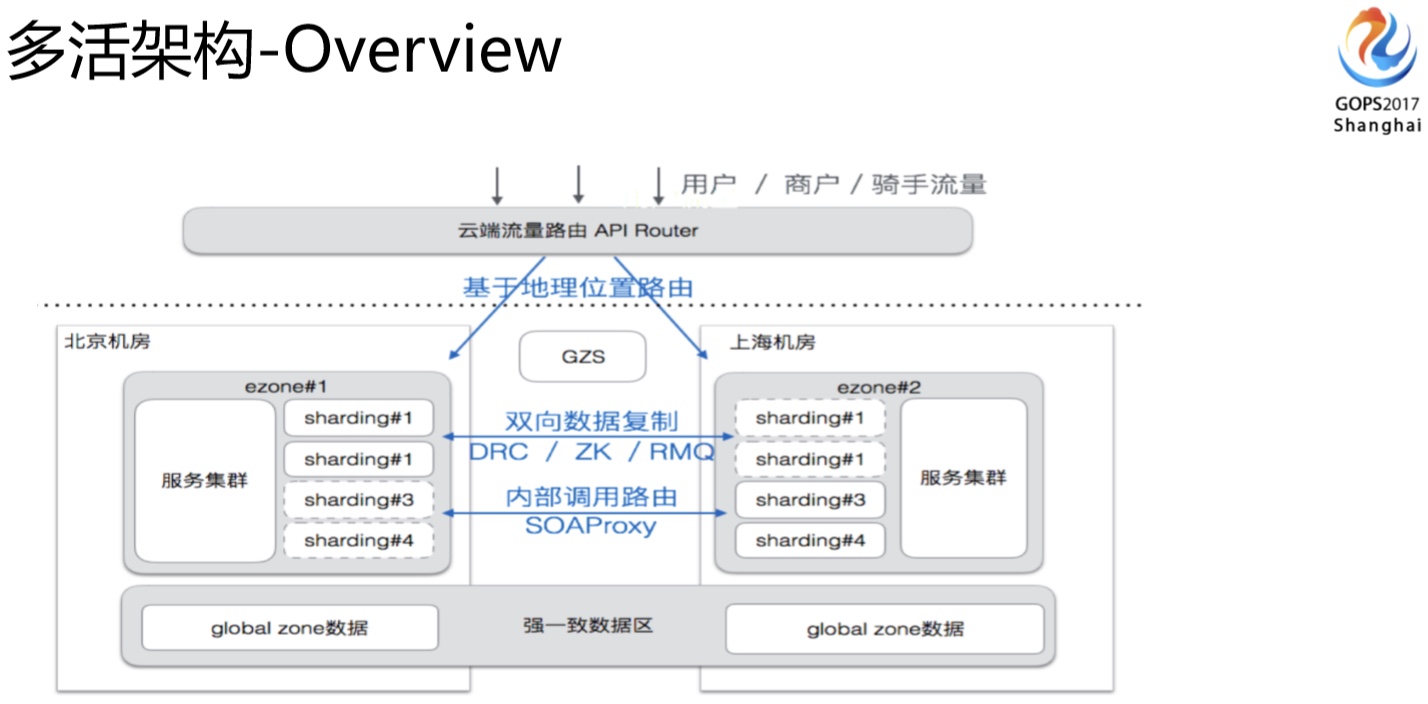
粗略过了多活的一些难点和我们的应对方案后,我们现在来看一下整个多活的架构。这个上面是我们从入口流量、分流控制、数据多机房同步,包括各个重要组件的架构等。还有里面有globol zone这一项,它是我们刚刚讲的需要全局依赖的业务会把它放在globol zone里面。
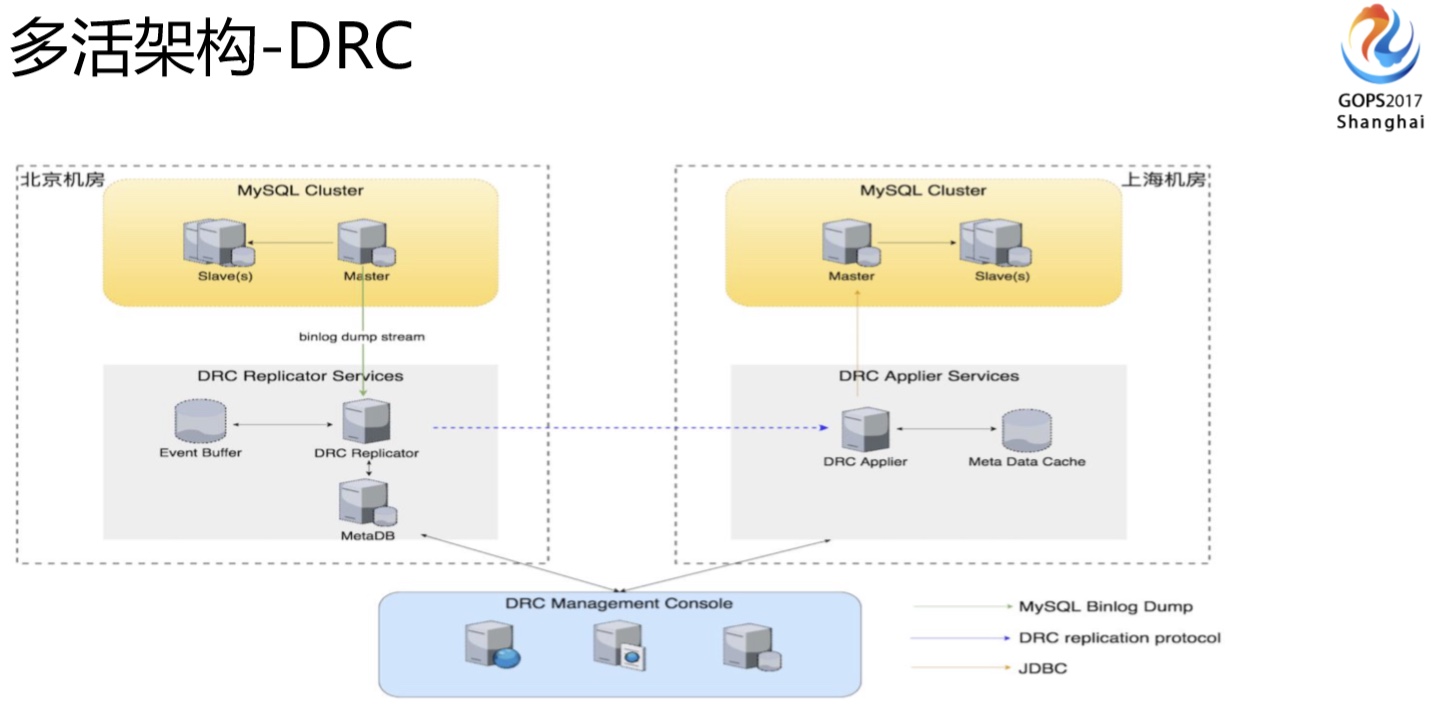
DRC这是做多活时相当重要的组件,主要解决数据在多个机房当中的同步复制。我们从北京机房写入的数据,会同步到上海的机房。上海的机房写入的数据也会通过DRC这个组件同步到北京的机房。大家可以看它其实包含三块服务,Replicator、Applier和Manager,一个收集变更数据、一个将变更数据写入到另一个机房,另外一个是做管理控制。
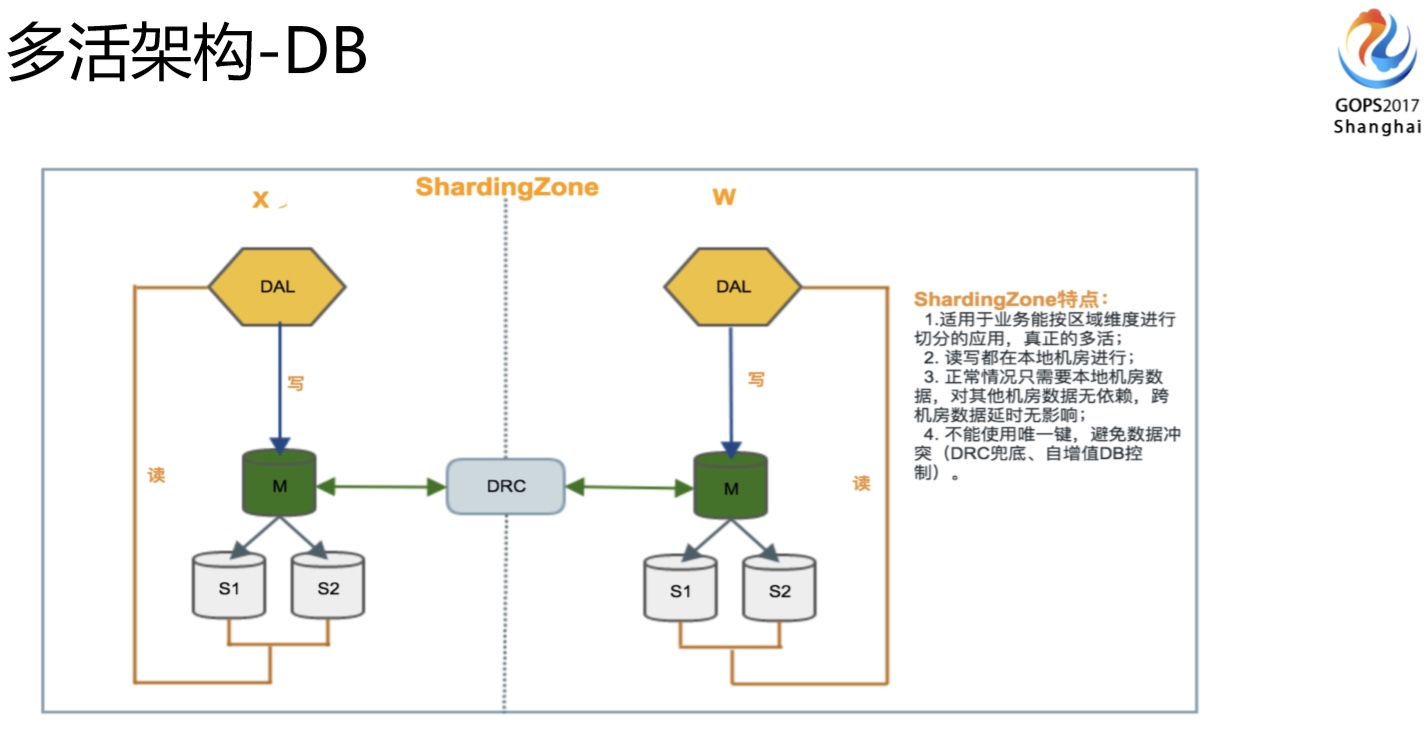
DB架构这块我们有两类(准确讲还有一类是多推的,比较少),第一类是ShardingZone,不管是数据写入还是访问都是本机房提供,出问题的时候也只是流量的切换,并不涉及到底层的变动,这个是真正多活的架构。还有一种是刚刚讲的,有些没有办法做业务分区的,是globolZone的架构,写是集中在一个机房,读在本地机房完成。大家可能会想到globalzone这种架构会天然面临一些刚刚讲的数据延迟的问题,所以这块我们的定义是一些写入量不大,访问量大,对数据延时是不那么敏感的业务就可以放到这里面来。
三、数据库改造
多活项目我们调研大概花的时间有半年左右,但真正做改造的时候时间是相当短的。从启动这个项目到真正上线就用了三个月左右的时间。那时候时间是相当紧的,大家可以看一下我列举大的为配合多活数据库所做的改造项目。

首先面临的问题,就是我们要把数据全量的从一个机房导入到另外一个机房,这个不光有测试环境还有生产环境都要全量的同步。我们数据有几百T数据,几百套集群,有各种主从结构需要搭建需要去搭起来,每个节点时间也很短。
我们刚刚讲的DRC会做数据的同步,但同步的时候也会面临数据冲突的问题,为解决这个问题我们需要在所有表上增加一个DRC时间戳字段,用来判断哪一边数据是最新的,这样在数据发生冲突的时候,我们会选最新的数据作为最终的数据。
为防止多活主键冲突,数据库做了一些自增的调整,自增步长放大后马上就会面临数据溢出的问题,所以我们需要把主键都从int调整为bigint。主键改完以后还有一些外键依赖的也会需要改造,所以整体会要做很多的DDL(几乎是全量表),而在MySQL里面DDL其实是风险比较高的操作。
第二个大改造是因为区分了不同的业务类型(我们刚刚讲了有goloblZone这些),就会面临各种不同类型的业务原来在同一套实例上的,现在需要拆分迁移到不同的实例上,这个我们也陆陆续续迁移50+的DB,现在还在有些在迁移。
下一个改造是我们现在用DRC做跨机房的数据同步了,所有的数据同步都是原生的改成DRC的模式,也会做很多的调整。
还有一个问题,就是帐号网段也需要做调整,因为我们原来基于安全考虑会限制某些IP网段,现在网段范围放大了,所有帐号都要面临调整网段的问题,如果量比较多的话,调整账号风险还是挺高的(很多历史遗漏会使得主从账号不一致,同名账号不同网段等问题,如果出现不一致调整的时候主从会中断)。
另外怎么保证全局参数的一致性,起码要保证同一个集群,在各个机房参数都是一致的,这个是比较脏活累活的东西,但是很容易出问题,到处是坑。
另外HA也面临改造,因为原来在一个机房,现在有多个机房,怎么做到HA的可靠性也是一个问题。这块我们也做了很多的改造。
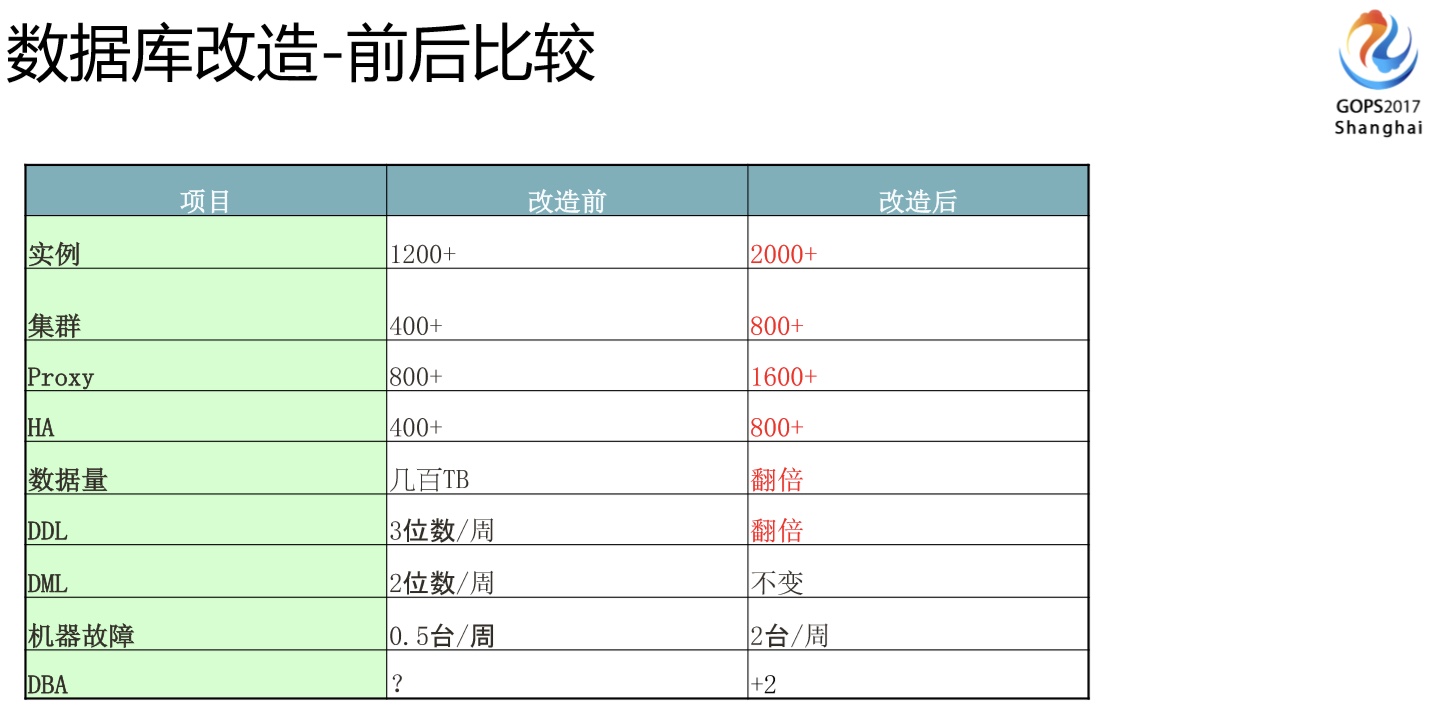
改造完成之后,我们对比下改造前后在数据库这端的变化。实例就翻了一倍,集群数量、Proxy配置、数据量、HA都会翻倍。这里特别列了一些DDL的变化,为什么会有变化,因为DRC不做DDL同步这个事情,这个事情都需要DBA分开机房来做(后面会细讲)。机器故障每周也增加了,原来一周碰不到一台,现在可能一周面临两到三台这样的机器故故障,所以必须要保证你的HA是足够可靠的。但是我们人数是没怎么增加,而且我们马上要上第三个zone,维护的工作量会增加更多,不过我们没有加人的计划,之所以这样是因为我们在把很多的工作通过平台、自动化和项目的方式来推动解决掉。
四、DBA挑战

刚刚讲了那么多的改造前后的变化。对DBA来讲,除了业务在多活的时候做改造,架构在多活时候的支持外,我觉得做多活改动最大的就是DBA了,对DBA的挑战真的很大。就像前面说的在集群数量很大的情况下,怎么有效保障数据一致性、HA、配置、容量,还有DDL等问题。
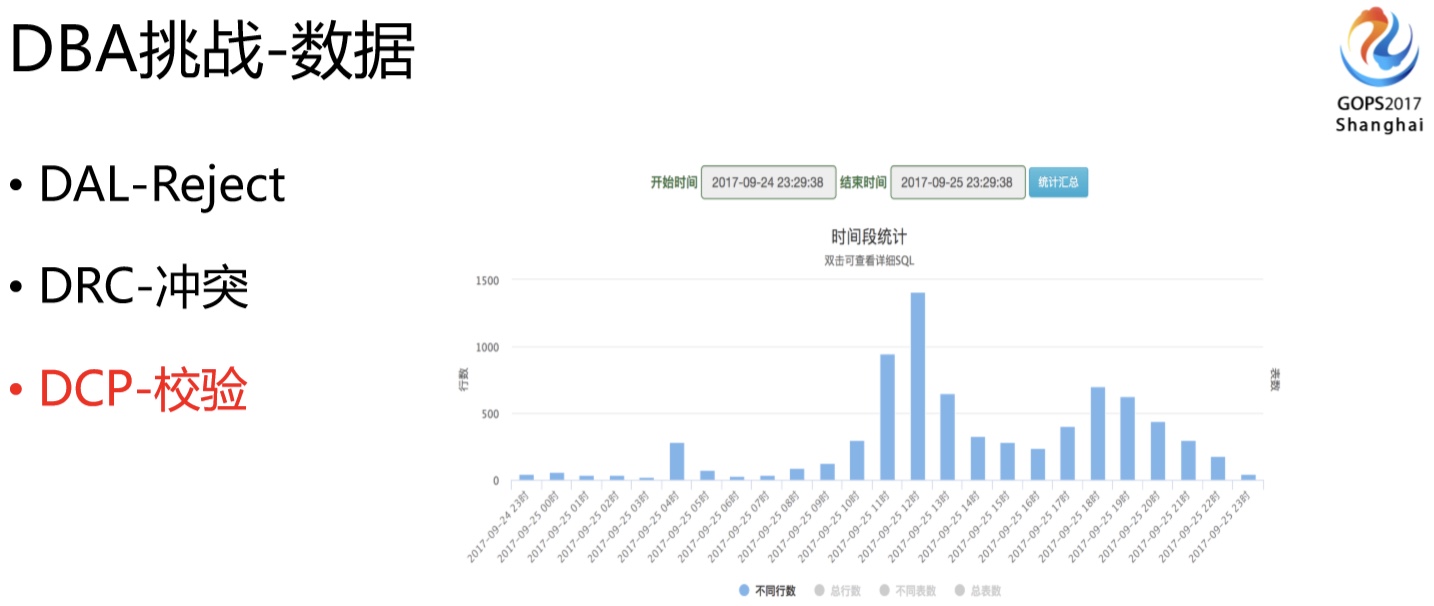
我们可以看一下。刚刚讲数据这块我们需要保证他不能错、不能乱,也不能说因为有一些数据的冲突,我们整个的数据流就停下来,这也不合理,否则多活就没有意义了。再一个即便是把前面流量的东西,都按规则走了,但你也不能保证各个组件不会出一些bug的问题,比如说DRC同步的时候就有bug,我们就要有兜底的检测,把有问题的数据及时的发现,甚至是修复好。所以我们DBA研发了一个DCP的平台,DCP就是为数据一致性兜底的,它会全量的对比我们各个机房的数据,告诉DBA到底什么时候有数据不一致的问题,大概是多少,是什么样的类型,怎么修复,不一致量大的时候还需要有合适的修复工具。
对DCP设计来说,因为我们有很多套集群,变动很多,如果说一旦变动就要人为调整的话,这个维护量也是很大的,也很难保证它的准确无误,所以它必须能自适配。它需要支持全量、增量、延时的控制校验和随时手动校验。延时校验就是我们有时候跨机房的时候天然就面临延时,这时候如果有延时数据肯定有差异,DCP需要知道到底是因为延时导致的数据不一致还是数据真的不一致。还有黑白名单机制,自定义规则,白名单有一些表我们不需要校验就可以跳过。自定义规则就是可以设定一些相应的过滤条件来比较,滤掉一些不需要比较的数据。
DCP不光是支持对数据一致性的校验,表结构不一致了也需要校验,甚至说多维数据也能提供校验支持,比如说一个订单可能根据用户做了拆分,也根据商户做了拆分,这两个数据是否一致是需要校验的。还有我们需要控制比较的时候它的延时、并发、校验的时长等,因为你的校验一直在跑,消耗过大,跑的时间很长势必对生产会造成影响。
最后我们是需要提供灵活修复的工具和配套的脚本。这样比出来的数据才能够快速的恢复,否则你虽然知道数据有问题,但要找这些数据怎么样不一致的,怎么去修复,再根据条件去把脚本写出来,这个过程就很长了,等你修复说不定业务已经影响比较大了。

DCP平台上线以后,每天大概有400多套集群需要校验,日均校验的数据有60多亿,分钟级别的校验频率。实际发现数据一致性的问题起码有50+例。不一致的原因可能是业务写错了,DRC出BUG了,还有可能是各环节(包括DB)的配置问题,如果你没有相应数据校验的工具,其实你是很难知道到底数据到底是不是一致的,多活做的时候这个情况必须要能掌握,否则心里没底了。

刚刚讲的是数据校验DCP的平台,还有一个HA的保障,集群数量翻番了,这时候你需要保证任何一个节点挂了都能尽快的切过去,同时如果你的节点有调整有下线等,你都需要保证HA配置能够跟着变动,否则HA的成功率就会得不到保证,800多套集群也不可能再依赖人肉去保证了。
所以我们做一个EMHA,他有什么作用呢?首先集群任何节点变动都能够自动感知,当然我们底层是依赖于MHA的,MHA的配置大家用过的话都知道它需要对SSH做互通,有任何一个调整需要把他从配置文件里面加进去或者删除,否则切换就有问题,所以EMHA新增了自动感知配置保持的功能,自动解决这些问题。第二个重要的功能是变动信息的扩散通知的机制,因为我们是通过DRC同步数据的,如果有一个master出问题切换了,这时候要通知DRC去连新的master,并且还需要提供相应的位点信息,还有各种监控也需要得到通知,要知道这个master挂了以后,新的master是哪一个,否则后面维护的信息其实都会错乱;第三点我们的切换需要让Proxy这一层自动感知,如果不能自动感知的话,每次切换Proxy都需要维护,这个可能会中断生产的访问,而且这个维护质量基本也得不到保证,所以EMHA也会自动完成与Porxy配置层信息的互通。
还有配置的保持也是比较麻烦的事情,我们在代理层的配置,如果节点变动了也需要变(调整区别于切换,切换DAL可以通过EMAH自动感知)。有各种参数,如果说调整不一样了,也需要全局的同步的,这些东西都需要有很多自动发现的手段,包括自动处理的方式。当然我们现在有些也还没有能完成做到自动化(正在努力中),目前还有些是通过巡检脚本来发现的,起码保证能够发现它然后解决掉。
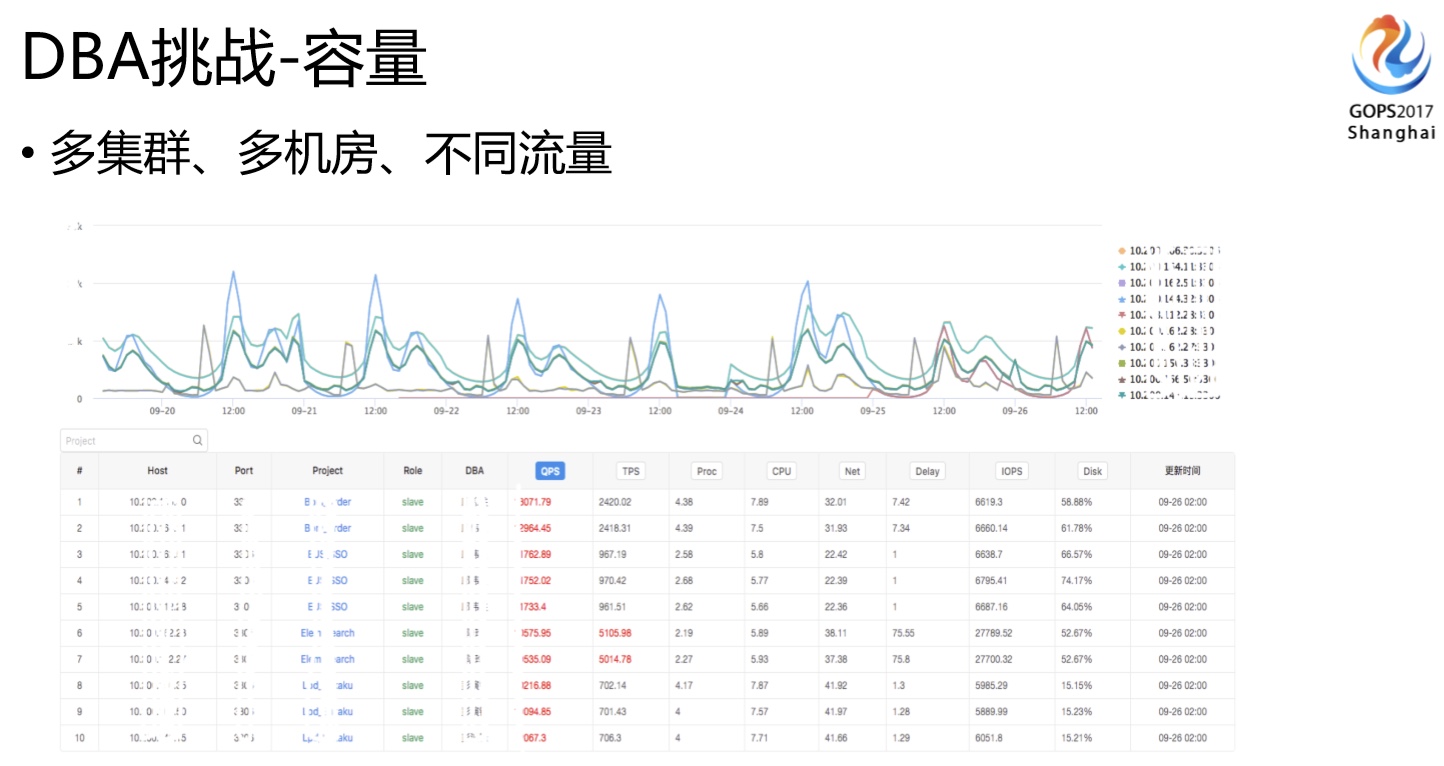
容量这块,现在是两个机房,两个机房的流量并不一定均衡,比如上海机房70%的流量,北京机房30%的流量,但流量会随时切换,所以必须保证每个机房都能够承担所有流量。当然三个机房的话,不一定百分之百的冗余,但也一定要知道每套集群是不是能承载切换过来的流量,否则切换过来就面临雪崩的效应。所以对各项指标我们都要有相应的水位监控,提前发现这些问题。
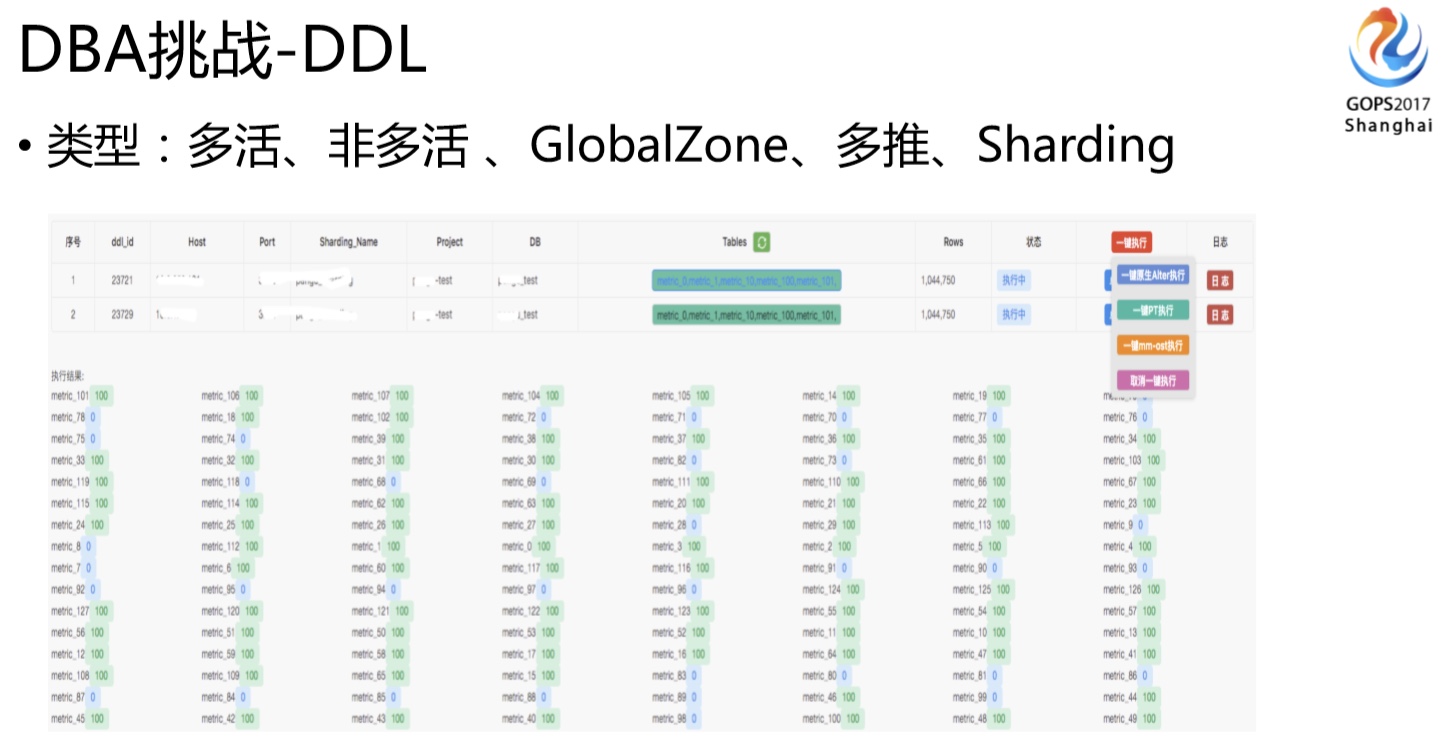
还有一个很大的困难是在DDL这块,因为DRC里面不方便做DDL这个事情,之前我们也尝试让DRC同步DDL操作,比如说我们做DDL的时候,一般是用PT工具来做,这个过程要拷贝整张表的数据,如果这个表比较大,DDL时两个机房之间的流量就会面临很大的冲击,而且延时会相当大,比如说100G的表在一个机房做完要同步到另外一个机房去,这冲击业务影响是不可接受的。所以DDL需要DBA在每个机房单独做,我们开发了一套DDL发布工具。因为我们有很多数据类型,有GlobalZone还有shardingZone我们还有大量Sharding 表。对单个业务逻辑表的DDL来说,实际上我们一套集群里面有几百张表,这个表又分布在多套集群里面,所以实际业务一张逻辑表的DDL操作,实际DDL需要做一千张表,同时还有各种不同的业务集群类型,我们在发布工具必须要能自动适配和识别这些情况(这个时候元数据维护相当重要了,因为人已经识别不了啦,只能依靠工具)。
还有刚刚讲DDL的时候大家普遍用PT的工具,我们用的时候也发现了很多问题,毕竟是它是同步触发器的,一旦加上去之后,瞬间TPS很高的话,就把数据库打爆了。所以我们在这块也做了大量改造,到现在大部分情况下我们已经不用PT了,大家看这个图上有好几种工具可以选择。我们基于开源社区的gh-ost做了一个二次开发改造,改造后的工具叫mm-ost,是一个跨机房的DDL工具,不仅解决了DDL的时候threadrunning不可控、主从延时不可控的问题,还解决了跨机房延时的问题,速度比gh-ost要快一倍。我们是多机房,多机房和你做一个机房的DDL时完全不一样的,因为你的机器可能有差异或者繁忙程度不一样,可能这个机房DDL做完了,另外一边要半小时之后才能做完,尤其是一个业务逻辑表的DDL对应的是上千张物理表的DDL时,差异性就更大了,这样造成的跨机房延时业务可能没法接受,所以我们需要的不仅是能保证同机房DDL主从延时的可控,还要保证跨机房的延时的可控。
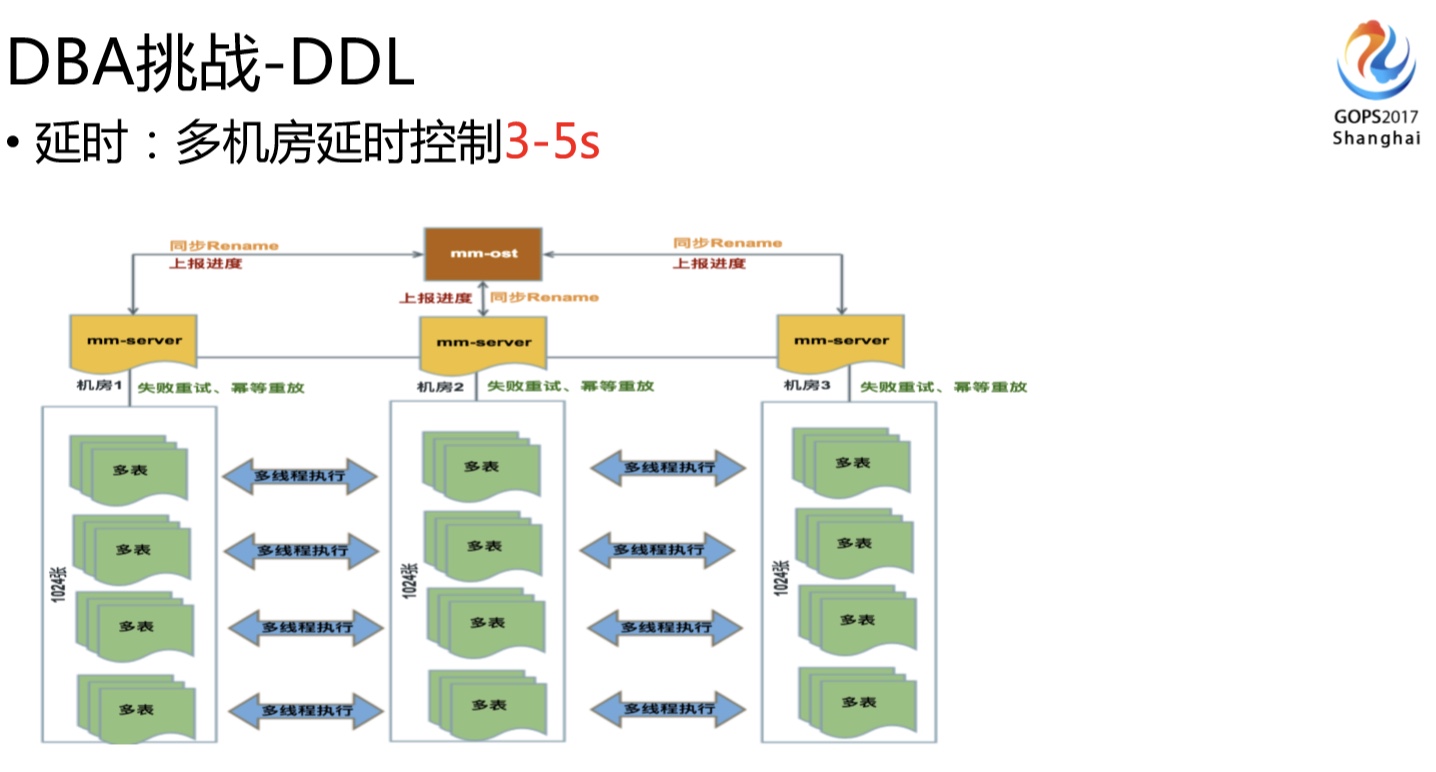
mm-ost现在就能够支持到跨机房同步完成DDL的时差控制在3到5秒之内。这延时对业务来说就没什么感觉了,而且他可以支持暂停、探测到DDL数据延时的时候能够减慢速度,能根据机器负载动态调整DDL的速度等,所以现在DDL基本上对业务来说是没有感觉的。
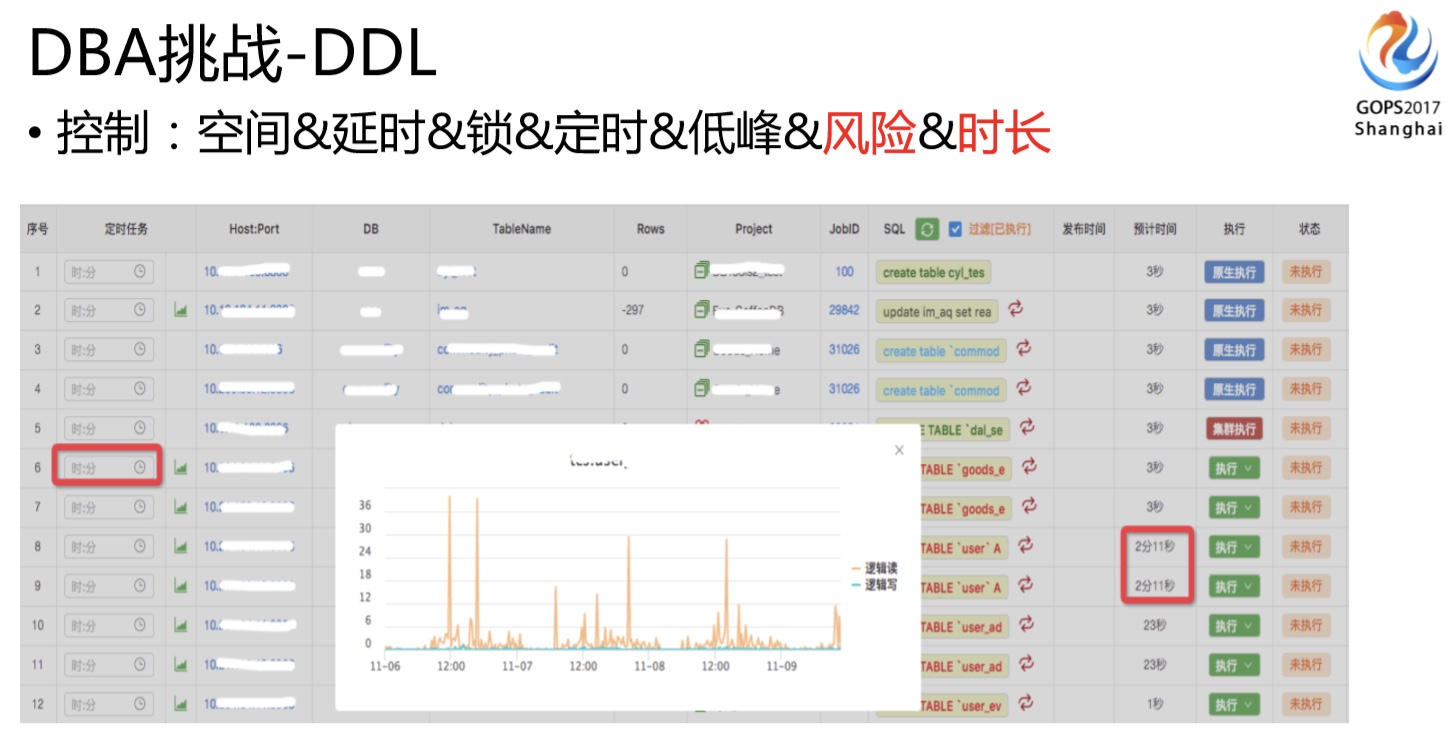
另外,大家可以看我们的发布平台做的很复杂,它底层调用的是mm-ost,在发布平台上我们也做很多控制,比如说DDL空间满不满足,各个主机是不是都满足去做DDL的条件,主从我们需要控制的延时在30秒之内,有锁的时候需要减缓速度,还支持定时执行(因为我们有些业务的低峰是晚上4点,所以DBA不可能每次都是4点来做这个事情,这时就要定时功能的支持),另外系统还可以通过识别业务高低峰推荐什么时候做DDL比较合适,还有一些风险识别的控制,我们还要预估DDL的时长,如果开发问一个500G的表DDL大概多久能做完?你需要能大概告诉他,给他一个预期。总之发布这块是我们面临最大的一个挑战,我们在上面做了很多工作。
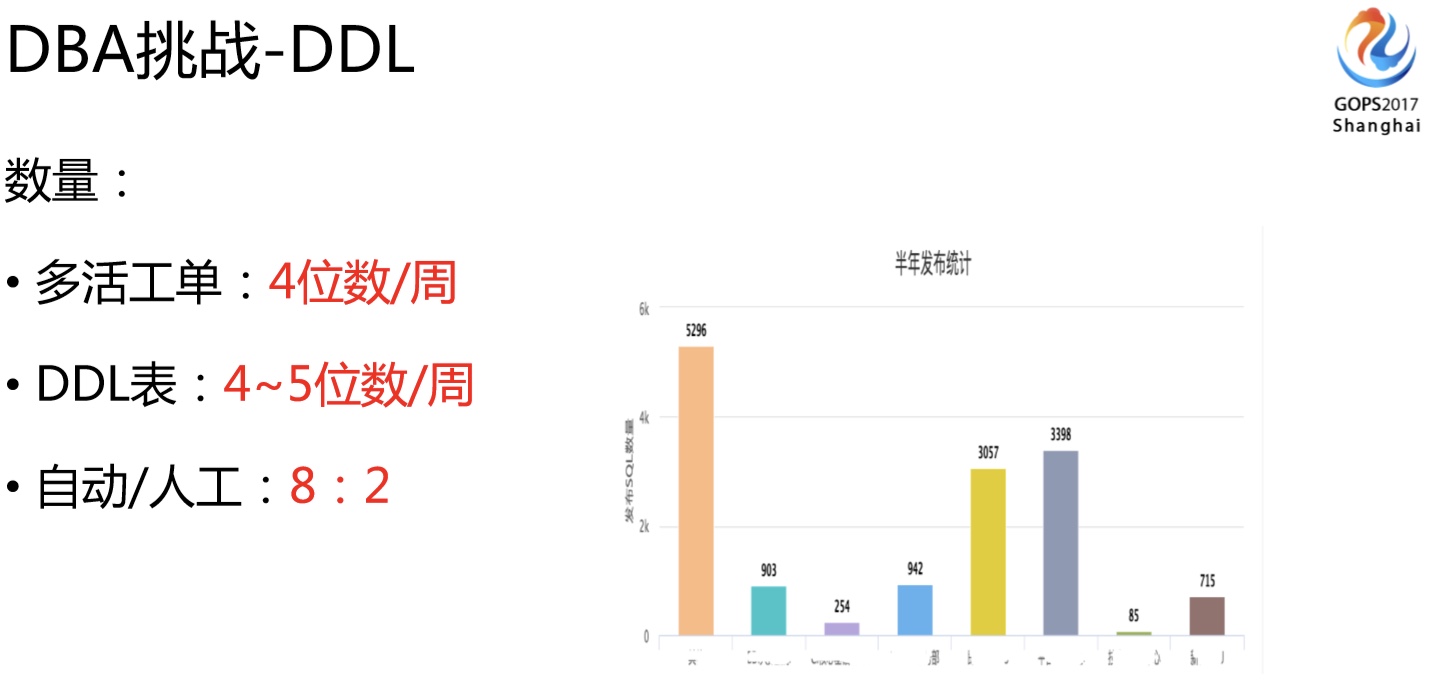
我们DDL数量相当多,可以说在多活改造的时候,DBA发布的量是最多的。多活改造期间我们DDL基本上每周的工单都在四位数,四位数的工单数量,放到底层来讲,可能一个逻辑表生成一千个DDL,就是最少是5位数DDL物理表的量了,如果完全依赖DBA来执行,也很难支持了,所以我们加了自动发布功能,对于风险不高的工单是系统自动执行的,粗略的比例大概是8:2,绝大部分都是自动发布了。风险性比较高的工单我们才需要人去处理,我们统计了一下半年大概有15000个工单。
五、收益与展望

大概的挑战主要的方面已经跟大家分享了。我们最后看一下多活做完以后收益有哪些。做多活之前,我们也面临过很多棘手的问题,比方我们之前面临着整个机房出现问题(核心交换机出问题、网络出问题),还有些机房因为在业务没有那么大之前你不可能预留特别多的机柜,但你现在说我业务涨的很快,现在要加一千台机器、两千台机器的时候,发现你加不了,因为你的IDC不能给你这个支持,他们不可能给你预留这么多机柜,这个时候你就面临单机房没法扩容的麻烦,之前只能考虑迁移到一个更大的机房去,但也是个耗时费力成本高的事情。我们多活做了之后,首先打破了单机房容量的瓶颈,单机房不能扩容的时候,我们现在可以在另外的机房扩容我的机器,也可以分不同的流量来满足负载,就不再受到单个机房容量的限制。另一个,多活上线到现在我们流量切了有20次左右,有时候是演练,有时候是真实发生故障,现在其实就不再受到单机房故障的影响,甚至是单地域的影响,假如说上海哪一天全断电了对我们影响也不大(当然只是指技术层面)。
还有故障兜底,有的问题可能是比较麻烦的问题,一下子没有办法判断或者解决,那时候可能影响很大,但只影响单个机房,这个时候就可以把业务切到另外一个机房,等我们把问题解决了以后再把流量切回来,这样对业务就基本没有损失了,所以多活之后对我们整体可用性也有一个很大提升。另外一块是动态调整各个机房的流量,尤其是在做一些促销活动的时候,有些地区的流量明显是不均衡的,这时候如果能动态的调整机房之间的流量访问,这是比较好的分担压力,像阿里双11这种活动,应该会根据流量压力来调整各机房之间的分配。

接下来在来讲下多活这块后续我们可能要做一些事情,一个是刚刚讲的多个机房,我们现在正在准备第三个机房,因为两个机房的代价比较高,冗余比较多,我们需要做第三个机房分摊这块的成本,当然一开始成本是比较高的,往后业务继续上涨的话,可能不需要做太多的扩容。而且现有百分之百冗余的机器资源,可以再做调配,这样成本往后来看的话是会下降的。
另外一块是数据的Sharding,这个我们还没有做到,因为我们在各个机房都是全量的数据,这也是我们后面努力的方向;
还有一个是自动动态扩缩容,我们需要有更细的控制能力来自动的完成这些动作,尤其是在硬件资源利用率上能动态调整;
最后一个点是希望能够提供多机房数据强一致性的架构方案,因为我们现在来讲都是最终一致性的,怎么对一些非常重要的数据,提供各个机房数据及时强一致性,这块也是我们接下来需要努力的方向。
