@gaoxiaoyunwei2017
2018-12-10T10:02:23.000000Z
字数 12104
阅读 1157
中小银行的DevOps实践
白凡
分享:李丙洋
编辑:白凡
讲师介绍:首先是自我介绍,我是李丙洋,我的网名是君三思,实际上是我是混DB圈的。我之前写过两本书,一本是涂抹MySQL, 一本是涂抹ORACLE。刚才邓骏说我在DevOps是专家,其实这一个成为不敢当,很业余,我们野路子出身。完了这一次更多也是想学习,我们顺道分享一下我行在DevOps实践的一些经验。我目前所在的企业是重庆的富民银行,是我国中西部比较年轻的银行。因为我们行目前定位是要做互联网银行。实际上我们团队里面有很多来自于互联网体系和互联网企业的人才来加入。同样呢,我们也大量地在使用互联网企业里面会应用到的这一些技术或者是解决方案。在DevOps落地的过程中,我们同样也是这样,也是在深度地应用很多互联网体系的思路或者是中间件来解决我们实际遇到的问题。

我今天的介绍呢,我想主要分三个方面来讲:
- 我们为什么要做
- 我们现在已经做了什么
- 我们还会在去做什么,包括我们现在还在做什么这样一些事情

1. 为什么要做运维自动化
首先要讲第一部分,为什么要做?像类似于这样的事情不是一拍脑袋,这一个东西热就做,不是这样的,讲这一个话题之前我引申远一点,我一直觉得优秀的IT人一定是懒惰的,这一个懒惰是加引号的,它不是贬义词,是一个褒义词,为什么这么讲?
1.1 传统运维支撑工作的痛点
我举一个场景,比如说你是一个运维工程师,大量重复性的工作每天让你重复性地执行,那你下意识的是什么,如果你具备足够的技能,为了偷懒,我把我原来手中做的工作能不能分装成脚本,然后我要手动敲几十条命令,现在我知需要敲一条,一个懒惰的人。假定你是一个测试工程师其实也是这样,每天做各种各样的回归,用力都一模一样,场景也一模一样,甚至有的时候报错都一样,很繁琐。
怎么办呢?写一些自动化的用力,自动化的方式调用它,你只要看一个结果,一个懒惰的人。开发更是如此。开发人员最常见的是什么,看到别人写的工具类,一边抱怨代码写得丑陋了,怎么写成这个样子;然后一边用得很爽,大量地引用,但是他不会重复写一遍。或者你会发现他代码里面抽象的层次越高,反倒他的技能水平越高,就是他懒得写重复的东西,所以我一直有这样的理解,我觉得优秀的人,“懒惰”是比较具备的品质,打引号的懒惰。
讲到这儿,为什么要做自动化基础已经很清晰了,但是为了把这个过完,我们还是要接着往下讲。首先你看确实不容易,有痛点,我觉得这一页不能深入讲,为什么?应该我算一名IT行业的老兵,刚才有朋友过来说十多年前看过我写的书,我很感慨,岁月催人老,我干过开发,设计过架构,带过运维团队,整个开发的运维角色都参与过,像很多的痛点,比如说运维里面遇到痛点,我完全是感同身受的,我甚至连续两个通宵干过,一年前都维持这样的工作。所以痛点这个不忍再提,这一个属于伤疤,不好去揭,这一页我不详细讲。
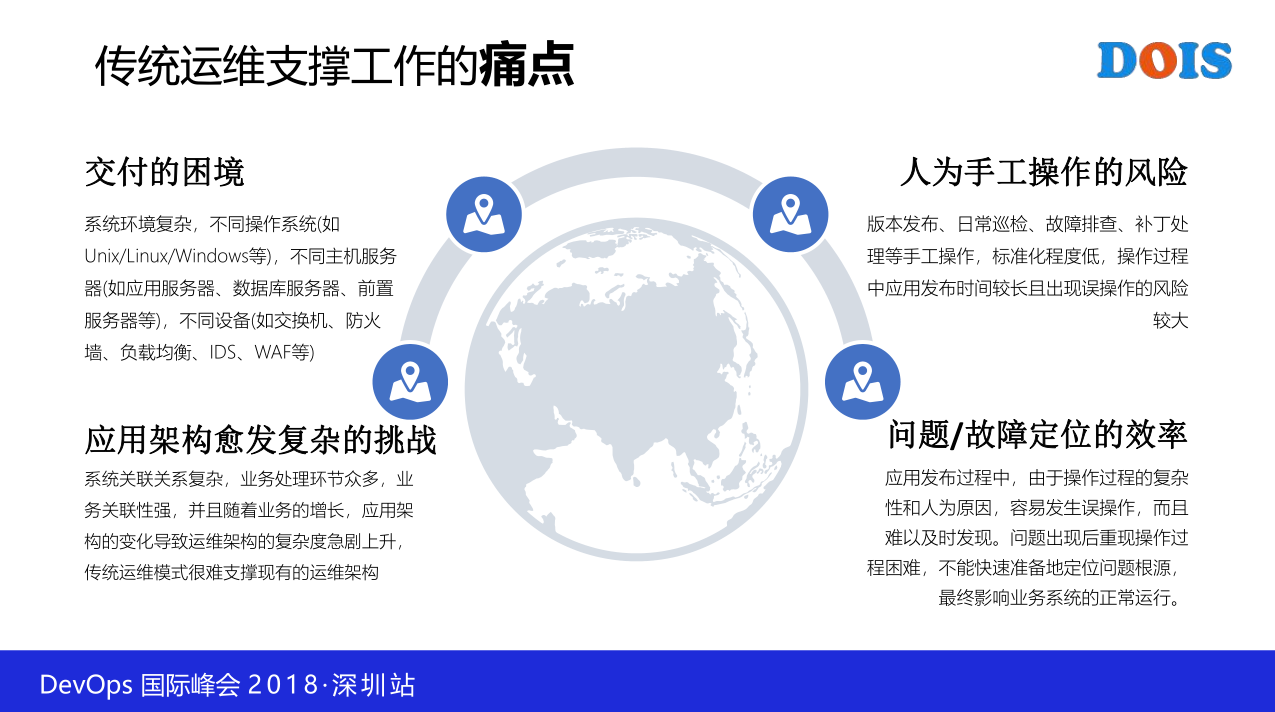
1.2 日常运维工作
其实特别是运维的同事看倒觉得这就是我们面对的问题。这可能是其中的一方面。同时运维本身作为一个支撑的团队它也会有很多需求,有一些是外部团队给他的,比如说昨天有一个哥们找你,假定你是一个运维工程师,找你过来告诉你说,帮我升级一下系统。然后今天又告诉你说,哥们再帮我初始化一下服务器。对不起,我把这个时针往拨一下,我描述的这一个频次可能不对。应该是这样,20分钟前,有一个同事找你告诉你说帮我排查一个故障,十分钟前然后又有人有一个兄弟来找你说来帮我修一个数,然后10分钟以后又有一个人告诉你说帮他搞一个报表,然后20分钟以后等等,频次基本上这样。
所以其实响应度是这样,其实一线的工程师对他们的响应度是非常高的。一方面是外部的需求,同样我们内生也有很多的需求。比如说像这里面,随便找一个像什么日常巡检,你看马上就元旦了,能不能踏踏实实放个假呢,能不能不安排现场职称人员呢,你的巡检工作是不是要做好。
比如说我们一些服务的优化,会不会导致内存溢出,负载情况控制得怎么样呢,监控有没有保障到位,运维团队自身要关注,所以这里面很复杂。有源源不断的,而且频度很高的外部需求就不说了。运维团队自身有很多内生的需求,这一些需求,如果说我们没有一个比较好的流程体系,没有一个工具平台支撑,你想我用投入多少人才能做得过来,尤其是我们现在接触到的环境,动不动服务器就上万台,这一个要支撑的工作量其实非常大。尤其是有的时候,更悲催的是你找不到人。那你要把现有的团队压榨成什么样子才能支撑这些需求,都是现实的需求,这一个感觉到转化到痛点上去了,不好揭伤疤,我们开放过。
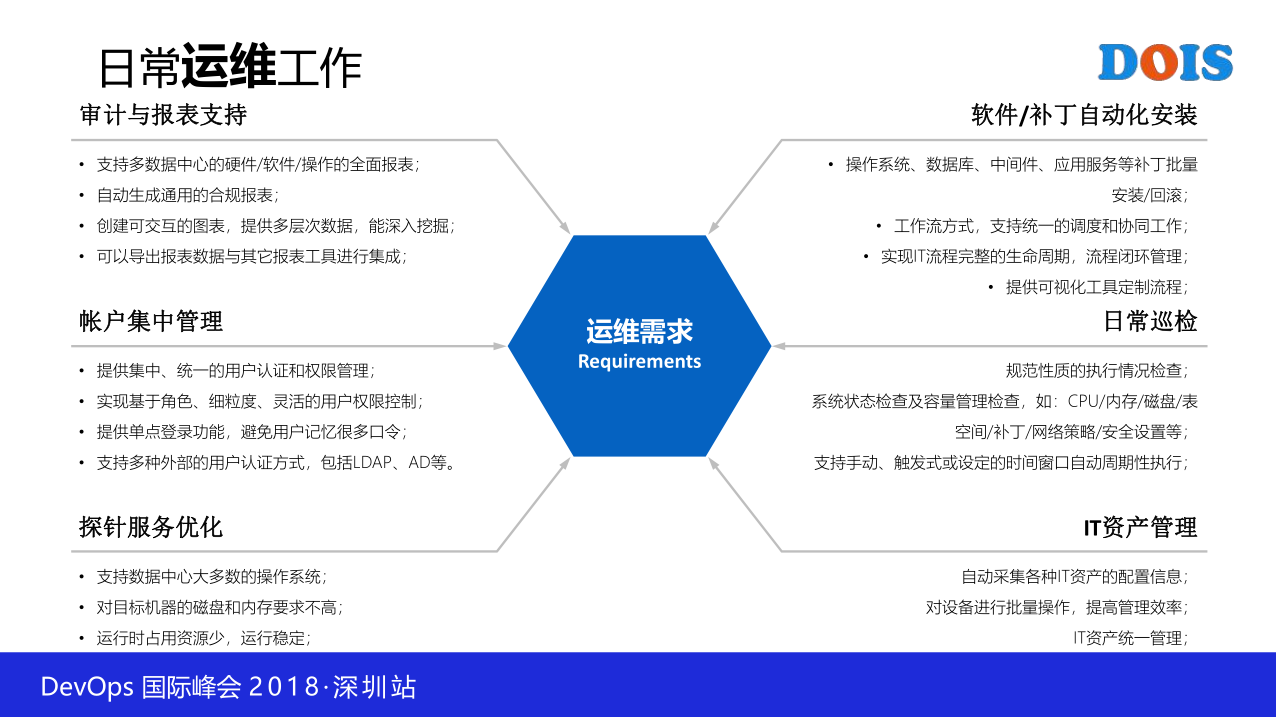
1.3 运维自动化的优势
因为这一些原因,所以我们痛定思痛,赶紧干自动化。有自动化就有很多优势,这里我觉得不用念,好多是网上抄的,抽象了一下。比如说减轻人员负担,提升工作效率,降低运维成本,都是实实在在的,确实会做这样的。然后像可视化也会实实在在的,比如说原来我们要登到服务器一台一台地搞,确实还是很低级的,我们建成自动化系统后,一定有一个平台,那我在这里面点按钮,我操作视窗界面去操作,肯定比你手动执行命令好很多。然后同样不止是这些,你看我还是花了不少的功夫,看了不少的文章写出来,然后摘抄出来这么多,其实不止这么多,我也是偷懒,我也是一个懒惰的人,所以我随便列了几条。

效率就不说了,肯定是这样的。对,服务标准化我讲一下。你比如说即便我们同样是干运维的,同样一个岗位不同的人员,因为他的知识体系,技术水平,可能会导致什么呢,可能响应的速度不一样,有的人十分钟搞定,有的人半天,有的人做不了,对不对。如果我们自动化了之后,不管谁来做都是一样,输出的结果肯定是保证一样的。你觉得这一个可靠性就强,然后我执行的步骤肯定是一样,因为我封装过了,不管谁做都一样,我的服务很容易标准化。然后易管理,通过平台各方面的可控性都是很强的,所以结合前面这一些,我觉得都不重要,感觉讲一个课题前我们讲我们为什么要做,所以我们要把这一个事情说清楚。罗列了这么多,觉得这一个事干,值,所以我们就做。
2. 我们做了什么
在做了什么之前呢,我觉得真的是有必要先讲讲我们准备怎么做。就是号的问题,我自己前面讲我不是DevOps的专家,我们是野路子,我们是一路摸爬滚打,不知道踩了多少坑,完了才积累了一些经验。
首先我们觉得DevOps首先不是一个自动化发布的系统,因为你其实自动化发布你要做什么集成啊,构建布署,再简单不过,很容易,你自己写脚本就搞定,不是那么回事。也不上一个工具就搞定,前面的嘉宾也分享了,我也认真看了,你可以看到一个完整的DevOps流程是很复杂,那这一个要做好的话,一方面我们不是基于工具,另外很大程度是要基于团队内部的情况构建适合的开发环境,建立起统一的这一种标准,团队的这种文化,然后才有可能把这一个事情做好。

在这一个基础之上,然后我们还是要做什么呢,我觉得有几个事情很重要,要单独提出来说,第一是标准化。你想这样一个道理,哪怕你是一个小企业,你要管理的服务器,上千台玩似的,如果每一台都不一样的话,你怎么做的,你可以想象,你要为一千台分别打造自动化模式,他最多会帮你解决什么问题,就是你布署一千种模式,或者是你做一千做操作,这一个重复性,仅此而已,但是其实你企业要维护一千种代价高昂,这是不现实。
2.1 标准化建立
所以最好的是什么,我们要先把标准建立起来,这一个标准在我们实际落地的过程中,我们主要从三个方面考虑:
1. 第一个是系统基线,这一块指的是我操作系统的版本,然后我的环境变量,我里面装的探针的服务,甚至虚拟机的配置。那么我们目前虚拟化做得非常彻底,正处在虚拟化和容器化的过渡阶段。在这一块我引申一下关于系统基线,我也一直有这样一个理解,我觉得目前我们实现的时候是保证生产环境的配置和测试环境,在主机层面,IaaS以层面,比如说虚拟化,对于开发来说,虚拟化就是一个IaaS层面的东西,我们的操作系统是一模一样的。比如说生产环境四核8G内存,那么在测试环境也是这样。由一个什么好处呢,首先是标准了,比如说特别是跟性能测试相关,很多时候你会听到业务团队你的需求部门来给你抱怨,不行啊,这一个环境和生产不一致啊,我怎么能压出它的实际性能表现呢,我做了这一个标准了以后,你发现就不存在了。因为你保障生产和测试完全一直本身这是一个伪命题。你想你即便把主机资源、存储资源配置一样了,你的网络结构肯定是不一样的,是不可能一样的,生产的复杂性和测试环境是无论如何模拟不了的,有一些是你接不了的。尤其是考虑金融自身的特点,你找人行,你说要建一个测试,人家理都不理你。
那配置完了以后,我在IaaS层面的配置跟生产是完全一模一样的,这样我在做IaaS的时候,我只需要关注在这种配置下我的拐点在哪里,比如说两核4G,或者是四核8G, 它的性能表现是什么样,它的并发,它的RT是什么样,我的生产没有到了比这一个低,甚至有可能比这个还高一点,这样的话,我就能知道甚至为我后期的弹性伸缩打下一个好基础,这是引申讲到的,就是一定要做操作系统层的标准化。
2. 我们对应用服务这一块也会做一些标准化。这里就像上面讲的JDK的版本一定是一模一样的,路径完全一样,然后输出的日志绝对也是完全一样。
3. 关于配置和日志。其实在项目支出,或者是在很多优秀架构师加入进来之前,代码结构或者说工程结构是没法看的。比如说域名化其实完全没有开始做,所有的连接全是IP这简直就是一个灾难。然后我们在这一个过程中做了大量的工作,比如说想强制域名化,引入配置中心确保我们工程下面没有一个Project文件,没有一个config文件,只有代码。我打包出去,我尽管没有做容器化,但是我出去就是一个外包,非常干净,没有任何配置,所有的配置全部在配置中心。然后我们通过日志输出格式我们定义我们自己的日志规范,这一些日志规范是方面是说你什么情况要打log,什么情况打BUG,一方面是这个。另外关于日志输出内容,甚至你的时间,你时间的分隔符全部都定义得非常清楚,按这一个做改造。日志输出的路径更是如此。那么我们通过这一个方式为后续做,不是今天的后续,而是我们做完这一个事情后,比如说接ELK等等都是顺风顺水,特别简单。那么标准化建立起来了之后,我们前面讲的你现在有一千种模式,如果运气好,有可能就变成十种,你只要维护十种模版就可以了,这是最大的一个收获。

3.2 准生产环境
然后第二块,一定要有像生产环境的预演环境,有一些叫准发布环境,有的叫准生产环境,或者是叫预演环境,不重要,其实是一回事。这一个之前我们也踩过坑,不是在我们现有的银行,而是在以前的企业里面踩过数次坑。反正每次发布都不顺利。你在测试环境怎么测都好好地,在生产就是有问题,每次发布都不顺利,要不回滚,要不搞通宵干,这一种折磨人。而且最坑的就是折磨我们运维兄弟,因为我们就是干的人,就是被干的人,这是最坑的。
所以最好呢,无论如何,不管多难我们要把这个准生产环境建立起来,跑这一个有什么用途呢,我保证我的顺生产跟生产是几乎一样,几乎的意思是它的结构首先绝对一样的。这一个URL路径过来是Nginx的转发,在非生产环境肯定也是这样,或者是在FO转发的生产环境也是这样,转发的路径是怎样的,跟生产也是一样,唯一的差异是在哪里,生产生产的环境是八个点的集群,我在准生产环境我为了节省资源,我用两个节点,但是结构是一样,两个和八个其实不影响你发布的正确验证,对不对,所以我们投入很大的资源,花了很多的代价,不知道有多坑,建一个破玩意儿。
好,我们把它建立起来,会发现后续的上线会容易很多,就是上去生产会容易很多,但是上去发布还是有坑,上去发布就是好在你可以白天,你就不用通宵了,所以是重要的点,不管花多大力,一定要建立准生产环境。
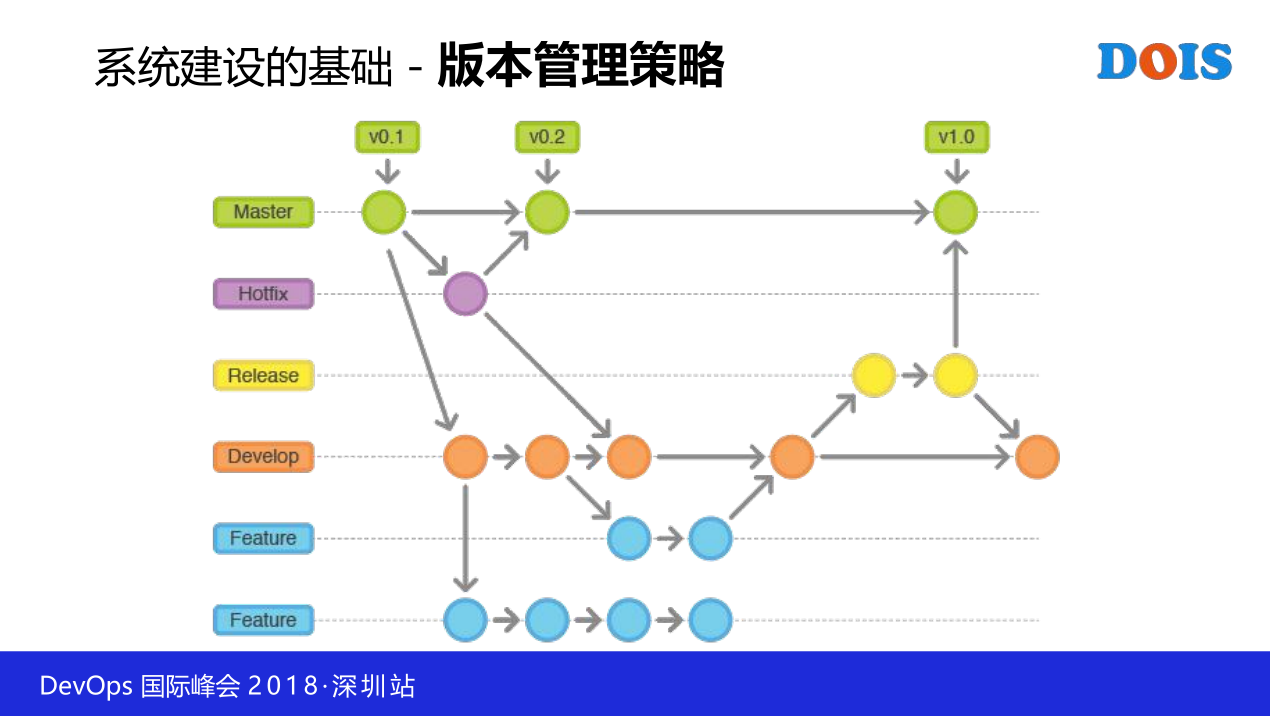
3.3 版本管理的策略
这是我前面讲的,甚至包括你开发的模式,你团队组成的模式都要跟着变,什么意思,我们举这样一个例子,我不管你用什么管理工具,什么玩意都不重要,你最起码关注一个问题,开发人员提测的版本和测试人员的版本是不是一样。测试人员测过的版本和投到生产的版本是不是一样,你怎么去保障它,有没有一种机制来保障。不要提容器,因为容器方式不一样,所以我们也是为什么要干到容器去,容器确实是解决了好多的问题,但是你上来没有干成容器的时候,现实的问题你就遇到了。你比如说说我同样基于版本,其实围绕版本开发有几种理念。一种是基于分支,或者是基于主干或者Trunk的方式做开发,你始终基于Trunk开发,你会面临什么时候打上线包,我打完之后,在我变更的过程把它识别出来。
同样地,如果说我基于分支做开发,那么我什么时候合并代码到主干去。如果我一直不合并,那么它所引申的负面的效果能不能接受等等。
那么我们在我们做我们的这种DevOps,在做自动化的时候,其实你要把这一些层面的问题解决,如果没有解决,你会发现路走不顺。在我们的团队还有一些用SVN,其实强烈推荐事业GIT的,GIT确实提供了很大的便利。我们目前的版本管理和分支管理的策略也是基本沿用GIT的这种形式,当然做了适当的删减,我们没有这么多层,没有这么复杂,或者是每一个版本都没有这么复杂,是做的适度的裁剪的,但是大致是按照这一个方式在做,通过版本管理的方式来去确保我任意节点提交的版本一定是我想发布的版本,不管它是哪个环境里面。
2.4 制度管理

这是我们的基础,然后你完前面的那个之后,其实有一些跟技术无关的,就是你的制度要跟上,你的流程,你的规范,你的约定,你的管理办法,该出台要配套做出台,这样你有法可依。但是有法不依,或者是违法不究这是另外的问题,但是你首先要确保我有这样的方式,就是我要求他们去遵循,其实提醒一下,制度也要跟上,尽管这是非技术的问题。但是有的时候管用。
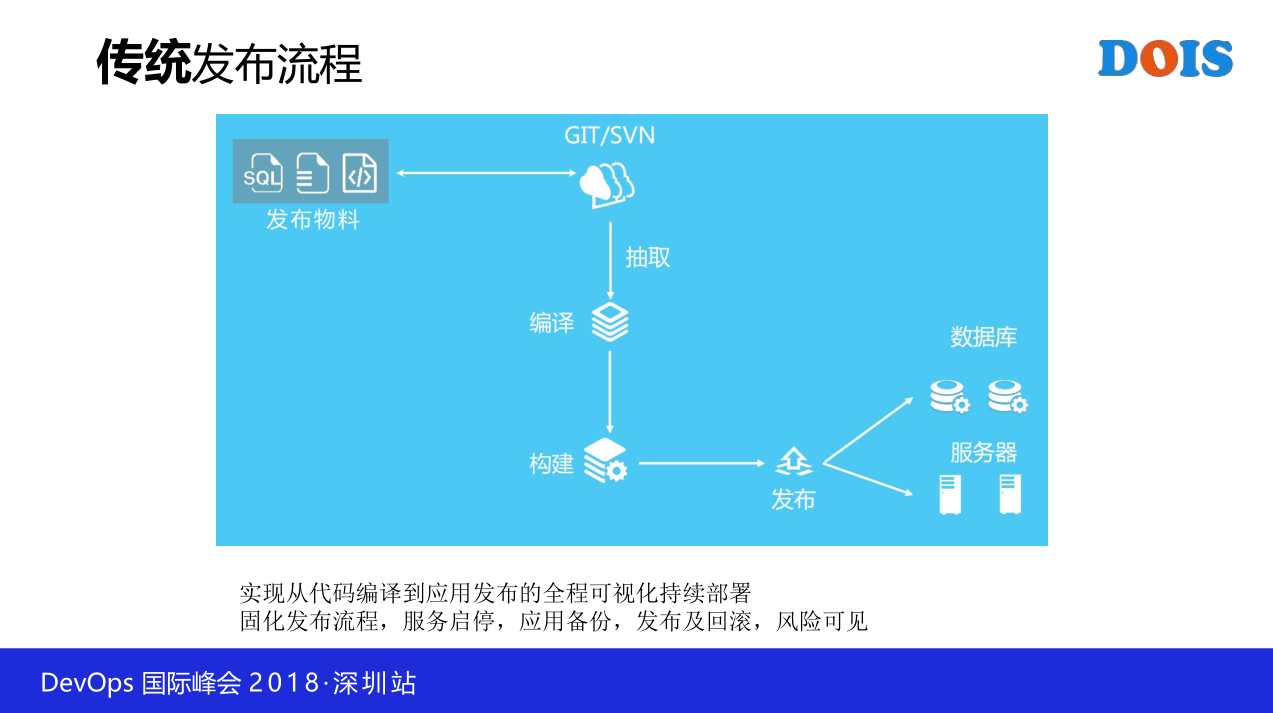
好,然后基础建完之后,我们传统的这个发布,假如我们不是金融体系,其实好多事情也很简单。比如说最传统的发布方式就是这样,我有一个物料库,然后在版本库里面,然后我从版本库里面拖代码下来,然后做这一种变异,然后做构建,同时做部署,其实都很简单,整个过程也基本上实现,很简单的方式。比如说基于Jenkins很简单可以实现持续的布署等等,这是一个最简单的模式,它只管发布。
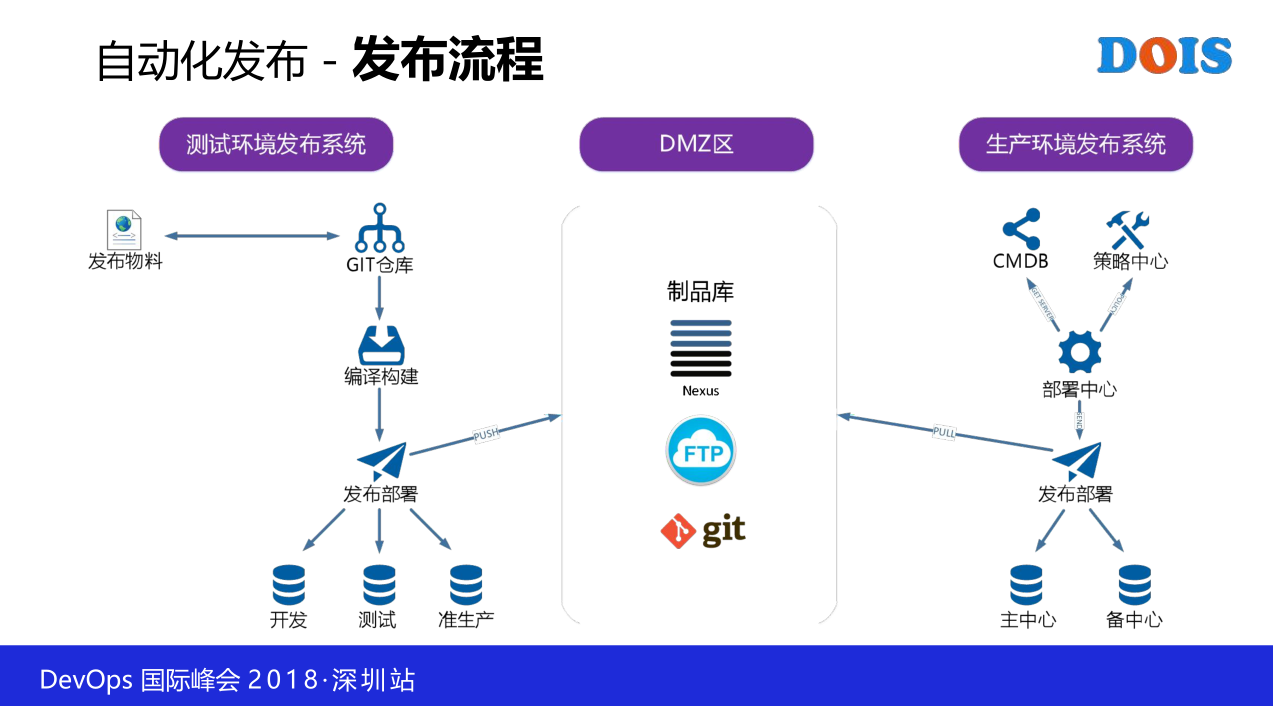
但是仅仅讲发布来看的话,你发现金融行业都不一样。为啥,我这一个行业有一个抽象的图,先不看下面,就是一般金融有三张网的说法,是吧,互联网,办公网,还有你的生产网,三网是完全隔离的,这一个就很坑,也就是说你测试走不到生产里面去。
那怎么办呢,在我们这一个环境里面,左边的部分,这一个测试的环境其实跟传统没有什么区别,就是还可以那样玩,怎么做都可以。然后呢,我们会在我们DMZ区有一个制品库。最重要的,因为我们是数据中心,我们是保生产的,我们更关注的是右边,右边呢,我们的发布系统就会从制品库里面出货,制品库是什么都不重要,可以是一个FTP服务器,可以是一个HTTP服务器,可以是一个源码服务器等等。是什么其实不重要,就是你只要告诉我的物料在哪里,然后在右边通过我们发布系统布署出去,然后过程实现一系列的功能。所以这就是我接下来要讲的真正的干货。
2.5 系统的架构
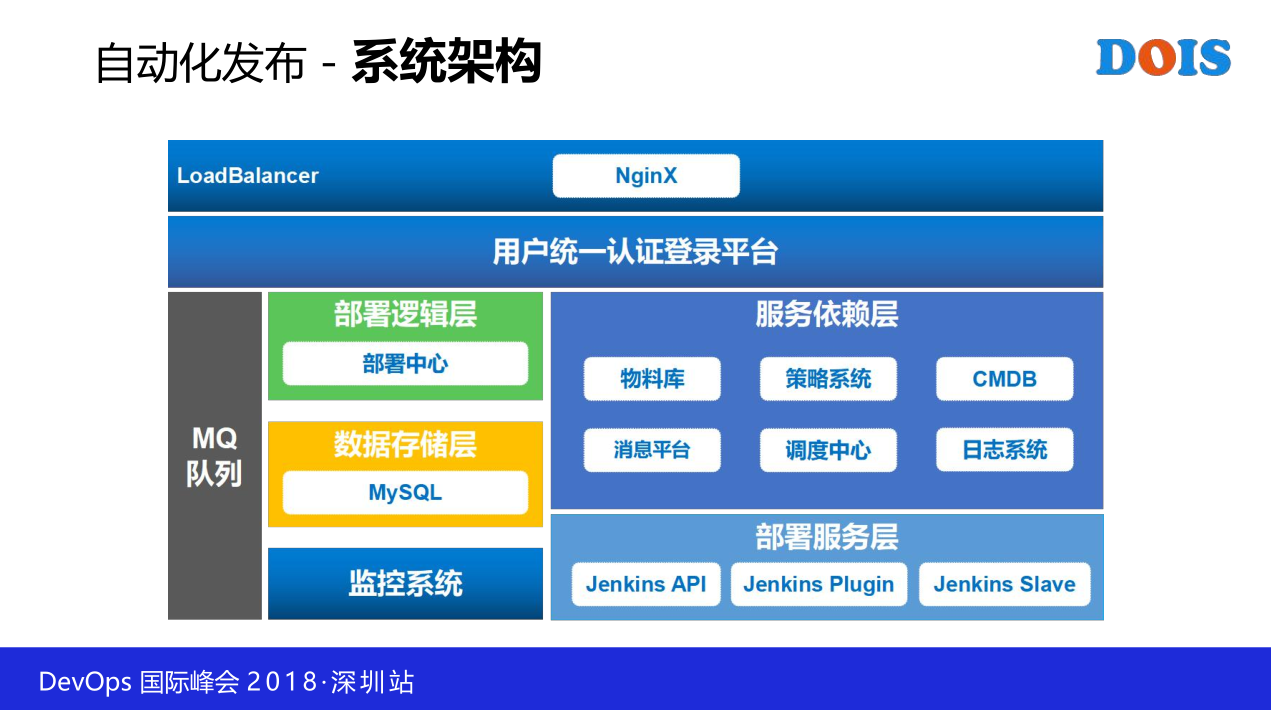
但凡是这种,但凡大的基本上都是自研的,小的是第三方的。这里是自研的,这里分三个重要三个部分:
一个是我们得逻辑层,逻辑层你可以把它理解为控制台。我们把我们自己最关注的,或者是为了我们用得爽,为了减化我们的工作,体现我们是一个懒惰人的这部分的工作全部放在布署逻辑里面,去把它封装起来,然后尽可能简化我们要做的每一步操作,说得更直观一点,就是点按钮,点这个还是点那个。然后呢,但只依靠它不行,为什么,为啥呢,它要有一些依赖,比如说它要连物料库,它要有账户统一关系的平台,然后它要做调度,要连日志等等,所以它会有一系列的依赖层。
然后具体部署的时候,我们下层有一个部署服务这一个布署服务呢,我们目前基于Jenkins,其实这一层不重要,你用Jenkins也好,你用什么Ansible,什么Salt都可以,不重要,然后我们为什么选择Jenkins,最主要的原因是我们团队对Jenkins最熟,我觉得这一点也很重要,就是你选型的时候一定要选了最熟悉的平台,选选熟悉的解决方案,特别是当你解决有无问题的时候,然后解决优劣的时候可以去考虑,解决有无的时候就是怎么快怎么来,然后怎么熟悉怎么来,这一个时间不能莽撞,不能适应潮流,或者是盲目体现我们的新颖,盲目引入一些新东西,那么金融行业的生产环境不是闹着玩的,这一个敬畏是要在的。我们基本上的系统架构会是这样。
对,考虑我们系统在快速迭代的周期,我们系统构建的时候呢,主要着重关注两方面:
- 一块是发布,就是前面讲的自动化的控制这部分。功能不列举。
- 第二是巡检,更多帮助我们解决自动化日常工作的这些问题。还有最基础的系统管理等等。这一个不重要。

然后还有原型设计,原型设计这一块其实还要讲一下,里面还是有一些很有意思的小细节,比如说发布计划管理等,不是界面怎么样,而是说像熟悉发布计划等等,就是有一些我们小的细节在里面。

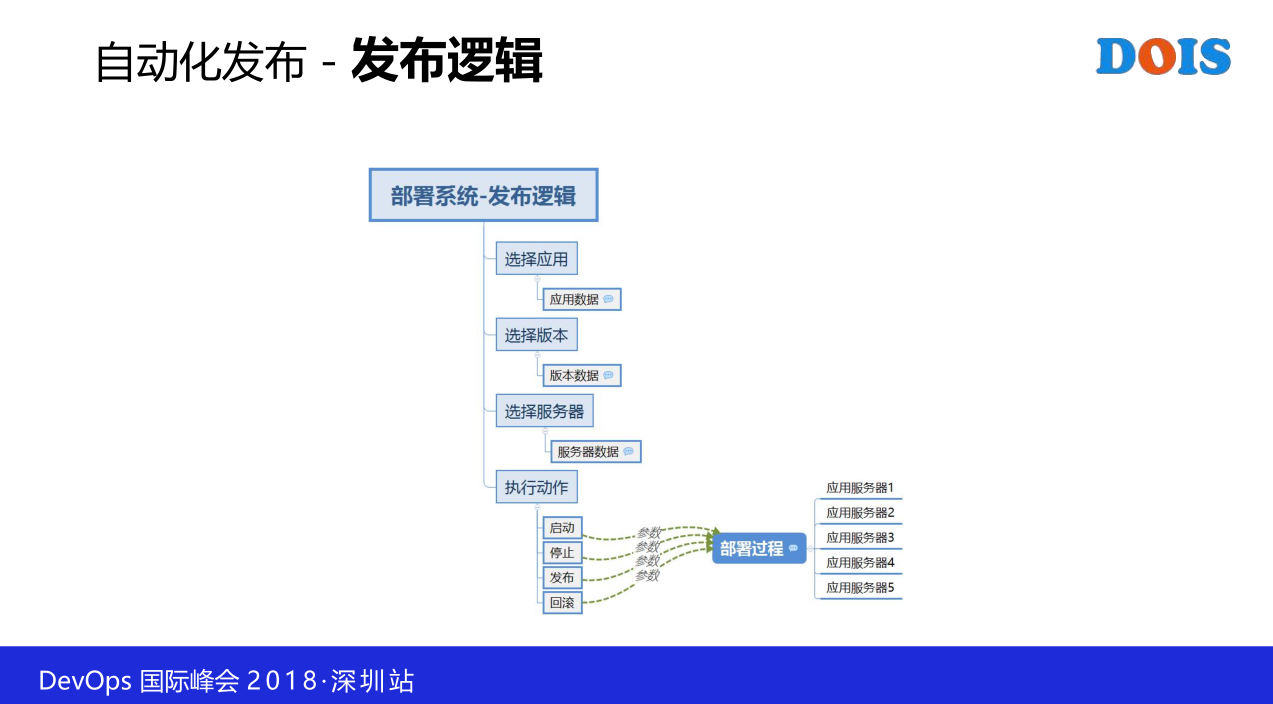
然后在具体的这一个发布上面来看,就是前面我们更多考虑生产,然后完全不关注分析生产的情况,因为我们的制品库的来源很简单,来源就是一个FBB库,或者是给我就是一个地址,或者给我的是一个仓库的地址。我的发布在实现上面也可以很简单。整体发布就是说我要先选应用,就是我要发布什么样的系统,然后我选版本,我要发布的是哪一个,然后我接下来选我发到哪个服务器,最后是执行动作,是发布还是停止。这里有一些细节的东西,有的时候我们遇到不是这一些动作,他只是想把这一个包放在服务器的某个位置,别的什么都不做,这一个都有。所以在发布上面会根据企业的实际情况实现对应的功能。
这一个是我们自研发布系统的截图,这一个应该是分辨率的问题,这一个原图很清晰的。比如说中间日志这一块,我们可以快速看三类的日志,一个是Jenkins的日志,这个日志就是可以看我布署的过程,因为它自身有Jenkins。然后我也要看我外部容器的日志,这一个容器会告诉我这一个tomcat容器启动的情况怎么样。然后我们日志的规范,这一个约定的里面呢,所有的输出不会直接输到Kibana,而是我们自己定义的额外的路径,所以我的应用系统工作是否正常,也有另外的应用日志的路径。所以即便查日志都有不同的方式。有点繁琐,但是实际用起来发现很爽的,就是确实要解决痛点,你要看什么一点,一下揪出来,特别的高效,用起来是这样。
我们起了很好的名字叫泰坦,内部还很响亮,外部不响亮,那我们持续做,我觉得后面做了一些时间,有可能外部觉得这是一个好系统。
2.6 自动化发布和运维
讲到这里,废话说完了,要进入最关键的环节了,我觉得我们做的这一部分,如果单纯看这一块的话,其实和传统的大同小异,仍然没有太大的差距。这里我们额外做了什么,我们在做自动化的发布,尤其是响应线上快速布署的需求的时候,我们不仅仅是War包,你的War包解决不了问题。尤其是考虑我们是一家年轻的小银行,然后三天两头上新系统,上新系统要有服务器,所以我们要考虑把我们的虚拟机也管理起来。所以我们研发我们得自动化运维装机系统。然后可以快速地把我们资源管理起来。平台化的,就是虚拟化底层是什么不重要,不管是vmware,不管是KVM都不重要,反正通过这一个就可以快速初始化机器。然后我有了机器,我就能做布署吗,其实不是,你要管你的缓存,要管你的数据库。

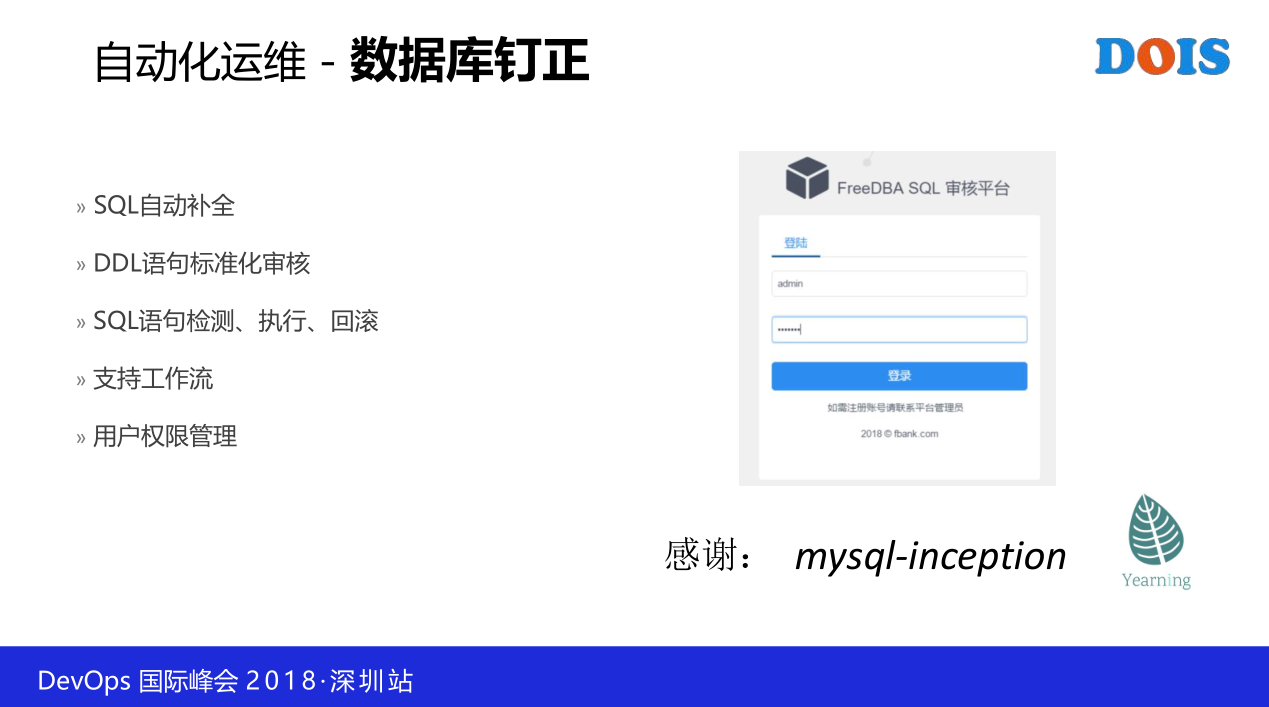
刚才有朋友说我早就不搞数据库了,然后我们同样的,我们针对数据库方面做数据库订正的系统,我们为什么需要这样的系统,你可以想想传统的DBA怎么样去响应需求。一个新的业务,然后给你提了一串的sql过来,没有打开发现几百K, 没有打开就是发现几百K, 打开了一看发现一时半会儿根本读不完,企业的内部,尤其是像我们这一种有专业DBA坐镇的企业肯定是有严谨的数据库设计的规范。但是你看一个几百K的文件,你肯定也是懵,这个怎么看,这一行一行地看,不知道要投入多长的时间,很苦恼,然后也很累。
那怎么办呢,我们通过自动化数据审计的平台,我们把这一个规则放在这一个平台里面。比如说你的数据库设计,你能用什么的数据类型,比如说我们内部要求是什么,只有int等等,有限的几个类型,凡是不是这一些类型统统提交不了,就是基本上我们DBA不会碰数据库,或者不到命令行,就到这一个平台上面,那开发人员在这里面提交他要的sql,不管是建库的,输出的,在我们这一个平台上去执行,系统根据我们的规则来检测,你要修改的列数行数有多少,你的语句有哪些不合法,不是执行会报错,执行报错肯定会报出来,也有一些不符合我们规范的罗会被列出来,来去简化人工要做的审核工作,那么我们的DBA在这个平台上面,就是流程提交,如果能够顺利提交,代表着什么,代表着通过了我们第一道初始审核,就是能够帮我们介绍大量原来靠人工,要有经验的工程师来去看、去分析的过程。
然后进入到第二环境是你的设计是不是合理,比如说你的索引创建了没有,或者索引创建的优不优,它主要关注这样的细节问题就可以了。然后对于像数据修订的话,他基本上看都不用看,他可以点审核。那在这个平台里面,同样工单很重要,就是我们通过工单的设计,把大部分的工作放在开发来执行,然后对于运维体系的团队来说呢,他们只要点审核,审核完了之后就可以执行了。在限定的时间内。
为什么这里要写两个感谢,因为一个方面是底层支撑,所以我说我们团队内部有大量来自互联网体系的,我们也在深度地使用一些互联网开源的技术,就是因为我们底层实现是基于两个开源的解决方案。分别是来自去来自去哪儿团队的mysql-inception和一个爱好者写的,有点不信,近期闭源了,就是代码你看不到了,但是我们还是很有幸,我们接触很早,然后给去哪儿团队也有之前的接触,我们还做了一些工作,不管怎么样,这样一个系统确实帮我们解决了很多问题。我们是在它的基础上做二次开发,所以表示感谢,当然也希望他发展得更好,不管是开源和闭源我们都支持他。
然后是数据库订正,然后你订正完了之后,你还有其他的需求,比如说RAC的管理,对,就是RAC同理的,只不过我们胶片里面没有体现,我们基于是搜狐来去管理,同样我们不会动到系统里面去。所以从资源的申请到整个管理机群的监控等等,都会基于平台化的方式,你要扩展机群,你要做切换,都是在界面点就可以了。
你做完了之后,你上线发布,或者是你在实际去投产一个版本的时候,你数据库初始化完了之后,并代表工作就完了,比如说你的配置要做变更,我们前面讲了,我们引入了一个配置的中心。这里感谢写成的携程的阿波罗,配置中心开发体系的同学大家都熟悉,我们最终选型没有自研,而是基于携程的阿波罗来去实现。这一个配置中心呢,这里面不是介绍他的功能或者给他打广告,而是介绍我们的这个理念。我们所采用的这一些中间件,不管是自研的,还是使用第三方的,我们由一个重要的要求是什么呢,里面一定有工作流的,有工单这样的。就是这一个事情谁来做不重要。谁来提交才重要。提交完之后,流程走下去,怎么确保他执行的结果是得到正确的响应才重要。平台来去确保,只要你提交的检测是正确的,我一定能帮你执行成功。或者是如果执行失败了,如果执行失败了,我会帮你回滚成功,然后回滚成功,或者是执行成功,我一定帮你把这一个信息同步给你,让你在第一时间知晓。我们关注了这样一个层面了之后,其实大部分的工作不用再到数据中心执行了。

我们更多的关注是什么,我们关注的是这样一个平台,需要多少人去维护它,我们的理念是一个人去运维全部,这是我们想做的,而不是一堆人去维护一堆的系统。就像前面讲我们说标准化,比如说你在想这样一个例子,你的团队要管oracle数据库,你要管mysql数据库,你要管sqlserver数据库,要管docker,那你靠一个人行吗。如果不行,你养四个数据库团队吗,这一个成本怎么去考量。然后成本当然不是我关心的问题,钱又不是我出,但是管理你要去考虑,对不对。所以一系列复杂的问题,我们想通过标准化各种各样的手段来去把工作尽可能前置,这一个运维体系,这个运维体系,或者是数据中心,数据中心的人员配比再怎么高也比不上开发,这中间总归有一个比例的。比如说开发跟测试是十比三,或者是十比几,跟运维来说比例可能一般更低一些。那么如果我们能把前置的工作做得到位,我们就把前置的资源用到位。我们的人更多做什么,我们就做平台的保障,平台来保障他的执行不出错。只要做到这一点,谁来执行还重要吗,可以开发来执行,可以运维来执行,可以配管来执行,谁来执行都不重要,甚至审批是谁,领导来审批,领导来执行都可以。因为执行就只剩下了一个按钮,这是我们的理念,所以我们前面一系列的工作都是为了保障这一点,而不仅仅是做了一个发布。
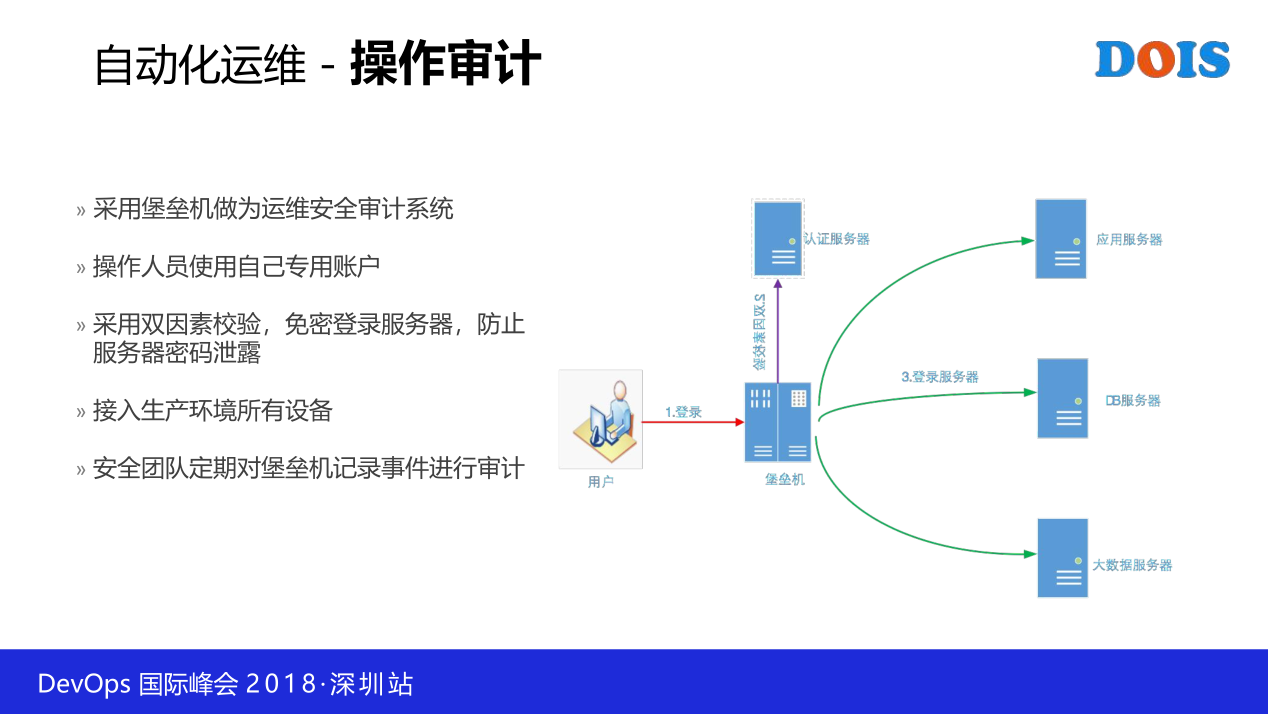
2.7 安全审计
考虑到我们是金融体系,所以我们保护还是有漏洞,或者有后门,有的人要搞破坏,我们也不担心,因为我们有堡垒机,我们有操作审计,我们有专业的人员以不定期的、震慑方式告诉他们,你做的每一件事情我们都知晓。然后通过这一种方式,对我们平台的使用也比较大胆地敢去运用,就是我们可以把前置放得更强,甚至有一些我们真是把执行的权限交到了开发团队。就是我们的响应人员,我们只是审核他要做的操作,同意了之后,所有的权限都交给具体的申请人,他可以选择在任意时间做这样的事情。那么这一个时候确实在整个支撑响应上,数据中心在这一块是要轻松一些,这是我们在这方面要做的事情。
讲到这块,还有一个点,DevOps是一个持久战,就是不要妄图通过一个工具或者是平台、软件就能解决,不是这样的,一方面呢,它的主要目的是交付赋能,是为了快。然后于我们自身来说是偷懒,我们干得快一点,少干一点。同时呢,你要考虑企业有很多现实的情况,你看哪怕是我们成立才两年,比较的年轻银行,我们有一些历史包袱,有一些历史包袱不是我们的原因导致的。比如说我们采用的银行软件,就是监管层面就说只能用这个,这个厂商都十都年前开发的,开发人员都没有了,只剩下一堆授权。我们也没有办法,也得买啊,他什么都不支持,我们也搞不定,就是对于这一种存量你要怎么搞,其实你是要想一下的。所以这是一个持久化的过程,对吧。

然后DevOps需要一个需要强有力的保障团队,得有懂的人,还得有执行力,有推动里的人,然后过程中也需要一些技巧,然后保障你的思路被贯穿下去。这是我们在这个过程中使用的工具链,这个没有什么神奇的,我觉得不用牌照,基本上都很常见,就是我们没有用新奇的东西,我们就是组合,就是组合搭配,希望把它用好,仅此而已。

3. 我们接下来要怎么做
我们现在要做,以及将来要做什么,现在在做的,毋庸置疑的,其实前面的这一些截图,为什么截图不敢放太多,我们很年轻,我们有不少的东西很土,我们持续不断地完善我们这样的平台。比如说前面有一堆的系统,这不是我们的目的,我们有一个大Platform,尽管我们线上有用户管理,我们去搭建,但是其实系统很多,在操作上面有一些不便,但是比纯手工还是要高效一些,所以我们持续不断地迭代、迭代我们的软件,提高它的体验是一方面,另外就是功能,就是我们已经迈过了从0到1,按照我们的这个理念呢,其实现在还是极大地解决了我们痛点的问题。我们仍然有不少新的痛点,这一些痛点将来怎么做,就是我们将要面临的,就是我们这里讲的,又遇到痛点了。
发布功能仍然很弱,这个不说了,它要持续不断地完善,同时也有很现实,也很迫切的一些需求。比如说绘图发布,或者是我们的应用系统,比如说自身不支撑多租户,但是我们快速商量的过程,这一个又需要系统支持这个,支持那个,我们在现有的场景怎么搞呢,把一整套的体系从基础设施,然后到上层的应用层,然后包括网络设置,全面复制一边,重来一边。即便有一些自动化的方式去支持,还是很吃力,对吧。那么我们能不能做一些改变,如果是让运用层直接改呢,当然是一种方式,但是应用层开发团队一评估,明年12月份应该差不多,你当时就很崩溃,你现有的系统改造怎么办,求人不如求己,可能我们在这方面希望通过这一种系统工具的应用来去解决这样的问题。

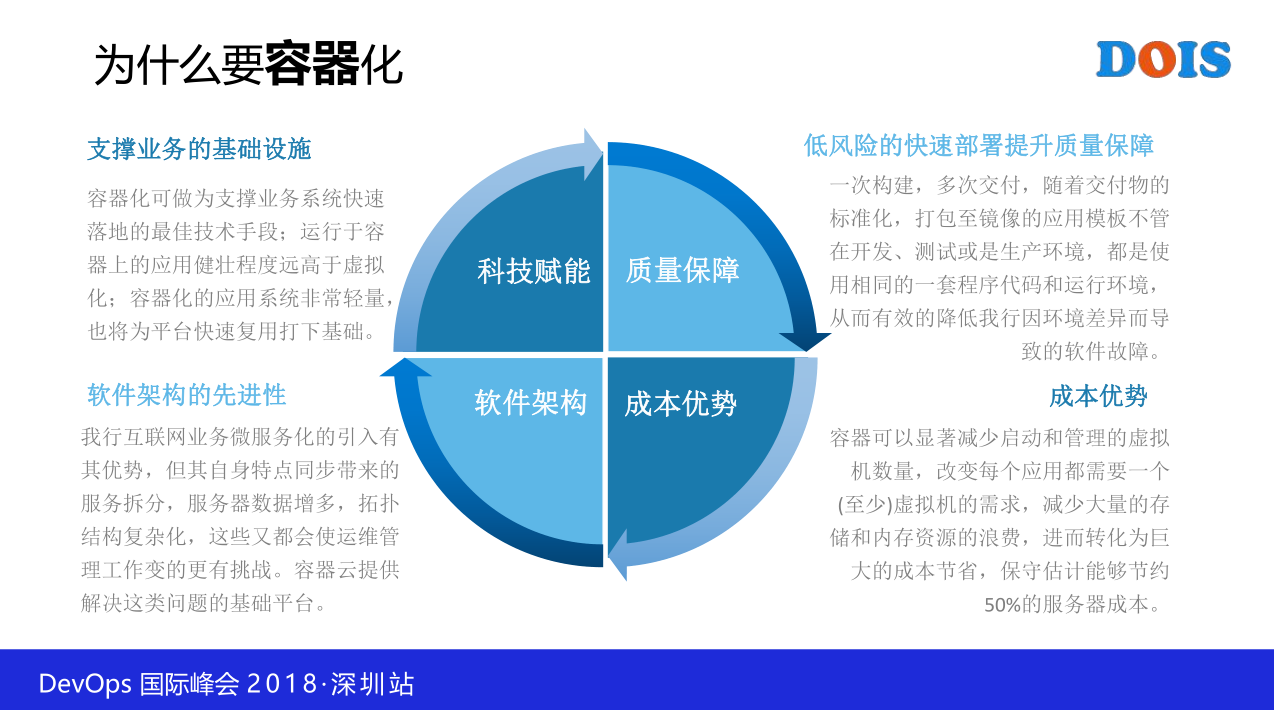
然后我们的目标是什么,容器化,这一个不用讲,对,各家不一样,但是其是目的一样,我要上容器,怎么编程自己去想。
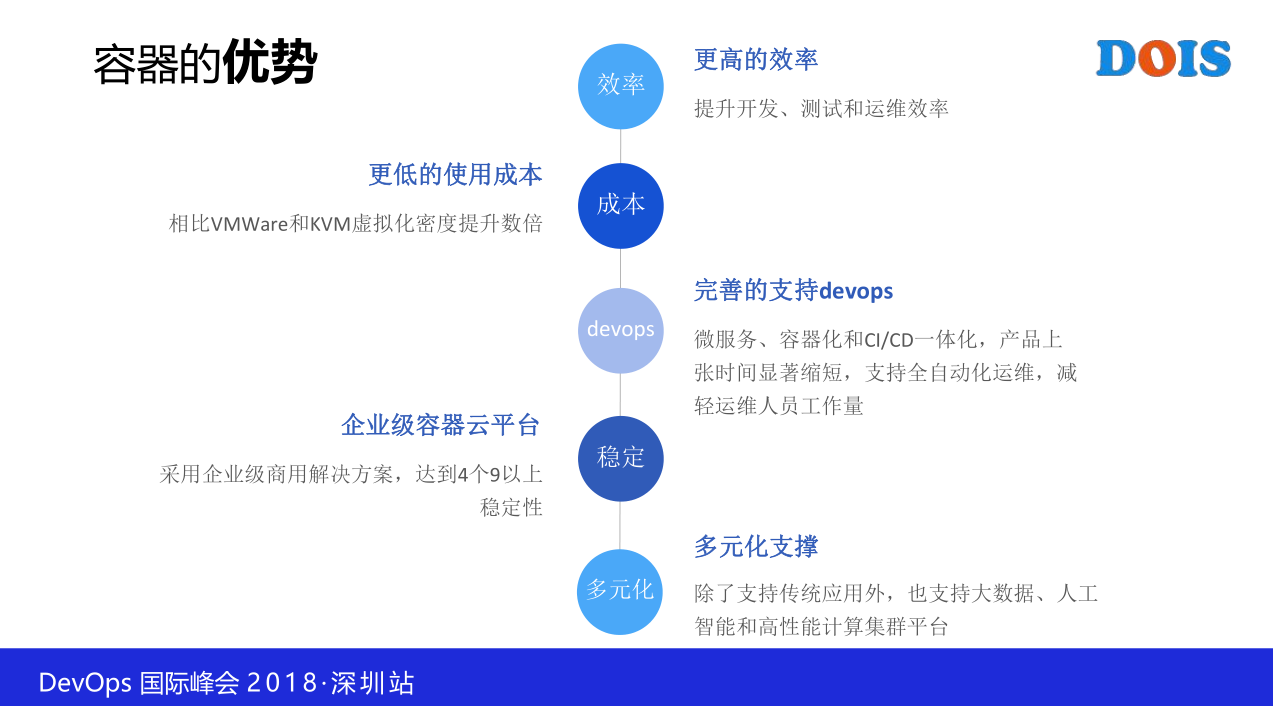
然后优势这一个可以抄一下,每一个我们花了不少的心思,每一个点都想过,这一个效率快不说了,快很多,前面这一个李晓璐说用了上亿,我们没有用,但是我们对容器很熟,我们团队的人很熟悉,不是我们的企业。
然后使用成本就不说了,比如说容器里面,比如说像虚拟化生产环境能做到1:15就管理得很吃力,容器轻轻松松1:50,甚至1:200都见过,所以它的密度肯定是不一样的。那成本有可能不是我们的痛点。支持devops,像前面提的什么版本管理等等全都不存在,因为我是基于镜像,我在自动环境打的这一个镜像,然后到生产一定还是这个镜像。
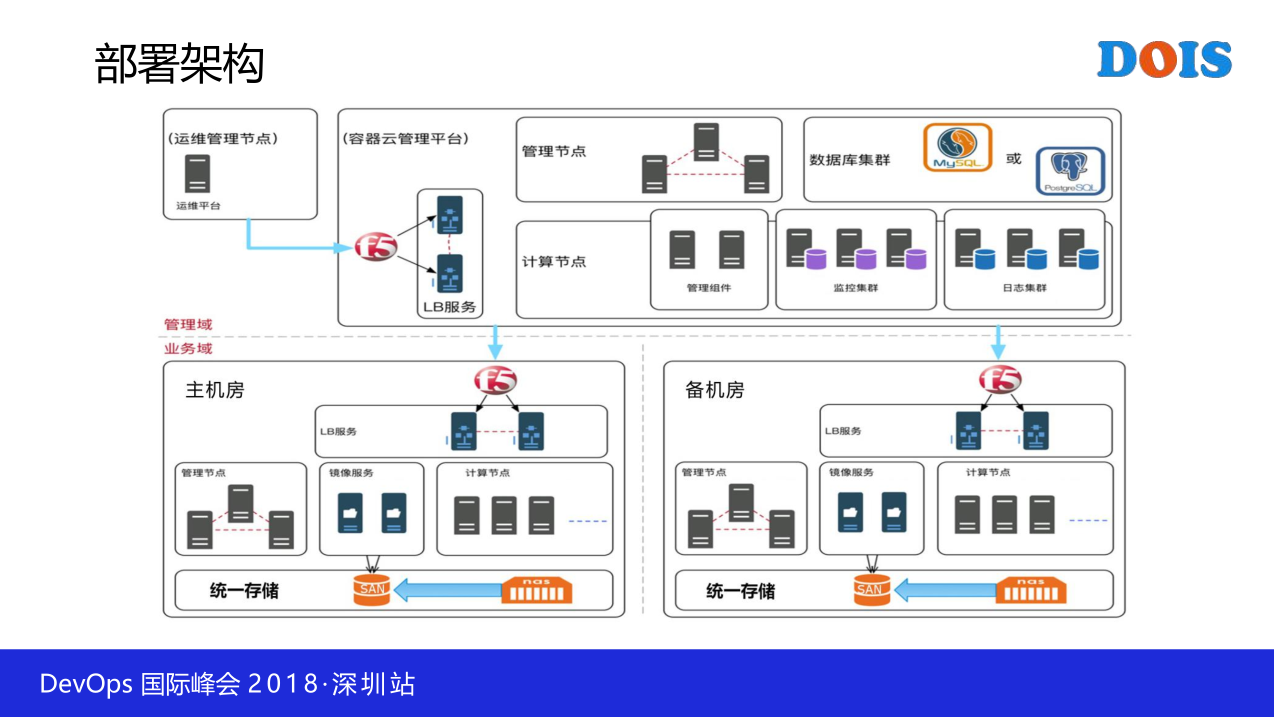
那就可以确保他可以是同样一个版本,那可能有一些痛点就不存在,而且你考虑到想K8S这样的平台框架,它原生提供了很多的功能,比如说像灰度发布,金丝雀等,已经很好了,甚至像多机房,我们解决起来费老劲了,然后找各种厂商去执行,其实你机遇容器云本身就已经很好了。然后你系统出现故障,当了一个虚拟机,当然我们现在宕虚拟机不用怕,完全不担心,宕物理机都不怕。但是你基于容器更简单。你当几个节点,容器自己帮你提起来了,都是一系列的好处。然后这是一个部署架构,其实我觉得这一些不重要。
那我们真正想做的是什么,我们ServiceMesh,你可以去考虑这样一个问题,就是始终会有一些老旧的应用,对不对。那你考虑一下我们现实的需求,比如说你的限流,你的服务发现,你的服务注册等等,对于一些老应用,就是前面讲的,厂商都是十年前,哪听说过微服务,完全没戏。怎么办呢,我们完全可以跳开它,ServiceMesh就把它可以了,我不管你是什么样的系统,所以我们想给传统应用插上微服务的翅膀,我的介绍就到这里,谢谢大家!