@gaoxiaoyunwei2017
2021-07-29T07:34:54.000000Z
字数 4344
阅读 2159
数智万物下,重新思考运维的价值
未分类
作者简介
彭华盛,广发证券数字化运维研发负责人
先做个自我介绍,我是广发证券负责运维研发的负责人,有近十年的金融工作经验,也在银行和券商工作过。现在是两个宝宝的爸爸,平时写点东西,会带娃。当时二娃出来之后功课比较重,所以写的没那么频繁了。
今天我分享的话题主要分三点。第一是数智万物时代,第二是IT价值传递,第三是运维价值创造。
前面两个老师讲的是案例,今天我尝试和大家以聊天的方式来讲这个话题。我讲这个话题,是因为我在前年做了一年的项目,做完项目回过头来看运维有很当感触,所以选择了今天这个话题。

数智万物我举五个一例子。最左边是数字孪生的图,这是工业4.0,是NASA的杨平提出的,火箭运维比较重,后来NASA没有把这个论文以后实践,第一个实践的是美国的五角大楼,他们在运维上装了传感器,在飞机执行回来之后在上面就可以看到飞机运行的情况,这和我们运维很像。
第二是数字口腔,这是我经历的一个故事,前两年我牙痛,去医院是数字口腔中心,我很感兴趣,和教授聊了一下,现在把口张开之后,他们进行扫描,然后做了一个三维的口腔构造,接下来进行构建模型,用3D模型打印出来,以前是一周,现在是一个小时就可以做完。
向下是我前年去华为的时候,华为介绍了在深圳龙岗的数字城市的智慧大脑,这是智慧城市,把城市里面的一些信息通过数字化,通过3D描绘出来。右上是滴滴,它是把每个人的手机,手机是一个强大的传感器,它通过传感器把乘客变成数字化,司机也变成数字化,再结合数字地图,就形成了一个出行的数字世界。接下来你会发现以前我们的管理是绩效管理,是人和司机做交互,现在是平台直接来管司机。最下面是MBank,这是波兰的第三大银行,它的母公司也是银行,创建了这个品牌,做了几年发现母公司垮了,后来做战略转型的时候,就把这个名字替换掉了原来母公司的名字。这是在数字化转型中,子公司颠覆母公司的案例。这些案例在我们的运维里面也是很像的,我们运维一直都是在和机器、软件和人在互联在一起。
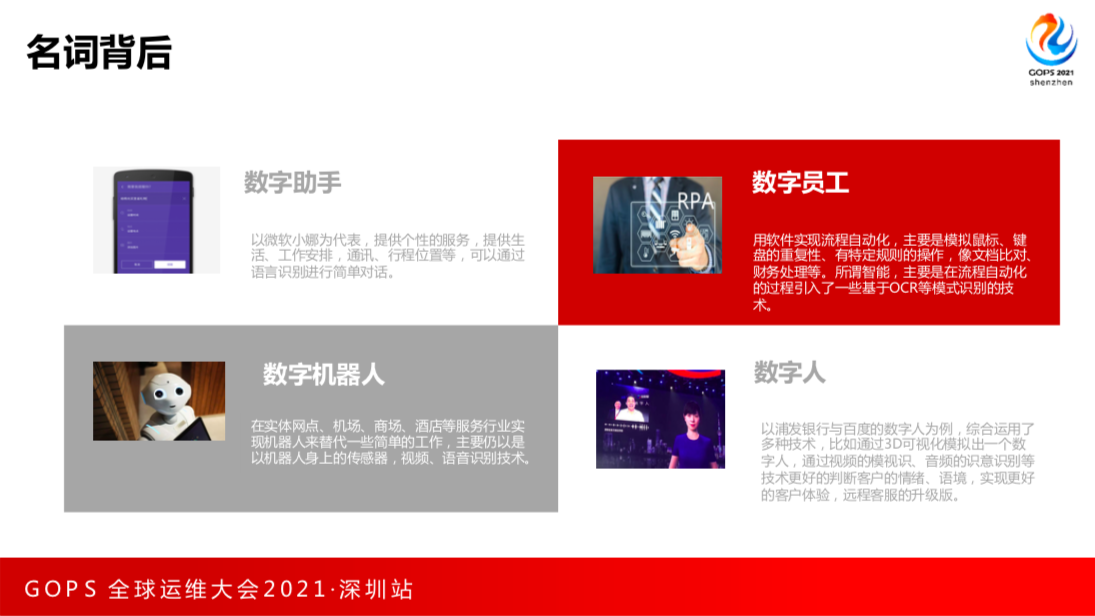
我们在做项目的时候经常有焦虑感,外面同业经常喊数字助手、数字员工、数字机器人、数字人。我们老板也经常问他们在做的数字员工是什么东西?我尝试理解一下。第一个数字助手,就像微软小娜一样做数字管理。数字员工大部分是RPA,是用软件实现流程自动化。数字机器人可以给我送牙刷。数字人是一通过3D方式模拟一个人。这些并不能完全简单数字化。
从技术角度看数字化有四大关健词。第一是协同网络。我讲四个关健词,是因为后面有一些案例。强调连接,企业内外的人和机器连接起来。数据智能强调数据,不仅仅是我做一个报表,更多是做一个闭环,是做数据洞察,根据洞察做一个决策,最终还是要执行,有一个闭环。三是员工赋能,前面讲应急,在我们企业专家经验优于工具,所以我们在运维工具化建设的时候,要更多考虑员工,可能一些小事就会对他帮助很大。第四是一切皆服务,例如IaaS、PaaS、SaaS的验证。

提到今天的主题,就是价值变化。原来我们在做是以投资回报率指标来做,就看投入多少钱能够赚多少。现在数字化之后发生了变化,更多是让客户成功。我昨天和一些厂商聊天,他们说客户成功了,自然而然企业就成功了。所以企业就讲要提升客户体验,创造客户价值,这是他的价值。要加快业务的创新以及一给运营提质增效。我讲价值,是我认为价值是一个传递的过程。
2、IT价值传递
价值传递过程是我老板提的,我们要关注这个项目是否和公司的价值是贴切的,价值是传递的,是公司价值传递到IT价值,再传递到运维价值。这样我们看到做这个项目不是内卷,不是内部一起做管理创新或者其他方式来做这个事情。
我尝试讲一下。过渡到企业价值有三个价值,回到IT应该变成了安全稳定、快速交付、技术引领。IT这三个价值画下来要做一些事情,一是IT风险保障能力,二是客户服务能力,企业一直在讲提升客户体验,IT要以客户为中心,给业务、运营提供感知、决策、执行的服务能力。三是快速交付,我们怎么解决这个问题?这是整个IT要考虑的问题。四是生态扩展能力,生态必然是未来的一个方向,IT如何把这个能力为业务和企业赋能?五是IT服务能力,提升IT服务效能,灵活弹性、安全可靠的技术基础资源交付能力。六是运营协同,有一次老板和我聊天,在IT领域,业务部门就是农民,他想把麦子做得更好,就提出需求有一把锋利的镰刀,我们IT部门需要把懂的知识给他提供一个收割机,这才是我们真正需要的能力。我们要用专业知识构建数字化攻坚,做成武器装备给他。
价值传递,一是增强IT风险保障能力,二是加快业务交付速度,三是提升速度,四是保证质量。
3、运维价值创造
运维复杂性,我简单总结了八点。包括技术架构,新技术选择时机,像云原生进来了,我们的运维有可能量大了,而且知识体系也发生了变化。技术成熟度、对忖量技术架构的影响,以及新技术附带的选择成本等。还有应用逻辑、变更交付、海量连接。操作风险,工作量越来越大,自动化服务器的引用可能会产生风险,可能风险更大。还有协同机制,DevOps、一切皆服务、SRE、ITOAAIOPS概念。
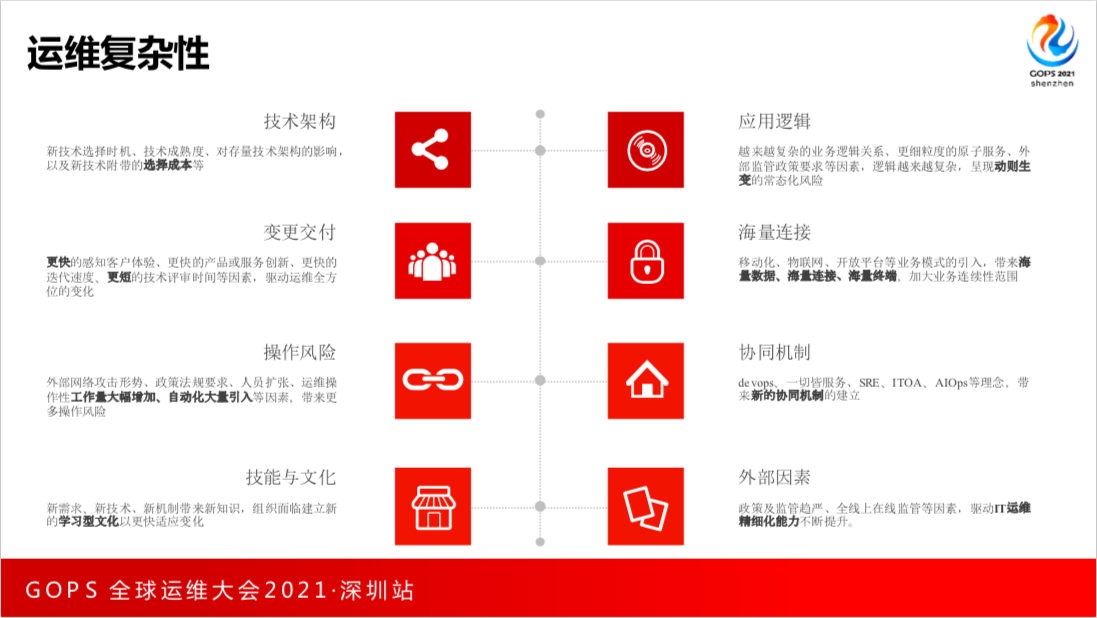
面对这个复杂性,运维要面临挑战,是想如何设计一辆不用停车的高铁。中国高铁以后也想设计永不停车的高铁,这很有意思。我们要进化为更加适应数字化时代,持续的稳定性。适应并赋能企业转型,不确定性能力要驾驭。
我们在做一个事情,我们经常和财务沟通时遇到一个问题,每天在做安全投入,做运维,什么时候才能做完?我们要告诉他一个事情,运维能力是持续提升的,因为运维复杂度是不断变化的。这是亚马逊的观点,建立运维复杂性适应性系统的增长飞轮。
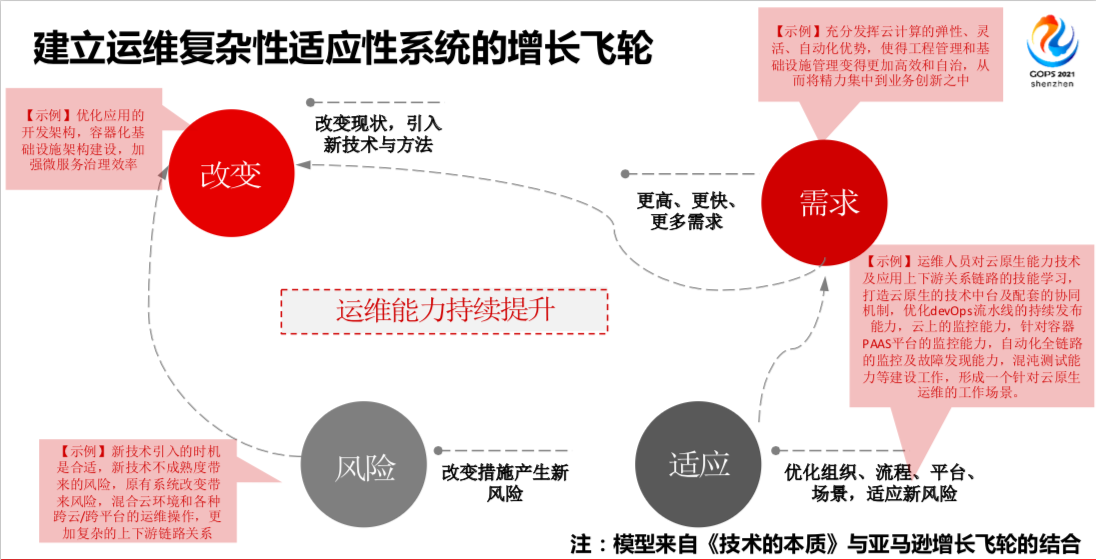
任何一个点都可以开始,比如以需求开始,我们可能面临更多更高要求,更快的要求。运维需要适应这种需求需要引入新的方法,就会产生新的风险,我们就适应它,通过组织、流程、平台和产品来适应它。例如云原生,我们肯定要充分发挥云计算的弹性,自动化,工程性的管理,来更好的适配我们工作,给我们赋能。
接下来我们需要优化开发架构,容器化、基础设施建设、加强服务效率。
做完这些改变之后,自然而然产生风险了,我们引入技术不成熟带来的风险,可能还有选型的风险,还有上下游链路变得更加复杂了,这都是给我们运维带来的风险。遇到风险之后我们需要做很多事情,做平台,做流程的优化,做一些岗位的培养。这是我们运维应该做的事情。

运维四个价值。增强IT风险保障能力,由原来的保障业务连续性,扩展到保障“业务连续性、数据正确性、逻辑完整性”,三个层次的IT风险保障能力。二是提升客户体验,客户体验是我们运维从背锅向上移的增长点,比如我们是否可以利用运维产生的数据,给业务提供一种客户体验的看板,让他们能够更好做产品运营。三是提高IT运营服务质量,我们要建立数字化的交互模式,不止是我们,还可以给企业提供。四是加快业务交付速度。
一,增强IT风险保障能力
我这里画了一幅图,每个点的问题都会产生故障。可能这个图也会越来越复杂。每个点的问题都是能产生异常事件的,都会影响IT风险,我们IT风险的保障能力就是让每个点不断的优化。增强IT风险保障能力,我总结了一些方法。因为时间有限,不多讲太多。第一用数字化的思维连接网络+数据驱动,重塑监管控析运维平台化能力。二是以主动的运行数据分析反向推动提升应用架构的健壮性。三是加强应急管理、可用性管理能力,推动运维前移,加强应用架构非功能性设计。一四月是敏稳双态的运维模式。大家有空可以看一下片子。

二是优化客户体验
一是增加客户行为数据的收集与分析,为产品设计的决策提供辅助数据。我们可以把数据拿出来,给业务部门做一些运营数据的看板、报告。二是加强业务系统的性能管理,优化响应效率。三是模拟客户行为操作监控,提前发现并解决潜在问题。四是建立混沌工程思想,对应用系统进行改进。
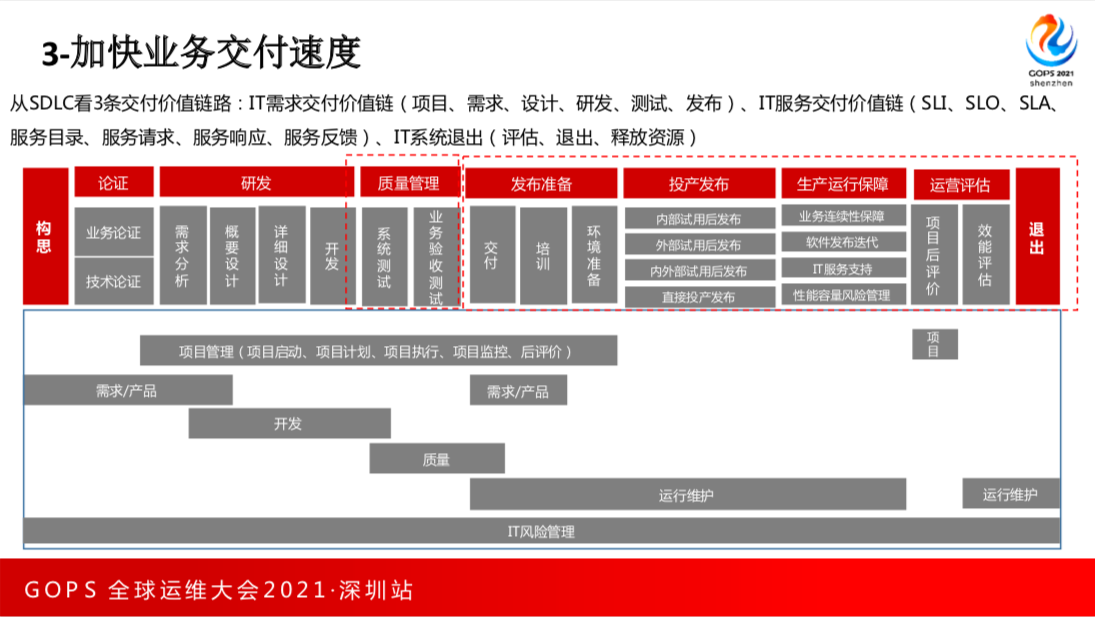
三是加快业务交付速度
从SDLC来看,交付链路有三条,包括IT需求交付价值链,IT服务交付价值链,包括SLI等等。三是IT系统退出。我们系统之上不下,我们如何让它通过数据的方式发现系统能力运行的效率低下,推动系统下行。
基于IT交付的速度,对于运维来讲,一是要用运维掌握的数据、工具,来去感知系统上升后的情况,感知新业务上线。三是CD,三是混合云模式,四是做好SDLC退出的事情。
四是提升IT服务质量
一是建立IT服务质量模型。二是建立全在线的IT交付模式。三是搭建IT服务管理系统。四是统一的服务目录。我看大家都在做,我们可以搞一个统一的服务目录。

举一个简单的异常处置场景的例子,把前面讲的四个关健词协同网络、数据智能、圆工赋能、一切皆服务,看我们是怎么用的。
我们有几个方法,第一是发现风险/问题,运行可观察。第二是通过数据洞察与决策,很多团队做完第一步就结束了,我们认为这只做了一半,还要强调复盘优化,同时复盘优化的结果能够跟进。
第一个关键字是协同网络。我们的核心是要做两个事情,一个是增加故障时间,第二是减少故障恢复时间。在协同网络上,我们以场景连接人、事、时间、协同、环境,把整个事情通过线上化把这个过程给串起来。有了这个线上化以后,我们可以做一些事情,在这个场景里面,我们把值班经理、一线、二线服务台、研发、故障机器人全部串联起来,做线上化过程。第二是数据智能。协同网络,从线下到线上,比如我们做一个视频的时候出现故障,通过机器人把所有的人串起来,让他们在IT群里做一些事情,原来运维的应急处置人员出现故障之后要打电话给关联的人,现在我们把这个事情做自动化,通过机器人做自动化拉群,就可以专注做运行。第二是平台化管理,我们把故障化告警提升效率。
第三是值班经理在故障出现过程中,需要盯着故障,故障发生之后没有快速应急,如果靠人经常会漏,因为事多。我们也通过机器人的方式来管。这虽然是小事,但是也帮助了我们在故障应急中的各个人进行赋能。下一步,我们也许可以通过AIOPS能力,要设置一些机器人工作岗位,现在机器人是做重复性的事情,我们希望后面可以做一些挑战性、复杂性的事情。
我为什么讲这个点?是因为我们发现在刚刚那条链路上面,我们在做AIOPS项目的时候,项目里面在做互相定位数据的分析,但这个时间并不是应急处置最长的时间,最长的时间是监控发生以后是否马上能应急了?有时候可能是花两分钟,如果这两分钟缩短到半分钟,效率就更高。我们监控发生以后,是否有快速有人去响应?高速把它处置掉,这个时间也很长,例如有3分钟,这个时间就占十几分钟,如果不做平台管理。我们做了应急定位,就从5分钟变成3分钟了。
