@gaoxiaoyunwei2017
2019-02-14T06:27:43.000000Z
字数 7546
阅读 1469
如何构建混合云场景下 金融级中间件自动化运维平台
luna
作者:王晔倞
作者介绍:我先做一下自我介绍,我名字最后一个词读lang(倞),我是2000年踏入这个圈子的,非常倒霉,我刚踏入这个圈子遇到了网络经济泡沫,在座的有一些同学的年龄你应该也遇到过,有些也没有遇到过,不知道这是什么东西。我做了7-8年的开发,4-5年的架构,我做过很多东西,除了微软那条线技术栈没有做过以外,其他的我都做过。

可能有的人听到什么什么公司,金融一听觉得好像特别高大上,通过今年一年大家听到金融会觉得特别害怕。对不对?而且好像听金融公司,觉得你们公司好有钱,你们会做很多事情,会大手笔。但是,我跟大家讲的是,不是这样。因为大家都知道,很多金融类企业的老大,也就是他们的CEO和创始人,基本上都是做业务出身的,做业务出身的、做金融的首先第一点就是成本理念非常强。他特别特别会算帐,所以在这样的公司做IT是非常辛苦的,为什么辛苦呢?你要经常去跟他谈成本,他也会跟你经常谈成本,但是那些人民币不懂。所以我给大家纠正一下,金融什么什么东西,肯定用的东西特别牛,安全性特别高,其实不是这样的。
我今天来讲几个内容,首先来给大家介绍一下,因为很多同学会说讲技术就讲技术,做什么背景介绍,咱们这个世界都是由客观组成的,不是你的技术用在我这边就可以的,因为我们每个人在公司解决的是业务性问题,或者痛点性问题,如果你的公司一帆风顺,你的老板不需要花钱请你来,我们很多搞技术的同学都是完美主义,你到一家公司希望遇到干干净净的一套系统,做你想做的事情,请问,是这个样子的吗?招人的时候觉得怎么怎么好,进去了以后发现很多坑。但是你根本不知道当时发生了什么,我们进去要面对很多问题,很多客观环境,案例和解决方案充斥着我们很多人的日常工作。

1. 背景介绍
简单介绍一下公司,很多人一听什么什么财富,我们公司不做P2P,我们有一个爸爸有一个妈妈,爸爸是腾讯,妈妈是联想,大家在手机上打开理财通,腾讯也是我们公司最大的股东,我们公司几年前在新三板挂牌上市,我们现在叫腾讯系的财富公司。我们不做P2P,我们是做基金的。

先来说一下我们为什么要去做中间件。我相信在座很多大家听过阿里和腾讯包括京东,很多大型公司里面听到一些东西,比如我们现在的阿里云,阿里云的前身就是阿里中间件团队,只是现在做了技术赋能和技术输出,把技术变现然后对外输出。简单一句话,当你公司变成多条业务线的时候,从单业务的业务方位变成多维的业务方位的时候,举一个例子,你又卖食品又卖其他的东西,有多条业务线,中间需要的业务产品是不一样的。大家都有交易,都有账户,所以阿里有一个叫共享业务事业群,中间又有共同的业务栈,以前我们的做法,比如说饿了么,很多的这种互联网公司,他们的做法就是把缓存作为应用的一部分,我用了任何一个技术栈,我用就可以了。
我想给大家陈述一些数据,首先我们2015年,当然2015是年牛市,2015-2018年我们公司在业务上进行了变化,先说动向,我们的接口从百级变成了千级,微服务、服务化,要做拆分,业务要发展,从单一的卖基金,到现在卖很多,我才关心什么基金,我就要知道什么业务要赚多少钱,只要安全就行了。在这样的业务变革下变出来很多组合,我的接口会有变化。第一个是变多了。
还有我的子系统会进行拆分,我们的研发团队从测试运维变成的纵向团队,把运维的部分拆掉,拆到各个团队里面去,你这个团队又有产品经理,又有研发,又有运维,你的目标就是把公募基金交易系统做好,从横向变成纵向的时候你的数量会变多,你是交易团队,你这个是账户团队,你是资产清算团队,都有不同的团队。大家都要用到一些相关技术怎么办?我们有统一的架构团队来给你提供标准化的服务,好像大家看到的阿里云提供很多的技术服务,中间我们也会用到好多的SDK,适配,穿透等各种各样,为什么?因为你的技术栈不一样,你的技术债也不一样,大家的接入形态不一样。
我们业务型也是一样的,原先我们卖公募基金的,还有卖私募的,就是百万起,高端的,像诺亚财富。还有一个就是旁边的这些数据我不去念了,总而言之大家能看到,我们好买遇到的技术壁垒和所有的互联网+团队都是一样的,你的技术栈变复杂了,你的数量变多了,你的业务也变多了,但是有一样没变多,什么东西?人。人还是那些人,我们经常说偷偷摸摸做架构,为什么金融很多老板算成本怎么算的?我前面做5个接口要用5个人,很正常。什么是架构?不就是ABC吗?不就是两张代码吗?没听懂,我就给你5个人,怎么办?你的架构要去变。

我们很多人如何看待我们的运维?第一个就是客户越来越多,速度越来越快,需求越来越复杂,要么招不到,招多不划算,招少不够用。还有分布式很多的开发和研发,分布式对于业务开发来说是非常好的事情,有非常多的优点,对于运维来说是一场灾难。我们看一个场景,我当时在IOE做架构的时候很简单,现在呢?所以我们走的方向是什么,很简单,一句话把能力赋予工具或者平台,用最低的成本交付与开发,自己玩去吧。
刚才前面谈到了组织结构也变了,不能要求每个运维都有开放的架构,你也招不到,有人我招到就厉害了,你能留得住他吗?你一共团队这么大,你给的空间是5个领导,3个总监,你往哪发展去?你发展来发展去,上面的人一直站在上面,你也上不去,除非公司有更快的发展,大家知道这两年消费在退化,很多团队不需要特别强的人,包括很多人做技术输出,你可以从他那边用便宜的价格获得好的技术服务,你是不需要的。
所以我把东西做成平台,你想哪天发布就哪天发布,你想哪天上线就哪天上线,你每个团队自己做。

2.中间件运维有哪些痛点
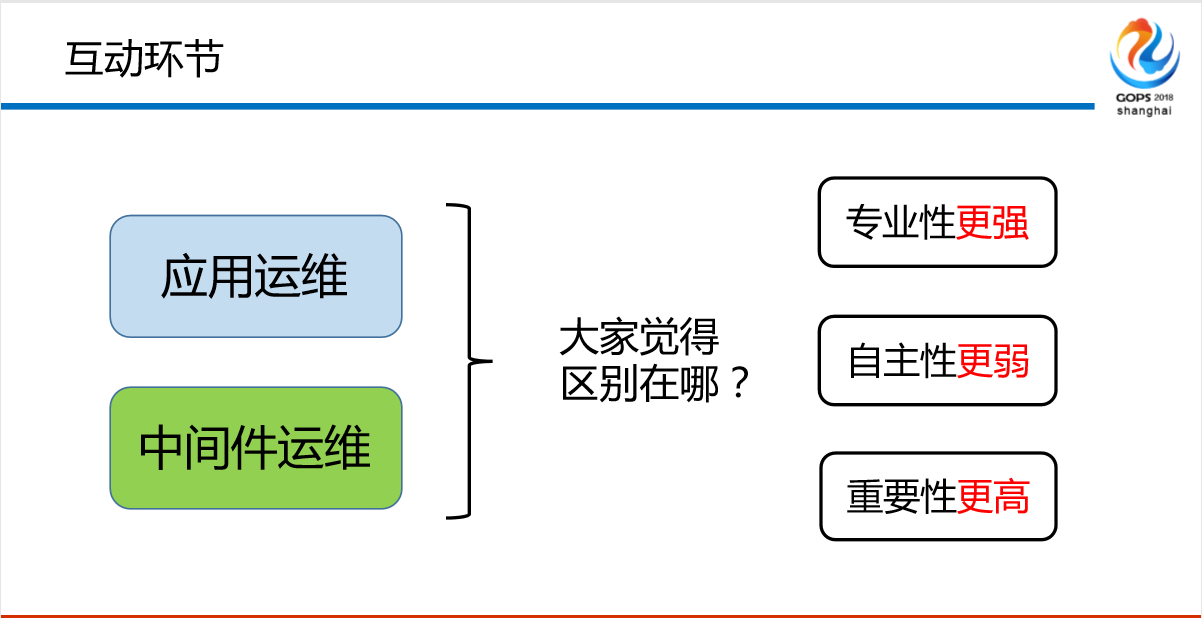
中间件运维有哪些痛点?首先第一个问大家一个问题,应用运维和中间件运维有什么区别?有很大的区别。区别在哪儿?
- 第一点,专业性更强。如果让你画一个图谱,很简单,我们不说更大的,我们从研发的视角。所有的东西都在架构里,架构是什么?就是逻辑。一堆的业务算法,就是这些东西,但是它的专业性不需要特别强,为什么?我有这些东西就可以了。因为大量的技术栈都被中间件所包含了,高可用,你也不可能招到一个运维所有的技术栈都懂。
- 第二点,自主性更弱。中间件独立存在的价值就没有了,应用不用你,你是没有任何价值的。我如果访问量很小,缓存干什么呢?我是不需要的,只要你流量大了,你的微服务做的多了,信用负载大了。我举一个例子,在我们系统里面是不是在座的运维同学遇到的常见问题就是连接池爆了,你怎么管理呢?中间件往什么样的发展,架构布成什么样子,是应用和前端应用系统决定的,不是你决定的。
- 第三点,重要性更高。我们公司最近在办《王者荣耀》的比赛,我们团队有一句口号,如果你敢战胜我,我就按一键销毁的功能。我的分布式要做一致性,消息、缓存包括我们统一的分布式调度,统一的分布系统,决定了你的系统是不是好得起来,是不是安全,你遇到高流量的时候是不是能够快速拓展,拓展的过程中会不会引起其他的故障,这全是中间件决定的。这三点区分了应用运维,我指的应用运维是偏前端的,不是IaaS。
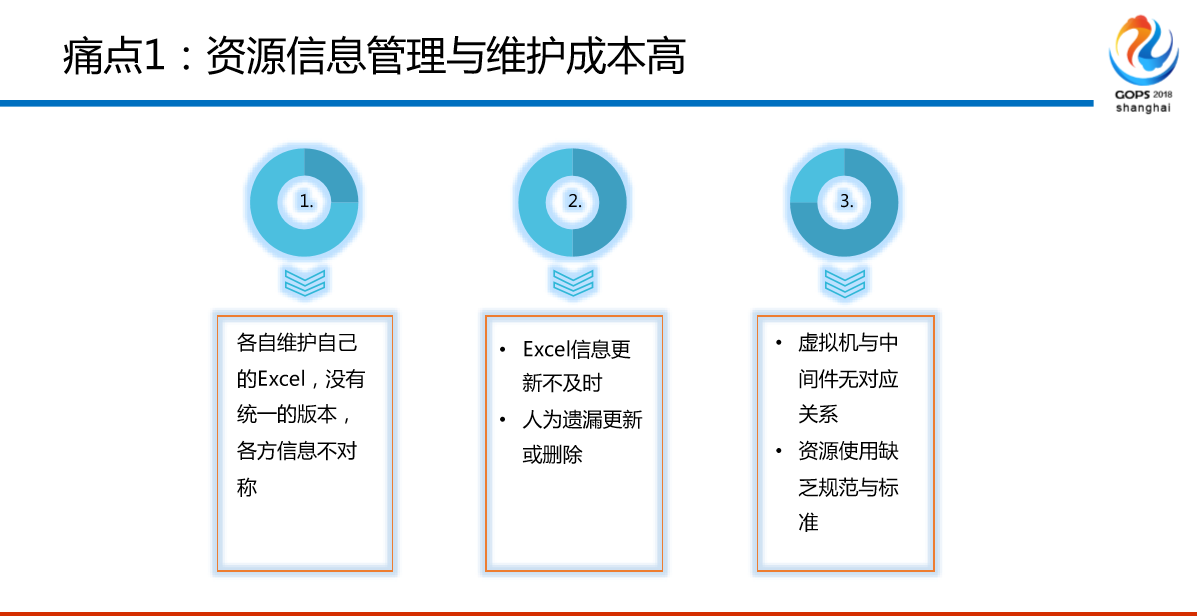
痛点1:资源信息管理与维护成本高。我们的虚拟化已经达到95%以上了,也用了超融合的架构,也是用资源池调配,但是上面的中间件转成分布式,我都是动态的。对于资源的对应情况,我用了多少资源我是不知道的,一开始不知道的,怎么办?每天统计一遍,输出一个Excel,我们一个同学一边花一两个小时干这个事,我们同学说了干这个干什么呢?老板用啊。
痛点2:就是裸用各种开源的监控,无法精准定位。很多人用Zabbix,它是干嘛的?就这几件事。请问一下,如果你知道这几件事情,你知道故障的真正来源吗?你知道应用是哪个系统引起的吗?你大部分是不知道的,如果真的是由于设备和故障引起的话,好解决。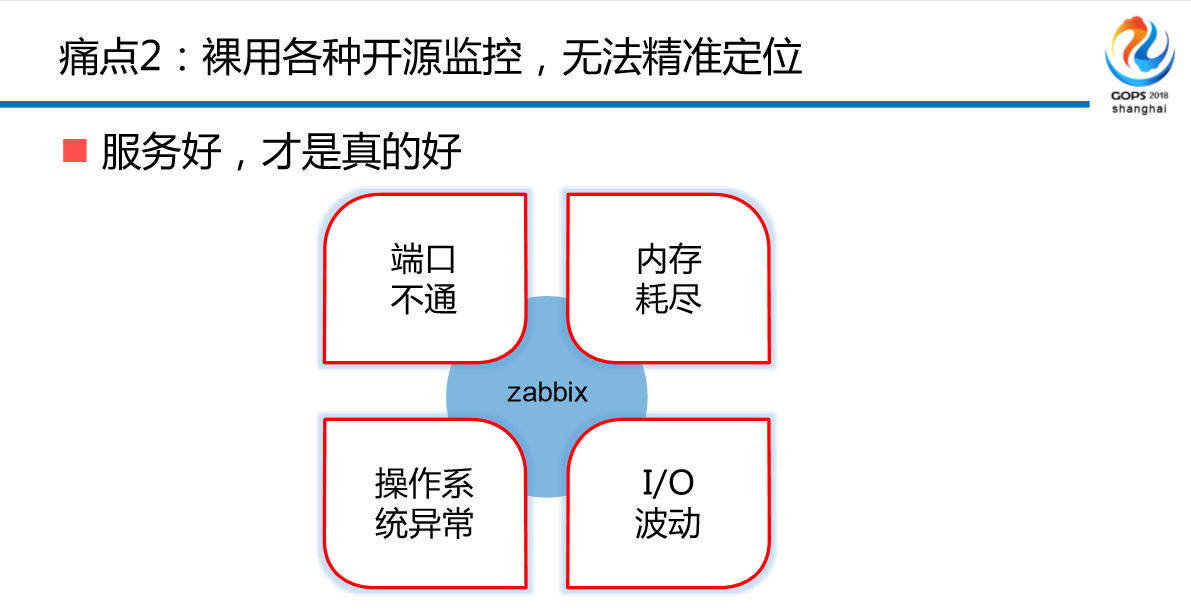
痛点3:还有缺乏短链路监控与排障手段。什么叫短链路?我举一个例子,因为我们现在采用的是运维下沉中间件团队单独服务所有的分布式中间件,这个时候当遇到故障的时候,业务端说你很慢,比如说我举一个例子,我们现在应用运维跑过来跟你说,下单超时了,你知道吗?你说我这边也很慢,这是第一反应。第二个说我不慢,我很快。就说第一种,是你的代理慢?还是虚拟机慢,到底哪里慢?大部分情况是不知道的。会怎么办?打Zabbix去查了。我们作为一个交易系统是有交易时间的,你下单的时候在2点到3点30之间出现问题了,说3000块钱不要了,你肯吗?
饿了么送外卖丢了一个东西,最多赔你一个,那个东西你能赔吗?你可能赔不起。我们通过SDK,包括我们代理层,包括所有中间件的系统进行短链路的监控,当前端出现问题的时候,我可以非常清楚定位到底哪个节点出现了问题。
看一个例子,业务说下单报错了;前台说,我没问题,问问服务报错了吗?中台说,是你没调过来吧,我连日志都没打;运维说进程都在,也没看到ZB报错;后台说,胡说什么,我这有反应,你传错了;DBA说,你叫什么叫,连数据库都没连上;运维说,傻X,MQ阻塞了,不知道都在叫啥。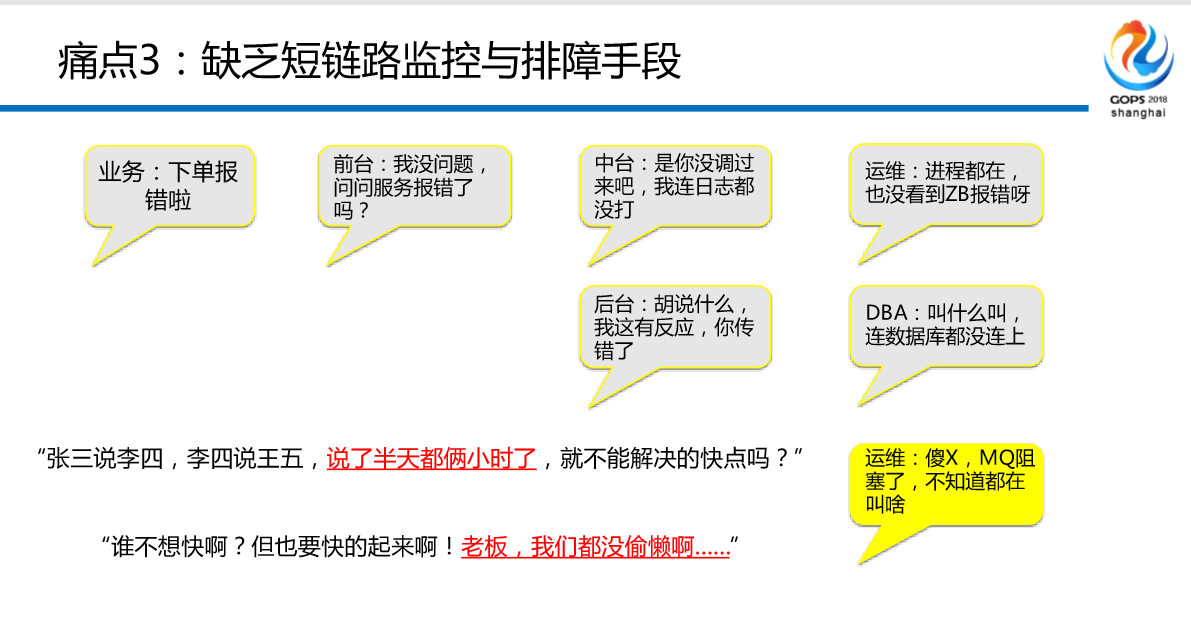
我们公司是做基金交易,如果系统出问题的话,如果今天交易因为系统的问题没有交易成功的话,第二天基金市值大涨的话,我是要赔钱的。因为你的系统导致的问题,你要赔我的,我买的越多,你赔的越多。我们公司有一句话,为什么会出问题?因为人品好。这次出问题正好在3 :05分,交易时间过去了,但是再好的人品也会刷爆的。
3.从‘人肉’到工具,我们是如何演进的?
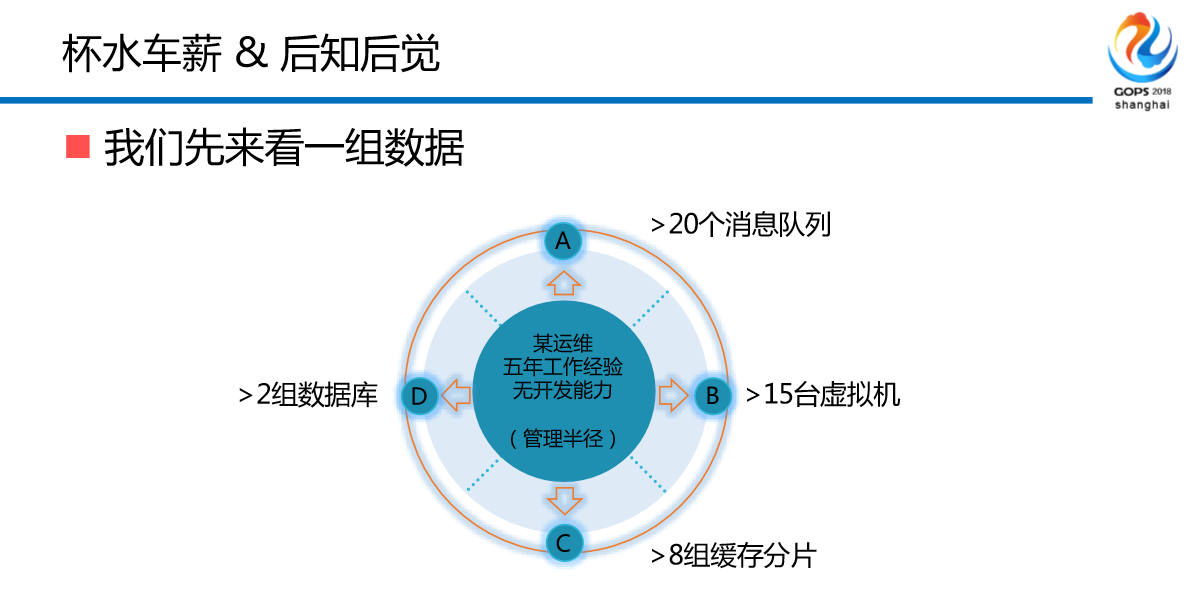
我们先来看一组数据,20个消息队列,15台虚拟机,8组缓存分片,2组数据库。你知道线上几千几百的节有点问题吗?你知道吗?你不知道,你哪知道有问题?你只知道报错了,你认为是好的,但是你的管理是有半径的,最多在显示屏上管4-5个节点,另外有没有问题,你不知道。
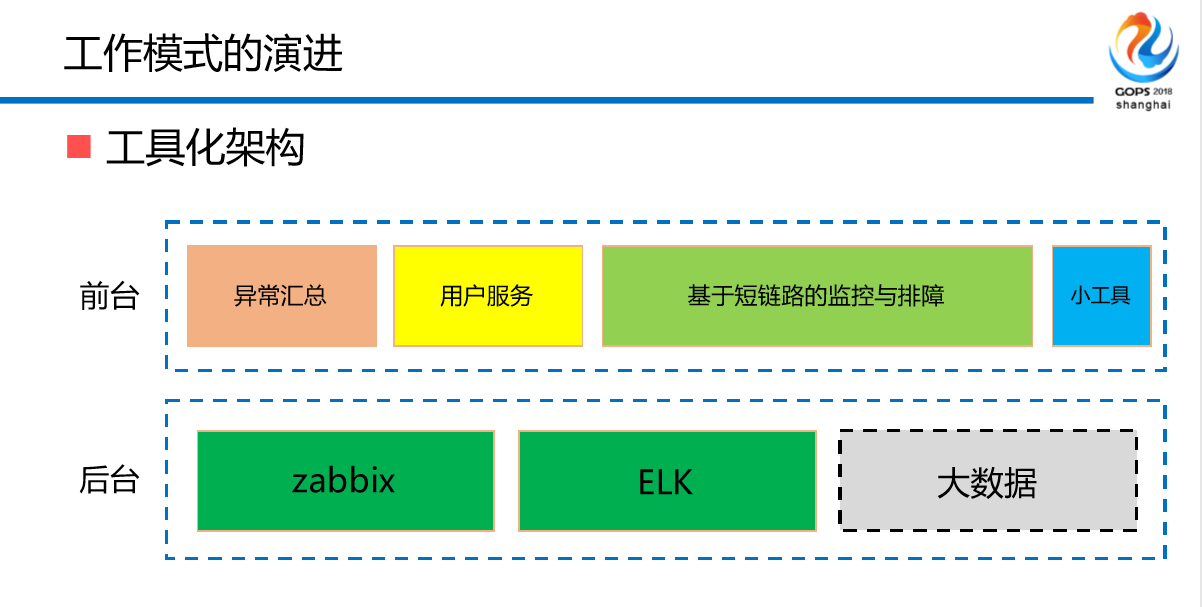
怎么办?开始建中间件的架构,前台,先异常汇总—用户服务—基于短链路的监控与排障—小工具。Zabbix做一些基础性的,像端口、CPU,它的定位为什么不好?因为它的应用没有办法进行关联。还有ELK,做实时分析。比如说我们公司的缓存某一些切片要求非常高,不允许你的抖动在交易24小时大部分时间,包括交易时间,你的抖动不允许,每一次访问不允许超过50毫秒或者30毫秒,或者说20毫秒,因为你的底层业务,每一个用户登录这个账户信息,包括交易过程当中需要账户当中的信息,交易要做很多认证,每个环节都要做认证,我不管是本地缓存,还是异地缓存都要响应,如果缓存有一定的抖动,你整个应用的长链路都要受到影响,最后就会崩溃,你的交易系统没有办法进行下去。所以说我们来解决这样的问题。
大数据做什么?做比对。比如说,我们缓存数据,它哪个K更新的最多,哪个K更新的时间最长,哪个最大,这个要比对,哪个下降了,哪个没有下降,数据的失效情况,哪个合理哪个不合理,这些数据从什么地方来,都是经过我们大数据分析得出报表得到的。
简单来说,大数据主要处理离线数据。有的同学说了,这个传统运维做不了,对,我们现在里面有架构师,有产品,有测试,有开发,有运维。所以我们现在的运维转型相对简单?因为我们传统的运维同学在跟着我们的架构师学开发,而且我的架构师是可以给我的运维赋能的,因为我是一个闭环的团队,我只需要对外输出,人性化的界面和管理控制台,并且输出各种各样的SDK和接入方式的适配器就可以解决了,这个东西不需要运维来做,需要开发和架构师来做就可以了。
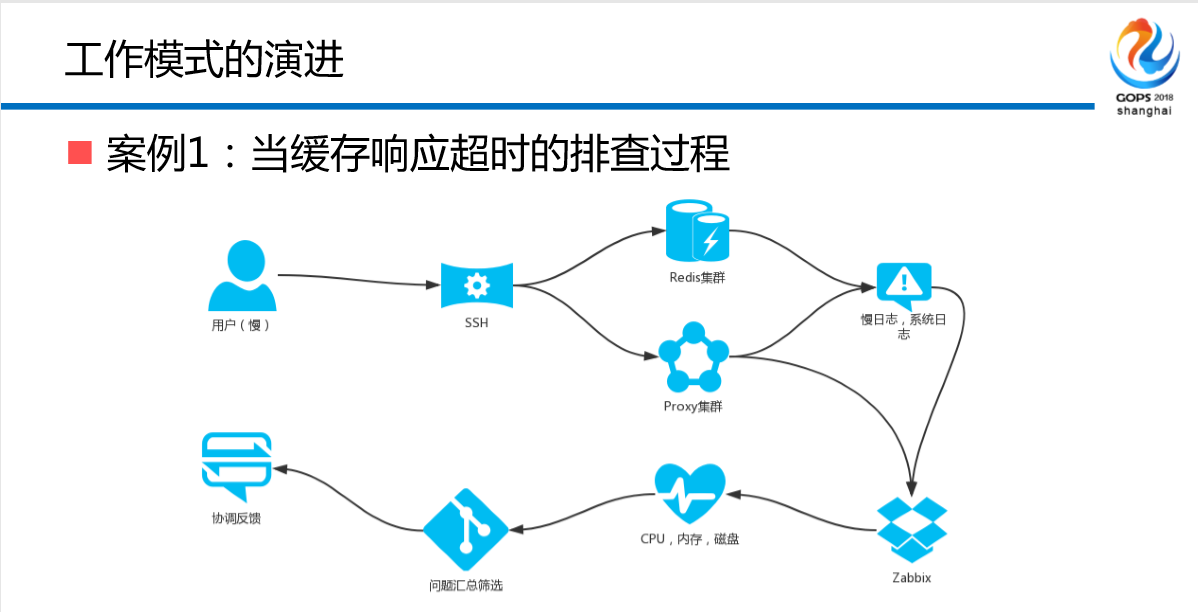
这个内容大家看得清楚,当缓存响应慢的时候怎么办?一个小伙伴连接集群,查日志,这是一个日常苦逼的运维在干的事。
案例2:当消息阻塞时的排查过程,这种情况是什么?一会儿好一会儿不好,业务说我也没有问题,前端的产品说我就很慢,我为什么这边的数据就是看不到呢?用户为什么就是看不到那笔交易呢?最后查下来大部分的锅确实是中间件的,因为有时候阻塞有时候不阻塞,罪魁祸首是消费方,他消费慢了,它坏了,但是还是要找你,你能不能不阻塞,我说你能不能消费快一点,他说你们都是技术精英,你们应该在这种烂的情况下怎么解决这个问题。你没有办法狡辩,我要拿出数据告诉他到底哪里有问题,并且把界面交给他让他自己去看。
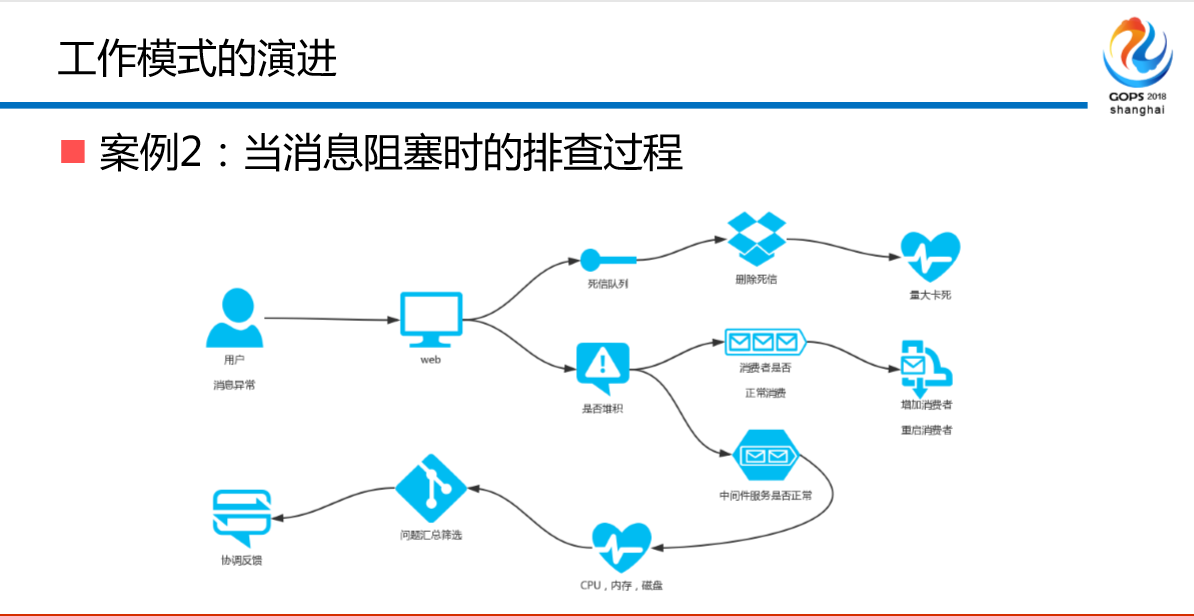
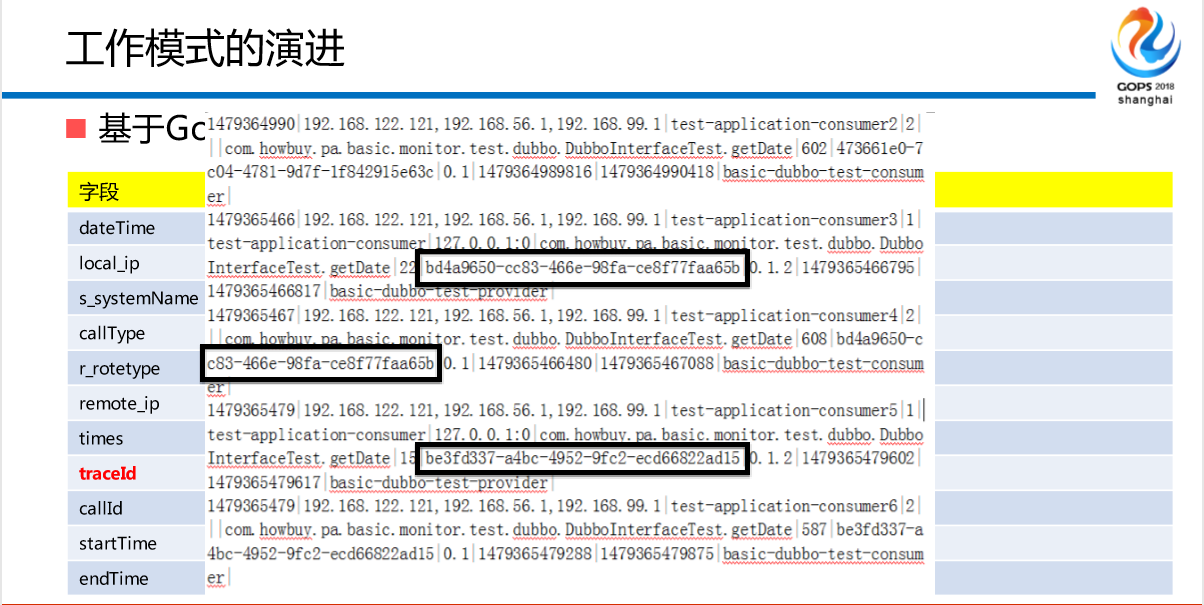
怎么演进?第一个,明确的边界、松偶合,我们帮助他们做边界的划清,通过SDK的方式。大家听过这个吗?基于Google Dapper实现的TRACE ID。你通过自己的MQ的切片、缓存的切片自己去查,不要问我,因为ABC消费B节点慢了,导致消费的速度慢了15.84,你自己去看,不要问我,我的MQ慢不慢,不是运维拼命把你拖慢,而是生产和消费不对等导致的,你自己去查。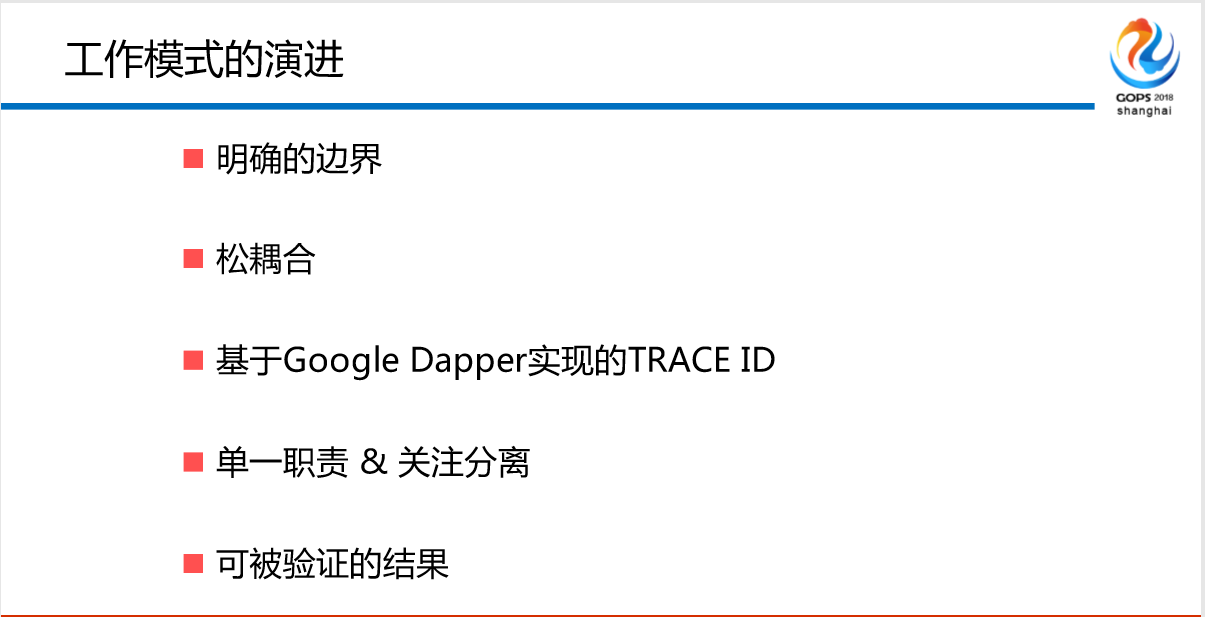
这里的内容大家可以看一下,这个其实没有什么内容,无非就是里面的一些协议,时间、机器、IP、调用类型、节点类型、SDK、服务,这是做短链路的时候非常清楚,我100毫秒到底消费在哪里。
演进之后的情况是什么?大家看一下,我一个用户当很慢的时候看这个界面,这个界面在前台的闭环当中已经有了。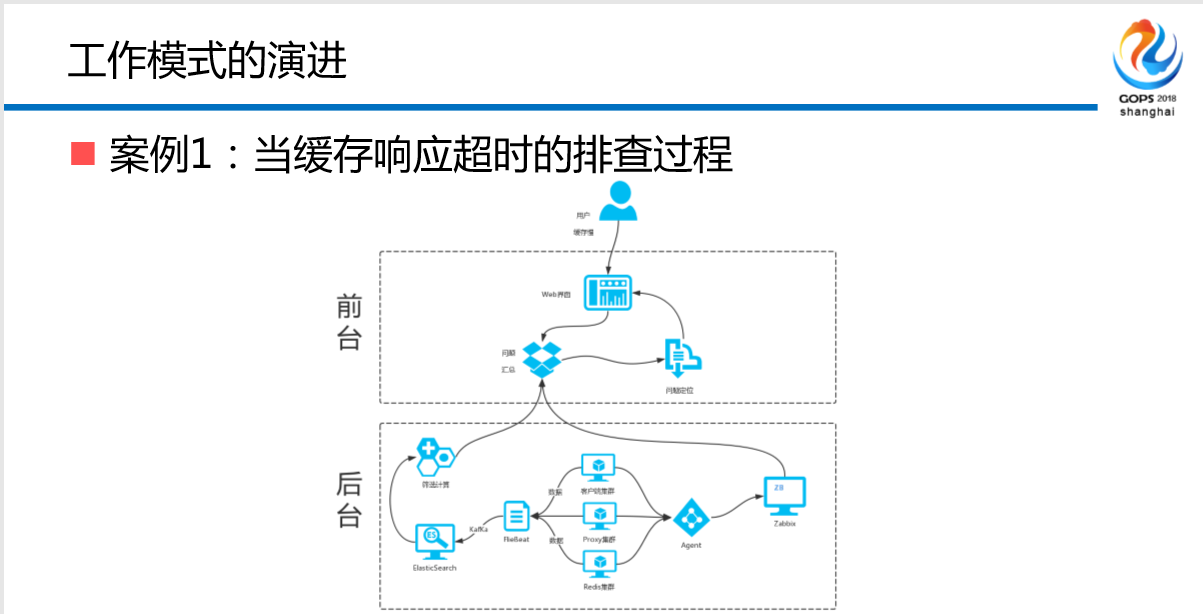
有的同学说了,我不知道什么叫切片,我后边有一张图。很简单,你不用来找我,你找我干嘛呢,你交易系统慢了,可以看一下账户系统的切片慢不慢。
消息阻塞通例,也是通过下端消费直接情况,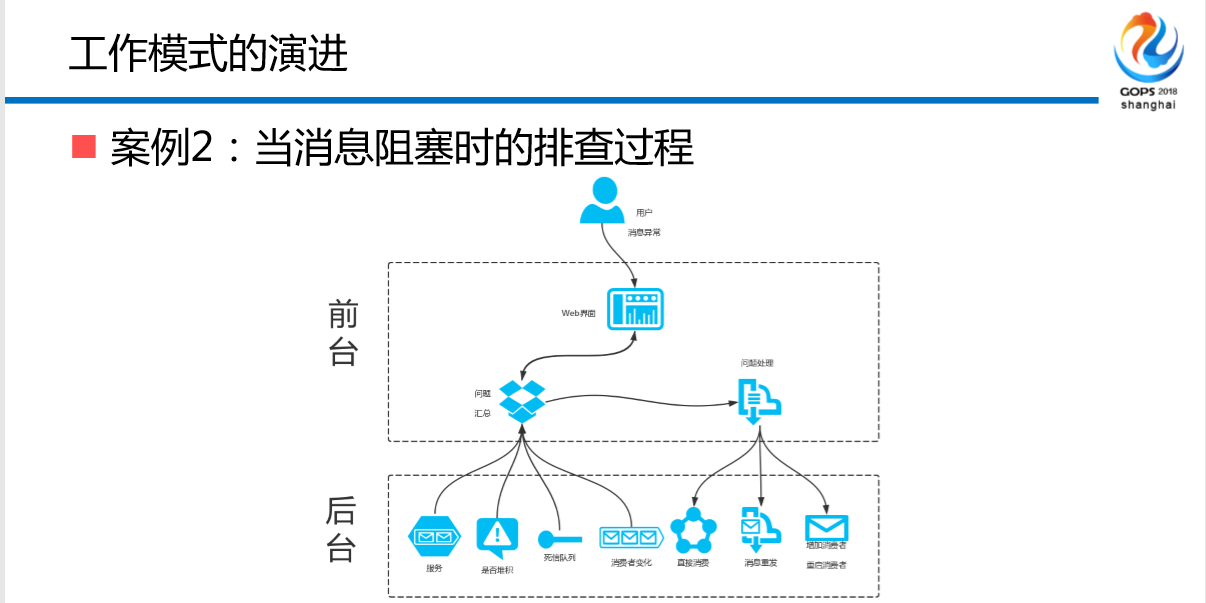 。这个很简单,我们在座如果做研发的同学很简单,我无非通过一些命令把MQ中间的数据接口反馈到数据库当中,这个技术没有什么难的点。
。这个很简单,我们在座如果做研发的同学很简单,我无非通过一些命令把MQ中间的数据接口反馈到数据库当中,这个技术没有什么难的点。
4.从单机房到混合云,我们做了什么?
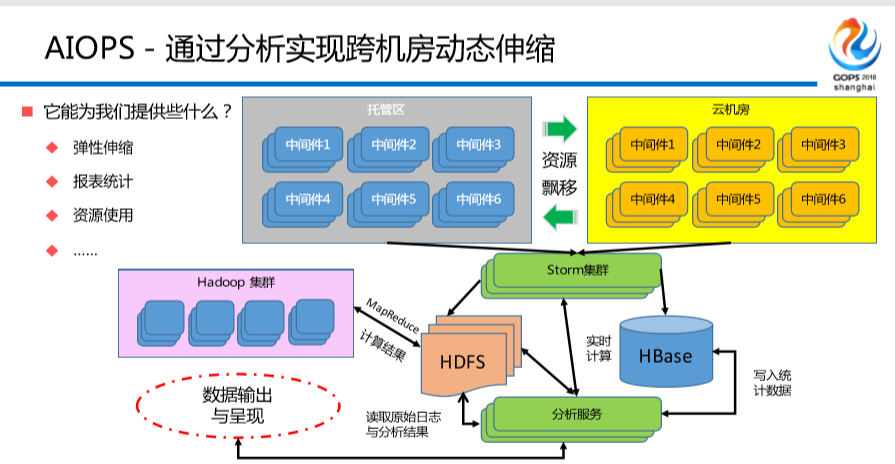
我们是从去年开始进行混合云,有的同学说了,干嘛不知道做双活呢?为什么不直接上公共云呢?首当其冲的是监管不允许。有的同学说了,你们这个行业为什么这么怪?是这样的,金融行业跟钱有关的是强监管,所有的都是跟钱有关系的,我的交易系统不允许放到我的公共云上,我只能放在我自己的私有系统中间,为什么?没有技术上的任何问题,原因是什么,监管不允许,或者监管不明确。所以能上的是资讯类的,行情类的,或者说其他的跟金融基金交易牌照没有任何关系的一些数据,可以放到云机房当中去。
遭遇故障或者流量突增的时候,我们现在是这样的,根据时间段不一样来把我们的中间件的主机放在云机房。有的同学问了,你刚才不是说不可以吗?我说的是应用系统不代表中间件,中间件是可以的。

我现在保证单机房的控制台,从一个控制台登录可以管理三个机房,可以根据需求使用你的私有云和你的托管区,这是我们的一张图谱。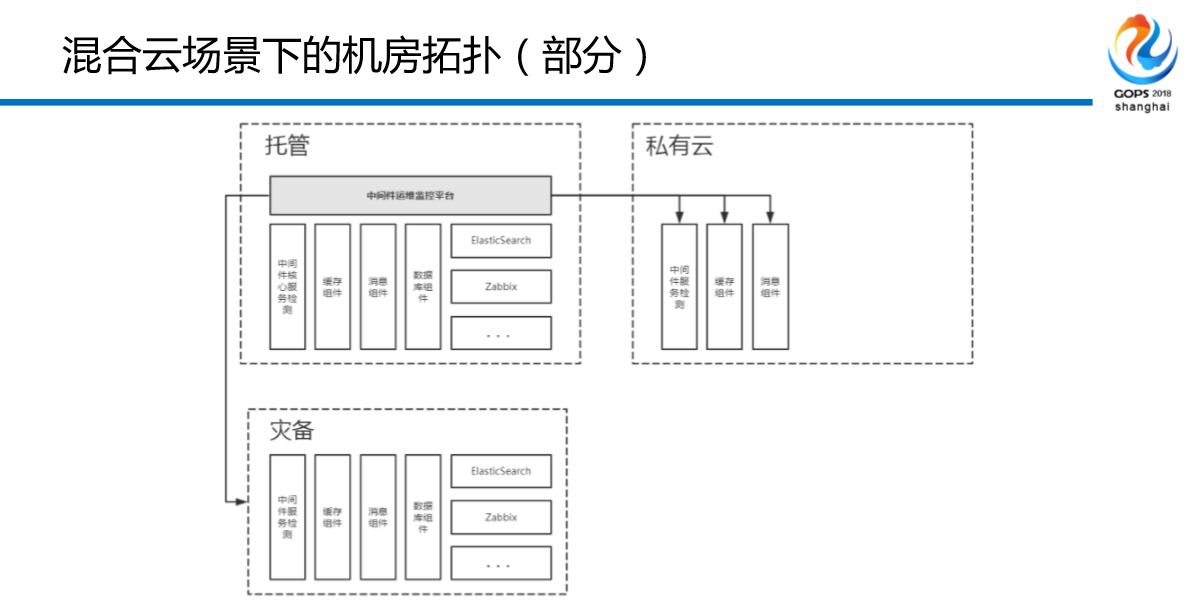
后面这几张图,这是我们几张界面,这是我们现在用的,我应用所属产品线,我们现在的云整个中间件团队运作模式跟阿里云是完全一样的,说白了是我们照抄人家的,组织结构也是照抄的,我们所有的,包括缓存消息,分布式数据库,统一分配系统按照产品的规划方式对外输出,向所有的FT团队进行兜售,比如说小张管A系统,小李管B系统,我跑过来卖。这是市场化经济,有的同学可能听不懂,在我们的公司全部都是CTO强压的,你必须搞这个动作。
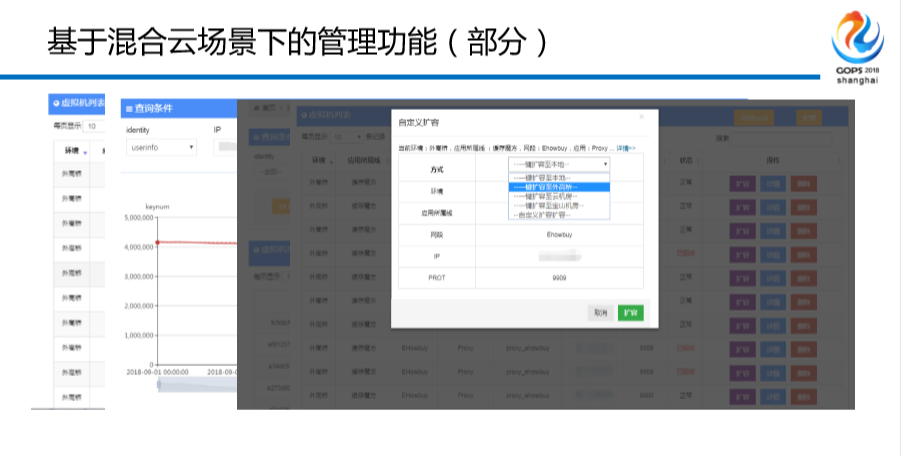
大家看到没有?这就是一个非常经典的缓存界面,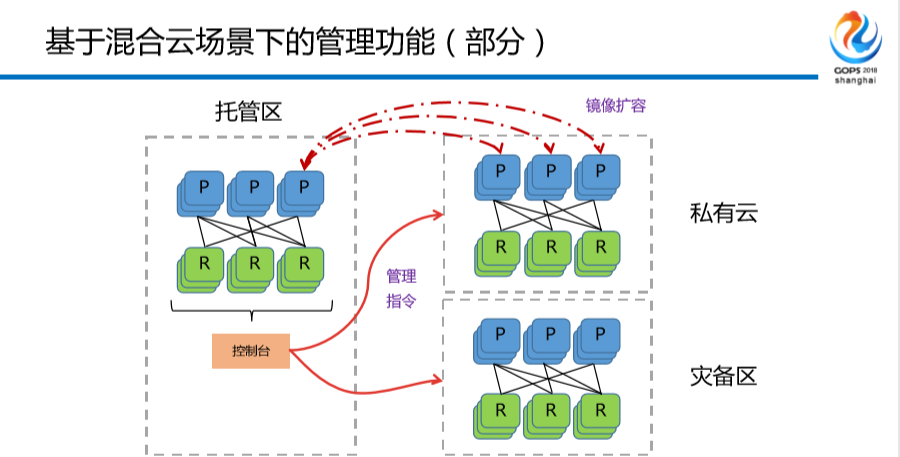 不用展开,大家都知道。这个是你所有的缓存切片的图,哪个占的最好,哪个占的最小。最后一张图,是混合云进行漂移的实例,可以选择不同的切边。
不用展开,大家都知道。这个是你所有的缓存切片的图,哪个占的最好,哪个占的最小。最后一张图,是混合云进行漂移的实例,可以选择不同的切边。
举一个例子,我的托管区就是我自己的老机房,我自己的控制台没有什么问题,当我需要进行某一时间点扩容的时候,或者我因为某一些业务或者某一些活动要进行漂移,我把我的分片进行私有云的漂移,漂移到我私有云机房,说白了不叫漂移,就是重装一套。有同学说,容器可以做的更好,对,容器我们目前只是尝试阶段,如果在座有同学对阿里比较了解的话,淘宝之前其实很多很多年以前就做了,但是他们一直到这两年蚂蚁金服才做了一部分,或者没有完全做完,做金融类所有的技术改造类的东西,中间所有的数据验证以及技术改变的成本和路径都慢半拍甚至一拍至两拍。所有的前台、中台,所有的过程所有的数据多少要对账的,你不对账是不能往上走的,但是中间件不需要。
同理,一样的,有的同学说了,灾备区什么意思?我们遇到问题的时候,保证所有的机房能够所有用户正常赎回就可以了,我是完全受损的一个服务,有的同学说了你为什么不做双活,要钱。
所有的技术,圈内有一句话,所有的优秀架构都不是设计出来的,优秀的架构是迭代和演变过程迭代出来的。大家相信吗?全是迭代过来的,为什么迭代?因为需求堆出来的,不管是前端还是后端业务需求。
5.AIOPS-展望未来
最后谈一下AIOPS的展望,我认为的AIOPS只是一个理念和方向,能提供什么?弹性的伸缩。我们现在做的更多是人工的。我们的弹性伸缩可以做到自动化,其实AlOps在研发演进里面没有什么困难,你只要能够抽象出规则,像扩容的这些动作很简单,只要满足了某些场景,做了某些事情,前提是一定要标准化。在研发的视角中,或者架构师的眼中并不是很难的事情,但是要记得做提前更新。在北京有DevOps学院,里面说过一句话,很多公司谈DevOps,你NG还在调优呢,你还DevOps。那边小伙伴在做NG调优,你这边做DevOps,合适吗?你没有标准,怎么做DevOps。
有的同学说了,你们现在做到哪里了?还在制定明年的规划,我们是腾讯系的,所以八九月份开始做明年的规划。主要的目的是跟CEO要钱,这是最终目的,这是核心目的。
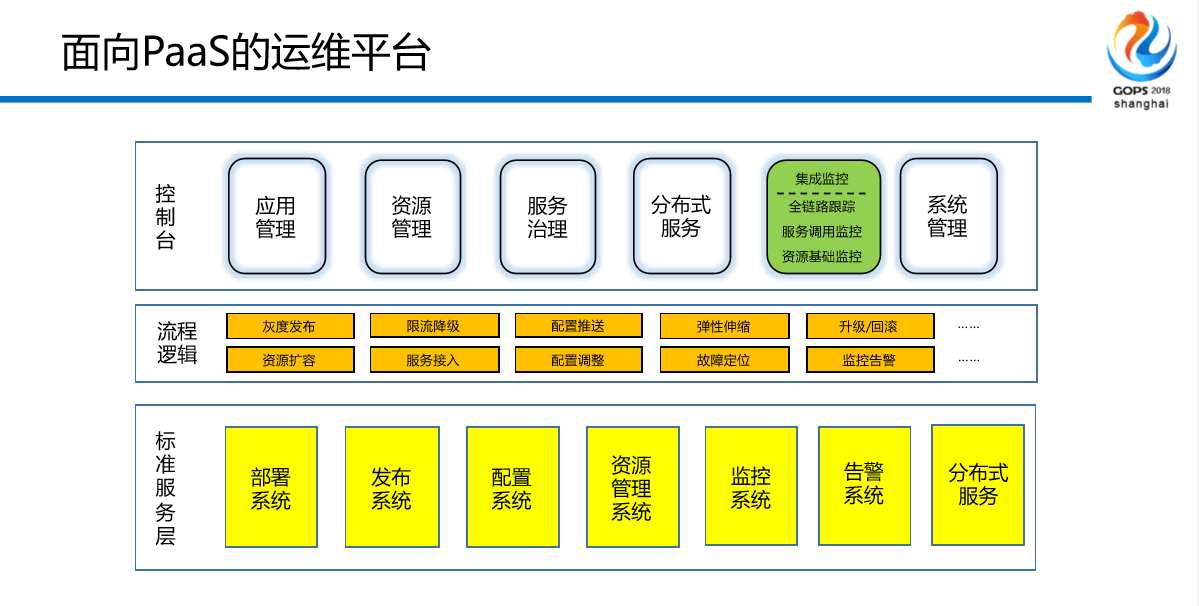
这是我们面向PaaS的运维平台,我们原先没有中台的,没有流程逻辑这块的,我们现在正在增加,所以我把颜色标为橘黄色,下部分我们都有了,我们中间件的部分只包含中间很小一部分,在右侧分布式服务这块,和预警告警这块,其他的部署发布目前我们都有。技术栈没有什么区别,也没有什么难的地方,就是现在外面大家用什么我们用什么。
最后看两张图,首先很多人第一次见到我说,你一点都不像搞技术的人。为什么不像呢?体型不像,发型也不像,我前天写了一篇文章,技术男为什么那么不爱干净或者穿着不受女孩子欢迎,在我们圈子内IT男总找IT女,这种情况多见,为什么?因为我比较喜欢运动,搞了这么多年,看上去蛮年轻的,其实蛮大了。
这两张图能看到什么不同点吗?一个是运动跑步,一个是机房。在我看来太枯燥,跑步也是枯燥的,太乏味,甚至太难以坚持。很多人说运动什么东西都很难,运维也是一样的,很多人说运维太过于枯燥,现在外面摇旗呐喊的说要干掉传统运维,虽然嘴巴没说,一嘴巴的男女道德,一肚子男盗女娼。搞IT的结什么婚啊?这是我们圈内经常互相调侃说的一些段子。

所以我觉得,就是因为这样的原因,所以我们的运维同学也好,研发同学,架构同学大家更应该提高,大家在一起共同解决问题。我们现在公司现在已经变成纯互联网化。
我的内容就讲这么多,我基本从去年和前年开始,我自己经常会写一些技术的文章,三年的演变我不可能靠几分钟就去讲清楚,现在大概一周左右输出1-2篇原创,是我自己写的,里面有技术的故事,有技术的演化包括我在外面参加的活动,大家有兴趣的话,可以一起聊一聊。
谢谢大家!

