@evilking
2018-04-30T12:45:06.000000Z
字数 17511
阅读 4374
NLP
相似度计算
向量之间的相似度计算有很多种方法,而在实际的文本挖掘任务中,往往我们要计算两个句子,或两个文本,或两个单词的相似度。当然我们可以先想办法将句子或单词转换成向量表示,再使用数学上的向量相似度计算方法,而文本有语义上的区别,所以也有些其他特殊的方法.
向量相似度
假设有两个对象 都包含 维特征,
R 代码如下:
> set.seed(11)# 11 个特征的 X 向量> (X = rnorm(11))[1] -0.59103110 0.02659437 -1.51655310 -1.36265335 1.17848916 -0.93415132 1.32360565[8] 0.62491779 -0.04572296 -1.00412058 -0.82843324# 11 个特征的 Y 向量> (Y = rnorm(11) + 1.2)[1] 0.85164827 -0.33829340 0.94443475 0.05005497 1.21232697 0.97703046 2.08777165[8] 0.60784472 0.54428188 0.51748238 1.18414181
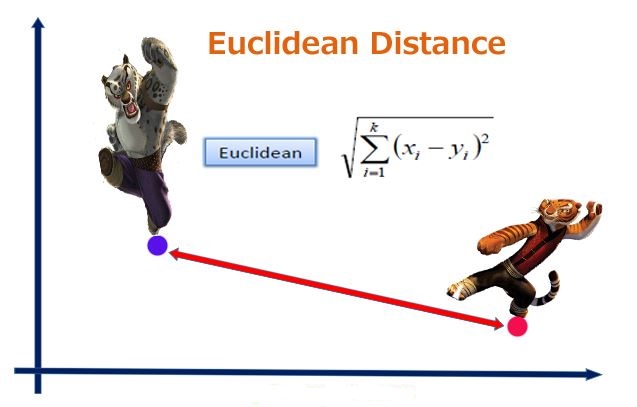
欧几里得距离
欧式距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式.
计算公式为:
因为计算是基于各个维度特征的绝对数值,所以欧式度量需要保证各维度指标在相同的刻度级别,比如对身高 (cm) 和体重 (kg) 两个单位不同的指标使用欧式距离可能使结果失效.
一般这时我们需要对数据进行归一化处理,统一量纲
R 代码如下:
# 按欧式距离计算公式得> (euclidean = sqrt(sum((X -Y)^2)))[1] 4.606356>
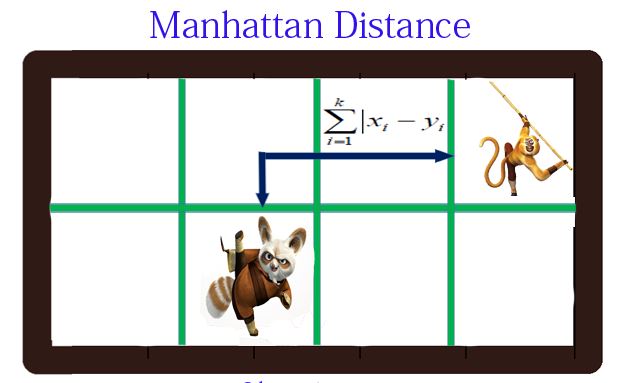
曼哈顿距离
曼哈顿距离 (Manhattan Distance) 只考虑两个向量每个维度各自的绝对差之和.
计算公式为:
R 代码如下:
# 计算 Manhattan 距离> (manhattan = sum(abs(X - Y)))[1] 12.5317>
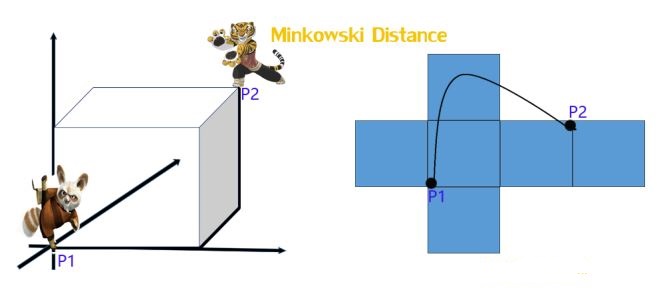
明可夫斯基距离
明氏距离 (Minkowski distance) 是欧式距离的推广,是对多个距离度量公式的概况性表述.
计算公式为:
其中 为参数:
- 当 ,“明氏距离” 变成了 “曼哈顿距离”.
- 当 ,“明氏距离” 变成了 “欧几里得距离”.
- 当 ,“明氏距离” 变成了 “切比雪夫距离”.
R 代码如下:
# 参数 p> p = 3# 按公式计算明氏距离> (minkowski = sum(abs(X - Y)^p)^(1/p))[1] 3.42231>
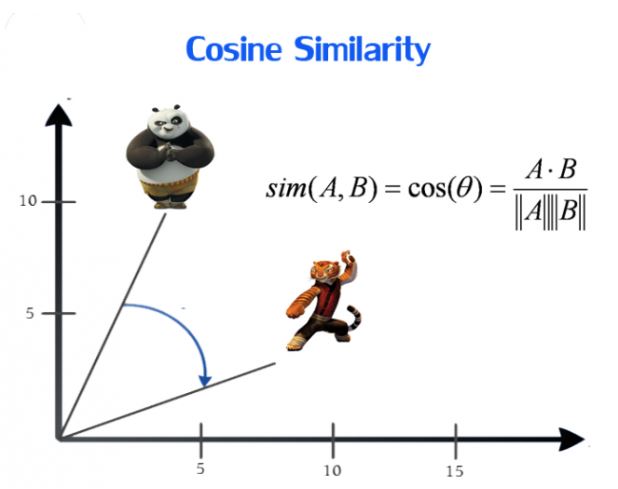
余弦相似度
余弦相似度 (Cosine Similarity) 用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上.
计算公式为:
R 代码如下:
> sum(X * Y)/sum(sqrt(X^2) * sqrt(Y^2))[1] 0.01340308>
皮尔森相关系数
皮尔森相关系数 (Pearson Correlation) 又称相关相似性,通过 Pearson 相关系数来度量两个用户的相似性。计算时,首先找到两个用户共同评分的项目集,然后计算着两个向量的相关系数.
计算公式为:
R 代码如下:
> (n = length(X))[1] 11> (person = (n*sum(X*Y) - sum(X)*sum(Y))/(sqrt(n * sum(X^2) - sum(X)^2) * sqrt(n * sum(Y^2) - sum(Y)^2)))[1] 0.4100478>
Jaccard Similarity
Jaccard 系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以 Jaccard 系数只关心个体间共同具有的特征是否一致这个问题.

对上面两个对象 ,我们用 Jaccard 计算它的相似性,公式如下:
首先计算出 和 的交 ,以及 和 的并 :
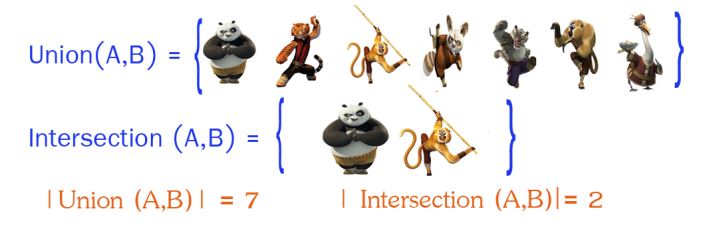
然后利用公式计算:

R 代码如下:
# 先构造符号集合 X> (X = c(1,2,3,4,5,6,7))[1] 1 2 3 4 5 6 7# 构造符号集合 Y> (Y = c(2,4,6,8,10,12,14))[1] 2 4 6 8 10 12 14# 先求两向量交集的长度,再除以 并集的长度> (Jaccard = length(intersect(X,Y)) / length(union(X,Y)))[1] 0.2727273>
R 语言自带的函数 dist() 就可求各种距离,具体用法可参见: http://blog.csdn.net/xxzhangx/article/details/53153821
文本相似度
文本相似度这部分主要以代码分析为主,不过首先还是会先介绍下每种相似度的计算方式.
其中使用的 github 源码下载地址: https://github.com/shibing624/similarity
我们主要从测试用例为入口来分析.
解析相似度
这是一种简单的短语相似度计算方法,计算方法如下: 先假设两个句子 ,长度分别为 :
这种计算就是比较两个句子或短语中相同字符位置索引之差的累积.
下面我们看源码,从 org.xm.similarity.phrase.PhraseSimilarityTest 类开始:
public void getSimilarity() throws Exception {double score = PhraseSimilarity.getInstance().getSimilarity("继续发展", "努力发展");System.out.println(score+"");}
进入到 PhraseSimilarity 类,分析 getSimilarity() 方法:
public double getSimilarity(String phrase1, String phrase2){//求均值return (getSC(phrase1, phrase2) + getSC(phrase2, phrase1)) / 2.0;}
这是算的第一个表达式.
private double getSC(String first, String second) {double total = 0.0;for (int i = 0; i < first.length(); i++) {//求 first 中每个字符与 second 的计算得分total = total + getCC(first, second, i);}return total / first.length();}
这步算的是第一个表达式的两个分数部分.
private double getCC(String first, String second, int pos) {return (second.length() - getDistance(first, second, pos)) * 1.0 / second.length();}
这部分算的是第二个表达式.
private int getDistance(String first, String second, int pos) {int d = second.length();//计算second中每个first 的 第 pos 位的字符的位置索引for (int k : getC(first, second, pos)) {int value = Math.abs(k - pos);//求位置索引差的最小值if (d > value) {d = value;}}return d;}
这步算的是第二个表达式中分子部分求最小值的逻辑.
private List<Integer> getC(String first, String second, int pos) {List<Integer> results = new ArrayList<Integer>();char ch = first.charAt(pos);for (int i = 0; i < second.length(); i++) {//记录second中每个与first pos 位的字符相同的字符索引if (ch == second.charAt(i)) {results.add(i);}}return results;}
这个相似度计算源码就分析完了,比较简单也相对粗糙一定,在精度要求不那么高的情况下是不错的选择,因为它的计算逻辑不复杂,所以计算速度比较快.
像这种简单又快速的方法,可以作为其他高精度方法的辅助过滤条件,因为往往高精度的算法计算比较复杂,耗费的时间比较长,所以可以先用简单的方法过滤一次,然后再使用精度高点的算法.
字面相似度
CharBasedSimilarity 同样是一种基于字形的简单的相似度计算方法,快速、简单.
计算公式如下,先假设有两个短语,其中较短的短语 长度为 ,较长的短语 长度为 , 公共字符集合为 长度为 :
其中, 为权重参数, 为 中公共字符在 中的位置索引, 为 字符串中字符的索引.
下面分析代码,从 org.xm.similarity.word.CharBasedSimilarityTest 测试类入口:
public void getSimilarity() throws Exception {CharBasedSimilarity sim = CharBasedSimilarity.getInstance();String s1 = "手机";String s2 = "飞机";System.out.println(sim.getSimilarity(s1, s2)+" :"+s1+","+s2);}
进入 CharBasedSimilarity 类,查看 getSimilarity() 方法:
public double getSimilarity(String word1, String word2) {......List<Character> sameChars = new ArrayList<>();//较长字符串String longString = StringUtil.getLongString(word1, word2);//较短字符串String shortString = StringUtil.getShortString(word1, word2);//统计公共字符for (int i = 0; i < longString.length(); i++) {Character ch = longString.charAt(i);if (shortString.contains(ch.toString())) {sameChars.add(ch);}}//较短字符串长度 / 较短字符串长度,m/ndouble dp = Math.min(1.0 * word1.length() / word2.length(), 1.0 * word2.length() / word1.length());//公共字符串长度分别占两个字符串的长度比例,k/m + k/ndouble part1 = alpha * (1.0 * sameChars.size() / word1.length() + 1.0 * sameChars.size() / word2.length()) / 2.0;//公共字符的累积索引, phi(X,Z) + phi(Y,Z)double part2 = beta * dp * (getWeightedResult(word1, sameChars) + getWeightedResult(word2, sameChars)) / 2.0;return part1 + part2;}
如公式中计算的.
private double getWeightedResult(String word, List<Character> sameChars) {double top = 0.0;double bottom = 0.0;//这里成了累加了,不知道是不是有问题for (int i = 0; i < word.length(); i++) {if (sameChars.contains(word.charAt(i))) {top += (i + 1);}bottom += (i + 1);}return 1.0 * top / bottom;}
如第三个公式。
这个相似度用在单词上准确率不高,一般用在短句上,比如文章的标题、摘要等.
词林相似度
CilinSimilarity 是根据词林编码来计算两个单词的相似度,计算比较准确,而且是从语义角度去算的。词林编码的内容可以参考这篇论文: https://wenku.baidu.com/view/0b1b7d5e804d2b160b4ec030.html
或者参考 《哈工大信息检索研究室同义词词林扩展版》说明 : https://wenku.baidu.com/view/db0de7bbed630b1c58eeb578.html
下面直接进入源码分析:
从 org.xm.similarity.word.clin.CilinSimilarityTest 入手开始分析:
public void getSimilarity() throws Exception {String text = "词林:" + CilinSimilarity.getInstance().getSimilarity("电脑", "电椅");System.out.println("电脑 vs 电椅:" + text);}
直接看 CilinSimilarity 类的 getSimilarity() 方法 :
public double getSimilarity(String word1, String word2) {......double sim = 0.0;//分别获取两个单词的词林编码集合,//因为一个单词可能对应多个词林编码Set<String> codeSet1 = CilinDictionary.getInstance().getCilinCodes(word1);Set<String> codeSet2 = CilinDictionary.getInstance().getCilinCodes(word2);......for (String code1 : codeSet1) {for (String code2 : codeSet2) {//计算任意两个词林编码的相似度double s = getSimilarityByCode(code1, code2);//取最大的一个编码相似度得分if (sim < s) sim = s;}}return sim;}public double getSimilarityByCode(String code1, String code2) {//根据词林编码相似度计算规则计算权重return CilinCode.calculateCommonWeight(code1, code2) / CilinCode.TOTAL_WEIGHT;}
在获取某个单词的词林编码的时候,要先加载该编码词典,词林编码格式类似于:
麟凤龟龙 1 Al03B01=麟角凤觜 1 Ba08A02=黛 2 Bk12A02= Bm11A04#
词林编码扩展版中每个编码有 8 层,最后一层的 "=" 或者 "#" 等表示词语之间的关系,前面的七层成一个树状结构,每一层对应一个相似度权重.
其中一个单词可能对应对个编码,一个编码可能对应多个单词.
public static double calculateCommonWeight(String code1, String code2) {double weight = 0.0;//对每一层计算加权for (int i = 1; i <= 6; i++) {String c1 = getCodeLevel(code1, i);String c2 = getCodeLevel(code2, i);if (c1.equals(c2)) {weight += WEIGHT[i - 1];} else {break;}}return weight;}public static double[] WEIGHT = new double[]{1.2, 1.2, 1.0, 1.0, 0.8, 0.4};public static double TOTAL_WEIGHT = 5.6;//每一层都具有不同的权重public static String getCodeLevel(String code, int level) {switch (level) {case 1:return code.substring(0, 1);case 2:return code.substring(1, 2);case 3:return code.substring(2, 4);case 4:return code.substring(4, 5);case 5:return code.substring(5, 7);case 6:return code.substring(7);}return "";}
词林编码计算词语的相似度比较准确,但由于是固定的编码词典表,所以对于一些未登录词就不好算相似度了.
拼音相似度
PinyinSimilarity 是根据汉语单词的拼音来计算 编辑距离,从而算出两个单词的相似度的.
下面开始分析源码,我们从 org.xm.similarity.word.pinyin.PinyinSimilarityTest 测试类开始分析:
public void getSimilarity() throws Exception {//创建拼音相似度计算类PinyinSimilarity pinyinSimilarity = new PinyinSimilarity();//计算 两个单词的相似度double result = pinyinSimilarity.getSimilarity("教授", "教师");System.out.println("教授" + " 教师 " + ":" + result);}
我们直接看 PinyinSimilarity 的 getSimilarity() 方法 :
public double getSimilarity(String word1, String word2) {double max = 0.0;//获取两个单词的拼音Set<String> pinyinSet1 = PinyinDictionary.getInstance().getPinyin(word1);Set<String> pinyinSet2 = PinyinDictionary.getInstance().getPinyin(word2);for (String pinyin1 : pinyinSet1) {for (String pinyin2 : pinyinSet2) {//计算两个拼音的编辑距离的代价损失double distance = new EditDistance().getEditDistance(pinyin1, pinyin2);//根据编辑代价计算相似度double similarity = 1 - distance / (MathUtil.max(pinyin1.length(), pinyin2.length()));//求最大的相似度max = (max > similarity) ? max : similarity;//相似度最大为 1if (max == 1.0) {return max;}}}return max;}
上面先从拼音词典中获取两个单词对应的拼音集合,接着计算两个拼音集合中所有组合的编辑距离,从而计算相似度,取最大相似度.
其中,拼音词典的格式为:
屏 bing3坡 po1泼 po1颇 po1婆 po2
第一个字符是汉字,后面是汉字对应的拼音,拼音最后的数字代表声母.
一个汉字可能有多个拼音,所以计算单词的拼音时,需要将所有可能的组合放到集合中返回,都要参与编辑距离的计算.
后面一步是计算两个单词拼音的编辑距离,编辑距离是由字符串 通过插入、删除、替换等操作变换成另一个字符串 所需要的代价.
public int getEditDistance(String S, String T) {......D = new int[a.length + 1][b.length + 1];/** 初始化D[i][0] */for (int i = 1; i <= n; i++) {D[i][0] = D[i - 1][0] + getDeletionCost();}/** 初始化D[0][j] */for (int j = 1; j <= m; j++) {D[0][j] = D[0][j - 1] + getInsertionCost();}// 字符串 X 转换成 字符串 Yfor (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {//D[i-1][j] 变成 D[i][j] ,j 不变,需要删除 X_i 字符//D[i][j-1] 变成 D[i][j],i 不变,而j增长了,所以需要在 X 的基础上增加一个字符//D[i-1][j-1] 变成 D[i][j] 两个字符长度都不变,需要替换一个字符D[i][j] = MathUtil.min(D[i - 1][j] + getDeletionCost(), D[i][j - 1] + getInsertionCost(),D[i - 1][j - 1] + getSubstitutionCost(a[i - 1], b[j - 1]));}}return D[n][m];}
这里的编辑距离可扩展到句子相似度的计算上,计算两个句子的编辑距离.
详细的编辑距离内容可参看下面的博文:
- http://blog.csdn.net/yutianzuijin/article/details/50273335
- https://www.cnblogs.com/sumuncle/p/5632032.html
- https://www.cnblogs.com/biyeymyhjob/archive/2012/09/28/2707343.html
- http://www.cnki.com.cn/Article/CJFDTOTAL-LNDZ201104019.htm
知网情感词分析
知网单词情感分析主要是利用了单词与正面情感词和负面情感词的知网义原相似度来计算的.
知网(英文名称为 HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
比如“笔”、“本子”是“办公用品”,“办公用品”就是一个概念.
知网义原的介绍,可参看: http://www.360doc.com/content/11/0524/09/5928821_118963825.shtml
或者 《基于《知网》义原空间的文本相似度计算》论文: http://new.wanfangdata.com.cn/details/detail.do?_type=perio&id=kxjsygc201329020
下面从源码中分析知网情感词,从 org.xm.tendency.word.HownetWordTendencyTest 测试类入口分析 :
public void getTendency() throws Exception {//创建知网情感词分析工具,加载概念、义原词典表HownetWordTendency hownet = new HownetWordTendency();//根据正负面情感词的概念、义原,计算情感得分double sim = hownet.getTendency("流氓");System.out.println(sim);}
先从加载概念解析器和义原解析器开始分析:
public HownetWordTendency() {//概念相似度工具this.conceptParser = ConceptSimilarity.getInstance();try {//义原相似度工具this.sememeParser = new SememeSimilarity();} catch (IOException e) {logger.error("exception:{}", e.getMessage());}}
《知网》中有两个核心的概念:概念和义原,这部分代码分别创建了概念解析器和义原解析器,去加载各自的词典.
概念词典:
<c d="qValue|数量值,amount|多少,cardinal|基,mass|众" p="NUM" w="8"/><c d="qValue|数量值,amount|多少,cardinal|基,mass|众" p="NUM" w="9"/><c d="symbol|符号,computer|电脑,software|软件" p="N" w="ASCII"/><c d="tool|用具,*LookFor|寻,#cry|喊" p="N" w="BP机"/><c d="fact|事情,diagnose|诊察,medical|医" p="N" w="B超"/><c d="tool|用具,*diagnose|诊察,medical|医" p="N" w="B超"/><c d="part|部件,%computer|电脑,heart|心" p="N" w="CPU"/><c d="part|部件,%animate|生物" p="N" w="DNA"/>
d 标识的是概念,p 标识的是词性,w 标识的是单词.上面的概念解析器就是加载该概念词典表中的这几个字段.
义原词典:
<sememe cn="不同" define="{relevant,contrast,scope}" en="differ" id="1-1-1-3-2"/><sememe cn="值得" define="{relevant,content}" en="worth" id="1-1-1-3-3"/><sememe cn="不值" define="{relevant,content}" en="WorthNot" id="1-1-1-3-4"/><sememe cn="相适关系" en="suit" id="1-1-1-4"/><sememe cn="适合" define="{relevant,contrast,scope}" en="fit" id="1-1-1-4-1"/><sememe cn="陪衬" define="{relevant,contrast,scope}" en="ServeAsFoil" id="1-1-1-4-2"/><sememe cn="不适" define="{relevant,contrast,scope}" en="FitNot" id="1-1-1-4-3"/>
cn 标识义原的中文名,en 标识义原的英文名,id 标识义原的关系,它是一个树状结构,可用于计算两个义原直接的相似度. 义原解析器加载了 cn 和 id 两个字段.
下面分析情感词:
//正面词模板public static String[] POSITIVE_SEMEMES = new String[]{"良", "喜悦", "夸奖", "满意", "期望"};//负面词模板public static String[] NEGATIVE_SEMEMES = new String[]{"莠", "谴责", "害怕", };public double getTendency(String word) {//正面情感词最大的得分double positive = getSentiment(word, POSITIVE_SEMEMES);//负面情感词最大的得分double negative = getSentiment(word, NEGATIVE_SEMEMES);return positive - negative;}
上面分别计算当前单词与提供好的正面情感义原的相似度得分、负面情感义原的相似度得分,相减后得到属于正面情感的得分.
这里代码中只是举了正负面情感义原的几个例子,实际应用中我们可以做成配置表,登录情感比较鲜明的正负面情感义原作为情感词典库.
private double getSentiment(String word, String[] candidateSememes) {//获取单词的概念集合Collection<Concept> concepts = conceptParser.getConcepts(word);Set<String> sememes = new HashSet<>();//获取每个概念所属的所有义原for (Concept concept : concepts)sememes.addAll(concept.getAllSememeNames());double max = 0.0;//计算每个义原与指定情感词对应的义原的相似度for (String item : sememes) {double total = 0.0;for (String positiveSememe : candidateSememes) {//义原解析double value = sememeParser.getSimilarity(item, positiveSememe);// 如果有特别接近的义原,直接返回该相似值if (value > 0.9) {return value;}total += value;}//取相似度最大的double sim = total / candidateSememes.length;if (sim > max) {max = sim;}}return max;}
基本上上面的注释就是能解释这段代码的意思了.
下面跟踪 getSentiment() -> getSimilarity() -> getMaxSimilarity() -> getSimilarityBySememeId()
/*** 计算两个义原的相似度*/double getSimilarityBySememeId(final String id1, final String id2) {int position = 0;String[] array1 = id1.split("-");String[] array2 = id2.split("-");// id1 ="1-1-1-6-1-1"// id2 ="1-1-1-6-2"for (position = 0; position < array1.length && position < array2.length; position++) {if (!array1[position].equals(array2[position])) {break;}}//计算相似度return 2.0 * position / (array1.length + array2.length);}
计算两个义原最开始不同的位置索引,根据这个索引计算两个义原的相似度.
上面跳转的几步,中间做了一些格式的判断,符号义原、关系义原的判断;跟踪源码的时候可以先忽略.
概念相似度
上面的知网情感词分析更多的是依靠与配置好的情感义原之间的义原相似度来判断。而两个单词的概念相似度首先需要概念上相似,然后才是义原上相似.
直接从 org.xm.similarity.word.hownet.concept.ConceptSimilarityTest 测试类开始分析:
public void test() throws Exception {//构建概念相似度工具ConceptSimilarity conceptSimilarity = ConceptSimilarity.getInstance();String word3 = "出租车";String word4 = "自行车";//计算两单词的概念相似度System.out.println(conceptSimilarity.getSimilarity(word3, word4) + " :" + word3 + "," + word4);}
概念相似度工具类的构建就是加载概念词典表和义原词典表,在上面我们讲过,下面就直接讲 ConceptSimilarity 的 getSimilarity() 方法:
public double getSimilarity(String word1, String word2) {double similarity = 0.0;if (word1.equals(word2)) {return 1.0;}//先分别获取两个单词的概念Collection<Concept> concepts1 = getConcepts(word1);Collection<Concept> concepts2 = getConcepts(word2);// 未登录词需要计算组合概念......// 处理所有可能组合的相似度for (Concept c1 : concepts1) {for (Concept c2 : concepts2) {//计算两个概念的相似度double v = getSimilarity(c1, c2);//取最大的个相似度if (v > similarity) {similarity = v;}if (similarity == 1.0) {break;}}}return similarity;}
上面的步骤是先获取两个单词的概念集合,如果该单词是未登录词,即在概念词典表中不存在,就根据一定的算法自动计算最接近的概念,调用方法 autoCombineConcepts(),不过这一步具体逻辑比较复杂,笔者目前也还没看懂,所以先不讲这部分.
代码后面部分就是计算两个概念之间的相似度了,概念之间的相似度是转换成概念所属的义原直接的相似度来算的.
public double getSimilarity(Concept concept1, Concept concept2) {double similarity = 0.0;......// 虚词if (concept1.isbSubstantive() == false) {//虚词只比较第一义原similarity = sememeParser.getSimilarity(concept1.getMainSememe(), concept2.getMainSememe());} else {// 实词//第一义原直接进行比较double sim1 = sememeParser.getSimilarity(concept1.getMainSememe(), concept2.getMainSememe());//第二义原直接进行比较double sim2 = getSimilarity(concept1.getSecondSememes(), concept2.getSecondSememes());//参考义原直接进行比较double sim3 = getSimilarity(concept1.getRelationSememes(), concept2.getRelationSememes());//符号义原直接进行比较double sim4 = getSimilarity(concept1.getSymbolSememes(), concept2.getSymbolSememes());//义原相似度的加权和similarity = calculate(sim1, sim2, sim3, sim4);}return similarity;}protected double calculate(double sim_v1, double sim_v2, double sim_v3, double sim_v4) {//不同义原相似度的加权和return beta1 * sim_v1 + beta2 * sim_v1 * sim_v2 + beta3 * sim_v1 * sim_v3 + beta4 * sim_v1 * sim_v4;}
其中某个概念的第一义原、第二义原等信息,是在构造 Concept 对象的时候调用 initDefine() 方法进行 解析的,这种在概念表中都有定义.
另外上面义原相似度计算在上一小节中已经讲过,这里就不讲了.
总结起来就是两个概念之间的相似度,是通过概念所属的各个义原对应相似度的加权和来计算的.
概念、义原相似度是基于《知网》知识系统来计算相似度的,精度比较高,在去重或求句子相似度时经常用到.
文本余弦相似度
在上面向量的余弦相似度中有讲过它的原理,这里应用到中文文本中,也是类似的原理,由于是处理的单词,稍微做了些处理.
从 org.xm.similarity.text.CosineSimilarityTest 开始分析:
public void getSimilarityScore() throws Exception {String text1 = "我爱购物";String text2 = "我爱读书";//文本余弦相似度TextSimilarity similarity = new CosineSimilarity();double score1pk2 = similarity.getSimilarity(text1, text2);}
传入文本,需要先对文本进行分词,然后对分词后的两个单词列表进行余弦相似度计算.
public double getSimilarityImpl(List<Word> words1, List<Word> words2) {// 根据单词的词频计算单词的权重taggingWeightByFrequency(words1, words2);// 将词频转换成 HashMap<String,Float>Map<String, Float> weightMap1 = getFastSearchMap(words1);Map<String, Float> weightMap2 = getFastSearchMap(words2);Set<Word> words = new HashSet<>();words.addAll(words1);words.addAll(words2);AtomicFloat ab = new AtomicFloat();// a.bAtomicFloat aa = new AtomicFloat();// |a|的平方AtomicFloat bb = new AtomicFloat();// |b|的平方// 对 words列表中每一个单词进行计算words.parallelStream().forEach(word -> {//word 在第一句中的词频Float x1 = weightMap1.get(word.getName());//word 在第二句中的词频Float x2 = weightMap2.get(word.getName());//两个句子中同时存在的单词if (x1 != null && x2 != null) {//x1x2float oneOfTheDimension = x1 * x2;//+ab.addAndGet(oneOfTheDimension);}if (x1 != null) {//(x1)^2float oneOfTheDimension = x1 * x1;//+aa.addAndGet(oneOfTheDimension);}if (x2 != null) {//(x2)^2float oneOfTheDimension = x2 * x2;//+bb.addAndGet(oneOfTheDimension);}});//|a|double aaa = Math.sqrt(aa.doubleValue());//|b|double bbb = Math.sqrt(bb.doubleValue());//使用BigDecimal保证精确计算浮点数//|a|*|b|//double aabb = aaa * bbb;BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb));//similarity=a.b/|a|*|b|//double cos = ab.get() / aabb.doubleValue();//余弦相似度计算double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue();return cos;}
先根据分词后的单词列表统计单词词频,然后按照余弦相似度的公式计算。 句子中未出现的单词的词频就是 0 ,则两个句子计算 时,只需要计算两个句子共同出现的单词的词频之积即可.
在源码中还提供了其他几种向量相似度的文本计算方式,比如 JaccardTextSimilarity, EuclideanDistanceTextSimilarity等等,读者可以自行对比学习.
另外概念、义原相似度上面讲的是对两个单词进行相似度计算,若将句子分词之后,也可以应用于计算句子的相似度,在上面测试类中的
org.xm.similarity.sentence.morphology.MorphoSimilarityTest就是这么做的.
小结
这里只是分析了一些常用的相似度计算方法,还有像 simhash、Rabin指纹 等等在前面的 SimHash 一篇中有介绍,读者可以结合起来学习.
