@evilking
2018-04-30T16:23:19.000000Z
字数 6468
阅读 7772
NLP
PageRank与TextRank算法
TextRank算法本质上是 PageRank算法,经过修改可以用于关键词提取,以及自动摘要提取.
本篇先详细介绍下PageRank算法原理,然后以TextRank做关键词提取的应用做源码分析.
PageRank算法详解
本算法是由谷歌的两位创始人佩奇(Larry Page)和布林(Sergey Brin)参考学术界评判学术论文重要性的方法———看论文的引用次数 而提出.
算法思想
如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高
如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高

算法原理
PageRank算法预先给每个网页一个 PR值(下面用 PR值指代 PageRank值),由于 PR值物理意义上为一个网页被访问概率,所以一般是 ,其中 N 为网页总数。另外,一般情况下,所有网页的 PR值的总和为 1。如果不为 1的话也不是不行,最后算出来的不同网页之间 PR值的大小关系仍然是正确的,只是不能直接地反映概率了。
预先给定 PR值后,通过下面的算法不断迭代,直至达到平稳分布为止。
互联网中的众多网页可以看作一个有向图。下图是一个简单的例子 :
![]()
这时 A 的 PR值就可以表示为 :
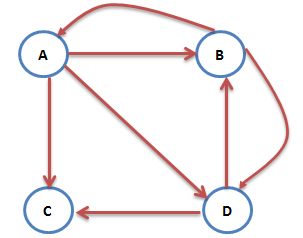
图中的 C 网页没有出链,对其他网页没有 PR值的贡献,我们不喜欢这种自私的网页(其实是为了满足 Markov 链的收敛性),于是设定其对所有的网页(包括它自己)都有出链,则此图中A的PR值可表示为:
然而我们再考虑一种情况:互联网中一个网页只有对自己的出链,或者几个网页的出链形成一个循环圈。那么在不断地迭代过程中,这一个或几个网页的PR值将只增不减,显然不合理。如下图中的 C 网页就是刚刚说的只有对自己的出链的网页:
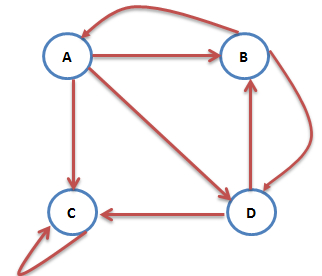
为了解决这个问题,我们想象一个随机浏览网页的人,当他到达 C 网页后,显然不会傻傻地一直被 C 网页的小把戏困住。我们假定他有一个确定的概率会输入网址直接跳转到一个随机的网页,并且跳转到每个网页的概率是一样的。于是则此图中 A 的 PR值可表示为:
所以在一般情况下,一个网页的 PR值计算公式如下 :
根据上面的公式,我们可以计算每个网页的 PR值,在不断迭代趋于平稳的时候,即为最终结果。
算法证明
上面说了在不断迭代中趋于平稳时,为最终结果,这就有两个问题:
是否存在?
如果极限存在,那么它是否与 的选取无关?
PageRank算法的正确性证明包括上面两点。为了方便证明,我们先将PR值的计算方法转换一下。
仍然拿刚刚的例子来说:
有向图我们可以用矩阵来表示,所以这里用矩阵来表示出入链关系, 表示 j 网页没有对 i 网页的出链 :
取 为所有分量都为 1 的列向量,接着定义矩阵 :
若一个 Markov 过程收敛,那么它的状态转移矩阵 A 需要满足 :
- A 为随机矩阵
- A 是不可约的
- A 是非周期的
先看第一点,随机矩阵又叫概率矩阵或 Markov 矩阵,满足以下条件:
令为矩阵 A 中第 i 行第 j 列的元素,则
第二点,不可约矩阵:方阵 A 是不可约的当且仅当与 A 对应的有向图是强联通的。有向图 是强联通的当且仅当对每一对节点对 ,存在从 到 的路径。因为我们在之前设定用户在浏览页面的时候有确定概率通过输入网址的方式访问一个随机网页,所以 A 矩阵同样满足不可约的要求.
第三点,要求 A 是非周期的。所谓周期性,体现在 Markov 链的周期性上。即若 A 是周期性的,那么这个 Markov 链的状态就是周期性变化的。因为 A 是素矩阵(素矩阵指自身的某个次幂为正矩阵的矩阵),所以 A 是非周期的。
至此,我们证明了 PageRank 算法的正确性。
PR值计算方法
幂迭代法
首先给每个页面赋予随机的 PR值,然后通过 不断地迭代 PR值。当满足下面的不等式后迭代结束,获得所有页面的 PR值 :
特征值法
当上面提到的 Markov链收敛时,必有 :
代数法
相似的,当上面提到的 Markov链收敛时,必有 :
又因为 e 为所有分量都为 1 的列向量,P 的所有分量之和为 1 :
PageRank算法的缺点
第一,没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现PageRank值的传递关系。
第二,没有过滤广告链接和功能链接(例如常见的“分享到微博”)。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
第三,对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高PR值的页面仍需要很长时间的推广。
针对PageRank算法的缺点,有人提出了TrustRank算法。其最初来自于2004年斯坦福大学和雅虎的一项联合研究,用来检测垃圾网站。TrustRank算法的工作原理:先人工去识别高质量的页面(即“种子”页面),那么由“种子”页面指向的页面也可能是高质量页面,即其TR值也高,与“种子”页面的链接越远,页面的TR值越低。“种子”页面可选出链数较多的网页,也可选PR值较高的网站。
TrustRank算法给出每个网页的TR值。将PR值与TR值结合起来,可以更准确地判断网页的重要性。
TextRank算法详解
TextRank 是由 PageRank 改进而来,其公式有颇多相似之处 :
TextRank用于关键词提取的算法如下 :
把给定的文本 T 按照完整句子进行分割,即
对于每个句子 ,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即 ,其中 是保留后的候选关键词
构建候选关键词图 ,其中 V 为节点集,由上步生成的候选关键词组成,然后采用共现关系构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为 k 的窗口中共现,k 表示窗口大小,即最多共现 k 个单词
根据上面的公式,迭代传播各节点的权重,直至收敛
对节点权重进行倒序排列,从而得到最重要的 T 个单词,作为候选关键词
由上步得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词
上面最后一步相当于是对 TextRank 结果进行处理,或者可以考虑候选关键词在文本中出现的位置来进一步处理,一般出现在文档靠前以及靠后的词更重要.
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
如果是生成摘要,则将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察两个句子的相似度就有很多方法了。
TextRank关键词提取 源码详解
源码导入
下载地址 : https://github.com/hankcs/TextRank
运行 TextRankKeyword类 :
public static void main(String[] args) {String content = "程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。";System.out.println(new TextRankKeyword().getKeyword("", content));}
得到如下关键词提取结果,关键词用 '#'分隔 :
程序员#人员#程序#分为#开发#非常#软件#维护#中国#高级#
源码分析
public String getKeyword(String title, String content) {//分词,并去掉停用词List<Term> termList = HanLP.segment(title + content);List<String> wordList = new ArrayList<String>();for (Term t : termList) {if (shouldInclude(t)) {wordList.add(t.word);}}//将词构建 有向加权图Map<String, Set<String>> words = new HashMap<String, Set<String>>();Queue<String> que = new LinkedList<String>();for (String w : wordList) {if (!words.containsKey(w)) {words.put(w, new HashSet<String>());}que.offer(w);//共现窗口设为 5if (que.size() > 5) {que.poll();}for (String w1 : que) {for (String w2 : que) {if (w1.equals(w2)) {continue;}//共现窗口内的词有边相连words.get(w1).add(w2);words.get(w2).add(w1);}}}//开始 TextRank迭代Map<String, Float> score = new HashMap<String, Float>();for (int i = 0; i < max_iter; ++i) {Map<String, Float> m = new HashMap<String, Float>();float max_diff = 0;for (Map.Entry<String, Set<String>> entry : words.entrySet()) {String key = entry.getKey();Set<String> value = entry.getValue();//对每个词进行迭代,设置初值m.put(key, 1 - d);for (String other : value) {int size = words.get(other).size();if (key.equals(other) || size == 0)continue;//按照公式,对每条边进行 TextRank 的 PR值计算m.put(key, m.get(key) + d / size * (score.get(other) == null ? 0 : score.get(other)));}//记录每次所有词做一遍迭代后的最大误差,作为迭代稳定的标志max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));}score = m;if (max_diff <= min_diff)break;}//对 TextRank结果进行倒序排列List<Map.Entry<String, Float>> entryList = new ArrayList<Map.Entry<String, Float>>(score.entrySet());Collections.sort(entryList, new Comparator<Map.Entry<String, Float>>() {@Overridepublic int compare(Map.Entry<String, Float> o1, Map.Entry<String, Float> o2) {return (o1.getValue() - o2.getValue() > 0 ? -1 : 1);}});String result = "";//取前 nKeyword 个关键词for (int i = 0; i < nKeyword; ++i) {result += entryList.get(i).getKey() + '#';}return result;}
基本上上述代码过程与上面所讲述的 TextRank算法过程一致,先分词,然后构建有向加权图,然后利用 TextRank公式迭代,当前后两次迭代的误差小于某一阈值时,就代表稳定了,则停止迭代;最后对 TextRank结果进行倒序排列,取前 kKeyword 个关键词.
R 中使用关键词提取
> library(jiebaR)载入需要的程辑包:jiebaRD> keys = worker("keywords",topn = 4,idf = IDFPATH)> keys <= "我爱北京天安门,天安门在北京"17.9908 9.3348"天安门" "北京">
结巴分词工具的使用在前篇《NLP之 结巴分词》中有详细讲解,读者有兴趣可以自行阅读
小结
到这里 PageRank 和 TextRank算法的讲解就结束了,其中有提到 TrustRank算法以及BM25算法,在后面篇章中再详细讨论.
以上内容若有不妥之处,还望批评指正.
