@evilking
2018-05-01T11:12:08.000000Z
字数 6012
阅读 3179
时间序列篇
ARIMA模型
前面的篇幅中我们讲解了 模型,而差分运算具有强大的确定性信息提取能力,许多非平稳序列差分后会显示出平稳序列的性质,这时我们称这个非平稳序列为差分平稳序列.对差分平稳序列可以使用 模型进行拟合.
模型的结构
具有如下结构的模型称为求和自回归移动平均模型,简记为 模型:
求和自回归移动平均模型这个名字的由来是因为 阶差分后序列可以表示为:
另有:
由上式容易看出, 模型的实质就是差分运算与 模型的组合.这说明任何非平稳序列如果能够通过适当阶数的差分实现差分后平稳,就可以对差分后序列进行 模型拟合了.而 模型的分析方法非常成熟,这意味着对差分平稳序列的分析也将是非常简单、非常可靠的.
特别的:
当 时,模型实际上就是 模型.
当 时,模型可以简记为 模型.
当 时, 模型可以简记为 模型.
当 时,模型为:
该模型称为随机游走(random walk)模型,或醉汉模型.
随机游走模型描述为:假如有个醉汉醉得非常严重,完全丧失方向感,把他放在荒郊野外,一段时间之后再去找他,在什么地方找到他的概率最大呢?
模型的性质
平稳性
假如 服从 模型:
式中,
因为 差分后平稳,服从 模型,所以不妨设:
由上式很容易判断, 模型的广义自回归系数多项式共有 个根.
其中 个根 在单位圆外, 个根在单位圆上.
自回归系数多项式的根即为特征根的倒数,所以 模型共有 个根,其中 个根在单位圆外, 个根在单位圆上.
因为有 个特征根在单位圆上而非单位圆内,所以当 时, 模型不平稳.
方差齐性
对于 模型,当 时,不仅均值非齐性,序列方差也非齐性.
以最简单的随机游走模型 为例:
这是一个时间 的递增函数,随着时间趋于无穷,序列 的方差也趋向于无穷.
但 阶差分之后
模型建模
在掌握了 模型的建模方法后,尝试使用 模型对观察序列建模时一件比较简单的事情了.一般建模流程如下:
下面我们以一个具体的实例来演示建模过程:
#数据的准备> d <- read.table("data/file17.csv",",",header = T)> x <- ts(d$index,start = 1952)> plot(x)>
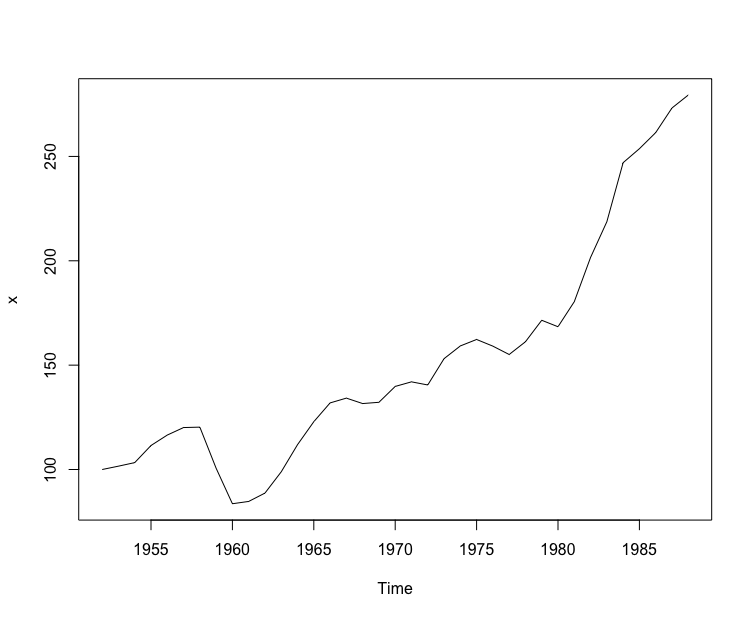
这里是对 1952 ~ 1988 年中国农业实际国民收入指数序列建模.
#一阶差分> x.dif <- diff(x)> plot(x.dif)>
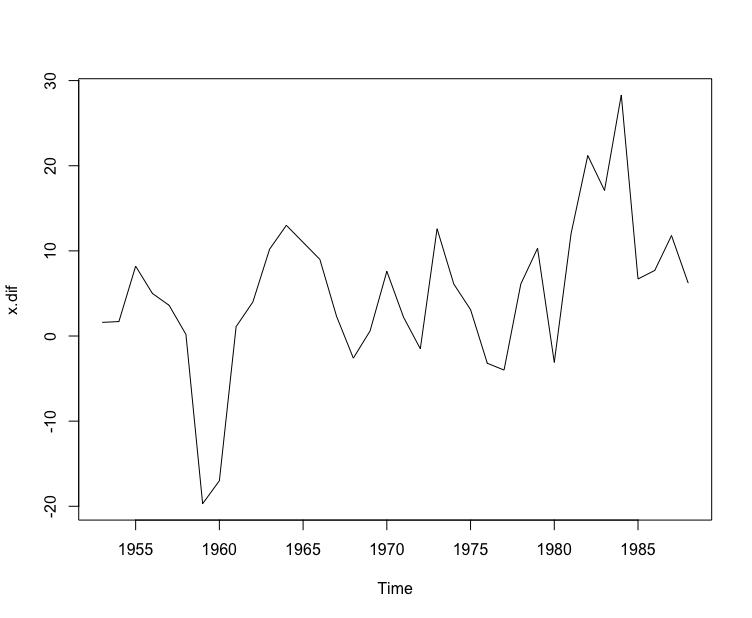
一阶差分后可以看到时序图基本平稳,不用进行二阶差分.
#考察自相关图> acf(x.dif)>

从自相关图中可以看出,一阶滞后后的自相关阶数均在 2 倍标准差范围之内,显示出很强的短期相关性,所以可以认为 1 阶差分后序列平稳,相关系数 1 阶截尾.
#考察偏自相关图> pacf(x.dif)>
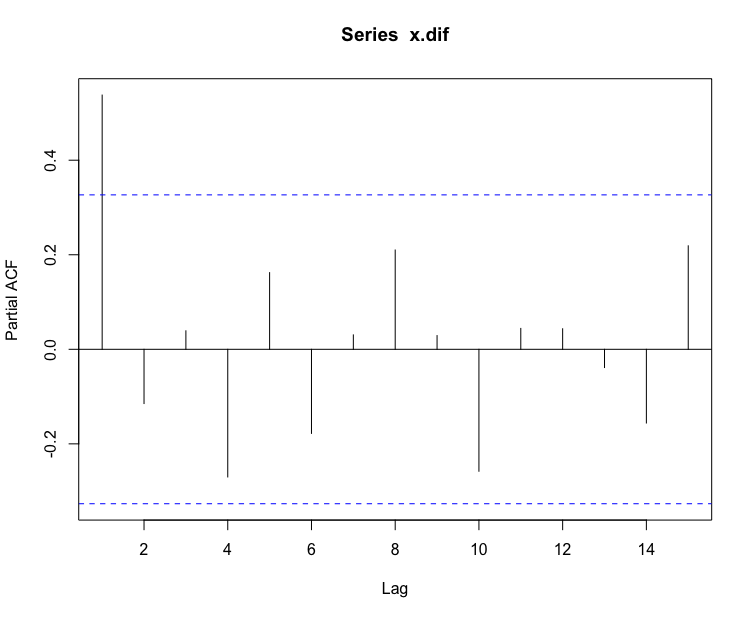
从偏自相关图中看出,0 阶滞后后,偏相关阶数均在 2 倍标准差范围之内,偏自相关系数 0 阶截尾.
综合acf和pacf,确定模型为 .
# arima(0,1,1) 模型拟合> x.fit <- arima(x,order = c(0,1,1))> x.fitCall:arima(x = x, order = c(0, 1, 1))Coefficients:ma10.7355s.e. 0.1545sigma^2 estimated as 61.95: log likelihood = -125.74, aic = 255.49>
从Coefficients参数值可以得到拟合模型的表达式为
#残差白噪声检测,考察拟合效果> for(i in 1:2) print(Box.test(x.fit$residuals,lag = 6*i))Box-Pierce testdata: x.fit$residualsX-squared = 3.3169, df = 6, p-value = 0.7681Box-Pierce testdata: x.fit$residualsX-squared = 6.0284, df = 12, p-value = 0.9146>
对模型拟合后的残差做白噪声检测,从p-value = 0.9146可以看出,残差是白噪声非常显著,说明 arima(0,1,1)模型拟合的很好.
模型预测
模型建立好之后,我们就可以用来预测了.在最小均方误差预测原理下,模型和 模型的预测方法非常相似.
模型的一般表示方法为:
和 模型一样,也可以用随机扰动项的线性函数表示:
式中, 的值由如下等式确定:
容易验证, 的值满足如下递推公式:
式中,
那么,的真实值为:
由于 的不可获得性,所以 的估计值只能为:
真实值与预测值之间的均方误差为:
要使均方误差最小,当且仅当
期预测误差为:
真实值等于预测值加上预测误差:
期预测误差的方差为:
下面依然是以中共农业实际国民收入指数序列作为期 10 年的预测来演示:
#引入必要的时间序列预测包> library(zoo)> library(forecast)# arima 模型拟合> d <- read.table("data/file17.csv",",",header = T)> x <- ts(d$index, start = 1952)> x.fit <- arima(x,order = c(0,1,1))# 模型预测> x.fore <- forecast(x.fit,h = 10)> x.forePoint Forecast Lo 80 Hi 80 Lo 95 Hi 951989 283.0082 272.9213 293.0950 267.5816 298.43471990 283.0082 262.8045 303.2118 252.1094 313.90701991 283.0082 256.2756 309.7407 242.1243 323.89211992 283.0082 251.0540 314.9624 234.1384 331.87791993 283.0082 246.5731 319.4432 227.2856 338.73081994 283.0082 242.5860 323.4304 221.1878 344.82861995 283.0082 238.9582 327.0581 215.6396 350.37671996 283.0082 235.6073 330.4090 210.5149 355.50151997 283.0082 232.4782 333.5382 205.7292 360.28711998 283.0082 229.5318 336.4845 201.2231 364.7932# 绘制预测图> plot(x.fore)>
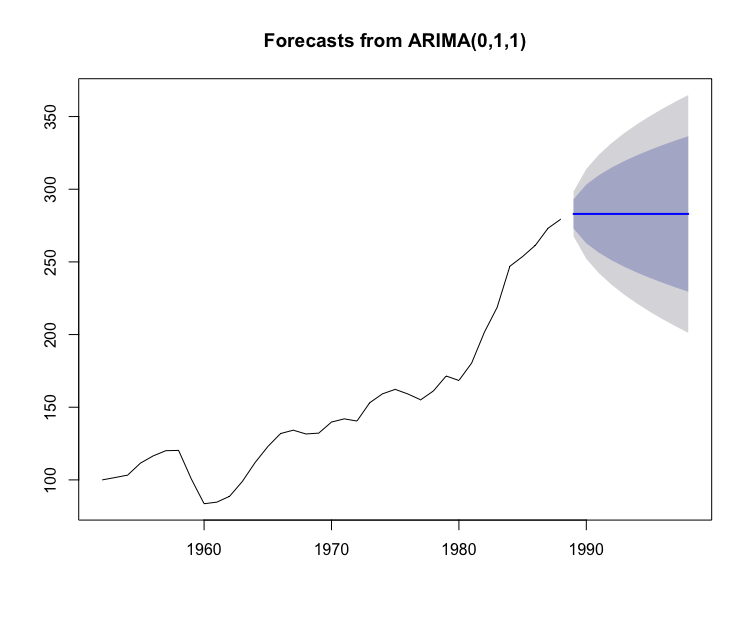
arima()函数用来拟合模型,forecast()函数利用拟合好的模型来进行预测,具体的用法可以使用 help(arima)以及 help(forecast)命令查看帮助文档.
模型中,如果有部分系数缺省了,那么该模型称为疏系数模型,记为 ,其中 ,以及分别表示自相系数的非零阶数和移动平滑部分的非零阶数.
在 R 中,
arima()函数的transform.pars参数和fixed参数用来调节疏系数模型的参数,详情请help(arima)
