@evilking
2018-05-01T09:57:19.000000Z
字数 18534
阅读 3479
机器学习篇
CRF 模型
条件随机场(conditional random field,CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔科夫随机场.
条件随机场可以用于不同的预测问题,因本系列教程后面重点在文本挖掘、NLP的标注问题上,为了简化所以主要讲述线性链(linear chain)条件随机场。
概率无向图模型
因 CRF 模型是一种概率无向图模型,为了完整性,我们先简要介绍下什么是概率无向图模型.
模型定义
图(graph)是由结点(node)及连接结点的边(edge)组成的集合.结点和边分别记作 和 ,结点和边的集合分别记作 和 ,图记作 .无向图是指边没有方向的图.
概率图模型(probabilistic graphical model)是由图表示的概率分布.设有联合概率分布 , 是一组随机变量. 由无向图 表示概率分布 ,即在图 中,结点 表示一个随机变量 ;边 表示随机变量之间的概率依赖关系.
局部马尔科夫性:设 是无向图 中任意一个结点, 是与 有边连接的所有结点, 是 , 以外的其他所有结点. 表示的随机变量是 , 表示的随机变量组是 , 表示的随机变量组是 . 局部马尔科夫性是指在给定随机变量组 的条件下随机变量 _vY_OP(Y_O |Y_W) > 0$
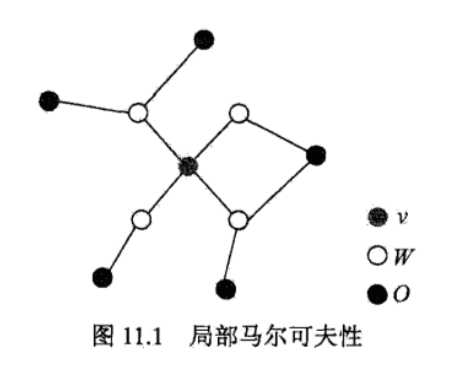
这里只给出局部马尔科夫性,还有等价的成对马尔科夫性、全局马尔科夫性,有兴趣的读者可以参考《统计学习方法》的 CRF 一章.
概率无向图模型: 设有联合概率分布 ,由无向图 表示,在图 中,结点表示随机变量,边表示随机变量之间的依赖关系.如果联合概率分布 满足成对、局部或全局马尔科夫性,就称此联合概率分布为概率无向图模型(probability undirected graphical model),或者马尔科夫随机场(Markov random field).
概率无向图模型的因子分解
团与最大团: 无向图 中任何两个结点均有边连接的结点子集称为团(clique).若 C 是无向图 的一个团,并且不能再加进任何一个 的结点使其成为一个更大的团,则称此 为最大团(maximal clique).
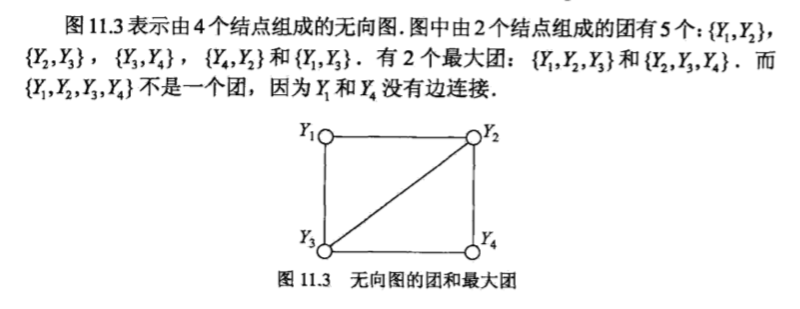
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解(factorization).
给定概率无向图模型,设其无向图为 , 为 上的最大团, 表示 对应的随机变量.那么概率无向图模型的联合概率分布 可写作图中所有最大团 上的函数 的乘积形式,即
Hammersley-Clifford 定理: 概率无向图模型的联合概率分布 可以表示为如下形式:
其中, 是无向图的最大团, 是 的结点对应的随机变量, 是 上定义的严格正函数,乘积是将无向图上所有的最大团的势函数相乘.
条件随机场
定义
有了上面的概率无向图模型基础,下面我们来定义条件随机场.
条件随机场: 设 与 是随机变量, 是在给定 的条件下 的条件概率分布. 若随机变量 构成一个由无向图 表示的马尔科夫随机场,即
在该定义中并没有要求 和 具有相同的结构. 现实中,一般假设 和 有相同的图结构.
在很多自然语言处理的标注问题中,都是应用的线性链条件随机场, 的结构相同,都是线性链.
线性链条件随机场: 设 均为线性链表示的随机变量序列,若在给定随机变量序列 的条件下,随机变量序列 的条件概率分布 构成条件随机场,即满足马尔科夫性:
则称 为线性链条件随机场. 在标注问题中, 表示输入观测序列, 表示对应的输出标记序列或状态序列.
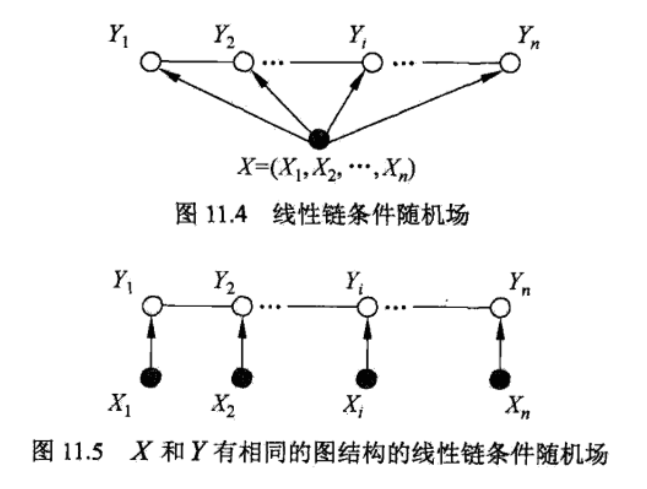
在线性链中,一个结点所在的最大团就两个,与其前一个结点构成一个最大团,与其后一个结点构成第二个最大团,于是线性链条件随机场的概率分布的分解式为:
线性链条件随机场的参数化形式
设 为线性链条件随机场,则在随机变量 取值为 的条件下,随机变量 取值为 的条件概率具有如下形式:
式中, 是特征函数, 是对应的权值. 是规范化因子,求和是在所有可能的输出序列上进行的.
上两式是线性链条件随机场模型的基本形式,表示给定输入序列 ,对输出序列 预测的条件概率.
式中 是定义在边上的特征函数,称为转移特征,因为它依赖于当前位置 和前一位置 ;
是定义在结点上的特征函数,称为状态特征,它仅依赖于当前位置.
都依赖于位置,是局部特征函数.通常,特征函数 取值为 1 或 0;当满足特征条件时取值为 1,否则为 0. 条件随机场完全由特征函数 和对应的权值 确定.
以一个简单的例子来说明什么是特征函数:
比如有一标注问题:输入观测句子为 ,输出标记序列为 ,其中 取值于 .
我们要识别出该句子中的人名 “小明” 和地名 “武汉”,于是可以构造特征函数如下:
假设我们就定义这两个特征函数(当然你可以定义多个,看你具体的应用场景是什么),这里是为了做命名实体识别,所以上面这两个特征函数都是转移特征函数;另外这里主要是考察特征函数,忽略特征函数的权值系数,则假设权值系数都取 1.
其中 表示位置 标注为 ,且位置 标注为 时满足该特征.(这一特征提取的是人名)
表示位置 标注为 ,且位置 标注为 时满足该特征.(这一特征提取的是地名)
所以只有当 序列被标注为 时特征函数的期望才是最大的,而此标注序列能正确的提取出人名和地名.
特征函数是 CRF 的核心,同时也不是特别好理解,读者可以通过这篇博客来体会: http://www.jianshu.com/p/55755fc649b1
条件随机场的简化形式
条件随机场还可以由简化形式表示,将局部特征转换成全局特征.
注意到条件随机场的条件概率表达式中同一特征在各个位置都有定义,可以对同一特征在各个位置求和,将局部特征函数转换为一个全局特征函数,这样就可以将条件随机场写成权值向量和特征向量的内积形式,即条件随机场的简化形式.
为了简便起见,首先将转移特征和状态特征及其权值用统一的符号表示.设有 个转移特征, 个状态特征,,记
然后,对特征与状态特征在各个位置 求和,记作
函数是 特征函数在所有位置上的累积值.
特征函数上面做了统一,可表示转移特征或者状态特征.
用 表示特征 的权值,即
统一特征函数的权值系数表示.
于是,条件随机场可表示为:
若以 表示权值向量,即
以 表示全局特征向量,即
则条件随机场可改写成向量 与 的内积形式:
其中,
这一步变换都比较简单,主要是认准两个元素————位置 和 特征函数,这两个元素可理解为两维的矩阵,不同的是按横向累加还是纵向累加.
条件随机场的矩阵形式
条件随机场还可以由矩阵表示,改写成类似于 HMM 中的转移矩阵.
假设 是由上面给出的线性链条件随机场,表示对给定观测序列 ,相应的标记序列 的条件概率.引进特殊的起点和终点状态标记 ,这时 可以通过矩阵形式表示.
对观测序列 的每一个位置 ,定义一个 阶矩阵( 是标记 取值的个数)
这就类似于 HMM 的转移矩阵了,当然每个
是不一样的.最后写成矩阵形式为:
其中的 为 所有可能的取值状态. 可以看到是不是有点类似 HMM 的转移矩阵?只不过这里的“转移概率”是按所有的特征函数算出的.
这样,给定观测序列 ,标记序列 的非规范化概率可以通过 个矩阵的乘积 表示,于是,条件概率 是:
其中, 为规范化因子,是 个矩阵的乘积的 (start,stop) 元素:
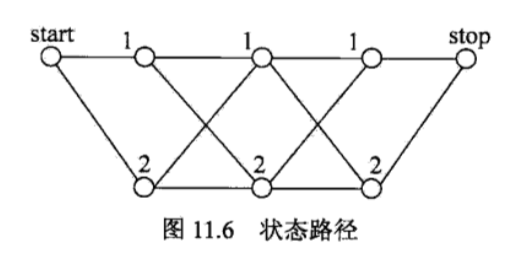
注意, 与 表示开始状态与终止状态,规范化因子 是以 start 为起点 stop 为终点通过状态的所有路径 的非规范化概率 之和.
矩阵形式不太好理解,这里给出一个例子来说明: 给定一个线性链条件随机场,观察序列 ,状态序列 ,,,标记 ,假设 ,各个位置的随机矩阵 分别是
试求状态序列 以 start 为起点 stop 为终点所有路径的非规范化概率及规范化因子.
解:首先计算从 start 到 stop 对应于
若以 为例来说明:
首先加上 start 和 stop 状态, 序列变成 ,于是 考虑从状态 1 转换到状态 1, 考虑从状态 1 转换到状态 1, 考虑从状态 1 转换到状态 2, 考虑从状态 2 转换到状态 1;于是概率连乘得
于是各路径的非规范化概率分别是:
规范化因子 通过计算矩阵乘积 可知,为所有路径的非规范化概率之和
条件随机场的概率计算问题
同隐马尔科夫模型一样,引进前向-后向向量,去计算 以及相应的数学期望问题.
前向-后向算法
对每个指标 ,定义前向向量 :
递推公式为
表示在位置 的标记是 并且到位置 的前部分标记序列的非规范化概率, 可取的值有 个,所以 是 维列向量.
同样,对每个指标 ,定义后向向量 :
递推公式为
表示在位置 的标记为 并且从 到 的后部分标记序列的非规范化概率.
由前向-后向向量定义不难得到:
这里, 是元素均为 1 的 m 维列向量.
概率计算
按照前向-后向向量的定义,很容易计算标记序列在位置 是标记 的条件概率和在位置 与 是标记 和 的条件概率:
这里与 HMM 中的类似, 相当于转移矩阵,由于 是由所有转移特征和状态特征计算出来的,状态特征的计算就包含了观测序列 的信息,所以 式的分子就没有 类似于 HMM 中的 这项.
期望值的计算
利用前向-后向向量,可以计算特征函数关于联合分布 和条件分布 的数学期望.
特征函数 关于条件分布 的数学期望是
其中,,
假设经验分布为 ,特征函数 关于联合分布 的数学期望是
其中,,
上两式是特征函数数学期望的一般计算公式.对于转移特征 ,可以将式中的 换成 ;对于状态特征,可以将式中的 换成 ,表示为 .
通过概率计算和期望值计算公式,对于给定的观测序列 与标记序列 ,可以通过一次前向扫描计算 及 ,通过一次后向扫描计算 ,从而计算所有的概率和特征的期望.
条件随机场的学习算法
条件随机场的学习算法常用的有迭代尺度法或改进的迭代尺度法,还有拟牛顿法。
笔者看过的实现中,拟牛顿法用的比较多,特别是 L-BFGS 算法,所下面列出拟牛顿法的算法过程,具体算法原理可参考前面的牛顿法与拟牛顿法 一章.
对于条件随机场模型:
学习的优化目标函数是:
其梯度函数是:
拟牛顿法的 BFGS 算法如下:
输入:特征函数 ;经验分布
输出:最优参数值 ;最优模型
选定初始点 ,取 为正定对称矩阵,置
计算 . 若 ,则停止计算;否则转第 3 步.
由 求出
一维搜索: 求 使得
置
计算 ,若 ,则停止计算;否则,按下式求出 :
其中,置 ,转第 3 步.
条件随机场的预测算法
同 HMM 一样,我们使用 Viterbi算法进行预测。
首先根据条件随机场的定义,预测问题的目标可以改为:
这里,路径表示标记序列,其中
注意,这时只需计算非规范化概率,而不必计算概率,可以大大提高效率.为了求解最优路径,将上式目标又可以改下成:
下面叙述维特比算法,首先求出位置 的各个标记 的非规范化概率:
其中,, 直到 时终止. 这时求得非规范化概率的最大值为
由此最优路径终点返回,
求得最优路径
输入: 模型特征向量 和权值向量 ,观测序列 ;
输出: 最优路径
初始化
递推. 对
其中,终止.
返回路径
求得最优路径
R 版 CRF 使用
java 源码分析
为分析 CRF 的实现过程,我们使用 github: https://github.com/asher-stern/CRF 的源码,该工程实现了基于CRF的标注,比如词性标注、命名实体识别等。
由于该工程没有提供数据集,所以运行不了,不过也是可以直接去从程序入口开始分析。该工程的大致流程笔者整理如下:
读取数据集
生成
Iterable<List<TaggedToken<K, G>>> corpus列表对象,其中每一个List<TaggedToken<K, G>>表示一条句子,句子中的每个TaggedToken<K, G>表示一个单词实体,单词实体的K表示 token,一般就是单词字符串了,G表示标注,如果是词性标注,那就是表示词性标注体系里的标签了。
由于项目中读取语料库比较复杂,我们可以直接跳过,若要应用自己的项目中,可以替换为自己语料库的解析。生成 CRF 的特征函数
把语料库中每个标注与对应的观察值作为状态特征,把前一个标注转移到当前标注,作为转移特征。统计完成后可以做一些过滤,比如特征数量出现次数特别少的过滤掉等等。
训练各个特征函数的权重
使用 L-BFGS 拟牛顿法训练各个特征函数的权重,结合标注集与特征函数集,构成 CRF 完整的模型。
测试语料标注评估
使用 Viterbi 算法对新句子进行解码,预测出最有可能的标注序列。
程序入口为 com.asher_stern.crf.postagging.demo.TrainAndEvaluate.java 的 main() 方法:
public static void main(String[] args) {//传入语料库路径、训练集大小、测试集大小、模型保存路径new TrainAndEvaluate(args[0], Integer.parseInt(args[1]), testSize, loadSaveDirectoryName).go();}
在 go() 方法中做模型训练和测评:
public void go() {//加载语料库TrainTestPosTagCorpus<String, String> corpus = createCorpus();//用训练数据集去训练模型PosTagger posTagger = train(corpus.createTrainCorpus());//用测试语料集去评估模型AccuracyEvaluator evaluator = new AccuracyEvaluator(corpus.createTestCorpus(), posTagger);evaluator.evaluate();}
加载语料库所得到的数据格式在上面介绍项目流程时已经说了,我们直接看训练部分。
private PosTagger train(Iterable<? extends List<? extends TaggedToken<String, String>>> corpus) {//创造训练器,构造特征函数CrfPosTaggerTrainer trainer = new CrfPosTaggerTrainerFactory().createTrainer(corpusAsList);//此时 trainer 已生成特征函数 and 过滤集trainer.train(corpusAsList);if (loadSaveDirectoryName != null) {File saveDirectory = new File(loadSaveDirectoryName);//保存训练好的模型trainer.save(saveDirectory);}}
从上面的理论部分可知,CRF模型的核心就是特征函数的构造,这个项目中特征函数的构造比较简单,不过从实现过程我们可以更深入的理解特征函数是如何构造的,以及如何优化。因此我们源码分析重点就分析下特征函数的构造,而训练部分就比较常规了,使用 L-BFGS 算法,可以参考 《拟牛顿法》 进行学习。
public CrfPosTaggerTrainer createTrainer(List<List<? extends TaggedToken<String, String>>> corpus) {CrfTrainerFactory<String, String> factory = new CrfTrainerFactory<String, String>();// 创造训练器,训练器里去构造特征函数CrfTrainer<String, String> crfTrainer = factory.createTrainer(corpus,(Iterable<? extends List<? extends TaggedToken<String, String>>> theCorpus,Set<String> tags) -> new StandardFeatureGenerator(theCorpus, tags),new StandardFilterFactory());//训练器与标注器互持引用CrfPosTaggerTrainer trainer = new CrfPosTaggerTrainer(crfTrainer);return trainer;}
createTrainer() 方法主要是为了构造特征函数,并对里面的一些数据结构进行封装;参数主要有三个,第一个是语料集,第二个是封装的特征函数生成器,第三个是特征函数过滤器。
public CrfTrainer<K, G> createTrainer(List<List<? extends TaggedToken<K, G>>> corpus,CrfFeatureGeneratorFactory<K, G> featureGeneratorFactory, FilterFactory<K, G> filterFactory) {//传入语料集,Crf特征生成器,过滤器CrfTagsBuilder<G> tagsBuilder = new CrfTagsBuilder<G>(corpus);//先生成标注集tagsBuilder.build();CrfTags<G> crfTags = tagsBuilder.getCrfTags();CrfFeatureGenerator<K, G> featureGenerator = featureGeneratorFactory.create(corpus, crfTags.getTags());// 生成特征函数,包括状态特征和转移特征featureGenerator.generateFeatures();//包含状态特征和转移特征;状态特征是忽略大小写特征,转移特征是TagTransitionFeatureSet<CrfFilteredFeature<K, G>> setFilteredFeatures = featureGenerator.getFeatures();// 特征函数已生成,做了一个数据结构的封装CrfFeaturesAndFilters<K, G> features = createFeaturesAndFiltersObjectFromSetOfFeatures(setFilteredFeatures, filterFactory);return new CrfTrainer<K, G>(features, crfTags);}
从上面的流程可看成,主要是两步:
标注集统计
统计标注集有哪些,每个标注的前后标注有哪些,用于标注转移矩阵的统计生成。特征函数生成
特征函数包括状态特征、转移特征,分别统计。
public void build() {Set<G> tags = new LinkedHashSet<G>();Map<G, Set<G>> canPrecede = new LinkedHashMap<G, Set<G>>();Map<G, Set<G>> canFollow = new LinkedHashMap<G, Set<G>>();//对每句进行处理for (List<? extends TaggedToken<?, G>> sentence : corpus) {G previousTag = null;//对每个单词实体进行处理,包括token、tagfor (TaggedToken<?, G> taggedToken : sentence) {G tag = taggedToken.getTag();// Set 集合,统计有多少个不同的标注tags.add(tag);// tag 的前 tag 为 previousTagCrfUtilities.putInMapSet(canPrecede, tag, previousTag);// previousTag 的后 tag 为 tagCrfUtilities.putInMapSet(canFollow, previousTag, tag);previousTag = tag;}}//前向集合与后向集合补全addEmptySets(canPrecede, tags);addEmptySets(canFollow, tags);// crf tags 包含 tag集合,每个tag 可能的前tag 和 后tag 集合crfTags = new CrfTags<G>(tags, canFollow, canPrecede);}
上面统计了所有标注类别,构成集合 tags,每个标注的前向标注集 canPrecede,每个标注的后向标注集 canFollow。据此可以生产标注转移的转移矩阵。
下面看 StandardFeatureGenerator类分析特征函数的构造:
public void generateFeatures() {setFilteredFeatures = new LinkedHashSet<CrfFilteredFeature<String, String>>();addTokenAndTagFeatures(); //添加所有的状态特征addTagTransitionFeatures(); //添加所有的转移特征}
先是添加状态特征:
private void addTokenAndTagFeatures() {//对每条语料进行处理for (List<? extends TaggedToken<String, String>> sentence : corpus) {//对每个单词实体进行处理for (TaggedToken<String, String> taggedToken : sentence) {//从观察值到标注构成一条状态特征setFilteredFeatures.add(new CrfFilteredFeature<String, String>(//这是一条忽略大小写的特征new CaseInsensitiveTokenAndTagFeature(taggedToken.getToken(), taggedToken.getTag()),new CaseInsensitiveTokenAndTagFilter(taggedToken.getToken(), taggedToken.getTag()), true));}}}
然后是转移特征:
private void addTagTransitionFeatures() {//前后标注转移构成转移特征函数for (String tag : tags) {//第一个标注由 null 标注转移到当前标注setFilteredFeatures.add(new CrfFilteredFeature<String, String>(new TagTransitionFeature(null, tag),new TwoTagsFilter<String, String>(tag, null), true));//前标注转移到当前标注for (String previousTag : tags) {setFilteredFeatures.add(new CrfFilteredFeature<String, String>(//前状态转换到当前状态new TagTransitionFeature(previousTag, tag),new TwoTagsFilter<String, String>(tag, previousTag), true));}}}
将状态特征与转移特征合并到一起,构成 CRF模型的特征函数集合;不过按上面这张方法构造特征函数的数量会非常大,我们需要利用一些规则去把不常用的特征或者噪音特征给过滤掉。
后面统计每个特征函数出现次数的时候,可以把出现次数比较小的特征函数给过滤掉,从而优化模型;另外也可以在训练数据完成后,把权值较小的特征函数过滤掉。
这几步就可以构造完特征函数,然后 new CrfTrainer<K, G>(features, crfTags); 封装成 CRF训练器,用于后面 CRF 特征函数的权重训练。
训练过程需要注意的是,不同于一般的 L-BFGS 算法,使用的函数是 CRF 模型的势函数,即在源码中 function.value(point) 计算的是势函数的值,计算所有样本的势函数之和,即考虑全局信息。
小结
本文详细分析了 CRF 模型的原理,并结合 java版本的 CRF 做标注问题的源码分析了 CRF 模型实现过程。
CRF 模型训练是为了得到各个特征函数的权值,与特征函数和标注集一起,构成完整的 CRF 模型。
训练的核心就是构造特征函数,因为前面理论部分对特征函数是如何构造的也没讲清楚,不过我们通过代码分析具体实现过程清楚了。后面的模型训练没细讲,读者有兴趣可参看前面的《拟牛顿法》一篇进行分析。
参考
- 《统计学习方法》——李航
