@evilking
2018-05-15T14:49:27.000000Z
字数 5102
阅读 2217
大数据平台篇
Hive搭建
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
本篇接着前面两篇(配置虚拟机,搭建Hadoop环境)的基础上来搭建hive,读者对本篇中提到的路径和配置不是很了解的可以先参考前面两篇的内容
本篇是以 evilking 用户登录到虚拟机中的
Hive下载
hive的官方下载地址: http://mirrors.tuna.tsinghua.edu.cn/apache/hive/
这里有hive的各个版本,本文档演示的版本是hive-2.1.1,下载下来的文件为apache-hive-2.1.1-bin.tar.gz,通过虚拟机搭建一篇中的SecureFX工具将该压缩文件传到虚拟机中,然后解压:
比如笔者是将hive的压缩文件传到 /home/evilking/Document/ 目录下,则:
[evilking@master Documents]$ tar -xvf apache-hive-2.1.1-bin.tar.gz
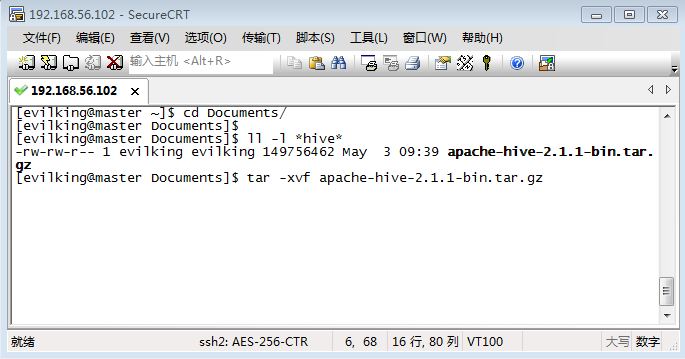
然后将hive的解压文件夹移动到 /opt/目录下:
[evilking@master Documents]$ sudo mv apache-hive-2.1.1-bin /opt/hive
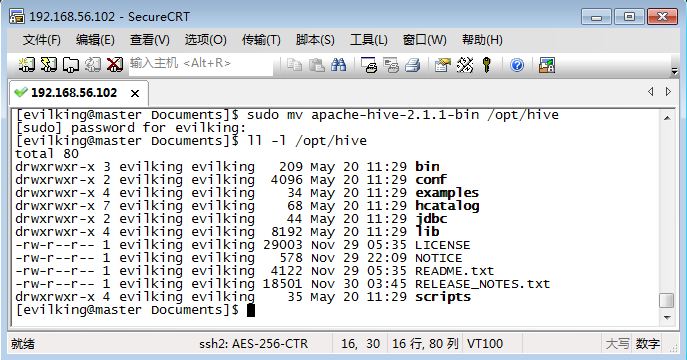
Hive配置
Hive环境变量的配置
将hive目录添加到PATH环境变量中:
[evilking@master hive]$ sudo vim /etc/profile
使环境变量修改生效:
[evilking@master hive]$ source /etc/profile
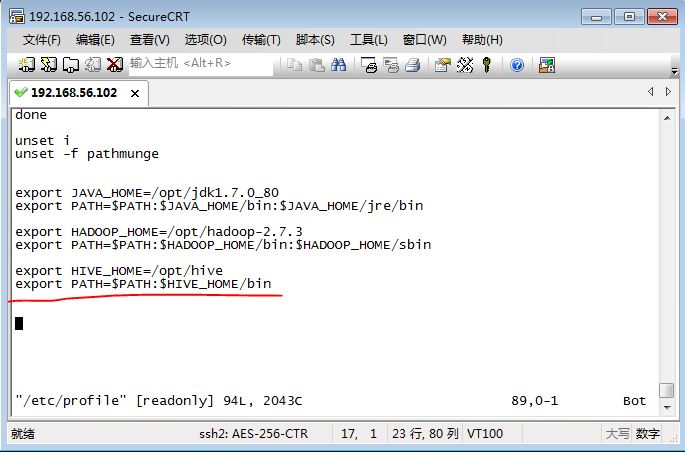
其中:
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
环境变量设置好后,就可以在任意路径下直接通过hive命令来操作hive了,hive没有类似于hive -version的命令查看hive的版本,但是可以通过hive --help来查看:
[evilking@master hive]$ hive --help
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/home/evilking/.local/bin:/home/evilking/bin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/opt/hive/bin)
Usage ./hive <parameters> --service serviceName <service parameters>
Service List: beeline cleardanglingscratchdir cli hbaseimport hbaseschematool help hiveburninclient hiveserver2 hplsql hwi jar lineage llapdump llap llapstatus metastore metatool orcfiledump rcfilecat schemaTool version
Parameters parsed:
--auxpath : Auxillary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
[evilking@master hive]$
可以看到hive的环境变量配置好了
Hive配置表的配置
在目录 $HIVE_HOME/conf/ 下,修改属性文件,执行下列命令:
首先在 $HIVE_HOME/ 目录下创建一个 logs 子目录,用来存放hive的日志文件
[evilking@master hive]$ mkdir $HIVE_HOME/logs
#切换到conf目录下
[evilking@master conf]$ cd $HIVE_HOME/conf/
#查看属性文件的模板文件
[evilking@master conf]$ ll hive-log4j2.properties.template
-rw-r--r-- 1 evilking evilking 2925 Nov 29 05:32 hive-log4j2.properties.template
#拷贝一份属性文件重命名
[evilking@master conf]$ cp hive-log4j2.properties.template hive-log4j2.properties
#修改hive的配置文件
[evilking@master conf]$ vim hive-log4j2.properties
修改 property.hive.log.dir = /opt/hive/logs/,其中属性文件中的property.hive.log.level属性是代表日志打印时的级别,默认为INFO,读者可以根据需要修改为WARING,以避免终端打印过多的信息
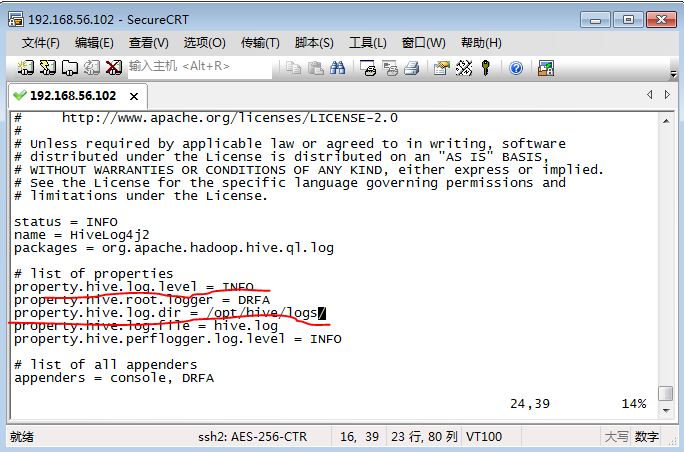
Hive启动
由于Hive默认内嵌的是 derby 数据库,所以配置文件可以暂时先配置这么多即可启动Hive
由于hive的数据文件是放在hadoop上的,所以启动hive前,先得用start-all.sh脚本启动hadoop:
[evilking@master hive]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-namenode-master.out
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-datanode-master.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.3/logs/yarn-evilking-resourcemanager-master.out
localhost: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-evilking-nodemanager-master.out
#用jps命令查看hadoop各组件的启动情况
[evilking@master hive]$ jps
5760 NodeManager
5498 SecondaryNameNode
6060 Jps
5652 ResourceManager
5189 NameNode
5325 DataNode
[evilking@master hive]$
这个时候hadoop就启动成功了;在Hive的官方文档 上描述,Hive2.1 的启动需要先执行 $HIVE_HOME/bin/schematool -dbType <db type> -initSchema 命令,先使用默认的 derby 数据库运行该命令:
[evilking@master hive]$ schematool -dbType derby -initSchema
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/home/evilking/.local/bin:/home/evilking/bin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/opt/hive/bin)
.......
[org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 2.1.0
Initialization script hive-schema-2.1.0.derby.sql
Initialization script completed
schemaTool completed
[evilking@master hive]$
可以看到最后的schemaTool completed,说明hive初始化成功了;下面就可以通过hive命令进入到 Hive Shell 操作了:
[evilking@master hive]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/home/evilking/.local/bin:/home/evilking/bin:/opt/jdk1.7.0_80/bin:/opt/jdk1.7.0_80/jre/bin:/opt/hadoop-2.7.3/bin:/opt/hadoop-2.7.3/sbin:/opt/hive/bin)
......
[org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in file:/opt/hive/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
hive>
可以看到进入到hive shell里去了,这就说明Hive安装成功了,这个时候就可以运行hive命令来操作hive数据库了
#查看hive数据库中的表
hive> show tables;
OK
Time taken: 1.066 seconds
hive>
默认情况下,Hive的元数据保存在了内嵌的derby数据库里,但一般情况下生产环境使用 MySQL 来存放Hive元数据信息
