@evilking
2018-05-02T15:00:07.000000Z
字数 14226
阅读 6007
回归分析篇
多元线性回归
前一篇讲了一元线性回归,但是实际应用中多半都是要考察多个因素对某个因素的影响,这就需要跨越到多元回归分析了
本篇先介绍多元线性回归分析的一般理论,然后以一个完整的小例子来应用这些理论
多元线性回归模型
设随机变量 与一般变量 的线性回归模型为
其中, 是 个未知参数, 称为回归常数, 称为回归系数。 称为被解释变量(因变量),而 是 个可以精确测量并可控制的一般变量,称为解释变量(自变量)。我们称上述式子为多元线性回归模型。是随机误差,与一元线性回归一样,对随机误差项我们常假定
对一个实际的问题,我们获得 组观察数据 则线性回归模型可表示为
写成矩阵形式为
其中,
矩阵 是一 矩阵,称 为回归设计矩阵或资料矩阵。在实验设计中, 的元素是预先设定并可以控制的,人的主观因素可作用于其中,因而称 为设计矩阵。
多元线性回归模型的基本假定
为了方便地进行模型的参数估计,对方程由如下一些基本假定:
解释变量 是确定性变量,不是随机变量,且要求 。这里的 ,表明设计矩阵 中的自变量列之间不相关,样本容量的个数应大于解释变量的个数, 是一满秩矩阵.
随机误差项具有0均值和等方差,即
这个假定常称为高斯-马尔科夫条件。,即假设观察值没有系统误差,随机误差 的平均值为零。随机误差项 的协方差为零表明随机误差项在不同的样本点之间是不相关的(在正态假定下即为独立的),不存在序列相关,并且有相同的精度。正态分布的假定条件为
对于多元线性回归的矩阵形式可表示为
有上述假定和多元正态分布的性质可知,随机向量 遵从 维正态分布,回归模型的期望向量
因此,
多元线性方程组的普通最小二乘法
多元线性回归方程未知参数 的估计与一元线性回归方程的参数估计原理一样,任然可以采用最小二乘法估计。
与一元线性回归方程的最小二乘法推导一致,寻找 满足
求出的 就称为回归参数 的最小二乘估计
这是个求极值的问题,于是求偏导得
以上方程组经整理后,用矩阵的形式表示为:
回归值与残差
在求出回归参数的最小二乘估计后,就可以用经验回归方程求出因变量的回归值与残差:
称
记 为残差向量 的协方差阵,或称方差阵,记为 ,因而
于是有
回归方程的显著性检验
在实际问题的研究中,我们事先并不能断定随机变量与变量之间确实有线性关系,我们对与变量做多元线性回归拟合,只是根据一些定性分析所作的假设。
因此,当求出线性回归方程后,还需要对回归方程进行显著性检验。
与一元回归分析类似,多元回归分析这里介绍两种统计检验方法,回归方程显著性的 检验,以及回归系数显著性的 检验;同时介绍衡量回归拟合程度的拟合优度检验
检验
与一元线性回归的 检验类似的提出原假设,由于有多元,所以原假设为
为了建立对 进行检验的 统计量,任然利用总离差平方和分解式,即
该总离差平方和分解式的推导过程可参考一元线性回归中的过程
构造 检验统计量如下:
对于给定的数据,,计算出和,进而得到的值,其计算过程一般列在方差分析表中,再由给定的显著性水平 ,查 分布表,得临界值 ;
其中方差分析表(ANOVA)如下所示:
| 方差来源 | 自由度 | 平方和 | 均方 | F值 | P值 |
|---|---|---|---|---|---|
| 回归 | |||||
| 残差 | |||||
| 总和 |
当 时,拒绝原假设 ,认为在显著性水平 下,对有显著的线性关系,也就是说回归方程显著;反之,当 时,则认为回归方程不显著。
与一元线性回归一样,也可以根据 值作检验。当 时,拒绝原假设;当 时,接受原假设。
当回归方程显著时,说明用线性方程来拟合是有效的;当回归方程不显著时,说明自变量与因变量不满足线性关系,这时就需要考虑其他非线性关系,或者对自变量或因变量做变换后再考虑线性关系
回归系数的显著性检验
在多元线性回归中,回归方程显著并不意味着每个自变量对 的影响都显著,因此我们总想从回归方程中剔除那些次要的、可有可无的变量,重新建立更为简单的回归方程。所以我们需要对每个自变量进行显著性检验
这里我们使用的是 检验,在一元线性回归分析中,由于只有一个自变量,所以对该自变量进行回归系数的显著性检验也相当于是对回归方程进行显著性检验;但是在多元线性回归分析中,对回归系数的显著性检验与回归方程的显著性检验就不一样了
类似的,检验变量 是否显著,等价于检验假设
由于
据此可以构造 统计量
当原假设 成立时,上式构造的 统计量服从自由度为 的 分布。
给定显著性水平 ,查出双侧检验的临界值 。当 时拒绝原假设,认为 显著不为零,自变量 对因变量 的线性效果显著;当 时接受原假设,认为 为零,自变量 对因变量 的线性效果不显著。
若发现有自变量 不显著,则需要考虑剔除掉这些不显著的自变量,可一次只剔除一个变量,先剔除其中 值最小的(或值最大的)一个变量,然后再对求得的新的回归方程进行检验,有不显著的变量再剔除,直到保留的变量都对 有显著影响为止
关于如何处理不显著的自变量,在后面讲逐步回归时会详细讲解
回归系数的置信区间
当我们有了参数向量 的估计量 时,这两者的接近程度如何呢?这就需要构造 的一个区间,以 为中心的区间,该区间以一定的概率包含
我们知道
拟合优度
拟合优度用于检验回归方程对样本观测值的拟合程度。
在一元线性回归中,定义了样本决定系数 ,在多元线性回归中,同样可以定义样本决定系数为
与 检验相比,可以更清楚直观地反映回归拟合的效果,但是并不能作为严格的显著性检验.
称
实际应用中,人们用复相关系数 来表示回归方程对原有数据拟合程度的好坏,它衡量作为一个整体的 与 的线性关系的大小
中心化和标准化
在多元线性回归分析中,因为涉及到多个自变量,自变量的单位往往不同,给利用回归方程进行结构分析带来了一定困难;再因为多元回归涉及的数据量很大,就可能由于舍入误差而使计算结果不理想。因此,对原始数据进行一些处理,尽量避免大的误差是有意义的.
产生舍入误差有两个主要原因:
- 一是回归分析计算中数据量级有很大差异;
- 二是设计矩阵 的列向量近似线性相关时,为病态矩阵,其逆矩阵 就会产生较大的误差.
中心化
多元线性回归模型的一般形式为
上述经验方程式即转变为
其中 可求出常数项估计值
中心化就是将经验回归方程作了平移变换,将样本中心移到了坐标原点
标准化
在中心化的基础上,为了消除量纲不同和数量级的差异所带来的影响,就需要对样本数据作标准化处理,然后用最小二乘法估计未知参数,求得标准化回归系数
样本数据的标准化公式为
而
用最小二乘法求出标准化的样本数据 的经验回归方程,记为
标准化包括了中心化,因而标准化的回归常数为0;容易验证,标准化回归系数与普通最小二乘回归系数之间存在关系式
标准化回归系数是比较自变量对 影响程度相对重要性的一种较为理想的方法,但是我们对回归系数的解释任需谨慎,这是因为当自变量相关时会影响标准化回归系数的大小.
相关阵
复相关系数 反映了 与一组自变量的相关性,是整体和共性指标,简单相关系数反映的是两个变量间的相关性,是局部和个性指标.
由样本观测值 ,分别计算 与 之间的简单相关系数 ,得自变量样本相关阵
注意相关阵是对称矩阵。
记 表示中心标准化的设计阵,则相关阵可表示为
这里不介绍 偏决定系数了,感兴趣的读者可以自行百度学习
在多元线性回归分析中,当其他变量被固定后,给定的任两个变量之间的相关系数,叫做偏相关系数
偏相关系数可以度量 个变量 之中任意两个变量的线性相关程度,而这种相关程度是在固定其余 个变量的影响下的线性相关
R程序作多元线性回归的演示实例
这里参考一网友的多元线性回归分析的例子,http://blog.csdn.net/lance313/article/details/51241142
使用的训练数据: csv格式,含有19维特征
数据下载地址: http://pan.baidu.com/s/1eSx1fwe
数据准备
将下载好的两个csv文件放在R的工作目录下,可通过getwd()函数查看当前工作目录
rm(list = ls(all = TRUE)) #清空工作空间
library(car)
library(corrplot,quietly = TRUE)
##数据读取
name <- "vt.csv"
namepre <- "vp.csv"
#训练集
dataset <- read.csv(name,na.strings = c(".","NA","","?"),strip.white = TRUE,encoding = "UTF-8")
#预测集
datasetpre <- read.csv(namepre, na.strings = c(".","NA","","?"),strip.white = TRUE,encoding = "UTF-8")
head(datasetpre)
head(dataset)
datapre <- datasetpre[,-1]
##训练集准备
datatrain <- dataset[,-ncol(dataset)]
datatarget <- dataset$t
> head(dataset)
v1 v2 v3 v4 v5 v6 v7 v8 v9 v10 v11 v12 v13 v14 v15 v16 v17 v18 v19 t
1 1 1 1 3 1 1 3 3 13 13 13 14 13 13 18 18 13 13 12 96
2 3 2 2 2 2 2 3 2 78 48 47 50 47 48 83 52 57 38 38 166
3 2 2 2 2 2 2 2 2 15 14 14 18 14 14 23 22 29 28 27 13
4 52 49 48 64 48 49 91 88 328 297 288 419 288 297 530 493 287 278 274 1002
5 0 0 0 0 0 0 0 0 20 6 6 6 6 6 26 7 3 2 2 10
6 0 0 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 4
> head(datasetpre)
item_id v1 v2 v3 v4 v5 v6 v7 v8 v9 v10 v11 v12 v13 v14 v15 v16 v17 v18 v19
1 197 2 2 2 4 2 2 4 4 38 37 37 46 37 37 58 57 41 39 38
2 300 0 0 0 0 0 0 0 0 6 4 4 4 4 4 6 4 16 13 13
3 535 5 5 5 5 5 5 5 5 18 18 18 18 18 18 20 20 28 26 26
4 585 4 4 4 4 4 4 5 5 27 26 26 32 26 26 36 35 28 24 24
5 727 4 4 4 4 4 4 6 6 172 169 162 202 162 169 248 244 147 146 140
6 1765 1 1 1 2 1 1 4 4 13 13 13 14 13 13 18 17 13 13 13
>
相关性检测
#相似矩阵
cor <- cor(dataset,use = "pairwise",method = "pearson")
cor
corrplot(cor) #相关阵图
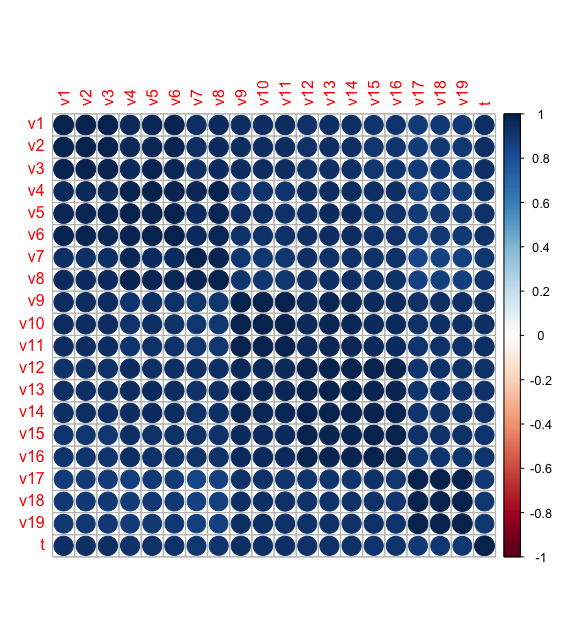
从结果可以看到,自变量之间存在非常严重的共线性,不能直接作为回归参数输入;若自变量之间的线性关系超过自变量与因变量之间的线性关系,则回归模型稳定性受到破坏.
主成分分析
利用主成分分析来确定主成分因子,从而可以去掉一些影响不大的自变量
#主成分分析
pca <- princomp(datatrain,cor = T)
summary(pca,loadings = T)
screeplot(pca,type = "lines") #主成分分析的碎石图
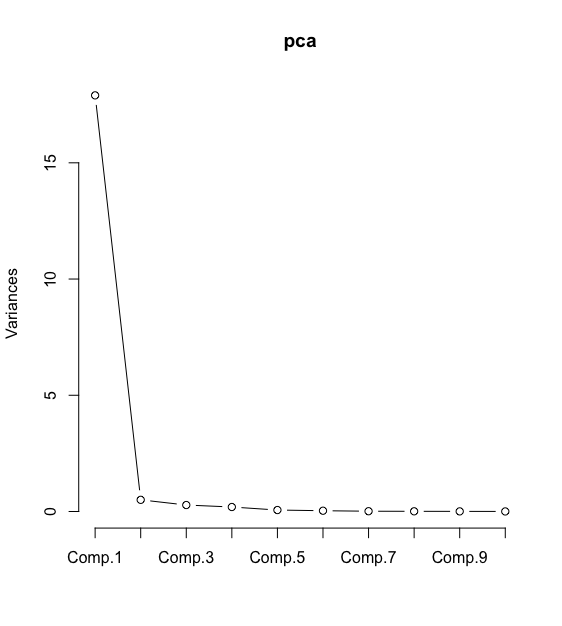
从图中可以看成,仅用两个主成分即可解释96.8%的累积误差,因此选用 Comp.1和Comp.2进行建模
#重新整理数据
loading <- as.data.frame(pca$loadings[])
comps <- as.data.frame(as.matrix(datatrain) %*% as.matrix(loading))
建立多元回归模型
> lmP <- lm(formula = dataset$t ~ comps$Comp.1+comps$Comp.2) #利用两个主成分做多元线性回归拟合
> summary(lmP)
Call:
lm(formula = dataset$t ~ comps$Comp.1 + comps$Comp.2)
Residuals:
Min 1Q Median 3Q Max
-346.46 -7.58 -3.99 2.13 539.17
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.98998 3.66767 1.088 0.27753
comps$Comp.1 -0.93848 0.08962 -10.472 < 2e-16 ***
comps$Comp.2 -0.44861 0.14896 -3.012 0.00282 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 59.48 on 298 degrees of freedom
Multiple R-squared: 0.8913, Adjusted R-squared: 0.8905
F-statistic: 1221 on 2 and 298 DF, p-value: < 2.2e-16
>
模型检验结果为:
- 拟合优度检验
为0.8905,自变量与因变量之间具有较强的线性关系 - 估计标准误差检验
RSE值为 59.48 - 回归方程显著性检验(检验)
检验结果为1221,p-value < 2.2e-16,非常显著,所有自变量与因变量的线性关系密切 - 回归系数显著性检验(检验)
可以看到Comp.1,Comp.2的p-value均小于0.05,表明这两个自变量对模型影响显著
多重共线性检验
> #多重共线性检验
> compsx <- comps[c("Comp.1","Comp.2")]
> x <- cor(compsx,use = "pairwise",method = "pearson")
> kappa(x)
[1] 172.2621
>
可以看到,kappa值等于172,任具有较强的多重共线性,因为 k < 100,可认为不存在多重共线性
逐步回归
可进一步利用step函数选取精简变量,从而消除多重共线性的影响
> step(lmP)
Start: AIC=2462.52
dataset$t ~ comps$Comp.1 + comps$Comp.2
Df Sum of Sq RSS AIC
<none> 1054211 2462.5
- comps$Comp.2 1 32084 1086295 2469.5
- comps$Comp.1 1 387936 1442147 2554.8
Call:
lm(formula = dataset$t ~ comps$Comp.1 + comps$Comp.2)
Coefficients:
(Intercept) comps$Comp.1 comps$Comp.2
3.9900 -0.9385 -0.4486
>
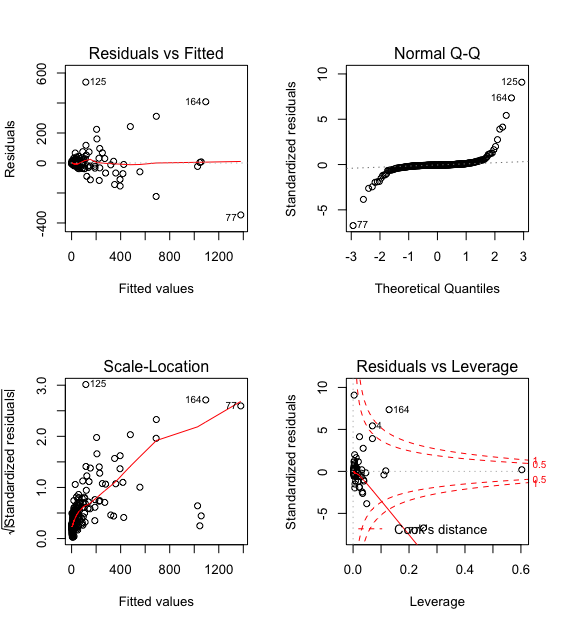
发现回归方程并没有改善,需要进行残差分析看看
残差分析
> #残差分析
> par(mfrow = c(2,2))
> plot(lmP)
>
预测
comppre <- as.data.frame(as.matrix(datapre) %*% as.matrix(loading))[c(1,2,3)]
coe <- as.matrix(lmP$coefficients)
tpre <- as.matrix(comppre) %*% coe
output <- data.frame(datasetpre[,1],as.data.frame(tpre))
