@evilking
2018-05-01T14:47:30.000000Z
字数 5778
阅读 1911
时间序列篇
序列预测
所谓预测,就是要利用序列已观察到的样本值对序列在未来某个时刻的取值进行估计.
目前对平稳序列最常用的预测方法是线性最小方差预测.线性是指预测值为观察值的线性函数,最小方差是指预测方差达到最小.
线性预测函数
根据 模型的平稳性和可逆性,可以用传递性和逆转形式等级描述该序列:
式中, 为 Green 函数值; 为逆转函数值.
代入可得:
显然 是历史数据 的线性函数,不妨简记为:
对任意一个未来时刻 而言,该时刻的序列值 也可以表示成它的历史数据 的线性函数:
但问题是其中只有部分历史信息 是已知的,还有部分信息 都是未知的.
一个有趣的现象是,根据线性函数的可加性,所有的未知历史信息 都可以用已知历史信息 的线性函数表示出来.以 为例,已知
式中,是未知信息.
把 代入上式,得:
由此, 最终表示为已知历史信息 的线性函数.
同理,对于未来任意 时刻的序列值 ,最终都可以表示成已知历史信息的线性函数,并用该函数形式估计 的值:
也称为序列 的第 步预测值.
预测方差最小原则
用 衡量预测误差:
显然,预测误差越小,预测精度就越高.因此,目前最常用的预测原则是预测方差最小原则,即
因为 为 的线性函数,所以该原则也称为线性预测方差最小原则.
根据 平稳模型的性质和线性函数的可加性,显然有
则
预测方差为:
显然,要使得预测方差达到最小,必须有
这时, 的预测值为:
预测误差为:
由于 为白噪声序列,所以:
线性最小方差预测的性质
条件无偏最小方差估计值
序列值 可以如下分解:
因为
即在 已知的条件下, 为常数,有
推导出
这说明在预测方差最小原则下得到的估计值 是序列值 在 已知的情况下得到的条件无偏最小方差估计值,且预测方差只与预测步长 有关,而与预测起始点 无关.但预测步长 越大,预测值的方差也越大,因而为了保证预测的精度,时间序列数据通常只适合做短期预测.
序列预测
在 序列场合:
式中:
预测方差为:
下面还是以我国邮路及农村投递线路每年新增里程数为例,演示模型预测:
> library(forecast)> a <- read.table("data/file8.csv",sep = ",", header = T)> x <- ts(a$kilometer, start = 1950)> x.fit <- arima(x,order = c(2,0,0), method = "ML")> x.fore <- forecast(x.fit,h = 5)> x.forePoint Forecast Lo 80 Hi 80 Lo 95 Hi 952009 9.465302 -15.02455 33.95516 -27.98870 46.919302010 6.214789 -23.94131 36.37089 -39.90499 52.334562011 8.392250 -21.76556 38.55006 -37.73015 54.514652012 11.677647 -19.95516 43.31046 -36.70056 60.055862013 12.885518 -19.44684 45.21788 -36.56256 62.33360#系统默认输出预测图> plot(x.fore)
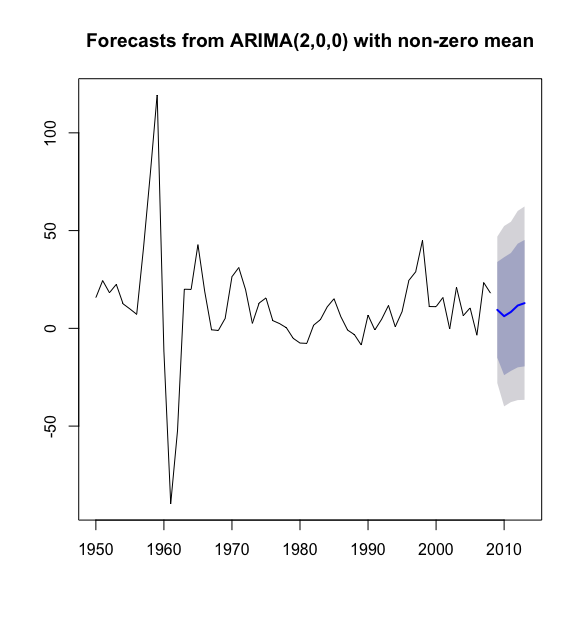
#个性化输出预测图> L1 <- x.fore$fitted -1.96*sqrt(x.fit$sigma2)> U1 <- x.fore$fitted + 1.96*sqrt(x.fit$sigma2)> L2 <- ts(x.fore$lower[,2],start = 2009)> U2 <- ts(x.fore$upper[,2],start = 2009)> c1 <- min(x,L1,L2)> c2 <- max(x,L2,U2)> plot(x,type="p",pch=8,xlim=c(1950,2013),ylim=c(c1,c2))> lines(x.fore$fitted,col=2,lwd=2)> lines(x.fore$mean,col=2,lwd=2)> lines(L1,col=4,lty=2)> lines(U1,col=4,lty=2)> lines(L1,col=4,lty=2)> lines(L2,col=4,lty=2)> lines(U2,col=4,lty=2)>
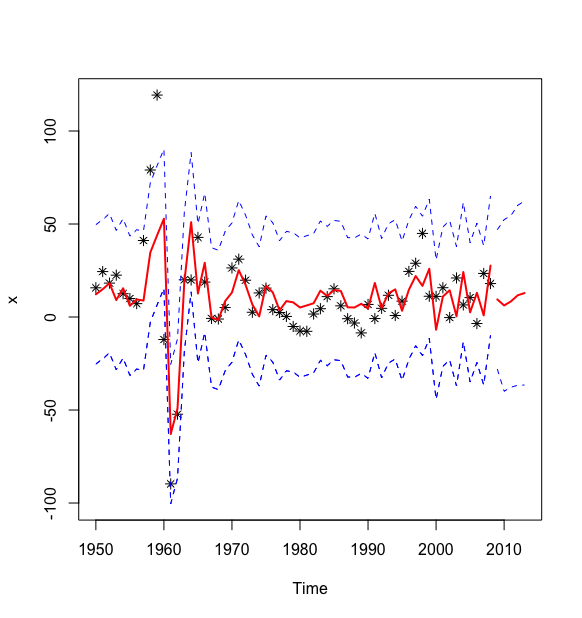
序列预测
对一个 序列 而言,有
在 已知的条件下求 的估计值,就等价于在 已知的条件下求 的估计值,而未来时刻的随机扰动 是不可预测的,属于预测误差.
所以: 当预测步长小于等于 模型的阶数 时, 可以分解为:
即 序列 步的预测值为:
这说明 序列理论上只能预测 步之内的序列走势,超过 步预测值恒等于序列均值.这是由 序列自相关 步截尾的性质决定的.
序列预测方差为:
序列预测
在 模型场合:
式中:
预测方差为:
