@evilking
2018-05-01T10:11:50.000000Z
字数 9419
阅读 3024
机器学习篇
高斯判别分析
简介
高斯判别分析(Gaussian discriminative analysis)是一个较为直观的模型,基本的假设是我们得到的数据是独立同分布的(IID),虽然在实际中这种假设很难达到,但有时候拥有了好的假设可以得到较好的结果。
在Andrew Ng大神的CS229 Lecture notes中有一个例子:
假设我们要对大象和狗分类,回归模型和感知机模型是在两类数据之间找到一个判决边界(decision boundary),通过这个decision boundary来区分大象和狗。
高斯判别分析提供了另外一种思路:
首先我们观察大象,对大象建立一个模型来描述他的特点;
再观察狗,并建立相应的模型来描述狗。
当一个新的狗或者象过来时,我们首先带入象模型和狗模型,对比两者的满足不同模型的概率,最后决定新来的的动物的类别。
多元高斯分布
我们处理的数据往往是多维了,因此高斯分布也应该是多维的。
我们先回顾一下一维正态分布:
该分布通常记为: ,当 时的正态分布是标准正态分布.
正态分布: https://baike.baidu.com/item/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83/829892?fr=aladdin
正态分布也叫高斯分布.
那么, 维正态分布表示为:
协方差: https://www.zhihu.com/question/20852004
协方差矩阵: https://baike.baidu.com/item/%E5%8D%8F%E6%96%B9%E5%B7%AE%E7%9F%A9%E9%98%B5/9822183
当 是二维的时候可以如下图表示:
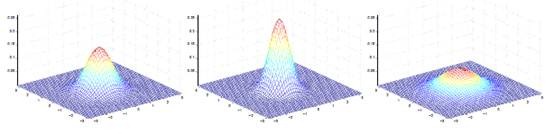
其中 决定中心位置, 决定投影椭圆的朝向和大小。
如下图:
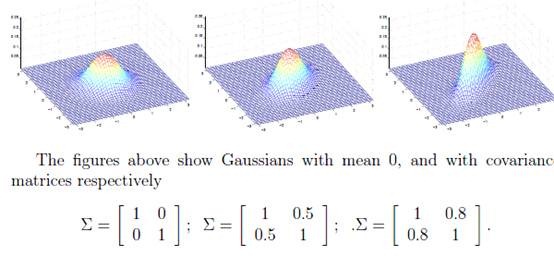
对应的 都不同。
模型描述
将 维高斯模型应用到监督学习中,假设输入数据为 ,输出类别为 ,那么对应的二分类问题描述为:
其中, 表示伯努利分布,其表达式为:
这里的 表示 这个事件发生的概率.
这就是经典的高斯判别分析模型。
伯努利分布: https://baike.baidu.com/item/%E4%BC%AF%E5%8A%AA%E5%88%A9%E5%88%86%E5%B8%83/7167021?fr=aladdin
类别 服从伯努利分布;当 时, 服从均值为 ,协方差矩阵为 的多元高斯分布.
这里假设 和 时 服从的多元高斯分布的协方差相同;
事实上这两者不一样模型会更精确,不过为了简化我们这里假设一样;另外如果样本量比较少,不同的 会使算法不稳定,因为过少的样本甚至导致协方差矩阵不可逆.
于是上面的表达式更直观的表述为:
通过贝叶斯公式求出一个样本分别属于两类的概率,进而可实现对该样本的分类:
用高斯判别分析做分类,其实就是为了学习这其中的几个参数 ,下面我们先直接给出学习公式,在下一节中我们会详细的推导出这些学习公式.
可以直观的求解:每个数据的类别已经知道,并且每一组别的数据分布都是高斯分布,我们可以直接用高斯分布的参数估计来求解这几个未知参数
我们知道高斯分布的均值的估计就是数据的均值,那么
其中,, 为给定的条件或者是集合.
如果两个高斯分布用同一个 ,则:
否则,分布求取每个类别的方差即可。
还有一个参数 ,直接统计点的个数可得到:
这就是 GDA 的思路和实现方式,通过上面的几个参数的计算公式就可以得到高斯判别分析模型;当有新的样本点进来是,就可以通过 计算出相应的概率,然后取最大的那个所对应的类别即可。
算法推导
使用最大似然估计应用到目标函数上,对未知量 进行估计。
其对数似然函数为:
其中上述第二行式子到第三行,只是将 展开了而已,因为 ,所以 可按 的值分开来考虑;
注意此函数第一部分只和 有关,第二部分只和 有关,第三部分只和 有关。
最大化该函数,首先对 求偏导,令其等于零:
其中第四行到第五行的式子,同样是按照 和 展开分别考虑,而又因为 ,所以从第五行式子得到了第六行式子.
令上式偏导为零,可求解出 :
同样的,对 求偏导为:
其中第一行到第二行,是应用了 服从多元高斯分布;第二行到第三行是简单的对数运算;第三行到第四行是对 求偏导,这里 ,这有点类似于与一元高斯分布时, .
令其等于零,可解得:
根据对称性,可直接得出:
下面对 求偏导数,由于似然函数只有前面两部分与 有关,则将前面两部分改写如下:
这其中也只是一些简单的对数运算,看懂难度不大。
于是我们整理出与 有关的项,然后对 求偏导,并令其等于零:
这其中用到了:
这里的矩阵对矩阵求导,只要会用就行了,不用深究,或者读者可以自己查阅相关的数学资料.
令其为零,求得:
可以看到上面推出来的各个参数的式子与上一节中给出的一致。
与逻辑回归的关系
根据上面的结果以及贝叶斯公式,可有:
而:
那么令:
于是有:
这就是逻辑回归的形式了。
在推导逻辑回归的时候,我们并没有假设类内样本是服从高斯分布的,因而GDA只是逻辑回归的一个特例,其建立在更强的假设条。故两者效果比较:
逻辑回归是基于弱假设推导的,则其效果更稳定,适用范围更广
数据服从高斯分布时,GDA效果更好
当训练样本数很大时,根据中心极限定理,数据将无限逼近于高斯分布,则此时GDA的表现效果会非常好
R 代码示例
R版本的高斯判别分析笔者没找到对应的包,所以自己根据上面的参数估计公式写了一个:
# 构造数据 xdata = c(0.230000, 0.394000,0.238000, 0.524000,0.422000, 0.494000,0.364000, 0.556000,0.320000, 0.448000,0.532000, 0.606000,0.358000, 0.660000,0.144000, 0.442000,0.124000, 0.674000,0.520000, 0.692000,0.410000, 0.086000,0.344000, 0.154000,0.490000, 0.228000,0.622000, 0.366000,0.390000, 0.270000,0.514000, 0.142000,0.616000, 0.180000,0.576000, 0.082000,0.628000, 0.286000,0.780000, 0.282000)x = matrix(data,ncol = 2,byrow = T)dim(x)head(x)# 表示一个样本有两个特征x1 = x[,1]x2 = x[,2]# 对应的类别 y,这里设置为两类y = matrix(rep(c(0,1),each = 10))dim(x)# 参数估计sum0 = sum(1 - y)sum1 = sum(y)phi = sum1/(sum0 + sum1) # 估计出类别y 的伯努利分布参数phi# 类别0 的期望均值,类别1 的期望均值mu0 = c( t(1 - y) %*% x1/sum0 , t(1 - y) %*% x2/sum0 )mu1 = c( t(y) %*% x1/sum1, t(y) %*% x2/sum1 )#协方差sigma = cov(x1,x2)# 根据 p(y)*p(x|y) 来进行判别evalutor_p <- function(x){n = length(x)py0 = phi^0 * (1 - phi)^(1 - 0)py1 = phi^1 * (1 - phi)^(1 - 1)px0 = 1/((2*pi)^(n/2) * sigma^(1/2)) * exp(-1/2 * sigma * t(matrix(x - mu0)) %*% matrix(x-mu0))px1 = 1/((2*pi)^(n/2) * sigma^(1/2)) * exp(-1/2 * sigma * t(matrix(x - mu1)) %*% matrix(x-mu1))# 比较分别属于不同类别的概率,取最大的ifelse(py0*px0 > py1*px1,0,1)}#测试testx <- c(0.780000, 0.282000)evalutor_p(testx)
测试的输出结果为类别 1 ,预测正确.
小结
高斯判别法也是一种线性分类器,到这里就讲完了,希望对读者有帮助。
