@evilking
2018-05-15T14:44:15.000000Z
字数 7810
阅读 2145
大数据平台篇
Hadoop搭建
我们以搭建伪分布式为例来展示Hadoop集群的搭建过程.
JDK安装
下载jdk1.7地址:
将下载好的.tar.gz文件通过SecureFX传到虚拟机上,假设是放在 /home/evilking/Documents/ 目录下,然后解压配置环境变量
在安装jdk1.7之前,如果虚拟机安装时自带的安装了一些OpenJDK,则需要将之前的jdk全部卸载掉
#查看系统默认安装了哪些jdk
[evilking@master Documents]$ rpm -qa | grep java
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
tzdata-java-2016g-2.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
可以看到系统默认安装了openjdk1.7,openjdk-headless1.7,openjdk1.8,openjdk-headless1.8这四个版本,就需要把这四个版本的openjdk全部卸载掉.
#卸载四个版本的openjdk
[evilking@master Documents]$ sudo rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64 java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64 java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
[sudo] password for evilking:
#重新查看安装的jdk
[evilking@master Documents]$ rpm -qa | grep java
tzdata-java-2016g-2.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
[evilking@master Documents]$
到这里我们就将系统默认安装的所有openjdk全部卸载完成了,接下来就需要安装我们自己下载的jdk了
#解压jdk
[evilking@master Documents]$ tar -xvf jdk-7u80-linux-x64.tar.gz
#移动解压后的jdk文件夹到/opt/下
[evilking@master Documents]$ sudo mv jdk1.7.0_80 /opt/
[sudo] password for evilking:
#修改环境配置表,加入JAVA环境变量
[evilking@master Documents]$ sudo vim /etc/profile
#使修改生效
[evilking@master jdk1.7.0_80]$ source /etc/profile
#验证JAVA_HOME配置成功
[evilking@master jdk1.7.0_80]$ echo $JAVA_HOME
/opt/jdk1.7.0_80
#查看此时java版本信息
[evilking@master jdk1.7.0_80]$ java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
[evilking@master jdk1.7.0_80]$
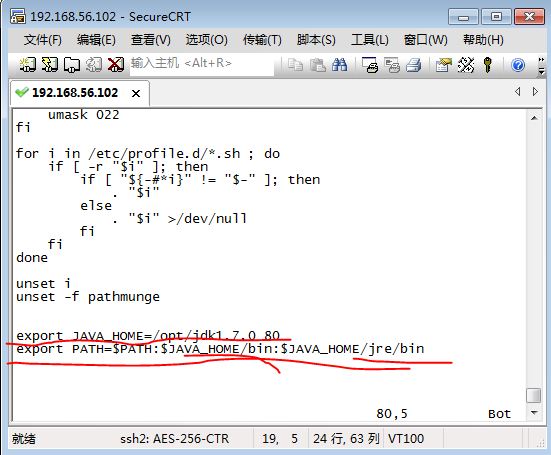
其中:
export JAVA_HOME=/opt/jdk1.7.0_80
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
到这里就说明jdk安装好了,环境变量也配置好了,接下来开始安装Hadoop伪分布式
搭建Hadoop伪分布式
下载Hadoop压缩包: http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
进入到这个页面中下载Hadoop 2.7.3版本,如果想下载其他版本,需进入 http://hadoop.apache.org/releases.html 页面
下载好hadoop压缩包后通过SecureFX传入虚拟机中,假设是放在 /home/evilking/Documents/ 目录下,然后解压配置环境变量
#解压hadoop压缩包
[evilking@master Documents]$ tar -xvf hadoop-2.7.3.tar.gz
#移动hadoop文件夹到/opt/下
[evilking@master Documents]$ sudo mv hadoop-2.7.3 /opt/
[sudo] password for evilking:
#配置Hadoop环境变量
[evilking@master hadoop-2.7.3]$ sudo vim /etc/profile
#让配置生效
[evilking@master hadoop-2.7.3]$ source /etc/profile
#查看hadoop的环境变量
[evilking@master hadoop-2.7.3]$ echo $HADOOP_HOME
/opt/hadoop-2.7.3
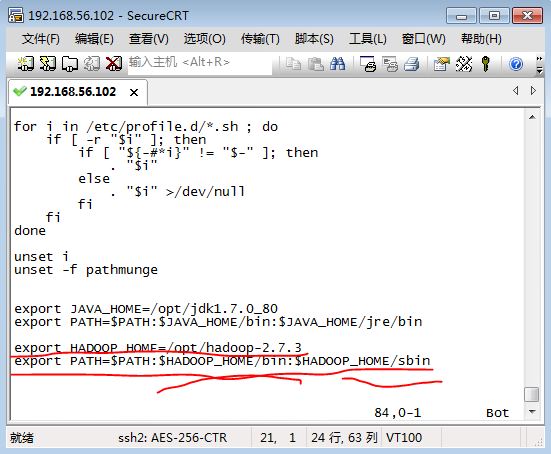
其中:
export HADOOP_HOME=/opt/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
到这里Hadoop的环境变量就配置好了,下面就开始配置Hadoop集群
配置Hadoop配置文件
需要先在 $HADOOP_HOME/ 目录下新建 tmp 目录和 dfs 目录,以及 dfs/name 目录和 dfs/data 目录
[evilking@master hadoop-2.7.3]$ mkdir tmp
[evilking@master hadoop-2.7.3]$ mkdir dfs
[evilking@master hadoop-2.7.3]$ mkdir dfs/name
[evilking@master hadoop-2.7.3]$ mkdir dfs/data
[evilking@master hadoop-2.7.3]$
其中tmp目录是用来放临时文件,dfs/name目录用来放namenode数据,dfs/data目录是用来放datanode数据
配置core-site.xml
该文件在 $HADOOP_HOME/etc/hadoop/ 目录下,切换路径到该目录下
[evilking@master hadoop]$ vim core-site.xml
由于 $HADOOP_HOME 文件夹的用户和用户组都为 evilking,所以 evilking 用户对该文件夹内的所有文件都有操作权限,所以这里用 vim 修改不需要加上 sudo
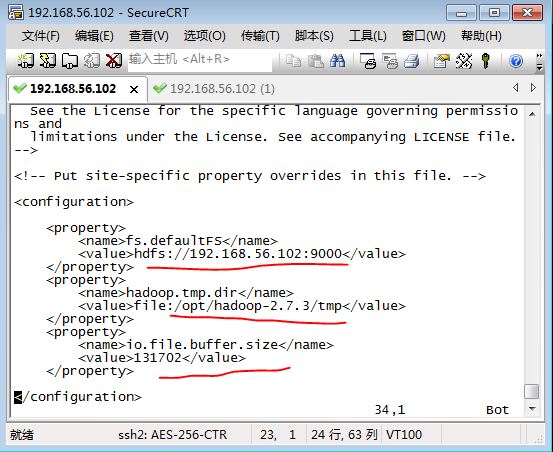
其中:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.102:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
配置hdfs-sit.xml
该文件在 $HADOOP_HOME/etc/hadoop/ 目录下,切换路径到该目录下
[evilking@master hadoop]$ vim hdfs-site.xml
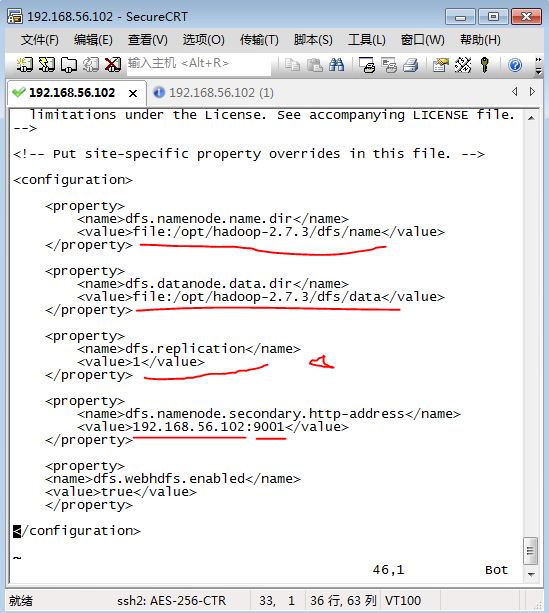
这里的dfs.replication配置很重要,这里配置为 1 是代表我们搭建的是伪分布式,只有1台机器
其中:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.56.102:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置mapred-site.xml
该文件在 $HADOOP_HOME/etc/hadoop/ 目录下,切换路径到该目录下,首先得复制一份mapred-site.xml.template成mapred-site.xml,然后再配置mapred-site.xml
[evilking@master hadoop]$ cp mapred-site.xml.template mapred-site.xml
[evilking@master hadoop]$ vim mapred-site.xml
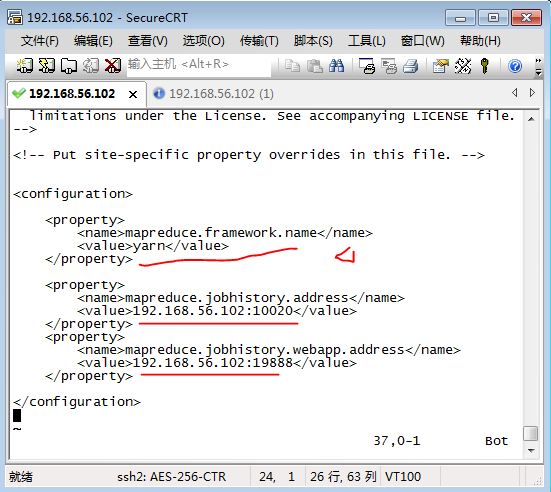
其中:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.56.102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.56.102:19888</value>
</property>
</configuration>
配置yarn-site.xml
该文件在 $HADOOP_HOME/etc/hadoop/ 目录下,切换路径到该目录下
[evilking@master hadoop]$ vim yarn-site.xml
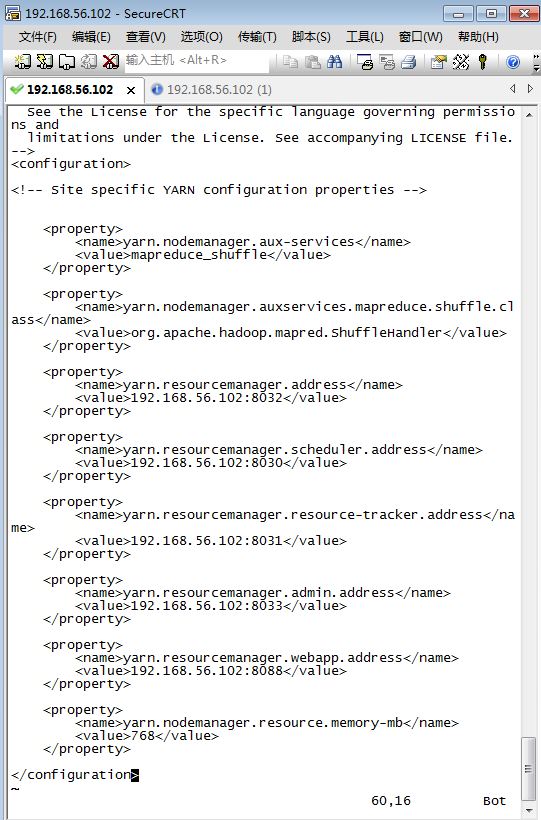
其中:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.56.102:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.56.102:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.56.102:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.56.102:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.56.102:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>768</value>
</property>
</configuration>
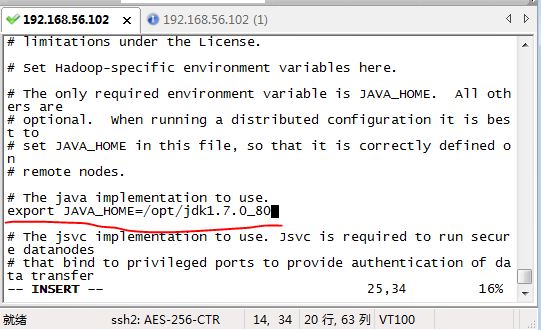
配置hadoop-env.sh中JAVA_HOME
修改hadoop-env.sh中的JAVA_HOME,如果不设置的话,hadoop启动不了
[evilking@master hadoop]$ vim hadoop-env.sh
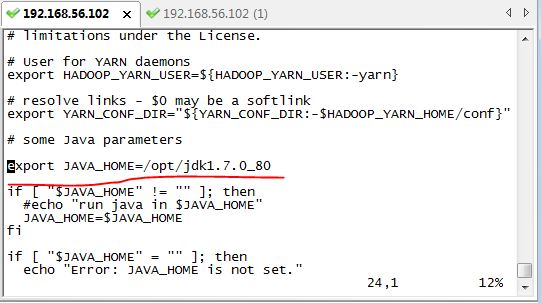
配置yarn-env.sh中的JAVA_HOME
修改yarn-env.sh中的JAVA_HOME,如果不设置的话,hadoop启动不了
[evilking@master hadoop]$ vim yarn-env.sh
格式化hadoop的namenode
目录切换到 $HADOOP_HOME 目录下,执行下面的命令
[evilking@master hadoop-2.7.3]$ bin/hdfs namenode -format
当出现下图所示标志,就说明格式化成功了:
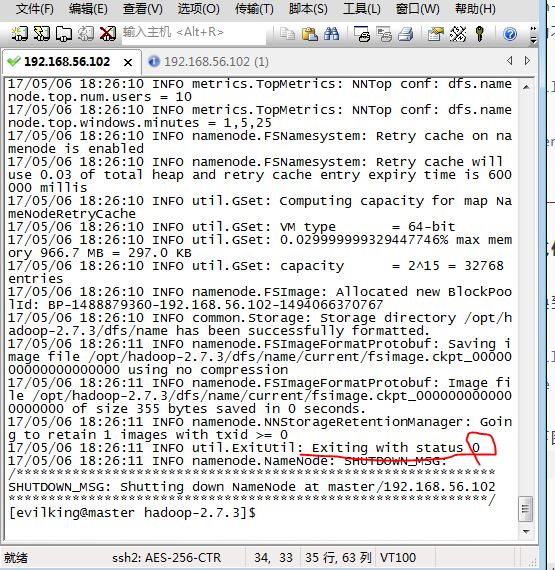
格式化成功后再格式化,会导致 namenode 的 id 不一致,所以不要重复格式化 namenode
启动hadoop
start-all.sh脚本是在 $HADOOP_HOME/sbin 目录下,但是我们前面已经将 $HADOOP_HOME/sbin 目录加入到环境变量中去了,所以直接运行该脚本名称就可以启动hadoop了
#启动hadoop和yarn
[evilking@master hadoop-2.7.3]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-namenode-master.out
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is 4d:77:34:0b:d0:14:df:a8:cc:36:bb:65:4b:70:c6:8b.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: starting datanode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-datanode-master.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /opt/hadoop-2.7.3/logs/hadoop-evilking-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.3/logs/yarn-evilking-resourcemanager-master.out
localhost: starting nodemanager, logging to /opt/hadoop-2.7.3/logs/yarn-evilking-nodemanager-master.out
[evilking@master hadoop-2.7.3]$ jps
5695 NameNode
6632 Jps
6148 ResourceManager
5999 SecondaryNameNode
5833 DataNode
[evilking@master hadoop-2.7.3]$
最后运行 jps命令,可以查看当前运行的hadoop组件;这里可以看到NameNode,DataNode,ResourceManager,SecondaryNameNode都已经启动起来了,说明hadoop安装成功了
关闭hadoop
最后若想将hadoop停掉,只需要执行stop-all.sh即可:
#停掉hadoop
[evilking@master hadoop-2.7.3]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: no nodemanager to stop
no proxyserver to stop
#查看各组件的状态
[evilking@master hadoop-2.7.3]$ jps
7224 Jps
可以看到上面的输出信息,逐渐的在停掉hadoop的各个组件,最后用 jps 命令看可知,各组件已经停掉
小结
到这里我们就将整个伪分布式Hadoop集群搭建好了,伪分布式和分布式的区别对于数据分析师来说不是很重要,因为我们的重点是在数据处理上,而不是大数据平台的运维上,所以搭伪分布式就足够用了
