@evilking
2018-04-30T16:36:15.000000Z
字数 12840
阅读 3379
NLP
结巴分词
本篇我们以 java 版本的结巴分词工具为例,详细分析该工具的分词细节;最后同样演示下 R 版本的jiebaR分词工具的用法和词云的绘制.
中文分词问题
什么是中文分词
在文本挖掘,情感分析,上下文语义分析等应用场合需要对纯文本进行分析,主要是对语句进行分析;像英文这种语句本身词与词之间有空格隔开,这种语句就容易分割,但是像中文或日文这种词与词之间没有分割界限的语言,在分割单词上就存在很大的困难;
像中文单词分割的时候如果分割的不准确,就很容易得出歧义的语句,甚至是意思完全相反的,比如”不同意”分割成”不”/”同意”。
中文分词常用的方法
基于字符匹配的方式
这种方式虽然准确,但是覆盖不全,需要大量的规则,对于新词就无能为力了.基于统计分析的方式
这种方式目前来说比较普遍,大部分是与字符匹配的方式相结合,字符匹配用来做精确匹配,而统计方法用来做新词发现.基于机器学习的方式
这种方式目前刚发展,就目前来说也是取得了很不错的效果.
基于字符匹配的分词
这类分词方法主要是词典匹配,用于切分出已登录词,如果只使用词典的话,就对未登录词无能为力了;后来人们就在此基础上加入统计方法,比如 HMM 模型,用来识别出未登录词;最后用动态规划求分词序列的最大概率,即最有可能的分词组合。
本篇要讲的结巴分词就属于这类。
基于字符标注的统计分析分词
例如,”小明硕士毕业于中国科学院计算所”,最正确的分词应该分成”小明 / 硕士 / 毕业 / 于 / 中国 / 科学院 / 计算所”,这是人工分词的结果,但是对于计算机来说,可能会把”计算所”分成”计算 / 所”。
为了使用字符标注的方式来分词,我们定义了四种标签:
- ”B” 表示一个单词的第一个字符
- “E” 表示一个单词的最后一个字符
- “M” 表示一个单词的中间的字符
- “S” 表示一个孤立的字符构成的一个单词
于是上面的例句最正确的标注应该为 BEBEBESBEBMEBME,有了这样的字符标注序列,我们就能够将语句分开,分割的结果为”BE / BE / BE / S / BE / BME / BME”,所以我们的问题就变成了 已知观测语句、字符标注标签,要求用字符标注标签对观测语句标注后的序列。如果了解隐马尔科夫过程的话,就能知道这是一个典型的HMM模型解码的问题。
基于字符标注的统计分析分词方法,像 HMM 模型、CRF 模型 等都是属于这类。
HMM 模型在《HMM 模型》这篇中详细讲了;CRF 模型分词其本质上是将分词问题转换为标注问题,其训练和标注都在 《CRF 条件随机场》一篇中详细讲了。读者可以参考学习。
基于机器学习的分词
机器学习做分词,原理与统计分析方法类似,都是将分词问题转换成分类问题,比如把“小明是中国共产党的接班人”这句的每个汉字进行分类,分为“B”、“M”、“E”、“S”这四类,然后根据分类的结果序列进行切分。
JAVA版本结巴分词详解
工具下载
github下载地址: https://github.com/huaban/jieba-analysis
下载好后导入 eclipse,则maven工程目录结构如下图所示:
编写测试用例类 SegmenterTest,对句子进行分词,测试代码如下:
@Testpublic void test() {//初始化jieba分词工具类JiebaSegmenter jieba = new JiebaSegmenter();String content = "这里讲解的是java版本的结巴分词工具";/*** 对句子进行分词,* 源码中有个方法是对整篇文章进行分词,其原理是先对文章进行分句,然后对每一句进行分词,* 所以这里我们只考虑对一句话进行分词的过程*/List<String> words = jieba.sentenceProcess(content);for(String word: words){System.out.print(word + " ");}}
运行后输出结果为:
main dict load finished, time elapsed 1557 msmodel load finished, time elapsed 47 ms.这里 讲解 的 是 java 版本 的 结巴 分词 工具
可以看出分词效果还是不错的,下面我们以这句话的分词来分析结巴分词的分词过程.
结巴分词时序图
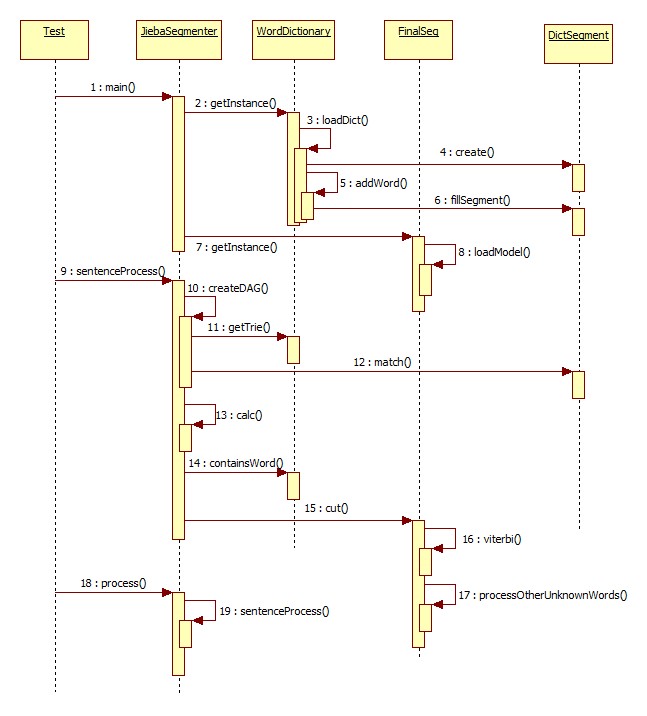
从时序图中可知,在初始化 JiebaSegment类时,会去先初始化词典表,即WordDictionary类;然后开始分句,分句又分为三步,如下:
构建 DAG图
通过动态规划求解最可能的分词结果
利用上一步求的的分词结果,对比词典,再利用viterbi算法做新词发现
初始化词典表
在JiebaSegmenter类的初始化过程中,会初始化两个词典表,WordDictionary和FinalSeg:
private static WordDictionary wordDict = WordDictionary.getInstance();private static FinalSeg finalSeg = FinalSeg.getInstance();
首先看看WordDictionary的初始化,这里使用了双重检查锁定的单例模式(保证在多线程环境下也只会初始化一次),在构造方法中执行 loadDict()方法去加载词典:
_dict = new DictSegment((char) 0);InputStream is = this.getClass().getResourceAsStream(MAIN_DICT);......BufferedReader br = new BufferedReader(new InputStreamReader(is, Charset.forName("UTF-8")));long s = System.currentTimeMillis();while (br.ready()) {//读取词典文件中的一行String line = br.readLine();String[] tokens = line.split("[\t ]+");//跳过空行if (tokens.length < 2)continue;String word = tokens[0];//计算词数double freq = Double.valueOf(tokens[1]);total += freq;word = addWord(word);freqs.put(word, freq);}// normalizefor (Entry<String, Double> entry : freqs.entrySet()) {//将单词的词数转换为词频entry.setValue((Math.log(entry.getValue() / total)));minFreq = Math.min(entry.getValue(), minFreq);}......
其中 addWord(String word)方法如下:
private String addWord(String word) {if (null != word && !"".equals(word.trim())) {//将单词转行小写String key = word.trim().toLowerCase(Locale.getDefault());//将单词添加到词典_dict.fillSegment(key.toCharArray());return key;}elsereturn null;}
上面loadDict()方法是加载工具基础词典,如果是用户自定义词典,需要使用loadUserDict()方法,与上面的加载方法不同的是,如果用户没有设置单词的统计词数,则默认设置为 3 :
String line = br.readLine();String[] tokens = line.split("[\t ]+");if (tokens.length < 1) {// Ignore empty linecontinue;}String word = tokens[0];//默认词数为 3double freq = 3.0d;if (tokens.length == 2)freq = Double.valueOf(tokens[1]);word = addWord(word);freqs.put(word, Math.log(freq / total));
从代码可以看出,加载词典,无非就是读取词典表,用分隔符截取每一行,获得对应的单词,以及单词的统计词数,如果没有设置统计词数,默认为 3;同时在单词添加到_dict词典数据结构中时,都统一转换成了小写.
然后看 FinalSeg 类的初始化,该类初始化也是使用了双重检查锁定来处理多线程环境下的单例,初始化时会调用loadModel()方法来加载 HMM模型,即HMM模型的五个组成元素 :
private static char[] states = new char[] { 'B', 'M', 'E', 'S' };
由于是中文分词,所以隐状态定义为 B,M,E,S;
prevStatus = new HashMap<Character, char[]>();prevStatus.put('B', new char[] { 'E', 'S' });prevStatus.put('M', new char[] { 'M', 'B' });prevStatus.put('S', new char[] { 'S', 'E' });prevStatus.put('E', new char[] { 'B', 'M' });trans = new HashMap<Character, Map<Character, Double>>();Map<Character, Double> transB = new HashMap<Character, Double>();transB.put('E', -0.510825623765990);transB.put('M', -0.916290731874155);trans.put('B', transB);Map<Character, Double> transE = new HashMap<Character, Double>();transE.put('B', -0.5897149736854513);transE.put('S', -0.8085250474669937);trans.put('E', transE);Map<Character, Double> transM = new HashMap<Character, Double>();transM.put('E', -0.33344856811948514);transM.put('M', -1.2603623820268226);trans.put('M', transM);Map<Character, Double> transS = new HashMap<Character, Double>();transS.put('B', -0.7211965654669841);transS.put('S', -0.6658631448798212);trans.put('S', transS);
然后定义状态转移概率矩阵,这里定义的概率都是经过对数转换的,以方便计算时将乘法操作改为加法操作,下同;
start = new HashMap<Character, Double>();start.put('B', -0.26268660809250016);start.put('E', -3.14e+100);start.put('M', -3.14e+100);start.put('S', -1.4652633398537678);
这里是定义了初始状态概率;
下面给出结巴分词工具的发射矩阵资源文件格式:
M耀 -8.47651676173蘄 -14.3722960587涉 -10.5600933886B耀 -10.4602834131蘄 -11.0155137948涉 -8.76640550684M耀 -8.47651676173蘄 -14.3722960587涉 -10.5600933886E耀 -9.2667057128蘄 -17.3344819086涉 -9.09647365936
举个例子,隐状态为'M'时对应的汉字为'耀'的概率的对数为 -8.47651676173,即为发射概率,其中表中所有的汉字被定义为观察值
InputStream is = this.getClass().getResourceAsStream(PROB_EMIT);BufferedReader br = new BufferedReader(new InputStreamReader(is, Charset.forName("UTF-8")));emit = new HashMap<Character, Map<Character, Double>>();Map<Character, Double> values = null;while (br.ready()) {String line = br.readLine();String[] tokens = line.split("\t");if (tokens.length == 1) {//读取为标号,B M S Evalues = new HashMap<Character, Double>();//设置发射概率矩阵emit.put(tokens[0].charAt(0), values);}else {//添加值values.put(tokens[0].charAt(0), Double.valueOf(tokens[1]));}}
如此,发射概率矩阵就加载完成了,到这里整个 HMM模型的几个要素就都加载完成了,剩下的就是具体分词时的解码问题了.
构建DAG图
分词的第一步是构建词的DAG图,例如上面测试用例中的句子,DAG图如下所示:
0 [0, 1] //这1 [1] //里2 [2, 3] //讲3 [3] //解4 [4] //的5 [5] //是6 [6] //j7 [7] //a8 [8] //v9 [9] //a10 [10, 11] //版11 [11] //本12 [12] //的13 [13, 14] //结14 [14] //巴15 [15, 16] //分16 [16] //词17 [17, 18] //工18 [18] //具
具体是如何算的呢,我们分析createDAG()方法:
private Map<Integer, List<Integer>> createDAG(String sentence) {Map<Integer, List<Integer>> dag = new HashMap<Integer, List<Integer>>();//获得词典树DictSegment trie = wordDict.getTrie();char[] chars = sentence.toCharArray();int N = chars.length;int i = 0, j = 0;while (i < N) {//核心的就是下面这几句,不断的增加字扩展词,去词典中查找//如果是一个词的前缀,则可以继续往后扩展词//如果匹配到了一个词,则将索引添加到DAG图中Hit hit = trie.match(chars, i, j - i + 1);if (hit.isPrefix() || hit.isMatch()) {if (hit.isMatch()) {if (!dag.containsKey(i)) {List<Integer> value = new ArrayList<Integer>();dag.put(i, value);value.add(j);}elsedag.get(i).add(j);}j += 1;if (j >= N) {i += 1;j = i;}}else {i += 1;j = i;}}//最后将没有与其他字构成词的字加上for (i = 0; i < N; ++i) {if (!dag.containsKey(i)) {List<Integer> value = new ArrayList<Integer>();value.add(i);dag.put(i, value);}}return dag;}
举例说明,假设当前词为'版',去词典里查,发现'版'字是某个单词的前缀词;则往后添加下个字,构成词'版本',然后去词典里查,发现能匹配上'版本',于是就将'本'字的索引添加到'版'所对应的索引列表中;然后继续往后添加一个字,构成'版本的',这时查询词典,发现该词既不是前缀词,也无法匹配到单词,则最开始的索引往后移一位,当前词就变成了'本',然后从'本'开始继续往下搜索,直到结束.
动态规划求解最可能的分词序列
构建完DAG图后,我们要分词,就要判断具体如何划分才最好,这里我们使用了动态规划,使整句划分的概率最大.
private Map<Integer, Pair<Integer>> calc(String sentence, Map<Integer, List<Integer>> dag) {int N = sentence.length();HashMap<Integer, Pair<Integer>> route = new HashMap<Integer, Pair<Integer>>();//动态规划从后往前,初始化最后一步的概率route.put(N, new Pair<Integer>(0, 0.0));for (int i = N - 1; i > -1; i--) {Pair<Integer> candidate = null;for (Integer x : dag.get(i)) {//从后往前组合,获得词的频率double freq = wordDict.getFreq(sentence.substring(i, x + 1)) + route.get(x + 1).freq;if (null == candidate) {candidate = new Pair<Integer>(x, freq);}else if (candidate.freq < freq) {//取累计频率最大的划分candidate.freq = freq;candidate.key = x;}}route.put(i, candidate);}return route;}
动态规划是从最后一个字符开始往前逐个累加,取局部累计词频最大的分词结果,最终取使整句分词结果的累计词频达到最大.
新词发现
经过上一步动态规划求最可能的分词结果,有了一个粗略的分词,需要在此基础上进一步的去准确分词,包括新词发现 :
while (x < N) {y = route.get(x).key + 1;String lWord = sentence.substring(x, y);if (y - x == 1)sb.append(lWord);else {if (sb.length() > 0) {buf = sb.toString();sb = new StringBuilder();//一个字的可以直接添加if (buf.length() == 1) {tokens.add(buf);}else {//多个字的先去词典中查询//如果是已登录词就直接添加if (wordDict.containsWord(buf)) {tokens.add(buf);} else {//未登录词就用Viterbi算法解码finalSeg.cut(buf, tokens);}}}tokens.add(lWord);}x = y;}
下面就是HMM模型中 Viterbi算法解码过程 :
public void viterbi(String sentence, List<String> tokens) {Vector<Map<Character, Double>> v = new Vector<Map<Character, Double>>();Map<Character, Node> path = new HashMap<Character, Node>();//处理第一个隐状态v.add(new HashMap<Character, Double>());for (char state : states) {Double emP = emit.get(state).get(sentence.charAt(0));if (null == emP)emP = MIN_FLOAT;v.get(0).put(state, start.get(state) + emP);path.put(state, new Node(state, null));}for (int i = 1; i < sentence.length(); ++i) {Map<Character, Double> vv = new HashMap<Character, Double>();v.add(vv);Map<Character, Node> newPath = new HashMap<Character, Node>();for (char y : states) {Double emp = emit.get(y).get(sentence.charAt(i));if (emp == null)emp = MIN_FLOAT;Pair<Character> candidate = null;for (char y0 : prevStatus.get(y)) {//从状态y0 转移到状态 yDouble tranp = trans.get(y0).get(y);if (null == tranp)tranp = MIN_FLOAT;//y0状态的前向变量 + y0转移到y状态的转移概率 + y状态下是字i的发射概率tranp += (emp + v.get(i - 1).get(y0));if (null == candidate)candidate = new Pair<Character>(y0, tranp);else if (candidate.freq <= tranp) {candidate.freq = tranp;candidate.key = y0;}}vv.put(y, candidate.freq);newPath.put(y, new Node(y, path.get(candidate.key)));}path = newPath;}//因为'B'、'M'不可能构成最后一个字,所以只需要比较'E'、'S'就行double probE = v.get(sentence.length() - 1).get('E');double probS = v.get(sentence.length() - 1).get('S');Vector<Character> posList = new Vector<Character>(sentence.length());Node win;if (probE < probS)win = path.get('S');elsewin = path.get('E');while (win != null) {posList.add(win.value);win = win.parent;}Collections.reverse(posList);//路径回溯,得到最优的隐状态序列int begin = 0, next = 0;for (int i = 0; i < sentence.length(); ++i) {char pos = posList.get(i);if (pos == 'B')begin = i;else if (pos == 'E') {tokens.add(sentence.substring(begin, i + 1));next = i + 1;}else if (pos == 'S') {tokens.add(sentence.substring(i, i + 1));next = i + 1;}}if (next < sentence.length())tokens.add(sentence.substring(next));}
以上就是 HMM模型中 Viterbi解码过程,具体原理可参考上篇 《基于HMM的中文分词》.
到这里,java版本的结巴分词工具对每一句的分词过程就清楚了;这个工具结合词典和概率,并使用HMM模型做新词发现,总体分词结果来看,效果还可以.
R 版本的结巴分词
由于笔者没有找到 R版本的结巴分词工具包"jiebaR"的源码,所以上面使用java版本的源码来分析处理流程,下面我们使用"jiebaR"包来做简单的分词,以及用"wordcloud"包做词云分析,以演示 R 版本的结巴分词工具的使用.
作为演示用的文本如下所示,保存在data.txt文件中,并放在Rstudio的工作目录下,工作目录可通过getwd()命令获得:
笔者在实际项目中使用的是 java 版本的结巴分词,它是词典+HMM模型的分词工具,源码中对 HMM的Viterbi算法演示的很清楚,不过这里为了与整体风格相统一,我们使用 R语言的相关HMM包来演示;后面我们单独用一个篇幅去讲解结巴分词,因为结巴分词工具总体上来说算是一个效果不错,而且原理简单的工具.
下面我们先导入必要的两个包,并读取文本:
install.packages("jiebaR")library(jiebaR)install.packages("wordcloud")library(wordcloud)f <- scan("data.txt",sep = "\n",what = '',encoding = "UTF-8")head(f)
输出信息为:
> f <- scan("data.txt",sep = "\n",what = '',encoding = "UTF-8")Read 2 items> head(f)[1] "笔者在实际项目中使用的是 java 版本的结巴分词,它是词典+HMM模型的分词工具,源码中对 HMM的Viterbi算法演示的很清楚,不过这里为了与整体风格相统一,我们使用 R语言的相关HMM包来演示;\n"[2] "后面我们单独用一个篇幅去讲解结巴分词,因为结巴分词工具总体上来说算是一个效果不错,而且原理简单的工具.">
下面开始使用 jiebaR 去分词:
#使用 qseg函数分词> seg <- qseg[f]#去掉单词为一个字的词> seg <- seg[nchar(seg) > 1]> head(seg)[1] "笔者" "实际" "项目" "使用" "java" "版本">
#统计词频> seg <- table(seg)> segsegHMM java Viterbi 版本 包来 笔者 不错 不过3 1 1 1 1 1 1 1词典 单独 而且 分词 风格 工具 后面 简单1 1 1 4 1 3 1 1讲解 结巴 来说 模型 篇幅 清楚 实际 使用1 3 1 1 1 1 1 2算法 算是 统一 为了 我们 相关 项目 效果1 1 1 1 2 1 1 1演示 一个 因为 语言 原理 源码 这里 整体2 2 1 1 1 1 1 1总体1># 对词频进行排序,并取前 30个词> seg <- sort(seg,decreasing = TRUE)[1:30]> segseg分词 HMM 工具 结巴 使用 我们 演示 一个4 3 3 3 2 2 2 2java Viterbi 版本 包来 笔者 不错 不过 词典1 1 1 1 1 1 1 1单独 而且 风格 后面 简单 讲解 来说 模型1 1 1 1 1 1 1 1篇幅 清楚 实际 算法 算是 统一1 1 1 1 1 1>
文本经过分词,过滤掉一些无效词(停用词等)后,再进行词频统计并排序,取前 k个词(一般就是保留的关键词了);下一步就是利用词云工具绘制词云了,以可视化的方式展现文本特征 :
#生成一张 .bmp图,宽高个 500像素> bmp("comment_cloud.bmp",width = 500,height = 500)#绘图,背景设为黑色> par(bg = "black")# 生成词云> wordcloud(names(seg),seg,colors = rainbow(100),random.order = F)# 关闭绘图设备> dev.off()null device1>
这样,在工作目录下就会生成一张.bmp图,如下所示:

从图上可以看出,主要词有分词、HMM、结巴、工具,其中分词占的比重最大,其次是 HMM。这个结果与最开始的文本语料对比可以看出,效果还是不错的,主要的关键词都体现出来了.
接下来再玩点深入一点的,jiebaR包可以实现分词(分行分词)、整个文档分词(分文档分词)。library(jiebaR)加载包时,没有启动任何分词引擎,启动引擎很简单,就是一句赋值语句就可以了mixseg=worker()
详细版本请参考官方:https://jiebar.qinwf.com/section-3.html#section-3.0.1
但是实际上worker中有非常多的调节参数。
mixseg = worker(type = "mix",dict = "dict/jieba.dict.utf8",hmm = "dict/hmm_model.utf8",user = "dict/user.dict.utf8",detect = T,symbol = F,lines = 1e+05,output = NULL)> mixsegWorker Type: Jieba SegmentDefault Method : mixDetect Encoding : TRUEDefault Encoding: UTF-8Keep Symbols : FALSEOutput Path :Write File : TRUEBy Lines : FALSEMax Word Length : 20Max Read Lines : 1e+05Fixed Model Components:$dict[1] "dict/jieba.dict.utf8"$user[1] "dict/user.dict.utf8"$hmm[1] "dict/hmm_model.utf8"$stop_wordNULL$user_weight[1] "max"$timestamp[1] 1506665756$default $detect $encoding $symbol $output $write $lines $bylines can be reset.>
说明一下:
type 代表分词模型,有mix(混合模型)、mp(最大概率)、hmm(隐马尔科夫链)、query(索引)、tag(词性标注)、simhash(距离)、keywords(关键词)
hmm 代表隐马尔科夫链所使用的语料库,一般不用更改
user 代表用户自定义词典,一般我们修改的就是这个文件
detect 决定了引擎是否自动判断输入文件的编码,加载后通过
cutter$detect = F也可以设置symbol 当输入为文档文件时,一次性最大读取行数
lines 当输入为文档文件时,一次性最大读取行数
output 代表分词内容是否变成文件写出
#设置分行输出> mixseg$bylines = TRUE> mixseg[c("这是第一行文本。","这是第二行文本.")][[1]][1] "这是" "第一行" "文本"[[2]][1] "这是" "第二行" "文本">
> words = "我爱北京天安门"# 创建词性标注的 worker> tagger = worker("tag")# 对句子words进行分词,并做词性标注> tagger <= wordsr v ns ns"我" "爱" "北京" "天安门">
# 构建一个提取关键词的 worker> keys = worker("keywords",topn = 4,idf = IDFPATH)> keys <= "我爱北京天安门"8.9954 4.6674"天安门" "北京">
这里创建了一个能提取关键词的worker,topn = 4表示提取 4 个关键词,idf = IDFPATH表示使用逆文档率;
下一句输出结果中,第一行的数值表示 IDF,第二行表示具体关键词.
#显示词典路径> show_dictpath()[1] "D:/evirnment/R-3.3.3/library/jiebaRD/dict">
如果读者想设置自己的词典、停用词典,可以通过
show_dictpath()显示词典路径,然后修改文件内容,并在构建 worker是指定相应文件路径.
小结
以上,就是对结巴分词工具的使用以及分析了,其中关于 HMM模型的原理部分,可以参考《基于HMM的中文分词》一篇.
如果因为这篇文章而让读者对结巴分词有了更深入的理解,那是笔者的荣幸.
