@evilking
2018-09-03T06:20:00.000000Z
字数 5091
阅读 4731
NLP实战
基于语言模型做文本自动纠错
本实验室希望通过训练英文职位名的 n-gram 语言模型,然后对拼写有错误的职位名进行自动纠错,最后实验准确率为 73% 左右,效果良好,结合人工检查后在实际生产过程中可以使用。
纠错场景
这里介绍几种文本纠错的应用场景,可以看出文本纠错的价值所在。
文本查询
做文本查询时,我们需要对用户输入的关键词进行关键词查找,但如果用户输入的关键词中某一个字有错误,就会导致搜索出的结果不是用户想要的。我们希望能有一种方法能对用户的拼写进行检查并纠错,这样即使用户输入的关键词有误,也能正确的返回给用户想要的信息。
语音识别纠错
对于歌曲的语音搜索实现方案中,使用百度语音进行用户语音识别,返回的字符串调用歌词搜索,而歌词搜索使用的是分词的方式建立索引,因此字符串识别的准确率直接影响最后返回歌曲的正确性。
而百度语音是基于非特定样本进行训练,其语言环境涵盖非常广,对于歌曲语言搜索这个业务来说,我们的语料库只是特定的歌词文本集,那么如何解决这个纠正语音识别结果的问题,便是需要讨论的问题
实验目标
下面介绍一下笔者使用文本纠错的目的:
在实际的生产中,我们的词典数据大多都是从网上爬取的,但由于不同的数据源质量不一致,就会有些拼写错误的单词混杂其中,而词典的使用是一个精确匹配的过程,我们就需要对其中错误的单词进行纠错。
当错误的数据量比较大时,人工去纠错是非常消耗成本的,能否用程序自动的去处理呢?
这就是本篇要讲的内容,其中涉及到使用 kenlm 训练 n-gram 语言模型,使用 spelling corrector 做文本纠错,后面会一点点介绍具体是如何操作的。
单词纠错
我们从简单的开始讲起,下面先介绍一下对单个单词是如何纠错的。
参考:https://blog.csdn.net/helihongzhizhuo/article/details/50498693
英文单词
我们通常是根据单词的词形本身去考虑,判断哪些词与这个错误的单词最可能相似,这是一个求相似度的问题。
比如错误单词 "he lo",可能是 "hello" 也可能是 "helot" ,不过这是我们还无法确定错误的单词具体是哪一个。
从我们我们日常使用的经验可以知道,可能是 “hello” 的可能性更大一点,这就需要结合上下文环境去进一步判断
上面说了这是一个求相似度的问题,具体来说主要分为两步:
检验单词是否拼写正确
我们事先准备大量正确的单词集,首先要判断查询词是否在词典中,如果在,则表示查询词为正确的单词,不需要纠错可直接返回;如果不在,就需要计算与查询词最相近的几个单词。可能的纠错词推荐
如果查询词确定不在词典中,则需要计算该查询词与词典中的所有词的相似度,返回相似度最高的几个词,供下一步进一步筛选。
这两步都好理解,其中计算单词的相似度有很多方法,比如说 Jaro-Winkler Distance 算法、 其中比较常用的方法就是 编辑距离。
比如说 "he lo" 与 "hello" 的编辑距离为 1,"he lo" 与 "helot" 的编辑距离为 2,假设我们纠错的规则是选编辑距离最小的那个单词,那纠错后的单词就为 "hello"。
关于相似度的介绍,可参考笔者之前的文章:http://www.51learn.info/?p=327
其中有个小细节,如果每次用查询词与词典中的所有词去计算相似度,这个计算量是非常大的。按照人们的经验来看,人在书写时前一两个字母一般不大容易写错,所以我们可以先假定前两个字母都是书写正确的,这样就在计算相似度时就可以过滤掉词典中的绝大部分单词,可以大大减少计算量。
中文单词
中文单词的纠错可能比英文单词稍微麻烦一点,因为汉字是世界上仅存的几门象形文字之一,它有自己的文字特点。
一般来说中文单词的拼写错误大致有这么几种类型:
字形相似
这种在手写字时特别容易出现,比如 “彬彬有礼“ 写成 ”杉杉有礼”。读音相似
手写字或者拼音输入法时容易出现,比如 "南通市" 写成 "难通市",前后的读音都是 "nan tong shi"。
因为汉语表达比较精炼,使用编辑距离去做纠错,效果就很不好,比如 "南通市 – 难通市 – 北通市",这三者的编辑距离都是 1,就不好判断了。但这时结合拼音去判断,就会发现 "南通市" 与 "难通市" 的相似度高于 "南通市" 与 "北通市" 了。
所以对于汉字的纠错,我们需要同时结合拼音和字形上的特点:
读音相似度
读音上相对来说好处理一点,我们可以将汉字转成对于的拼音,比如说 "南" 字转成 "nan2",其中 2 为声调部分,然后对拼音构成的字符串再用传统的相似度匹配算法,比如编辑距离,就可以达到很好的效果。也可以使用 Soundex 语音算法,在拼音文字中有时会有会念但不能拼出正确字的情形,可用Soundex做类似模糊匹配的效果。
不同这里有一点需要注意,由于不同地区有着各自截然不同的方言,所以在计算相似度时需要适当调整。
比如许多南方人很难分辨 "L" 和 "N',他们常常会将这两个音弄混,将“篮球”读作“南球”,而“刘德华”就变成了“牛德华”。
另外有汉字是多音字,在汉字转拼音时不好处理,因为要考虑所有可能的拼音组合,在极端情况下会导致指数爆炸!例如美团的实现(枚举多音字全排列)。所以我们一般就取该汉字拼音出现次数较多的那个读音
字形相似度
字形相似读计算是个特别难的问题,一种朴素的思想,便是首先将汉字转化成一组的字母数字的序列,而这个转化所用到的hash算法必须能够将该汉字的字形特征保留下来。利用这样的转化,我们便将汉字字形的相似度问题,变成了两组字母数字序列的相似度问题。而这正是传统相似度匹配算法的强项。这种解决方案的核心,就在于找到一个恰当的hash算法,能够将汉字进行适当的转化,并在转化结果中,保留住汉字的字形特征。
曾经有人发明了一种名为 四角编码 的汉字检字法来实现这样的算法。四角算法是由王云五于1925年发明,这种编码方式根据汉字所含的单笔或复笔对汉字进行编号,取汉字的左上角,右上角,左下角以及右下角四个角的笔形,将汉字转化成最多五位的阿拉伯数字。 通过将汉字转化成四角编码,再对四角编码的相似度进行计算,便可以得出两个汉字在字形上的相似程度。
这种编码可以在一定程度上解决形近词的问题,但也有其自身的问题,由于只取汉字的四角笔形,有些外形截然不同的汉字,因为四角结构相同,也拥有同样的四角编码。
比如:量 - 6010 ,日 - 6010 ,但它们是不一样的。
所以为了解决汉字相似度计算问题,我们可以结合汉字的拼音、声调、四角编码、笔画数、字形结构等来考虑。
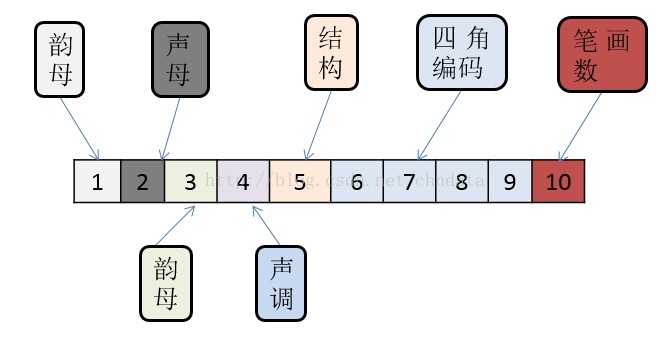
上面是一位网友设计的汉字编码图,具体可参考:https://blog.csdn.net/chndata/article/details/41114771
语言模型
上面介绍了单个单词的纠错,比如错误单词 "vender" ,它可能是 "vendor",也可能是 "render" 、"venter" 等等,它们的编辑距离都为 1,那要如何进一步确定到底哪个单词才是正确的单词呢?
这时就需要结合上下文语境来确定,需要用到语言模型了。
什么是语言模型
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?
那么如何计算一个句子的概率呢?
我们说当前单词的出现是与它前面所有单词有关的,假设给定句子(词语序列)
它的概率可以表示为:
其中:
表示词序 在语料库中出现的总次数.
可以看出这样的方法存在两个致命的缺陷:
- 參数空间过大:条件概率 的可能性太多,无法估算,不可能有用
- 数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0
为了解决參数空间过大的问题,于是我们引入马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的 n 个词有关。
如果一个词的出现与它周围的词是独立的,那么我们就称之为 unigram,一元语言模型:
如果一个词的出现仅依赖它前面出现的一个词,我们就称之为 bigram,二元语言模型:
如果一个词的出现仅依赖于它前面出现的两个词,我们就称之为 trigram,三元语言模型:
所以上述计算概率参数的公式也改为
一般来说,n-gram 模型就是假设当前词的出现概率只与它前面的 n-1 个词有关。而这些概率参数都是可以通过大规模语料库统计得来,比如三元概率有:
在实践中用的最多的就是 bigram 和 trigram 了,高于四元的用的非常少,由于训练它须要更庞大的语料,并且数据稀疏严重,时间复杂度高,精度却提高的不多。
举例说明
比如说我们的语料库有如下几条:
software developerandroid software developerjr. web developersoftware managerax software developerhr software developer
以 bigram 为例计算 software developer 的概率:
所以整个句子的概率为:
参考
http://media.people.com.cn/n1/2017/0112/c409703-29018801.html
https://blog.csdn.net/glanderlice/article/details/53005791
https://blog.csdn.net/jccg3030/article/details/54909290
