@evilking
2018-04-30T13:01:57.000000Z
字数 11781
阅读 2877
NLP
Paragraph_Vector
写在前面
第一次翻译经典论文,英文水平不行,一些地方直译不了就意译了。
原文链接: 《Distributed Representations of Sentences and Documents》
论文主要是讲 Word2Vec 和 Doc2Vec ,统称为 Paragraph Vector.
论文作者: Tomas Mikolov . Google 出品.
摘要
许多机器学习算法要求输入是一个固定长度的特征向量.当我们将这些算法应用到文本的时候,一种通用的构造特征向量的方法就是词袋模型,但是词袋模型构造的特性向量有两个主要的缺陷: 它们丢失了词序信息,也忽略的语义信息. 例如,“powerful”,“strong”,“Paris” 是同样的距离,但是它们的语义却不同.
在这篇文章中,我们提出 Paragraph Vector,它是一种无监督学习算法,从不同长度的文本片段比如句子、段落或文档中去学习固定长度的特征向量. 该算法可以生成一个稠密的向量来代表该文档,然后用该向量来预测文档中的单词.
该算法是为了能解决词袋模型的缺陷。实验证明,Paragraph Vectors 的效果做得比词袋模型和其他的文本表现技术要好.
最后,我们在几个文本分类和情感分析人物中取得了最优秀的效果.
介绍
文本分类和聚类在许多应用扮演了一个重要的角色,比如文档检索、web 查询、垃圾过滤等等. 这些应用程序的核心就是机器学习算法,例如逻辑回归或者 K 均值聚类. 这些算法是典型的要求输入文本被转换成一个固定长度的特征向量. 可能大多数常用的特征向量表征文本的算法是词袋模型或者是 n-grams 模型(Harris, 1954),因为它们简单、有效,并且经常有令人惊喜的精确度.
然而,词袋模型 (BOW) 有许多的缺点. 词序信息丢失了,这导致不同的两条句子,只要它们使用的单词一样,就能提取出一样的表现特征. 尽管 N-grams 模型在较短的上下文环境下考虑到了词序的信息,但是它却受数据稀疏和维度灾难之苦. 词袋模型和 N-grams 模型在考察单词的语义、两个单词之间的语义距离上就没什么作用了. 比如说 “powerful”、“strong” 和 “Paris” 三者之间的距离是相等的,尽管从实际的语义角度看,“powerful” 相比于 “Paris” 应该更加接近 “strong” .
在这篇文章中,我们提出 Paragraph Vector,它是一种无监督学习框架,训练处连续分布的特征向量来表示文本片段. 其中文本可以是可变长度的,Paragraph Vector 这个名字是为了强调这个方法可以应用到任何文本片段中,短语、句子、段落甚至是整个长文档.
在我们的模型中,训练特征向量是为了用于预测 paragraph 中的单词,进一步来说就是,在一个 paragraph中我们使用连续的几个词的词向量作为上下文,来预测下一个词. 词向量和 paragraph向量使用随机梯度下降和误差反传来训练.(Rumelhart et al., 1986). 然而 paragraph向量在众多的文档中是唯一的,而词向量是共享的. 在预测时,paragraph向量被修正的词向量和训练直到收敛的 paragraph向量给推测出来.
文中的
paragraph上面也说了,可以泛指任意长度的文本,所以翻译成“段落”好像也不太合适.paragraph向量有别于词向量,是一条句子或一篇文档的特征向量表示,理解这个意思就好.
最近工作中学习使用神经网络去训练词的向量表示,我们的这种方法也是从中受到启发(Bengio et al., 2006; Collobert & Weston, 2008; Mnih & Hinton, 2008; Turian et al.,2010; Mikolov et al., 2013a;c). 在它们的构想中,每个词都被一个向量表示,这个向量是由它上下文中的其他词的词向量通过串联或者求平均得出来的,然后用于预测上下文中的其他词. 例如,神经网络语言模型是在 (Bengio et al. 2006) 中被提出,它使用前几个单词的词向量通过串联这些词向量或者求它们的平均值来构造神经网络的输入向量,然后试着去预测下一个单词. 模型训练完后生成的词向量,是将单词映射到了向量空间中,在这个空间中语义上相似的词它们的表征向量之间的距离也相似 (e.g.,“strong” 与 “powerful” 距离更近).
紧跟着这项成功的方法,研究者们已经将这种单词级别的模型扩展到了短语级别、句子级别 (Mitchell & Lapata, 2010; Zanzotto et al., 2010; Yessenalina & Cardie, 2011; Grefenstette et al., 2013; Mikolov et al., 2013c). 举个例子,一种比较简单的方法就是将文档中的所有单词的词向量通过加权平均后得到该文档的文档向量. 一种更复杂的方法是通过矩阵运算,按照句子的语法解析树的顺序将句子中的各个单词的词向量组合起来 (Socker et al., 2011b). 这两种方法都有一些缺陷,第一种方法通过词向量的加权平均,与标准的词袋模型一样会丢失词序信息. 第二种方法通过语法解析树将词向量组合起来,由于用到句子的解析树,所以这种方法也只能应用到句子上.
Paragraph Vector 有能力将可变长度的句子转换成向量. 不像前面描述的一些方法,它是通用的、能应用到任何长度的文本上: 句子、锻炼和文本. 它也不要求比如句子语法解析树这种特定的权值函数来辅助. 在接下来的篇幅中,我们将在几个基准的数据集上实验,证明 Parapraph Vector 的优秀. 举个例子,在情感分析任务上,我们比复杂的方法取得了更好的效果,在错误率方面的相对改进超过了16%. 在文本分类任务上,我们的方法也比词袋模型更好,分类精度相对提升了差不多 30% .
算法
我们先讨论词向量的训练方法,因为该方法是本方法的灵感来源.
训练词向量
这部分介绍词向量分布的一些概念. 图 1 很好的展示了词向量的学习框架. 它的任务是给定该词上下文中的其他词来预测该词.
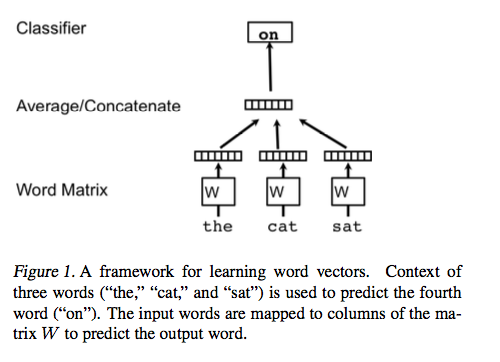
在这个框架中,每个词被映射到一个唯一的向量上,用矩阵 中的一列来表示. 列的索引表示该单词在词典表中的位置. 串联或者求这些词向量的平均作为特征去预测这个句子中的下一个单词.
更正式的描述为,给定一系列训练预料,,观测词向量模型是去最大化对数似然概率:
这个预测任务通过一个多分类方法求解,比如 softmax. 于是我们有
其中, 是 softmax 的参数. 通过从 中提取词向量并经过串联或者求平均后的向量来构造.
在实际应用中,hierarchical softmax (Morin & Bengio, 2005; Mnih & Hinton, 2008; Mikolov et al., 2013c) 用于快速训练 softmax . 在我们的工作中,hierarical softmax 的结构被设计成一颗哈夫曼树,词频较高的单词有更短的编码. 这是一种非常好的加速技巧,因为常用的单词能更快的被访问. 在 (Mikolov et al., 2013c) 这篇论文 中在 hierarchy 上同样是使用了哈夫曼编码.
基于词向量的神经网络通常使用随机梯度下降法来训练,并通过误差反向传播获取梯度更新 (Rumelhart et al. 1986). 这种类型的模型统称作神经语言模型 (Bengio et al., 2006). 一种基于神经网络训练词向量的实现在 http://code.google.com/p/word2vec/ (Mikolov et al., 2013a).
训练收敛后,相同语义的单词被映射到相似位置的向量空间中. 例如,“powerful” 和 “strong” 相互之间比较接近,然而 “powerful” 和 “Paris” 距离就比较远. 另外一个不同之处是词向量同样包含了语义信息. 例如,词向量可以通过简单的向量运算解决类似的问题: “King” - “man” + “woman” = “Queen” (Mikolov et al., 2013d). 在不同的语种上同样可以将单词或短语转换成一个向量 (Mikolov et al., 2013b).
词向量在其他的自然语言处理任务中,性能同样是吸引人的,例如语言模型 (Bengio et al., 2006; Mikolov, 2012),自然语言理解 (Collobert & Weston, 2008; Zhilaet al., 2013),统计机器翻译 (Mikolov et al., 2013b; Zou et al., 2013),图像理解 (Frome et al., 2013),以及关系提取 (Socker et al., 2013a).
Paragraph Vector: 一种分布式记忆模型
我们训练 paragraph vectors 的方法是借鉴训练词向量的方法. 词向量是为了解决在一个句子中预测下一个单词的问题. 尽管词向量最开始是随机初始化的,但是它们最后能包含语义信息,间接的得到预测任务的结果. 我们将借鉴这种思想,用类似的方法训练 paragraph vectors . 通过从文档中提取很多上下文预料,paragraph vectors 同样是为了解决预测下一个单词的问题 .
在我们的 Paragraph Vector 框架中(如图 2),每一篇文档被映射成一个唯一的向量,用矩阵 中的一列表示,每个单词同样被映射成唯一的向量,用矩阵 中的一列表示. paragraph vector 和词向量通过求平均或者串联成一个向量,预测上下文中的下一个单词. 在我们的实验中,我们使用串联的方式来组合向量.
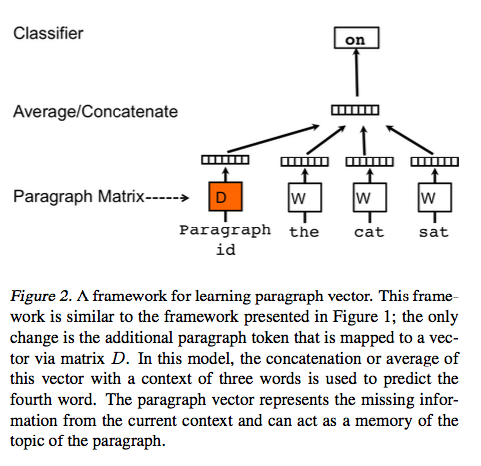
更进一步说,比较这个模型框架和词向量的模型框架,唯一的改变是在第一步, 是由 和 一起构造的.
这个 paragraph 表征可以被看成是其他的单词,它作为一个记忆单元,记忆当前上下文或者这篇段落的主题所缺失的信息. 因为这个原因,所以我们经常称这个模型为 Distributed Memory Model of Paragraph Vectors (PV-DM) .
上下文是一个固定长度的滑动窗口逐步滑过 paragraph 时抽取其中的单词组成. paragraph vector 在一篇段落中计算所有上下文时都是相同的,而在不同段落间是不同的. 而词向量矩阵 在不同段落间是相同的. 例如 “powerful” 的词向量在所有段落中都是相同的.
paragraph vectors 和词向量都使用随机梯度下降法和梯度反向传播来训练. 在随机梯度下降的每一步迭代中,每次随机从一篇段落中抽取一个固定长度的上下文,按照图 2 所示的模型框架去计算误差梯度,再使用梯度更新模型的参数.
预测时,一个需要执行的推理步是计算一篇新的 paragraph 的 paragraph vector. 这步同样是使用梯度下降来生成. 在这一步中,模型的参数直接使用训练好的结果,其中词向量矩阵 和 softmax 的权值矩阵都是固定的.
假设语料库中有 篇段落,词典表中有 个单词. 我们想要训练 paragraph vector,将每篇 paragraph 映射成一个 维的向量,每个单词映射成 维的向量,如此这个模型就总共有 个参数 (排除 softmax 的参数). 尽管当 很大时参数的数量也会很大,但在训练期间更新参数通常是稀疏的,因此总体也是有效的.
在训练之后,paragraph vector 可以作为 paragraph 的特征 (e.g. 替代或者附加到词袋模型中). 我们就能够将这些特征喂给常用的机器学习算法,比如逻辑回归,支持向量机,或者 K均值聚类等等.
总结一下,这个算法有两个关键阶段:
- 训练词向量 、softmax 的权值矩阵 和偏置项 ,已经训练过的段落的
paragraph vector矩阵 ; - 固定 ,通过附加更多的列在 上,使用梯度下降来生成从未见过的段落的
paragraph vector.
这里比较绕口,就是 的每一列是一篇段落的 paragraph vector,这里是为了符合同一所以说的是矩阵
但要预测新段落的 paragraph vector,就将 paragraph 以及随机初始化的 paragraph vector 输入模型,只是这个时候对 不做参数更新,只误差反传去更新新段落的 paragraph vector .
paragraph vectors 的优点: 一个重要的优点是能够从无标签数据中学习 paragraph vectors,而且在没有足够标签数据的任务中工作的很好.
Paragraph vectors 同样解决了一些词袋模型的关键缺点. 首先,它继承了词向量的重要性质: 单词的语义信息. 在这个向量空间中,“powerful” 相比于 “Paris” 与 “strong” 更接近. 第二个优点是考虑了词序信息,至少是在一个小的shang上下文范围内是这样,就好比在 n-gram 模型使用了一个较大的 n 一样. 这点很重要,因为 n-gram 模型保留了很多段落的信息,包括词序信息. 也就是说,我们的模型可能比 n-grams 词袋模型更好,因为 n-grams 模型会创建一个非常高维的特征,而这往往会泛化.
丢失词序的 paragraph vector: 分布式词袋
上面的方法通过串联 paragraph vector 和词向量来预测文本窗口中的下一个词. 另一种方法就是在输入的时候忽略上下文单词,但是强迫模型预测从输出段落中随机抽取的单词. 实际应用起来,这个意思就是每次随机梯度下降迭代的时候,我们从一个段落中抽取一个文本窗口,然后从文本窗口中随机抽取一个单词,利用该段落的 paragraph vector 形成一个分类任务去预测该单词. 这个方法在图 3 中显示. 我们叫这个版本为 Paragraph Vector 的词袋模型版本 (PV-DBOW),与 Paragraph Vector 的分布式记忆版本相对.
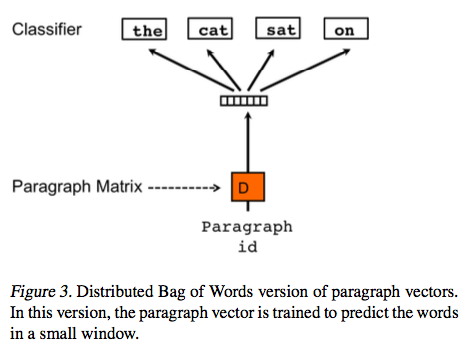
除了概念简单以外,这个模型只需要存储少量的数据. 相比于前面的 PV-DM 模型要存储 softmax 的权值矩阵和词向量矩阵,PV-DBOW 版本的模型只需要存储 softmax 的权值矩阵. 这个模型与词向量模型中的 Skip-gram 模型相似 (Mikolov et al., 2013c).
在我们的实验中,每一个 paragraph vector 都是由两个向量串联起来构成的: 一个向量是由 PV-DM 模型训练得出,另一个是由 PV-DBOW 模型训练得出. PV-DM 单独训练出的 paragraph vector 在大多数任务中已经能工作的很好 (也有更好的性能),但是联合 PV-DBOW 使得在很多的任务中使结果更一致,所以我们极力推荐联合这两者.
实验
后面部分主要是实验了,就不给大家翻译了.
到这里这篇论文算法描述部分就翻译完了,由于是边看边翻译,所以笔者感觉翻译的有点啰嗦.
另外得益于这篇文章本身通俗易懂,理解起来也没有难度,才能顺利翻译完;个人水平有限,其中若有不对的地方请及时指出,及时修改.
java 源码分析
由上面的理论可知,Paragraph Vector 的训练过程与 Word2Vec 类似,所以可以结合 Word2Vec 的源码分析进行跟踪: https://www.zybuluo.com/evilking/note/989233
这里还是使用的: https://github.com/yao8839836/doc2vec_java
训练预处理
从上面论文看,Paragraph Vector 与 Word2Vec 的差别是在第一步输入时,是将 paragraph vector 和 word vector 一起输入的,而训练时不更新词向量,只更新paragraph vecotr,这点从代码中体现.
运行 test 包下的 Doc2VecTest.java 类,可以看到前面部分主要是训练词向量,跟之前的 Word2Vec 一样的过程;后面主要是下面几行:
Word2VEC w2v = new Word2VEC();//加载词向量模型w2v.loadJavaModel("model//clinical.mod");System.out.println(w2v.distance("麻黄"));// 得到训练完的词向量,训练文本向量Map<String, Neuron> word2vec_model = learn.getWord2VecModel();//初始化学习器LearnDocVec learn_doc = new LearnDocVec(word2vec_model);//训练 doc vectorlearn_doc.learnFile(result);
在 LearnDocVec 类的构造过程中,一样是创建 的索引表,可通过查表法求 的近似。
接着就是 learnFile(File file) 方法了:
public void learnFile(File file) throws IOException {//初始化 doc vectorInitializeDocVec(file);//通过词向量模型构造 Haffman 树new Haffman(layerSize).make(wordMap.values());// 为每个叶子节点创建分类路径for (Neuron neuron : wordMap.values()) {((WordNeuron) neuron).makeNeurons();}//训练 doc2vec 模型trainModel(file);}
我们主要看 InitializeDocVec(file) 方法和 trainModel(file) 方法,其他部分跟 Word2Vec 一致.
private void InitializeDocVec(File file) throws IOException {try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)))) {String temp = null;// doc 的 idint sent_no = 0;while ((temp = br.readLine()) != null) {//记录单词数,是为了能自动调节学习率String[] split = temp.split(" ");trainWordsCount += split.length;// doc vectorfloat[] vector = new float[layerSize];//初始化 doc vectorRandom random = new Random();for (int i = 0; i < vector.length; i++)vector[i] = (float) ((random.nextDouble() - 0.5) / layerSize);doc_vector.put(sent_no, vector);sent_no++;}br.close();}}
这一步主要是为每一个 doc 生成 sent_no 和 doc vector ;其中 doc vector 的初始化方法跟 Word2Vec 的词向量的初始化方法一样:
模型训练
模型训练部分,通 word2vec 一样是实现的 Hirearch softmax 的 CBOW 模型和 Skip-gram 模型.
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)))) {String temp = null;long nextRandom = 5;//为了自动调节学习率int wordCount = 0;int lastWordCount = 0;int wordCountActual = 0;int sent_no = 0;while ((temp = br.readLine()) != null) {if (wordCount - lastWordCount > 10000) {wordCountActual += wordCount - lastWordCount;lastWordCount = wordCount;//自适应学习率alpha = startingAlpha* (1 - wordCountActual/ (double) (trainWordsCount + 1));//学习率阈值if (alpha < startingAlpha * 0.0001) {alpha = startingAlpha * 0.0001;}}String[] strs = temp.split(" ");wordCount += strs.length;List<WordNeuron> sentence = new ArrayList<WordNeuron>();//对句子上下文进行子采样for (int i = 0; i < strs.length; i++) {Neuron entry = wordMap.get(strs[i]);if (entry == null) {continue;}if (sample > 0) {double ran = (Math.sqrt(entry.freq/ (sample * trainWordsCount)) + 1)* (sample * trainWordsCount) / entry.freq;nextRandom = nextRandom * 25214903917L + 11;if (ran < (nextRandom & 0xFFFF) / (double) 65536) {continue;}}sentence.add((WordNeuron) entry);}//对上下文中每个单词进行处理for (int index = 0; index < sentence.size(); index++) {nextRandom = nextRandom * 25214903917L + 11;//默认使用 skip gram 模型if (isCbow) {// CBOW 模型cbowGram(index, sent_no, sentence, (int) nextRandom% window);} else {//Skip gram 模型skipGram(index, sent_no, sentence, (int) nextRandom% window);}}sent_no++;}br.close();}
这一步的过程与 Word2Vec 没什么区别,唯一的区别在于 cbowGram() 方法和 skipGram() 方法会把 sent_no 传进去,从而在训练 CBOW 模型和 Skip Gram 模型时结合该文档的 doc vector 和词向量.
Doc2Vec 的这两个模型 和 Word2Vec 模型的训练大同小异,所以这里我们只以 CBOW 模型的训练来分析.
CBOW模型
下面是 cbowGram() 方法的实现:
WordNeuron word = sentence.get(index);int a, c = 0;//得到 doc vectorfloat[] doc_vec = doc_vector.get(sent_no);List<Neuron> neurons = word.neurons;double[] neu1e = new double[layerSize];double[] neu1 = new double[layerSize];WordNeuron last_word;//在上下文窗口内将词向量和 doc vector累积for (a = b; a < window * 2 + 1 - b; a++) {if (a != window) {c = index - window + a;if (c < 0)continue;if (c >= sentence.size())continue;last_word = sentence.get(c);if (last_word == null)continue;//词向量累加for (c = 0; c < layerSize; c++)neu1[c] += last_word.syn0[c];}// 将文本的向量也作为输入for (c = 0; c < layerSize; c++)neu1[c] += doc_vec[c];}// HIERARCHICAL SOFTMAXfor (int d = 0; d < neurons.size(); d++) {HiddenNeuron out = (HiddenNeuron) neurons.get(d);double f = 0;//先计算 X^T * theta// Propagate hidden -> outputfor (c = 0; c < layerSize; c++)f += neu1[c] * out.syn1[c];//然后查表法计算 e^zif (f <= -MAX_EXP)continue;else if (f >= MAX_EXP)continue;elsef = expTable[(int) ((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];//计算梯度 g// 'g' is the gradient multiplied by the learning rate// double g = (1 - word.codeArr[d] - f) * alpha;// double g = f*(1-f)*( word.codeArr[i] - f) * alpha;double g = f * (1 - f) * (word.codeArr[d] - f) * alpha;//更新 e,从而去更新 doc vectorfor (c = 0; c < layerSize; c++) {neu1e[c] += g * out.syn1[c];}// doc2vec 中不需要更新词向量// Learn weights hidden -> output// for (c = 0; c < layerSize; c++) {// out.syn1[c] += g * neu1[c];// }// 不改变预测的中间词的向量}//更新 doc vectorfor (a = b; a < window * 2 + 1 - b; a++) {if (a != window) {c = index - window + a;if (c < 0)continue;if (c >= sentence.size())continue;last_word = sentence.get(c);if (last_word == null)continue;for (c = 0; c < layerSize; c++) {// last_word.syn0[c] += neu1e[c];doc_vec[c] += neu1e[c];// 更新句子(文本)向量,不更新词向量}}}
这一步跟 Word2Vec 的 CBOW 模型的区别有两处,第一是输入的时候是将 doc vector 与词向量累加输入,第二是参数更新的时候只需要更新 doc vector 而不需要更新词向量;如论文中所述,训练 paragraph vector 时词向量和 softmax 的参数向量 都是固定的.
梯度更新时同样是使用的:
小结
到这里 Doc2Vec 就分析完了.
不过其中有个想不明白的地方,按论文上说是把 paragraph vector 与 word vector 串联或者求平均,然后输入到模型中训练,源码中是把上下文中的每个单词的词向量上都加了 doc vector,感觉这里是不是有点问题,应该直接加一次就可以,那么更 doc vector 的时候也只更新一次.
