@evilking
2018-04-30T16:44:21.000000Z
字数 7227
阅读 4691
NLP
Word2Vec之 基于Negative Sampling的模型
本篇介绍基于 Negative Sampling 的 CBOW和 Skip-gram模型.Negative Sampling(简称为 NEG)是 NCE(Noise Contrastive Estimation)的一个简化版本,目的是用来提高训练速度并改善所得词向量的质量.与 Hierarchical Softmax 相比,NEG 不再使用(复杂的)Huffman树,而是利用(相对简单的)随机负采样,能大幅度提高性能,因而可作为 Hierarchical Softmax 的一种替代.
CBOW 模型
在 CBOW 模型中,已知词 的上下文 ,需要预测 ,因此,对于给定的 ,词 就是一个正样本,其它词就是负样本.负样本那么多,该如何选取呢?
假定现在已经选好了一个关于 的负样本子集 .且对 ,定义
对于一个给定的正样本 ,我们希望最大化
为什么要最大化 呢?让我们先来看看 的表达式,由上面两式得:
其中 表示当上下文为 时,预测中心词为 的概率,而 则表示当上下文为 时,预测中心词为 的概率(这里可看成一个二分类问题).从形式上看,最大化 ,相当于最大化 ,同时最小化所有的 .这不正是我们希望的吗?增大正样本的概率同时降低负样本的概率.于是,对于一个给定的语料库 ,函数
为了下面梯度推导方便起见,将上式花括号里的内容简记为 ,即
接下来利用随机梯度上升法对上式进行优化,关键是要给出 的两类梯度.首先要考虑 关于 的梯度计算:
于是, 的更新公式可写为
接下来考虑 关于 的梯度,同样利用 中 和 的对称性,有
下面以样本 为例,给出基于 Negative Sampling 的 CBOW 模型中采用随机梯度上升法更新各参数的伪代码.
注意,步 7 和步 8 不能交换次序,即 要等贡献到 后才更新.
Skip-gram 模型
有了 Hierarchical Softmax 框架下由 CBOW 模型过渡到 Skip-gram 模型的推导经验,这里,我们任然可以这样做.首先,将优化目标函数由原来的
下面以样本 为例,给出基于 Negative Sampling 的 Skip-gram 模型中采用随机梯度上升法更新各参数的伪代码:
负采样算法
顾名思义,在基于 Negative Sampling 的 CBOW 和 Skip-gram 模型中,负采样是个很重要的环节,对于一个给定的词 ,如何生成 呢?
词典 中的词在语料 中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小.这就是我们对采样过程的一个大致要求,本质上就是一个带权采样的问题.
下面先用一段通俗的描述来帮助读者理解带权采样的机理.
设词典 中的每一个词 对应一个线段 ,长度为
接下来谈谈 word2vec 中的具体做法: 记 ,这里 表示词典 中第 个词,则以 为剖分节点可得到区间 上的一个非等距剖分,为其 个剖分区间.进一步引入区间 上的一个等距离剖分,剖分节点为 ,其中 ,具体如下图所示:
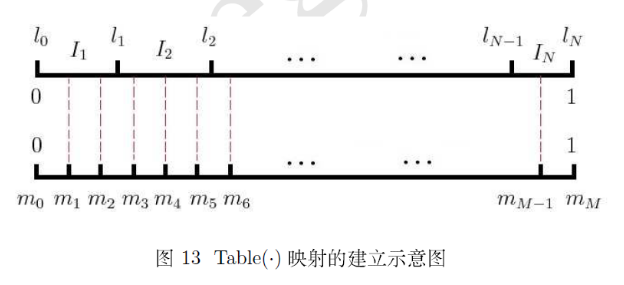
将内部剖分节点 投影到非等距剖分上,可建立 与区间 (或者说 ) 的映射关系
有了这个映射,采样就简单了:每次生成一个 间的随机整数 , 就是一个样本.当然,这里还有一个细节,当对 进行负采样时,如果碰巧选到 自己怎么办?那就跳过去呗:-),代码中也是这么处理的.
指得一提的是,word2vec 源码中为词典 中的词设置权值时,不是直接用 ,而是对其作了 次幂,其中 ,即变成了
