@Dmaxiya
2022-07-06T09:43:50.000000Z
字数 5933
阅读 1745
浅谈数据压缩算法
博文
压缩算法
压缩算法(Compaction Algorithm)指的是数据压缩的算法,主要包括压缩和还原(解压缩)的两个步骤。其实就是在不改变原有文件属性的前提下,降低文件字节空间和占用空间的一种算法。
压缩算法的分类
有损和无损
无损压缩:能够无失真地从压缩后的数据重构,准确地还原原始数据
- 特点:压缩比较小
- 适用场景:对数据的准确性要求严格的场合,如可执行文件和普通文件的压缩、磁盘的压缩,也可用于多媒体数据的压缩
- 编码算法:差分编码、RLE、Huffman 编码、LZW 编码、算术编码
有损压缩:有失真,不能完全准确地恢复原始数据,重构的数据只是原始数据的一个近似
- 特点:压缩比较大
- 适用场景:对数据的准确性要求不高的场合,如多媒体数据的压缩
- 编码算法:例如预测编码、音感编码、分形压缩、小波压缩、JPEG / MPEG
对称性
可通过编解码算法的复杂性和所需时间相差程度进行分类,相差程度低的可分类为对称的编码方法,较高的则为不对称的编码算法。
- 编码难而解码容易:Huffman 编码和分形编码
- 编码容易而解码难:用于密码学的编码方法
帧间与帧内
帧间编码:参照前后帧才能进行编解码,并在编码过程中考虑对帧之间的时间冗余的压缩
- 应用:MPEG
帧内编码:在一帧图像内独立完成的编码方法
- 应用:JPEG
在视频编码中会同时用到帧内与帧间的编码方法。
信息论的开山之作
1948 年贝尔实验室的 Shannon 发表了论文《通信的数学理论》,Shannon 借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为信息熵,并给出了计算信息熵的数学表达式。这篇伟大的论文后来被誉为信息论的开山之作,信息熵同时也奠定了所有数据压缩算法的理论基础。利用信息熵公式,人们可以计算出信息编码的极限。
Shannon 在提出信息熵理论的同时,也给出了一种简单的编码方法—— Shannon 编码。1952 年,麻省理工学院的 R.M.Fano 又进一步提出了 Fano 编码。两者后来被称为 Shannon-Fano 编码。
这种早期的编码方法揭示了变长的编码方法揭示了变长编码的基本规律,也确实可以取得一定的压缩效果,但离真正实用的压缩算法还相去甚远。
信息熵
Shannon 把随机变量 的熵值 (希腊字母 Eta)定义如下,其值域为 :
其中, 为 的概率质量函数, 为期望函数,而 是 的信息量。 本身是个随机变数。当取自有限的样本时,熵的公式可以表示为:
在这里 是对数所使用的底,通常是 2,自然常数 ,或是 10。当 时,熵的单位是 bit;当 ,熵的单位是 nat;而当 ,熵的单位是 Hart。
即时码
在唯一可译码中,如果 是一信号字母串,由码元 中的码元前后排列而成,把字母串 从左到右来读,当码元一出现,就可以确定该码元所对应的消息字符,那么这个码称为即时码。
最佳码
最佳码是信源编码的一种类型。对于某一信源和某一码元集,若有一个唯一可译码,其平均长度 小于等于所有其他唯一可译码的平均长度,则称该码为最佳码或紧致码。无失真信源编码的基本问题就是寻找最佳码。
若一个离散无记忆信源 具有熵为 ,并有码元集 ,则总可找到一种无失真编码方法,构成唯一可译码,使其平均码长 满足
上式表示最佳码的平均长度的下限值与信源熵 成正比。
Shannon 编码
编码步骤
- 将信源符号 按概率从大到小顺序排列,令
- 按 计算第 个符号对应的码字的码长( 以 2 为底, 取整)
- 计算第 个符号的累加概率
- 将累加概率变换成二进制小数,取小数点后 位数作为第 个符号的码字
编码示例
对于以下信源数据(按 从大到小排序后),计算第 个符号的累加概率 、码长 及码字:
| 信源符号 | 符号概率 | 累加概率 | 码长 | 码字 | |
|---|---|---|---|---|---|
| 0.38 | 0 | 1.40 | 2 | 00 | |
| 0.22 | 0.38 | 2.18 | 3 | 011 | |
| 0.17 | 0.60 | 2.56 | 3 | 100 | |
| 0.15 | 0.77 | 2.74 | 3 | 110 | |
| 0.05 | 0.92 | 4.32 | 5 | 11101 | |
| 0.03 | 0.97 | 5.06 | 6 | 111110 |
观察
在区间 内的函数图像如下图:
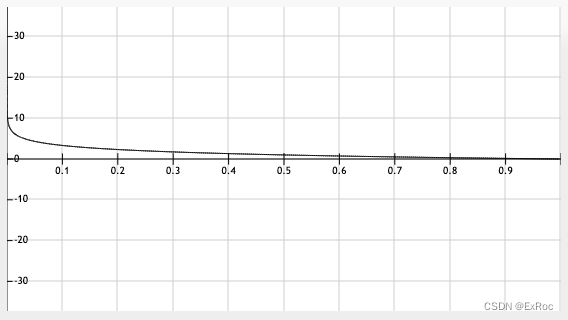
- 信源符号出现的概率与码长呈现负相关: 越大,表示信源符号出现的概率越大, 越小,码长 越小,反之亦然
- 值越小,相邻 的差值越小,函数值越大,码长越长,二进制表示中能区分的差值也越小。实际上每增加一个 的差值,码长 ,保证信源数据码字的唯一性,且任意一个码字都不可能是其他码字的前缀,从而保证解码的唯一性
补充
- Shannon 编码的效率不高,实用性不大,但对其他编码方法有很好的理论指导意义
- 一般情况下,按照 Shannon 编码方法编出来的码,其平均码长不是最短的,即不是最佳码
Fano 编码
编码步骤
- 将 个信源符号按概率递减的方式进行排列:
- 将排列好的信源符号按概率值划分成两大组,使每组的概率之和接近于相等,并对每组各赋予一个二元码符号 0 和 1
- 将每一大组的信源符号再分成两组,使划分后的两个组的概率之和接近于相等,再分别赋予一个二元码符号 0 和 1
- 依次下去,直至每个小组只剩一个信源符号为止
- 将逐次分组过程中得到的码元排列起来就是各信源符号的编码
编码示例
对以下信源数据进行编码,编码过程如图:
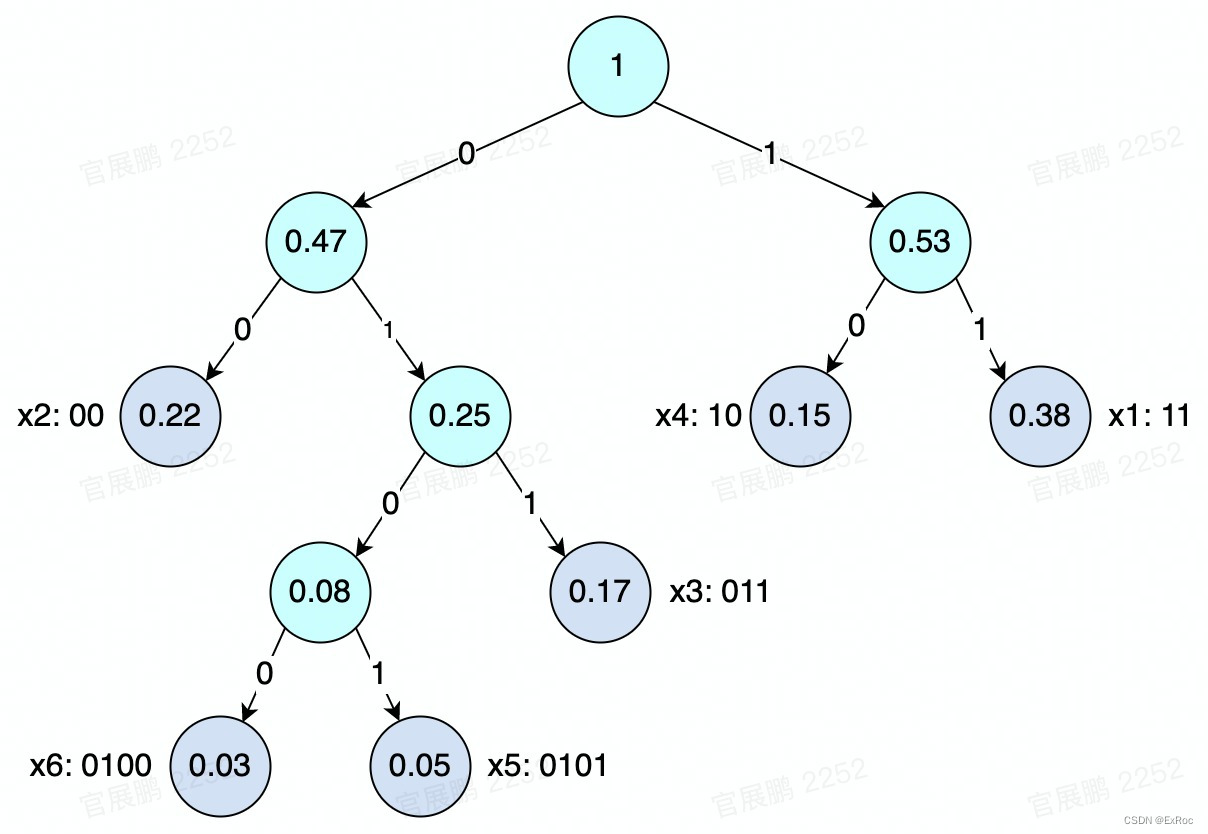
编码结果:
| 信源符号 | 符号概率 | 码字 |
|---|---|---|
| 0.38 | 11 | |
| 0.22 | 00 | |
| 0.17 | 011 | |
| 0.15 | 10 | |
| 0.05 | 0101 | |
| 0.03 | 0100 |
性质
- Fano 码的编码方法实际上是一种构造码树的方法,所以 Fano 码是即时码
- Fano 码考虑了信源的统计特性,使概率大的信源符号能对应码长较短的码字,从而有效地提高了编码效率
- Fano 码不一定是最佳码。因为 Fano 编码方法不一定能使短码得到充分利用,当信源符号较多时,若有一些符号概率分布很接近,分两大组的组合方法就会很多。可能某种分大组的结果,会使后面小组的“概率和”相差较远,从而使平均码长增加。
补充
- 元 Fano 码:与二元 Fano 码的编码方法相同,只是每次分组时应将符号分成概率分布接近的 个组
- 最佳性能条件:只有当信源的概率分布呈现 分布形式的条件下,才能达到最佳码的性能
- 平均码长的界限:一般 Fano 编码的平均码长的界限为
Huffman 编码
Huffman 编码是第一个真正实用的编码方法,由 D.A.Huffman 在 1952 年提出。当时 Huffman 是麻省理工学院的一名学生,据说为了向老师证明自己可以不参加某门功课的期末考试,他设计了这个看似简单却影响深远的编码方法。即使在今天,在许多知名的压缩工具和压缩算法里(如 WinZip、gzip 和 JPEG),也都有 Huffman 编码的身影。
编码步骤
- 将 个信源符号按概率递减的次序排列:
- 用 0 和 1 码符号分别分配给概率最小的两个信源符号,并将这两个概率最小的信源符号合并成一个新符号,用这两个最小概率之和作为新符号的概率,从而得到由 个符号组成的新信源 ,称 为信源 的缩减信源
- 把缩减信源 的信源符号按概率递减的次序排列,将其最后两个概率最小的信源符号合并成一个新符号,并分别用 0 和 1 码符号表示,形成 个符号的缩减信源
- 依次下去,直至缩减信源 只剩两个符号为止。将最后两个新符号分别用 0 和 1 码符号表示(最后两个符号的概率和为 1)。然后从最后一级缩减信源开始,依编码路径由后向前返回,就得出各信源符号所对应的码符号序列,即得对应的码字。
补充:其中每次取出两个最小信源符号,合并后对新信源进行排序的过程,可以用小顶堆实现
编码示例
对以下信源数据进行编码,编码过程如图:
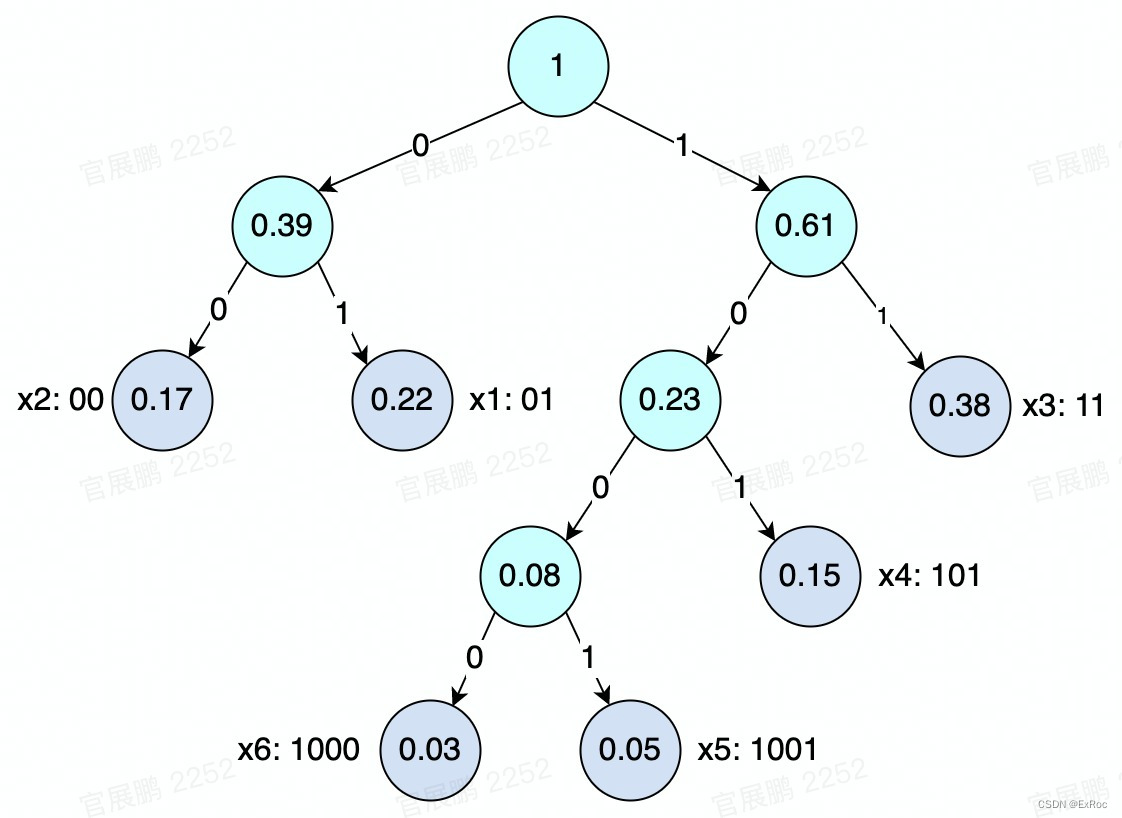
编码结果:
| 信源符号 | 符号概率 | 码字 |
|---|---|---|
| 0.38 | 11 | |
| 0.22 | 10 | |
| 0.17 | 00 | |
| 0.15 | 011 | |
| 0.05 | 0101 | |
| 0.03 | 0100 |
优点
- 以下三点可保证 Huffman 码一定是最佳码,
a. Huffman 码的编码方法保证了概率大的符号对应短码,概率小的符号对应长码,而且短码得到充分利用
b. 每次缩减信源的最后两个码字总是最后一位码元不同,前面各位码元相同
c. 每次缩减信源的最长两个码字有相同的码长 - 编码相当容易理解
- 在数据有噪音的情况下非常好,这种情况下大多数基于字典方式(如 LZ 系列压缩算法)的编码器都有问题
缺点
- 慢位流实现
- 解码耗时比编码时要长
补充
- 元 Huffman 编码:Huffman 编码同样有 元编码的方法,编码方式为每次取出出现概率最小的 个信源字符
LZ 系列压缩算法
LZ是其发明者 J.Ziv 和 A.Lempel 两个犹太人姓氏的缩写。此二人于 1977 年发表题为《顺序数据压缩的一个通用算法》的论文,论文中描述的算法被后人称为 LZ77 算法。1978 年,二人又发表了该论文的续篇,描述了后来被命名为 LZ78 的压缩算法。
LZ 系列压缩算法均为 LZ77 与 LZ78 的变种,在此基础上做了优化:
LZ77:LZSS、LZR、LZB、LZH
LZ78:LZW、LZC、LZT、LZMW、LZJ、LZFG
LZ77 压缩算法
算法步骤
- 确定滑动窗口长度,设置编码位置为待编码字符的第一个位置
- 在滑动窗口的字典中查找待编码区的最大匹配字符串
- 如果找到,输出(向左偏移量,最大匹配长度,编码区中第一个未匹配的字符), 窗口向右滑动“匹配长度”个单位
- 如果没有找到,输出(0, 0, 待编码区的第一个字符),窗口向右滑动一个单位
- 反复执行步骤 3, 4,直到最后一个字符
- 匹配结束后,若最后一个字符也在匹配字符串内,则最后一个保存的字符为“空”
编码示例
对字符串 aacaacabcabaaac 进行编码:
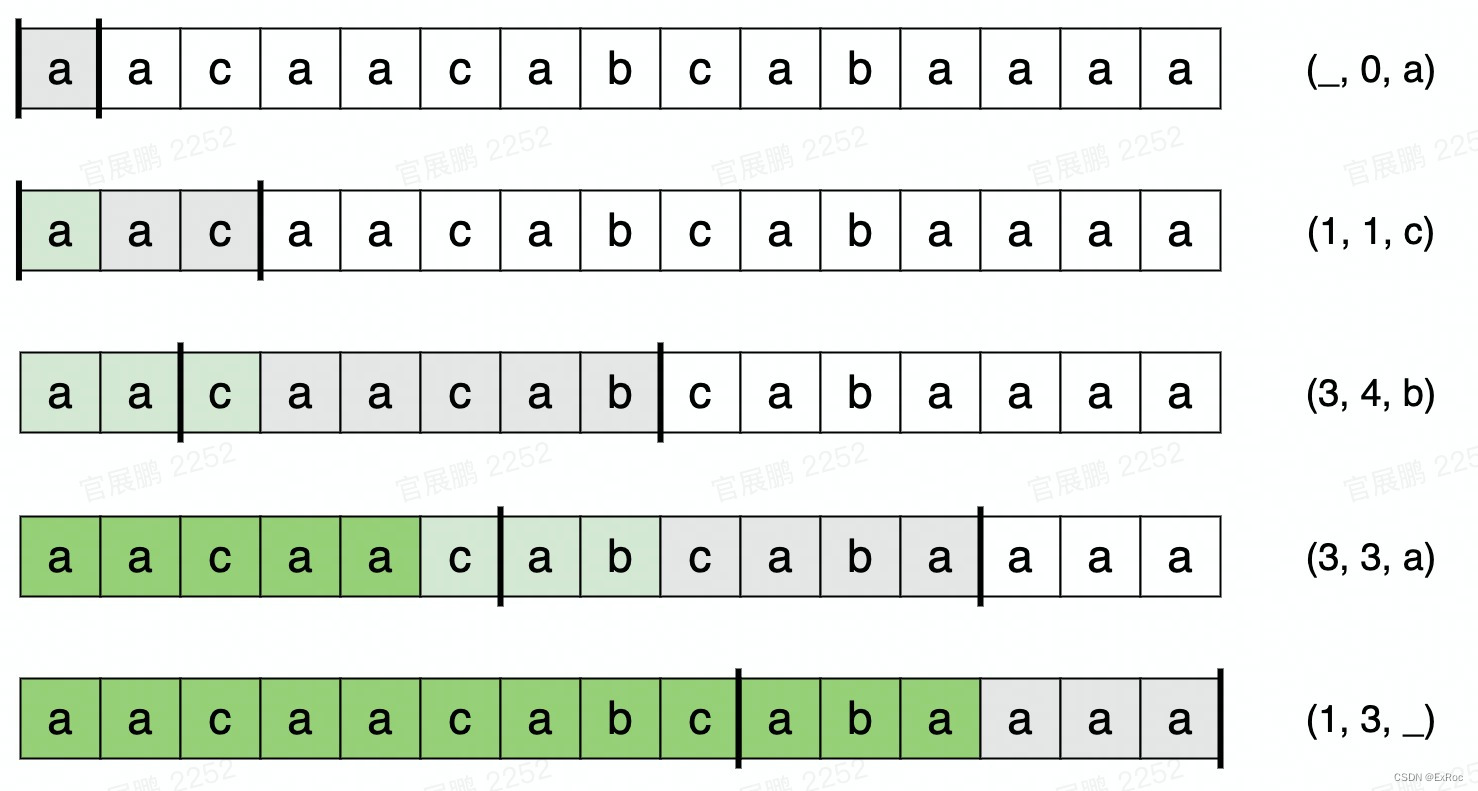
根据编码规则,可以完成解码
LZ78 压缩算法
算法步骤
在压缩过程中动态维护一颗字典树,对每一个待编码区的第一个字符 进行匹配,完成一次匹配后,将第 个匹配到的字符串记录到字典树中的下标:
a. 若当前字符 未出现在字典中,则编码为
b. 若当前字符 出现在字典中,则与字典做最长匹配,然后编码为“最长匹配前缀字符串的字典树下标,第一个未匹配到的字符”
编码示例
对字符串 babaabrrra 进行编码:
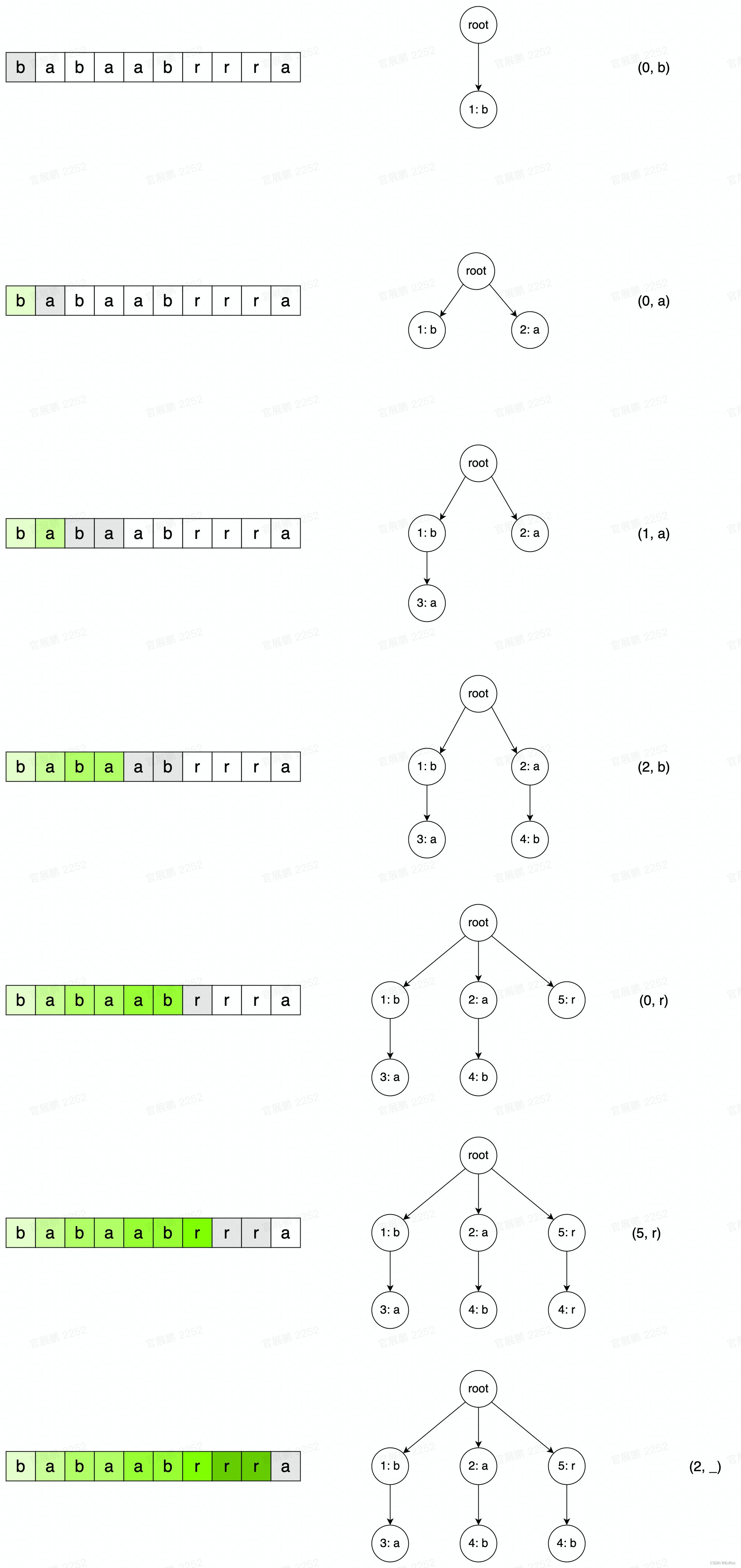
根据编码规则,可以完成解码
补充
与前面提出的三种编解码方法不同,LZ 系列的压缩算法既没有高深的理论背景,也没有复杂的数学公式,它们只是用一种极为巧妙的方式将字典技术运用于通用数据压缩领域。LZ 系列压缩算法的核心思想是自解释,字典是不会被写入压缩文件中的,在编码过程中生成的字典,解码时也可以只通过编码后的数据还原。
WinZip、WinRAR、gzip 等压缩工具都是 LZ 系列算法的受益者,字典式编码不但在压缩效果上大大超过了 Huffman 编码,而且在实现上,压缩和解压缩的速度也异常惊人。
参考资料
RAR和ZIP: 压缩大战真相 - 转载 - CSDN (推荐)
LZW 压缩算法原理解析 - hyuan - segmentfault (推荐)
LZ77 Encoding, decoding with examples - Georgi lvannikov - YouTube
程序员需要了解的硬核知识之压缩算法 - 程序员cxuan - 掘金
【数据压缩】LZ77 算法原理及实现 - Treant - 博客园
