@snuffles
2019-08-22T00:58:21.000000Z
字数 1170
阅读 2162
TVM 优化
roborock
todo::https://zhuanlan.zhihu.com/p/28226956
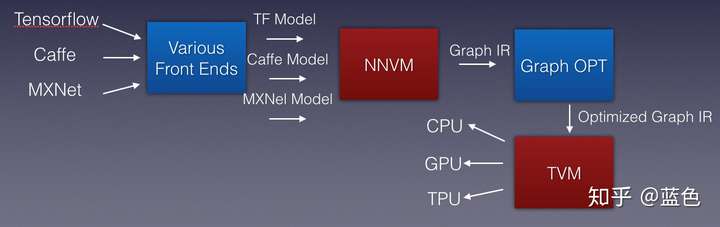
浮点峰值那些事儿
在这多种多样的设备中都保持一个高效的Inference性能,其实是一件很有挑战的事情
各大设备厂商的Inference框架性能都比较不错),比如Intel的OpenVINO,ARM的ARM NN,NV的TensorRT等
但是不统一,业务想要统一的框架
我们能不能做一个基于编译优化思想的推理框架呢
如何利用TVM快速实现超越Numpy(MKL)的GEMM
https://zhuanlan.zhihu.com/p/75203171
- 了解我们的硬件计算力和硬件利用率
- 优化
2.1 教程的第一个优化的技术为Blocking,其优化的原理是增加Cache命中率
2.2 第二个优化技术是vectorize,即SIMD,可以发现时间基本上没改变,感兴趣的同学可以像上文打印一下汇编指令,想想为什么。
2.3 调整循环的顺序,提升也很明显,所以Cache很重要。
2.4 Array Packing,这一个就是尽量让我们访问的数据在内存中是连续的,该技术基本没有提升,排除波动,基本一致。
2.5 接下来是WriteCache,同样是访写内存问题。在我这边也有很好的提升
2.6 最后的一项技术为并行,即利用4个核一起。
比numpy更快
3.1 在上文中,我们发现我们加入了一些限定参数,比如bn,而到底这个参数应该设为多少,其实就应该让机器告诉我们。于是TVM引入了一个东西,叫做AutoTVM,用机器学习来解决机器学习的问题。
3.2 我认为是我们可以再进行一次tile。如我们现在把一个1024变为了32x32,我们符合了Cache,但是我们其实可以分为类似4x32x8,这样的话,我们用4个核,每个核我们同时取32x8的小方块,最里层的8我们使用SIMD一次做完。同时在s[C]向CC(即Cache)拷贝数据的时候,我们也可以添加s[C].unroll与s[C].vectorize,从而拷贝的更快。
FMA,以及后文所提到的优化技术,如内存布局、并行、Blocking、更好的Cache命中率
总结
- 我们在优化的时候,需要思考用什么样的优化技术,如更好的Cache命中率,而非说用汇编就一定性能好。
- 我们需要关注我们的计算力,知道我们性能的优化理论值,在必要的时候利用性能优化工具,如Intel的VTune分析查看瓶颈。
- 我们需要做我们人类擅长的事情,即思考High Level的优化,以及精细的微内核控制,而非机器更擅长的事情。比如我们换一款CPU型号,或者换成ARM CPU,我们这套代码还是正常工作,机器会自动告诉我们最适合的参数是什么,而不是我们自己去设定魔数。
- 我始终相信深度学习+编译优化是深度学习系统的未来,TVM是目前我认为结合最好的一个系统,希望大家一起来
