@blueband21c
2023-04-24T13:18:19.000000Z
字数 6482
阅读 5765
第七讲 离散型随机变量的期望与方差
概率论与数理统计 讲义 NUDT 2023SP
7.1 随机变量的期望
例: 一所大学共有 15,000 名学生,下表是按照选课门数对人数进行的统计,求平均每个学生选修的课程门数.
例:随机变量取值的平均
例:一所大学共有 15,000 名学生,随机变量 表示任意一个学生注册的课程门数. 的 pmf 如下表所示. 求 的平均值.
- .
- 以上的均值也可以理解为 最有可能取到的值 (的近似),称为 随机变量 的期望值 (Expected Value).
- 记为:, , , .
离散型随机变量的期望
设 是离散型随机变量,取值范围 ,pmf 为 . 则其 期望值 (简称:期望) or 均值(Mean value)
- 记 且 , 则
期望的意义
- 本质上是对 的所有可能取值的一个加权平均 (weighted average).
- 有时并不是 的一个可能取值, 但却是总体上最接近于 的所有可能的取值的值.
- 也可以理解为大量重复试验情况下, 的取值的总的平均,或对可能观测到的所有结果的最好的近似.
例:民意调查

rv 投票选项对应的数值.
- 以上结果反映出,总体上,本班同学认为概率论比微积分要容易学.
Bernoulli rv 的期望值
已知 为Bernoulli rv, 其 pmf
其中 .
- 例: 以 rv 分别代表硬币的两面.
例:节约检验费用的方案
- 在某个社区中开展某类病毒的排查,若每个人分别采样化验,则一个人消耗一份化验费.
- 为了节省费用,采用一种改进的方案:将 个人的样本混合在一起化验.
- 如果呈阴性,则说明每个人都没有问题. 否则,则将以上的 个人再次全部分别进行检验.
- 已知当前病毒总体的感染率为 .
- 问:如何优化以上方案,使得总体的检验费用尽可能地少?
分析: 记 为每个人产生的检验费用.
- 于是 .
- 以单人检验费用的期望最小化为目标,寻找最优的 ,就能够使得检验的费用总体上尽可能地少.
- 例如:,,.

例:第一次出现
反复抛一枚图钉. 已知每次针头朝上的概率为,且抛的结果相互独立. 求第一次出现针头朝上时抛的总次数的期望.
解: 令 rv 第一次出现针头朝上时抛的总次数. 的 pmf 为
由定义, 的期望值为
- 本例中 的分布称为 几何分布 (Geometric distribution),记为
注:上例中的无穷和的计算过程,记 ,
期望的存在性
例: 设 的 pmf 为
- 定理: 设 rv 且 pmf 为 ,若 收敛,则 存在.
- 若 发散,则称 的期望不存在
注:关于以上涉及的级数求和,参考:https://www.cnblogs.com/misaka01034/p/BaselProof.html
7.2 随机变量函数的期望
例: 机动车测试的成本与车辆的气缸数 紧密相关. 已知 的 pmf 如下:
测试成本 . 由于 是一个随机变量, 必然也是. 试求 的期望值.
解: 利用 的 pmf 可以导出 的 pmf:
于是
- 思考: 是否成立?
- 定理: 设离散型 rv 的 pmf 为 , 则函数 的期望
期望的性质
定理:对任意离散型 rv 和常数
- 推论:对任意常数 , .
- 思考:
- 若存在,则为常数.
- .
7.3 离散型随机变量的方差
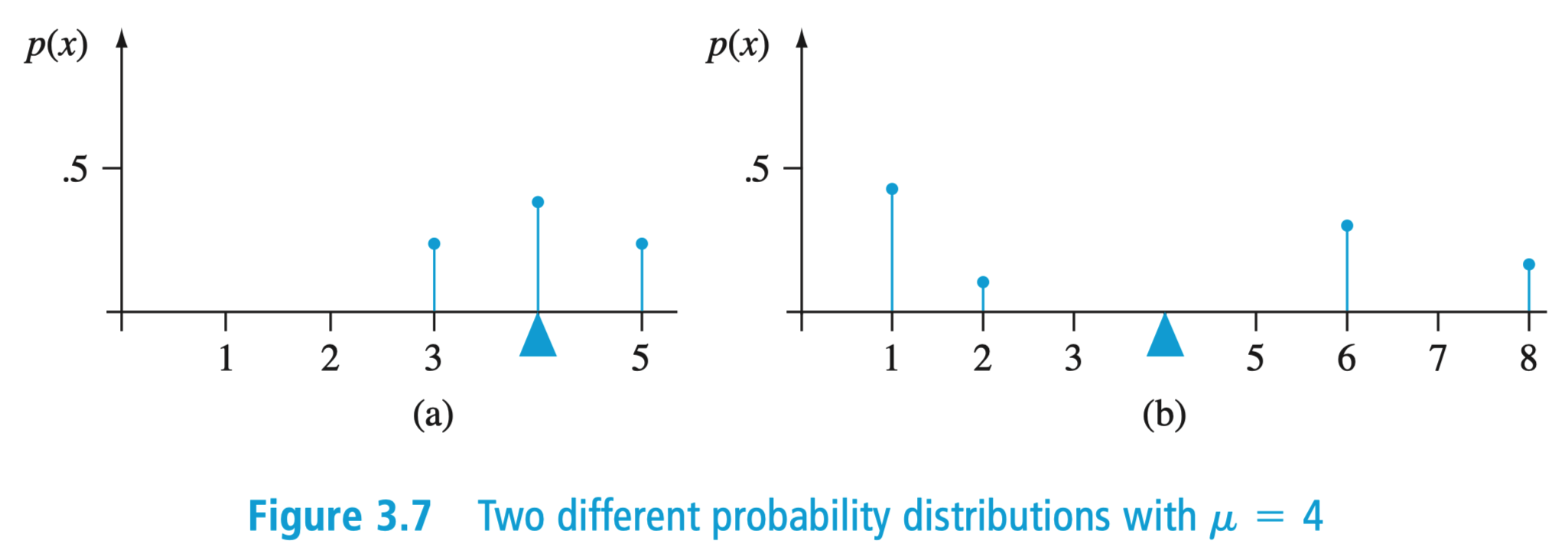
如果两组数据均值相同,还可以如何对进行比较?
方差的定义
设离散型 rv 的 pmf 为 且期望值存在 , 则
称为 的 方差(variance)
- 常用记号:, , , ,
- 称为 的标准差(standard deviation).
方差的计算
定理: 对离散型 rv , 如果 和 均存在,则
例: 给定离散型 rv 的 pmf 如下
方差的性质
定理 对任意离散型 rv 和任意常数
- 推论 对任意常数 , .
Bernoulli rv 的方差
考虑 Bernoulli rv , 其 pmf 为
其中 .
小结
- 期望:
- rv 的函数的期望:
- 方差:
- 熟练掌握 Bernoulli 分布的 pmf,期望和方差
Every good mathematician is at least half a philosopher, and every good philosopher is at least half a mathematician.
-- Friedrich Ludwig Gottlob Frege
课堂讨论
如何理解:期望是总体上最接近随机变量所有可能取值的值?
- 定理:
- ,.
- 是函数 的唯一最小值点.
- 在所有常数中, 整体上与 的所有可能取值最为接近.
例:赌场没有福利!
- 有一种赌博游戏的规则如下:顾客押上赌本,并先在 中选定一个数,然后连续抛掷三次均匀骰子.
- 如果抛掷的点数中有顾客选定的数字,则按照该点数出现的次数,顾客可以在拿回赌本的同时,赢得与次数相同倍数的赌本.
- 如果三次抛掷均未能得到顾客选定的数字,则赌本被庄家(赌场)拿走.
- 顾客在平均意义上是否会赢钱呢?
分析: 不妨设顾客选择的数字是 ,赌本也是 . 表示顾客的收益,则 .
- ,
- .
- .
- .
- .
矩(Moment)
给定对随机变量 ,对任意 ,定义
- k 阶原点矩 (k-th origin moment):
- k 阶中心矩 (k-th centrl moment):
- 例:
- , , ...
偏度 (skewness)
- 用于描述随机变量分布的对称性.
- 偏度为零,说明分布完全左右对称.
- 偏度为正,分布整体的重心偏左;反之偏右.
峰度 (kurtosis)
- 用于描述随机变量峰值的尖锐程度以及拖尾的“粗重”程度.
- 峰度越大,峰值越尖,拖尾越粗;
- 峰度越小,峰值越圆润,拖尾越细.
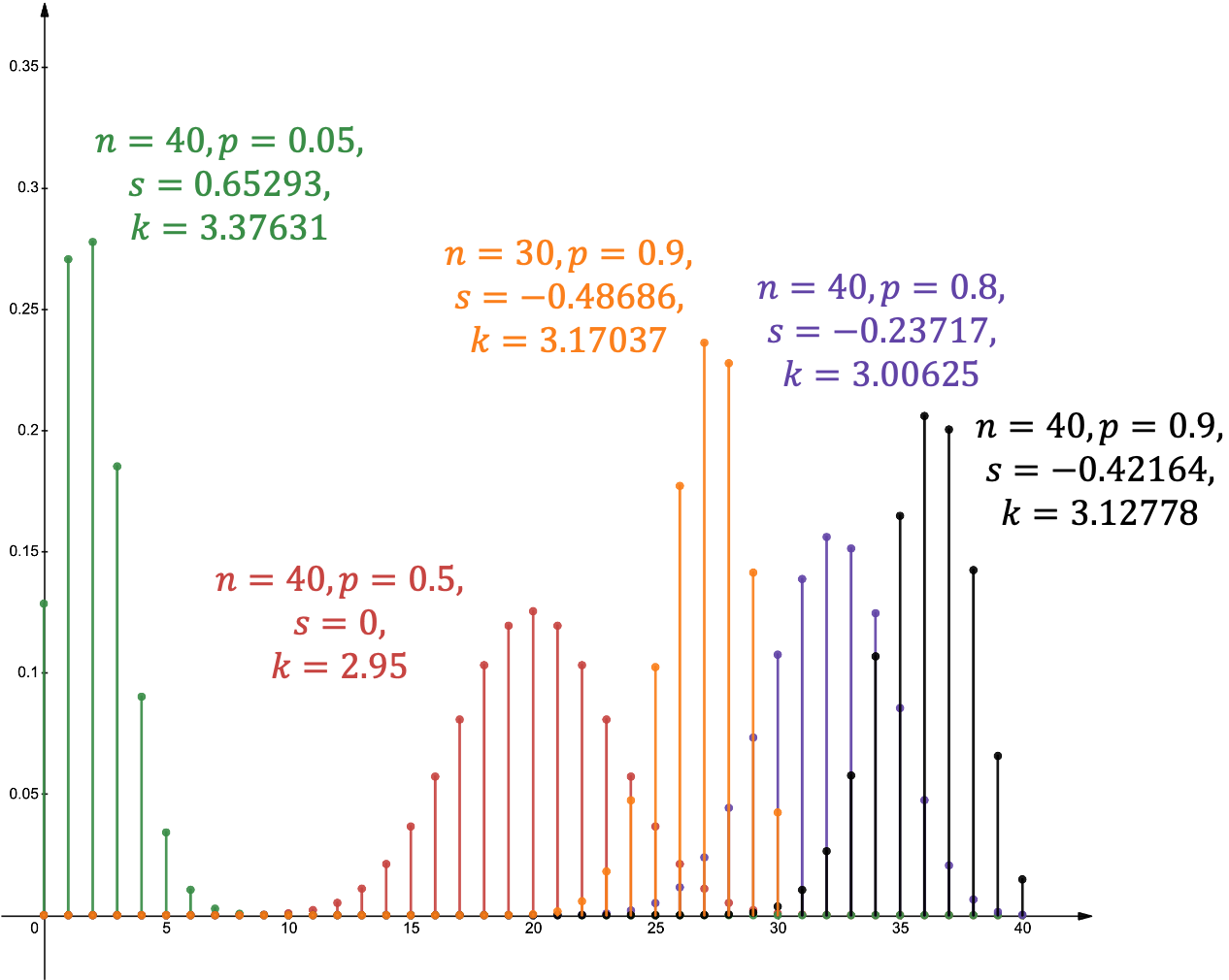
二项分布的偏度与峰度
设 ,
- 偏度: .
- 峰度: .
随机分布的熵
给定离散型随机变量 ,满足
其 熵 (Entropy)定义为
- 不难发现,,且 与 的取值无关.
- 熵体现了随机变量的混乱程度,也即随机变量取值的不确定性的大小.
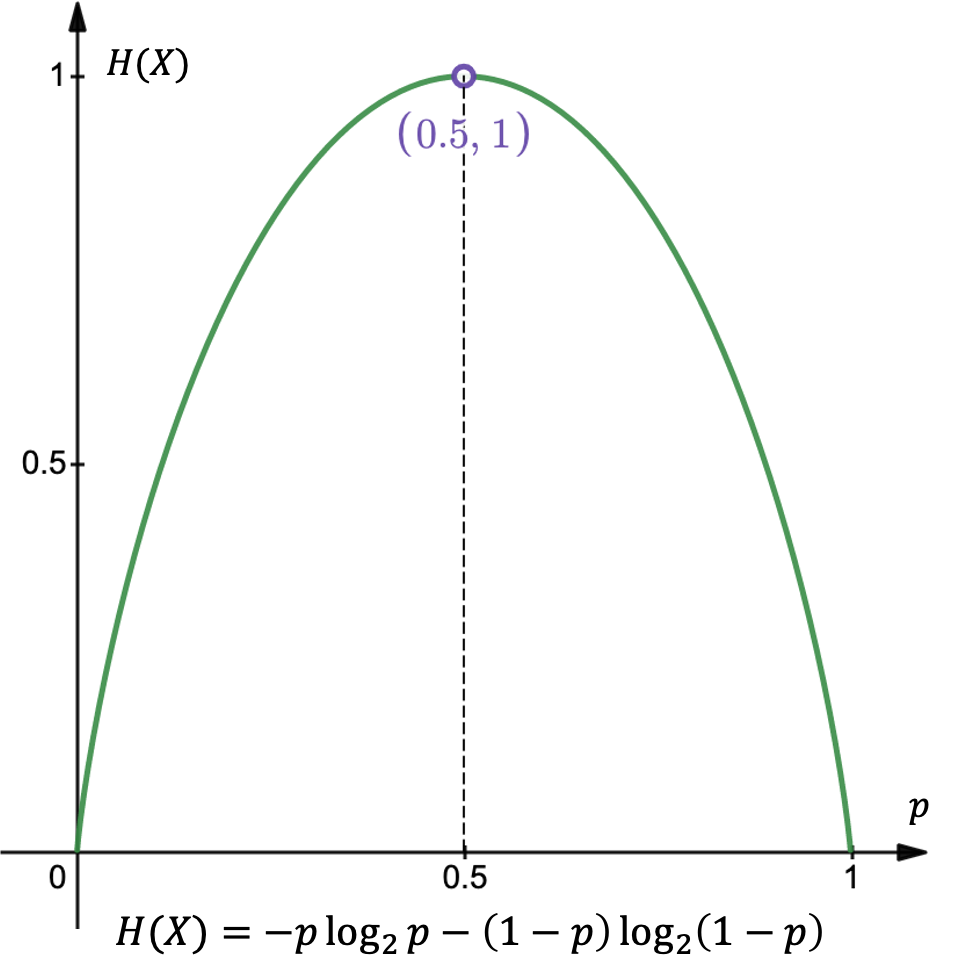
Bernoulli 分布的熵
设 ,则
- 当 时, 取最大值,也即此时 的取值最难以预测.
离散均匀分布的熵
定理: 设 是仅有有限多个取值的离散型随机变量,则当且仅当 的所有取值为等可能时,其熵最大.
- 事实上,对任意有限取值的随机变量,其熵最大为 .
- 直观地看,均匀分布的随机变量对于任意的取值没有特定的“倾向性”,因此其取值的不确定性最大,也最难以预测.
- 熵常常作为信息量的一种度量,对随机变量而言,一般来说,熵越大则意味着潜在的可能性若多,因此信息量也越大.
