@coder-pig
2018-04-02T03:56:39.000000Z
字数 7929
阅读 3368
小猪的Python学习之旅 —— 3.正则表达式
Python
引言:
上一节学习了一波urllib库和BeautifulSoup的使用,爬取很多小网站
基本是得心应手的了,而一般我们想爬取的数据基本都是字符串,图片url,
或者是段落文字等,掌握字符串的处理显得尤为重要,说到字符串处理,
除了了解字符串相关的处理函数外,还需要 正则表达式 这枚字符串处理神器!
对于正则表达式,很多人开发者貌似都很抗拒,老说学来干嘛,要什么
正则表达式上网一搜就是啦,对此我只能说2333,爬取网页数据的时候,
你搜下给我看,不同的场景匹配字符串的正则表达式都是不一样的,掌握
正则表达式的编写就显得尤为重要了。本节通过一些有趣的例子帮你
快速上手正则表达式,其实真没想象中那么难!
re模块
Python中通过re模块使用正则表达式,该模块提供的几个常用方法:
1.匹配
re.match(pattern, string, flags=0)
- 参数:匹配的正则表达式,要匹配的字符串,标志位(匹配方法)
- 尝试从字符串的开头进行匹配,匹配成功会返回一个匹配的对象,
类型是:<class '_sre.SRE_Match'>
group与groups
re.search(pattern, string, flags=0)
- 参数:同上
- 扫描整个字符串,返回第一个匹配的对象,否则返回None
注意:match方法和search的最大区别:match如果开头就不和正则表达式匹配,
直接返回None,而search则是匹配整个字符串!!
2.检索与替换
re.findall(pattern, string, flags=0)
- 参数:同上
- 遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回
re.finditer(pattern, string, flags=0)
- 参数:同上
- 遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回
re.sub(pattern, repl, string, count=0, flags=0)
- 参数:repl替换为什么字符串,可以是函数,把匹配到的结果做一些转换;
count替换的最大次数,默认0代表替换所有的匹配。 - 找到所有匹配的子字符串,并替换为新的内容
re.split(pattern, string, maxsplit=0, flags=0)
- 参数:maxsplit设置分割的数量,默认0代表所有满足匹配的都分割
- 在正则表达式匹配的地方进行分割,并返回一个列表
3.编译成Pattern对象
对于会多次用到的正则表达式,我们可以调用re的compile()方法编译成
Pattern对象,调用的时候直接Pattern对象.xxx即可,从而提高运行效率。
附:flags(可选标志位)表
多个标志可通过按位OR(|)进行连接,比如:re.I|re.M
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
2.正则规则详解
1.加在正则字符串前的'r'
为了告诉编译器这个string是个raw string(原字符串),不要转义反斜杠!
比如在raw string里\n是两个字符,'\'和'n',不是换行!
2.字符
| 字符 | 作用 |
|---|---|
. |
匹配任意一个字符(除了\n) |
[] |
匹配[]中列举的字符 |
[^...] |
匹配不在[]中列举的字符 |
\d |
匹配数字,0到9 |
\D |
匹配非数字 |
\s |
匹配空白,就是空格和tab |
\S |
匹配非空白 |
\w |
匹配字母数字或下划线字符,a-z,A-Z,0-9,_ |
\W |
匹配非字母数字或下划线字符 |
- |
匹配范围,比如[a-f] |
3.数量
| 字符 | 作用(前面三个做了优化,速度会更快,尽量优先用前三个) |
|---|---|
* |
前面的字符出现了0次或无限次,即可有可无 |
+ |
前面的字符出现了1次或无限次,即最少一次 |
? |
前面的字符出现了0次或者1次,要么不出现,要么只出现一次 |
{m} |
前一个字符出现m次 |
{m,} |
前一个字符至少出现m次 |
{m,n} |
前一个字符出现m到n次 |
4.边界
| 字符 | 作用 |
|---|---|
^ |
字符串开头 |
$ |
字符串结尾 |
\b |
单词边界,即单词和空格间的位置,比如'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er' |
\B |
非单词边界,和上面的\b相反 |
\A |
匹配字符串的开始位置 |
\Z |
匹配字符串的结束位置 |
5.分组
用()表示的就是要提取的分组,一般用于提取子串,
比如:^(\d{3})-(\d{3,8})$:从匹配的字符串中提取出区号和本地号码
| 字符 | 作用 |
|---|---|
 |
匹配左右任意一个表达式 |
(re) |
匹配括号内的表达式,也表示一个组 |
| (?:re) | 同上,但是不表示一个组 |
(?P<name>) |
分组起别名,group可以根据别名取出,比如(?P<first>\d)match后的结果调m.group('first')可以拿到第一个分组中匹配的记过 |
(?=re) |
前向肯定断言,如果当前包含的正则表达式在当前位置成功匹配, 则代表成功,否则失败。一旦该部分正则表达式被匹配引擎尝试过, 就不会继续进行匹配了;剩下的模式在此断言开始的地方继续尝试。 |
(?!re) |
前向否定断言,作用与上面的相反 |
(?<=re) |
后向肯定断言,作用和(?=re)相同,只是方向相反 |
(?<!re) |
后向否定断言,作用于(?!re)相同,只是方向想法 |
附:group()方法与其他方法详解
不引入括号,增个表达式作为一个组,是group(0)
不引入()的话,代表整个表达式作为一个组,group = group(0)
如果引入()的话,会把表达式分为多个分组,比如下面的例子:

输出结果:

除了group方法外还有三个常用的方法:
- groups(): 从group(1)开始往后的所有的值,返回一个元组
- start():返回匹配的开始位置
- end():返回匹配的结束位置
- span():返回一个元组组,表示匹配位置(开始,结束)
贪婪与非贪婪
正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
比如:ret = re.match(r'^(\d+)(0*)$','12345000').groups()ß
我们的原意是想得到('12345','000')这样的结果,但是输出
ret我们看到的却是: ,由于贪婪,直接把后面的
,由于贪婪,直接把后面的
0全给匹配了,结果0*只能匹配空字符串了,如果想尽可能少的
匹配,可以在\d+后加上一个?问号采用非贪婪匹配,改成:
r'^(\d+?)(0*)$',输出结果就变成了: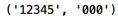
3.正则练习
例子1:简单验证手机号码格式
流程分析:
- 1.开头可能是带0(长途),86(天朝国际区号),17951(国际电话)中的一个或者一个也没有:

- 2.接着1xx,有13x,14x,15x,17x,18x,然后这个x也是取值范围也是不一样的:
13x:0123456789
14x:579
15x:012356789
17x:01678
18x:0123456789
然后修改下正则表达式,可以随便输个字符串验证下:

- 3.最后就是剩下部分的8个数字了,很简单:[0-9]{8} 加上:

^(0|86|17951)?(13[0-9]|14[579]|15[0-35-9]|17[01678]|18[0-9])[0-9]{8}$
例子2:验证身份证
流程分析:
身份证号码分为一代和二代,一代由15位号码组成,而二代则是由18个号码组成:
十五位:xxxxxx yy mm dd pp s
十八位:xxxxxx yyyy mm dd ppp s
为了方便了解,把这两种情况分开,先是十八位的:
- 1.前6位:地址编码(省市县),第一位从1开始,其他五位0-9

- 2.第7到10(接着的两位或者四位有):年,范围是1800到2099:

- 3.第11到12:月,1-9月需要补0,10,11,12

- 4.第13到14:日,首位可能是012,第二位为0-9,还要补上10,20,30,31

- 5.第15到17:顺序码,这里就是三个数字,对同年、同月、同日出生的人
编定的顺序号,奇数分给男的,偶数分给女的:

- 6.第18位:校验码,0到9或者x和X

能推算出18的,那么推算出15的也不难了:

最后用|组合下:

^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|10|11|12)([012][1-9]|10|20|30|31)\d{3}[0-9Xx]|[1-9]\d{5}\d{2}(0[1-9]|10|11|12)([012][1-9]|10|20|30|31)\d{2}[0-9Xx]$
另外,这里的正则匹配出的身份证不一定是合法的,判断身份是否
合法还需要通过程序进行校验,校验最后的校验码是否正确。
扩展阅读:身份证的最后一位是怎么算出来的?
更多可见:第二代身份证号码编排规则首先有个加权因子的表:(没弄懂怎么算出来的..)
[7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]然后位和值想乘,结果相加,最后除11求余,比如我随便网上找的
一串身份证:411381199312150167,我们来验证下最后的7是对的吗?sum = 4*7 + 1*9 + 1*10 + 3*5 +8*8 + 1* 4 ... + 6 * 2 = 282
sum % 11 = 7,所以这个是一个合法的身份证号。
例子3:验证ip是否正确
流程分析:
ip由4段组成,xxx.xxx.xxx.xxx,访问从0到255,因为要考虑上中间的.
所以我们把第一段和后面三段分开,然后分析下ip的结构,可能是这几种情况:
一位数:[1-9]
两位数:[1-9][0-9]
三位数(100-199):1[0-9][0-9]
三位数(200-249):2[0-4][0-9]
三位数(250-255): 25[0-5]
理清了第一段的正则怎么写就一清二楚了:

然后后面三段,需要在前面加上一个一个.,然后这玩意是元字符,
需要加上一个反斜杠\,让他失去作用,后面三段的正则就是:
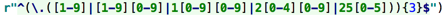
把两段拼接下即可得出完整的验证ip的正则表达式了:

^([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(\.([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}$
例子4:匹配各种乱七八糟的
- 匹配中文:
[\u4e00-\u9fa5] 匹配双字节字符:
[^\x00-\xff]匹配数字并输出示例:

输出结果: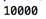
匹配开头结尾示例:

输出结果: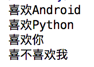
4.正则实战
实战:抓一波城市编码列表
本来想着就抓抓中国气象局的天气就好了,然后呢,比如深圳天气的网页是:
http://www.weather.com.cn/weather1dn/101280601.shtml
然后这个101280601是城市编码,然后网上搜了下城市编码列表,发现要么
很多是错的,要么就缺失很多,或者链接失效,想想自己想办法写一个采集
的,先搞一份城市编码的列表,不过我去哪里找数据来源呢?中国气象局
肯定是会有的,只是应该不会直接全部暴露出来,想想能不能通过一些间接
操作来实现。对着中国气象局的网站瞎点,结果不负有心人,我在这里:
http://www.weather.com.cn/forecast/
发现了这个:
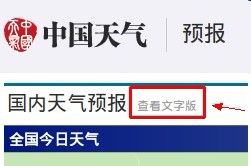
点进去后:http://www.weather.com.cn/textFC/hb.shtml#
然后,我觉得这可能是入手点:
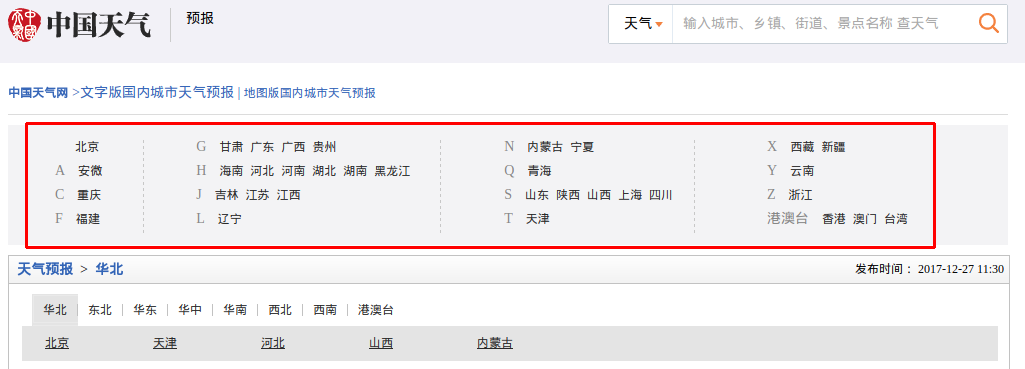
F12打开开发者工具,不出所料:
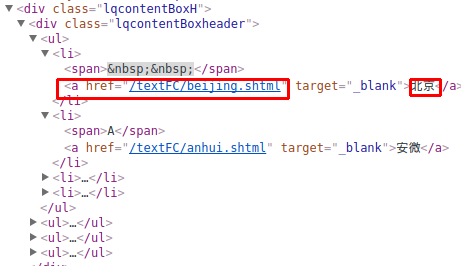
这里有个超链接,难不成是北京所有的地区的列表,点击下进去看看:
http://www.weather.com.cn/textFC/beijing.shtml
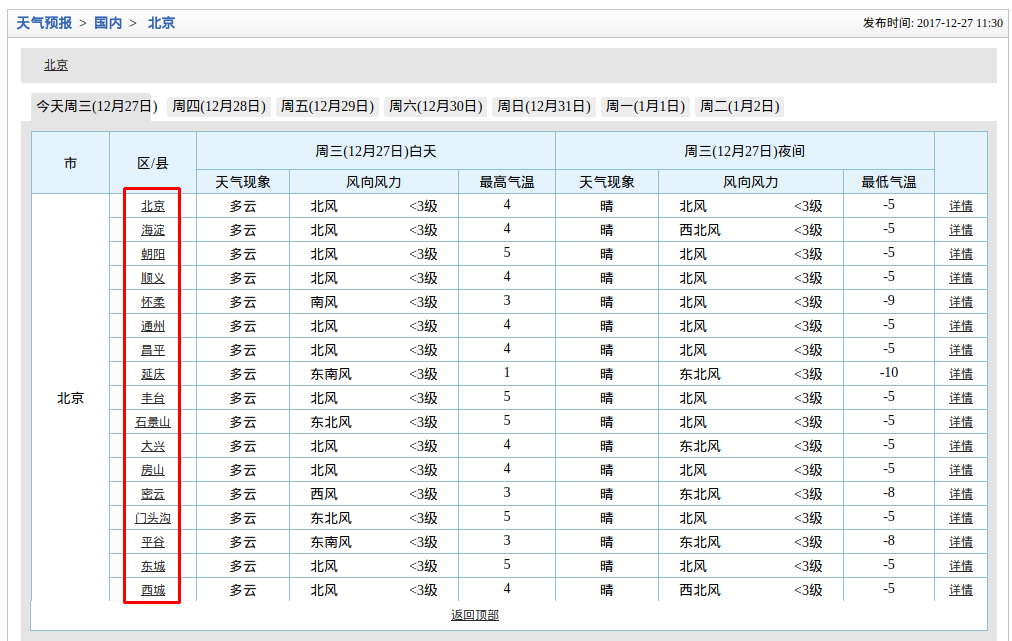
卧槽,果然是北京所有的地区,然后每个地区的名字貌似都有一个超链接,
F12看下指向哪里?
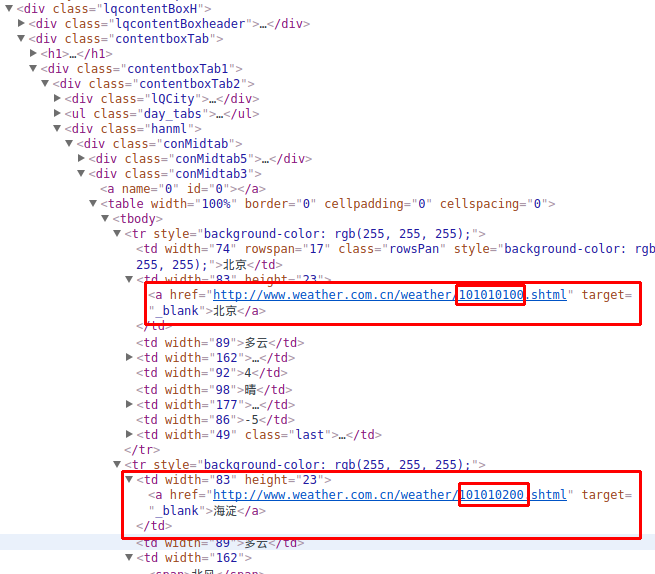
到这里就豁(huo)然开朗了,我们来捋一捋实现的流程:
- 1.先拿到第一层的城市列表链接用列表存起来
- 2.接着遍历列表去访问不同的城市列表链接,截取不同城市的城市名,城市编码存起来
流程看上去很简单,接着来实操一波。
先是拿城市列表url

这个很容易拿,就直接贴代码了:

拿到需要的城市列表url:

接着随便点开一个,比如beijing.shtml,页面结构是这样的:
想要的内容是这里的超链接:
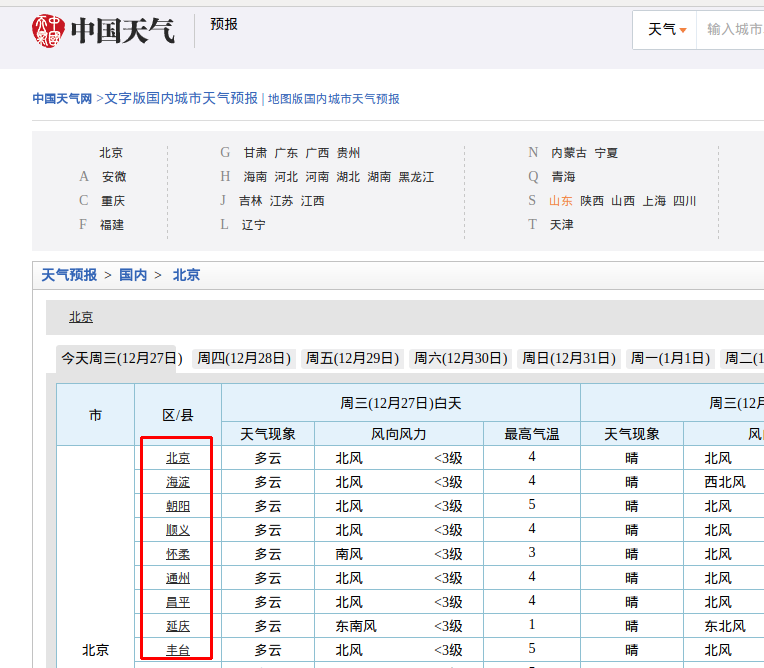
F12看下页面结构,层次有点多,不过没关系,这样更能够锻炼我们

入手点一般都是离我们想要数据最近地方下手,我看上了:conMidtab3
全局搜了一下,也就八个:

第一个直接就可以排除了:

接着其余的七个,然后发现都他么是一样的...,那就直接抓到第一个吧:

输出下:

是我们想要的内容,接着里面的tr是我们需要内容,找一波:

输出下:

继续细扒,我们要的只是a这个东西:
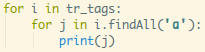
输出下:
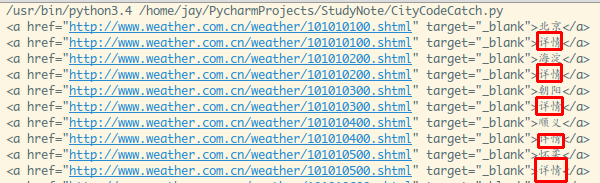
重复出现了一堆详情,很明显是我们不想要的,我们可以在循环的时候
执行一波判断,重复的不加入到列表中:

然后我们想拿到城市编码和城市名称这两个东西:

城市的话还好,直接调用tag对象的string直接就能拿到,
而城市编码的话,按照以前的套路,我们需要先['href']拿到
再做字符串裁剪,挺繁琐的,既然本节学习了正则,为何不用
正则来一步到位,不难写出这样的正则:

匹配拿到group(1)就是我们要的城市编码:

输出内容:
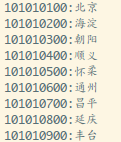
卧槽,就是我们想要的结果,美滋滋,接着把之前拿到所有
的城市列表都跑一波,存字典里返回,最后赛到一个大字典
里,然后写入到文件中,完成。
========= BUG的分割线 =========
最后把数据打印出来发现只有428条数据,后面才发现conMidtab3那里处理有些
问题,漏掉了一些,限于篇幅,就不重新解释了,直接贴上修正完后的代码把...
import urllib.requestfrom urllib import errorfrom bs4 import BeautifulSoupimport os.pathimport reimport operator# 通过中国气象局抓取到所有的城市编码# 中国气象网基地址weather_base_url = "http://www.weather.com.cn"# 华北天气预报urlweather_hb_url = "http://www.weather.com.cn/textFC/hb.shtml#"# 获得城市列表链接def get_city_list_url():city_list_url = []weather_hb_resp = urllib.request.urlopen(weather_hb_url)weather_hb_html = weather_hb_resp.read().decode('utf-8')weather_hb_soup = BeautifulSoup(weather_hb_html, 'html.parser')weather_box = weather_hb_soup.find(attrs={'class': 'lqcontentBoxheader'})weather_a_list = weather_box.findAll('a')for i in weather_a_list:city_list_url.append(weather_base_url + i['href'])return city_list_url# 根据传入的城市列表url获取对应城市编码def get_city_code(city_list_url):city_code_dict = {} # 创建一个空字典city_pattern = re.compile(r'^<a.*?weather/(.*?).s.*</a>$') # 获取城市编码的正则weather_hb_resp = urllib.request.urlopen(city_list_url)weather_hb_html = weather_hb_resp.read().decode('utf-8')weather_hb_soup = BeautifulSoup(weather_hb_html, 'html.parser')# 需要过滤一波无效的div_conMidtab = weather_hb_soup.find_all(attrs={'class': 'conMidtab', 'style': ''})for mid in div_conMidtab:tab3 = mid.find_all(attrs={'class': 'conMidtab3'})for tab in tab3:trs = tab.findAll('tr')for tr in trs:a_list = tr.findAll('a')for a in a_list:if a.get_text() != "详情":# 正则拿到城市编码city_code = city_pattern.match(str(a)).group(1)city_name = a.stringcity_code_dict[city_code] = city_namereturn city_code_dict# 写入文件中def write_to_file(city_code_list):try:with open('city_code.txt', "w+") as f:for city in city_code_list:f.write(city[0] + ":" + city[1] + "\n")except OSError as reason:print(str(reason))else:print("文件写入完毕!")if __name__ == '__main__':city_result = {} # 创建一个空字典,用来存所有的字典city_list = get_city_list_url()# get_city_code("http://www.weather.com.cn/textFC/guangdong.shtml")for i in city_list:print("开始查询:" + i)city_result.update(get_city_code(i))# 根据编码从升序排列一波sort_list = sorted(city_result.items(), key=operator.itemgetter(0))# 保存到文件中write_to_file(sort_list)
运行结果:

5.小结和几个API
本节对Python中了正则表达式进行了一波学习,练手,发现和Java里的正则
多了一些规则,正则在字符串匹配的时候是挺爽的,但是正则并不是全能
的,比如闰年二月份有多少天的那个问题,还需要程序另外去做判断!
正则还需要多练手啊,限于篇幅,就没有另外去抓各种天气信息了,
而且不是刚需,顺道提供两个免费可用三个和能拿到天气数据的API吧:
- 小米:http://weatherapi.market.xiaomi.com/wtr-v2/weather?cityId=101280601
- 魅族:http://aider.meizu.com/app/weather/listWeather?cityIds=101280601
还有个中国气象局提供的根据经纬度获取天气的:
http://e.weather.com.cn/d/town/index?lat=22.5383&lon=113.9524
人生苦短,我用Python,爬虫真好玩!期待下节爬虫框架scrapy学习~

来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

