@coder-pig
2018-04-02T03:51:42.000000Z
字数 6697
阅读 2907
小猪的Python学习之旅 —— 13.文字识别库pytesseract初体验
Python
引言
度过了短暂的春节假期,又要开始继续搬砖了,因为还处于节后
综合征,各种散漫,不想看任何代码相关的东西,根本挤不出学习热情...
恰逢前几天,公司的UI妹子安利了一个卖萌的新番:小木乃伊到我家

就是图中的这四只小东西,敲可爱的说,分别叫:
小伊(木乃伊),可尼(小鬼,牛),啊勇(龙),胖嘟嘟
UI妹子尤其喜欢可尼,是挺萌的,突然想找些相关的手机或者电脑壁纸,
壁纸没找到,却在 小木乃伊到我家吧 里找到了一些自制的表情包:
https://tieba.baidu.com/p/5522091060
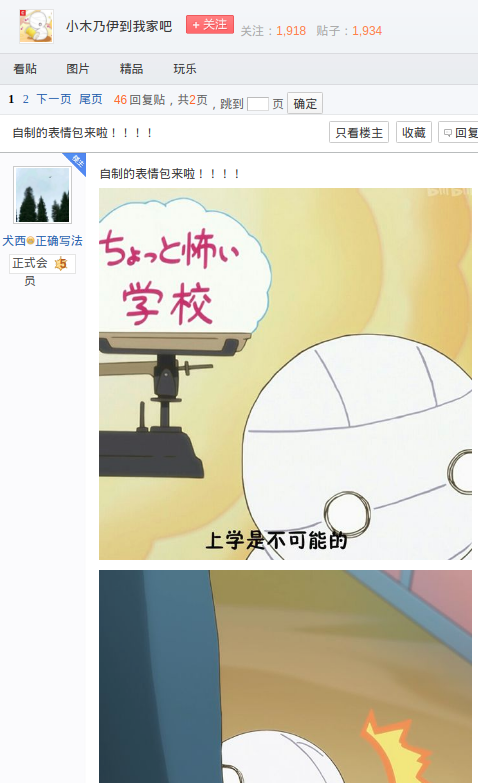
表情都很有趣嘛,写个脚本把图片都爬下来?走一波流程:
Step 1:Network抓包看下返回的数据是否和Element一致,
或者说有我们想要的数据,而不是通过JS黑魔法进行加载的;
复制下第一个图的图片链接,到Network选项卡里的Response
里查找以下,嗯,找得到,可以:

Step 2:滚动到底,抓包没有发现Ajax动态加载数据的踪迹
Step 3:点击第二页,抓包发现了Ajax加载的痕迹!!!
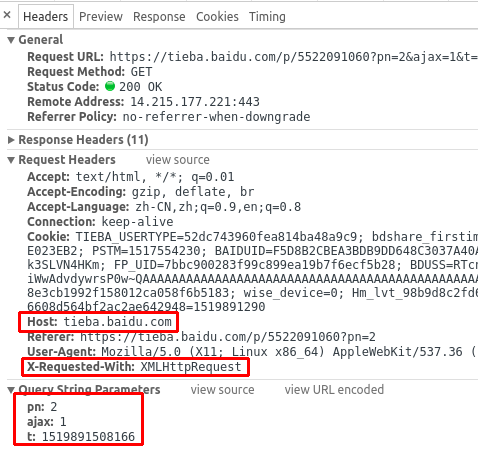
同样拿第一个图的url搜下,同样可以找到

三个参数猜测pn为page_number,即页数,PostMan或者自己
写代码模拟请求,记得塞入Host和X-Requested-With,验证pn=1
是否为第一页数据,验证通过,即所有页面数据都可以通过这个
接口拿到;
Step 4:先加载拿到末页是第几页,然后走一波循环遍历即可
解析数据获得图片url,写入文件,使用多个线程进行下载
比较简单,就不详解了,直接给出代码,看不懂的自己复习去:
# 抓取百度贴吧某个帖子里的所有图片import coderpig_n as cpnimport requestsimport timeimport threadingimport queuetiezi_url = "https://tieba.baidu.com/p/5522091060"headers = {'Host': 'tieba.baidu.com','User-Agent': cpn.user_agent_dict['chrome'],}pic_save_dir = 'output/Picture/BaiduTieBa/'pic_urls_file = 'tiezi_pic_urls.txt'download_q = queue.Queue() # 下载队列# 获得页数def get_page_count():try:resp = requests.get(tiezi_url, headers=headers, timeout=5)if resp is not None:soup = cpn.get_bs(resp.text)a_s = soup.find("ul", attrs={'class': 'l_posts_num'}).findAll("a")for a in a_s:if a.get_text() == '尾页':return a['href'].split('=')[1]except Exception as e:print(str(e))# 下载线程class PicSpider(threading.Thread):def __init__(self, t_name, func):self.func = functhreading.Thread.__init__(self, name=t_name)def run(self):self.func()# 获得每页里的所有图片def get_pics(count):while True:params = {'pn': count,'ajax': '1','t': int(time.time())}try:resp = requests.get(tiezi_url, headers=headers, timeout=5, params=params)if resp is not None:soup = cpn.get_bs(resp.text)imgs = soup.findAll('img', attrs={'class': 'BDE_Image'})for img in imgs:cpn.write_str_data(img['src'], pic_urls_file)return Noneexcept Exception as e:passpass# 下载线程调用的方法def down_pics():global download_qwhile not download_q.empty():data = download_q.get()download_pic(data)download_q.task_done()# 下载调用的方法def download_pic(img_url):while True:proxy_ip = {'http': 'http://' + cpn.get_dx_proxy_ip(),'https': 'https://' + cpn.get_dx_proxy_ip()}try:resp = requests.get(img_url, headers=headers, proxies=proxy_ip, timeout=5)if resp is not None:print("下载图片:" + resp.request.url)pic_name = img_url.split("/")[-1]with open(pic_save_dir + pic_name, "wb+") as f:f.write(resp.content)return Noneexcept Exception as e:passif __name__ == '__main__':cpn.is_dir_existed(pic_save_dir)print("检索判断链接文件是否存在:")if not cpn.is_dir_existed(pic_urls_file, mkdir=False):print("不存在,开始解析帖子...")page_count = get_page_count()if page_count is not None:headers['X-Requested-With'] = 'XMLHttpRequest'for page in range(1, int(page_count) + 1):get_pics(page)print("链接已解析完毕!")headers.pop('X-Requested-With')else:print("存在")print("开始下载图片~~~~")headers['Host'] = 'imgsa.baidu.com'pic_list = cpn.load_list_from_file(pic_urls_file)threads = []for pic in pic_list:download_q.put(pic)for i in range(0, len(pic_list)):t = PicSpider(t_name='线程' + str(i), func=down_pics)t.daemon = Truet.start()threads.append(t)download_q.join()for t in threads:t.join()print("图片下载完毕")
运行结果:
接着在和UI妹子聊天的时候就可以拿这些表情来斗图了,但是问题来了,
总共有165个图,我每次想说什么都要打开图片一个个看文字是否
符合场景,然后才发,有点呆,而且浪费时间,有没有什么快点
找到表情的方法呢?
答:直接把表情里的文字作为图片名不就好了,直接文件搜索搜关键字;
但是问题又来了,一张张去改文件名?多呆哦!
突然想起之前看过一篇头脑王者答题辅助脚本的文章,就是
利用OCR文字识别,把识别出来的文字丢百度上搜索,选项频度最高
的一般就是正确答案,可以试一波这个套路,谷歌为我们提供了一个
免费的ORC文字识别引擎:Tesseract
仓库地址:https://github.com/tesseract-ocr/tesseract
1.装一波环境
稳定版本是3.0,4.0版本还处于研发,一开始以为新版的肯定牛逼
一些,装了4.0的发现对于中文的识别效率超低,差太远了,后来
又换回了3.0版本,情况稍微好一些,当然可以通过其他方法提高
中文识别率,图片裁剪,调节对比度,黄底黑字,自己训练语言库等,
不是本节的学习范畴,本节写个简单的例子了解下怎么用而已~
更多可移步到:ubuntu下使用Tesseract-ocr(编译、安装、使用、训练新的语言库)
各个版本介绍:https://github.com/tesseract-ocr/tesseract/wiki/ReleaseNotes
Ubuntu 14.04 环境安装(其他系统环境后续用到再补充...)
1.安装tesseract-ocr
sudo apt-get install tesseract-ocrtesseract --version
2.安装pytesseract与Image
sudo pip install pytesseractsudo pip install Image
3.下载tesseract中文简体字库
默认安装后是不带中文简体库的,官方仓库走一波:
https://github.com/tesseract-ocr/tessdata
记得选择版本Tag,3.0的tesseract-ocr是用不了4.0的字库的!!!
如果你下错了,调用的时候会报3.0用不了4.0的字库的错误!!!
这两个就是对应中文简体与繁体:
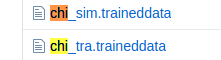
字库下载后需要放到下面的目录下:/usr/share/tesseract-ocr/tessdata
然后你发现字库文件无法拷贝到该目录下,因为需要权限,这里可以通过
命令行拷贝一波:
sudo cp '/home/jay/下载/chi_sim.traineddata' /usr/share/tesseract-ocr/tessdata
前面是源文件,后面是拷贝到哪个目录下。
好了,到此就准备完成了,接着写个简单的程序来识别一波!
2.识别一波图片
代码忒简单,创建一个Image对象,调用下pytesseract.image_to_string()方法
就能识别文字了,参数依次是Image对象,识别语言类型,chi_sim中文简体
import pytesseractfrom PIL import Imageimage = Image.open('1.png')text = pytesseract.image_to_string(image, lang='chi_sim')print(text.replace(" ", ""))
随手截一波掘金首页的分类栏:

运行一波:

识别结果有点感人,调一张表情图试试:

识别结果:

???都识别出来什么东西,后面试了几张图片我还发现不止识别
错误,有时连字都识别不出来...在不自己去训练字体库的情况下,
中文识别率真心感人,不过最大的有点优点还是:Tesseract免费。
识别数字或者英语的时候,还凑合,随手复制一段英文:

设置下lang='eng',输出结果:

免费的识别率低,试试收费的怎样,百度云OCR
3.试试百度云OCR
收费,每天免费500次,拿来完成我们这个图片命名的小脚本足矣!
官方文档:文字识别 - Python SDK文档
配置流程:
1.开通文字识别服务:https://cloud.baidu.com/product/ocr.html
2.创建一个应用,然后记下API Key 和 Secret Key 程序里要用

3.点右上角->用户中心,抄下自己的用户ID

4.pip命令安装一波
sudo pip install baidu-aip
编写简单代码:
from aip import AipOcr# 新建一个AipOcr对象config = {'appId': 'XXX','apiKey': 'YYY','secretKey': 'ZZZ'}client = AipOcr(**config)# 读取图片def get_file_content(file_path):with open(file_path, 'rb') as fp:return fp.read()# 识别图片里的文字def img_to_str(image_path):image = get_file_content(image_path)# 调用通用文字识别, 图片参数为本地图片result = client.basicGeneral(image)# 结果拼接返回if 'words_result' in result:return '\n'.join([w['words'] for w in result['words_result']])if __name__ == '__main__':print(img_to_str('1.png'))
试试上面掘金的那个,输出结果:

啧啧,可以的,试试搞基那个表情?
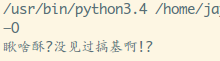
嗯,还是有点小错误,在文档里找到:

把basicGeneral 改为 basicAccurate,结果:
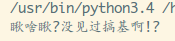
啧啧,完美识别,稍微慢了一点点,接下来把代码完善下,
把所有的图片重命名一波咯!
4.实战:利用百度OCR识别自动修改文件名
遍历文件夹,获得所有的图片路径,然后文字识别一波,获得结果集
里长度最长的字符串作为文件名,能识别的就修改下文件名,完整代码
如下:
import osfrom aip import AipOcr# 新建一个AipOcr对象config = {'appId': 'XXX','apiKey': 'YYY','secretKey': 'ZZZ'}client = AipOcr(**config)pic_dir = r"/home/jay/图片/BaiduTieBa/"# 读取图片def get_file_content(file_path):with open(file_path, 'rb') as fp:return fp.read()# 识别图片里的文字def img_to_str(image_path):image = get_file_content(image_path)# 调用通用文字识别, 图片参数为本地图片result = client.basicGeneral(image)# 结果拼接返回words_list = []if 'words_result' in result:if len(result['words_result']) > 0:for w in result['words_result']:words_list.append(w['words'])file_name = get_longest_str(words_list)print(file_name)os.rename(image_path, pic_dir + str(file_name).replace("/", "") + '.jpg')# 获取字符串列表中最长的字符串def get_longest_str(str_list):return max(str_list, key=len)# 遍历某个文件夹下所有图片def query_picture(dir_path):pic_path_list = []for filename in os.listdir(dir_path):pic_path_list.append(dir_path + filename)return pic_path_listif __name__ == '__main__':pic_list = query_picture(pic_dir)if len(pic_list) > 0:for i in pic_list:img_to_str(i)
运行结果:
要注意一点,高精度版免费只有50次,我一开始不知道,后面跑程序
突然卡住一直不动,这点要注意,后面还是用回了普通模式,所以有
些文件名并不完全是对的,就调调API的事,非常简单,项目有极大
刚需要用到文字识别的自行去官网了解吧~
5.小结
本节简单的了解了一下pytesseract这个免费的OCR识别库,
对于中文的识别率不高,后面试了下百度云OCR,顺道写了
一个简单的实战项目,都比较简单,那么本节就到这里啦~

来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

