@coder-pig
2020-11-05T08:45:04.000000Z
字数 2499
阅读 2029
Python爬虫 | 0x5 - Chrome抓包详解
Python爬虫教程
抓包(Packet Capture):将网络传输发送与接收的数据包进行截获、重发、编译、转存等操作,也用来检查网络安全。
——摘自《百度百科-抓包》
简单点说:抓取客户端与远程服务器间通信时传递的数据包。
本节带着读者学习一波入门抓包工具——Chrome开发者工具的使用,此工具为Chrome浏览器内置,没安装此浏览器的请自行下载安装。
1、打开开发者工具
Windows下可按F12、Ctrl+Shift+I、点击浏览器右上角更多工具打开:
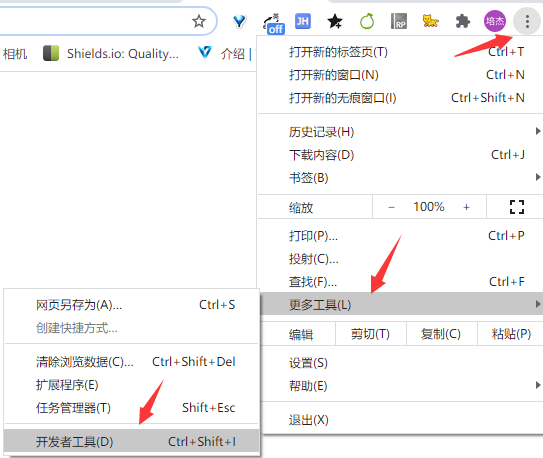
也可以在页面元素上右键选择检查(Inspect)打开。
2、工具结构
打开后开发工具页面如下:

结构依次为:
- Elements → 元素面板,当前网页结构,编写爬虫分析抓取结点时会用到,而且可以实时修改页面内容,改成自己想要的效果,一个很常用的小技巧:把密码输入框type属性从password改为text,就可以看到明文密码了。
- Console → 控制台面板,记录开发者开发过程中的日志信息,或使用它作为Shell,在页面上与JavaScript交互。
- Sources → 源代码面板,可在此断点调试JavaScript。
- Network → 网络面板,从发起网页页面请求Request后分析HTTP请求后得到的各个请求资源信息(如状态、资源类型、大小,耗时等),web开发者常根据此进行网络性能优化。
- Performance → 性能面板,使用时间轴面板,可记录查看网站生命周期内发生的各种事件,可根据此面板对页面运行时性的性能优化。
- Memory → 内存面板,查看web应用或页面的执行时间及内存使用情况。
- Application → 应用面板,记录网站加载的所有资源信息,包括存储数据(Local Storage、Session Storage、IndexedDB、Web SQL、Cookies)、缓存数据、字体、图片、脚本、样式表等。
- Security → 安全面板:判断当前网页是否安全,调试混合内容问题、证书问题等。
- Lighthouse → 性能分析工具,分析手机网页性能指标并提供对开发者最佳实践的意见。点击Generate report即可生成报告,需要科学上网,不然会一直卡在"lighthouse is warming up...",也可以单独安装Chrome插件Lighthouse。
抓包的话,主要关注Network选项卡,它由下图所示的四类窗格组成:
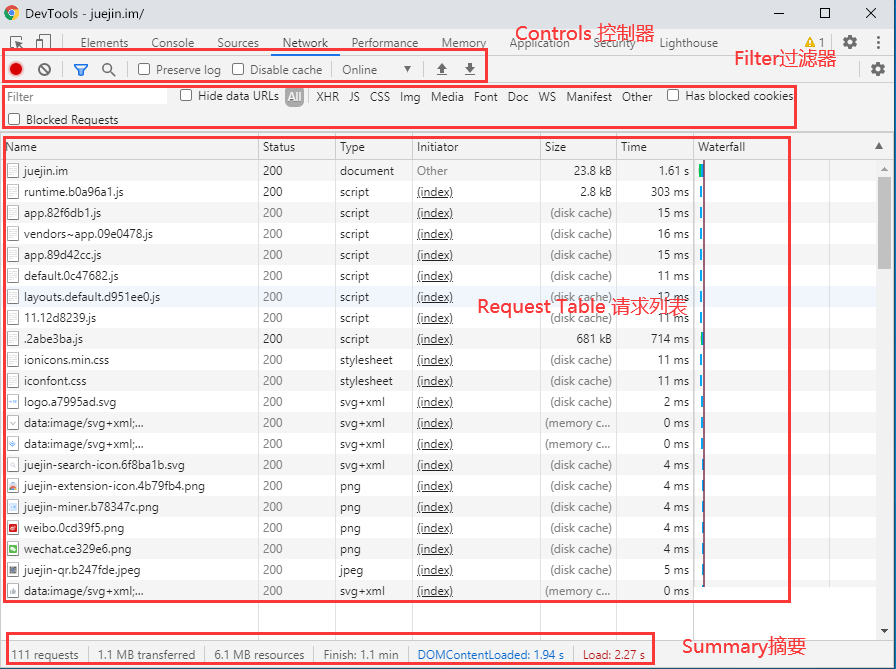
下面一一介绍下~
Control(控制器)
图标及对应描述如下所示:
 → 记录资源请求;
→ 记录资源请求; → 清空信息;
→ 清空信息; → 自定义筛选条件,只显示符合条件的请求;
→ 自定义筛选条件,只显示符合条件的请求; → 查找所需的资源信息;
→ 查找所需的资源信息; → 保存日志;
→ 保存日志; → 禁用缓存;
→ 禁用缓存; → 限流控制,模拟处于各种网络环境下的不同用户访问本页面的情况;
→ 限流控制,模拟处于各种网络环境下的不同用户访问本页面的情况; → 导入/导出HAR文件;
→ 导入/导出HAR文件;
Tips:HAR(HTTP Archive),HTTP档案规范,基于Json,用来存储HTTP请求/响应信息的通用文件格式。使用这种格式导出的数据可被其他支持HAR的HTTP分析工具(Fiddler,Httpwatch等)使用。
Filter(过滤器)
可在Filter输入框处输入过滤条件,比如:method:GET,只会显示Get请求方式的请求,常用指定条件如下表所示:
| 指定条件 | 描述 |
|---|---|
| domain | 资源所在的域,即url中的域名部分,如domain:coderpig.cn |
| has-response-header | 资源是否存在响应头,无论其值是什么,如 has-response-header: Access-Control-Allow-Origin |
| is | 当前时间点在执行的请求,当前可用值:running |
| larger-than | 显示大于指定值大小规格的资源,单位是字节(B),但是K(kB)和M(MB) 也是可以的,如larger-than:150K |
| method | 使用何种HTTP请求方式,如GET方式 |
| mime-type | 也写作content-type,是资源类型的标识符。如text/html |
| scheme | 协议,如HTTPS |
| set-cookie-name | 服务器设置的cookies名称 |
| set-cookie-value | 服务器设置的cookies的值 |
| set-cookie-domain | 服务器设置的cookies的域 |
| status-code | HTTP响应头的状态码 |
而后跟着过滤不同类型的资源,按住ctrl/control点击,可以选择多个过滤器,可搭配Filter输入框一起使用。
Requests Table(请求列表)
请求列表对应字段及描述如下所示:
- Name → 资源名称及URL路径;
- status → Http状态码;
- Type → 请求资源的MIME类型;
- Initiator → 解释请求是怎么发起的;
- size → 响应头部和响应体结合的大小;
- Time → 响应时间;
- Waterfall → 瀑布流,当某个资源耗时较长时,可看到时间都花到哪里去了;
点击其中一个请求打开:

右侧顶部有五个选项卡,依次为:
- Headers:请求URL、请求方法、响应码、请求头、响应头等;
- Preview:预览面板,资源预览,如html,json,html等;
- Response:响应信息面板,包含资源还未进行格式处理的内容;
- Cookies:请求用到的Cookies内容;
- Timing:资源请求的详细信息花费时间;
编写爬虫时一般先看Headers选项卡,看下请求需用到的请求头,请求参数等,然后在看Response选项卡返回的数据查看要解析的结点。
另外,还可以右键,对请求仅限复制、保存,或者清除:

有点多,就不一一介绍了,读者可以自己试试。
其他
① 底下的Summary(摘要)是记录请求站点耗时,资源等,没太大作用就不详细介绍了。
② 还有Overview(概览),默认是关闭的,可以点击右上角的设置,勾选Show overview:

此图表显示的是检索资源的时间轴,如果看到多个垂直堆叠,意味着这些资源时同时检索的。
③ 按住Shift并移动鼠标到资源上,可以查看它的发起者和依赖关系。
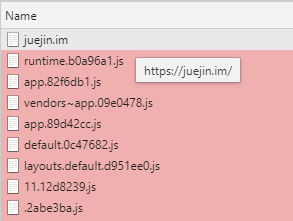
红色资源为当前请求的依赖,绿色为依赖此资源的请求。
小贴士:可在浏览器键入 chrome://about 查看Chrome浏览器中所有的地址命令~
