@coder-pig
2018-04-17T13:23:38.000000Z
字数 10970
阅读 2686
小猪的Python学习之旅 —— 16.再尝Python数据分析:采集拉勾网数据分析Android就业行情
Python
一句话概括本文:
爬取拉钩Android职位相关数据,利用numpy,pandas和matplotlib对招人公司
情况和招聘要求进行数据分析。
引言:
在写完上一篇《浅尝Python数据分析:分析2018政府工作报告中的高频词》,
一直都处于一种亢奋的状态,满脑子都想着数据分析,膜一下当然很开心,
更重要的是感受到了Python数据分析的好玩,迫不及待地想写个新的东西玩玩,
这不,给我翻到一个好玩的东西:《Python拉钩数据采集与可视化》
就是采集拉钩上关于Python岗位的相关信息,然后做数据分析,通过
图表的形式把分析结果展示给别人看;在我潜水的很多个Android群里
普遍有这样的反馈:尽管是现在是招聘的金三银四,但是Android的工作
真不好找?原因是Android岗位稀缺?要求过高?薪资问题?又或者其他
因素,我决定通过Python来采集相关数据,利用numpy,pandas,matplotlib
数据分析基础三件胡乱分析一波:

试图从分析结果中获取点什么有用的信息,以便了解方便自己更好的了解
市场行情,不逼逼,开始本节内容~

1.知道下数据分析三件套
在开始之前你可能需要大概了解下这三个库:numpy,pandas和matplotlib,
数据分析必备三件套,考虑如果要把文档吃透需要不少时间,还有文章篇幅
等原因,这里不慢慢去啃了,后续可能会写单独的教学章节,本节给出相关
的参考链接,有兴趣可先行自己研究~
书:《Python for Data Analysis, 2nd Edition》

PDF下载:Python for Data Analysis, 2nd Edition.pdf
中文翻译:利用Python进行数据分析·第2版
numpy库:
科学计算基础包,为Python提供快速的数组处理能力,
作为在算法和库之间传递数据的容器。
NumPy是在在一个连续的内存块中存储数据,独立于其他Python内置对象。
NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它
前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
学习链接:
pandas库:
提供了快速便捷处理结构化数据的大量数据结构和函数,有两种数据
常见的数据结构,分别为:Series (一维的标签化数组对象)和
DataFrame (面向列的二维表结构)
学习链接:
- 十分钟上手pandas:http://pandas.pydata.org/pandas-docs/stable/10min.html
- 更多内容:http://pandas.pydata.org/pandas-docs/stable/cookbook.html#cookbook
matplotlib库
用于绘制图表和其它二维数据可视化的Python库
学习链接:
2.数据爬取
打算分析一波深圳区的,打开首页https://www.lagou.com/
进去后选择深圳站,搜索栏输入 android点进去后,发现有30页:
随手点下一页,页面没有整个刷新,基本都是Ajax了,
F12开发者选项,打开抓包,Network选项卡clear一下,
选中XHR,点下一页,哟,有两个:

点击preview看下具体的json内容:
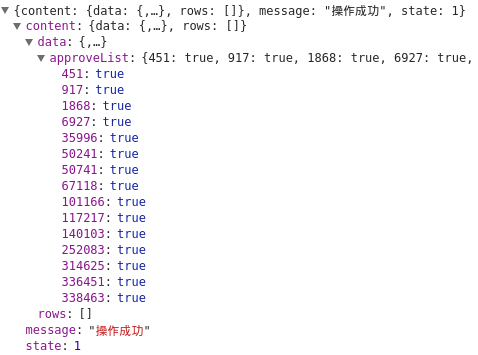
不知道是什么东西,随手复制个451,然后切换到Element搜索,

哟,原来是公司id,拼接下可以获得一个跳到公司详细信息的url,
这里暂时没用,approve,译作认证,就是认证公司id列表,
跟着一个true,猜测是企业是否认证的标识,可能是页面上
不显示未认证企业或者显示不一样的UI吧,接着看下一个接口:
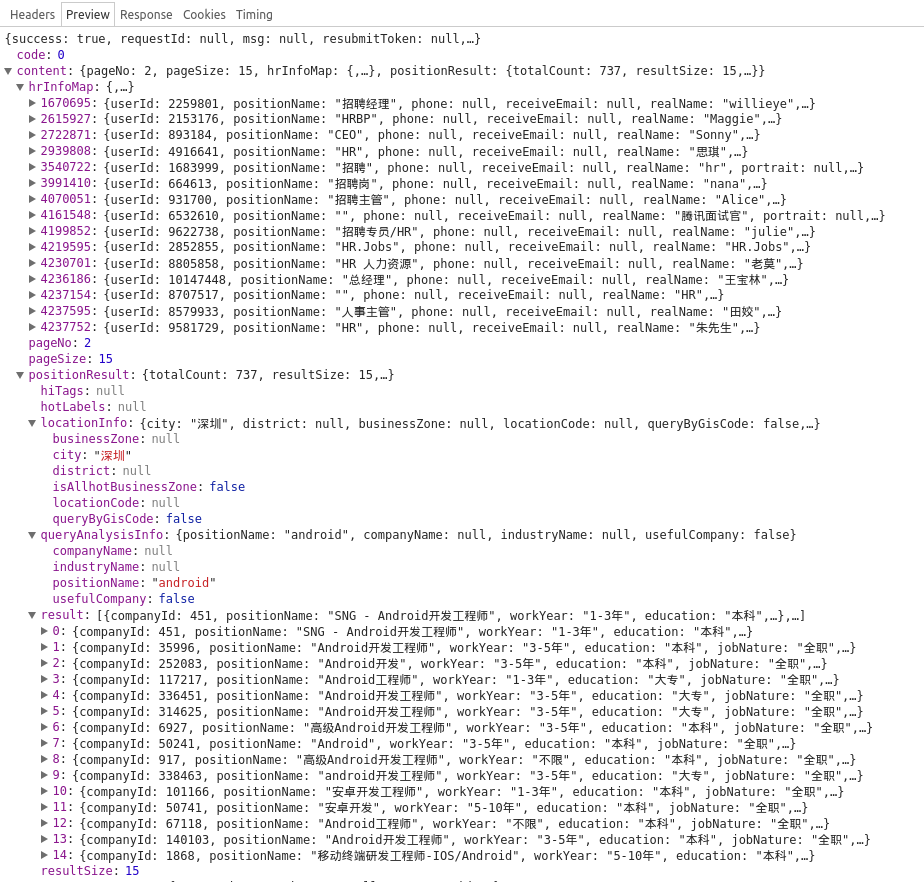
明显就是我们想Get的数据,hrInfoMap字段是和HR相关的信息,没用
跳过,最下面的result数组则是我们最关注的招聘信息了,点开一个
确认下:

知道了要爬哪里的数据,接着就是到怎么模拟请求了:
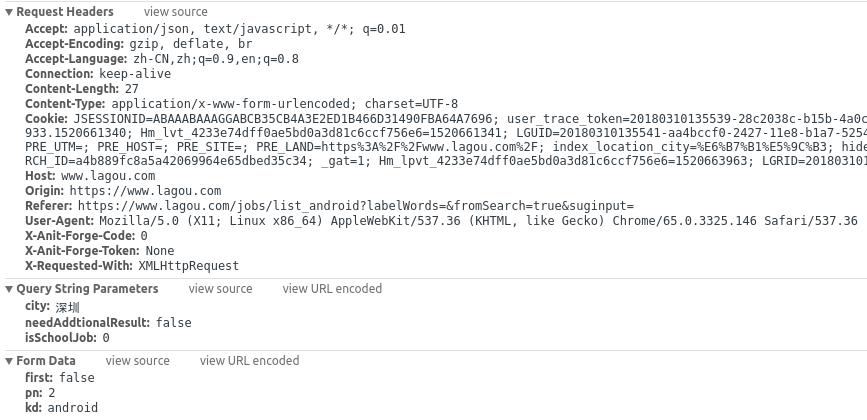
先是请求头,因为没登录就可以访问了,Cookies就不用传了,
其他的能带上就带上,多了也没什么,然后是链接后面附带
的参数,固定的不用改:
- city: 深圳
- needAddtionalResult: false
- isSchoolJob: 0
然后是Post提交的表单数据:
- first: false
- pn: 2
- kd: android
pn是页码,其他的都不用动!都清楚了,接着就写下代码
模拟下了,流程都一清二楚了,不难写出下面的代码:
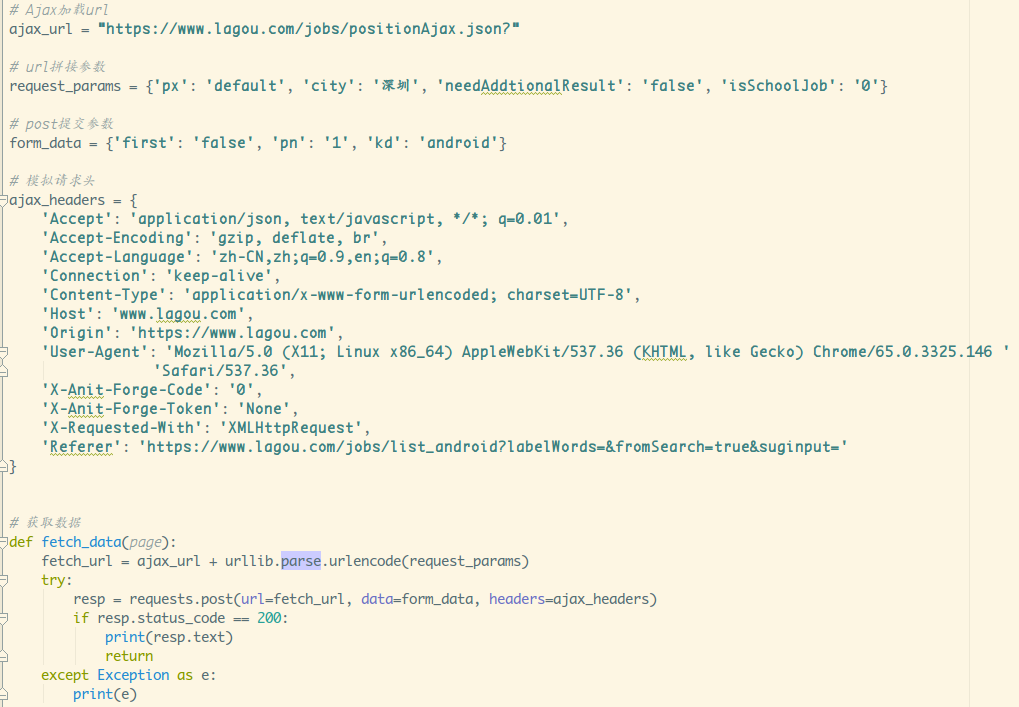
执行下,把结果贴到Json格式化工具里:
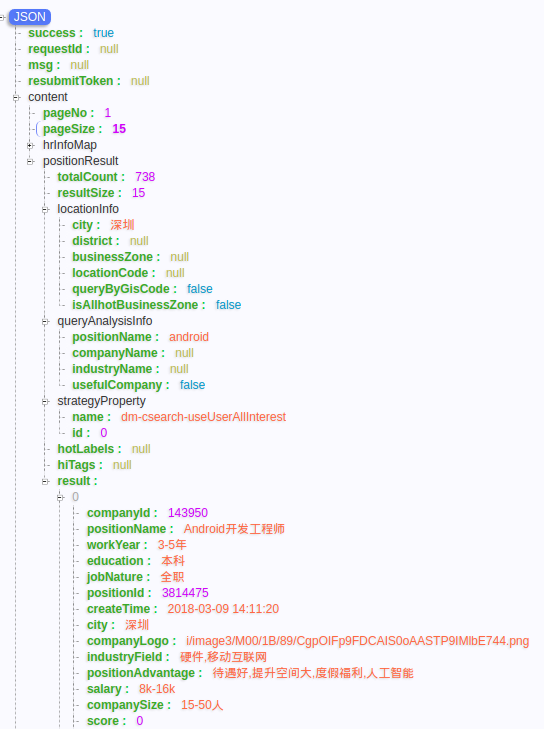
可以,另外这里还有个点可以get以下,就是总共有多少页,总共有738条数据,
每页显示15个,738/15=49,测了下确实是最后一页!
接着捋一捋想要采集的字段:
公司id,招聘岗位id,公司全名,招聘职位名,工作年限,
学历,性质,行业领域,公司优势, 薪资范围,公司规模,
技能标签,融资状态,公司标签,所在区域,公司经度,
公司纬度
因为我自己买的代理很多都是连接超时或者拒绝连接等各种问题,
所以直接用本机ip爬,随机5-15s避免ip被封,趁着去吃饭的空档,
让他自己慢慢爬。一开始是打算写正则来抠数据的,按照返回的
Json结构,我试着写了这样的正则:

运行后,看到爬取了4,5页没什么问题,于是乎安心去吃饭了,后来
发现部分数据都乱套了,原来是有些页面的Json字段顺序不一样,我服...

还是回归Json按照字段取稳妥,手动抠字段,拼成一个列表,
最后塞一个数组里,最后通过pandas库的to_csv()方法转换
为一个列表。
3.用pandas的to_csv方法把数据都塞Excel里
代码如下:

执行完后会在当前工程下生成一个result.csv文件,打开检查下数据是否
都正确,处理下脏数据,发现有五个数据位置是错乱的:
依次查看错乱的原因:
Android高级开发工程师 最新iMAC 双休 待遇丰厚 Android系统&移动开发经理 (Android &移动App开发工程师(Android&
这里简直是巨坑,上面的 和&是Html里的转义字符,需要调用
html.unescape()方法转义一波,对应相反的方法escape()
当爬取的内容是字符串的时候要小心这个坑!!!修改后的代码:
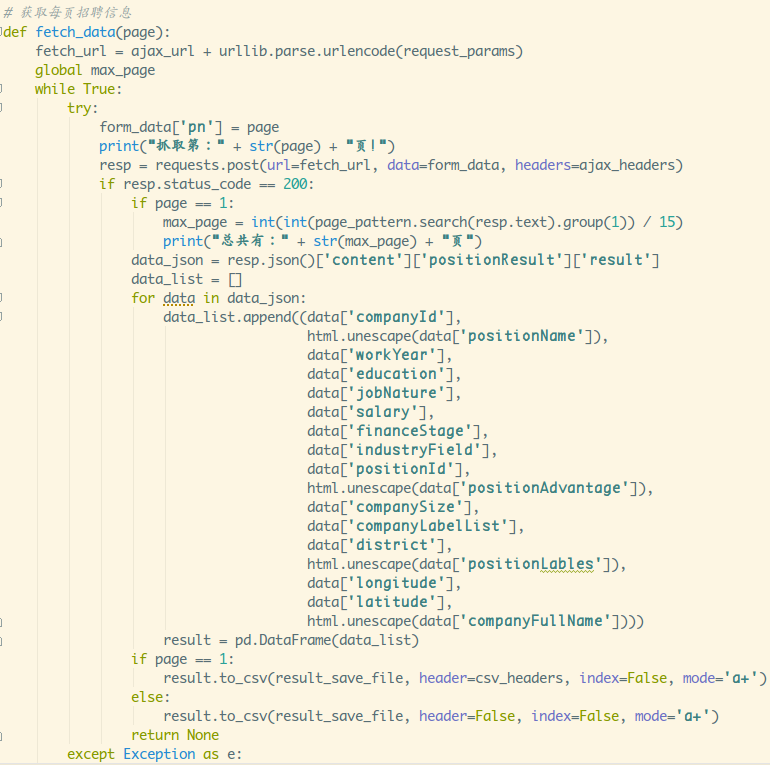
总共采集到736条数据,不算多,但也可以开始做数据分析了。
4.数据分析前可能遇到的一些问题
1)matplotlib中文乱码问题
主要使用条形图,饼图和词云来展示数据分析结果!
使用matplotlib进行图标绘制,基本都会遇到的一个问题,中文乱码,
解决流程如下:


打开终端,cd到路径下,然后准备一枚中文ttf,接着命令行sudo mv
把ttf文件拷贝到该路径下:

接着双击安装,安装后修改配置文件,对如图三处做相应修改:
修改完毕后,执行下述命令删除一波缓存文件

接着再运行就可以了:
其他系统处理matplotlib中文乱码问题自行参见:matplotlib图例中文乱码
2)matplotlib绘制显示不全
如图所示,在绘制的时候可能会出现显示不全的情况:
顺道介绍下按钮,依次是:
重置回主视图,上一步视图,下一步视图,拖拽页面,
局部放大,设置,保存成图片
然后的话,可以点下设置,会出现:
拖拉调整下,直到差不多能显示完全
接着记录下对应的参数,代码中设置下:

5.开始数据分析
一.分析招聘公司的一些情况
行业领域

从词云可以看出,Android招聘大部分还是移动互联网公司,接着依次是金融,
硬件,电子商务,电子商务?都是干嘛的,利用pandas做下简单筛选,

随手搜了几个百度下,这种从事电子商务大概是:
电商(有自己的购物APP,平台),外包,支付,POS机等
接着是游戏,数据服务,企业服务,o2o等等。
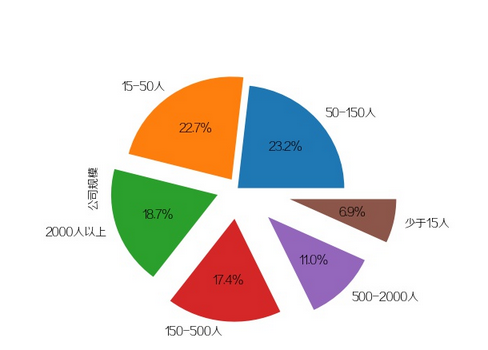
公司规模
融资状态
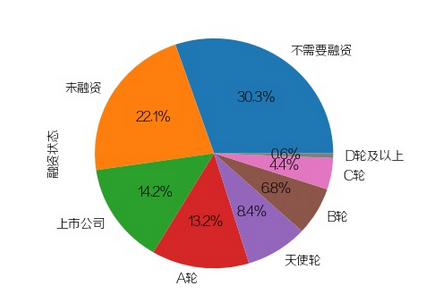
PS:卧槽,15-50人和未融资公司的百分比竟然异常接近,应该大部分都是
小型的创业公司吧,基本都很坑...
所在区域
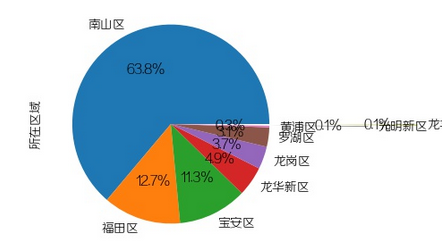
大部分招Android的公司还是集中在南山区,其次是福田区和宝安区,
小部分在龙华新区和龙岗区。
公司标签
看下公司都打着怎么样的标签招人

公司优势

和上面一个样,假如你公司要你写招聘条件的时候,就不愁写什么啦~
二.分析对招聘者的一些要求
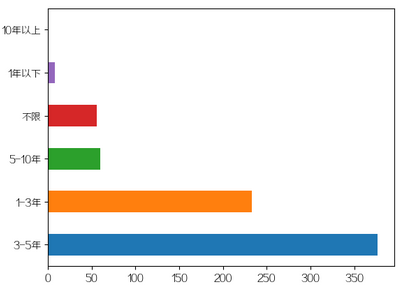
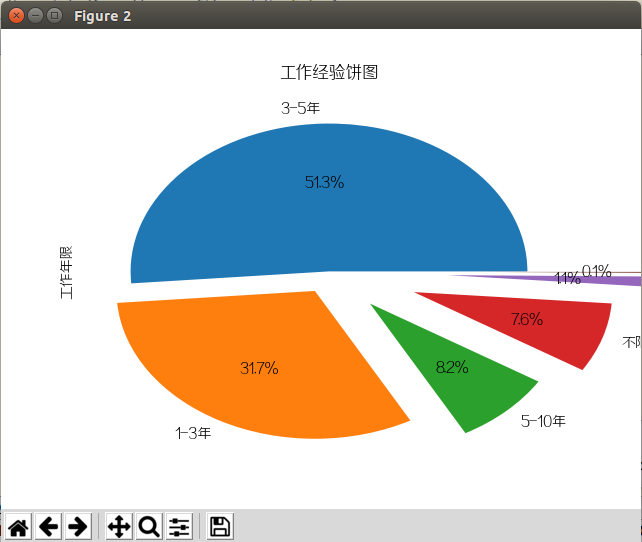
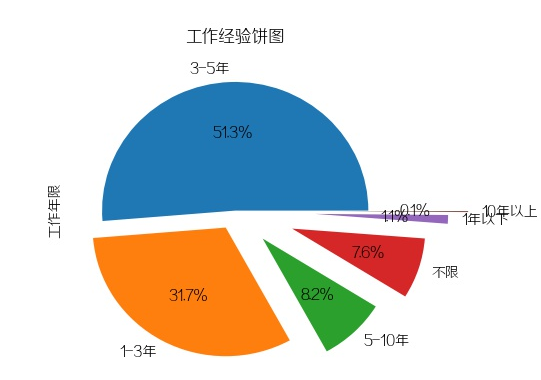
工作年限
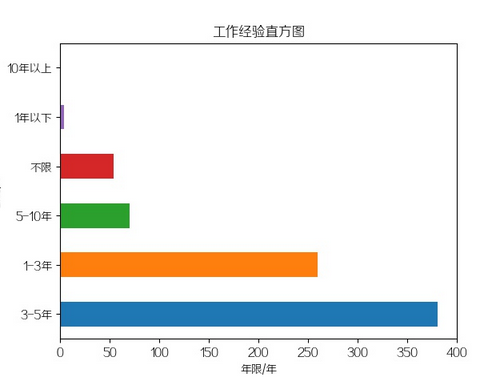
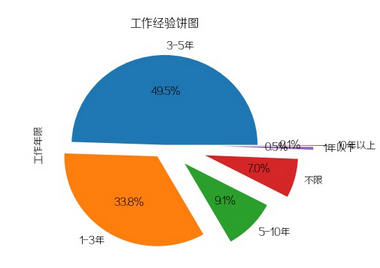
招最多的是3-5年工作经验,其次是1-3年,再接着是5-10年
学历要求
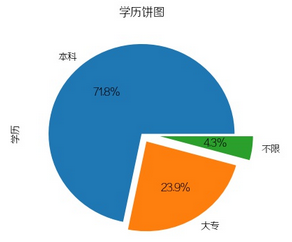
以前以为学历不重要,然而图中本科要求占比71.8%,没有本科学历意味着:
可能失去七成的机会,哭哭/(ㄒoㄒ)/~~,我这种渣渣还是继续当咸鱼吧...
薪资情况
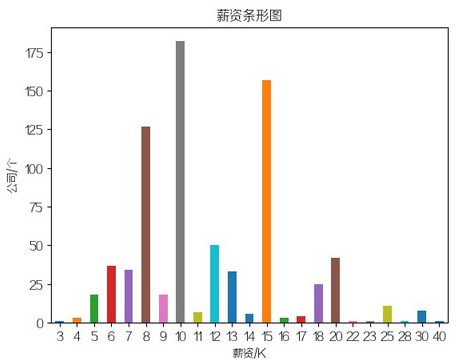
拉钩标的薪酬都是有个范围的,其实一般最小值就是你实际进公司后的
薪资,直接以最小值作为参考,图中明显的三个小高峰,10k,15k,8k。
猜测对应:
10k - 3年经验左右的一般的中初级工程师
15k - 3-5年经验的技术较好的中高级工程师
8k - 1到3年内的初中级工程师
当然土豪公司不在范围内,看完自己找工作的时候开口要多少钱,
心里应该有点B数啦。(哭哭,又拖后腿了/(ㄒoㄒ)/~~)
技能标签

Java, iOS,架构,C++,系统开发,中级,高级,资深,视频,信息安全...

要求Java我能理解,这要求iOS是什么鬼?现在找个Android岗都要会iOS了?
后来才发现并没那么夸张,只是招聘职位那里Android/iOS,所以才有iOS
的标签,还有些瞎几把填的标签,进去招聘要求里一个iOS的字眼也没有。

到此就分析完啦~
6.小结
本节依次抓取了一波拉勾网和Android职位相关的数据,利用这些数据对
公司情况和招聘要求进行了分析,通过图表以及词云的形式,尽管没有
得出非常有用的信息,不过应该也get了不少东西,上上周周一就立flag
出的,结果因为项目发新版本,自己感冒凉了几天,一直拖到现在...
因为篇幅和时间关系,有两个遗憾:Jupyter Notebook 和 geopandas,
前者是用作数据可视化展示的一个很强大的工具,而后者则是生成
地图类的一个库,还记得我们采集到的经纬度么?弄一个类似于热力
图的东东不是很酷么?学习成本有点高,后面再了试试吧!
附:最终代码(都可以在:https://github.com/coder-pig/ReptileSomething 找到):

# 拉勾网Android招聘数据分析import urllib.parseimport requestsimport xlwtimport xlrdimport tools as timport pandas as pdimport geopandas as gpimport reimport randomimport timeimport htmlimport matplotlib.pyplot as pltimport numpy as npfrom wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorfrom collections import Counterfrom scipy.misc import imreadimport config as cfrom shapely.geometry import Point, Polygonmax_page = 1result_save_file = c.outputs_logs_path + 'result.csv'pic_save_path = c.outputs_pictures_path + 'LaGou/'default_font = c.res_documents + 'wryh.ttf' # 生成词云用的默认字体default_mask = c.res_pictures + 'default_mask.jpg' # 默认遮罩图片# Ajax加载urlajax_url = "https://www.lagou.com/jobs/positionAjax.json?"# url拼接参数request_params = {'px': 'default', 'city': '深圳', 'needAddtionalResult': 'false', 'isSchoolJob': '0'}# post提交参数form_data = {'first': 'false', 'pn': '1', 'kd': 'android'}# 获得页数的正则page_pattern = re.compile('"totalCount":(\d*),', re.S)# csv表头csv_headers = ['公司id', '职位名称', '工作年限', '学历', '职位性质', '薪资','融资状态', '行业领域', '招聘岗位id', '公司优势', '公司规模','公司标签', '所在区域', '技能标签', '公司经度', '公司纬度', '公司全名']# 模拟请求头ajax_headers = {'Accept': 'application/json, text/javascript, */*; q=0.01','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Host': 'www.lagou.com','Origin': 'https://www.lagou.com','User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 ''Safari/537.36','X-Anit-Forge-Code': '0','X-Anit-Forge-Token': 'None','X-Requested-With': 'XMLHttpRequest','Referer': 'https://www.lagou.com/jobs/list_android?labelWords=&fromSearch=true&suginput='}# 获取每页招聘信息def fetch_data(page):fetch_url = ajax_url + urllib.parse.urlencode(request_params)global max_pagewhile True:try:form_data['pn'] = pageprint("抓取第:" + str(page) + "页!")resp = requests.post(url=fetch_url, data=form_data, headers=ajax_headers)if resp.status_code == 200:if page == 1:max_page = int(int(page_pattern.search(resp.text).group(1)) / 15)print("总共有:" + str(max_page) + "页")data_json = resp.json()['content']['positionResult']['result']data_list = []for data in data_json:data_list.append((data['companyId'],html.unescape(data['positionName']),data['workYear'],data['education'],data['jobNature'],data['salary'],data['financeStage'],data['industryField'],data['positionId'],html.unescape(data['positionAdvantage']),data['companySize'],data['companyLabelList'],data['district'],html.unescape(data['positionLables']),data['longitude'],data['latitude'],html.unescape(data['companyFullName'])))result = pd.DataFrame(data_list)if page == 1:result.to_csv(result_save_file, header=csv_headers, index=False, mode='a+')else:result.to_csv(result_save_file, header=False, index=False, mode='a+')return Noneexcept Exception as e:print(e)# 生成词云文件def make_wc(content, file_name, mask_pic=default_mask, font=default_font):bg_pic = imread(mask_pic)pic_colors = ImageColorGenerator(bg_pic)wc = WordCloud(font_path=font, background_color='white', margin=2, max_font_size=250,width=2000, height=2000,min_font_size=30, max_words=1000)wc.generate_from_frequencies(content)wc.to_file(file_name)# 数据分析方法(生成相关文件)def data_analysis(data):# 1.分析招聘公司的相关信息# 行业领域industry_field_list = []for industry_field in data['行业领域']:for field in industry_field.strip().replace(" ", ",").replace("、", ",").split(','):industry_field_list.append(field)counter = dict(Counter(industry_field_list))counter.pop('')make_wc(counter, pic_save_path + "wc_1.jpg")# 公司规模plt.figure(1)data['公司规模'].value_counts().plot(kind='pie', autopct='%1.1f%%', explode=np.linspace(0, 0.5, 6))plt.subplots_adjust(left=0.22, right=0.74, wspace=0.20, hspace=0.20,bottom=0.17, top=0.84)plt.savefig(pic_save_path + 'result_1.jpg')plt.close(1)# 融资状态plt.figure(2)data['融资状态'].value_counts().plot(kind='pie', autopct='%1.1f%%')plt.subplots_adjust(left=0.22, right=0.74, wspace=0.20, hspace=0.20,bottom=0.17, top=0.84)plt.savefig(pic_save_path + 'result_2.jpg')plt.close(2)# 所在区域plt.figure(3)data['所在区域'].value_counts().plot(kind='pie', autopct='%1.1f%%', explode=[0, 0, 0, 0, 0, 0, 0, 1, 1.5])plt.subplots_adjust(left=0.31, right=0.74, wspace=0.20, hspace=0.20,bottom=0.26, top=0.84)plt.savefig(pic_save_path + 'result_3.jpg')plt.close(3)# 公司标签tags_list = []for tags in data['公司标签']:for tag in tags.strip().replace("[", "").replace("]", "").replace("'", "").split(','):tags_list.append(tag)counter = dict(Counter(tags_list))counter.pop('')make_wc(counter, pic_save_path + "wc_2.jpg")# 公司优势advantage_list = []for advantage_field in data['公司优势']:for field in advantage_field.strip().replace(" ", ",").replace("、", ",").replace(",", ",").replace("+", ",") \.split(','):industry_field_list.append(field)counter = dict(Counter(industry_field_list))counter.pop('')counter.pop('移动互联网')make_wc(counter, pic_save_path + "wc_3.jpg")# 2.分析招聘需求# 工作年限要求# 横向条形图plt.figure(4)data['工作年限'].value_counts().plot(kind='barh', rot=0)plt.title("工作经验直方图")plt.xlabel("年限/年")plt.ylabel("公司/个")plt.savefig(pic_save_path + 'result_4.jpg')plt.close(4)# 饼图plt.figure(5)data['工作年限'].value_counts().plot(kind='pie', autopct='%1.1f%%', explode=np.linspace(0, 0.75, 6))plt.title("工作经验饼图")plt.subplots_adjust(left=0.22, right=0.74, wspace=0.20, hspace=0.20,bottom=0.17, top=0.84)plt.savefig(pic_save_path + 'result_5.jpg')plt.close(5)# 学历要求plt.figure(6)data['学历'].value_counts().plot(kind='pie', autopct='%1.1f%%', explode=(0, 0.1, 0.2))plt.title("学历饼图")plt.subplots_adjust(left=0.22, right=0.74, wspace=0.20, hspace=0.20,bottom=0.17, top=0.84)plt.savefig(pic_save_path + 'result_6.jpg')plt.close(6)# 薪资(先去掉后部分的最大工资,过滤掉kK以上词汇,获取索引按照整数生序排列)plt.figure(7)salary = data['薪资'].str.split('-').str.get(0).str.replace('k|K|以上', "").value_counts()salary_index = list(salary.index)salary_index.sort(key=lambda x: int(x))final_salary = salary.reindex(salary_index)plt.title("薪资条形图")final_salary.plot(kind='bar', rot=0)plt.xlabel("薪资/K")plt.ylabel("公司/个")plt.savefig(pic_save_path + 'result_7.jpg')plt.close(7)# 技能标签skill_list = []for skills in data['技能标签']:for skill in skills.strip().replace("[", "").replace("]", "").replace("'", "").split(','):skill_list.append(skill)counter = dict(Counter(skill_list))counter.pop('')counter.pop('Android')make_wc(counter, pic_save_path + "wc_4.jpg")# 处理数据if __name__ == '__main__':t.is_dir_existed(pic_save_path)if not t.is_dir_existed(result_save_file, mkdir=False):fetch_data(1)for cur_page in range(2, max_page + 1):# 随缘休息5-15stime.sleep(random.randint(5, 15))fetch_data(cur_page)else:raw_data = pd.read_csv(result_save_file)# data_analysis(raw_data)# 筛选电子商务公司dzsw_result = raw_data.loc[raw_data["行业领域"].str.find("电子商务") != -1, ["行业领域", "公司全名"]]dzsw_result.to_csv(c.outputs_logs_path + "dzsw.csv", header=False, index=False, mode='a+')# 筛选人15-50人的公司p_num_result = raw_data.loc[raw_data["所在区域"] == "龙华新区", ["所在区域", "公司全名"]]p_num_result.to_csv(c.outputs_logs_path + "lhxq.csv", header=False, index=False, mode='a+')
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

