@coder-pig
2019-02-26T10:03:39.000000Z
字数 10163
阅读 2023
偷个懒,公号抠腚早报80%自动化——4.用Flask搭个简易(陋)后台
2019
简述
在上一节「偷个懒,公号抠腚早报80%自动化——3.Flask速成大法」中,快速地把
Flask的基本语法撸了一遍,本节直接开冲,用Flask来写下抠腚男孩的后台。

PS:笔者没有真正参加过前后端开发,此文都是现学现卖,你可以理解成小白文章,
有错的地方,还望海涵,批评或建议欢迎在评论区留言,谢谢~

1、从业务逻辑中提炼API接口
先捋下整个业务流程吧
- 1.早上定时8点执行爬虫脚本爬取新闻(删表建新表)。
- 2.查询当日爬取到的新闻,把觉得有意思的新闻添加到筛选池中。
- 3.对筛选池中的新闻进行二次筛选,在这一步可以新增或者修改筛选池新闻。
- 4.取筛选池中的前15条早报,附上日期插入日报池中。
- 5.传入日期,通过模板生成微信群文字版。
- 6.传入日期,通过模板生成微信公众号版。
- 7.传入日期,通过模板生成新闻详情列表页。

(PS:下述部分可以直接跳过,不过我还是建议看看概念性的东西)
① 业务逻辑思维导图
抽象出业务逻辑,把相同的东西先放一起,然后通过思维导图的形式表现出来。
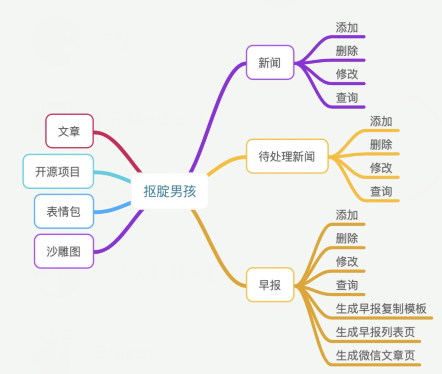
② 功能——业务逻辑思维导图
「业务逻辑」和「功能模块」呈现的内容结合,一个model对应多个业务逻辑。
模块的划分依据:功能与业务的关系,功能和功能间不能有关系,功能尽可能实现一对多。
笔者的项目过于简单,图跟业务逻辑思维导图差不了多少,直接略过。
③ 基本功能模块关系
找出功能——业务逻辑思维导图中的对应关系,功能模块按照人和事来划分。
事不能理解为用户的行为,「事」就是单纯的事,不是用户行为,「人」就是用户,
「事」就是指事物,「事件」是人和事之间的关系。不能主动发出请求的都归属于事。
你去星巴克喝咖啡 = 事件 = 人和事之间的关系。事是事物,不是事件,我给你发短信,
你接收短信,这是两个事件。
- 我是人,短信是事物,我发短信是事件
- 你是人,短信是事物,你收短信是事件
如果商家能主动发起请求,那就是人,即一个东西具备主动性,它就是人。
(这里的人之间没有啥关联,所以没有线~)

④ 功能模块接口UML(设计API)
只考虑功能模块,设计接口去解决问题,注意耦合把控,太高不能拆分,太低失去化模块意义。

目前所需的API就上面这些,后面按需扩展即可。
2、手撕API接口——前
① 项目结构
先是项目的结构,直接使用上一节说的简单通用的结构:
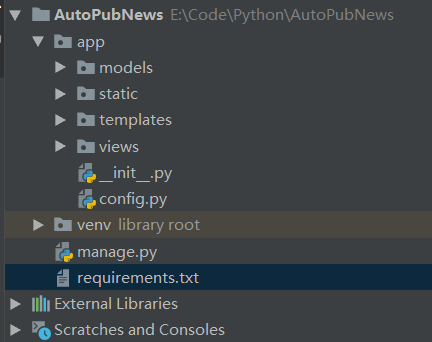
结构简述:
- app:整个项目的包目录。
- models:数据模型。
- static:静态文件,css,JavaScript,图标等。
- templates:模板文件。
- views:视图文件。
- config.py:配置文件。
- venv:虚拟环境。
- manage.py:项目启动控制文件。
- requirements.txt:项目启动控制文件。
② 定义数据模型
定义三种类型的数据:源新闻,筛选新闻、早报、字段大同小异,代码如下:
# models\news.pyfrom app import db__all__ = ['OriginNews', 'ChooseNews', 'MorningNews']class OriginNews(db.Model):__tablename__ = 'news_origin'__table_args__ = {"useexisting": True}id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.Text)url = db.Column(db.Text)create_time = db.Column(db.Text)def to_dict(self):return {"id": self.id, "title": self.title, "url": self.url, "create_time": self.create_time}class ChooseNews(db.Model):__tablename__ = 'news_choose'__table_args__ = {"useexisting": True}id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.Text)url = db.Column(db.Text)create_time = db.Column(db.Text)def to_dict(self):return {"id": self.id, "title": self.title, "url": self.url, "create_time": self.create_time}class MorningNews(db.Model):__tablename__ = 'news_morning'__table_args__ = {"useexisting": True}id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.Text)url = db.Column(db.Text)create_time = db.Column(db.Text)add_time = db.Column(db.Text)def to_dict(self):return {"id": self.id, "title": self.title, "url": self.url, "create_time": self.create_time,"add_time": self.add_time}
③ 编辑config.py文件
添加sqlalchemy相关的配置,如下:
SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root:Jay12345@127.0.0.1:3306/news'SQLALCHEMY_TRACK_MODIFICATIONS = True
④ app目录下创建__init__.py文件
在这里完成Flask,SQLAlchemy对象的实例化,以及相关数据库的创建:
from flask import Flaskfrom flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)app.config.from_object('config')db = SQLAlchemy(app)from app.models.news import *db.create_all()
⑤ 创建视图
从业务逻辑思维导图那里就知道,不只是做早报,还有表情包,沙雕图等,为了
便于后面方便扩展,利用蓝图来分离模块。直接在views目录下创建一个news.py。
# 创建蓝图ns = Blueprint('news', __name__)# flask实例注册蓝图app.register_blueprint(ns, url_prefix='/news')
视图文件创建,现在大部分的接口返回的数据都是Json字符串,如果每次返回数据都要
我们自行去拼接字符串,显得过于繁琐,可以包装下jsonify,把字典类型的数据直接
转换成Json字符串返回。代码如下:
class JsonResponse(Response):@classmethoddef force_type(cls, response, environ=None):if isinstance(response, dict):response = jsonify(response)return super(JsonResponse, cls).force_type(response, environ)app.response_class = JsonResponse
约定下返回的Json数据格式:
{"code":"200","msg":"请求成功","data":[]}
3、手撕API接口——中
准备工作做的差不多了,接着开始着手编写API接口,分几类进行编写,先是和数据库增删改查有关的:
① 数据库增删改查相关的接口
# 查询新闻,判断是否传入nid来判断是单条查询还是多条,# kind为表序号:1来源表,2筛选表,3早报表@ns.route("/show", methods=['GET'])def news_show():req_args = request.argsif 'kind' in req_args:kind = int(req_args['kind'])# 如果有nid参数,说明是查询单条,否则是查询全部if 'nid' in req_args:nid = request.args['nid']if kind == 1:news = OriginNews.query.filter_by(id=nid).first()elif kind == 2:news = ChooseNews.query.filter_by(id=nid).first()elif kind == 3:news = ChooseNews.query.filter_by(id=nid).first()else:return make_response({'code': '200', 'msg': '无效的kind参数', 'data': []})return make_response({'code': '200', 'msg': '请求成功', 'data': news.to_dict()})else:if 'count' in req_args and 'page' in req_args:count = int(req_args['count'])page = int(req_args['page'])news_list = []if kind == 1:for n in OriginNews.query.filter().offset(page * count).limit(count):news_list.append(n.to_dict())elif kind == 2:for n in ChooseNews.query.filter().offset(page * count).limit(count):news_list.append(n.to_dict())elif kind == 3:for n in MorningNews.query.filter().offset(page * count).limit(count):news_list.append(n.to_dict())else:return make_response({'code': '200', 'msg': '无效的kind参数', 'data': []})return make_response({'code': '200', 'msg': '请求成功', 'data': news_list})else:return make_response({'code': '200', 'msg': '缺少count或page参数', 'data': []})else:return make_response({'code': '200', 'msg': '缺少kind参数', 'data': []}# 查询新闻条数# kind为表序号:1来源表,2筛选表,3早报表@ns.route("/<int:kind>/count", methods=['GET'])def news_count(kind):if kind == 1:count = OriginNews.query.filter().count()elif kind == 2:count = ChooseNews.query.filter().count()elif kind == 3:count = MorningNews.query.filter().count()else:return make_response({'code': '201', 'msg': '错误的参数类型', 'data': []})resp = make_response({'code': '200', 'msg': '请求成功', 'data': {'count': count}})return resp# 删除某条新闻,传入参数nid代表新闻id# kind为表序号:1来源表,2筛选表,3早报表@ns.route("/destroy", methods=['DELETE'])def news_delete():req_args = request.formif 'kind' in req_args:kind = int(req_args['kind'])if 'nid' in req_args:nid = int(req_args['nid'])if kind == 1:news = OriginNews.query.filter_by(id=nid).first()db.session.delete(news)db.session.commit()elif kind == 2:db.session.delete(ChooseNews.query.filter_by(id=nid).first())db.session.commit()elif kind == 3:db.session.delete(MorningNews.query.filter_by(id=nid).first())db.session.commit()else:return make_response({'code': '200', 'msg': '无效的kind参数', 'data': []})return make_response({'code': '200', 'msg': '请求成功', 'data': []})else:return make_response({'code': '200', 'msg': '缺少mid 参数', 'data': []})else:return make_response({'code': '200', 'msg': '缺少kind参数', 'data': []})# 更新筛选池里的新闻(有的更新,没的插入)@ns.route("/update", methods=['POST'])def add_news():req_args = request.formif 'news' in req_args:news_dict = json.loads(req_args['news'])news = ChooseNews.query.filter_by(id=news_dict['nid']).first()# 没有数据是插入,有数据是修改if news is None:news = ChooseNews()news.id = news_dict['nid']news.title = news_dict['title']news.url = news_dict['url']news.create_time = news_dict['create_time']db.session.add(news)db.session.commit()return make_response({'code': '200', 'msg': '插入成功', 'data': []})else:news.id = news_dict['nid']news.title = news_dict['title']news.url = news_dict['url']news.create_time = news_dict['create_time']db.session.commit()return make_response({'code': '200', 'msg': '更新成功', 'data': []})else:return make_response({'code': '200', 'msg': '缺少news参数', 'data': []})# 把筛选池的新闻插入到日报池中(限制15条)@ns.route("/insert_morning", methods=['POST'])def add_morning_news():for n in ChooseNews.query.filter().limit(15):n_dict = n.to_dict()morning_news = MorningNews()morning_news.id = n_dict.get('id')morning_news.title = n_dict.get('title')morning_news.url = n_dict.get('url')morning_news.create_time = n_dict.get('create_time')morning_news.add_time = time.strftime("%Y%m%d")db.session.add(morning_news)db.session.commit()return make_response({'code': '200', 'msg': '请求成功', 'data': []})
② 启动爬虫的接口
需要通过命令行来启动爬虫,爬虫的执行比较耗时,而Flask的服务默认是同步的。
只有爬虫执行完毕才会响应客户端,显然是非常不合理的。这里用线程池来实现
最简单的异步操作,请求后直接响应,后台去执行爬虫。
executor = ThreadPoolExecutor(max_workers=2)# 执行新闻爬虫def spider():os.system("python PenpaiSpider.py")os.system("python WeiboSpider.py")print("爬虫执行完毕...")# 执行爬取新闻的爬虫@ns.route("/spider", methods=['GET'])def run_spider():os.system("python DBHelper.py")executor.submit(spider)return make_response({'code': '200', 'msg': '请求成功', 'data': []})
③ 生成微信转发文字的接口
就是简单的字符串拼接:
# 生成复制模板文本@ns.route("/show_copy_model", methods=['GET'])def show_copy_model():req_args = request.argsif 'date' in req_args:date = req_args['date']text_model = "『抠腚早报速读』| 第%s期\n\n要闻速读\n\n" % date[2:]news = MorningNews.query.filter_by(add_time=date).all()for i in range(len(news)):text_model += str(i + 1)text_model += "、%s。\n\n" % news[i].titlereturn make_response({'code': '200', 'msg': '请求成功', 'data': text_model[:-1]})else:return make_response({'code': '200', 'msg': '缺少date参数', 'data': []})
④ 公众号文章编辑复制样式的接口
就是微信公号编写文章时的内容,利用flask内置的jinja2模板来动态生成。这里有一点要注意:
render_template()函数虽然返回的是html,但是请求接口后浏览器显示的是HTML代码而非HTML
页面,而且还有乱码。这里需要在响应头中把「content-type」设置为「text/html; charset=utf-8」。
但是问题来了,笔者对于前端一窍不通(从我写的新闻列表页就知道了...)一个最简单的做法就是打开
浏览器的开发者工具,复制下网页源码,调整下代码以及排版,找出每天新闻对应的代码,利用
循环来构造,抽取后的部分html代码如下:
{% for i in news_list %}<p style="max-width: 100%; min-height: 1em;"><br></p><p style="max-width: 100%; min-height: 1em;">{{loop.index}}、{{i.title}}。</p>{% endfor %}
接着在视图函数中为模板传入新闻信息,动态生成页面:
# 生成微信复制模板@ns.route("/create_wc_model", methods=['GET'])def show_wc_model():req_args = request.argsif 'date' in req_args:date = req_args['date']news = MorningNews.query.filter_by(add_time=date).all()resp = make_response(render_template('news.html', news_list=news))resp.headers['content-type'] = 'text/html; charset=utf-8'return respelse:return make_response({'code': '200', 'msg': '缺少date参数', 'data': []})
⑤ 新闻列表详情页的接口
和上面那个一样玩法,定义模板news_list.html:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>『抠腚早报速读』| 第{{news_list[0].add_time[2:]}}期</title></head><body>{% for news in news_list %}<div style="height: 48px"><a href="{{news.url}}" target="_blank" style="color:black;text-decoration:none;">{{loop.index}}、{{news.title}}</a></div>{% endfor %}</div></body></html>
同样在意图中传入新闻信息:
# 生成新闻列表页@ns.route("/create_news_list", methods=['GET'])def show_news_list():req_args = request.argsif 'date' in req_args:date = req_args['date']news = MorningNews.query.filter_by(add_time=date).all()resp = make_response(render_template('news_list.html', news_list=news))resp.headers['content-type'] = 'text/html; charset=utf-8'return respelse:return make_response({'code': '200', 'msg': '缺少date参数', 'data': []})
⑥ 异常处理
对应常见的404和500错误,直接返回不好,这里简单的处理下。
@app.errorhandler(404)def error_404(e):return make_response({'code': '404', 'msg': '404错误', 'data': []})@app.errorhandler(500)def error_404(e):return make_response({'code': '500', 'msg': '500错误', 'data': []})
4、手撕API接口——后
行吧,API接口编写完毕,接着用PostMan模拟下请求:
增删改查的结果就不演示了,只展示早报复制文本,公号编辑,以及新闻详情列表页接口的请求结果,依次如下:


行吧,接着把项目部署到服务器上,怎么部署在上一节《偷个懒,公号抠腚早报80%自动化——3.Flask速成大法》
已经讲解过了,把代码传服务器上,安装配置nginx和uwsgi,配置完后,即可通过服务器公网ip进行访问。
当然你可以坐下域名解析,指向服务器,直接通过域名访问。(貌似个人域名备案变把以前严格了,前不久在腾讯云
备案一个域名,写的CoderPig的编程技术小站,客服说不能出现编程字眼,还有什么商业性的都不行~)
行吧,关于抠腚男孩的简陋后台,基本雏形就完成了,有些粗糙,又不是不能用。

( 顺带以此图,缅怀没有下个系统版本更新的坚果Pro 2S)后续根据需求,以及自己掌握更多
新的姿势后再来一点点优化把。

后续根据需求,还有自己掌握了更多的姿势再一点点优化把。下一节就是本系列的最后一节的了,手撕一个APP来调这些接口,敬请期待~
参考文献:
- 《App后台开发运维和架构实践》曾健生 编著——中的2.1 从App业务逻辑中提炼API接口。
Tips:公号目前只是坚持发早报,在慢慢完善,有点心虚,只敢贴个小图,想看早报的可以关注下~

