@coder-pig
2018-04-02T03:54:27.000000Z
字数 3095
阅读 2749
小猪的Python学习之旅 —— 8.爬虫实战:刷某博客站点的访问量
Python
引言:
Python并发的文章还在肝,比较乏味,写个爬虫小脚本玩玩,想起之前
在某博客站点看到,一个人发布的渣渣文章,半个小时不到2W访问量,
还连续几篇都是,然后一个留言或者点赞的都没有,比较多人看的鸿洋
的博客,一篇文章挂了3个月也才1w3的访问量,想想都知道是爬虫刷的,
小猪顿时正义感作祟,忍不住向他们的客服进行了举报,然而石沉大海,
并没有得到任何的回复,不禁感叹,时过境迁,物是人非,唉...

最近偶尔有次点出了排行版,看到了这样的东西???

卖优惠券的都没人管了...卧槽,这还能忍,这样对得起那些
辛辛苦苦肝出一篇技术文章的大佬和萌新吗?

刷访问量脚本谁不会写,而且这个博客站点不用登录就算一次
访问量,写个无限循环,然后换着ip去访问博客就行了。
具体的流程:
- 1.抓取你博客所有的文章URL存起来;
- 2.准备一堆代理ip(西刺很多都不行,可以上网买5块2W个高匿代理ip);
- 3.while True:换着ip,随机访问自己的一篇文章;
是的,就是这么简单,没有任何反爬虫或者惩罚,之前那个人
已经大摇大摆的刷到每篇文章5W多访问量。所以我选择搬到掘金...
1.写一个自己的常用模块
在写简单爬虫的时候,有一些很常用的代码段,比如发起一个
请求,然后获得一个Response;下载图片;读写文件等,其实
都可以写到一个py文件里(有点像Android里的工具类),然后要
用到的时候调用下就可以了,使用的时候import下你的这个模块
然后就可以用了。比如小猪随手写的一个简易模块:

部分代码

这些都可以自己定制,这样你在写爬虫的时候就方便多了。
另外,小猪闲暇没事也会爬点小东西练练手,初学者可以也跟着
试试,相关脚本都丢到我的Gayhub上了,按需自取:
https://github.com/coder-pig/ReptileSomething

2.编写刷访问量脚本
Step 1:获取博客的所有链接
打开:http://blog.csdn.net/coder_pig?viewmode=list
滑动到底部,可以发现有这个东西,要做的就是拿到每一页的
url,然后处理页面拿到所有的文章链接都存起来,然后随手
点开第二页,发现url变成:
http://blog.csdn.net/zpj779878443/article/list/2
所以我们只需拿到总共有多少页就可以了,然后自行拼接URL:

浏览器f12打开Elements,Ctrl+f搜 尾页,直接就定位到了
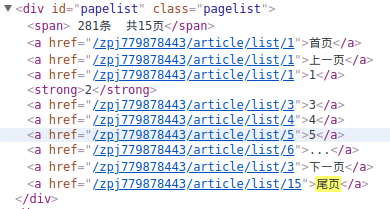
然后全局搜下这个papelist,发现也是唯一的,接下来好办
了,处理下href,拿到最后的页码:

接着就是看下每个列表页的页面结构,获取所有的文章url,
然后写入到一个文件里了:
就选我们刚刚打开的第二页吧,同样打开:Elements,随手
搜个:小猪浅谈Android屏幕适配,就可以定位到:
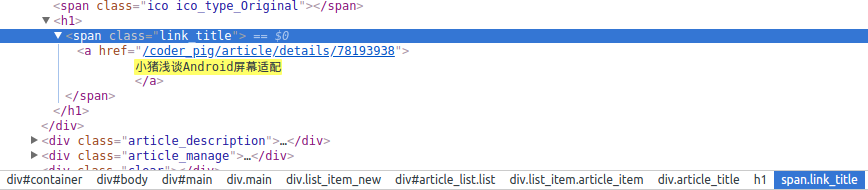
然后点结点,翻上去,不难找到:
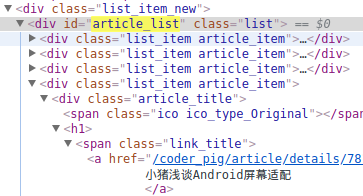
同样,搜下article_list,同样是唯一的,拿到这个div,然后
获取class='link_title'的span,然后拿到里面的a标签就可以了:

执行下这个方法,可以看到目录下生成了csdn_articles_file.txt
点开就可以看到我们所有文章的url了:

第一步完成~
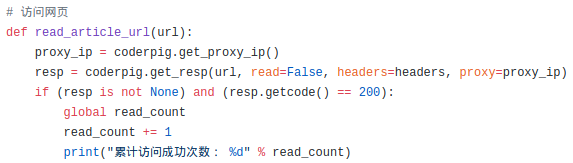
Step 2:访问网页
这里就非常简单了,换ip,然后给文章发起请求,你连read()
方法都不用执行,另外,这里还可以添加计数,当返回码为
200的时候,说明是一次顺利的访问,计数+1,代码很简单:
Step 3:执行代码
这里很简单,先判断文章列表文件是否存在,不存在遍历,
然后加载文件里所有的数据到列表,接着While无限循环,
然后random随机取出一个访问即可!
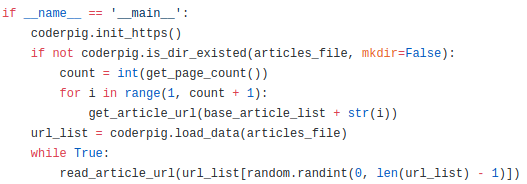
运行后开始计数就说明成功了,打开自己的博客页面放着
过一会在儿再刷新看看访问量是否增加了就知道了:

3.把脚本丢到服务器上跑
自己的电脑总不可能24小时开着是吧,费电,比如我一般下班
就会关电脑,如果想你的脚本可以24小时不间断运行,可以丢
到服务器上,一百来块就可以买个普通的玩玩了,有兴趣自行
百度阿里云,腾讯云虚拟主机之类的。
一般是通过ssh命令链接到我们的远程主机终端
ssh root@主机ip,然后输入下主机密码即可链接
然后你可以通过一些ftp工具把自己的脚本文件丢到
服务器上,然后ssh终端执行下python3 xxx.py就可以了。
但是有个问题是,如果你按了ctrl+c或者关闭了这个ssh终端
你的这个脚本就会停止!所以你需要以后台程序的方式执行
你的这个Python脚本,可以使用nobup命令。
键入这样的命令:
nohup python3 -u xxx.py > xxx.out 2>&1 &
解释下:
- nohup 和 最后的& 包着的就是让命令在后台执行,比如你直接
写nohup python3 xxx.py &就可以了 - > xxx.out 代表将输出信息输出到xxx.out日志文件中
- 2>&1 将信息变成标准输出,把错误信息也输入到日志文件中
0代表stdin,1代表stdout,2代表stderr
这样执行后,会返回一个pid(进程id):

然后你可以通过tail命令跟踪日志输出:
tail -f xxx.out
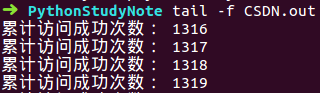
觉得跑得差不多了想停掉程序运行,只需执行下述命令把进程
杀掉,比如kill -9 19267
kill -9 pid
如果忘记了pid也没什么,可以通过下述命令找到:
ps -ef | grep python3

然后kill掉就可以了。另外上面那个执行了8:28分钟的就是
我昨晚睡觉前运行的脚本,tail看一波日志文件:
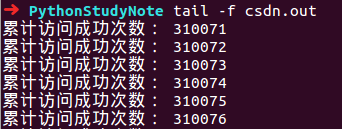
怒刷31W访问量,这个就不说了...
4.Python3 ssl模块找不到
把脚本丢服务器上,python3执行的时候一直安装不了ssl模块,
真是莫名其妙,pip3 install ssl,死命就是报错,后面搜了
下网上的资料, 先执行下面的两个命令装点东西:
apt-get install opensslapt-get libssl-dev
装上后还是不行,然后发现是要去改下python3文件夹里的
代码,然后重新make,cd到下面的路径,vim编辑Setup文件:
cd ../../usr/lib/python/Python-3.6.4/Modulesvim Setup
把对应这个部分的改成下述这个样子,然后esc,键入
:wq保存。
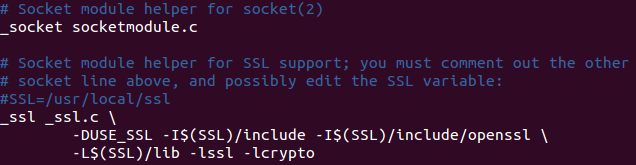
然后一次执行下述命令(如果最后名利提示权限不够,可在make前加-H)
cd ..sudo ./configuresudo makesudo make install
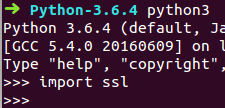
make完后,命令行键入python3,进入到python3 ide,import下ssl
没报错就说明安装成功了!
小结
本节学习了编写自己的模块,编写刷访问量脚本,以及如何把自己的
脚本丢到服务器上以后台程序的方式运行。

其实刷那么多的访问量又有什么用,写博客的初衷就是分享和记录
自己的学习历程,不知何时开始,我们开始热衷于追求所谓的阅读量,
点赞数,评论数,然后各种标题党,鸡汤...现在大多数的人对于短平
快结果立竿见影的事情趋之若鹜,而对需要沉下心长时间积淀的事却
避之而唯恐不及,这可能就是浮躁吧。
本节源码下载:
https://github.com/coder-pig/ReptileSomething
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

