@coder-pig
2023-04-14T02:38:38.000000Z
字数 19296
阅读 1407
一篇文章教你学废Git版本管理
2020
| Git概述 | ① 什么是版本管理系统 | ② Git和SVN的区别 |
| ③ Git的四个组成部分 | ④ Git中文件的几个状态 | |
| ⑤ Git中的四类对象 | ||
| Git下载安装配置 | ||
| Git本地基本操作 | ① 配置「git config」 | ② 获取帮助「git help」 |
| ③ 创建Git仓库「git init」 | ||
| ④ 添加文件到暂存区「git add」 | ||
| ⑤ 让Git不跟踪特定文件「.gitignore文件」 | ||
| ⑥ 暂存区内容提交到本地仓库「git commit」 | ||
| ⑦ 查看工作区与暂存区状态「git status」 | ||
| ⑧ 内容变化,差异对比「git diff」 | ||
| ⑨ 查看历史提交记录「git log」 | ||
| ⑩ 查看某个文件的改动记录「git blame」 | ||
| ⑪ 设置Git命令别名「git config --global alias」 | ||
| ⑫ 为重要提交打标签「git tag」 | ||
| Git文件恢复与版本回退 | ① 文件恢复,未add「git checkout」 | |
| ② 文件恢复,已add未commit「git reset HEAD」 | ||
| ③ 版本回退,已commit「git reset --hard」 | ||
| ④ 查看输入过的指令记录「git reflog」 | ||
| ⑤ 撤销某次提交「git revert」 | ||
| ⑥ 查看某次提交的修改内容「git show」 | ||
| ⑦ 查看分支最新commit的Hash值「git rev-parse」 | ||
| ⑧ 找回丢失对象的最后一点希望「git fsck」 | ||
| Git本地分支 | ① 分支的概念 | ② 创建其他分支的原因 |
| ③ 一个简单的分支管理策略 | ||
| ④ 分支的创建于切换「git branch」 | ||
| ⑤ 分支合并「git merge」 VS 「git rebase」 | ||
| ⑥ 解决合并冲突 | ⑦ 删除分支 | |
| ⑧ 恢复误删分支「git log --branches」 | ⑨ 分支重命名 | |
| ⑩ 切换分支时暂存未commit的更改「git stash」 | ||
| ⑪ 把commit从一个分支挪到另一个分支「git cherry-pick」 | ||
| Git远程仓库 | ① 远程仓库概述 | |
| ② 本地仓库与远程仓库建立关联「git remote」 | ||
| ③ 推送本地仓库到远程仓库「git push」 | ||
| ④ 克隆远程仓库「git clone」 | ||
| ⑤ 同步远程仓库更新「git fetch」VS「git pull」 | ||
| ⑥ git push 时的unrelated history问题 | ||
| ⑦ SSH Key避免每次push重复输入账号密码 | ||
| Git工作流 | ① 集中式工作流 | ② 功能分支工作流 |
| ③ Gitflow工作流 | ④ Forking工作流 | |
| ⑤ Pull Request工作流 | ||
| 其他杂项 | ① 为开源项目贡献代码 | ② SourceTree使用详解 |
0x1、Git概述——分布式版本控制系统
了解Git相关的概念,有助于后续命令的掌握~
1. 什么是版本管理系统
VCS(Version Control System),一种用于记录一个或多个文件内容变化
历史,以便将来能对特定版本的历史记录进行查看,更改,备份还原的系统。
可以简单类比为「游戏存档」,打Boss前存下档,没过关,重新读档;
分支剧情,想体验不同选择触发的不同剧情,可以存多个档, 想玩哪个读哪个。
VCS一般分为下述三类:
- 1.本地VCS
使用简单的数据库来记录文件的历史更新差异,比如RCS。
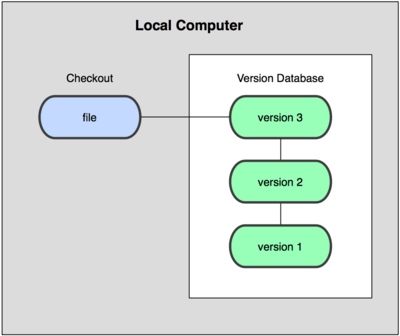
- 2.集中式VCS
用一个服务器来保存所有文件的修订版本,协同工作的人连接这个服务器,
获取或提交文件更新,比如SVN。
这种协同方式有个两个明显的缺点:
1.「需要联网」:同步和推送更新速度受带宽限制,内网还好,外网可能会有点慢了(大文件);
2.「依赖中央服务器」:每个人的本地只有以前所同步的版本,如果服务器宕(dang)机了,谁都无法获取或提交更新。
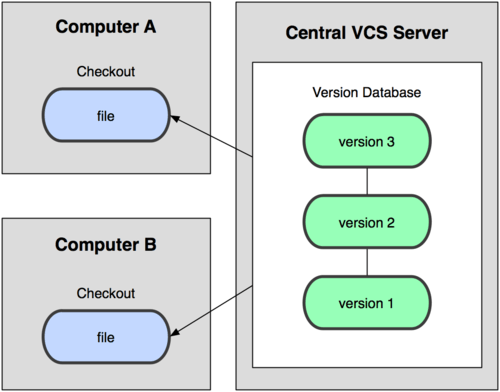
- 3.分布式VCS
每个用户拥有完整的提交历史,支持离线提交更改,查看历史提交记录等。中央服务器更多的只是用作更改合并,同步的工具,比如Git。
从根本上来说,Git是一个内存寻址的文件系统,根据文件的Hash值来定位文件。
这个40位的Hash值使用SHA1算法生成,由两部分拼接:
header = "<type>" + content.length + "\0"
(参数依次为:对象类型,数据字节长度,空字节(用于分隔header与content)
hash = sha1(header+content),这里的拼接是二进制级别的拼接,而非字符串拼接。

2. Git与SVN的区别
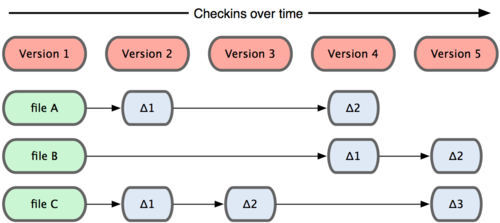
Git和SVN除了上面说的联网需求不同外,还有「存储差异」:
SVN关心:文件内容的具体差异;而Git关心:文件整体是否发生改变。
SVN每次提交记录的是:「哪些文件进行了修改,修改了哪些行的哪些内容」。
如图,Version 2中记录的是文件A和C的变化,而Version 3中记录文件C的变化,以此类推;
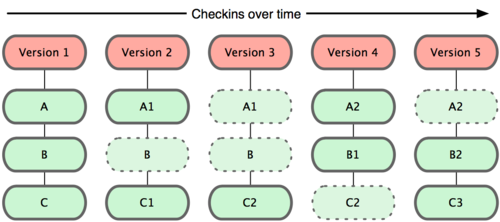
而Git中,并不保存这些前后变换的差异数据,而是保存整个缓存区中的所有文件,
又称快照,「有变化的文件保存,没变化的文件不保存,而是对上次保存的快照做一个链接」,
因为这种不同的保存方式,使得Git切换分支的速度比SVN快上不少。
当然SVN也有它的优点,比如「权限控制」,可以设定每个账户的读写权限,而Git中
则没有响应的权限控制。至于用哪个的,还是看公司要求吧~
3. Git的四个组成部分
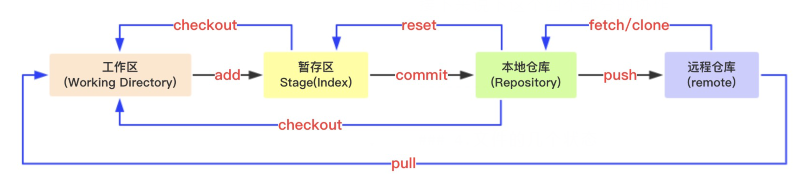
简单说下Git的四个组成部分:
- 工作区:不包含.git文件夹在内的整个项目目录,所有修改都在工作区内进行。
- 暂存区:又称索引区,本地文件修改后,执行add操作会把工作区的修改添加到缓存区。
- 本地仓库:当执行commit操作时,暂存区的数据被记录到本地仓库中。
- 远程仓库:托管项目代码的服务器,多人协作时通过远程仓库进行代码同合并与同步。
接下来说下这几个部分是如何协同工作的:
工作区与暂存区:工作区更改,通过git add命令可以把更改提交到暂存区;
也可以git checkout命令使用暂存区内容覆盖当前的工作区的内容。暂存区与本地仓库:可以通过git commit命令把暂存区的内容提交到本地仓库,
每次commit都会生成一个快照,快照使用Hash值编号。可以通过git reset Hash值,
把某个快照还原到暂存区中。工作区和本地仓库:通过git checkout 快照编号,直接把某个快照还原到工作区中。
本地仓库和远程仓库:可以通过git push命令把commit推送到远程仓库,多人协作的
时候可能还需要进行一些冲突处理;还有通过git clone拉取某个远程仓库的项目到本地,
或通过git fetch拉取远程仓库的最新内容,检查后决定是否合并到本地仓库中。工作区和远程仓库:这里两者的协作一般是git pull,即把远程主机的最新内容拉取下来后直接合并。
4. Git中文件的几个状态
按照大类划分,可以分为两种状态:Tracked(已跟踪)和Untracked(未跟踪),
依据是:「该文件是否已加入版本控制」?
文件状态变化周期流程图:
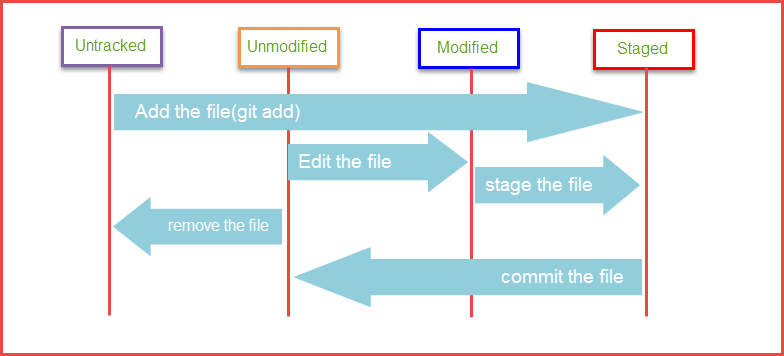
流程简述:
假设某个项目已加入Git版本控制系统
- 1.新建一个文件,该文件处于
Untracked状态;- 2.通过git add命令添加到缓存区,此时文件处于
Tracked状态又或者说
此时这个文件已经被版本控制系统所跟踪,而且他处于Staged(暂存)状态;- 3.通过git commit命令把暂存区的文件提交提交到本地仓库,此时文件处于
Unmodified(未修改)状态;- 4.此时如果去编辑这个文件,文件又会变成
Modified(修改)状态;
5. Git中的四类对象
在Git系统中有四种类型的对象,几乎所有的Git操作都是在这四种对象上进行的,依次为:
Blob(块)对象,Tree(树)对象,Commit(提交)对象,Tag(标签)对象。
前三者的关系如图所示:

接着我们来详解的讲解这四类对象:
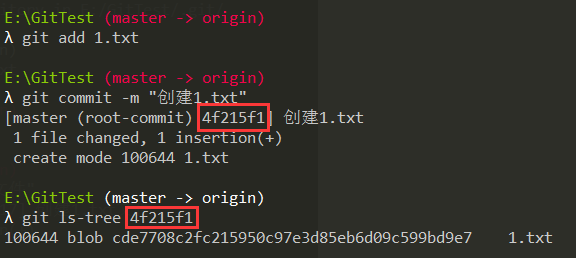
① 块对象(Blob)
一块二进制数据,「仅存放文件内容」,不包括文件名、权限等信息。Git会根据文件内容计算
出一个Hash值,以这个Hash值作为文件索引保存起来。意味着,相同文件内容的文件,只会保存
一个,即共享同一个Blob对象。可以使用:git hash-object 文件名来计算文件内容的Hash值。
如果你知道已经添加到Git中的某个文件的hash值,还可以通过git cat-file hash值来读取数据
对象,可选参数:-p(查看Git对象内容) ,-t(查看Git对象类型),示例如下:

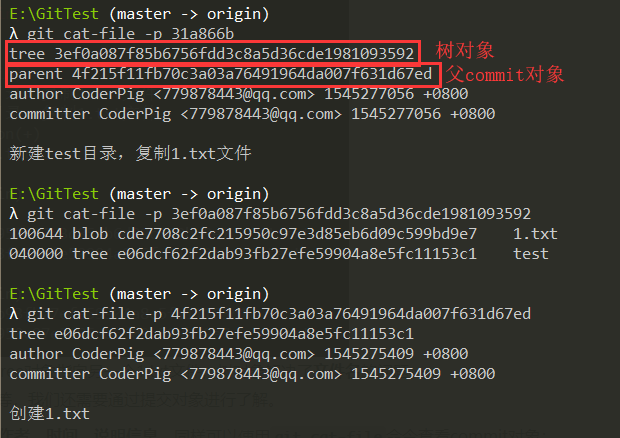
② 树对象(Tree)
保存一个或多个块对象的引用,每次commit对应一个树对象,这里生成一个commit,
然后调用git ls-tree Hash值查看树对象的内容:
利用上面的
git cat-file -p hash值来查看blob块的具体内容:
除了保存块对象的引用外,树对象还可以引用「其他树对象」,从而构成一个「目录层次结构」。
新建一个test目录,复制一个1.txt文件到这个路径下,提交一个commit,然后查看树对象的内容:
可以指向了另一个tree对象,这个tree对象指向另一个1.txt文件,树对象解决了文件名的问题。
而对于提交的人、时间、说明信息等,我们还需要通过提交对象进行了解。


③ 提交对象(Commit)
保存树对象的Hash值,父Commit的Hash值,提交作者、时间、说明信息。
同样可以使用git cat-file命令查看commit对象:
④ 标签对象(Tag)
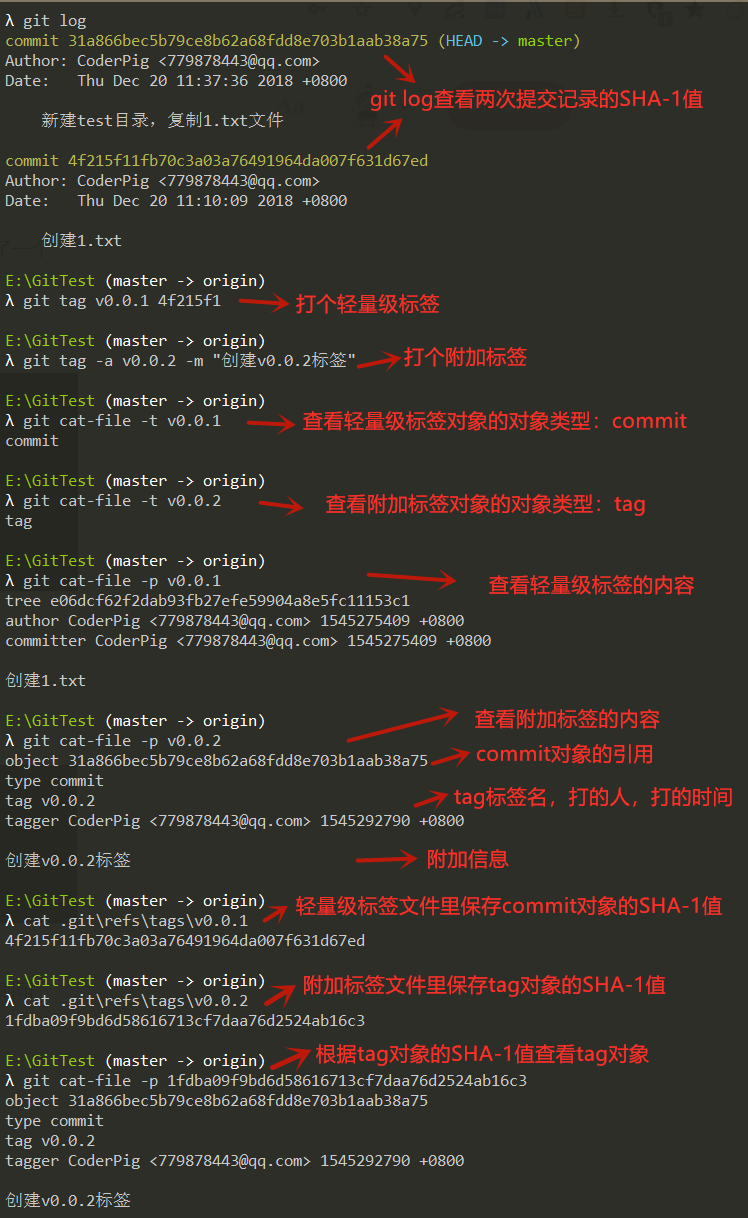
一般会对某次重要的commit加TAG,以示重要,分为两种情况:
- 轻量级标签:不会创建真正的TAG对象,而是直接引用commit对象的Hash值。
- 附加标签:会创建TAG对象,TAG对象中包含commit对象的引用,除此之外会创建
一个文件:.git/refs/tags/标签名,里面保存TAG对象的引用。这里为我们上面的两个commit一次打上两种标签,然后看下具体的结果:
0x2、Git下载安装配置
- Windows系统:到 Git For Windows 或 git-for-windows.github.io下载,傻瓜式下一步。
- Linux系统:到 Download for Linux and Unix 下载,如果是Ubuntu的话,直接Terminal键入:
sudo apt-get install git安装即可。 - Mac系统:到 Installing on Mac 下载,不过新系统貌似默认已经带有Git了,另外如果安装了
Homebrew的话可以直接命令行键入:brew install git进行安装。
0x3、Git本地基本操作
1. 相关配置「git config」
安装完后,使用Git还需要进行环境的配置,配置信息保存在gitconfig文件中,有三种级别:
- system(系统):系统中所有用户都会生效,配置文件:
C:\Program Files\Git\mingw64\etc\gitconfig,
不同的系统可能不一样,你可以通过:git config -e --system,底部可以找到配置文件的路径:

- global(全局):当前系统用户下生效,配置文件:
C:/Users/当前用户/.gitconfig,
同样可以采用上面的:git config -e --global查看配置文件的位置。 - local(本地):配置仅在当前项目生效,配置文件:
项目路径/.git/config
配置生效优先级:local > global > system,常用命令:
# 配置git config --global user.name "用户名" # 配置用户名git config --global user.email "用户邮箱" # 配置邮箱git config --global core.editor 编辑器 # 配置编辑器,模式使用vi或者vim# 查看配置git config --global user.name # 查看配置的用户名git config --global user.email # 查看配置的邮箱# 查看所有配置列表git config --global --list # 查看全局设置相关参数列表git config --local --list # 查看本地设置相关参数列表git config --system --list # 查看系统配置参数列表git config --list # 查看所有Git的配置(全局+本地+系统)
除了命令行的方式外,你还可以直接去编辑对应的配置文件。
2. 获取帮助「git help」
git help 命令 # 查看某个git命令的介绍,用法git 命令 --help # 另一种写法
3. 创建本地仓库「git init」
git init 仓库名 # 创建一个新的带Git仓库的项目git init # 为已存在的项目生成一个Git仓库
4. 添加文件到暂存区「git add」
git add 文件名 # 将工作区的某个文件添加到暂存区。git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件git add . # 将当前工作区的所有文件都加入暂存区git add -i # 进入交互界面模式,按需添加文件到缓存区
很多人应该没用过交互界面模式,这里演示下用法:

流程简述:
- 在GitTest文件夹中新建两个文件;
- 键入git add -i,进入交互界面模式,键入4,选择添加untracked(未标记)的文件;
- 根据未标记文件的序号来添加文件,输入?会弹出相关提示,直接回车,结束选择;
- 键入4,可以看到已经不存在untracked的文件了。
5. 让Git不Tracked特定文件「.gitignore文件配置」
当我们使用git add命令把未标记的文件添加到缓存区后,Git就会开始跟踪这个文件。
对于一些比如:自动生成的文件,日志,临时编译文件,应用签名文件等,就没必要进行跟踪了,
我们可以编写一个「.gitignore文件」,把不需要跟踪的文件和文件夹写上,git就不会去
跟踪这些文件了,另外:.gitignore文件与.git文件夹在同级目录下。
如果不想自己写这个文件,可以到 https://github.com/github/gitignore 选择对应的模板,复制粘贴。
也可以自行编写,支持简化了的真这个表达式(规范与示例模板摘自:Git王者超神之路)
*: 匹配零个或多个任意字符[abc]:只匹配括号内中的任意一个字符[0-9]:代表范围,匹配0-9之间的任何字符?:匹配任意一个字符**:匹配任意的中间目录,例如a/*/z可以匹配:a/z,a/b/z,a/b/c/z等
模板示例:
# 忽略所有以 .c结尾的文件*.c# 但是 stream.c 会被git追踪!stream.c# 只忽略当前文件夹下的TODO文件, 不包括其他文件夹下的TODO例如: subdir/TODO/TODO# 忽略所有在build文件夹下的文件build/# 忽略 doc/notes.txt, 但不包括多层下.txt例如: doc/server/arch.txtdoc/*.txt# 忽略所有在doc目录下的.pdf文件doc/**/*.pdf
有一点要特别注意!!!!
配置.gitignore只对那些没有添加到版本控制系统的文件生效(未Tracked的文件)!
举个简单的例子:
有A,B两个文件,你先把他两个add了,然后在.gitignore文件中
配置了不跟踪这两个文件,但是你会发现根本不会生效。
git add Agit add B# 配置不跟踪A和Bgit add .gitignore
所以,最好的做法就是在项目刚开始的时候,先添加.gitignore文件。
当然,即使是发生了,还是有解决方法的,可以键入下述命令清除标
记状态,然后先添加.gitignore,再添加文件即可:
git rm -r --cached . # 清除版本控制标记,.代表所有文件,也可指定具体文件
另外,如果你用的IDEA系列的代码编辑器,可以安装一个「.ignore」的插件,手动
勾选不需要跟踪的文件,直接生成.gitignore文件。
6. 将暂存区的内容提交到本地仓库「git commit」
git commit -m "提交说明" # 将暂存区内容提交到本地仓库git commit -a -m "提交说明" # 跳过缓存区操作,直接把工作区内容提交到本地仓库
如果不加-m “提交说明”,git会让用你让默认编辑器(vi或vim)来编写提交说明。
除此之外,有时可能想修改上次提交的内容:提交说明,修改文件等:
# 合并暂存区和最近的一次commit,生成新的commit并替换掉老的。如果缓存区没内容,# 利用amend可以修改上次commit的提交说明。## 注:因为amend后生成的commit是一个全新的commit,旧的会被删除,所以别在公共的# commit上使用amend!切记!!!git commit --amendgit commit --amend --no-edit # 沿用上次commit的提交说明
7. 查看工作区与缓存区的状态「git status」
git status # 查看工作区与暂存区的当前情况git status -s # 让结果以更简短的形式输出
8. 差异对比(内容变化)「git diff」
git diff # 工作区与缓存区的差异git diff 分支名 # 工作区与某分支的差异,远程分支这样写:remotes/origin/分支名git diff HEAD # 工作区与HEAD指针指向的内容差异git diff 提交id 文件路径 # 工作区某文件当前版本与历史版本的差异git diff --stage # 工作区文件与上次提交的差异(1.6 版本前用 --cached)git diff 版本TAG # 查看从某个版本后都改动内容git diff 分支A 分支B # 比较从分支A和分支B的差异(也支持比较两个TAG)git diff 分支A...分支B # 比较两分支在分开后各自的改动# 注:如果只想统计哪些文件被改动,多少行被改动,可以添加--stat参数
9. 查看历史提交记录「git log」
git log # 查看所有commit记录(SHA-A校验和,作者名称,邮箱,提交时间,提交说明)git log -p -次数 # 查看最近多少次的提交记录git log --stat # 简略显示每次提交的内容更改git log --name-only # 仅显示已修改的文件清单git log --name-status # 显示新增,修改,删除的文件清单git log --oneline # 让提交记录以精简的一行输出git log –graph –all --online # 图形展示分支的合并历史git log --author=作者 # 查询作者的提交记录(和grep同时使用要加一个--all--match参数)git log --grep=过滤信息 # 列出提交信息中包含过滤信息的提交记录git log -S查询内容 # 和--grep类似,S和查询内容间没有空格git log fileName # 查看某文件的修改记录,找背锅专用
除此之外,还可以通过 –pretty 对提交信息进行定制,比如:

更多规则与定制如下(更多可参见:Viewing the Commit History)
format对应的常用占位符:(注:作者是指最后一次修改文件的人,提交者是提交该文件的人)
| 占位符 | 说明 | 占位符 | 说明 |
|---|---|---|---|
%H |
提交对象(commit)的完整哈希字串 | %h |
提交对象的简短哈希字串 |
%T |
树对象(tree)的完整哈希字串 | %t |
树对象的简短哈希字串 |
%P |
父对象(parent)的完整哈希字串 | %p |
父对象的简短哈希字串 |
%an |
作者(author)的名字 | %ae |
作者的电子邮件地址 |
%ad |
作者修订日期(可以用 –date= 选项定制格式) | %ar |
按多久以前的方式显示 |
%cn |
提交者(committer)的名字 | %ce |
提交者的电子邮件地址 |
%cd |
提交日期 | %cr |
提交日期,按多久以前的方式显示 |
%s |
提交说明 |
一些其他操作:
| 选项 | 说明 |
|---|---|
-p |
按补丁格式显示每个更新之间的差异 |
–stat |
显示每次更新的文件修改统计信息(行数) |
–shortstat |
只显示 –stat 中最后的行数修改添加移除统计 |
–name-only |
仅在提交信息后显示已修改的文件清单 |
–name-status |
显示新增、修改、删除的文件清单 |
–abbrev-commit |
仅显示 SHA-1 的前几个字符,而非所有的 40 个字符 |
–relative-date |
使用较短的相对时间显示(比如,“2 weeks ago”) |
–graph |
显示 ASCII 图形表示的分支合并历史 |
–pretty |
格式定制,可选选项有:oneline,short,full,Fullerton和format(后跟指定格式) |
还有一些限制log输出的选项:
| 选项 | 说明 |
|---|---|
-(n) |
仅显示最近的 n 条提交 |
–since, –after |
仅显示指定时间之后的提交。 |
–until, –before |
仅显示指定时间之前的提交。 |
–author |
仅显示指定作者相关的提交。 |
–committer |
仅显示指定提交者相关的提交。 |
–grep |
仅显示含指定关键字的提交 |
-S |
仅显示添加或移除了某个关键字的提交 |
10. 查看某个文件是谁改动的「git blame」
git blame 文件名 # 查看某文件的每一行内容的作者,最新commit和提交时间
这里为了演示,先修改一波作者用户名和邮箱,然后往1.txt中新增内容:
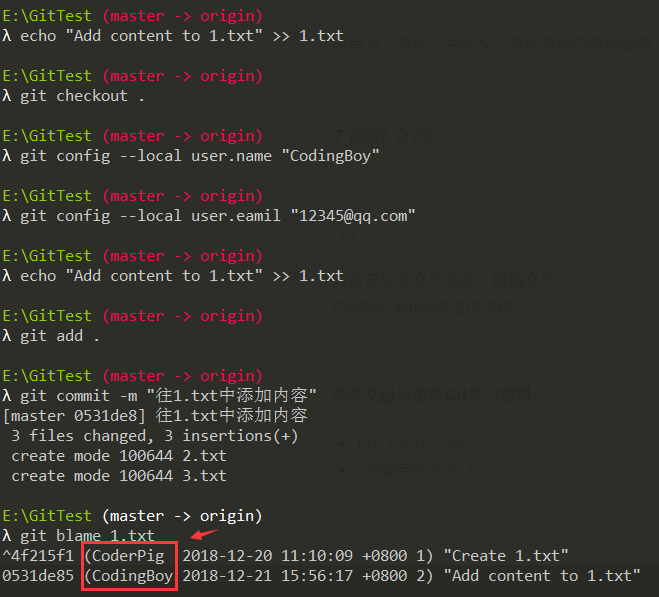
Tip:如果你用的IDEA系列的编译器,右键行号,选择Annotate也可以实现同样的效果。如:

11. 设置Git命令别名「git config –global alias」
在终端使用Git命令的时候,虽然可以通过按两次tab来自动补全。但是有些命令比较常用,
每次都要敲完就显得有些繁琐了,可以为这些命令起一个简单的别名,比如:
status为st,checkout为co ; commit为ci ; branch为br等,设置示例如下:
git config --global alias.st status

别名的设置保存在git的配置文件中:

12. 为重要的提交打标签「git tag」
对于某些提交,我们可以为它打上Tag,表示这次提交很重要, 比如为一些正式发布大版本的
commit,打上TAG,当某个版本出问题了,通过TAG可以快速找到此次提交对应的Hash值,
直接切换到此次版本的代码去查找问题,比起一个个commit找省事多了。
Git中的标签分为两种:轻量级标签 和 附加标签,命令如下:
git tag 标记内容 # 轻量级标签git tag -a 标记内容 -m "附加信息" # 附加标签
如果想为之前某次commit打TAG,可以找出此次提交的Hash值,添加-a选项,示例如下:
git tag -a 标记内容 版本id # 比如:git tag -a v1.1 bcfed96
另外,git push 的时候默认不会把标签推送到远程仓库,如果想把标签页推送到远程仓库,可以:
git push origin 标记内容 # 推送某标签到远程仓库git push origin --tags # 删除所有本地仓库中不存在的TAG
除此之外还有下述常规操作:
git checkout -b 分支名 标记内容 # 新建分支的时候打上TAGgit show 标记内容 # 查看标签对应的信息git tag -d 标记内容 # 删除本地TAGgit push origin --delete tag 标记内容 # 删除远程TAG
Git文件恢复与版本回退
1. 文件恢复(未commit)「git checkout」
如果在工作区直接删除已经被Git Tracked的文件,暂存区中还会存在此文件:
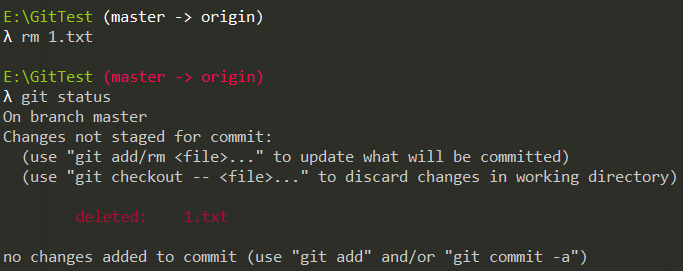
Git告诉你,工作区的文件被删除了,你有两种可选操作:「删除缓存区文件」 或 「恢复被删文件」:
# 删除暂存区中的文件:git rm 文件名git commit -m "提交说明"# 误删恢复文件(用暂存区的文件覆盖工作区的文件)git checkout -- 文件名# Tip:git rm 等价于 git rm --cached 文件名 + rm 文件名# 务必注意:git checkout会抛弃当前工作区的更改!!!不可恢复!!!务必小心!!!
2. 文件恢复(已add未commit)「git reset HEAD」
如果更改已经add到暂存区中,想恢复原状,可以执行下述命令:
git reset HEAD 文件名git checkout 文件名
3. 版本回退(已commit)【git reset –hard】
文件已经commit,想恢复未上次commit的版本或者上上次,可以:
git reset HEAD^ # 恢复成上次提交的版本git reset HEAD^^ # 恢复成上上次提交的版本,就是多个^,以此类推或用git reset HEAD~3 # 也可以直接~次数git reset --hard 版本号 # git log查看到的Hash值,取前七位即可,根据版本号回退
reset命令的作用其实就是:重置HEAD指针,让其指向另一个commit,而这个动作可能会对
缓存区造成影响,举个例子:
本来的分支线:- A - B - C (HEAD, master),git reset B后:- A - B (HEAD, master)
解释:看不到C了,但是他还是存在的,可以通过git reset C版本号找回,前提是
C没有被Git当做垃圾处理掉(一般是30天)。
reset提供了三个可选参数:
- soft:只是改变HEAD指针指向,缓存区和工作区不变;
- mixed:修改HEAD指针指向,暂存区内容丢失,工作区不变;
- hard:修改HEAD指针指向,暂存区内容丢失,工作区恢复以前状态;
4. 查看输入过的指令记录「git reflog」
Git会记住你输入的每个Git指令,比如上面的git reset 切换成一个旧的commit,然后
git log后发现新提交的记录没了,想切换回新的那次commit, 可以先调git reflog
获取新commit的Hash值,然后git reset 回去。
git reflog
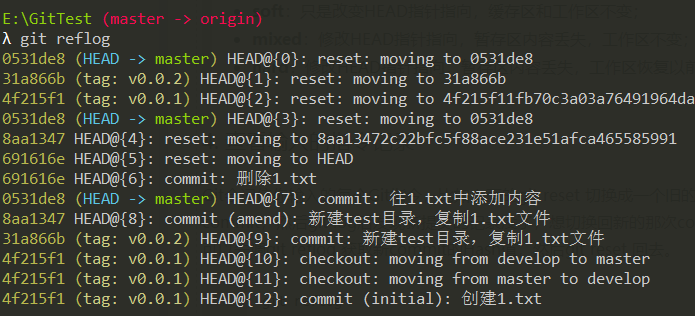
注:指令记录不会永久保存!Git会定时清理用不到的对象!!!
5. 撤销某次提交「git revert」
有时可能我们想撤销某次提交所做的更改,可以使用revert命令
git revert HEAD # 撤销最近的一个提交git revert 提交的Hash值 # 撤销某次commit
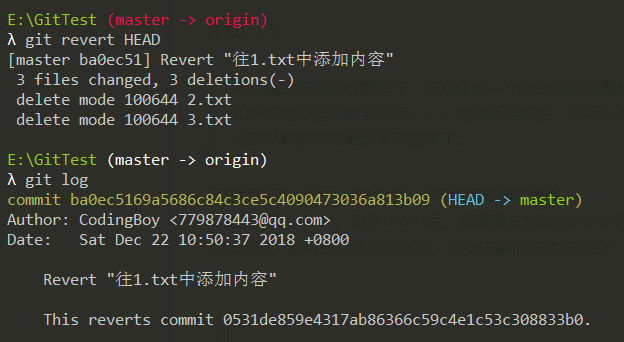
注意!!!
不是真的把提交给撤销了,而是生成一个新的提交来覆盖旧的提交,被撤销的提交
和新的提交记录都会保存!!!如果不信的话,你可以再键入git revert HEAD,
会发现被撤销的更改又变回来了。简单点说:「撤销的只是文件变化,提交记录依旧存在」。
6. 查看某次提交的修改内容「git show」
git show 提交Hash值 # 查看某次commit的修改内容
7. 查看分支最新commit的Hash值「git rev-parse」
git rev-parse 分支名 # 查看分支最新commit的Hash值,也可以直接写HEAD
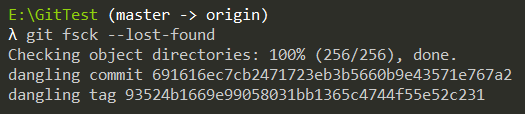
8. 找回丢失对象的最后一点希望「git fsck」
因为你的某次误操作导致commit丢失,如果git reflog都找不到,你可以使用git fsck,找到丢失
的对象的版本Hash值,然后恢复即可。
git fsck --lost-found
0x4、Git本地分支
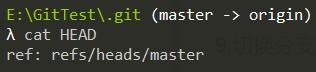
1.分支的概念
分支并不是Git对象,和轻量级的TAG对象类似,只包含对commit对象的索引。只是分支更新后,
索引会替换为最新的commit,而TAG对象创建后索引就不在变化。分支文件保存与下述两个路径:
- 本地分支:
当前项目/.git/refs/heads/ - 远程分支:
当前项目/.git/refs/remotes/
说到分支,必然会提及HEAD,它指向「当前工作的本地分支」,对应文件:当前项目/.git/HEAD
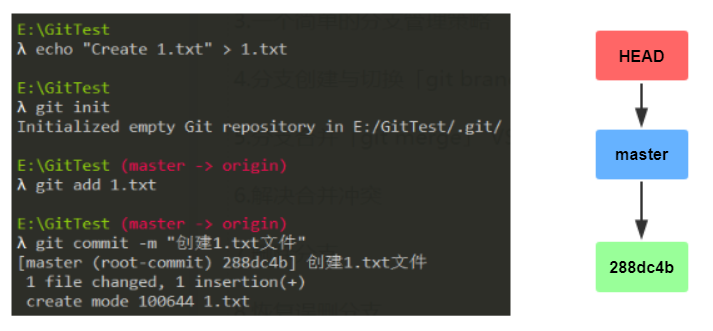
下面通过示例和图解的方式帮大家理解分支:
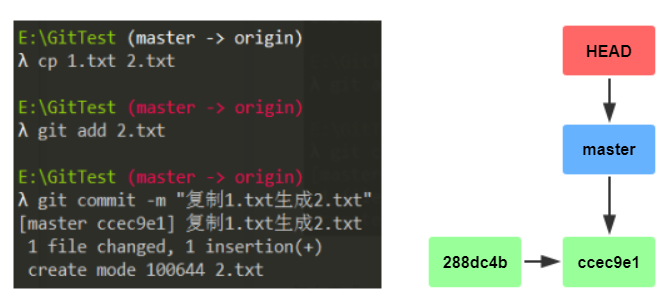
如法炮制,提交两次:

从上面的图中不难发现这样的规律:每次commit,master都会向前移动,指向最新提交。
这个时候可能有些童鞋会问:commit之间的箭头哪来的?或者说commit怎么串成一条线的?
答:还记得一开始介绍的commit对象吗?里面有一个parent的值,指向父commit的Hash值。
2.创建其他分支的原因
通过两个常见的场景来体会创建其他分支的必要性:
- 场景一:
项目一般都是一步步迭代升级的,有大版本和小版本的更新: 大版本一般是改头换面的更新,比如
UI大改,架构大改,版本是: v2.0.0这样;小版本的更新一般是UI小改,Bug修复优化等,版本是:
v2.0.11这样;只有一条master分支,意味着:你的分支线会 非常非常的长,假如你已经发布到了
第二个大版本,然后用户反馈第一个版本有很严重的BUG,这时候想切回第一个版本改BUG,
然后改完BUG切回第二个大版本,想想也是够呛的。 (PS:可能你说我可以对重要的commit打tag,
然后找到这个tag 切回去,当然也行这里是想告诉你引入其他分支会给你带来的便利)
- 场景二:
如果只有一个master分支的话,假如某次commit冲突了,而这个冲突很难解决或者解决不了,
那么整个开发就卡在这里,无法继续向后进行了。
3.一个简单的分支管理策略
为了解决只有一个master分支引起的问题,可以引入分支管理,最简单的一种策略如下:
在master分支上开辟一个新的develop分支,然后我们根据功能或者业务,再在develop
分支上另外开辟其他分支,完成分支上的任务后,再将这个分支合并到develop分支上!
然后这个功能分支的任务也到此结束,可以删掉,而当发布正式版后,再把develop分支
合并到master分支上,并打上TAG。
master与develop分支都作为长期分支,而其他创建的分支作为临时性分支!
简述各个分支的划分:
- master分支:可直接用于产品发布的代码,就是正式版的代码
- develop分支:日常开发用的分支,团队中的人都在这个分支上进行开发
- 临时性分支:根据特定目的开辟的分支,包括功能(feature)分支,或者预发布(release)分支,
又或者是修复bug (fixbug)分支,当完成目的后,把该分支合并到develop分支,
然后删除该分支,使得仓库中的常用分支始终只有:master和develop两个长期分支!
4.分支创建与切换「git branch」
git branch 分支名 # 创建分支git branch # 查看本地分支
我们在master分支上创建一个develop分支,此时的版本线变成了这样:
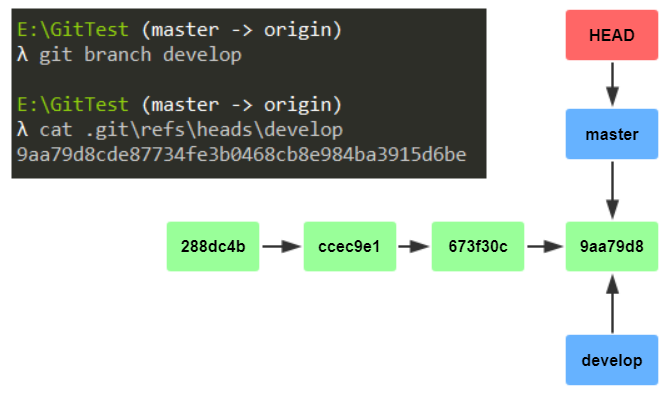
此时虽然已经创建了develop分支,但是HEAD还是指向master,接着我们来切换分支:
git checkout 分支名 # 切换分支git checkout -b 分支名 # 创建分支同时切换到这个分支

切换到develop后,提交一次,此时的版本线:

再提交一次,然后切换为master分支,此时的版本线:

切换回master后,提交一次,此时的版本线:
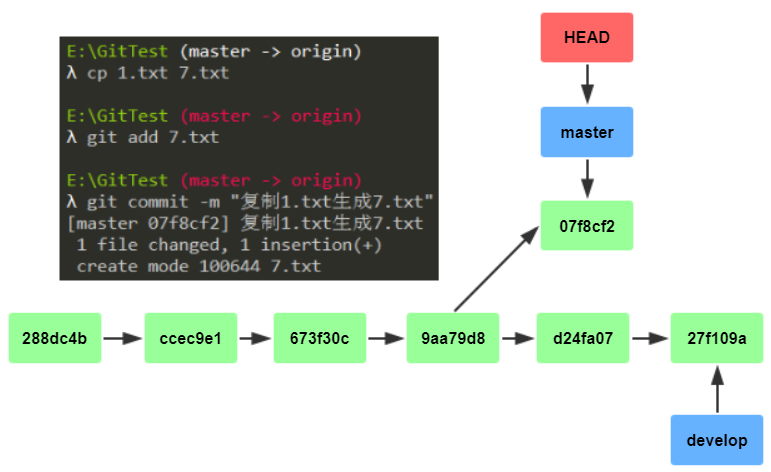
行吧,讲到这里,相信各位童鞋对Git中的分支已经有所了解了。
5.分支合并「git merge」 VS 「git rebase」
Git中,可以使用「git merge」和「git rebase」两个命令来进行分支的合并。
git merge合并分支
合并的方式分为两种:快速合并 和 普通合并,两者的区别在于:
「前者合并后看不出曾经做过合并,而后合并后的历史会有分支记录」
如图所示:

快速合并,默认,快速合并有一个前提:「当前分支的每个提交都在另一个分支中」,
Git不创建任何新的commit,只是将当前分支指向合并进来的分支。下面演示下快速合并,
执行git reset 切换到第四次commit,然后执行git merge develop合并master分支。

普通合并,添加–no-ff参数表示禁用快速合并。

另外有时会有这样的场景:合并的分支中有很多commit记录是无需在分支中体现的,一个commit
就够了。可以借助--squash参数来压缩提交,示例如下:

附:git merge的常用参数:
git merge -ff # 快速合并,默认参数git merge -ff-only # 只有快速合并的情况才合并git merge --no-ff # 不使用快速合并git merge -n 分支名 # 合并分支,不会在合并后显示合并前后的不同状态git merge -stat 分支名 # 合并分支,合并结束后显示合并前后的不同状态git merge -e 分支名 # 合并分支,合并前调用编辑器,可自行编写commit
Tips: git-merge除了用来合并分支外,拉取远程仓库更新时也可用到(git fetch + git merge)
git reabse合并分支
rebase(衍合,变基),网上很多教程写得很高深莫测,其实并没有那么复杂,
只是这种合并会让树整洁,易于跟踪。以上面4中的结果为例,先把master分支
和develop分支重置到最新的commit。
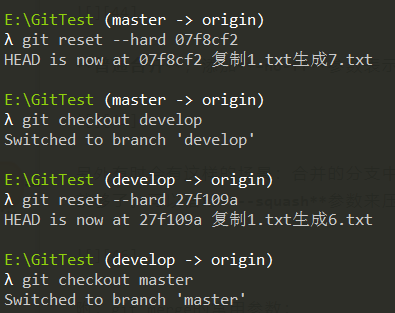
先走一波前面的merge合并方式:

接着再试试rebase合并方式:
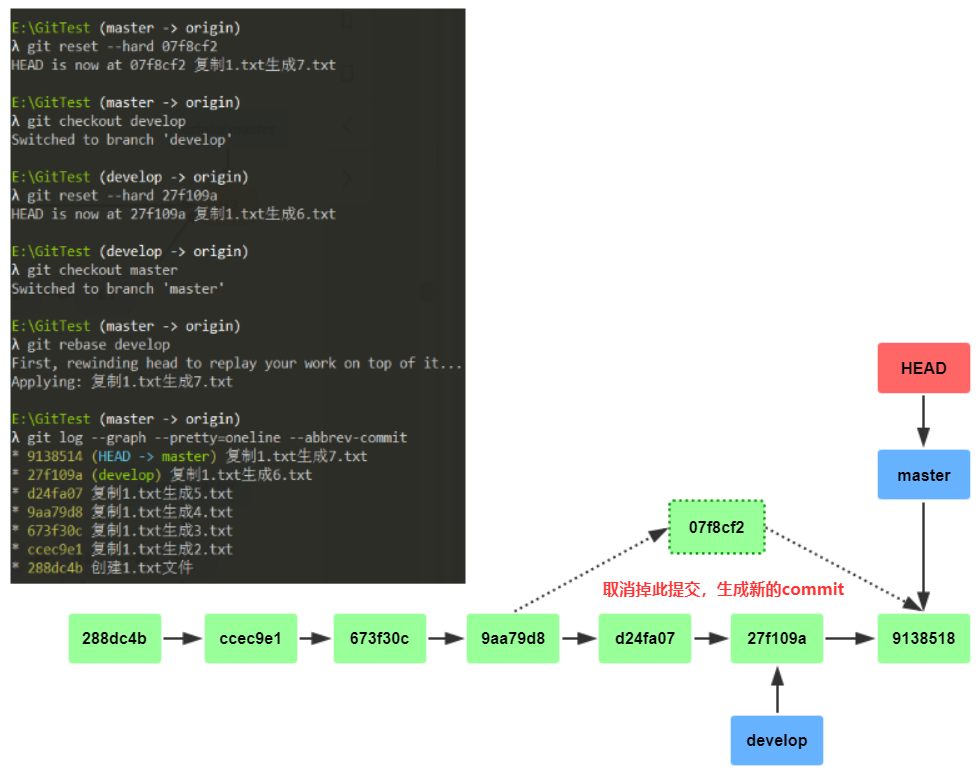
Git会把每个提交都取消掉,并把他们临时保存为补丁,比如经过一些冲突解决,生成新的commit,
旧的commit会被丢弃,还会被git的gc回收,这样的结果就是一条直线的树。
6.解决合并冲突
在分支的合并的时候,并不是每次都能直接合并的,有时会遇到合并冲突,特别是在多人协作的时候。
出现合并冲突后,需要解决完冲突,才能继续合并。
举个简单的例子,A和B在master分支上开辟出两个分支来完成相关的功能,
A做完了,把自己的分支合并到master分支,此时master分支向前移动了几次commit,
接着B也完成了他的功能,想把自己分支合并到master分支,如果改动的文件和和A改动
的文件相同的话,此时就会合并失败,然后需要处理完冲突,才能够继续合并!
接下来我们来简单的模拟合并冲突,先来试试merge:
merge分支后处理冲突
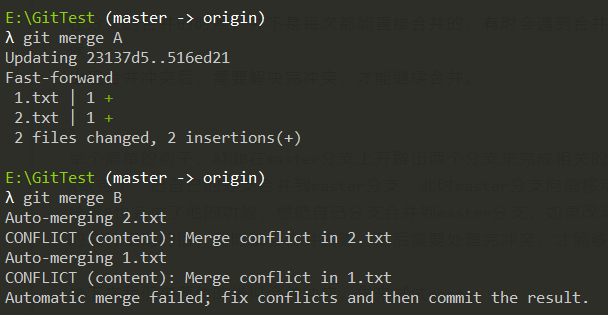
如图,合并完A分支后合并B分支出现了冲突,接着键入:git status查看冲突的文件:
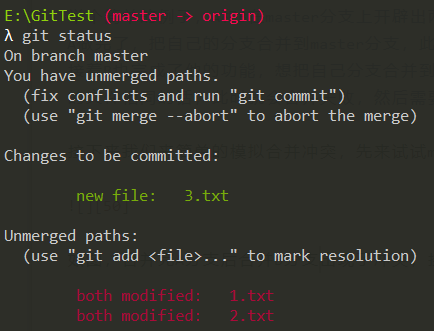
可以看到未合并的两个文件,1.txt和2.txt,打开其中一个文件:

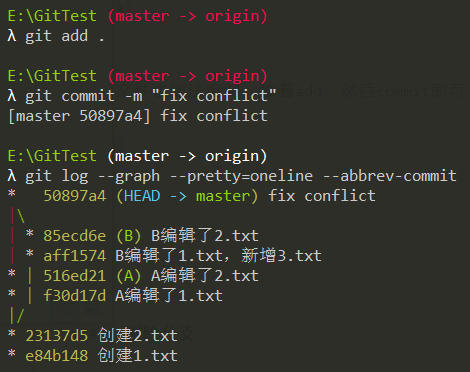
<<< 和 >>>包裹着的就是冲突内容,保留自己想要的内容,处理完后删掉<<<和>>>,修改完后:

2.txt文件也如法炮制,接着add,然后commit即可,合并结束。
rebase分支后处理冲突

如图,A合并成功,在合并B的时候,出现了合并冲突,有三个可选的操作:
git rebase --continue # 处理完冲突后,继续处理下一个补丁git rebase --abort # 放弃所有的冲突处理,恢复rebase前的情况git rebase --skip # 跳过当前的补丁,处理下一个补丁,不建议使用,补丁部分的commit会丢失!
键入git status查看冲突文件:
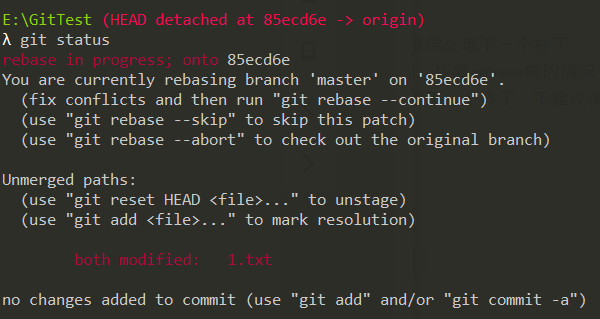
接着处理1.txt文件中的冲突,解决完成后,先键入git add,接着键入git rebase --continue
处理下一个冲突:

处理接下来的冲突,直到没有冲突为止:
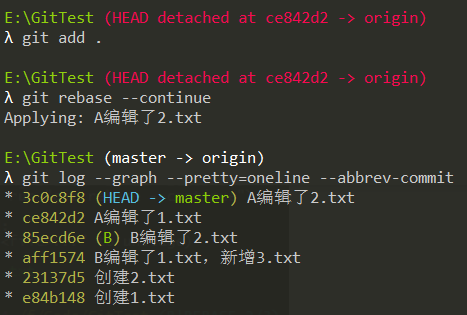
可以看到使用rebase合并,最后的分支线是一条直线。另外,使用rebase合并中途出差错,
可以使用git rebase --abort恢复rebase前的状态。
7.删除分支
合并完的分支,基本没什么用了,可以使用下述命令删除:
git branch -d 分支名 # 删除分支,分支上有未提交更改是不能删除的git branch -D 分支名 # 强行删除分支,尽管这个分支上有未提交的更改
8.恢复误删分支
两步:找出被删分支最新的commit的Hash值,然后恢复分支:
git log --branches="被删除的分支名" # 找到被删分支最新的commit版本号git branch 分支名 版本号(前七位即可) # 恢复被删分支
9.切换分支时暂存未commit的更改「git stash」
有时我们可能在某个分支上正编写着代码,然后有一些突发的情况,需要 我们暂时切换到
其他分支上,比如要紧急修复bug,或者切换分支给同事 review代码,此时如果直接切换
分支是会提示切换失败的,因为这个分支 上做的更改还没有提交,你可以直接add后commit,
然后再切换,不过我们习惯写完某个功能再提交,我们想:
先暂存这个分支上的改动,切去其他分支上搞完事,然后回来继续
继续在之前的改动上写代码。
那么可以使用:
git stash # 保存当前的改动
然后放心的切换分支,然后再切换回来,接着使用:
git stash apply # 恢复保存改动
另外有一点一定要注意!!!可以stash多个改动!!如果你切换到另一个分支
又stash了,然后切换回来stash apply是恢复成另一个分支的stash!!!
如果你这样stash了多次的话,我建议你先键入:
git stash list # 查看stash列表
找到自己想恢复的那个

比如这里恢复的应该是master上的stash,可以使用下述命令进行恢复:
git stash apply stash@{1}
10.分支重命名
git branch -m 老分支名 新分支名 # 分支重命名
11.把提交的commit从一个分支放到另一个分支「git cherry-pick」
有时我们可能需要把某个分支上的一次commit放到另一个分支上,此时可以使用git cherry-pick,
比如下面这样两个分支:
master分支:A -> B -> C
feature分支:a -> b
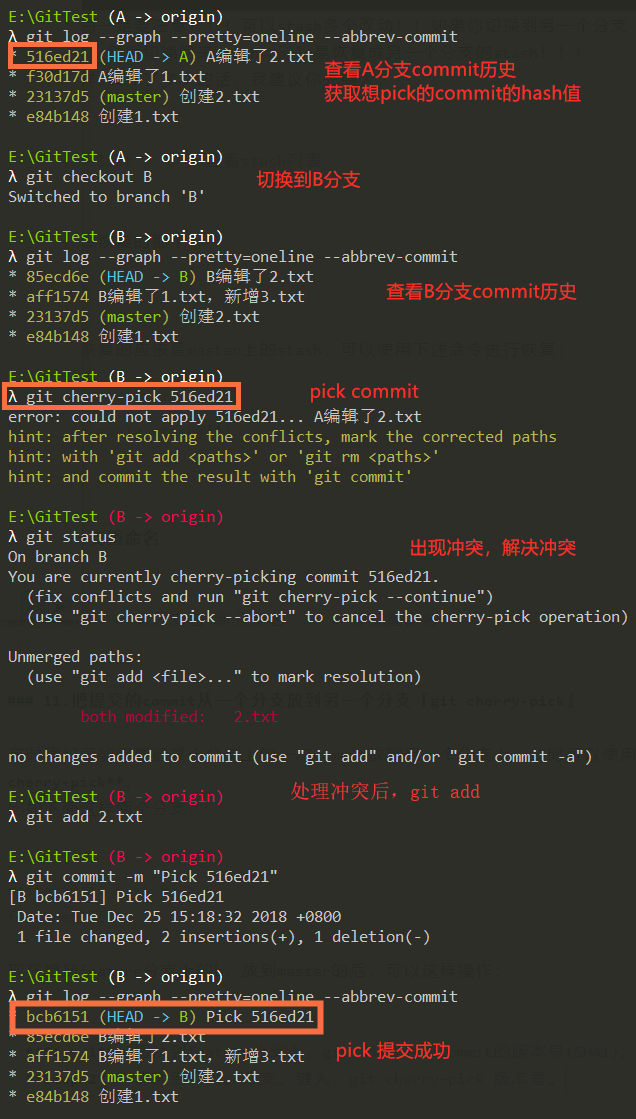
现在想把feature分支上的b,放到master的后,可以这样操作:
- Step 1:切换到feature分支上,git log拿到b commit的版本号(SHA1)。
- Step 2:切换到master分支,键入:git cherry-pick 版本号。
0x5、Git远程仓库
1.远程仓库概述
在实际开发过程中,基本都是团队协作的形式进行,即多人一起负责同一个项目,那如何共享同一份代码并进行管理呢?可以用到「Git远程仓库」。可以自己搭建,或选择专业的代码托管平台,比如:Github,Git@OSC,GitCafe,GitLab,coding.net,gitc,BitBucket,Geakit,Douban CODE 等。当然,如果有条件的话,肯定是自己搭建的爽一些,可控,还可以做一些订制(集成编译,机器人提醒等),简单点的可以试试「Gogs」,可玩性更高的可以试试「GitLab」。
2.本地仓库与远程仓库建立关联「git remote」
在Github上新建了一个项目仓库,会生成对应的仓库链接,如:

键入下述命令进行关联:
git remote add origin 远程仓库地址
接着可键入下述命令查看关联情况:
git remote # 列出已经存在的远程分支git remote -v # 查看远程仓库的地址

3.推送本地仓库到远程仓库「git push」
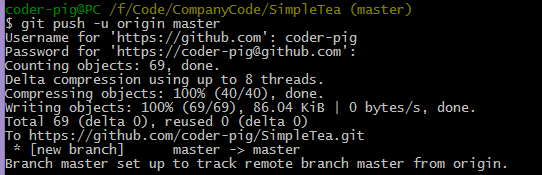
建立完关联后,我们可以使用git push命令把本地更改推送到远程仓库
git push -u origin master
-u参数:作为第一次提交使用,作用是把本地master分支和远程master分支关联起来(设置默认远程主机),后续提交不需要这个参数!
另外,如果想修改远程仓库地址,可通过下述命令:
# 直接修改远程仓库地址git remote set-url origin 远程仓库地址# 也可以先删除origin后再添加git remote rm origin # 删除仓库关联git remote add origin 远程仓库地址 # 添加仓库关联
你还可以直接修改「.git文件夹中的config文件」,直接替换圈住位置内容即可:

还有一点:「origin」并不是固定的东西,只是后面「仓库地址的一个别名」!!可以写成其他的东西,然后你也可以设置多个仓库关联,用不同的别名标志,比如:
git remote add github https://github.com/coder-pig/SimpleTea.gitgit remote add osc git@git.oschina.net:coder-pig/SimpleTea.git
4.克隆远程仓库「git clone」
把项目推送到远程仓库后,其他开发者就可以通过git clone命令把项目克隆到本地
git clone 仓库地址 # 克隆项目到当前文件夹下git clone 仓库地址 目录名 # 克隆项目到特定目录下# 注:git clone命令只会建立master分支,如果想克隆特定远程分支,可在克隆后:git checkout -t origin/dev# 该命令等同于git checkout -b dev origin/dev# 除此之外,还可以:git fetch origin 远程分支:本地分支 # 会在本地新建分支,但不会自动切换,还需checkoutgit branch --set-upstream 本地分支 远程分支 # 建立本地分支与远程分支的链接
5.同步远程仓库更新「git fetch」VS 「git pull」
获取远程仓库更新的方法有两种:fetch 和 pull,简要讲解下两者的区别:
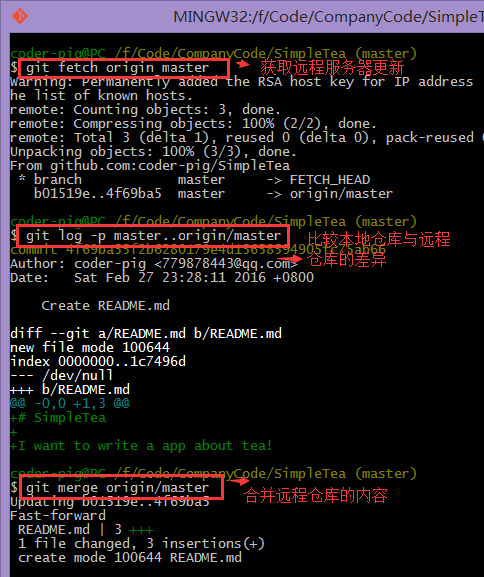
- git fetch
仅仅只是从远处服务器获取到最新版本到本地,假如你不去合并(merge),本地工作空间是不会发生变化的!比如:在Github上创建一个README.md文件,然后调 git fetch 去获取远程仓库的更新。
- git pull
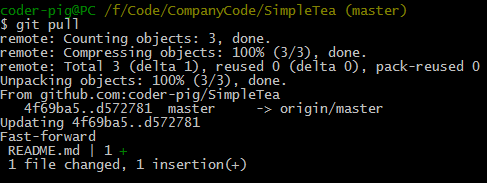
一步到位,pull = fetch + merge,比如:同样修改Github上的README.md 文件,然后git pull 同步远程仓库的更新:
区别显而易见,使用git fetch会更安全一些,毕竟merge的时候,查看更新的情况,再决定是否进行合并。
6.git push 时的unrelated history问题
在Github创建新项目后,在repo处创建了README.md或其他文件,然后关联本地仓库,push时会报错:
Push rejected: Push to origin/master was rejected,然后提示你pull一下,当你pull时又会报错:
「refusing to merge unrelated histories」,原因是两个仓库不同导致的,可使用下述命令解决:
git pull origin master --allow-unrelated-histories
除此之外,你还可以粗暴一点,直接用本地仓库「强制覆盖远程仓库」,但是 慎用!!!如果出问题了,只能看下其他人的电脑中是否有原始的本地仓库进行还原!!!
git push -f origin # 慎用!!!
7.SSH Key避免每次push重复输入账号密码
私有项目,使用Https协议pull或push,都需要验证账号和密码,有点繁琐,如果想避免这种重复输入的情况,可以考虑使用SSH协议。SSH,Secureshell(安全外壳协议),专为远程登陆会话与其他网络服务提供安全性的协议,而SSH传输的数据是可以经过压缩的,可以加快传输的速度,出于安全性与速度,优先考虑使用SSH协议,而SSH的安全验证规则又分为基于密码和基于密钥两种!这里使用的是第二种,即在本地创建一对密钥「公钥(id_rsa.pub)和私钥(id_rsa)」然后把公钥内容贴到远程仓库设置中的ssh keys中,从而建立本地与远程的认证关系。配置SSH Key的流程如下:
- ① 来到电脑的根目录下(假设还没创建过SSH key):

执行完ssh-keygen那个指令后,后面依次要你输入文件名
直接回车 → 会生成两个默认的秘钥文件,接着提示输入密码,
直接回车 → 如果这里你输入密码了的话,那么push的时候你还是需要输入密码,接着又输多一次密码
直接回车 → 出现最下面的这串东西就说明ssh key已经创建成功了!
接着可以用编辑器打开id_rsa.pub文件或者键入下述命令复制内容:
clip <id_rsa.pub
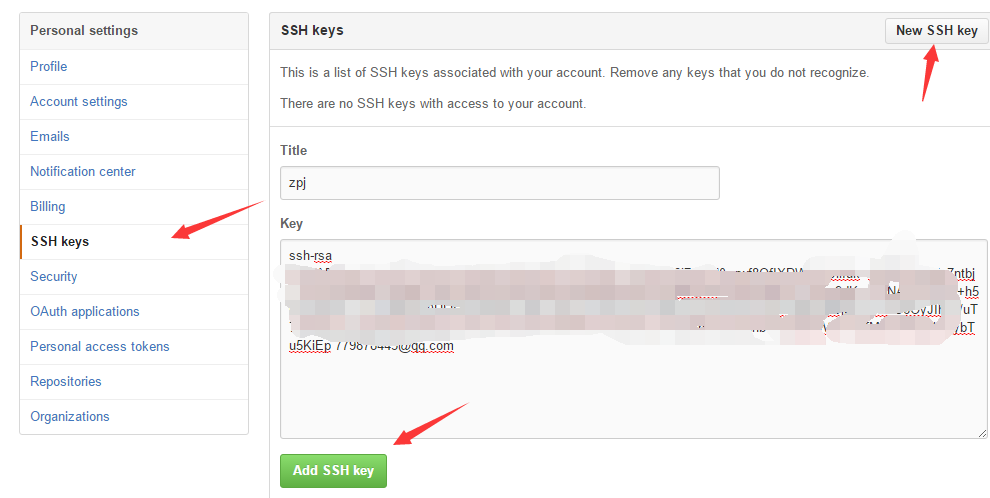
打开Github,点击头像,选择:Settings,然后点击左侧SSH Keys,然后New SSH Key
然后Github会给你发来一个提示创建了一个新ssh key的邮件,无视就好,接下来我们可以键入:
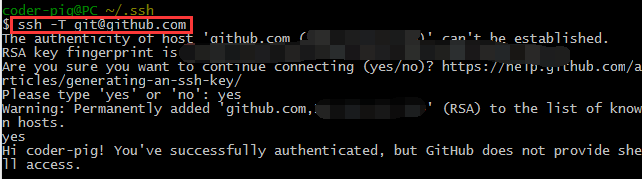
**ssh -T git@github.com**
然后如果上面设置过密码则需要输入密码,否则直接输入yes然后一直按回车就好!,最后出现Hi xxx那句话就说明ssh key配置成功了!
其他远程仓库配置方法类似,另外如果想一个电脑管理多个SSH-Key,可移步至:
0x6、Git工作流
关于Git工作流,Github上有一篇图文并茂写得很好的文章,就不细说了,只是简单介绍下,更多详情可见:《Git Workflows and Tutorials》
1.集中式工作流
类似于SVN,不过只有一条master分支,然后一群人就在这条分支上嗨,比如有小A和小B:
- 1.项目管理者初始化仓库,然后推到远程仓库
- 2.其他人克隆远程仓库项目到本地
- 3.小A和小B完成各自的工作
- 4.小A先完成了,git push origin master 把代码推送到远程仓库
- 5.小B后完成了,此时推送代码到远程仓库,出现文件修改冲突
- 6.小B需要先解决冲突,git pull –rebase origin master,然后rebase慢慢玩
- 7.小B把冲突解决后,git push origin master 把代码推送到远程仓库
2.功能分支工作流
和集中式分部流相比只是分支再不是只有master,而是根据功能开辟新的分支而已,示例如下:
- 1.小A要开发新功能,git branch -b new-feature 开辟新分支
- 2.小A在new-feature上新功能相关的编写,他可以这个分支推到远程仓库
- 3.功能完成后,发起请求pull request(合并请求),把new-feature合并到master分支
- 4.仓库管理员可以看到小A的更改,可以进行一些评注,让小A做某些更改,
然后再发起pull request,或者把pull request拉到本地自行修改。- 5.仓库管理员觉得可以了,合并分支到master上,然后把new-feature分支删掉
注:这里的仓库管理者是拥有仓库管理权限的人
3.Gitflow工作流
其实就是功能分支工作流做了一些规范而已,大概流程参见上面「一个简单的分支管理策略」
4.Forking工作流
分布式工作流,每个开发者都拥有自己独立的仓库,为开源项目贡献代码常用,把项目fork到自己的远程仓库,完成相应更改,然后pull request到源仓库,源仓库管理者可以决定是否合并。
5.Pull Request工作流
和Forking工作流类似,Pull Requests是Bitbucket上方便开发者之间协作的功能
0x7、其他杂项
1.为开源项目贡献代码
你可以Clone别人的开源项目,在看别人代码的时候,觉得作者某些地方写得不好,写错,或者你有更好的想法,在本地修改后,想把修改push推送到开源项目上,是无法直接Push推送更改的。参与开源项目的方式有两种:
方法一:
是让作者把你加为写作者,添加协作者流程:
点击仓库的Settings → Collaborators 然后输入想添加的人的用户名或者邮箱,点击
添加即可。方法二:
点击Fork按钮,把这个项目fork到自己的账号下,然后Clone到本地,然后做你想做的修改,commit提交,然后push到自己账号里的仓库,然后打开开源项目,点击,然后新建一个「pull request」,接着设置自己的仓库为源仓库,设置源分支,目标仓库与目标分支,然后还有pull request的标题和描述信息,填写完毕后,确定。
这个时候开源项目的作者就会收到一个pullrequest的请求,由他来进行审核,作者审查完代码觉得没问题的话,他可以点击一下merge按钮即可将这个pull request合并到自己的项目中,假如作者发现了你代码中还有些bug,他可以通过Pull Request跟你说明,要修复了xxBUG才允许合并,那么你再修改下BUG,提交,更改后的提交会进入Pull Request,然后作者再审核这样!
Tips:o(╯□╰)o假如作者不关闭或者merge你的这个Pull Request,你可以一直commit骚扰主项目…
2.SourceTree使用详解
命令行虽酷炫可装逼,但是有时用图形化工具还是能提高不少效率的,安利个巨好用的Git图形化工具SourceTree,官网下载地址:https://www.sourcetreeapp.com/,网上教程满天飞,笔者也不粘贴复制了,找到个写得还行的,有兴趣可移步至:《用SourceTree轻松Git项目图解》。
后面有新的会更新,待续...
参考文献与更多Git学习资料:
