@coder-pig
2018-04-02T03:52:15.000000Z
字数 5838
阅读 2170
小猪的Python学习之旅 —— 12.Python并发之queue模块
Python
一句话概括本文:
本节对queue.py模块进行了详细的讲解,写了一个实战例子:
多线程抓取半次元Cos频道的所有今日热门图片,最后分析了
一波模块的源码,了解他的实现套路。
大蕾姆镇楼:

引言:
本来是准备写multiprocessing进程模块的,然后呢,白天的时候随手
想写一个爬半次元COS频道小姐姐的脚本,接着呢,就遇到了一个令人
非常困扰的问题:国内免费的高匿代理ip都被玩坏了(很多站点都锁了),
几千个里可能就十个不到能用的,对于这种情况,有一种应付的策略
就是:写While True死循环,一直换代理ip直到能拿到数据为止。
但是,假如是我们之前的那种单线程的话,需要等待非常久的时间,
想想一个个代理去试,然后哪怕你设置了5s的超时,也得花上不少
时间,而你抓取的网页不止一个的话,这个时间就不是一般的长了,
这个时候不用多线程还等什么?我们可以把要请求的页面都丢到
一个容器里,然后加锁,然后新建页面数量 x 访问线程,然后每个
线程领取一个访问任务,然后各自执行任访问,直到全部访问完毕,
最后反馈完成信息。在学完threading模块后,相信你第一个想到的
会是条件变量Contition,acquire对集合加锁,取出一枚页面链接,
notify唤醒一枚线程,然后release锁,接着重复这个操作,直到集合
里的不再有元素为止,大概套路就是这样,如果你有兴趣可以自己
试着去写下,在Python的queue模块里已经实现了一个线程安全的
多生产者,多消费者队列,自带锁,多线程并发数据交换必备。
1.语法简介:
内置三种类型的队列
Queue:FIFO(先进先出);LifoQueue:LIFO(后进先出);PriorityQueue:优先级最小的先出;
构造函数的话,都是(maxsize=0),设置队列的容量,如果
设置的maxsize小于1,则表示队列的长度无限长
两个异常:
Queue.Empty:当调用非堵塞的get()获取空队列元素时会引发;
Queue.Full:当调用非堵塞的put()满队列里添加元素时会引发;
相关函数:
qsize():返回队列的近似大小,注意:qsize()> 0不保证随后的get()不会
阻塞也不保证qsize() < maxsize后的put()不会堵塞;empty():判断队列是否为空,返回布尔值,如果返回True,不保证后续
调用put()不会阻塞,同理,返回False也不保证get()调用不会被阻塞;full():判断队列是否满,返回布尔值如果返回True,不保证后续
调用get()不会阻塞,同理,返回False也不保证put()调用不会被阻塞;put(item, block=True, timeout=None):往队列中放入元素,如果block
为True且timeout参数为None(默认),为堵塞型put(),如果timeout是
正数,会堵塞timeout时间并引发Queue.Full异常,如果block为False则
为非堵塞put()put_nowait(item):等价于put(item, False),非堵塞put()get(block=True, timeout=None):移除一个队列元素,并返回该元素,
如果block为True表示堵塞函数,block = False为非堵塞函数,如果设置
了timeout,堵塞时最多堵塞超过多少秒,如果这段时间内没有可用的
项,会引发Queue.Empty异常,如果为非堵塞状态,有数据可用返回数据
无数据立即抛出Queue.Empty异常;- get_nowait():等价于get(False),非堵塞get()
- task_done():完成一项工作后,调用该方法向队列发送一个完成信号,任务-1;
- join():等队列为空,再执行别的操作;
官方给出的多线程例子:
def worker():while True:item = q.get()if item is None:breakdo_work(item)q.task_done()q = queue.Queue()threads = []for i in range(num_worker_threads):t = threading.Thread(target=worker)t.start()threads.append(t)for item in source():q.put(item)# block until all tasks are doneq.join()# stop workersfor i in range(num_worker_threads):q.put(None)for t in threads:t.join()
关于文档的解读大概就这些了,还是比较简单的,接下来实战
写个用到Queue队列的多线程爬虫例子~
2.Queue实战:多线程抓取半次元Cos频道的所有今日热门图片
1.分析环节
抓取源:https://bcy.net/coser/toppost100?type=lastday
拉到底部(中途加载了更多图片,猜测又是ajax):

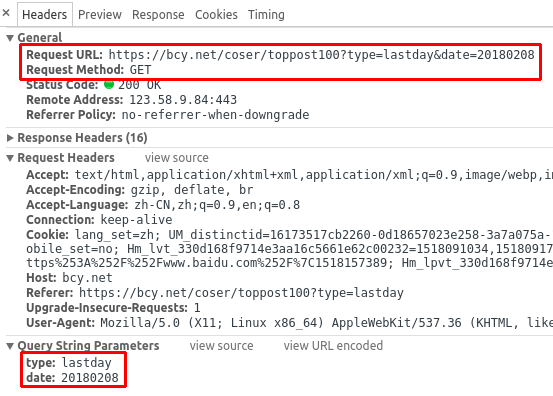
嗯,直接是日期耶,应该是请求参数里的一个,F12打开开发者模式,Network
抓包开起来,随手点开个02月08日,看下打开新链接的相关信息:
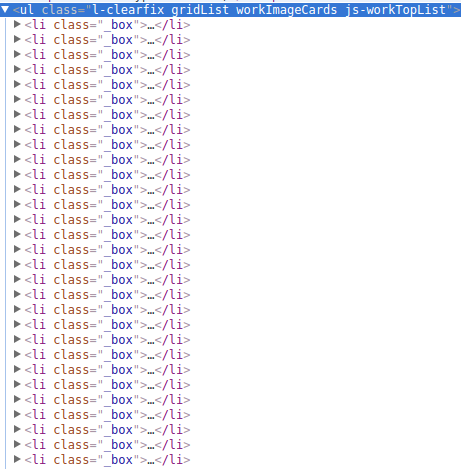
打开目录结构看看,要找的元素都在这里,数了下30个:
不然得出这样的抓包信息:
抓取地址:https://bcy.net/coser/toppost100
请求方式:Get
请求参数:
type(固定):lastday
date:20180208
清理一波,然后滚动下,抓下加载更多的那个接口:
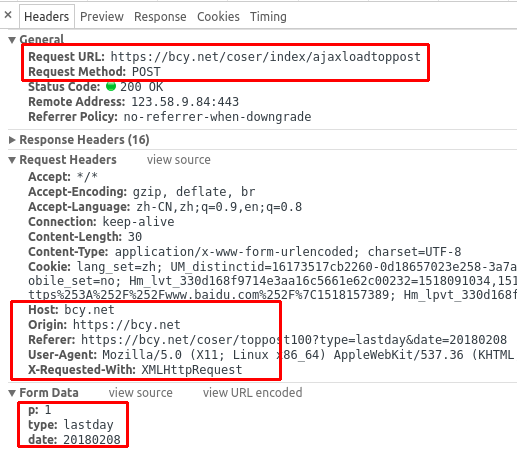
同样是Ajax加载技术,不过数据不是Json,直接就是XML,点击Preview看下:

好家伙,果然是XML,然后不难看出<li class="_box">包着的就是
一个元素,搜了下有20个,就是每次加载20个咯,算一算每日最热
每天的图片就是30+20 = 50个咯,整理下抓包信息:
抓取地址:https://bcy.net/coser/index/ajaxloadtoppost
请求方式:Post
请求参数:
p(固定):1
type(固定):lastday
date:20180207
嗯,两个要抓的接口都一清二楚了,然后就是获得日期的范围了,
这个就要自己慢慢试了,二分查找套路,慢慢缩减范围,知道得
出日期的前一天和日期内容相同,日期的后一天与内容不同为止,
这里直接给出起始时间:20150918,开始抓的时间就是这个,
截止时间就是今天,比如:2018.02.09。
分析完毕,接下来就一步步写代码了~
2.代码实现环节
- 1.定义获取两个日期间所有日期列表的函数
比较简单,利用datetime模块格式化下日期,弄个循环,轻松完成;

- 2.定义抓取今日热门默认加载部分的函数

简单介绍下,cpn是我自己写的一个模块,get_dx_proxy_ip()随机获取
一个大象代理的代理ip,接着的get_bs()则是获取一个BeautifulSoup对象,
write_str_data()是往文件里追加一串字符串的函数。最后还把异常给打印
出来了,运行下就知道了,这个是非常频繁的,threading.current_thread()
获得当前线程,只是方便排查,如果不想打印任何东西,这里直接改成pass就
可以了。另外,使用Θ分隔图片名与下载链接(因为还没学到数据库那里,暂时
就先写txt里...)
- 3.定义抓取今日热门加载更多的函数
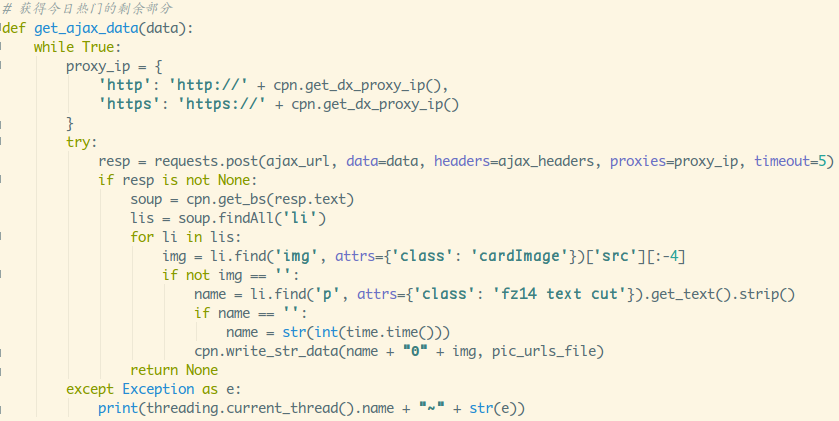
和2类似...
- 4.定义一个抓取线程类

继承threading.Thread类,init构造函数传入一个执行函数,
重写run函数,在此处调用传入的执行函数。
- 5.定义任务队列,把日期参数传入

- 6.定义线程执行的函数

循环,如果队列不为空,从里面取出一枚数据,执行两个抓数据
的函数,执行完毕后,调用queue对象的task_done()通知数目-1;
- 7.开辟线程执行任务

这里就是创建了和任务队列一样数目的线程,调用daemon=True是为了
避免因为线程死锁或者堵塞,然后程序无法停止的情况,保证当程序只
剩下主线程时能够正常退出。
运行截图:

是的,这种HTTPSConnectionPool的异常就是那么频发,代理ip问题,不是
你程序的原因,打开bcycos_url.xml,验证下数据有没有问题:

(PS:这里有些重复是网站本来就重复,一开始还以为是我程序出错...
还有,这里没有抓取所有的,只抓了:20150918到20150930的,数据多得一批...)
- 8.定义下载图片的函数
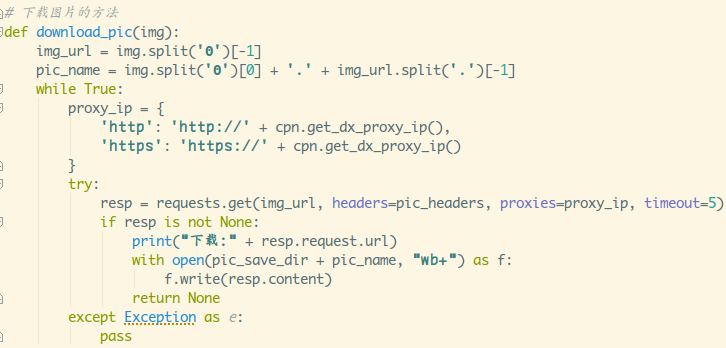
就是处理字符串,获得下载链接,还有图片名的拼接而已~
- 9.定义下载图片进程执行的函数

- 10.新建下载队列,开启线程
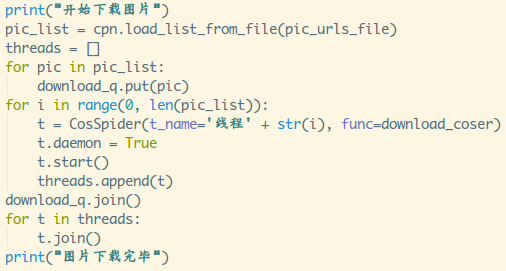
运行截图:
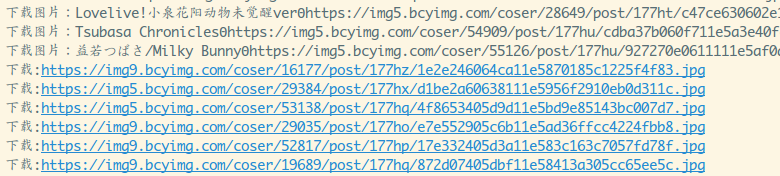
可以打开输入目录验证下:
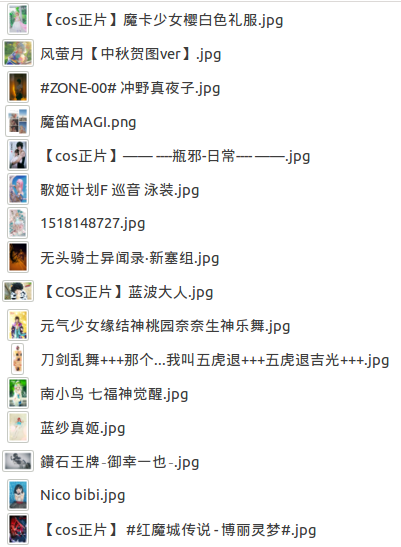
使用Queue编写一个多线程爬虫就是那么简单~
接下来会抠下Queue的源码,有兴趣的可以继续看,没兴趣的话直接跳过即可~
*3.queue模块源码解析
直接点进去queue.py,源码只有249行,还好,看下源码结构
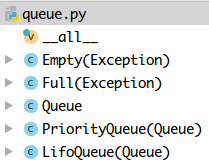
点开两个异常,非常简单,继承Exception而已,我们更关注__all__

1)__all__
__all__:在模块级别暴露公共接口,比如在导库的时候不建议写
from xxx import *,因为会把xxx模块里所有非下划线开头的成员都
引入到当前命名空间中,可能会污染当前命名空间。如果显式声明了
__all__,import * 就只会导入 __all__ 列出的成员。
(不建议使用:from xxx import * 这种语法!!!)
接着看下Queue类结构,老规矩,先撸下__init__方法

文档注释里写了:创建一个maxsize大小的队列,如果<=0,队列大小是无穷的。
设置了maxsize,然后调用self._init(maxsize),点进去看下:
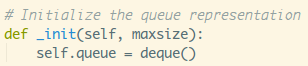
这个deque是什么?
2)deque类
其实是collections模块提供的双端队列,可以从队列头部快速
增加和取出对象,对应两个方法:popleft()与appendleft(),
时间复杂度只有O(1),相比起list对象的insert(0,v)和pop(0)的
时间复杂度为O(N),列表元素越多,元素进出耗时会越长!
回到源码,接着还定义了:
mutex:threading.Lock(),定义一个互斥锁
not_empty = threading.Condition(self.mutex):定义一个非空的条件变量
not_full = threading.Condition(self.mutex):定义一个非满的条件变量
all_tasks_done = threading.Condition(self.mutex):定义一个任务都完成的条件变量
unfinished_tasks = 0:初始化未完成的任务数量为0
接着到task_done()方法:

with加锁,未完成任务数量-1,判断未完成的任务数量,
小于0,抛出异常:task_done调用次数过多,等于0则唤醒
所有等待线程,修改未完成任务数量;
再接着到join()方法:

with加锁,如果还有未完成的任务,wait堵塞调用者进程;
接下来是qsize,empty和full函数,with加锁返回大小而已:

接着是put()函数:

with加锁,判断maxsize是否大于0,上面也讲了maxsize<=0代表
队列是可以无限扩展的,那就不存在队列满的情况,maxsize<=0
的话直接就往队列里放元素就可以了,同时未完成任务数+1,随机
唤醒等待线程。
如果maxsize大于0代表有固定容量,就会出现队列满的情况,就需要
进行细分了:
- 1.block为False:非堵塞队列,判断当前大小是否大于等于容量,是,抛出Full异常;
- 2.block为True,没设置超时:堵塞队列,判断当前大小是否大于等于容量,
是,堵塞线程; - 3.block为True,超时时间<0:直接抛出ValueError异常,超时时间应为非负数;
- 4.block为True,超时时间>=0,没倒时间堵塞线程,到时间抛出Full异常;
再接着是get()函数,和put()类似,只是抛出的异常为:Empty

这两个就不用说了,非堵塞put()和get(),最后就是操作双端队列的方法而已;

另外两种类型的队列也非常简单,继承Queue类,然后重写对应的四个
方法而已~
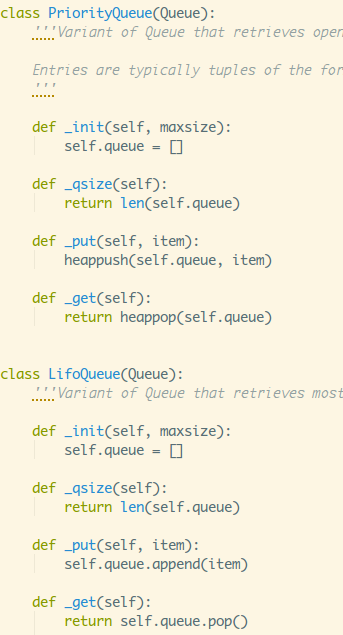
3)heapq模块
PriorityQueue优先级队里的heappush()和heappop()是heapq模块
提供的两个方法,heap队列,q队列,堆一般可看做是一棵树的
数组对象(二叉树堆),规则如下:
某个节点的值总是不大于或不小于其孩子节点的值
然后又分最大堆和最小堆:

(这里大概知道是二叉树就好了,笔者数据结构也学的比较烂...)
利用:heappush()可以把数据放到堆里,会自动按照二叉树的结构进行存储;
利用:heappop(heap):从heap堆中删除最小元素,并返回,heap再按完全二叉树规范重排;
queue.py模块大概的流程就是这个样子咯,总结下套路把:
关键点核心:三个条件变量,
not_empty:get的时候,队列空或在超时时间内,堵塞读取线程,非空唤醒读取线程;
not_full:put的时候,队列满或在超时时间内,堵塞写入线程,非满唤醒写入线程;
all_tasks_done:未完成任务unfinished_tasks不为0的时候堵塞调用队列的线程,
未完成任务不为0时唤醒所有调用队列的线程;
大概就这样~
4.小结
本节把queue模块个撸了一遍,不止是熟悉API,还把源码给撸了,
撸源码感觉就是在一件件脱妹子的衣服一样,每次总能发现新大陆~
嘿嘿,挺好玩的,就说那么多吧~
(PS:Coser的质量真是参差不齐,大部分是靠的化妆和滤镜,我还是喜欢素颜
小姐姐还有萌大奶~,最后来个辣眼睛的Coser给你洗洗眼。O(∩_∩)O)

本节源码下载
https://github.com/coder-pig/ReptileSomething
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

[36]:
