@Rays
2018-09-21T11:14:53.000000Z
字数 8105
阅读 3359
XNLI:评估跨语言句子表征的大规模语料库
摘要: 自然语言处理系统依赖于使用基于标注数据的有监督学习提高模型的处理能力。目前,许多模型是使用单一语言(通常是英语)训练的,并不能直接应用于其他语言。鉴于收集每种语言的语料数据是不现实的,因此如何实现跨语言句子理解(XLU)和低资源的跨语言迁移得到了越来越多的关注。XNLI论文进一步将多类型自然语言推理语料库(MultiNLI)的开发和测试集扩展到15种语言,其中甚至包括斯瓦希里语和乌尔都语等低资源语言,构建了一种用于XLU的基准测试数据集。此外,XNLI数据集还提供了一些标准的评估任务,可促进对跨语言句子理解的研究。
作者: Facebook AI研究院和纽约大学研究团队
正文:
近期,EMNLP 2018收录的一篇论文“XNLI: Evaluating Cross-lingual Sentence Representations”得到了Yann LeCun的关注,他转发并推荐了该论文提供的公开数据集XNLI(Cross-lingual Sentence Representations)。XNLI是Facebook AI研究院(FAIR)和纽约大学研究团队的一项合作研究成果,它提供了一种用于评估跨语句表征的数据集。自然语言处理系统依赖于使用基于标注数据的有监督学习提高模型的处理能力。目前,许多模型是使用单一语言(通常是英语)训练的,并不能直接应用于其他语言。由于收集每种语言的语料数据是不现实的,因此如何实现跨语言句子理解(XLU)和低资源的跨语言迁移得到了越来越多的关注。这篇论文进一步将多类型自然语言推理语料库(MultiNLI)的开发和测试集扩展到15种语言,其中甚至包括斯瓦希里语和乌尔都语等低资源语言,构建了一种用于XLU的基准测试数据集。对该论文感兴趣的读者,可访问XNLI项目主页下载数据集。据XNLI主页介绍,项目源代码也将于近期公开。
XNLI数据集提供了一些标准的评估任务,意在促进对XLU的研究。此外,XNLI还给出了多语言句子理解的多种基线方法,其中两种基线方法基于机器翻译系统,另外有两种基线分别使用了并行数据(parallel data)训练对齐的多语言词袋和LSTM编码器。论文给出了与基线的对比实验,表明XNLI具有更优的性能。本文将对XNLI的预发表ArXiv论文进行解读。
研究现状与挑战
当前,自然语言处理系统通常依赖标注数据去训练模型。常见的训练数据主要集中于英语和中文等单一语言,系统也只能在训练所用的语言中执行分类、序列标注、自然语言推理等任务。一款实用的国际化产品需要处理多种语言输入,但是为所有的语言分别生成标注的数据集是难以实现的。为此,一些研究提出了跨语言语句理解(XLU,cross-lingual Language Understanding)去构建多语言系统。使用XLU的系统主要使用一种语言去训练模型,并在其它语言上评估模型。尽管一些XLU研究在跨语种文档分类上给出了较好的结果,但目前XLU对自然语言推理(NLI,Natural Language Inference)等一些更难以理解的任务依然缺少基准测试数据集。大规模NLI,即文本蕴含识别(RTE,Recognizing Textual Entailment),业已成为评估语言理解的实际测试平台。在RTE中,系统读取两句话,并判定两者间的关系是否为“蕴含”(Entailment)、“矛盾”(Contradict)或“中性”(Neutral)。近期,一些众包的标注工作已生成了具有上百万实例的英语数据集,并在评估神经网络结构和训练策略、训练效果、可重用句子表征等任务中得到了广泛的应用。
该论文给出了一种称为XNLI(Cross-lingual Natural Language)的数据集。XNLI将NLI数据集扩展到15种语言,包括英语、法语、西班牙语、德语、希腊语、保加利亚语、俄语、土耳其语、阿拉伯语、越南语、泰语、中文、印地语、斯瓦希里语和乌尔都语,并以NLI的三分类格式为每种语言分别提供了7500个经人工标注的开发和测试实例,合计112500个标准句子对。XNLI中包括的语言跨越了多个语系,特别还包括了斯瓦希里语和乌尔都语这两种语料资源稀缺的语言。XNLI设计用于评估XLU,即使用一种语言训练模型,并在另一种语言上测试模型。论文使用来自公开可用语料库中的并行数据进行自然语言推理,对多种跨语言学习方法做了评估。论文的实验结果显示,并行数据有助于对齐多种语言中的句子编码,这种对齐机制给出了非常好的结果,使得用英语NLI训练的分类器可以正确地用于其它语言句子对的分类任务。XNLI的另一个实践用于评估预训练的(pretrained)语言通用(language-universal)句子编码器。该基准测试有助于研究领域构建多语言文本嵌入空间,进而推进多语言系统的建立,实现在无监督或有很少监督的情况下实现语言间的迁移。
从相关的研究看,目前对多语言理解的工作主要停留在词的层面,即多语言词嵌入。一些方法提出了学习跨语言词表示,即在嵌入空间中的词表示具有很近的翻译距离。还有一些方法需要做一定程度上的有监督学习,在同一空间中对齐源和目标嵌入。近期一些研究提出了无监督的跨语言词嵌入。在句子表征学习方面,一些方法提出将词嵌入扩展到句子乃至段落表征。生成句子嵌入的最直接方法是使用词表征的平均或加权平均,此类方法称为连续词包法(CBOW,Continuous Bag-Of-Words)。尽管CBOW类方法理念比较原始,但是它们通常能提供很好的基线。一类更复杂的方法是捕获句子表征中在语义和语法上的依赖性。尽管此类固定大小的句子嵌入方法在性能上要优于相应的有监督学习方法,但是一些近期研究表明,预训练的语言模型在一定的条件下也可实现很好地迁移。此外,一些研究关注了多语言句子表征问题。有研究训练双语自动编码器,目标是最小化两种语言间的重建错误。还有研究提出在多种语言上联合训练Seq2Seq机器翻译系统,学习共享的多语言句子表征。
在跨语言评估基准测试方面,可以说基准测试的缺乏已经妨碍了多语言表征的发展。大量前期提出的方法在评估中使用的是Reuter跨语言文档分类语料。但是,该语料中的分类是在文档层面实现的,由于存在多种聚合句子嵌入的方法,非常难以比较不同句子嵌入。此外,Reuters语料中类的分布是高度不平衡的,数据集并不提供目标语言的开发集,这使得测试更加复杂。此外,Cer等人在2017年提出一种句子层的多语言训练和评估数据集,实现四种语言在语义上的文本相似性。还有研究通过翻译英语数据集或是从并行语料中标注句子,构建了一种多语言RTE数据集。最近有研究给出的SNLI数据集是通过人工翻译为阿拉伯语、法语、俄语和西班牙语而构建了1332个句子对。与上述研究相对比,XNLI是首个用于评估句子层表征的大规模多语言语料库。
XLNI数据集
XNLI同样使用了构建Multi-Genre NLI语料库所用的众包方法。它从Multi-Genre NLI语料库使用的10个文本源中分别收集并验证了750新实例,合计7500个实例。以这部分数据为基础,XNLI工作聘请了一些专业翻译者,将这些实例分别翻译为10种目标语言,由此创建了完整的XNLI语料库。采用对每种语言分别翻译而非生成新的假设句子的做法具有多个好处。首先,这种做法确保了在各个语言间的数据分布的相似性最大化,避免了添加不必要的由人工表达所导致的自由度。第二,它使用了同一组受信任的人,无需为每种语言训练新的一组人工。第三,它支持每种语言所对应的假设。这使得XNLI中包括了150万假设(Hypothesis)和前提(Premise)的组合,具有支持评估各语言间对齐情况的能力。
但是,使用人工翻译过程也存在一些风险,主要问题在于两种语言对之间的语义关系可能会在翻译中丢失。论文指出,他们针对此问题作了一些统计,结果表明XNLI中只有少到可以忽略不计的部分受此问题影响。
数据收集
XNLI中英语语料的采集使用了和MultiNLI语料同样的方法。它从指定的10个文本源的250个句子中做抽样,这确保了所得到的句子不会与语料的分布产生重叠。在得到句子之后,研究者询问生成MultiNLI语料的众包平台上的同一人,为每个的前提生成三个假设的标记,然后将前提语句按MultiNLI使用的同一模板展示给标记生成者,并做验证。验证后重标记的句子会指派给四个人做重标记。结果表明,其中93%的数据的标记是一致的(即四个人中有三人仲裁一致)。此外7%的数据也保留,并用“-”做特殊标记。
得到标记的句子后,XNLI工作聘请了翻译者,将句子分别翻译为十五种语言,其中前提和假设是分别翻译的,以确保在假设中只是从英语句子中拷贝了标记,没有添加任何额外的上下文。图一给出了所得到结果的部分实例。
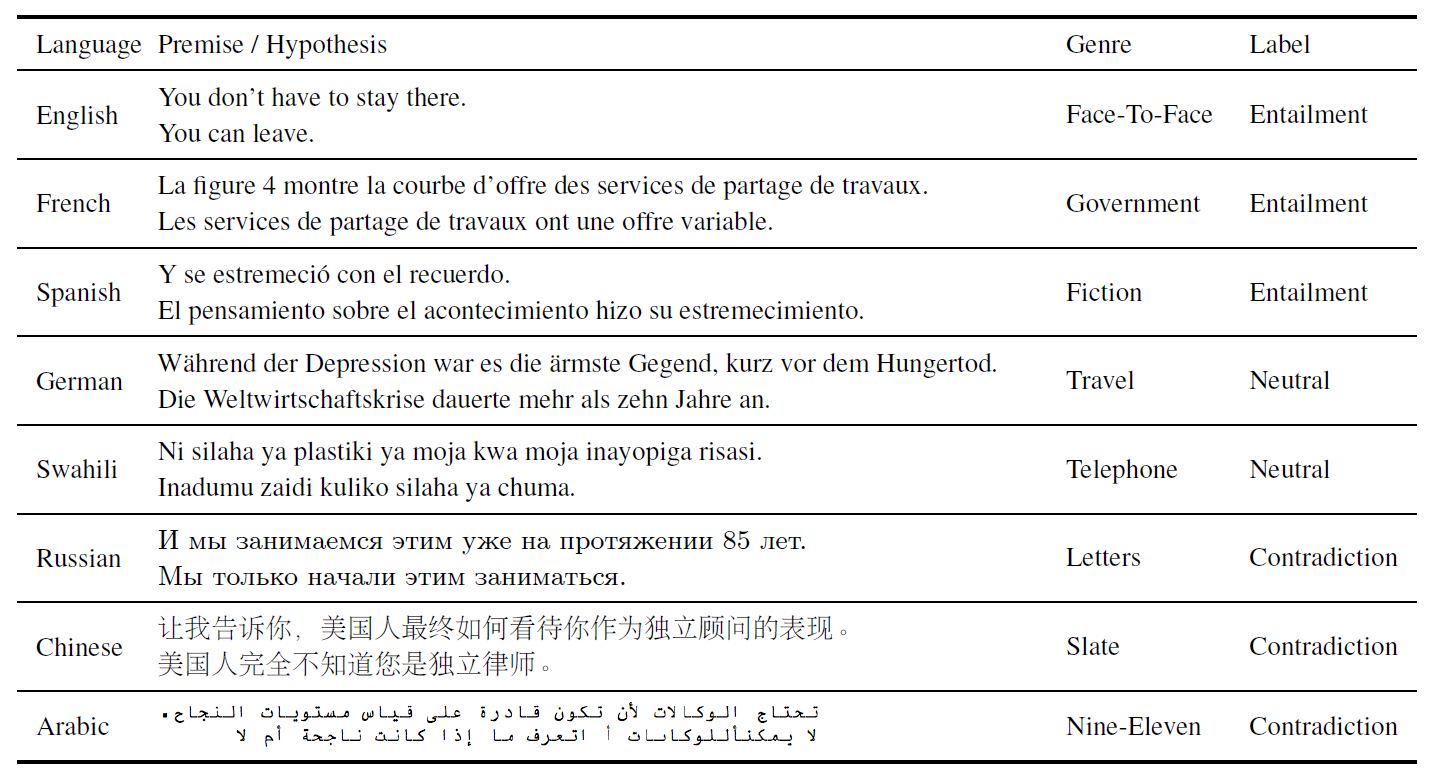
图一 XNLI中各种语言和文体的部分实例,其中包括了前提和假设
生成语料库
在生成语料库时,一个重要的问题是确定一些句子对的金标记(gold label)是否由于添加信息和翻译过程而发生了改变。论文提及,XNLI研究者在手工查看数据时,发现一个句子对在英文-中文翻译中由“蕴含”关系变成了“矛盾”关系,而该句子在翻译为其它语言时标记则未发生变化。为定量地确定该问题在XNLI中出现的规模,在论文工作中,英语-法语双语人工标注者从数据源中非重叠随机抽取并重新检查了100个实例。从整体情况看,在没有任何训练过程和Burn-in过程的情况下,标注者可以从85%的原始英语句子中得到与仲裁结果一致的标注,在翻译得到法语句子上标注有83%是一致的。这是由于语料中的很多句子相对易于翻译,尤其是人工得到的假设文本,因此在翻译过程中不太可能添加歧义。扩展到整个语料库,研究指出生成的XNLI具有和MultiNLI相似的属性。如图二所示,对于所有语言,前提平均会比假设的文本长两倍。词的重要性使用语料库中每个词和类的互信息打分,假设中最重要的词所显示的类标记,在所有语言对应的句子中是一致的,并且与MultiNLI语料库也是一致的。

图二 XNLI数据集中每种语言的每个句子中的平均Token个数
当前版本的XNLI中的大部分句子以OANC许可公开提供,可自由使用、修改和共享。
跨语言NLI
实现XLU的最直接方法是使用已有的翻译系统。有两种使用翻译系统的方式,一种方式称为“翻译训练”(Translate Train),其中将训练数据翻译为每种目标语言,作为提供给训练每个分类器的数据。另一种方式称为“翻译测试”(Translate Test),其中翻译系统只在测试中使用,用于将输入句子翻译为训练所用语言。这两种方式都可以作为很好的对比基线,但是在实践中都存在一些挑战。前者需要训练和维护使用同一目标语言数据的分类器,而后者在测试时依赖于计算强度很大的翻译。两者都受限于翻译系统的质量,而翻译系统本身则受限于可用的训练数据,以及所用语言句子对之间的相似性。
多语言句子编码器
与之相对比,另一种方法是使用文本的语言通用嵌入(language-universal encoder),并根据表征构建多语言分类器。如果编码器生成英语句子的嵌入与翻译为其它语言的句子嵌入是非常相似的(即在嵌入空间中距离很近),那么在英语句子嵌入上训练的分类器就可以迁移到用于分类其它语言的句子,实现无线翻译系统的推理任务。
论文对两类跨语言句子编码器做了评估。一类方法使用了基于词嵌入均值的预训练通用多语言句子嵌入X-CBOX,另一类方法是在MultiNLI训练数据上训练的双向LSTM句子编码器X-BILSTM。X-COBW评估了迁移学习,而X-BILSTM则评估了使用领域内数据训练的特定NLI编码器。两类方法在对齐多语言句子嵌入空间时使用了同一种对齐损失函数。两类方法在从BiLSTM中抽取特征向量时,前者使用了最初的和最终的隐含状态,后者使用的是所有状态的逐元素最大值(element-wise max)。
第一类方法通常作为一种很好的单语言语句嵌入的对比基线。在实现中,论文使用了英语FastText词嵌入空间,作为一种固定的、良好调优的到其他语言的嵌入,这样句子中词向量的均值非常接近于句子的英语翻译词向量。第二类方法使用MultiNLI训练数据学习的英语句子编码器和目标语言上的编码器,目标是使得两种翻译的表征在嵌入空间中的距离非常近。在这两类方法中使用了固定的英语编码器,训练目标语言的编码器,匹配编码器的输出,构建同一空间中的句子表征。当然,对于改进并简化句子嵌入空间,还可以考虑编码器的联合训练和参数共享等方法,这也将作为该论文的进一步工作。
对齐词嵌入
多语言词嵌入是一种高效的语言间知识迁移方法。论文使用了跨语言嵌入直接实现对齐句子层编码器。跨语言嵌入可以在非常少的监督情况下高效地生成。论文通过使用一个具有五千个词对的小型并行字典,学习了一个线性映射去最小化代价函数:
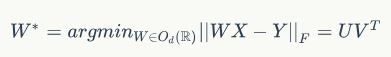
其中,d是嵌入的维度;X和Y分别是形状为(d,n)的矩阵,对应于出现在并行字典中的对齐词嵌入;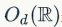 是一组维度为d的对角矩阵;U和V是由
是一组维度为d的对角矩阵;U和V是由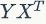 做SVD得到,即
做SVD得到,即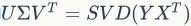 。一些现有研究表明,在词翻译任务中对线性映射强制对角约束将,将会给出更好的结果。
。一些现有研究表明,在词翻译任务中对线性映射强制对角约束将,将会给出更好的结果。
通用多语言句子嵌入
已有对通用句子表征的学习基本都是基于英语的。虽然一些研究中也考虑了使用公开可用的并行语料库构建对多种语言可共享的句子编码器,但是面对缺少大规模句子曾语义评估,限制了这些方法的应用。这些方法所考虑的语言规模都没有XNLI广泛,并局限于一些具有丰富资源的语言。我们考虑使用CBOW编码器的Common Crawl嵌入。我们的方法考虑翻译词的CBOW表征对在嵌入空间中具有很近的距离。认为多语言句子日安全是预训练的,并只在其上学习分类器,并评估分类器的性能,这类似于在多语言环境中的迁移学习。
对齐句子嵌入
相比于翻译源句子和目标句子对的方法而言,在嵌入空间中训练两者间相似度的方法从概念上更易于理解,计算复杂度也更低。论文提出了一种训练跨语言相似度的方法,并验证了对齐句子表征任务评估方法的有效性。两个并行句子的嵌入可能并不相同,但是它们在嵌入空间中可能具有非常近的距离,这种距离上的相似性可用英语分类器的决策边界捕获。
为了对齐两种不同语言的嵌入空间,论文提出了一种简单的对齐损失函数。在NLI上训练英语编码器是,采用了最小化损失函数
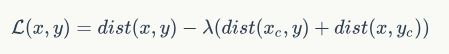
训练目标编码器。其中,对应于源句子嵌入和目标句子嵌入;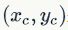 是对比词(即负向抽样);λ控制了损失函数中负向实例的权重。距离函数使用了L2范数
是对比词(即负向抽样);λ控制了损失函数中负向实例的权重。距离函数使用了L2范数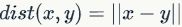 。排序损失(Ranking Loss)采用:
。排序损失(Ranking Loss)采用:
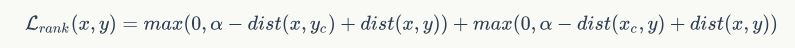
这使得翻译句子对的嵌入间距离,比导致不好结果的负向句子对嵌入间的距离更近。不同于 ,为使得共享分类器可以理解具有同一意思的句子,
,为使得共享分类器可以理解具有同一意思的句子, 并不强制句子对的嵌入距离必须足够近。
并不强制句子对的嵌入距离必须足够近。
论文对跨语言基线X-CBOW、X-BILSTM-LAST和X-BILSTM-MAX使用了。对于X-CBOW,编码器是预训练的,但是没有在NLI上调优(即做迁移学习),而BILSTM的两个英语基线是在MultiNLI训练集上做了训练。在上述三个基线方法中,英语编码器和分类器是固定的。其它十四种语言分别具有自己的编码器,它们具有相同的结构。编码器使用损失函数和并行数据在英语编码器上训练。句子嵌入对齐方法如图三所示。
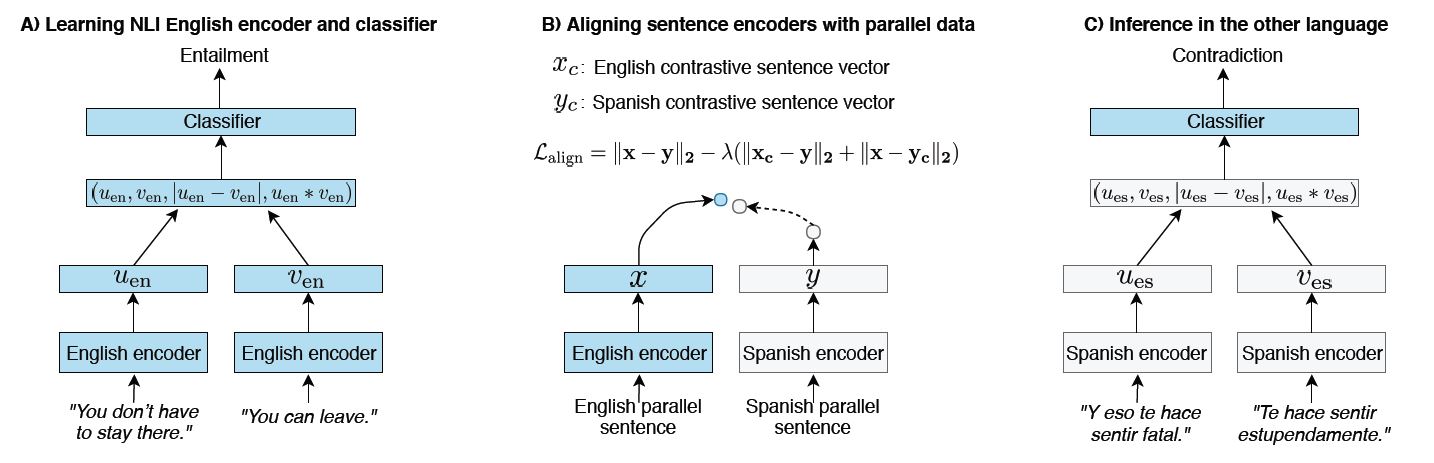
图三 图示使用句子嵌入对齐的语言
实验
在实验中,翻译系统使用的是Facebook内部的一种翻译系统,将英语句子翻译为其它十种语言。图四给出了“翻译测试”方法下的翻译情况,其中每个训练集都翻译为英语句子。使用“翻译训练”方法翻译MultiNLI的英语训练数据,翻译质量以BLEU分值给出,如图六实验结果所示。大部分语言的分词使用了MOSES,中文使用了Stanford分段,泰语使用了pythainlp软件包。
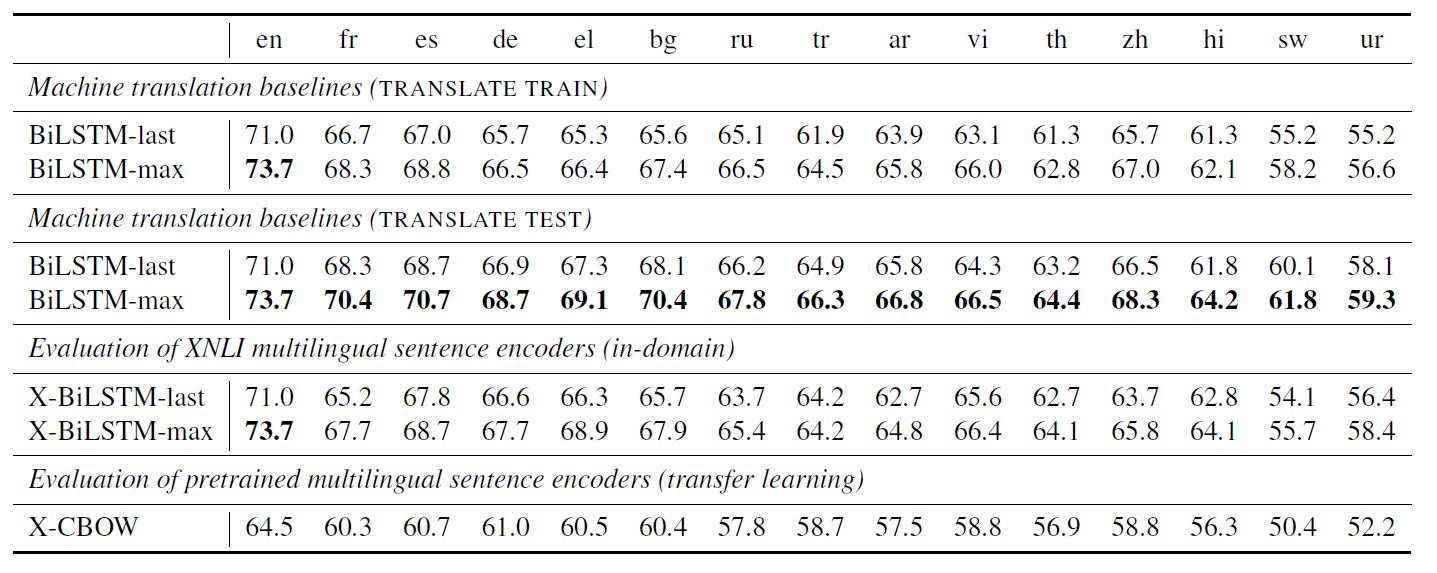
图四 十五种语言的XNLI测试准确率
X-CBOW和X-BILSTM使用预训练的300D对齐词嵌入,只考虑了词典中最频繁的50万个词,通常可覆盖XNLI数据集中98%的词。对于BiLSTM基线,隐含单元数量设置为512,使用Adam优化器作为默认参数。分类器接收参数向量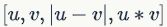 ,其中u和v分别是共享编码器给出的前提和假设的嵌入,“*”对应于逐元素乘积运算。对齐损失函数中设置λ=0.25,考虑了正向和负向对重要性之间的权衡情况,如图七实验结果所示。
,其中u和v分别是共享编码器给出的前提和假设的嵌入,“*”对应于逐元素乘积运算。对齐损失函数中设置λ=0.25,考虑了正向和负向对重要性之间的权衡情况,如图七实验结果所示。
负向实例采用随机抽样获得。将目标BiLSTM编码器拟合到英语编码器中,论文在保持源词嵌入固定的情况下,调优了目标编码器关联的查找表(looup table)。分类器使用了前向反馈神经网络,其中隐含层具有128个隐含单元,使用0.1丢弃率的Dropout做规范化。对于X-BiLSTM,对每种语言在XNLI验证集上执行模型选择。对于X-CBOW,保留并行语句上的验证集,用于评估对齐损失。但是在确定对齐的损失时,需要每种语言对中句子的并行数据集。
并行数据集
论文使用公开可用的并行数据集,学习英语和目标编码器之间的对齐。对于法语、西班牙语、俄语、阿拉伯语和中文,使用UN语料库。对于德语、希腊语和保加利亚语,使用了Europarl语料库。对于土耳其语、越南语和泰语,使用了OpenSubtitles 2018语料库。印地语使用了IIT Bombay大学的语料库。所有上述的语言对,都可以收集到超过50万并行语句,论文实验中设置了最大并行语句数量为200万。但是对于资源匮乏的语言乌尔都语和斯瓦希里语,并行句子的数据量要呈数量级地小于其它语言。乌尔都语使用了圣经和可兰经文本、OpenSubtitles 2016和2018、LDC2010T21、LDC2010T23LDC语料库,得到合计6.4万并行句子。斯瓦希里语使用了Global Voices和Tanzil可兰经文本语料库,只能收集到4.2万条并行句子。
对比分析
图五给出了语言间性能情况。使用BiLSTM时,BiLSTM-max的性能总是优于BiLSTM-last。而BiLSTM类基线普遍优于CBOW类基线方法。BiLSTM编码器也优于CBOW,即便是在MultiNLI训练集上调优了词嵌入。该实验说明,正如前期一些研究所指出的,NLI任务需要的不仅仅是词的信息。
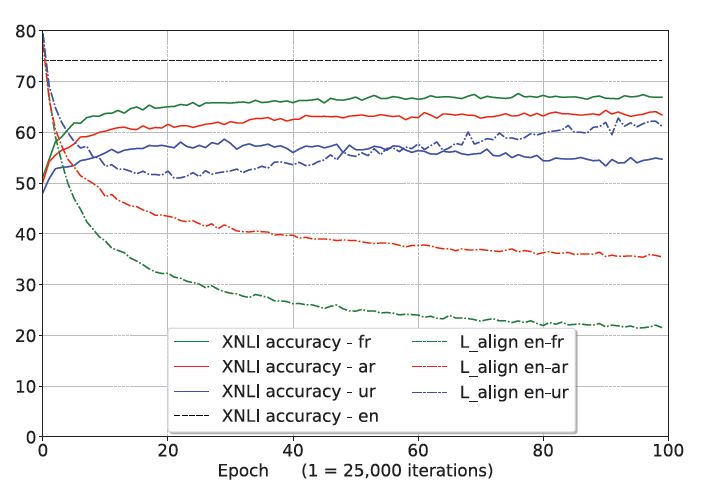
图五 各类方法训练中对齐损失的变化情况,观测到的与准确性的关系
图六显示了翻译给出的XLU的基线。“翻译测试”方法在所有语言上看上去总是优于“翻译训练”。在评估中,最优的跨语言结果来自于“翻译测试”。在使用翻译方法时,跨语言性能取决于翻译系统的性能。事实上,基于翻译的结果与翻译系统的BLEU分值具有很好的相关性。导致性能偏差的主要原因包括翻译误差、文风变化,以及由翻译系统引入的训练与测试数据集之间的差异。

图六 多语言词嵌入训练模型(XX-En) P@1的BLUE分值
对于跨语言性能,实验观察到英语结果和其它语言的结果存在这一定差距。图六显示了在三种语言上的验证准确性,其中使用了具有不同训练超参数的BiLSTM-max。调优嵌入并未显著地影响结果,这表明LSTM本身就确保了并行句子嵌入的对齐。
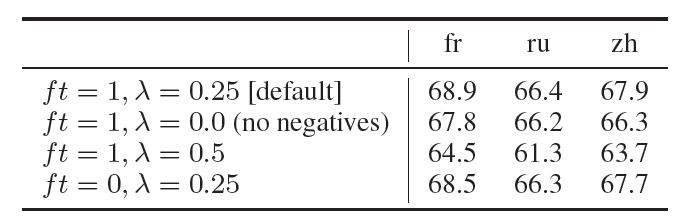
图七 使用BiLSTM-max情况下的验证准确性
结论
缺少英语以外其它语言(尤其是一些资源匮乏语言)的语料库,这是工业级应用中面对的一个现实问题。考虑到为每种语言生成标记数据是不现实的做法,因此在各语言场景下的跨语言理解和低资源迁移得到了广泛的关注。XNLI论文的工作扩展了MultiNLI语料库到十五种语言,设计用于解决在跨语言理解中缺少语料库的问题,并希望能有助于研究社区进一步推动这一领域研究的发展。论文还给出了对多种基于跨语言编码器和翻译系统的评估。虽然机器翻译基线在实验中给出了最优的结果,但是这些方法在训练和测试中依赖于计算强度很大的翻译模型。
查看英文原文: XNLI: Evaluating Cross-lingual Sentence Representations
