@Rays
2018-05-22T10:16:34.000000Z
字数 7766
阅读 2588
实现用于大规模机器学习的动态控制流
论文导读
摘要: 论文介绍了一种使用动态控制流实现机器学习的编程模型。该模型在设计中使用新的原语表示数据流图中的分支和循环基本计算,以支持更细粒度的分区使用CPU、GPU及TPU等定制ASIC计算,实现在异构设备间的并发和分布执行。模型支持使用分支和循环表示自动微分和分布式梯度计算的数据流通,实现应用在多设备间的频繁控制流决策。该模型已经实现在TensorFlow中,并得到了广泛地使用。在实际生产集群中的基准测试,表明了模型实现系统的性能和扩展性满足实际应用的需求。
论文标题: Dynamic Control Flow in Large-Scale Machine Learning
作者: Yuan Yu,及Google Brain团队
编译: 盖磊
正文:
一些最新机器学习模型,特别是RNN和强化学习,其训练和推理中使用了细粒度的动态控制流。在这些模型中,循环体执行和依赖于数据的条件执行需要动态控制流的支持,实现在分布异构环境各计算设备(包括CPU、GPU,以及TPU等定制的ASIC)间作快速的控制流决策。出于性能、可扩展性和运算表达能力上的考虑,现代机器学习系统应该支持分布式异构计算环境中的动态控制流。
本文是一篇EuroSys 2018会议接收论文,主要完成人来自于Google Brains团队,该团队实现并开源了TensorFlow系统。

论文工作的主要贡献来自Yuan Yu(本文工作主要完成于在Google Brain工作期间),以及Google Brain团队Jeff Dean等。
论文提出了一种支持动态控制流的分布式机器学习编程模型,并介绍了该模型的设计及在TensorFlow中的实现。为表示机器学习运算,编程模型对数据流图(data graph)做了扩展,实现了多个显著的特性。第一,该编程模型支持对数据流图的细粒度分区,实现了在多个异构设备上运行条件分支和循环体;第二,使用该模型编写的程序支持自动微分(automatic differentiation)计算和分布式梯度计算,这些计算是训练机器学习模型训练所必须的;第三,模型采用了非严格语义(non-strict semantics),支持多个循环迭代在设备间的并行执行,实现了计算和I/O操作的交叠(overlapping)。
背景
机器学习及应用的突飞猛进,对支持运算的底层系统提出了新的挑战。人们希望计算系统可扩展运行于不同设备 上,小到个人的智能手机,大到整个数据中心,并有效地利用各种计算资源,包括CPU、GPU,以及TPU等定制ASIC。
图1给出的是Google自然语言处理所用模型的一个简化架构,其中包括了两个RNN层,以及一个提供RNN层间动态学习连接的MoE(混合专家,Mixture of Experts)层。架构中的各个组件可运行在不同的设备上,其中使用了基本的动态控制流。计算的不同实现策略,对模型的性能具有很大的影响。例如,实现高性能RNN的挑战在于如何权衡内存的使用和计算时间。如果使用多GPU的分布式计算,在GPU间交换张量可降低对内存的使用,这为权衡添加了新的维度。
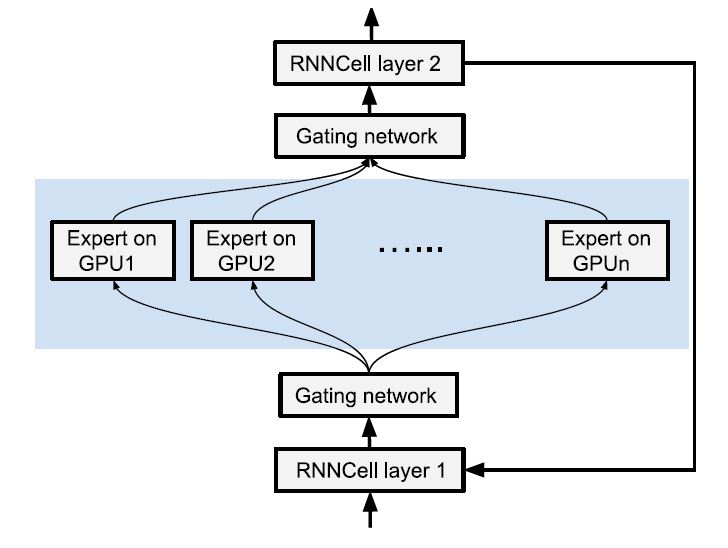
图1:一个模型架构例子
当前,机器学习的构件模块(例如,上例中的单个单元),以及使用这些模块所组成的架构,都正在快速地发展中,并且这一趋势也将继续。与将RNN、MoE等特性层实现为编程模型原语的方法相比,一种更好的做法是实现通用的控制流构件,例如,分支条件和循环计算。一个机器学习系统,应该提供一种通用的动态控制流机制。
在现代机器学习架构中,通常将计算表示为数据流图,并由一个客户进程驱动一组加速器(accelerator)执行各个构件的计算。所使用的方法可以分为两大类:
- 图内实现方式(in-graph):控制流的决策和操作是编码实现在数据流图中的;
- 图外实现方式(out-of-graph):由独立的客户进程实现控制流决策,而操作则使用Python等主机语言提供的控制流原语实现。
在TensorFlow的设计中,采用了图内方式。图内方式在编译和运行时间上具有优势。对于运行机器学习模型的集群而言,模型处理统一的数据流图,因此可以优化整个程序。特别是,图内方式可以确定模型运算中间结果的轻重缓急,并据此作出决策,是否需要缓存中间结果。此外,图内控制方法支持在系统运行时内执行整个计算,这非常适合于异构环境,因为在异构环境中客户进程间的通信和同步的代价非常大。如果不使用图内动态控制流特性,那么TensorFlow程序必须使用Python等主机语言所提供的控制流特性。对于循环计算而言,图内方式比图外方式可获得更大的并行性。基于本文的实验结果,对于一台具有8个GPU的单机,每秒迭代次数可实现五倍的提升。
论文的主要工作可归纳为:
论文提出了五种简单并强大的原语,支持高层控制流构件进一步编译为新的原语,实现了更细粒度的数据流图分区,进而可通过轻量级的协调机制在一组异构设备上执行。
模型支持自动微分和梯度计算。自动微分是机器学习模型训练中的重要技术。论文所提出的编程模型,支持在数据流图中添加计算梯度的子图,并实现了计算的优化和内存管理技术。计算子图也可进一步分区运行在多台设备上。
模型支持并行和异步,提供了非严格语义操作,一旦输入可用时,即调用相应的操作,实现调节分支和循环操作。这种设计支持了CPU上的控制流逻辑、GPU上的计算内核和CPU与GPU间的内存拷贝间的交叠。
论文提出的编程模型已实现在TensorFlow中,并已成功应用于Google去年超过1170万的机器学习任务,其中近65%的任务包含一个以上的循环。结果显示,模型的性能和可扩展性适合于真实系统上的真实应用。
编程模型
出于性能和异构运行的需要,TensorFlow核心运行时使用C++实现。TensorFlow对多种语言提供了API,这提供了构建数据流图的高层接口,并可管理数据流图在一组设备上的执行。TensorFlow运行时负责执行数据流图。为支持异构系统上的分布式执行,TensorFlow具有一个中央协调器(coordinator),它自动将图中的节点映射为一组设备。并将图中的边替换为一对通信操作,Send(t,k)和Recv(k)。通信操作对共享同一约会密钥k,传递张量t。数据流图分区后,每个子图将提交给相应的设备,由设备本地运行的执行器执行。各个本地执行器间使用Send(t,k)和Recv(K)通信,无需中央协调器参与。张量t一旦生成并需要在设备间传递,Recv(K)即可从发送设备拉取。
在数据流图中引入动态控制流,提出了一些额外的挑战。如果不存在控制流,那么图中的每个操作只会执行一次,每个值具有唯一命名,并且通信对使用唯一的约会密钥。但是如果存在控制流,例如循环,那么一个操作将可能多次执行。这时不能做唯一命名和唯一密钥,它们必须动态生成,以区分对同一操作的多次调用。
条件分支计算
cond(pred,true_fn,false_fn),其中pred是一个布尔张量,true_fn和false_fn是子图的构成函数,返回一个张量元组。cond返回一个张量元组,表示执行条件分支计算的结果。它仅使用了Switch、Merge。循环计算
while_loop(pred,body,inits)表示了一个迭代计算,其中pred和body是子图中循环计算的构成函数,分别是循环终止条件和循环体,输入参数为循环变量元组,body返回更新后的循环变量元组。inits是一个张量元组,指定循环变量的初始值。图3是while循环的实现。
TensorFlow的一个特性是不对分区做任何限制。无论图的拓扑如何,只要设备有能力运行相关操作,就可将操作赋予该设备。分区条件分支和循环体也可以任意分区,并运行在多个设备上。因此,必须在条件分支计算中实现通知机制,用于告知任何等待Recv的未执行操作重新请求资源。而对于迭代操作,必须实现一种机制,告知参与循环的分区是启动下一轮计算,或是终止计算。
设计与实现
模型设计中的关键点在于:如何用原语表示数据流图中的分支和循环基本计算,以支持更细粒度的分区;如何用分支和循环表示自动微分和分布式梯度计算;如何提高模型的处理能力。
控制流原语
在模型的设计上,论文考虑提供一小组灵活的、有表现力的原语,作为计算数据流模型中高层控制流构件的编译目标。模型给出了五个控制流原语,分别是Switch、Merge、Enter、NextIteration和Exit,如图2所示。高层控制流构件可编译为由上述控制流原语组成的数据流图,进而实现数据流图的细粒度分区。
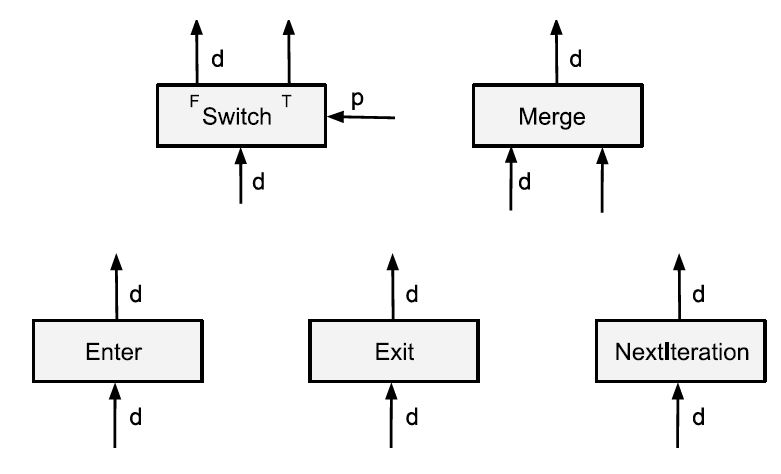
图2:控制流原语
使用论文提出的原语,可将while_loop(pred,body,inits)表示为如下数据流图。
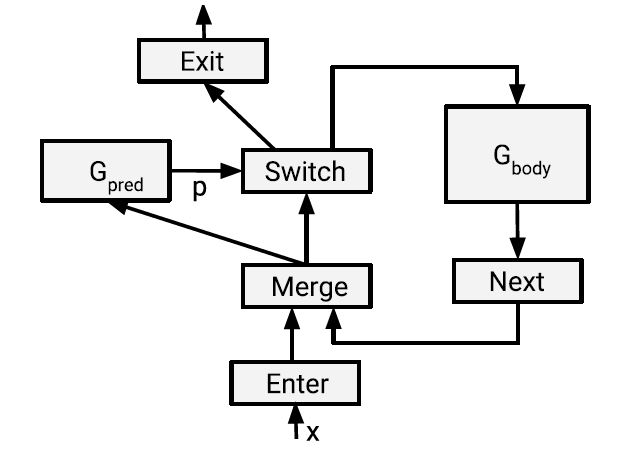
图3:While循环的数据流图
当本地执行一个数据流图时,分区子图中的所有Recv节点视为输入节点。一旦源节点的输入就绪就执行节点(Merge除外)。如果数据流图中没有控制流构件,那么每个节点只执行一次。当所有节点完成后,执行完成。如果存在控制流构件,动态控制流引入了新的复杂性。一个节点可能会被多次执行。执行器必须管理同一操作的多次执行实例,并根据终止条件判定整个执行的结束。因此,本地执行器需要重新设计,以处理动态控制流。为处理同一操作不同调用所产生的不同张量,执行器内每个张量表示为tuple(value,isdead,tag),其中value是张量的值,is_dead是表示张量是否是Switch未处理分支的布尔值,tag是全局唯一的张量标识符。在TensorFlow中,每次循环迭代启动一个新的帧(frame),在每个帧中,一个操作最多执行一次。因此,tag可以区分不同迭代所生成的张量。这对于正确的Send和Recv操作十分关键,因为tag就是约会密钥。
当分布式执行一个数据流图时,由于数据流图被分区为多个子图,实现动态控制流的挑战在于条件分支或循环体子图被分区到不同的设备上。设计中,每个执行器在执行分区时是独立相互通信的,无需中央协调器的参与。在循环执行时,无需设备间的同步,否则将会极大地限制并行性。本地执行器间通过Send和Recv通信,中央协调器只有在事件完成或失败时才参与。
对于条件分支,未选取分支上的Recv操作一直处于等待状态,并阻塞执行,以免重新申请资源。如果相应的Send操作并未执行,将在设备间从Send到Recv传播is_dead信号。如果Send-Recv操作对很多,传播会导致性能开销。这种情况尽管很少发生,但是需要对此做一些优化。
对于循环的分布执行,在每次迭代中,每个分区需要知道是继续执行,还是需要退出。在实现中,模型将自动重写数据流图为简单的控制状态机。图4显示了在两个设备间分区一个基本的while_loop的情况。循环体包括一个分配给设备B的Op操作。这样,在B的分区中,添加了一个循环控制状态机,用于控制循环体中的Recv操作。图中的点虚线是控制边,它确定了操作的执行顺序。循环体分布式执行的开销在于,每次迭代中每个参与设备需要从生成循环条件的设备上接收一个布尔值。由于通信是异步的,循环条件的计算通常要领先于其余计算。因此从整个模型看开销是很小的。例如,对于GPU执行器,控制流决策是由本机GPU的本地执行器做出的。这样,本地执行器对于计算和I/O操作是完全并发运行的,并使用各自的资源。因此,动态控制流可以给出与静态展开(static unrolling)相同的性能(静态展开是在定义模型创建数据流图的时候,序列的长度是固定的,之后传入的所有序列的长度都必须是定义时指定的长度。内存的使用,随序列长度呈线性增长)。
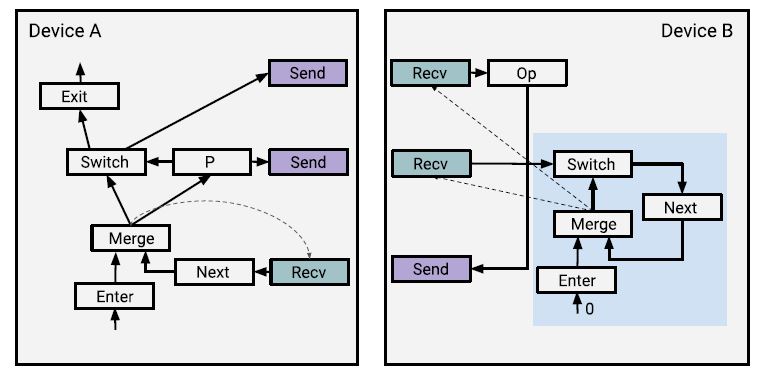
图4:while_loop的分布式执行
自动微分的实现
在机器学习算法中,常使用基于梯度的方法优化一组参数。模型训练期间,近大半的计算时间是用于梯度计算的。因此,提高梯度计算的效率和扩展性非常关键。TensorFlow支持自动微分计算。给定一个表示了神经网络计算的数据流图,TensorFlow将生成实现分布式梯度计算的高效代码。下面介绍如何将自动微分计算表示为控制流构件。
TensorFlow提供了一个反向自动微分库(autodiff),实现了后向传播算法。下面介绍如何支持cond和while_loop构件。tf.gradients()函数计算标量函数的张量,其中是一组张量参数,算法实现了向量的链式法则(chain rule)。图5给出了梯度函数G(Op)的数据流图结构,函数依赖于的偏微分,偏微分基于原始Op函数输出及输入,即以张量表示的矩阵和。由于和要被梯度函数G(Op)使用,因此在操作执行期间需要一直保持在内存中。由此所导致的内存占用,是影响深度神经网络训练能力的一个关键因素。
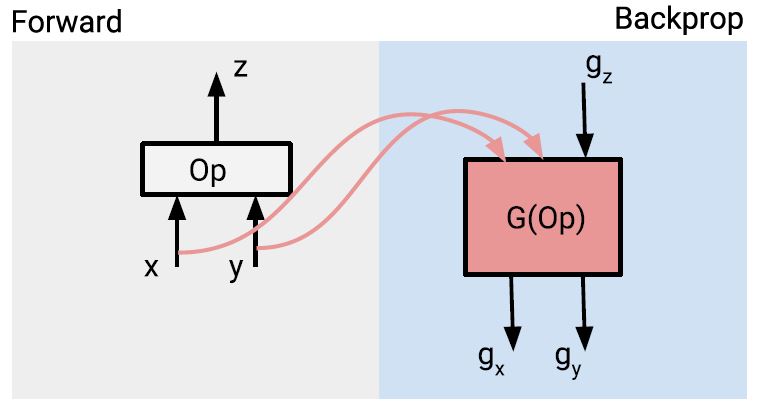
图5:操作Op及其梯度函数G(Op)
那么动态控制流构件是如何支持TensorFlow的autodiff算法执行后向传播的?数据流图中,每个操作关联到一个“控制流上下文”,它指定了最内层的控制流构件,其中的操作是由各个构件组成。当后向传播变量首次遇上的新控制流上下文时,它就在梯度计算数据流图中生成一个相应的控制流构件。这样,输出梯度g_z的操作tf.cond(pred,true_fn,false_fn),其梯度为tf.cond(pred,true_fn_grad(g_z),false_fn_grad(g_z))。而对于tf.while_loop(cond,body,loop_vars),下面的代码显示了如何静态展开循环体,并对tf.matmul()和tf.reduce_sum()应用梯度计算函数。
w = tf.Variable(tf.random_uniform((10, 10))x = tf.placeholder(tf.float32, (10, 10))a_0 = xa_1 = tf.matmul(a_0, w)a_2 = tf.matmul(a_1, w)a_3 = tf.matmul(a_2, w)y = tf.reduce_sum(a_3)g_y = 1.0g_w = 0.0# 广播reduce_sum的梯度。g_a_3 = tf.fill(tf.shape(a_3), g_y)# 应用MatMulGrad()三次,累加g_w.g_a_2 = tf.matmul(g_a_3, tf.transpose(w))g_w += tf.matmul(tf.transpose(a_2), g_a_3)g_a_1 = tf.matmul(g_a_2, tf.transpose(w))g_w += tf.matmul(tf.transpose(a_1), g_a_2)g_a_0 = tf.matmul(g_a_1, tf.transpose(w))g_w += tf.matmul(tf.transpose(a_0), g_a_1)
可以看到,前向循环的中间结果a_1、a_2和a_3将在梯度计算循环中使用。计算的性能取决于如何处理这些中间结果。为此,TensorFlow引入了一种新的栈数据结果,用于保存循环间的中间值。前向计算将结果压入栈中,而梯度计算则从栈中弹出值。图6给了实现这种基于栈的状态保存的数据流图结构。
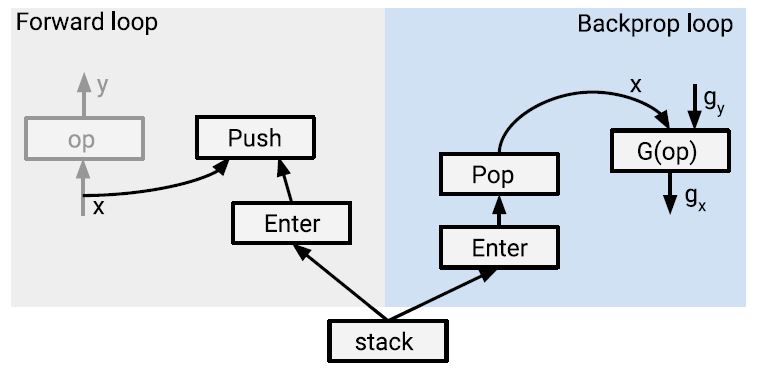
图6:在后向传播中保存可重用的张量
内存管理
对于GPU等特定设备,内存管理在上述过程中十分关键。因为GPU的内存使用通常局限于16GB以内。本论文在模型的实现中采用了多种技术。其中一种主要的技术使用了临时本地性,称为“内存交换”(memory swap)。当一个张量压入堆栈时,内存交换技术将其从GPU移动到CPU内存中,并在后向传播使用该张量时逐步放回。内存交换的高效实现,关键在于计算和I/O操作间的交叠。这需要多个系统组件的无缝合作,包括:
- 循环中的多次迭代可以并行运行,堆栈压入和弹出操作是同步的,可在计算中并行运行。
- GPU对计算和I/O操作使用用独立的GPU流,以增进这两类操作的交叠。
- 内存交换仅在内存使用超出设定阈值时启用。
实验表明,如果不使用内存交换机制,那么系统在处理序列长度500时就无内存可用。但在启用了内存交换后,同一系统可以处理序列长度1000,并且开销很小。可用的内存情况,是限制系统处理最大序列长度能力的首要因素。
评估与实际应用
实验运行使用了一套生产集群,该集群是与其它任务共享的,由Intel服务器组成,配置了Nvidia Tesla K40 GPU,通过以太网连接。论文中评估了模型实现的几个关键特性,包括性能、可扩展性、内存交换特性、序列长度处理能力等。
基准测试:模型性能和可扩展性
图8和图9是对分布式迭代计算性能和扩展能力的基准测试情况。基准测试采用了一个while_loop,循环体分区运行在一个GPU集群上。如图7所示,测试中采用的一种数据同步情况是设备间不做协调,另一种是每次迭代结束后所有设备等待协调(类似于AllReduce)。图8左图显示了机器数从1增加到64,每秒实现迭代次数的变化情况。图8右图表明,并行运行迭代对于实现GPU间的并行十分关键。图9给出了GPU数量对于处理性能(表示为每秒迭代次数)的影响情况。
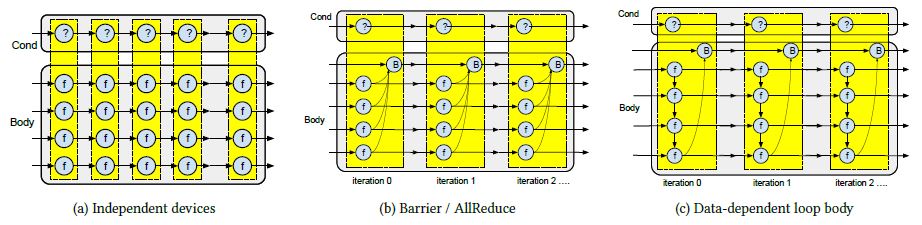
图7:分布式while-loop中数据流依赖性
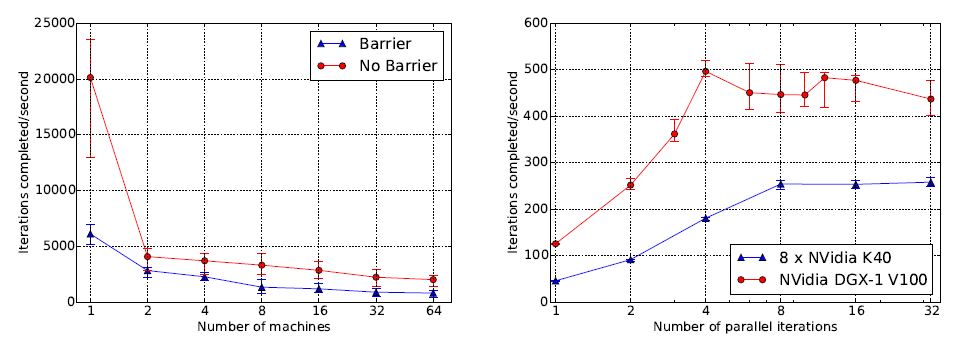
图8:分布式while-loop的性能分析(左图更改机器数量,右图更改迭代次数)
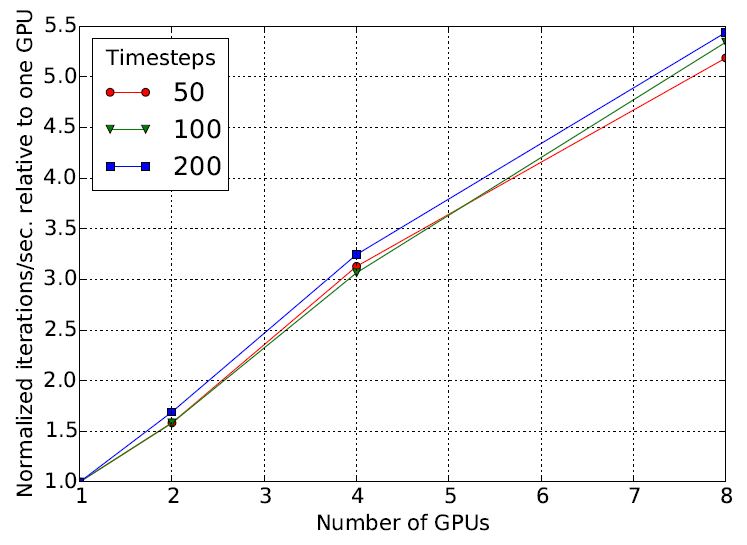
图9:计算性能(以每秒迭代次数表示)随GPU数量的变化情况。
模型特性测试
表1是使用内存交换并增加训练长度的运行情况。
表1:LSTM模型每次循环迭代训练时间,增加序列长度

图10对比了使用动态控制流和静态展开的情况。
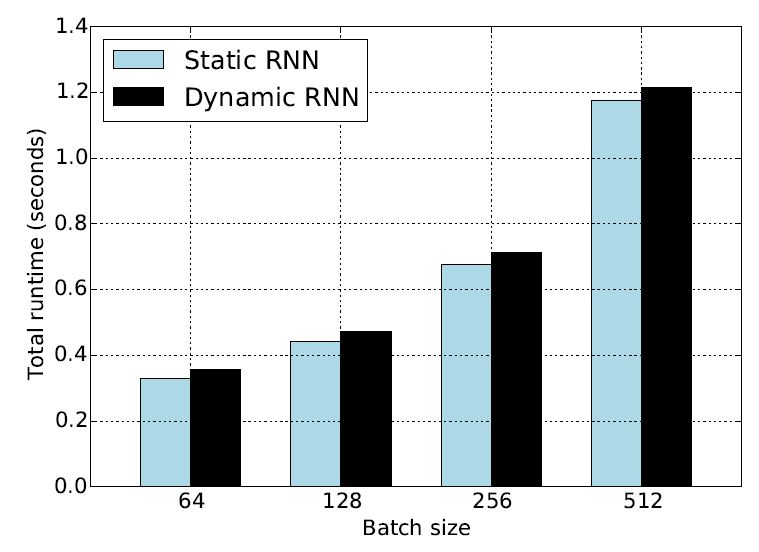
图10:动态控制流与静态展开的性能对比
实际应用:使用动态控制流实现强化学习
为展示动态控制流的优点,论文给出了一个强化学习实现的实例。作为基准测试,文中实现了深度Q网络(DQN,Deep Q-Networks),动态控制流如图11所示。数据库用于存储输入的经验,并通过周期性地对数据库采样,提供以往的经验给Q学习算法。Q学习算法使用这些经验,构建另一个称为“目标网络”的神经网络去训练主神经网络。目标网络也是周期性更新的,以反映主网络的周期性快照情况。动态控制流支持整个计算保持在系统运行时中,并支持并行计算。相比于基准系统,动态控制可提高性能21%。同时,用户无需使用主机语言对数据流图各个分区做编程,简化了算法的编程实现。
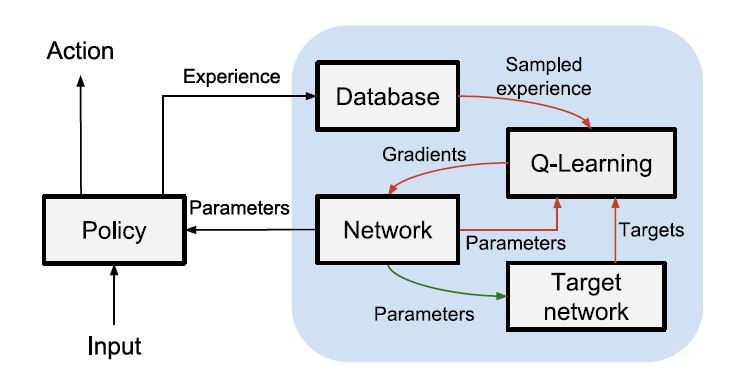
图11:深度Q-Network中的动态控制流
结论
论文介绍了一种使用动态控制流实现机器学习的编程模型。该模型设计支持异构设备间的并发和分布执行,可以使用CPU、GPU及TPU等定制ASIC计算,支持应用在多设备间的频繁控制流决策。模型已在TensorFlow中实现,并得到了广泛地使用,对机器学习的进展做出了贡献。
动态控制流是机器学习中的一个相当活跃研究领域,对未来工作发展非常重要。尤其是条件计算和流计算,可相应地提高计算能力。近期研究给出的模型具有超过1000亿个参数。条件计算和流计算的进一步抽象和实现技术值得做进一步研究。
查看英文原文: Dynamic Control Flow in Large-Scale Machine Learning
