@Rays
2018-08-28T02:48:40.000000Z
字数 3825
阅读 3200
组合CNN与RNN,天才还是错乱?
人工智能
摘要: 从有一些有趣的用例看,我们似乎完全可以将CNN和RNN/LSTM结合使用。许多研究者目前正致力于此项研究。但是,CNN的最新研究进展趋势可能会令这一想法不合时宜。
作者: Bill Vorhies
正文:
从有一些有趣的用例看,我们似乎完全可以将CNN和RNN/LSTM结合使用。许多研究者目前正致力于此项研究。但是,CNN的最新研究进展趋势可能会令这一想法不合时宜。

一些事情正如水与油一样,看上去无法结合在一起。虽然两者各具价值,但它们无法结合起来。
这就是我首次想到组合使用CNN(卷积神经网络)和RNN(递归神经网络)时的反应。毕竟,二者分别针对完全不同类型的问题做了优化。
CNN适用于分层或空间数据,从中提取未做标记的特征。适用的数据可以是图像,或是手写体字符。CNN接受固定规模的输入,并生成固定规模的输出。
RNN适用于时态数据及其它类型的序列数据。数据可以是文本正文、股票市场数据,或是语音识别中的字母和单词。RNN的输入和输出可以是任意长度的数据。LSTM是RNN的一种变体,它记忆可控数量的前期训练数据,或是以更适当的方式遗忘。
对于一些特定的问题类型,我们知道如何选取适当的工具。
是否存在同时需要CNN和RNN能力的问题?
事实证明,的确如此。其中大部分针对的是按时间序列出现的图像数据,换句话说,就是视频数据。但还存在着其它一些有意思的应用,它们与视频并没有任何直接关系,正是这些应用激发了研究者的想象力。下面我们将介绍其中部分应用。
还有一些近期提出的模型,它们探索了如何组合使用CNN和RNN工具。在很多情况下,CNN和RNN可使用单独的层进行组合,并以CNN的输出作为RNN的输入。但是,有一些研究人员在同一个深度神经网络中巧妙地实现了二者能力的结合。

视频场景标记
经典的场景标记方法是训练CNN去识别视频帧中的对象,并对这些对象分类。对象可能会进一步分类为更高级别的逻辑组。例如,CNN可以识别出炉子、冰箱和水槽等物品,进而升级分类为厨房。
显然,我们缺少的是对多个帧(在时间上)间动作的理解。例如,几帧台球视频就能正确表明击球者已经将八个球击入了边袋。另一个例子是如果有几个帧分别是一些年轻人在练习骑行两轮车,并且有一位骑手躺在地上,那么完全可以合理地得出结论:“那个男孩从两轮车上摔了下来”。
有研究者实现了一种分层的CNN-RNN对,以CNN的输出作为RNN的输入。为创建对每个视频片段的“瞬间”描述,研究者从逻辑上以LSTM取代了RNN。组合而成的RCNN模型如上图所示,其中递归连接直接实现在内核上。研究者最后对该RCNN模型做了一些实验验证。细节内容可参阅论文原文。
情绪检测
如何通过视频判断个体或群体的情绪,这依然是一个挑战性问题。针对此问题,ACM国际多模式互动会议(ICMI,International Conference on Multimodal Interaction)每年举办一届竞赛,称为“情绪大挑战”(EGC,EmotiW Grand Challenge)。
每年EGC竞赛的目标数据集会有一定变化。竞赛通常会给出一组不同的测试,对视频中出现的人群或个体做分类。
2016年:基于群体的幸福感分析。
2017年: 基于群体的三类情绪(即正向、中立和负向)检测。
2018年的竞赛(计划在11月开展)将更为复杂。挑战涉及就餐环境分类,其中包括三个子项:
- 食物类型挑战:将每个表述(utterance)按七类食物做分类。
- 食物好感度挑战:识别对象对食物好感度的打分情况。
- 进餐中交谈挑战:识别进餐中交谈的难度等级。
挑战的关键不仅在于如何组合使用CNN和RNN,而且包括如何添加可单独建模并集成的音轨数据。
2016年竞赛的获胜者创建了一个由RNN和3D卷积网络(C3D)组成的混合网络。和传统方式一样,数据融合和分类是在后期进行的。RNN以使用CNN从各个帧中提取的外观特征作为输入,并对随后的运动做编码。同时,C3D也对视频中的外观和运动进行建模,随后同样与音频模块合并。
准确性是EGC竞赛挑战的难点所在,该指标目前依然不是很高。2016年的获胜者在个体面部识别上的得分为59.02%。2017年则升至60.34%,群组得分升至80.89%。但应注意的是,挑战的性质每年都会发生一些变化,因此不能按年度进行比较。EGC年度竞赛挑战的详细信息可访问ICMI官方主页。
基于视频的人员重识别/步态识别
该应用的目标是识别视频中的某个人(根据已有的个人标记数据库),或者仅仅识别视频是否曾经出现过某人(即重识别,其中人员是未标记的)。步态识别是该应用的关键研究领域,进而发展为全身运动识别(例如手臂摆动方式、行走特征、体态等)。
该项应用中存在一些明显的非技术性挑战,其中最突出的问题包括着装和鞋子的变化、外套或全身衣物存在部分模糊等。CNN中一些众所周知的技术问题包括多视角(实际上是一个人从左到右经过所引发的多个视角,即第一视角是前面,然后是侧面,最后是背面),以及照明情况、反照率和大小等经典图像问题。
前期已有研究将一个完整的走步(即步态)使用由CNN获取的多个帧表示,进而组合成一类称为“步态能量图像”(GEI,Gait Energy Image)的热力图。
为一并分析多个“走步”的情况,有研究在模型中加入了LSTM。LSTM的时序能力实现了帧间视图变换模型,可用于调整透视的情况。
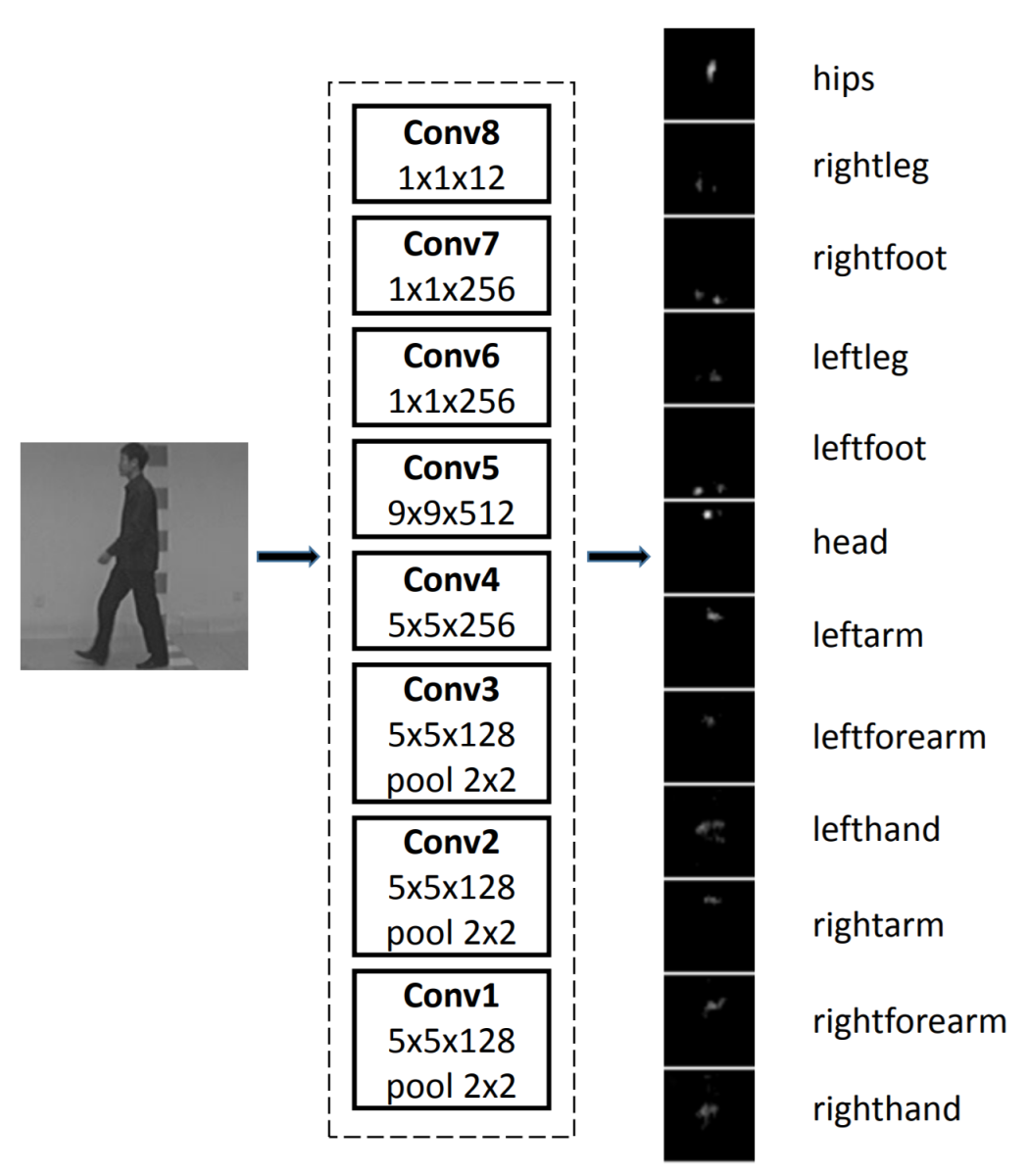
该研究原文及所用图像数据提供于此。视频监视、步态识别的研究论文具有很高的被引数,毫不惊奇几乎所有的研究都是在中国开展的。
下一个研究前沿方向将会是完整的人体姿势识别,无论是用于识别还是标记(人体处于站立、跳跃、坐姿等),它将对人体的每个部位提出独立的卷积模型。作为UI的一部分,手势识别正成为一个研究热点,尤其是在增强现实领域。

天气预报
该应用的目标是预测局部区域及相当短的时间跨度内的降雨强度。这一领域也被称为“临近预报”(nowcasting)。
DNA序列功能量化
人类DNA中有98%尚未编码,这些未编码的片段称为“内含子”(Intron)。内含子在最初被认为是一些毫无价值的进化残余,但是遗传学家现在认识到其价值所在。例如,有93%的疾病相关变种位于这些区域中。对这些区域的性质和功能建模,这是一项正在开展中的研究。近期,一种称为“DanQ”的CNN/LSTM组合模型为解决这一挑战给出了一定的贡献。
据DanQ的研究者介绍,“卷积层可捕获了调控模体(regulatory motif),而递归层则捕获了模体间的长期依赖关系,用于学习调控“语法”以改进预测。与其它模型做对比,DanQ在多个指标上得到了大大的改进。与一些相关模型的ROC曲线下面积相比,DanQ实现了某些调控标记(regulatory marker)超过50%的相对改善”。研究论文原文提供于此。
为默音视频创建逼真的音轨
一些MIT的研究者尽其所能创建了大量标记的鼓槌声音片段。他们使用了一种CNN/LSTM组合方法,其中CNN用于识别视觉场景(鼓槌在静音视频中的击打情况)。但由于声音片段是时序的,并且延伸了数个帧,因而他们使用LSTM层将声音片段与适当的帧进行匹配。
据研究者报告,人们在超过50%的时间中会被预测的声音匹配所欺骗。可在此查看视频。
未来的研究方向
我十分惊喜能看到大量的研究,其中研究者组合使用了CNN和RNN,以获得两者的优势。一些研究甚至在混合网络中使用了GAN,这非常有意思。
尽管这种组合模型似乎提供了更好的能力,但目前还有另一个新研究方向更受关注。该研究方向认为CNN自身就足以适用,RNN/LSTM组合模型并非长久之计。
一组研究人员提出了一种新颖的深度森林架构。该架构嵌入在节点结构中,性能超出CNN和RNN,并降低了计算资源和复杂度。
我们也关注着Facebook和Google这样的更主流方向。两家企业在近期停止在自己的语音互译产品中使用的基于RNN/LSTM的工具,转向使用TCN(Temporal Convolutional Net)。
通常对于时序问题,尤其是对于文本问题,RNN在设计上存在着固有的问题。RNN一次读取并解释输入文本中的一个字(或字符、图像),因此深度神经网络必须等待直到当前字的处理完成,才能去处理下一个字。
这意味着RNN无法像CNN那样利用大规模并行处理(MPP)。尤其是为了更好地理解上下文而需要同时运行RNN/LSTM时。
这是一个无法消除的障碍,绝对会限制RNN/LSTM架构的效用。TCN通过使用CNN架构解决这个问题。CNN架构可以轻松实现“关注”(attention)和“跳门”(gate hopping)等新概念的MPP加速。 详细内容可参阅我们的论文原文。
当然,我无法做到概述整个研究领域。即便是针对最小延迟需求不像语音翻译那么严格的情况,我也做不到一一列出所有研究。然而,对于我们上面介绍的所有这些应用,似乎完全可以重新审视TCN这种新方法是否适用。
扩展阅读
Bill Vorhies的博客文章。
作者简介

Bill Vorhies是Data Science Central的总编辑,自2001年以来一直从事数据科学研究。可通过Bill@Data-Magnum.com或Bill@DataScienceCentral.com与他联系。
