@w460461339
2019-02-26T03:09:31.000000Z
字数 3694
阅读 2923
Tensorflow Day8: YoloV3
Tensorflow
0、参考
很不错:https://blog.csdn.net/leviopku/article/details/82660381
关于loss部分的一些解释:https://www.jianshu.com/p/67163d52946f
1、YoloV3原理
yolo_v3的原理其实和yolov1没有大的改变,还是cell+一步到位预测的组合。
一些有意思的地方主要是在细节上。
比如在loss设计上,将anchors技术和yolov1采用的cell限制bbox中心偏移的方法结合在一起。
在网络设计上,采用多尺度。
。。。
2、anchors聚类(训练)
yolo系列运用anchors比较成功的地方在于,它没有人工指定anchors,而是通过对已有数据进行聚类,来得到。
聚类方法:k_means。
聚类输入:【None,2】其中,2表示每个gt的宽和高。
距离计算:
1、计算两个gt可能的最大IOU。
1.1 选择两者宽度的最小值w_min,和高度的最小值h_min.
1.2 w_min*h_min表示最大的相交面积。
1.3 计算IOU完事。
2、1-IOU表示两个gt的距离。
完全体的yolo而言,一般选择聚类中心=9
3、主干网络(训练)
主干网络是比较简单的部分了。
网络的结构图如下图:
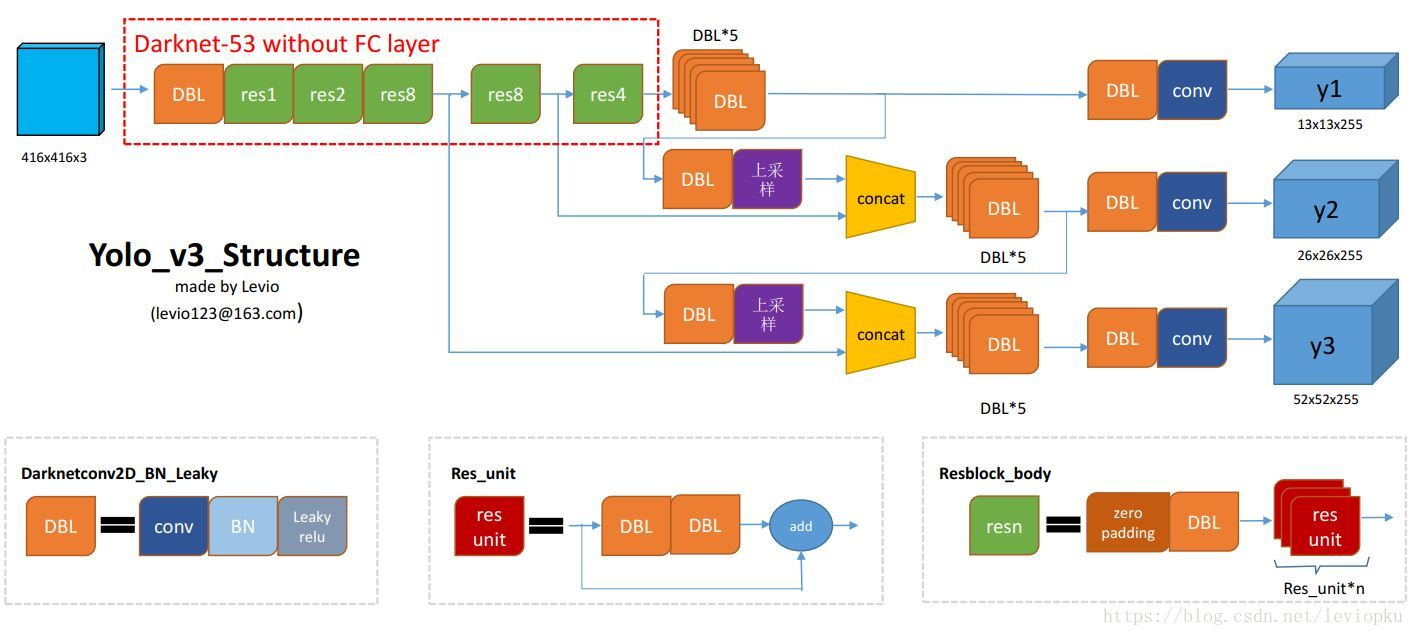
注意几个点:
1)yolov3特色DBL层:conv+BN+LeakRelu。
2)输入尺寸需要resize到416*416.
3)anchors和尺度。
聚类完成后,anchors有9种,按照面积从大到小排序,得到3组anchors。
那么第一组面积最大的anchors,对应于上图y1;
第二组面积中等的anchors,对应于上图y2;
第三组面积最小的anchors,对应于上图y3;
就是不同的尺度,对应的anchors面积也不一样,简单易懂。
4)输出维度:三个尺度:
13*13*255
26*26*255
52*52*255
255表示 3*(5+80)
3表示每个尺度对应3中anchors的预测。
5表示每个bbox的(4个坐标+1个置信度)
80表示每个bbox的分类信息。
这里涉及到一个问题,bbox的坐标信息是怎么表示的?是Faster_rcnn那一套相对偏移?还是yolo_v1的中心限制?
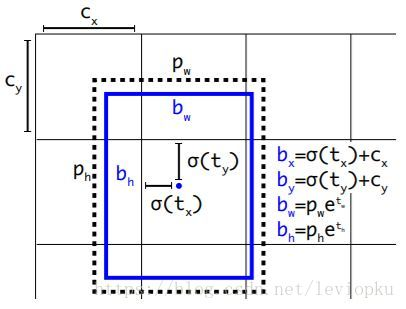
我们看上图,上图是解释yolo_v3中坐标输出的内容的。
在这里,是网络的输出,也就是啊上面3*(4+1+80)中的4.
其中,在经过sigmoid后,是相对于当前cell左上角的偏移,再加上cell位置,才是绝对位置。
而在经过后,得到的是原图下bbox的宽,其中表示anchors的宽。
那么可以看到,yolo_v3其实是Faster_Rcnn系和yolo_v1的结合体。
在中心预测上,用了yolo_v1的方法,限制中心在一个cell内。
在宽高预测上,用了faster的方法,寻找相对于anchors的比例。
因此,我们总结:
对于bbox的坐标信息而言,它预测的t_x,t_y,t_w,t_h是在当前尺度(当前划分,就是把原图划分成几份)的情况下,预测的一个相对值,需要通过上图的转换,得到在当前尺度的bbox坐标信息。
4、数据获取(训练)
我们想想该如何准备训练数据。
已有条件:
1、不同尺度的预测结果上,用了不同的anchors。
2、预测结果和anchors是依赖的。
3、不同尺度之间,互不重复。
那么,对于gt而言,它需要确定:
1、它对应于哪个anchors;
2、一旦确定了它对应哪个anchors,那么gt在哪个尺度上被预测也就能够知道了。
1)解析原始数据:
xxx/xxx/1.jpg 0 453 369 473 391 1 588 245 608 268
解析完毕后,得到 img_path:1,gt_cor=[None,4],gt_label=[None,4]的返回值
2)对于这张图片的每个gt,计算这个gt和每一个anchors的IOU,计算方法和anchors聚类时候用的一样。选在IOU最大的anchors,与这个gt对应。此时:
1、gt对应的anchors已经知道了。
2、gt对应的尺度也知道了。3)完成后,在对应尺度对应位置上,将gt的信息存好。那么对于每张图,我们能够获得:
1、resize过的图像:[416,416,3]
2、尺度1的label:[52,52,3,4+1+80]
3、尺度2的label:[26,26,3,4+1+80]
4、尺度3的label:[13,13,3,4+1+80]4)另外,我们注意,这里的4,表示的坐标,全部都是原图上的坐标,即原图上的x_c,y_c,w,h。
5、loss设计
loss设计上,其实和yolo_v1大同小异,都是分这么几部分:
1、坐标的loss
2、置信度loss
3、分类loss
同样,并不是所有的bbox都会用于loss。
由于yolo_v3还是基于cell的,我们可以把bbox分为这么几类:
1、确定被用于预测物体的。
2、确定不被用于预测物体的,并且和gt的IOU小于阈值。
3、确定不被用于预测物体的,但是和gt的IOU大于阈值。
大意就是,‘狗拿耗子,我也不惩罚,也不奖励’。
综上:
1、对于坐标loss和分类loss而言,仅有确定用于寻找物体的bbox,会被计算loss。
2、对于置信度而言,计算:
2.1 计算用于预测物体的bbox。
2.2 确定不被用于预测物体的,并且和gt的IOU小于阈值。
另外,很重要的一点是,所有的IOU,包括上面的anchors聚类,数据准备,和接下来的bbox分类,IOU的计算都是需要在原图的尺寸上进行的。
而loss的计算,都要在自己的尺度下进行。
那么LOSS的操作,步骤如下。
1)将网络得到的预测结果,【坐标,置信度,分类结果】分开,将坐标转换成在原图上的[x,y,w,h]坐标形式bbox。置信度和分类结果无所谓。
2)根据label中的置信度信息,从label中筛选出gt框信息[x,y,w,h]坐标gts。
3)对于每个bbox,计算它和每个gts的IOU。
4)对于IOU小于阈值的bbox,将其标记为ignore。【相当于得到ignore_mask】
回想这幅图:
5)坐标中心:由于bbox是原图尺寸下的值了,所以我们将bbox的[x,y]值除以放缩比例,减去cell左上角的值,相当于得到图中的,将gts的[x,y]除以缩放比例再减去cell左上角的坐标,也得到了gt的中心,相对于cell左上角的偏移。。
6)坐标长宽:对于原图的坐标长宽,我们计算它相对于anchors的偏移就好,这个偏移我们在Faster_RCNN里面说过,是无所谓尺度的。那么对于bbox的w和h,我们计算,得到了bbox相对于anchors的宽偏移量,h同理;gts同理。
7)在之前数据准备过程中,我们知道仅有部分cell的某个bbox负责预测。我们用一个obj_mask来表示它。
8)置信度:用sigmoid计算每个bbox的置信度,然后通过:“2.1 计算用于预测物体的bbox。2.2 确定不被用于预测物体的,并且和gt的IOU小于阈值” 来筛选用于计算loss的置信度。
9)分类坐标:采用sigmoid来计算,避免softmax造成的一家独大问题。
10)另外,gts越小,它的loss权重越高,因此还有一个
那么,最终的loss:
6、其他细节
1)tf.data:这个算是一个高速读取数据的模块。
总体分为两部分:1、获取数据。
2、返回数据。
获取数据上,我们用DataSet或者其子类,来读取数据。当我们需要对读取的数据进行处理,才能够得到我们最终要的数据时,还可以使用apply方法来操作。
返回数据,用的是迭代器,iterator,根据读取数据的不同采用不同的迭代器。
2)上采样/上池化/反卷积:https://blog.csdn.net/A_a_ron/article/details/79181108
差别在于反卷积的反卷积核需要学习,另外两者就直接放回去就好。3)sigmoid替代softmax。
注意到,在上面的分类loss中,用的是sigmoid而非softmax。是因为,对于一个bbox而言,如果用的是softmax的话,那么分类时,会出现一个类别之间相互压制的情况。
但有时会出现,这个物体属于两个类别,那么用sigmoid就能解决这个问题。它会对每个类别都都单独打分,然后利用每个类别的NMS进行边框筛选就好。
