@w460461339
2020-09-07T02:06:32.000000Z
字数 6268
阅读 4696
目标检测:Yolo,Yolo2,Yolo3
MachineLearning
1、前情回顾
我们这里简单回顾一下Yolo之前几个RCNN的操作。
1)RCNN:
1、selective search来提取候选框。
2、每个候选框过一遍CNN+SOFTMAX进行特征训练。
3、2中的CNN训练完了后,候选框再过一遍CNN,得到4096位向量。
4、4096维向量过SVM进行分类->>用非极大值抑制筛选一下候选框
5、候选框位置信息过回归器做精修。2)Spp-Net:
1、在CNN和全连接层之间,加入了kernel-size和stride可变的pooling层,解决不同尺寸输入问题。
2、完成了图片上的候选区和特征图上对应区域的映射。
3、流程如下:
4、Selective Search提取候选区。
5、将整个图送入CNN,提取特征。
6、将原图上的候选区映射到feature-map上,对feature-map上每个‘候选区’做Spp-net,得到统一尺寸的输出。
7、每个输出进SVM,并进行非极大值抑制。
8、每个候选框位置坐精修。3)Fast-RCNN
1、不需要单独的回归器和SVM来做位置精修和分类。
2、Spp层不需要太多层。
3、流程如下:
4、Selective Search提取候选区。
5、整个图送入CNN,提取特征。
6、原图候选区映射到特征图上,对特征图上每个‘候选区’用1层的SPP,得到统一尺寸输出,顺便再过一下全连接。
7、这个向量产生两种输出,一个是过一下softmax,得到分类概率;一个是过一下回归,得到精修的位置。
8、最后接一个非极大值抑制,过滤一下候选框4)Faster-RCNN:
1、把region proposal放在外面也不太好,现在我们把它一起放进来吧!
2、主要是一个RPN层。
3、首先整图过一下CNN,然后对feature-map做pad=1,3*3的卷积;每次卷积的时候,以卷积核的中心,在原图上框出9个候选框。
4、然后卷积的结果作为这9个候选框的特征向量,传入FAST-RCNN的softmax以及回归精修。
5、最后接一个非极大值抑制,过滤一下候选框。
2、Yolo
you only look once
2.0 参考:
https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
https://chenzomi12.github.io/2016/12/14/YOLO-details/
代码阅读:
https://zhuanlan.zhihu.com/p/36819531 【这里其实可以看到,yolov1中用的都是relu作为激活函数】
https://zhuanlan.zhihu.com/p/35325884 【这里可以看到,通过主干网络得到的13*13*50的结果,又按照各自不同的功能(位置,是否包含物体,属于每个class的概率)进行了不同的激活,这个很重要,这样也解释了在v3中,说用sigmoid替换softmax是如何做到的】
根据前面的梳理,我们发现,目标检测过程还是分两步,首先提取proposal-region,然后再对proposal-region进行分类和位置精修。
这样也不优雅,yolo使用一种方法,将分类问题转换为一种回归问题。
这里有些点我其实卡了一会,想要弄清楚,需要将其分为训练和测试两部分。
2.0 网络结构
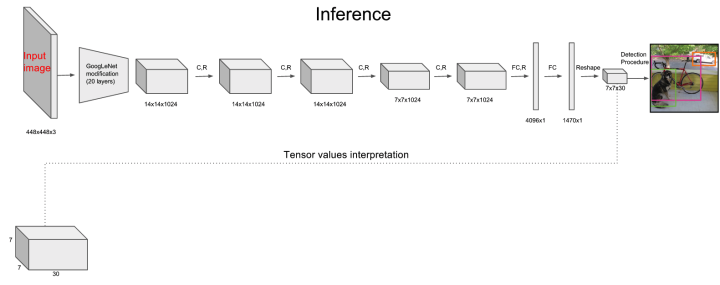
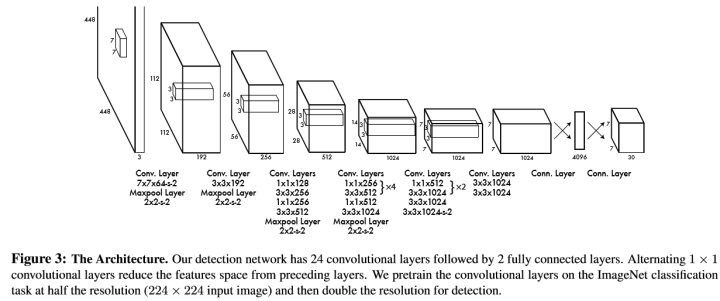
2.1 训练
注意:以下注意区分 网格,bbox(预测框),ground-truth-box
记住以下假设:
1、下面是一个20类的分类问题。
2、图像被分为7*7小网格。
3、每个网格产生2个boundingbox。
1)训练数据:对于一幅图,我们主要标注物体所在方框以及它是什么位置。(每个方框5个信息,4个表示位置,1个表示类别)
2)对于一幅图,我们将其分为S*S个网格,对于每个网格,我们选择两个boundingbox(随机选,大小比例不固定,以下简写bbox)。

3)对于每个bbox,我们需要2种信息:
1、一个是位置信息,用中心点位置和长宽表示->>>共4个数据。
2、bbox内含有物体的置信度(【Pr(Object)仅取0或者1】,只要有物体就好,是什么不重要)->>>1个数据
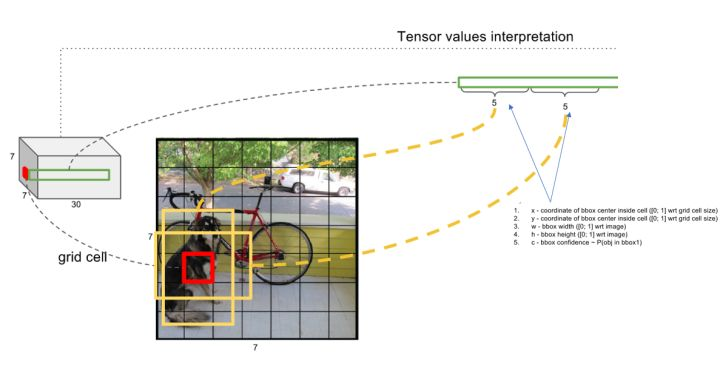
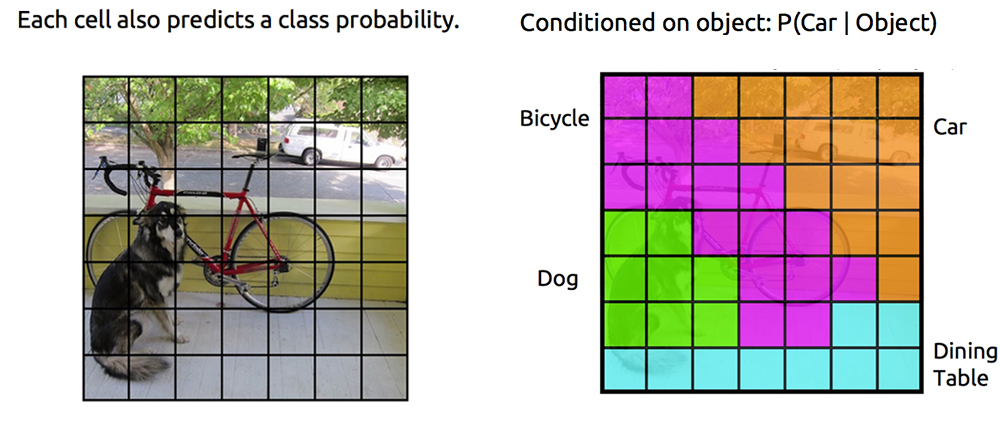
4)对于每个网格,在我们会根据ground-truth-box标注它属于什么类别。(其实是给这个网格属于哪个类别进行打分,打分最高的就能表示这个网格)【这个算是label数据】
5)那么,对于每个网格,我们就会有 个输出,一幅图会有个输出。
6)论文中和很多博客里面都提到了,(在训练时),由物体中心落入的那个网格负责检测该物体。我觉得,我对这句话的理解是:
1、训练的过程中,我们需要给网络一个引导。
2、这个引导的方式,就给正确的网格(中心落在的网格)对应的bbox,比较高的置信度;其他网格的置信度降低。
3、比如上图狗狗右下角的网格,我们并不希望/奢望它能够计算得到一个bbox,来得到狗狗,或者自行车。
4、那么对于中心落在的网格所对应的bbox,我们提高它的置信度(表示这个地方有物体,而且我这个bbox的重合度很高)。
5、对于如右下角那样的区域就降低其置信度(可以降为0吧?),表示这个区域没有物体,或者有物体,但是和我这个bbox的重合度很低。
20200218:
回过头来看这里真的是可爱…训练的是,物体中心落入的那个网格负责检测物体,其实对应着loss的设计,比如这个公式,对于左下角的狗狗,有8个cell都包含,那么究竟让那块来做预测呢?都做吗?这样偏离太远的,会让网络训练不稳定。所以就在标注label的时候,让中间那个cell来作为ground_truth,它对应的为1,其他为0.
- 7)另外其实loss的构造也很亮,但这里主要是把流程理顺。
2.2 预测/测试
1)对于输入图像,过了一遍网络后,我们模型会将它变成7*7*30的feature-map(这里说7*7)。
2)对于每个网格,模型会输出以下信息:
1、该网格属于20个类的概率。
2、输出两个bbox,每个bbox包括:
2.1 x,y,w,h:用来确定位置信息。
2.2 :该bbox内含有物体的概率*IoU。【Pr(Object)仅取0或者1】
20200218:
这里再提一句,这个公式,是在训练的时候,用来标注用的…换句话说,这个是告诉你如何计算label的;我们从模型中得到的,就是[0.1,0.2,0.3,0.4....]这样的值,然后和我们用自定义的confidence公式算出来的结果去计算loss,然后训练。
3)我们用乘以,有. 该值反映了这个bbox属于每个类的概率,以及它bbox的准确度。对每个网格的两个bbox都这么做。
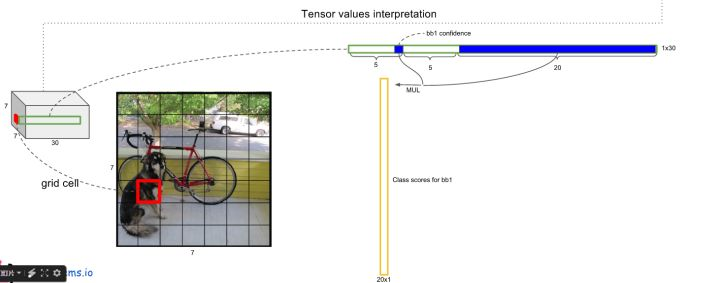
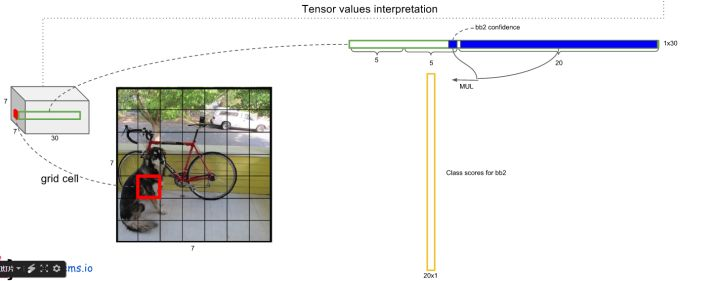
4)对于这个new_confidence,我们可以认识到,它的长度等于类别数量(或者+1,多一个背景)。因此,对于20类的分类而言,我们这里每个网格会得到2个长为20的向量,它表示这个网格所对应的两个bbox,其内包含是第i个种类物体的概率。
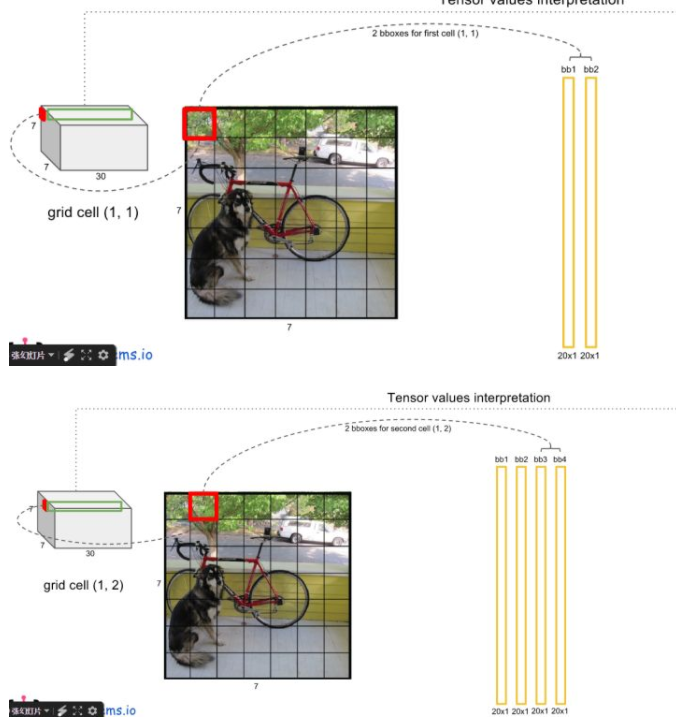
5)这样,我们就有2*7*7个20维的向量了。
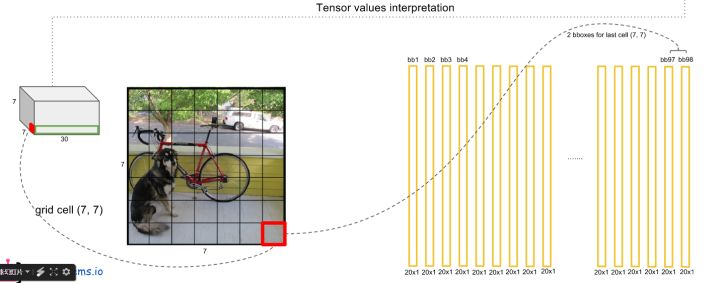
6)最后,和RCNN里面一样,对着2*7*7个20维向量以及他们对应的位置,采用阈值过滤和非极大值抑制,得到最终的框框。
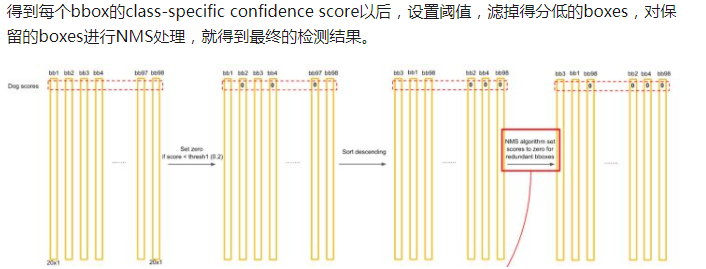
2.3 Yolo v1 缺点
1)YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
2)测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
3)由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
2、YOLO2
参考:
https://zhuanlan.zhihu.com/p/25167153
Yolo2主要就是把一系列方法加入进去,来对Yolo做提升.
1)Batch normalization:
1、神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch-梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
2、解决办法之一是对数据都要做一个归一化预处理。YOLOv2网络通过在每一个卷积层后添加batch-normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout优化后依然没有过拟合),使得mAP获得了2%的提升。2)High Resolution Classifier:
1、所有state-of-the-art的检测方法基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,例如AlexNet输入图片会被resize到不足256 * 256,这导致分辨率不够高,给检测带来困难。所以YOLO(v1)先以分辨率224*224训练分类网络,然后需要增加分辨率到448*448,这样做不仅切换为检测算法也改变了分辨率。所以作者想能不能在预训练的时候就把分辨率提高了,训练的时候只是由分类算法切换为检测算法。2、YOLOv2首先修改预训练分类网络的分辨率为448*448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入。然后fine tune为检测网络。mAP获得了4%的提升。
3)Convolutional With Anchor Boxes:
1、YOLO1现在每个网格提取两个bboxs,并且是通过全连接层来回归预测的,我们感觉这个方法会丢失很多空间信息。丢失空间信息是指,将feature-map过FC的时候,由于2维变1维,自然很多未知信息就没了。而且没有先验框(x,y,w,h)最开始的时候乱飘,很容易跑飞的。 2、现在我们借鉴RPN网络,对每一个网格,我们定好k个anchor,然后让网络通过卷积来给出每个anchor的位置精修参数,以及每个分类的置信度。 3、注意这里和FASTER-RCNN的区别。在FASTER-RCNN中,预测的基本流程是这样: 3.1 RPN预选m*n*k个anchor框,然后得到对每个框的前/背景概率以及对每个位置的精修。 3.2 同时,RPN拿到了proposal-region,然后在FAST-RCNN中提出的feature-map上找到对应的ROI,然后甩SPP提取size相同的feature-vector,最后送入回归网络和softmax做预测。 4、YOLO2在利用RPN的时候,就不再用一个后续送入FAST-RCNN的过程,直接把RPN精修过的anchor认为是最终的目标框;另外,也不需要预测前景背景,直接预测20个类别每个类的概率。 5、这里注意,YOLO2在采用RPN后,也不再是预测每个网格的类别概率了,而是针对每个anchor()预测类别概率。4)Dimension Clusters(维度聚类)
1、回忆FASTER-RCNN,里面的anchor都是人工预先指定,然后通过网络来进行位置精修的。
2、但是,如果能够用更科学的方法来选择anchor的size和数量,会不会更好。
3、于是,通过对标注好的ground-truth-box进行聚类,并在复杂性和效果之间做了平衡,最终选择了5中不同尺寸的anchor左作为基准的anchor。
之后还有很多操作,这里就不多说了,参考里都有。
3、YOLOV3
https://zhuanlan.zhihu.com/p/49556105
实例代码
https://github.com/eriklindernoren/PyTorch-YOLOv3
几个关键词:
1、Residual Block
2、FPN思想
3、anchors按需分配。
4、激活函数最后一层:logistics换softmax
5、边框回归
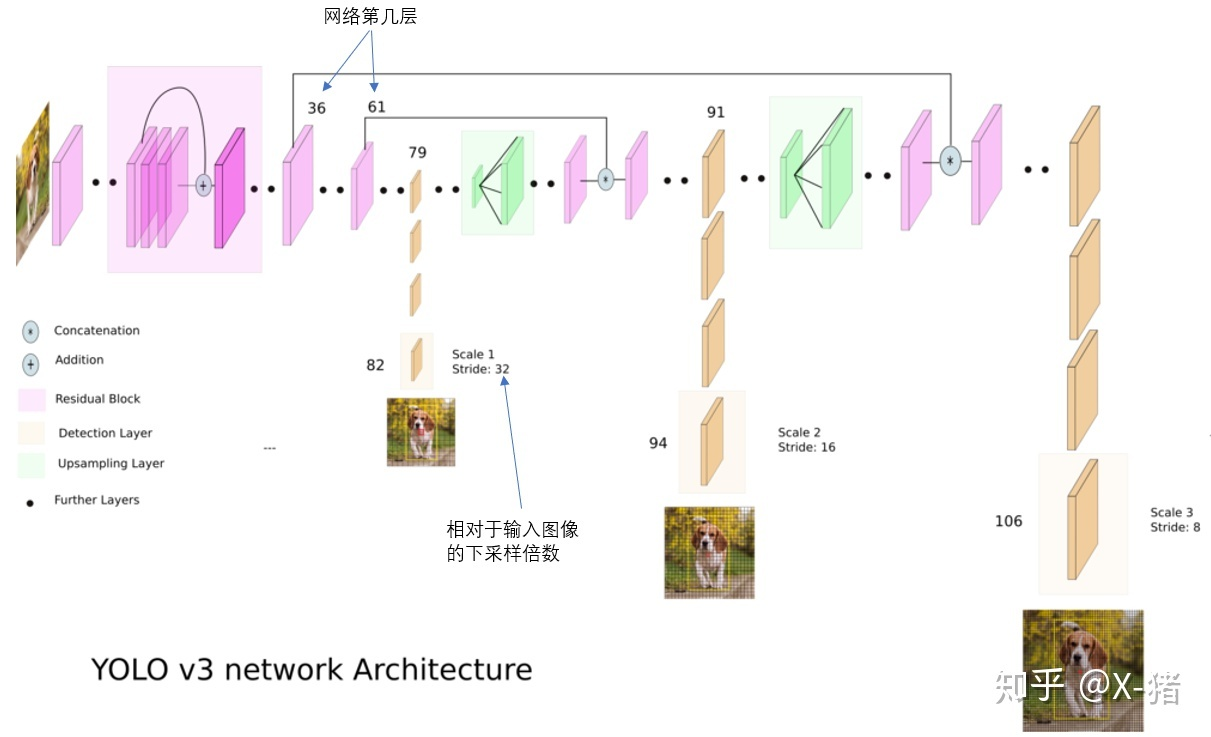
3.1 网络结构
3.2 Inference过程
事先准备好的anchors:

注意,这里先验框的大小都是针对原图而言的。
图像输入后,前面通过residual-block进行特征提取,到79层的时候,已经缩小了32倍了。
第79层的feature-map,其感受野最大,所以要用最大的三个先验框。下图中,黑色的小方块代表79层的feature-map上每一个1*1的点对应的感受野。另外蓝色框表示的就是我们的先验框。比如最小的那个蓝色,差不多占3.5*3个黑色方框,其实就是(116/32)*(90/32).

然后91层和106层同理。
注意,这里用了FPN的思想哈,不仅上采样,还会和之前的降采样相同大小的feature-map记性concatente。
对于feature-map上的每个位置,需要预测(某个anchor的分类概率+某个anchor的坐标+某个anchor的前背景置信度),因此,总共有(13*13*3+26*26*3+52*52*3)个边框被预测出来,每个边框对应(80+4+1)这么个维度。
输入到输出映射:
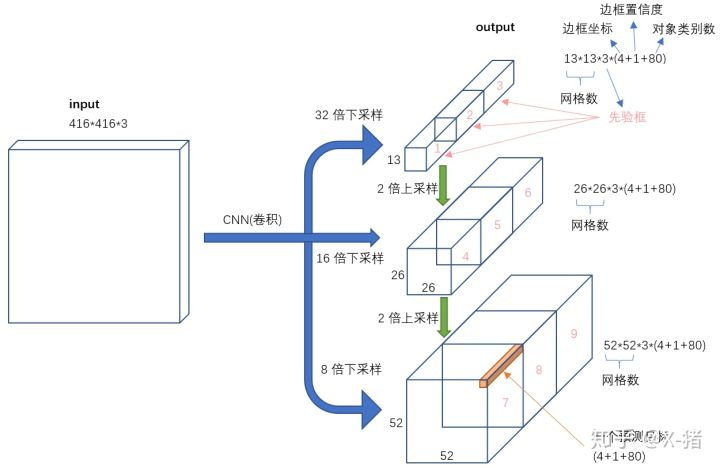
3.3 logistics和softmax
softmax:
1、当softmax做激活函数时,假设输出80个p,那么sum(p1...p80)=1
logistics:
1、当logistics做激活函数时,80个p互不相干,仅输出属于这个类别的可能性。
3.4 边框回归
预测款:bbox
label框:gt
- 1)训练的时候要求的label是什么样的?
class_label, cx,cy,cw,ch
0. 0.1129 0.5605 0.06226 0.079
对于416*416大小的原图,图中狗狗框的中心坐标为x=100,y=100,w=50,h=60,
那么,cx=100/416,cy=100/416,cw=50/416,ch=60/416
但这个不是inference过程给出来的结果。
中间需要转换。
- 2)预测出来的label是什么样子的:
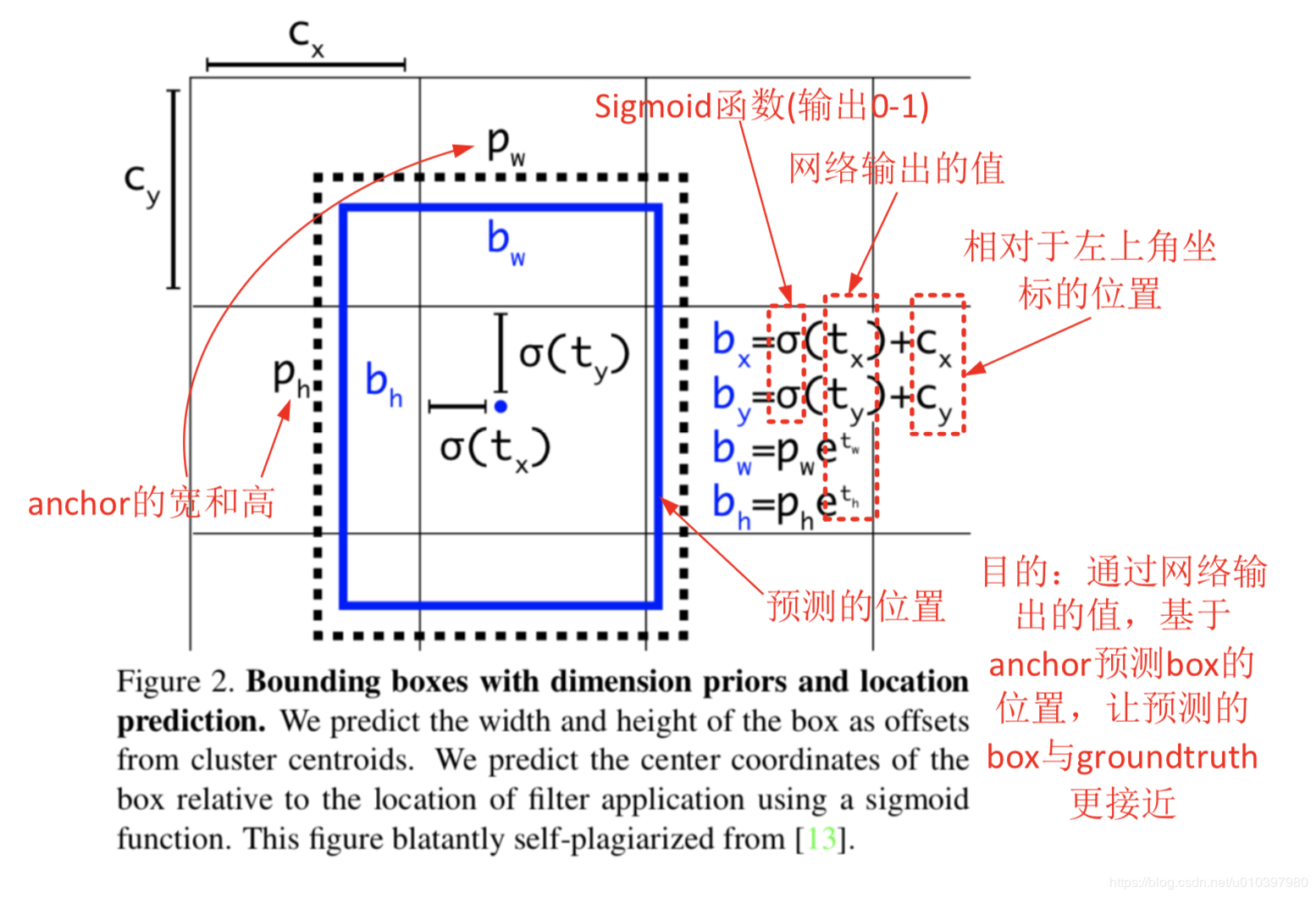
回味一下yolov3的FPN,对于13*13这个尺寸的输出,在每个cell上,它都会预测anchors_num*(4+1+class_conf)个值。
那么,对于每个cell的每个anchors,我会预测4+1+class_conf个值,不管后面的1+class_conf,我们看前面这个4。
这个4对应上图中的tx,ty,tw,th。其中,tx,ty在经过sigmoid之后,变成了bbox的中心在这个cell内的偏移量;而tw和th在变成e的次幂后,变成了bbox和anchors的比值。
通过这种方式,就将bbox和cell以及anchors绑定在一起。
https://github.com/eriklindernoren/PyTorch-YOLOv3
- 3)在所使用的代码中,模型会处理最终的输出结果,使其以(x,y,w,h)的方式输出,可以直接用来画图。
